D-66-데이터분석
Dataframe
-
T
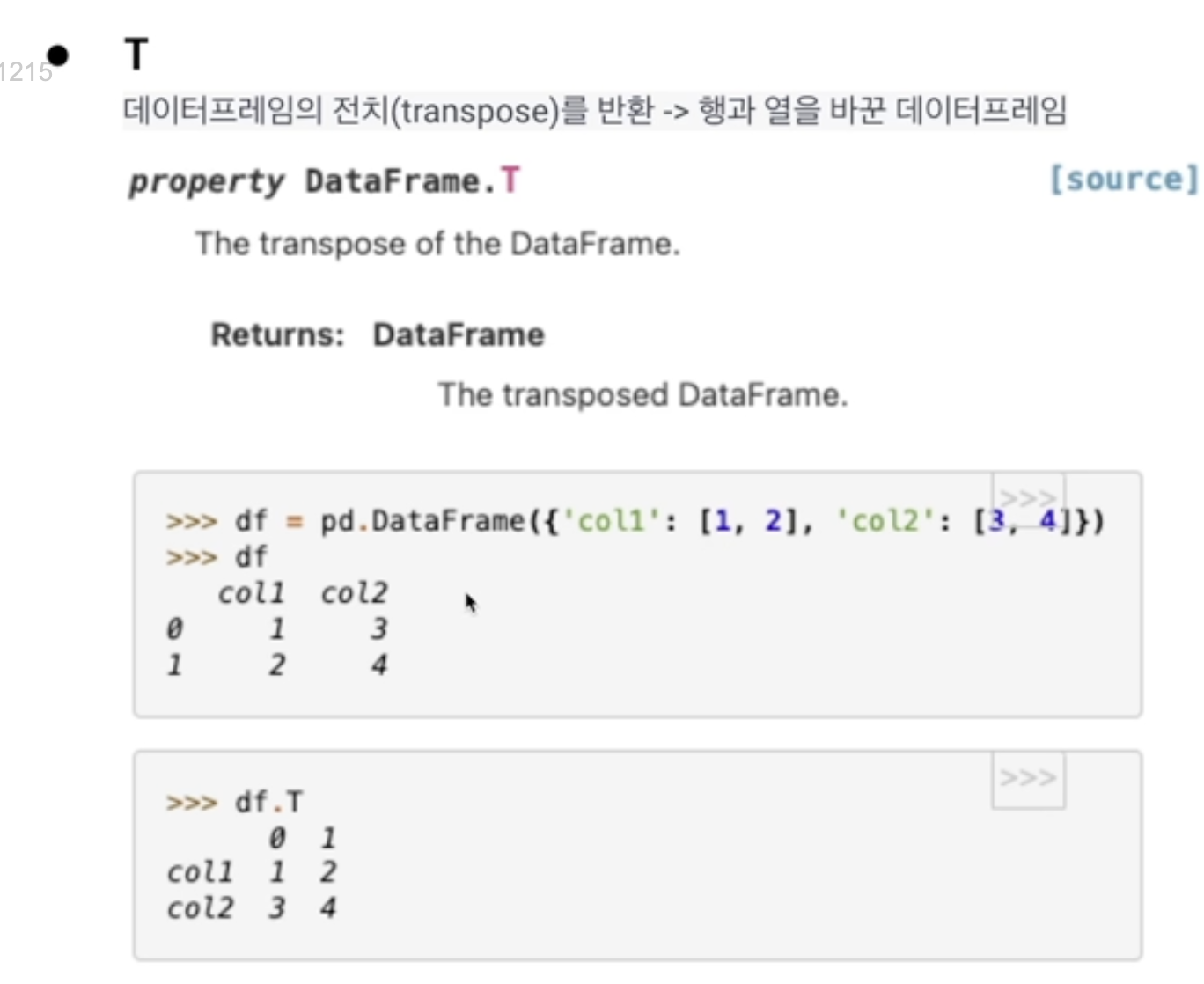
-
fillna()

df.fillna('값') -> 모든 컬럼 값 중 nan 값에 해당값 적용
df.fillna({'컬럼명':'값'}) -> 특정 컬럼 값 중 nan 값에 해당 값 적용
df.fillna({'이름':'홍길동','나이':df['나이'].mean().astype(int)})
-> 이름컬럼의 nan 값에는 '홍길동' , 나이컬럼의 nan 값에는 나이컬럼의 평균값을 적용- dropna()

df.dropna(subset=['이름','나이']) -> 이름, 나이 컬럼에 대해서 nan 값이 있는 행 삭제- reset_index()

df.reset_index() -> 기존 index는 컬럼으로 이동
df.reset_index(drop=True) -> 기존 index 삭제- 인덱싱/슬라이싱
- df[행][열]
- loc[행,열]
- iloc[행,열]
- df['col'] -> series 로 반환
- df[['col','col1',...]] -> dataframe 으로 반환- sort_values()
df.sort_values(by=['나이','이름'], ignore_index=True)
-> ignore_index=True 주면 인덱스 0 부터 초기화
도전적인 개발자