

(바로 이 짤이 떠올랐다)
지금까지 악명이 자자한 Project2를 진행하느라 정말 다들 고생 많았다 😂
Project3 Virtual Memory(vm)에 온 것을 환영한다...
개인적으로 가장 재밌었다고 생각하지만 양이 많아서 동기들이 힘들어했다.
하지만 도전하는 사람 모두가 끝까지 포기 하지 않았으면 하는 마음에 글을 작성하기로 마음을 먹었다.
OnlyEEE 노션 정리 링크 👨👦👦

OnlyEEE는 팀의 맏형이 mbti의 i를 혐오해서 e만 허용한다는 의미이다. 논란 있을듯..🤪
bulksup, kiwoon과 함께 정리한 노션
회고에 앞서 알아둬야 할 것 🧩
이 글의 pintos는 kaist의 CS330 과정의 pintos이며, 작성하는 부분 중 제가 잘못 이해한 부분도 있을 수 있음에 유의해 주시길 바란다.
우리 조는 git book을 참고해서 진행했고, 다른 정답 코드와 한토스(한양대 핀토스)를 참고하지 않았다.
그래서 코드에 관해서는 올리지 않을 생각이고, 보지 않는 걸 추천하지만 깃허브 링크를 첨부한다.
각 Part 별로 why(왜 해야 하는지), do(뭘 했는지), Problem(문제와 해결 과정)을 다룰 생각이다.
1. Memory Management

Why❔
Part1의 깃북을 보았을 때 가장 먼저든 생각은 supplemental page table(spt)이 왜 필요한 지였다.
아니 없어도 지금까지 우리 좋았잖아....
지금 생각하기에 정말 바보 같지만 pml4(페이지 테이블)가 충분히 spt의 역할을 할 수 있다는 생각이 들어 spt가 필요하지 않다고 생각했다.
우선 spt가 필요한 이유는 가상 메모리의 페이지와 물리 메모리 페이지 프레임을 효과적으로 관리하기 위해서다.
이해를 돕기 위해 Project3부터 변경된 page fault에 대해서 알아보자.
spt가 없을 때는 pml4(페이지 테이블)과 물리 메모리가 1:1로 매핑 되어 있다.
그래서 page fault가 발생했을 때는 이미 찾을 수 없는 페이지인 것이다.
하지만 변경된 page fault는
1. spt을 확인해서 page를 탐색한다.
2. spt 안에 page가 있다면 Pml4에 페이지를 넣고(설치하고), 프레임(물리 메모리)에 연결한다.
3. spt 안에 page가 없거나, 유효하지 않는 주소라면 true fault(진정한?! fault)가 발생한다. 사실 Part2의 anon page와 lazy load를 구현하게 되면 명확하게 알게 된다.
이번 Project3은 양이 상당하기 때문에 아직 이해하지 못했더라도 Part1은 일단 구현하는 것을 추천한다.
Do 💩
정말 간단하게 해야할 것을 정리하자면 깃북을 참고해서 SPT와 frame 관련한 모든 함수를 구현하면 된다.
supplemental page table
supplemental_page_table_init()→ pintos에서 지원하는 struct로spt를 초기화 하는 함수.spt_find_page()→ spt를 순회하면서 관련 hash 함수로 동일한 va를 가진 page를 찾음.spt_insert_page()→ spt에 관련 hash 함수로 page를 삽입한다.
frame
pintos에는 기본 frame의 틀은 가지고 있지만 이 후 추가기능을 구현하면서 기능을 추가해야함 → TODO!
vm_get_frame()→palloc_get_page()를 호출해서 메모리 풀에서 새로운 물리 메모리 페이지(frame)를 가져옴
1.palloc_get_page()를 통해 물리 메모리 페이지 공간(주소)을 할당 받는다.
2. 할당 받은 주소에 프레임 구조체를 연결 시킨다(init)
3. 일단 실패할 경우Swap out하는 과정은 구현 X → Part 5에서 함vm_claim_page()→ 함수는 인자로 주어진 va에 페이지를 할당하고, 해당 페이지에 프레임을 할당함.
1. spt에 va에 해당하는 페이지를 찾는다. (spt_find_page)
2.vm_do_claim_page를 실행한다.
vm_do_claim_page()→ 인자로 주어진 page에 물리 메모리 프레임을 할당함.
1.vm_get_frame을 통해 빈(새) 프레임을 가져옴.**
2. pml4(페이지 테이블)에 인자로 받은 page가 없을때 가상 주소에 매핑해준다. (install_page) →Page ↔ frame
3. 이후 각 page type에 맞게swap in해서frame table에 넣어줌→ Part 5에서 함
Problem ☠️
우리 조는 노션을 통해 정리했는데 problem에 대한 정리가 필요하다는 것을 늦게 깨달았다...
이걸 본다면 꼭 정리하는 것을 추천한다.🥲
- spt에 사용한 struct에 대한 이해가 부족해서 part1에는 문제가 없었지만
copy나kill를 구현할때 문제가 있었다.
2.Anonymous Page

Why❔
spt와 frame 구현을 마치고, Anonymous Page(anon_page)를 만나게 되는데 type별로 page를 나눈 다는 것과 lazy load가 어떻게 이루어지는지 이해가 잘 안갔다.
가장 먼저 page type은 uninit, anon, file, page cache가 있다.
짧게 설명하자면
uninit page는 물리 메모리에 연결되지 않은 type 변경을 기다리는 lazy load를 위한 기본 페이지라고 보면 된다. 그래서 uninit page에 해당하는 주소를 참조하면 page fault가 발생하고, type에 맞게 page를 변경한다.
anon page는 이번 파트에서 구현하려는 type이고, 메모리의 힙, 스택, 세그먼트 등의 영역을 담당하는 page이다.
file page는 실제로 disk(file system)에 존재하는 파일에서 데이터를 가져와서 사용하는 Page이다.
이 후 Part4에서 자세히 다룰 것이다.
page cache는 Project4에 다룰 것이다.
각각의 Page type 별로 다른 operations가 있는데 페이지를 세팅하는 생성자(initializer), 스와프 된 페이지를 불러오는(swap in), 페이지를 스와프 시켜 내보내는(swap out), 페이지를 제거하는(destroy)가 있다.
lazy load를 이해하기 전에 먼저 vm 이전의 pintos는 page table는 이미 세팅되어 있다. 그렇기 때문에 메모리를 사용하는 것에 비효율적이라고 볼 수 있다.(process.c의 load()를 보면 ifdef로 분기되어 있는 것을 확인할 수 있다)
그래서 vm를 사용해 page table을 미리 세팅해놓는 것이 아니라 page fault가 발생했을 때 page를 세팅한다는 것이 차이가 있다.(그러므로 vm에서는 초기에 page table은 당연히 비어있다)
정말 심플하게 순서를 나눈다면 이렇다.
- 프로세스가 데이터를 불러오려고 하면
uninit page를 생성하고spt에 넣어준다. - 프로세스가
uninit page에 해당하는 주소를 사용하려고 할 때(page fault) type에 맞는 page로 세팅하고, 물리 메모리(frame)에 연결한다.
이정도만 정리한다면 구현하는데는 문제 없다고 생각한다. 이어서 구현으로 가자!
Do 💩
이번 파트는 anon page, lazy loading, spt copy&kill 구현하게 된다.
Anonymous Page, uninit page, page 관련 함수
vm_anon_init()→anon page를 초기화함
1. 지금은 딱히 해줄 필요 없었다 → Part5 TODO !anon_initializer()→ page→operation에 있는anon page에 대한 handler를 설정해서anon page세팅
1. page를anon page로 초기화
vm_alloc_page_with_initializer()→ 인자로 전달한 vm_type에 맞는 적절한 초기화 함수를 가져와서 이 함수를 인자로 갖는uninit_new()를 호출함
1. type에 맞게initializer설정해줌
2.uninit_new()함수에 type에 맞는 인자를 전달해줌
3.uninit page가 생성되었으면spt에 넣어줌uninit_initialize()→ 처음으로 폴트가 발생한 페이지를 초기화 하고, 먼저 uninit 페이지의 멤버변수인vm_initializer와aux를 가져온 후,page_initializer를 함수 포인터로 호출함
1. type에 맞게initializer설정해줌
2.uninit_new()함수에 type에 맞는 인자를 전달해줌
3.uninit page가 생성되었으면spt에 넣어줌uninit_destroy() ,anon_destroy()→ page 구조체에 의해 유지되던 자원들을 free 시킴
1. page 구조체의 멤버들을 초기화 시킴.
lazy loading
pintos에는 기본 frame의 틀은 가지고 있지만 이 후 추가기능을 구현하면서 기능을 추가해야함 → TODO!
vm_get_frame()→palloc_get_page()를 호출해서 메모리 풀에서 새로운 물리 메모리 페이지를 가져옴
1.palloc_get_page()를 통해 물리 메모리 페이지 공간(주소)을 할당 받는다.
2. 할당 받은 주소에 프레임 구조체를 연결 시킨다(init)
3. 일단 실패할 경우Swap out하는 과정은 구현 X → Part 5에서 함vm_claim_page()→ 함수는 인자로 주어진 va에 페이지를 할당하고, 해당 페이지에 프레임을 할당함.
1. spt에 va에 해당하는 페이지를 찾는다. (spt_find_page)
2.vm_do_claim_page를 실행한다.
vm_do_claim_page()→ 인자로 주어진 page에 물리 메모리 프레임을 할당함.
1.vm_get_frame을 통해 빈(새) 프레임을 가져옴.
2. pml4(페이지 테이블)에 인자로 받은 page가 없을때 가상 주소에 매핑해준다. (install_page) → Page ↔ frame
3. 이후 각 page type에 맞게swap in해서frame table에 넣어줌→ Part 5에서 함
spt copy & kill
supplemental_page_table_copy()→supplemental page table를 복사함supplemental_page_table_kill()→supplemental page table를 삭제함
Problem ☠️
lazy_load_segment()가 실행 되지 않음..vm_try_handle_fault()→vm_alloc_page삭제 →spt_find_page()이 후 page를 못찾을 경우는 true fault임(bogus_fault가 아님)lazy_load_segment()
1.file_seek()→ 파일의 오프셋을 설정해줘야했음
2.memset()시작 위치 수정 → 읽은 바이트 만큼의 위치에서부터 0으로 채워줬어야함
3. file_info→zero_bytes를 read_bytes로 수정 →file_read시 파일을 읽은 만큼의 byte를 리턴해주기 때문에
4. return true → 리턴을 안해줬었음..
- tc 중
read-boundaryfail..- syscall.c 의
check_address()에서 인터럽트가 발생
1. 기존에는page_table에서 찾고 있었기 때문에spt_find_page를 통해spt에서 찾는 것으로 바꿔줌.
- syscall.c 의
3. Stack Growth

Why❔
project2까지는 기본의 메모리의 스택 부분이 1개의 page(4096byte)만 사용할 수 있었다.
vm의 part3인 Stack Growth는 스택의 크기를 최대 1MB까지 증가시킨다.
처음에는 어떻게 기존의 스택에 더 해줘야 하지하는 고민을 했는데 그냥 anon page를 공간이 필요한 만큼 할당해 주면 된다.
예를 들면 스택이 기존 최대 크기인 4kb 넘기지 않는다면 추가로 할당해 줄 필요는 없고,
15kb를 원한다면 anon page를 3개를 추가로 할당해 주면 된다.
우리 조는 Stack Growth를 하루 컷 했는데 팀원들이 기본이 탄탄해서 가능했던 것 같다.
ostep의 vm-segmentation 부분을 보면 도움이 될 듯하다.
Do 💩
이번 파트는 vm_try_handle_fault() 수정, vm_stack_growth() 등을 구현하게 된다.
thread 구조체
1.stack bottom추가
2.user_rsp추가 → 프로세스가 스택 포인터를 저장하는 것은 예외로 인해 유저 모드에서 커널 모드로 전환될 때 뿐이므로 유저 스택 포인터가 아닌 정의되지 않은 값을 얻을 수 있기 때문에vm_try_handle_fault()수정 → page fault가 발생한 주소가 유효한 주소이고,vm_stack_growth()가 필요한 상황인지 확인함.vm_stack_growth()→ 하나 이상의anon page할당하여 스택 크기를 늘림
1. stack growth가 필요한 만큼anon page를 할당해줌.(당연하지만 PGSIZE 크기로)
2. 현재 스레드에stack bottom업데이트
3.uninit page가 생성되었으면spt에 넣어줌.
Problem ☠️
이번 파트는 예외상황을 확실하게 잡고가서 그런지 딱히 문제가 없어서 빨리 끝낼 수 있었다.
4. Memory Mapped Files

Why❔
이번 PART4인 Memory Mapped Files도 anon page를 구현했어서 그런지 그렇게 어렵지 않았다.
Memory Mapped Files = file page라고 생각하면 편하다.
file page는 실제 disk(file system)에 있는 file을 읽어서 page에 작성한다.
그렇기 때문에 disk의 file을 어떻게 가져오고(mmap), 수정되었을 때 어떻게 변경하는지(mumap)가 가장 중요하다고 볼 수 있다.
mmap, munmap 이것들은 syscall이다.
Do 💩
이번 파트는 mmap(), munmap() 등을 구현하게 된다.
syscall.c, vm/file.c 두곳에서 작업해야하기 때문에 각자 입맛에 맞게 구현하면 좋을 것 같다.
우린 syscall에서 인자를 완성해서 주어주는게 편하다고 판단해서 인자를 재가공하는 과정을 syscall에 넣었다.
mmap()→ fd로 열린 파일의 length byte 만큼을, offset byte에서 시작하여 addr의 프로세스 가상 주소 공간으로 매핑
1. 파일 길이가 PGSIZE의 배수가 아닌 경우 남은 페이지 공간을 0으로 채우고,munmap이나swap out할때 다시 제거해야함
2. thread 구조체에mmap이 시작된 주소를 저장하는addr추가 →munmap시 사용(시작 주소부터 지워야하기 때문에)munmap()→ 지정된 주소 범위, addr에 대한 매핑을 해제
1. 파일이 변경되었다면 disk의 파일을 변경시켜야함
2. 파일에 대한 분리/독립적인 참조를 얻기 위해,file_reopen함수를 사용
3. page가공유페이지(shared)인지,사적 페이지(private)인지 지정해주는 인수 →Copy-on-wirte(opt)시 사용file_backed_initializer()→File-backed page를 초기화하고, 페이지 구조체에 일부 정보 (예: 메모리를 백업하는 파일)를 업데이트 해야함.
1.file page초기화.file_backed_destroy()→ 연결된 파일을 닫아file-backed page를 삭제
1. 파일이 변경되었으면 disk의 해당 파일에 적용
2. 페이지 구조체 free 안해줘도됨 →destroy 호출자가 해준다고하는데 아마vm_dealloc_page시 해줘서 그런 것 같음.
Problem ☠️
- page의 구조체 중
mumap시 사용하는is_writble이 업데이트가 되지 않았음.vm_alloc_with_initializer()에서uninit_new이후에 page 멤버의 값을 할당해야 했음.
- main()의
addr를 인자로 주는(main()의 주소에 page fault) tc가 있었는데 주소의 유효성을 검사하는 과정이 필요했음.→ 깃북에도 언급이 없었던 걸로 알고 있고, 이 부분만 한토스(p.319)를 참고했음.check_valid_buffer()를 구현해서 현재 쓰는 주소가 유효한지를 검사했음.
mmap-inherit는 부모와 자식이 파일을 상속받으면 안되는 것을 체크하는 tc였음.- file_type일 경우 file reopen 해서 file 복사해서 조건을 만족시켰음.
5. Swap In/Out

Why❔
보통의 tc에 사용하는 pintos의 메모리의 양은 20mb이다.(동기가 확인했고, 아마 최대 256mb까지 설정이 가능하다.)
그래서 pml4(page table)의 공간이 부족할 수 있는데 swap out을 통해 사용했던 page를 type에 따른 공간에 저장할 수 있다. 또한 swap in을 통해 저장했었던 page를 가져올 수도 있다.
이런 과정을 통해 20mb의 공간밖에 없지만 마치 무한한 공간을 사용하는 착각을 줄 수 있다.
Do 💩
이번 파트는 swap in&out, vm_get_victim(), check_valid_buffer() 등을 구현하게 된다.
check_valid_buffer()는 Git book에 없는 것으로 알고 있고, 한토스를 참고 했다.
vm_anon_init()→ 스왑 디스크를 설정하고, 스왑 디스크에서 사용 가능한 영역과 사용된 영역을 관리하기 위한 데이터 구조(swap table)가 필요함
1.swap disk를 초기화함
2.swap disk의 사이즈에 맞는swap table초기화anon_initializer()수정 → 스와핑을 지원하려면 anon page에 몇 가지 정보를 추가해야 함.
1.swap table의 idx를 추가함.
2.swap disk의 구현으로anon page의 파일 정보도 추가함.anon_swap_out()→ 메모리에서 disk로 내용을 복사하여anon page를swap disk로 스와핑함.frame table → swap disk
1.file page초기화.anon_swap_in()→swap disk의 데이터 내용을 읽어서anon page를(디스크에서 물리 메모리로) 스와핑함.swap disk → frame table
1. 인자의 page의swap table의 인덱스를 통해swap table에 있는swap slot을 찾는다.
2. page를물리 메모리(frame)에 복사함.file_backed_swap_out()→ 내용을 다시 파일에 기록하여swap out함.frame table → disk(file system)
1.file page가dirty(훼손됐는지)와 page가쓰기 권한(writable)이 있는지 확인한다
2.file page의dirty를 초기화 시켜주고 file에 변경사항을 적용시킨다.
3.file page를pml4(page table)에서 제거하고 구조체의 멤버를 초기화시킴.file_backed_swap_in()→ file system에서 콘텐츠를 읽어 kva 페이지에서swap in함.disk(file system) → frame table
1.disk(file system)에서 file을 읽어 물리 메모리에 올려준다.vm_get_victim()→frame table을 순회하면서 최근 접근하지 않은frame을희생자(victim)로 만든다. →clock 알고리즘
1.clock 알고리즘에서 모두가 최근에 사용하였을 때를 방지하기 위해서 2번 순회 한다.
2.frame table을 순회하면서 pml4 관련 함수를 통해 최근 접근했는지의 여부를 파악하고 접근하지 않았다면victim으로 선정한다.
3. 만약 접근하지 않았다면 접근여부를 바꿔주고, 한바퀴가 돌았을때도victim을 찾지 못할 수도 있기 때문에 한번 더 순회한다.check_valid_buffer()→buffer를 사용하는read()system call의 경우buffer의 주소가 유효한 가상주소인지 아닌지 검사
Problem ☠️
이번 파트는 시간에 쫓겨 기록하지 못했다ㅠㅠ
6. Copy on write(opt)

아침에 일어나서 봤던 팀원의 유언이었다..ㅋㅋㅋㅋ
우리 조는 copy on write(cow)를 마감 하루 전부터 구현하기 시작했는데 시간이 꽤 걸려서 cow 구현에는 중간에 빠져나와서 노선&블로그 정리를 선택했다.
그래도 cow를 왜 구현해야 하는지에 대해서 명확하게 이해했다고 생각해서 작성한다.
cow는 말 그대로 write 시에 copy 한다는 뜻이다.
일단 cow를 구현하기 시작하면 본래의 구조를 깨야 하는데 본래의 copy시에는 frame table까지 새로 만들어주었는데 이게 비효율적이기 때문에 새로 만드는 게 아닌 자식이 부모의 frame table를 가리킨다.
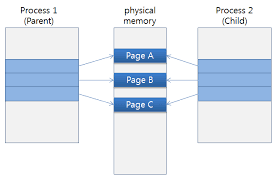
위의 그림을 보면 조금 이해가 될 것이라고 생각한다.
이제 가장 중요한 page를 작성했을 때(write)다.
자식이 부모의 frame을 사용하고 있는데 write하면 page fault를 발생시켜서 빈 페이지를 만들어 copy하고 변경사항을 작성한다. 즉, 새로운 frame을 만들고 각자도생한다.
끝으로 투머치 토크👍

매주 pintos를 진행하면서 쉬운적은 없었지만 특히 이번 Project3 VM은 너무 양이 많다.
그래서 내가 다시 Project3의 시작으로 가서 다른 사람들의 회고를 읽는 시점을 상상하며 과거의 나에게 쓰는 글이다.
이 글을 읽는 사람 모두가 피나는 노력을 하고 있다고 생각하기 때문에 pintos의 끝까지 포기하지 않고 도전했으면 좋겠다.
내가 요새 가장 좋아하는 말로 이 글을 마무리 하려 한다.
중요한 것은 꺾이지 않는 마음이다.하지만 나를 포함한 많은 동기들이 몸이 꺾였다....
- merge tc 들은 정말 모두를 힘들게 했다. 혹시 힘들어하고 있다면 copy on write(opt)를 구현하면 좀 완화된다는 말을 동기한테 들었다.
merge tc들이 터지는 이유는 race condition에 관한 것인데 vm을 구현하면서 공유 자원을 읽고, 쓰거나 하는 경우가 유난히 많기 때문이다. 코치님께서는 현업에서는 race condition이 있는 것 자체가 문제라고 말씀하셨다.(race condition이 많다는 것 자체가 불안한 프로그램이므로) 도전하는 것도 좋지만 안되더라도 너무 낙담하지 않았으면 좋겠다. - 어떤 problem이 있을 때 적어놓고, 어떻게 해결했는지를 적어놓는게 기억에 많이 남았다.
- 양이 생각보다 너
~무 많다. 스케줄을 타이트하게 짜는 것도 좋겠다. - 코치님께서는 다른 프로젝트와는 다르게 이번 프로젝트 3은 csapp 등의 책을 참고하는 것이 도움이 안 될 수도 있다고 하셨다.
하지만 우리 조는 csapp나 ostep을 읽고 이해하는데 큰 도움을 받았다.
아마 코치님께서는 양이 많아서 빨리 구현하라는 말씀이셨던 것 같다. - 이번 vm은 특히 구현할게 너무나도 많다. 구현하는 것에 대해 명확하게 이해하고 넘어가면 좋은 것 같다.
- 나는 원래 돌아다니면서 이야기하며 생각을 많이 주고받는 편인데, 이번에는 여유가 없어 마지막쯤 돌아다녔는데 내가 잘못 생각한 부분이나 배운 점이 정말 많았다. 팀(3명)으로 이루어져 진행하기 때문에 충분히 이야기했다고 생각했는데 아니었다.
- project3의 git book은 정말 친절한
대학원생분이 작성하셨는지 git book만 보고도 충분히 구현하는데 어려움이 없다. 하지만 버퍼 유효성 검사 부분은 한토스를 참고하자.. - 가장 중요한 것을 마지막으로 당부한다. 정답 코드를 안봤으면 좋겠다.
앞에서 말했듯이 양이 정말 많아서 정답 코드를 볼 수도 있을 것 같다. 하지만 이 부분은 정말 지양했으면 좋겠다. 그 이유는 시행착오 끝에 배우는 게 많이 남기 때문이다.
우리의 목표는 pintos의 완성도 중요하지만, 그 과정에서 배움이 가장 중요하다고 생각한다.

중꺾마..