CPU는 기억장치에 저장되어 있는 프로그램 코드인 명령어들을 실행함으로서 프로그램 수행이라는 컴퓨터의 기본적인 기능을 수행하는데, 그를 위하여 CPU가 수행해야 하는 세부적인 동작들을 순서대로 나열하면 다음과 같음.
(1) 명령어 인출 : 기억장치로부터 명령어를 읽어옴
(2) 명령어 해독 : 수행해야 할 동작을 결정하기 위하여 명령어를 해독함
(3) 데이터 인출 : 명령어 실행을 위하여 데이터가 필요한 경우에는 기억장치 혹은 I/O 장치로부터 그 데이터를 읽어옴
(4) 데이터 처리 : 데이터에 대한 산술적 혹은 논리적 연산을 수행함
(5) 데이터 저장 : 수행한 결과를 저장함
위의 동작들 중에서 첫 번째 및 두 번째 동작은 모든 명령어들에 대하여 공통적으로 수행되지만, 세 번째부터 다섯 번째까지의 동작들은 명령에 따라 필요한 경우에만 수행됨.
2.1 CPU의 기본 구조
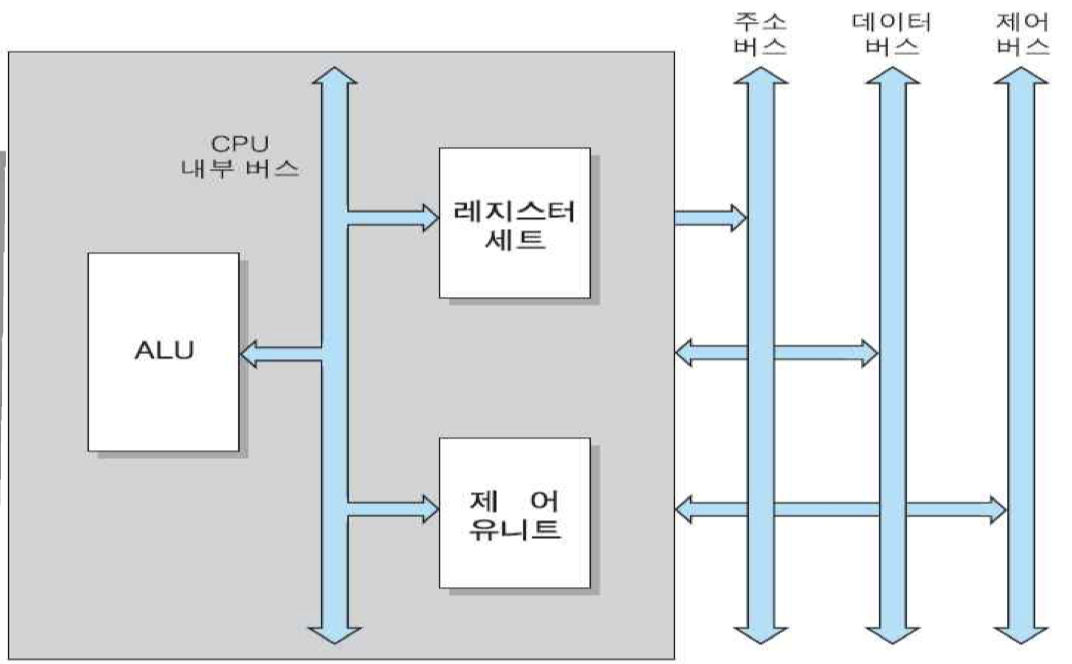
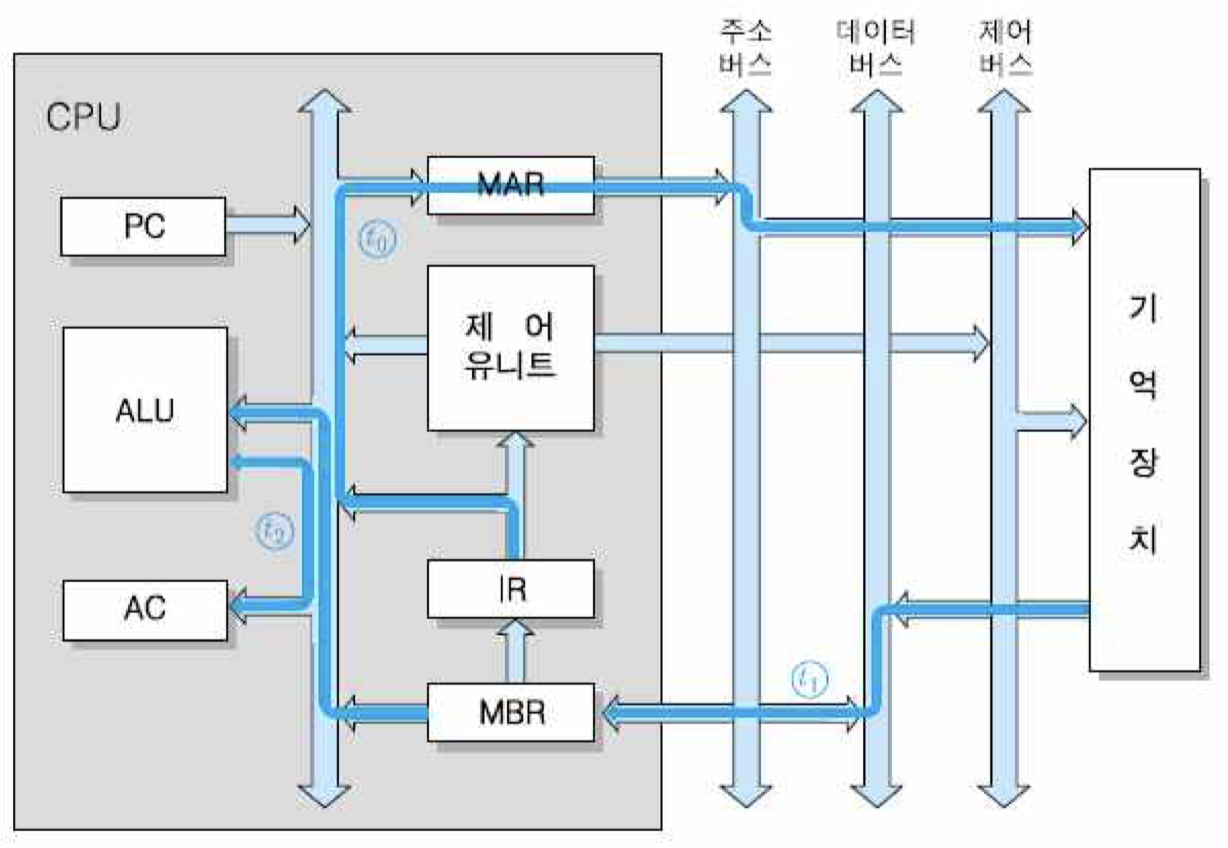
CPU는 그림과 같은 내부 구성 요소들로 이루어져 있음. 즉, CPU는 산술논리연산장치(ALU)와 레지스터 세트 및 제어 유니트로 구성됨.
ALU : 산술 및 논리 연산들을 수행하는 회로들로 이루어진 하드웨어 모듈
산술 연산 : 덧셈, 뺄셈, 곱셈 및 나눗셈
논리 연산 : AND, OR, NOT
레지스터 : CPU 내부 기억장치로서 액세스 속도가 기억장치들 중에서 가장 빠름
제어 유니트 : 인출된 명령어를 해독하고, 그 실행을 위한 제어 신호들을 순차적으로 발생하는 하드웨어 모듈
CPU 내부 버스 : CPU 내부 구성요소들 간의 정보 전송 통로
2.2 명령어 실행
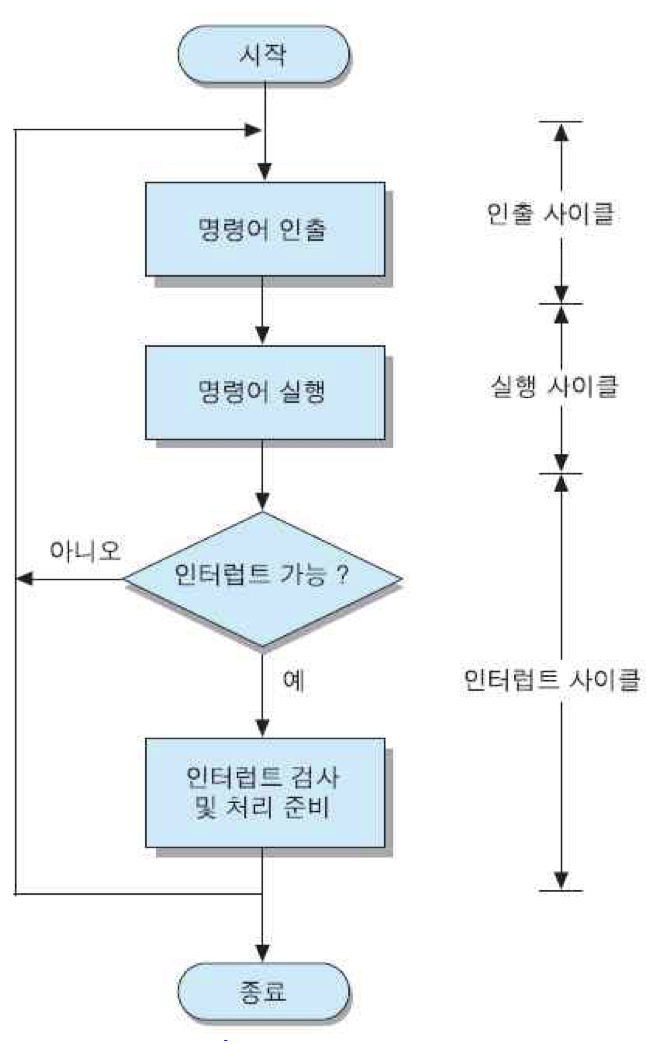
명령어 사이클 : 한 명령어를 실행하는데 필요한 전체 과정으로서, 명령어 인출 단계와 명령어 실행 단계로 나누어짐
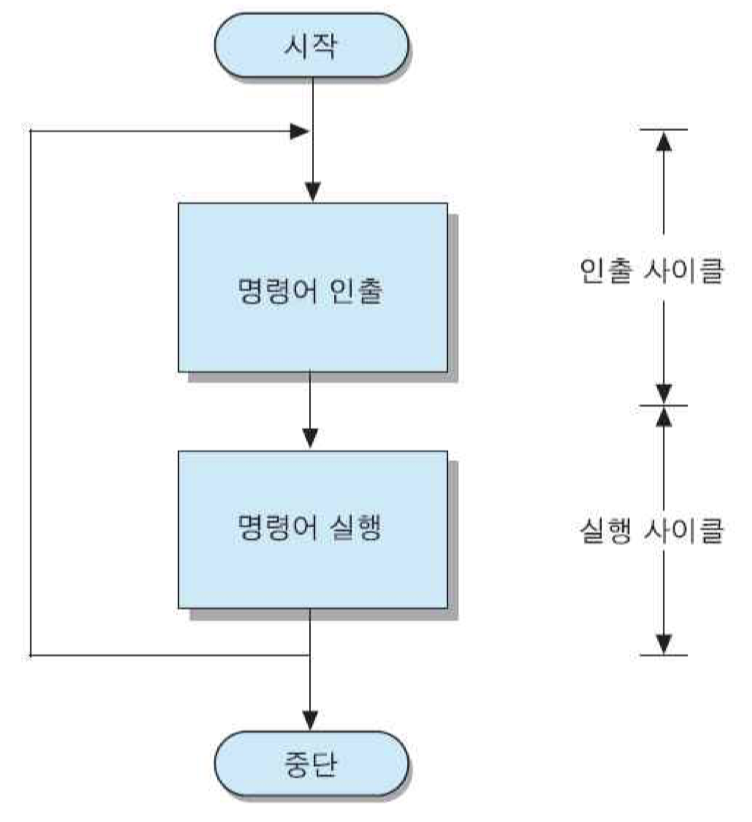
위 그림은 그 두 단계를 각각 부사이클로 구분하여 명령어 사이클의 흐름도를 나타낸 것인데, 그 부사이클들은 각각 인출 사이클과 실행 사이클이라고 부름. 명령어 사이클은 CPU가 프로그램 실행을 시작한 순간부터 전원을 끄거나 회복 불가능한 오류가 발생하여 중단될 때까지 반복하여 수행됨.
명령어를 실행하기 위하여 기본적으로 필요한 CPU 내부 레지스터
• 프로그램 카운터(PC) : 다음에 인출될 명령어의 주소를 가지고 있는 레지스터. 각 명령어가 인출된 후에는 그 내용이 자동적으로 1이 증가되며, 분기 명령어가 실행되는 경우에는 그 목적지 주소로 갱신됨.
• 누산기(AC) : 데이터를 일시적으로 저장하는 레지스터. 이 레지스터의 비트 수는 CPU가 한 번에 연산 처리할 수 있는 데이터 비트의 수, 즉 단어 길이와 같음.
• 명령어 레지스터(IR) : 가장 최근에 인출된 명령어가 저장되어 있는 레지스터.
• 기억장치 주소 레지스터(MAR) : 프로그램 카운터에 저장된 명령어 주소가 시스템 주소 버스로 출력되기 전에 일시적으로 저장되는 주소 레지스터. 즉, 이 레지스터의 출력 선들이 주소 버스 선들과 직접 접속됨.
• 기억장치 버퍼 레지스터(MBR) : 기억장치에 저장될 데이터 혹은 기억장치로부터 읽혀진 데이터가 일시적으로 저장되는 버퍼 레지스터. 이 레지스터의 입력 및 출력 선들은 데이터 버스 선들과 직접 접속됨.
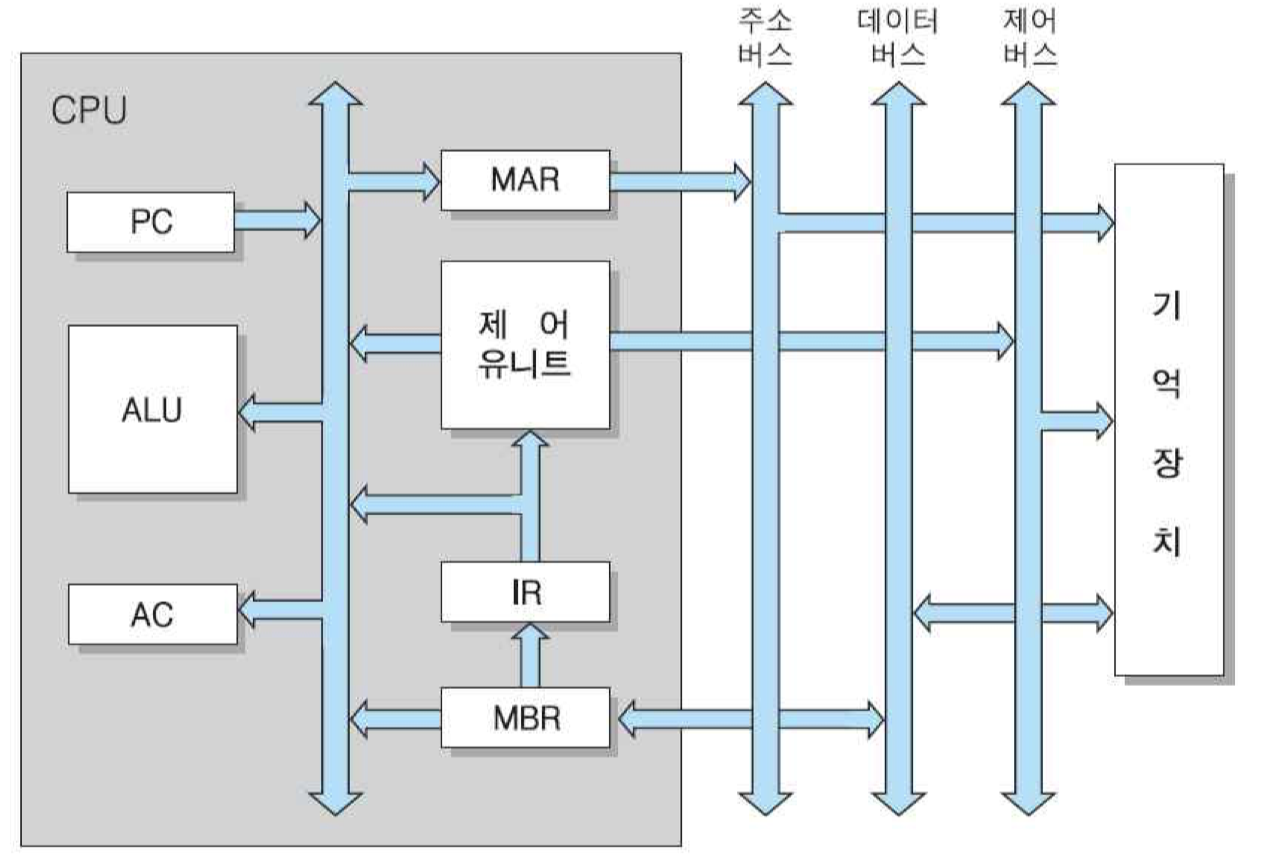
기억장치로부터 인출된 명령어는 MBR을 경유하여 IR에 저장되며, 실행 사이클에서 제어 유니트로 보내져 해독됨. MAR은 CPU 내부 주소 버스와 시스템 주소 버스 사이에서 버퍼 역할을 하는 레지스터이며, MBR은 데이터에 대하여 같은 역할을 하는 버퍼 레지스터임. 기억장치로부터 인출된 데이터는 MBR을 통하여 AC로 적재됨. 만약 명령어가 그 데이터에 대하여 산술 혹은 논리 연산을 수행하는 것이라면, AC의 내용이 ALU로 보내짐. 그리고 ALU의 연산 결과는 다시 AC에 저장됨.
2.2.1 인출 사이클
인출 사이클 : CPU가 기억장치의 지정된 위치로부터 명령어를 읽어오는 과정
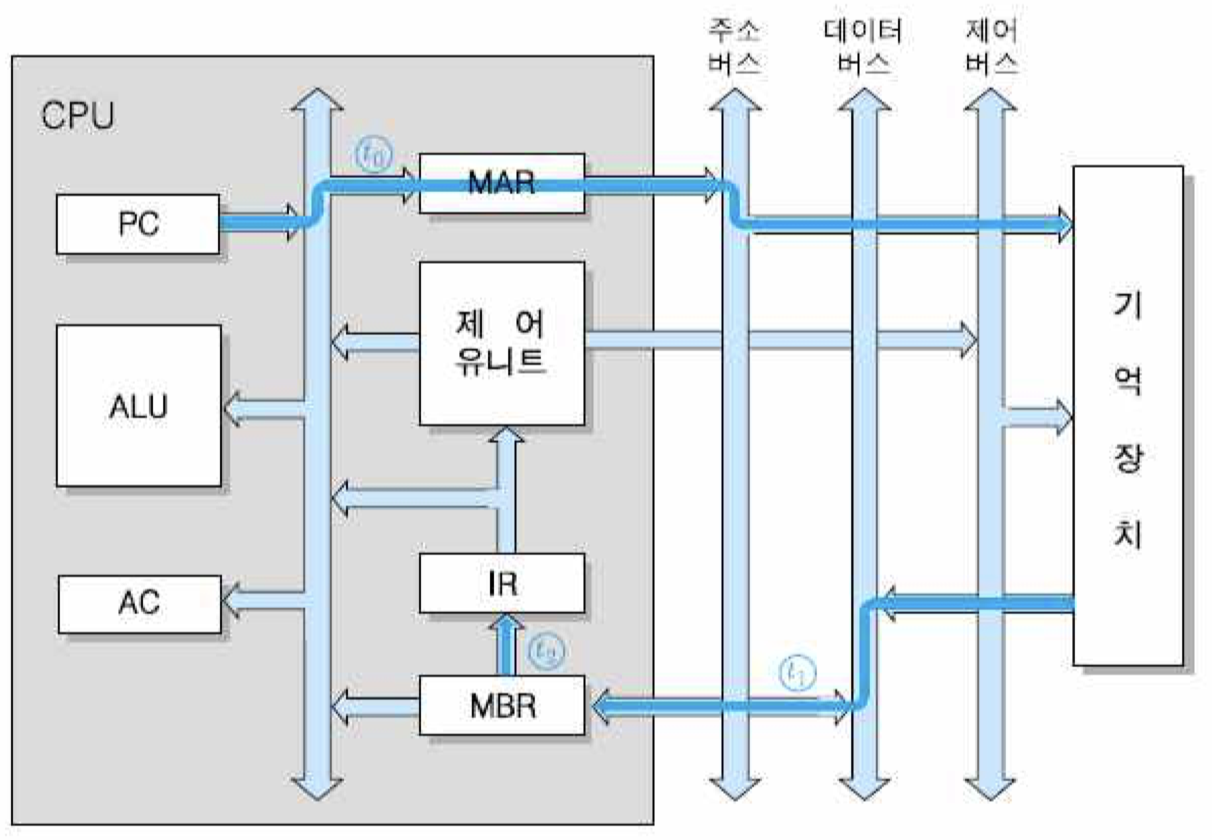
마이크로-연산 : CPU 콜록의 각 주기 동안 수행되는 기본적인 동작

t0, t1 및 t2는 CPU 클록의 각 주기를 가리킴. 즉, 명령어 인출에는 세 개의 CPU 클록 주기만큼의 시간이 걸림. 위의 마이크로-연산에서 보는 바와 같이, 인출 사이클에서 가장 먼저 수행되는 동작은 현재의 PC 내용을 CPU 내부 버스를 통하여 MAR로 보내는 것임. 그렇게 되면, 시스템 주소 버스와 직접 접속된 MAR을 통하여 주소가 기억 장치로 전송됨.
두 번째 주기에서는 그 주소가 지정하는 기억장치 위치로부터 읽혀진 명령어가 데이터 버스를 통하여 MBR로 적재되며, 그와 동시에 PC의 내용에 1을 더하여 다음 명령어의 주소를 가리키게 함. 만약 이 컴퓨터에서 각 기억장치 주소가 바이트 단위로 지정되고 명령어 길이는 16비트라면, 한 명령어는 두 개의 주소에 걸쳐 저장되어 있게 됨. 따라서 이 경우에는 한 명령어를 읽은 다음에 PC의 내용에 2를 더해야 다음 명령어가 저장된 위치를 지정할 수 있게 됨.
마지막 세 번째 주기에서는 MBR에 저장되어 있는 명령어 코드가 명령어 레지스터인 IR로 이동됨. 그림은 인출 사이클 동안에 주소와 명령어 코드가 이동하는 과정을 보여고 있음. 그림에서 원으로 표시된 기호들은 각 동작이 발생하는 클록의 주기를 나타냄.
2.2.2 실행 사이클
실행 사이클 : CPU가 명령어를 해독하고, 그 결과에 따라 필요한 연산들을 수행하는 과정
• 데이터 이동 : CPU와 기억장치 간 혹은 CPU와 I/O 장치 간에 데이터를 이동
• 데이터 처리 : 데이터에 대하여 산술 혹은 논리 연산을 수행
• 데이터 저장 : 연산결과 데이터 혹은 입력장치로부터 읽어들인 데이터를 기억장치에 저장
• 프로그램 제어 : 프로그램의 실행 순서를 결정
실행 사이클에서 수행되는 마이크로-연산들은 명령어의 종류에 따라 서로 달라지므로, 여기서는 위의 각 분류에 해당하는 명령어를 한 개씩 예를 들어 설명하기로 함. 명령어는 아래와 같이 CPU가 수행할 연산을 지정해주는 연산 코드와 그 연산의 수행에 필요한 오퍼랜드로 구성되며, 오퍼랜드는 명령어가 사용할 데이터가 저장되어 있는 기억장치의 주소를 가리킨다고 가정.

실행 사이클에서 첫 번째로 수행해야 할 연산은 IR에 저장된 명령어의 오퍼랜드, 즉 addr를 MAR을 통해 기억장치로 보내어 데이터를 인출하는 것임. 먼저, 첫 번째 연산 분류인 데이터 이동을 위한 명령어의 한 예로서 'LOAD addr'명령어의 경우를 살펴보면, 이 명령어는 기억장치에 저장되어 있는 데이터를 CPU 내부 레지스터인 AC로 적재하게 되는데, 그러한 동작을 위하여 실행 사이클 동안에 수행되어야 하는 마이크로-연산들을 보면 다음과 같음.

첫 번재 주기에서는 명령어 레지스터 IR에 적재된 명령어의 오퍼랜드인 주소를 MAR를 통하여 기억장치로 보냄. 두 번째 주기에서는 그 주소가 지정하는 기억 장소로부터 데이터를 인출하여 MBR에 저장하며, 그 데이터를 세 번째 주기 동안에 AC 레지스터에 적재함으로써 LOAD 명령어의 실행이 완료됨.
두 번재 분류인 데이터 저장을 위한 명령어의 예로서, AC 레지스터의 내용을 기억장치에 저장하기 위한 'STA addr'명령어의 실행 사이클은 다음과 같은 마이크로-연산들로 이루어짐.

여기서도 첫 번째 주기에서는 데이터를 저장할 기억 장소의 주소를 MAR로 보냄. 다음 주기에서는 저장할 데이터를 버퍼 레지스터인 MBR로 이동시킴. 결과적으로, 주소와 데이터가 모두 기억장치로 보내짐. 마지막 세 번째 주기에서는 그 주소가 지정하는 기억 장소에 데이터가 저장됨.
세 번째 분류인 데이터 처리를 위한 명령어의 예로서, 기억장치에 저장된 데이터를 AC 레지스터의 내용과 더하고, 그 결과를 다시 AC 레지스터에 저장하는 'ADD addr'명령어의 마이크로-연산들은 다음과 같음.

이 명령어의 경우에는 첫 번재 주기 동안에 명령어의 오퍼랜드를 주소 버스를 통하여 기억장치로 보내고, 두 번재 주기에서 해당 기억 장소로부터 데이터를 인출하여 MBR에 적재함. 그리고 세 번째 주기에서 그 데이터와 AC 레지스터의 내용을 더하고, 결과값을 다시 AC 레지스터에 저장함. 밑의 그림은 명령어의 실행 과정에서 주소와 데이터가 이동되는 경로와 각 마이크로-연산이 수행되는 클록 주기를 보여주고 있음.
일반적으로 명령어들은 기억장치에 저장되어 있는 순서대로 실행됨. 그런 경우에는 명령어 실행 순서를 결정하기 위하여 별도의 명령어가 필요하지 않고, 프로그램 카운터에 의해 자동적으로 순서가 결정됨. 그러나 그와 같은 순차적 실행이 아닌, 전혀 다른 위치에 있는 명령어를 실행해야 하는 경우도 있음. 그와 같이 프로그램 수행 순서를 조정해주는 동작을 위하여, 현재의 PC 내용이 가리키는 위치가 아닌 다른 위치의 명령어를 실행 순서를 바꾸도록 해주는 명령어들이 있음. 이러한 명령어들을 분기 명령어라고 부르는데, 한 예가 되는 'JUMP addr'명령어는 다음과 같이 한 주기 만에 실행이 완료됨.
즉, 이 명령어에 포함된 오퍼랜드는 분기 목적지 주소를 가리키기 때문에, 실행 사이클에서는 그 주소를 PC로 적재하기만 하면 됨. 그렇게 되면, 다음 명령어 인출 사이클에서는 그 주소가 가리키는 기억 장소로부터 명령어가 인출되므로, 명령어 실행 순서가 바귀게 되는 것임.
2.2.3 인터럽트 사이클
인터럽트 : CPU로 하여금 현재 진행중인 프로그램 처리를 중단하고 다른 프로그램을 처리하도록 요구하는 메커니즘으로서, CPU와 외부장치들 간의 상호작용을 위하여 필요한 기능
인터럽트 서비스 루틴(ISR) : 인터럽트 요구를 처리해주기 위해 수행하는 프로그램 루틴
CPU는 인터럽트 요구가 들어오면 그것을 인식할 수 있어야 하며, 어떤 장치가 인터럽트를 요구하였는지 확인하여 해당 인터럽트 서비스 루틴을 수행하고, 중단하였던 원래 프로그램의 수행을 계속할 수 있어야 함. 그를 위하여 CPU는 각 명령어의 실행 사이클을 종료하고 다음 명령어를 위한 인출 사이클을 시작하기 전에, 인터럽트 요구 신호가 들어와서 대기 중인지 검사해야 함. 만약 인터럽트 요구가 들어왔다면, CPU는 아래와 같은 동작들을 수행함.
① 다음에 실행할 명령어의 주소를 가리키는 현재의 PC 내용을 스택에 저장함. 이것은 인터럽트 처리를 완료한 후에 복귀할 주소를 저장해두기 위한 절차임.
② 해당 인터럽트 서비스 루틴을 호출하기 위하여 그 루틴의 시작 주소를 PC에 적재함. 이때 시작 주소는 인터럽트를 요구한 장치로부터 전송되거나 미리 정해진 값으로 결정됨.
인터럽트 사이클 : 인터럽트 요구가 들어왔는지 검사하고, 그 처리에 필요한 동작들을 수행하는 과정
인터럽트 요구가 들어온 경우에, 인터럽트 사이클 동안 수행되는 동작들을 마이크로-연산으로 표현

스택 포인터(SP) : 스택의 최상위 주소를 저장하고 있는 레지스터
인터럽트 사이클의 첫 번째 주기에서는 PC의 내용이 MBR로 보내짐. 두 번째 주기에서는 SP의 내용이 MAR을 통하여 주소 버스로 나가게 되며, PC에는 인터럽트 서비스 루틴의 시작 주소가 적재됨. 마지막 주기에서는 MBR에 저장되어 있던 원래의 PC 내용을 스택에 저장하며, 동시에 SP의 내용을 1 감소시켜 TOS의 주소를 수정함.
이제 인터럽트 사이클이 종료되어 다음 인출 사이클이 시작되면, CPU는 인터럽트 서비스 루틴의 첫 번째 명령어부터 인출하면서 인터럽트 요구에 대한 서비스를 시작하게 됨.
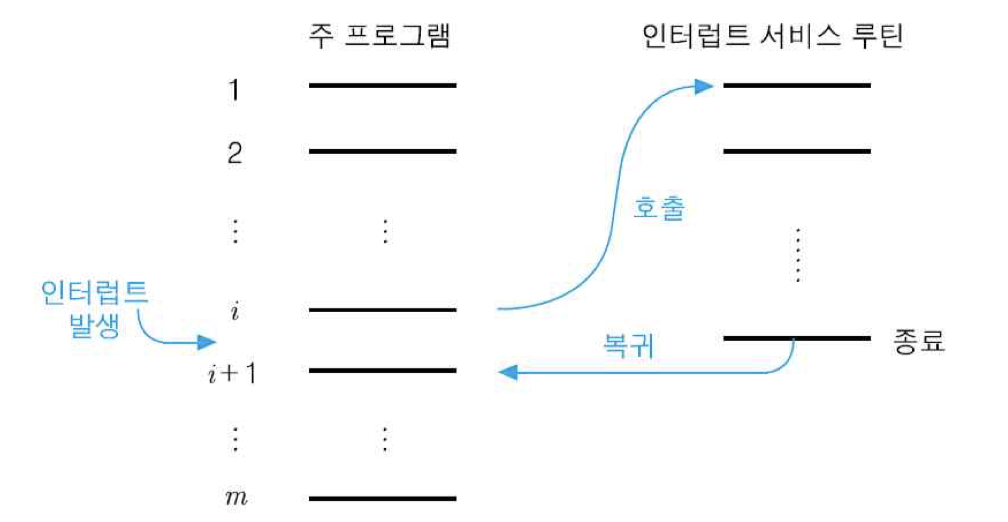
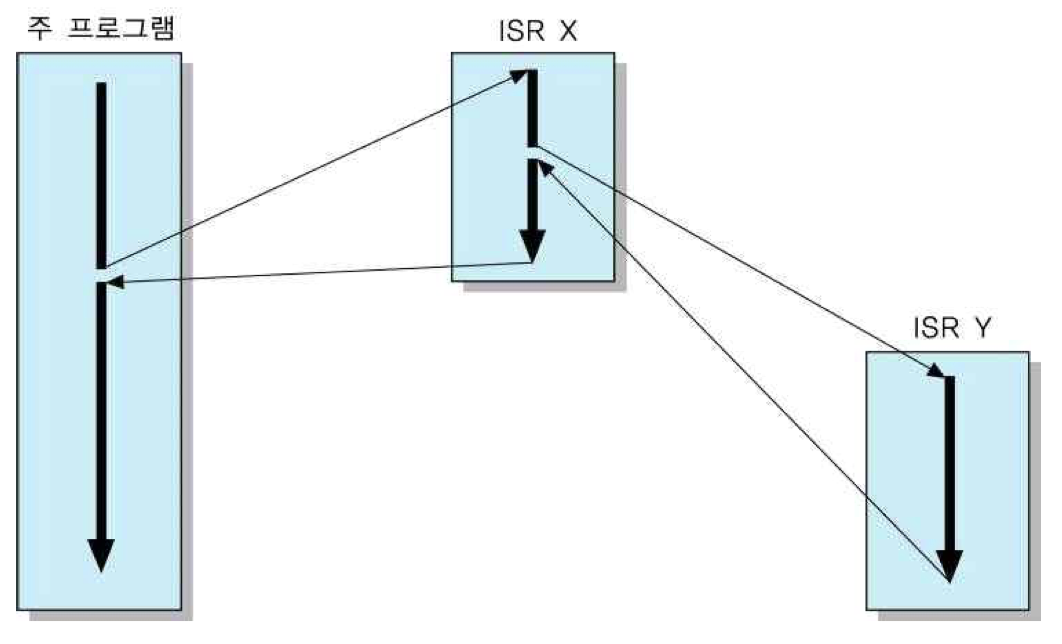
다중 인터럽트 : 인터럽트 서비스 루틴을 수행하고 있는 동안에 다른 장치로부터 인터럽트가 들어오는 경우
다중 인터럽트를 처리하는 방법으로는 두 가지가 있음
첫 번째 방법은 CPU가 인터럽트 서비스 루틴을 처리하고 있는 도중에는 새로운 인터럽트 요구가 들어오더라도 인터럽트 사이클을 수행하지 않는 것임. 즉, 앞에서 설명한 바와 같이 인터럽트 불가능 상태일때는 CPU가 인터럽트 요구 신호를 검사하지 않도록 함. 이렇게 되면, 그 루틴을 처리하는 동안에 발생한 인터럽트 요구는 대기 상태로 남아 있다가, CPU가 다시 인터럽트 가능 상태로 바뀐 후에 인식됨.
두 번째 방법은 인터럽트 요구들 간에 우선순위를 정하고, 우선순위가 낮은 인터럽트 요구를 처리하고 있는 동안에 우선순위가 더 높은 인터럽트 요구가 들어오면, 현재의 인터럽트 서비스 루틴의 수행을 중단하고 새로운 인터럽트를 처리하도록 하는 것. 이 경우에 PC의 내용을 저장하고 갱신하는 절차는 앞에서 설명한 단일 인터럽트의 경우와 동일함. 그러나 스택에는 원래의 주 프로그램으로 복귀하기 위한 주소뿐 아니라, 첫 번재 인터럽트 서비스 루틴으로 복귀하는데 사용될 주소도 저장되어야 함.
밑의 그림은 다중 인터럽트에서 프로그램이 실행되는 순서임.
2.2.4 간접 사이클
간접 사이클 : 실행 사이클에서 사용될 데이터의 실제 주소를 기억장치로부터 읽어오는 과정
간접 사이클에서는 다음과 같은 마이크로-연산들이 수행됨. 즉, 인출 사이클에서 읽혀져 IR에 적재되어 있는 명령어의 주소 필드 내용을 다시 기억장치로 보내어서, 데이터의 실제 주소를 인출하여 IR의 주소 필드에 저장함.

2.3 명령어 파이프라이닝
명령어 파이프라이닝 : 명령어 실행에 사용되는 하드웨어를 여러 단계로 분할함으로써 처리 속도를 높여주는 기술
2.3.1 2-단계 명령어 파이프라인
명령어 사이클은 기본적으로 인출 사이클과 실행 사이클이라는 두 개의 단계로 이루어짐. 그런데 이들 각 사이클의 동작을 처리하는 하드웨어를 독립적인 모듈로 구성할 수 있다면, 각 모듈이 서로 다른 명령어를 동시에 처리할 수 있을 것임. 즉, 명령어를 실행하는 하드웨어를 인출 단계와 실행 단계라는 두 개의 파이프라인 단계들로 분리하여 구성할 수 있음.
그런 다음에 두 파이프라인 단계들에 하나의 클록 신호를 동시에 인가한다면, 그 단계들의 동작 시간을 일치시킬 수 있음. 그리고 각 단계는 서로 다른 명령어에 대하여 각자의 동작을 수행할 수 있게 됨. 즉, 첫 번째 클록 주기 동안에 인출 단계가 첫 번째 명령어를 인출함. 그리고 두 번째 주기에서는 그 명령어가 실행 단계로 보내어져 처리되며, 그와 동시에 인출 단계는 두 번째 명령어를 인출함. 이 주기 동안에 실행 단계에서 처리될 명령어는 첫 번째 클록 주기 동안에 미리 인출되었기 때문에, 두 번째 클록 주기가 시작되는 즉시 실행이 시작될 수 있는 것임. 이와 같이, 다음에 실행될 명령어를 미리 인출하는 것을 명령어 선인출 혹은 인출 중복이라고 함.
세 번째 클록 주기에서는 두 번째 명령어의 실행과 세 번째 명령어의 인출이 동시에 이루어지는데, 이러한 동시 처리는 그림의 시간 흐름도에서 보는 바와 같이 연속적인 명령어들에 대하여 계속 적용될 수 있음. 이와 같이 명령어 실행 하드웨어를 두 단계로 분리시킨 것을 2-단계 명령어 파이프라인이라고 부름.
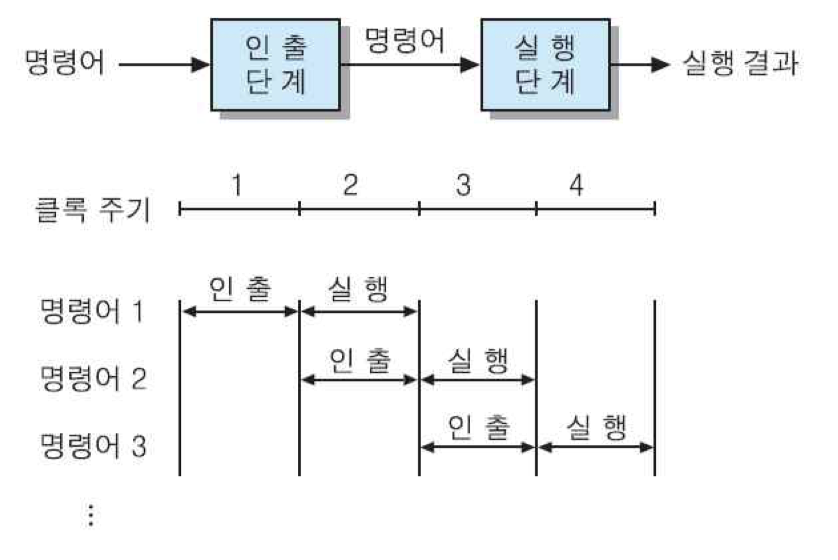
명령어 파이프라이닝을 이용하여 속도 향상을 얻을 수 있는 원리는 다음과 같음. 그림에서 보는 바와 같이 첫 번째 명령어의 실행은 두 클록 주기만에 종료되지만, 두 번째 명령어는 그 때부터 한클록 후에 실행이 완료됨. 그리고 세 번째 및 네 번째 명령어들도 각각 한 주기씩만 지나면 실행이 종료됨.
2-단계 파이프라인을 이용함으로써 얻게 되는 속도향상은 1.5배가 된다.
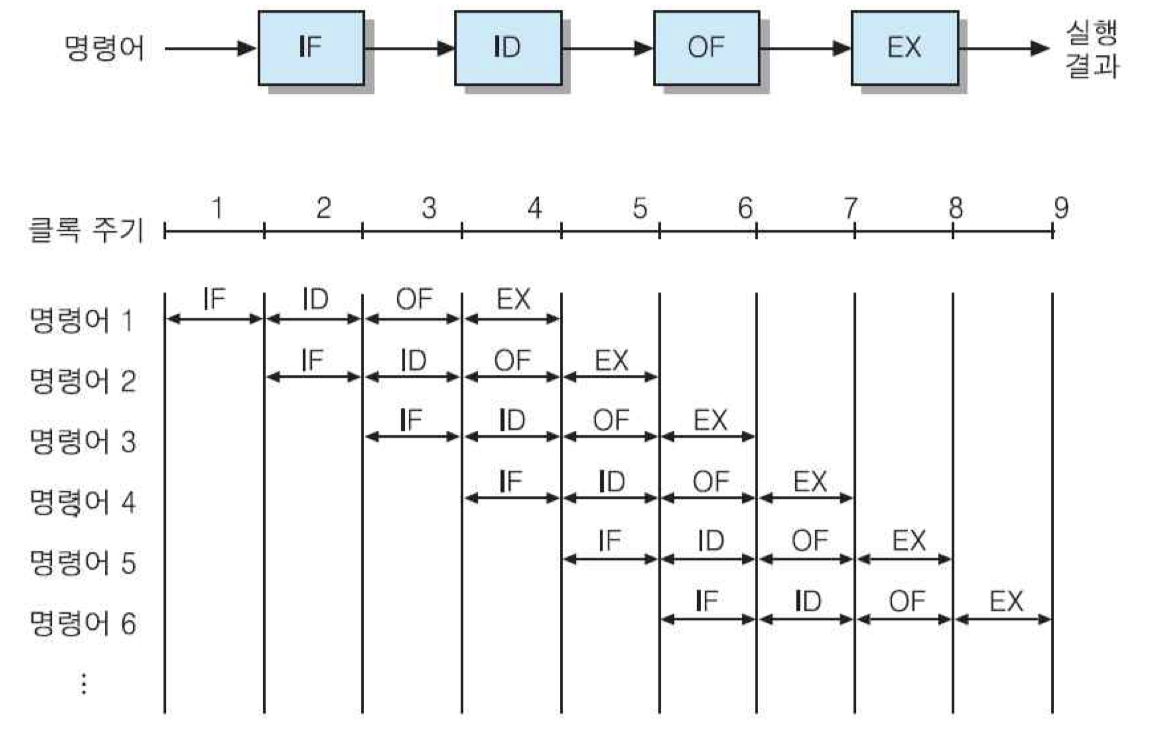
2.3.2 4-단계 명령어 파이프라인
파이프라인을 네 단계로 구성하는 경우
• 명령어 인출(IF) : 명령어를 기억장치로부터 인출
• 명령어 해독(ID) : 해독기를 이용하여 명령어를 해석
• 오퍼랜드 인출(OF) : 기억장치로부터 오퍼랜드를 인출
• 실행(EX) : 지정된 연산을 수행하고, 결과를 저장
4-단계 명령어 파이프라인으로 구성하면, 각 단계에서 걸리는 시간들이 거의 같아질 수 있음.
파이프라인 단계 수 = k
실행할 명령어들의 수 = N
각 파이프라인 단계는 한 클록 주기씩 걸린다고 가정함.
T = k + (N - 1)
즉, 첫 번째 명령어를 실행하는 데는 k 주기가 걸리고, 나머지 (N - 1) 개의 명령어들은 각각 한 주기씩만 소요됨. 만약 파이프라인이 되지 않았다면 N개의 명령어들을 실행하는 데는 k x N 주기가 걸리므로, 파이프라이닝을 이용함으로써 얻을 수 있는 속도 향상은 다음과 같아짐.
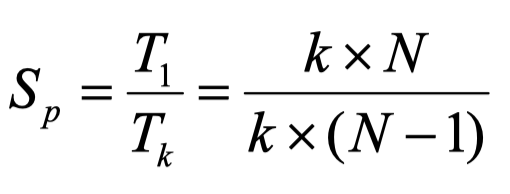
기억장치 충돌 : 두 개 이상의 하드웨어 모듈들이 동시에 기억장치 액세스를 시도하는 상황
조건 분기 명령어 : 지정된 조건이 만족하는 경우에는 프로그램 처리 순서를 변경하는 명령어
조건 분기가 존재하는 경우의 시간 흐름도
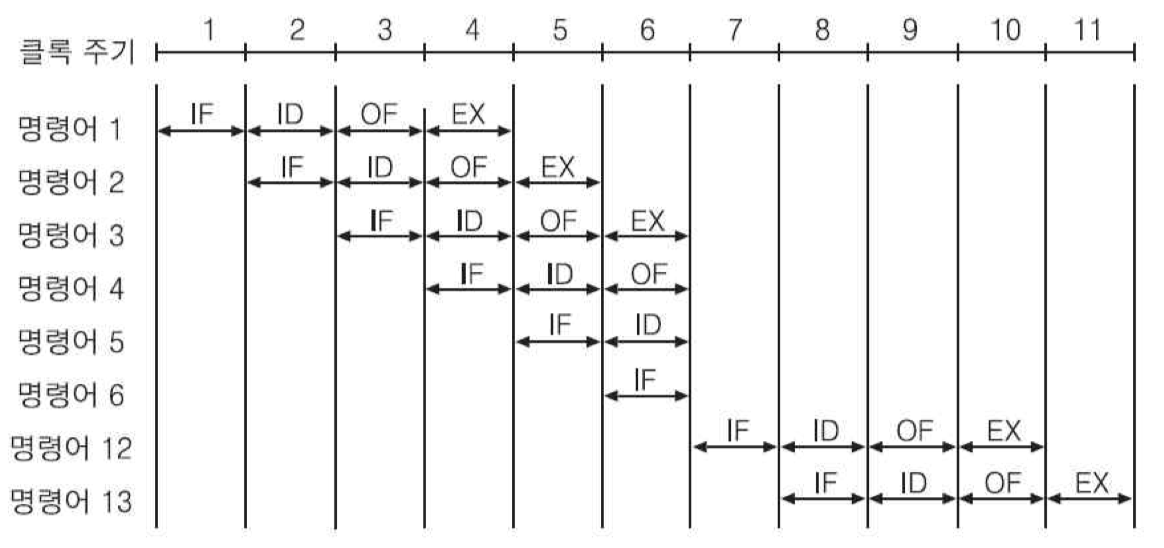
슈퍼파이프라이닝 : 명령어 파이프라인의 단계들을 더욱 작게 분할하여 처리 속도를 높여주는 기술
분기 발생에 의한 성능 저하의 최소화 방법
• 분기 예측 : 분기가 일어날 것인지를 예측하고, 그에 따라 어느 경로의 명령어를 인출할 지를 결정하는 확률적 방법
• 분기 목적지 선인출 : 조건 분기가 인식되면, 분기 명령어의 다음 명령어 뿐만 아니라, 조건이 만족될 경우에 분기하게 될 목적지의 명령어도 함께 인출하는 방법
• 루프 버퍼 : 파이프라인의 명령어 인출 단계에 포함되어 있는 작은 고속 기억장치인 루프 버퍼에 가장 최근 인출된 n개의 명령어들을 순서대로 저장해두는 방법
• 지연 분기 : 분기 명령어의 위치를 재배치함으로써 파이프라인의 성능을 개선하는 방법
상태 레지스터 : 연산처리 결과(부호, 올림수 등) 및 시스템 상태를 가리키는 비트들을 저장하는 레지스터
플래그 : 각 조건의 상태를 나타내는 비트
상태 레지스터에 포함된 조건 플래그들

부호(S) 플래그 : 직전에 수행된 산술연산 결과값의 부호 비트를 저장(양수: 0, 음수: 1)
영(Z) 플래그 : 연산 결과값이 0 이면, 1로 세트
올림수(C) 플래그 : 덧셈이나 뺄셈에서 올림수(carry)나 빌림수 (borrow)가 발생한 경우에 1로 세트
동등(E) 플래그 : 두 수를 비교한 결과가 같게 나왔을 경우에 1로 세트
오버플로우(V) 플래그 : 산술 연산 과정에서 오버플로우가 발생한 경우에 1로 세트
인터럽트(I) 플래그
인터럽트 가능(interrupt enabled) 상태이면, 0으로 세트
인터럽트 불가능(interrupt disabled) 상태이면, 1로 세트
슈퍼바이저(P) 플래그 :
CPU의 실행 모드가 슈퍼바이저 모드(supervisor mode)이면, 1로 세트
사용자 모드(user mode)이면, 0으로 세트
2.3.3 슈퍼스칼라
슈퍼스칼라 : CPU 내에 여러 개의 명령어 파이프라인들을 두어, 동시에 그 수만큼의 명령어들을 실행할 수 있도록 한 구조
2-way 슈퍼스칼라 : 두 개의 파이프라인들로 이루어진 구조
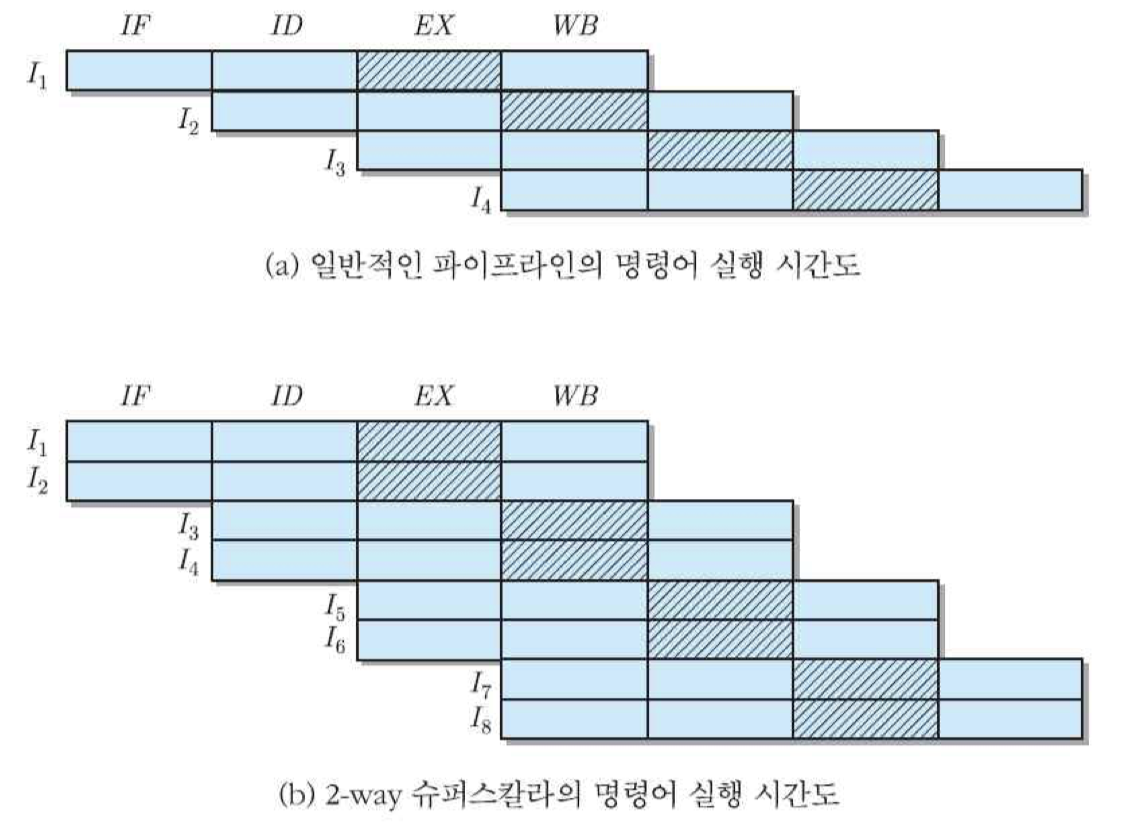
2-way 슈퍼스칼라 프로세서에서 유의할 점으로는 동시에 처리할 명령어들이 서로 간에 영향을 받지 않고 독립적으로 실행될 수 있어야 한다는 것. 즉, 두 명령어들 사이에 데이터 의존성이 존재하지 않아야 그들을 동시에 실행할 수 있음. 그러한 조건이 만족된다면, 이 슈퍼스칼라의 명령어 실행 속도는 하나의 명령어 파이프라인에 비하여 두 배가 될 수 있음.
데이터 의존성 : 한 명령어를 실행한 다음에, 그 결과값을 보내주어야 다음 명령어의 실행이 가능한 관계
단일 파이프라인에 의한 실행 시간
T(1) = k + N - 1
m-way 슈퍼스칼라에 의한 실행 시간
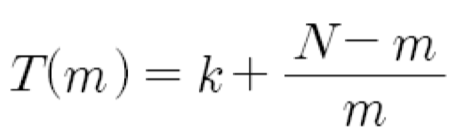
속도 향상
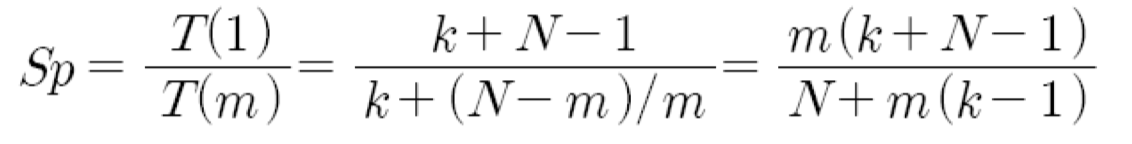

실행되는 명령어들의 수가 매우 많아진다면, 속도 향상은 명령어 파이프라인의 수인 m배에 접근함.
2.3.4 듀얼-코어 및 멀티 코어
최근 반도체 제조 기술이 계속 발전하여 하나의 프로세서 칩에 더 많은 수의 회로들을 집적시킬 수 있게 됨에 따라, 한 칩에 두 개 혹은 그 이상의 CPU 코어들을 포함시킬 수 있게 됨.
CPU 코어 : CPU 칩의 내부회로 중에서 명령어 실행에 반드시 필요한 핵심 부분들로 이루어진 하드웨어 모듈
멀티-코어 프로세서 : 여러 개의 CPU 코어들을 포함하고 있는 프로세서 칩
듀얼-코어 프로세서 : 두 개의 CPU 코어들을 넣은 프로세서 칩
쿼드-코어 프로세서 : 네 개의 CPU 코어들을 넣은 프로세서 칩
이들은 칩-레벨 다중프로세서 혹은 단일-칩 다중프로세서라고 불리기도 함.
듀얼-코어 프로세서의 각 CPU 코어는 앞에서 설명한 슈퍼스칼라 구조로 구성되기 때문에, 그러한 코어 두 개를 한 칩에 포함시키면 두 배 더 빨라질 것으로 기대할 수 있음. 그런데 듀얼-코어에서는 각 CPU 코어가 슈퍼스칼라의 명령어 파이프라인에 비하여 독립성이 더 높음. 다시 표현하면, 각 CPU 코어는 별도의 하드웨어 모듈로 구현된 상태로 하나의 칩에 포함되며, 내부 캐시와 시스템 버스 인터페이스만 공유함. 따라서 각 CPU 코어는 프로그램 실행을 독립적으로 수행하며, 필요한 경우에만 공유 캐시를 통하여 정보를 교환. 결과적으로, 하나의 프로그램에 포함된 명령어들을 명령어 파이프라인의 수만큼씩 인출하여 동시에 실행하는 슈퍼스칼라 프로세서와는 달리, 듀얼-코어 프로세서에서는 독립적인 처리가 가능한 태스크 플그램들이 CPU 코어들에 의해 동시에 처리됨. 이와 같은 프로그램 동시처리 기술을 멀티-태스킹이라고 부르는데, 더 많은 수의 CPU 코어들을 포함하고 있는 멀티-코어 프로세서는 그 수만큼의 태스크 프로그램들을 동시에 처리 할 수 있게 됨.
최근 고성능 프로세서들에서는 성능을 더욱 높이기 위하여 멀티-스레딩 기법이 도입되고 있음. OS와 같은 시스템 소프트웨어와 응용 프로그램들은 내부적으로 여러 개의 스레드들로 분할될 수 있는데, 스레드란 독립적으로 실행될 수 있는 최소 크기의 프로그램 단위를 의미함. 그림 (a)와 같은 일반적인 듀얼-코어 프로세서에서는 각 코어가 한 번에 한 개씩의 스레드를 실행함. 그 경우에는 각 코어는 스레드를 처리하는 중의 시스템 상태와 데이터 및 주소 정보를 저장하기 위하여 프로그램 카운터, 스택 포인터, 상태 레지스터, 데이터 레지스터, 주소 레지스터 등으로 이루어진 레지스터 세트를 가지고 있음. 그런데 그림 (b)의 구조에서는 각 코어가 두 개의 레지스터 세트들을 가지고 있어서 스레드를 두 개씩 동시에 처리할 수 있음. 즉, 두 개의 스레드들이 CPU 코어의 하드웨어 자원들을 공유하면서 동시에 처리되며, 스레드의 상태는 각 별도의 RS에 저장되는 것임.
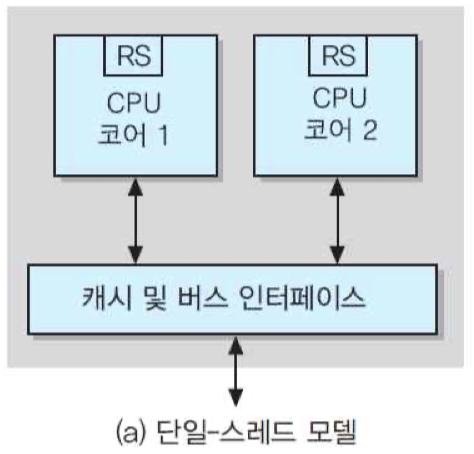
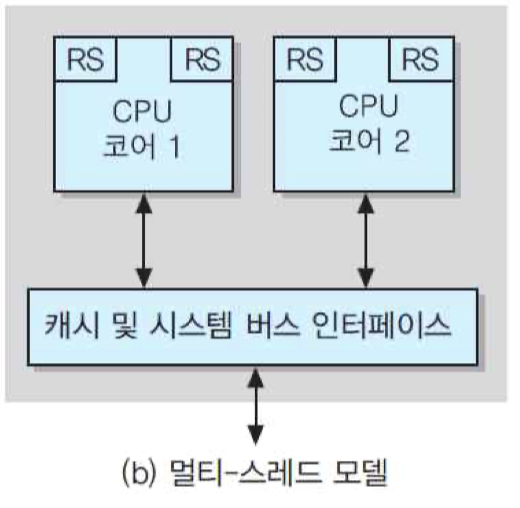
듀얼-코어 멀티-스레드 프로세서 : '두 개의 물리적 프로세서들이 네 개의 논리적 프로세서들로 구성되어 있다'고 정의하기도 함.
2.4 명령어 세트
명령어 세트 : 한 CPU를 위해 정의되어 있는 명령어의 집합
• 연산 종류 : CPU가 수행할 연산들의 수와 종류 및 복잡도
• 데이터 유형 : 연산이 수행될 데이터들의 유형. 즉, 데이터의 길이와 수의 표현 방식 등
• 명령어 형식 : 명령어의 길이, 오퍼랜드 필드들의 개수와 길이 등
• 주소지정 방식 : 오퍼랜드의 주소를 지정하는 방식
2.4.1 연산의 종류
데이터 전송 : 레지스터와 레지스터 간, 레지스터와 기억장치 간, 혹은 기억장치와 기억장치 간에 데이터를 이동하는 동작
산술 연산 : 덧셈, 뺄셈, 곱셈 및 나눗셈과 같은 기본적인 산술 연산들
논리 연산 : 데이터의 각 비트들 간에 대한 AND, OR, NOT 및 exclusive-OR 등과 같은 논리 연산을 수행
입출력(I/O) : CPU와 외부 장치들 간의 데이터 이동을 위한 동작들이 수행
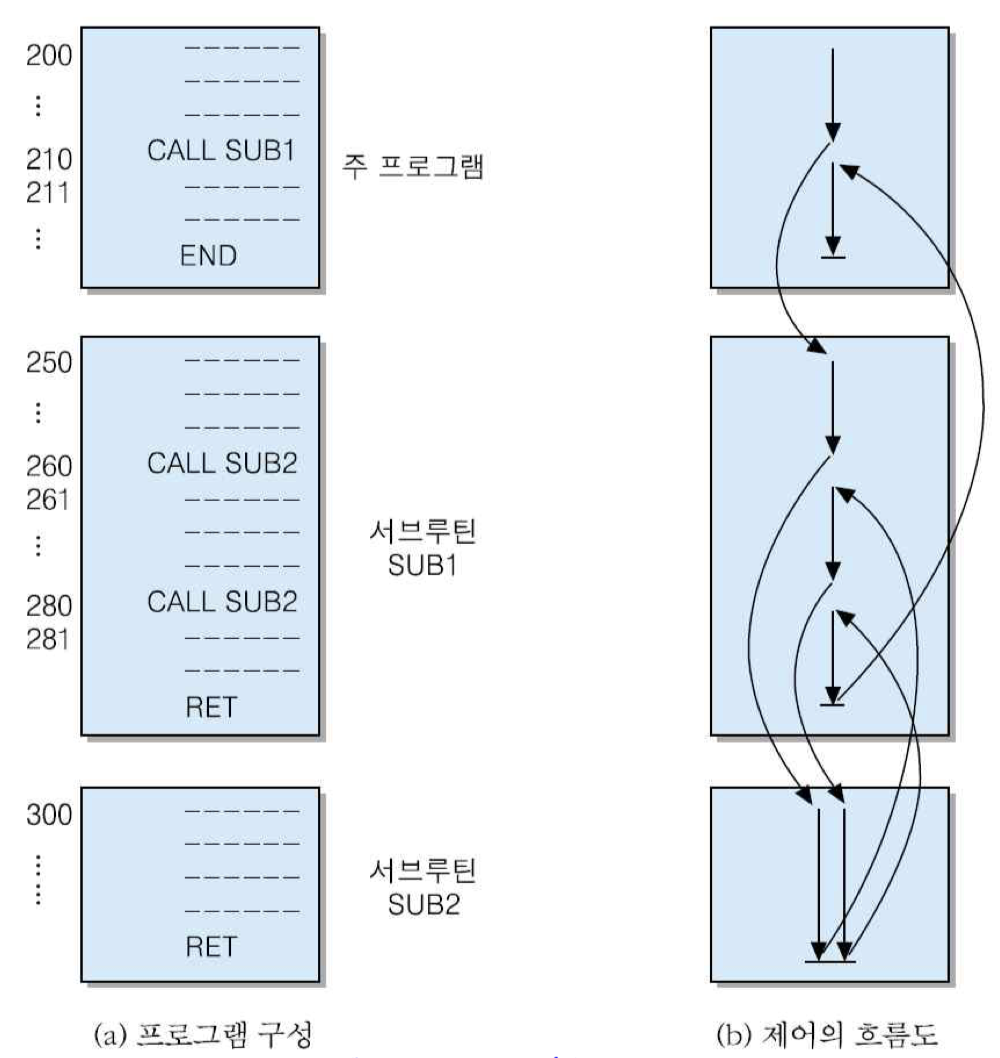
프로그램 제어 : 명령어 실행 순서를 변경하는 연산들이 필요. 이 분류의 연산들로는 분기와 서브루틴 호출 등이 있음
두 가지 기본적인 명령어
• CALL 명령어 : 서브루틴을 호출하는 명령어
• RET 명령어 : 서브루틴으로부터 원래 프로그램으로 복귀시키는 명령어
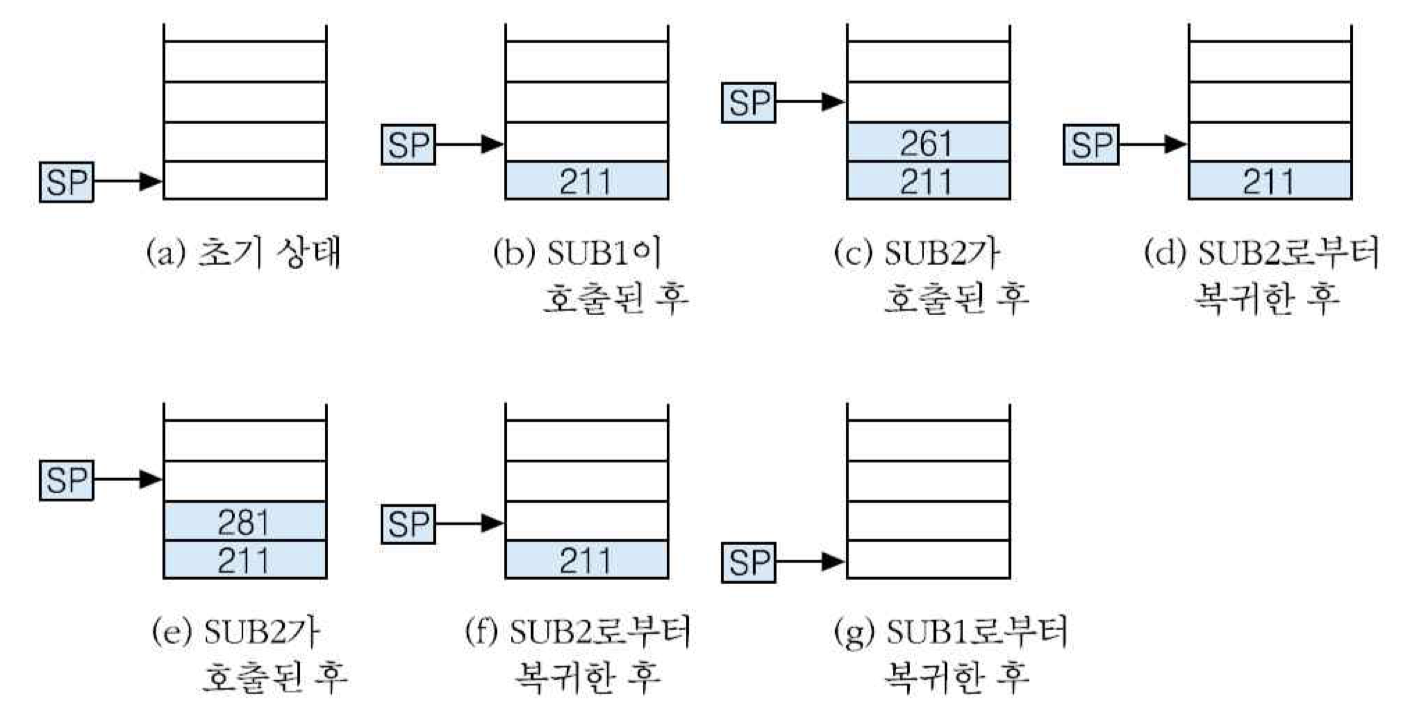
서브루틴이 포함된 프로그램이 수행되는 순서
CALL X 명령어의 마이크로-연산

RET 명령어의 마이크로-연산

프로그램 수행 과정에서 스택의 변화
2.4.2 명령어 형식
• 연산 코드 : 수행될 연산을 지정
• 오퍼랜드 : 연산을 수행하는 데 필요한 데이터 혹은 데이의 주소를 나타냄. 각 연산은 한 개 혹은 두 개의 입력 오퍼랜드들과 한 개의 결과 오퍼랜드를 가질 수 있음. 데이터는 CPU 레지스터 혹은 기억장치에 위치함
• 다음 명령어 주소 : 현재의 명령어 실행이 완료된 후에 다음 명령어를 인출할 위치를 나타냄. 순차적으로 다음 명령어가 실행되는 경우에는 이 부분이 필요하지 않으며, 분기 혹은 호출 명령어와 같이 실행 순서를 변경하는 경우에만 필요
명령어 형식 : 명령어 내 필드들의 수와 배치 방식 및 각 필드에 포함되는 비트 수
필드 : 명령어 각 구성 요소들에 소요되는 비트들의 그룹
명령어의 길이 = 단어 길이
세 개의 필드들로 구성된 16-비트 명령어
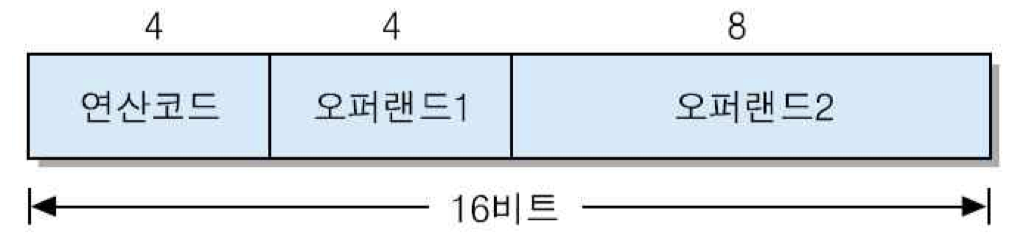
연산 코드 필드 길이 : 연산의 개수를 결정
ex) 4 비트 = 2의 4승, 즉 16가지의 연산 정의 가능
만약, 연산 코드 필드가 5비트로 늘어나면, 2의 5승, 즉 32가지 연산들 정의 가능. 따라서
다른 필드의 길이가 감소함
오퍼랜드 필드의 길이 : 오퍼랜드의 범위 결정
• 데이터 : 표현 가능한 수의 크기가 결정
• 기억장치 주소 : CPU가 오퍼랜드 인출을 위하여 직접 주소를 지정할 수 있는 기억장치 영역의 범위가 결정
• 레지스터 번호 : 데이터 저장에 사용될 수 있는 내부 레지스터들의 수가 결정
예를 들어, 오퍼랜드1은 레지스터 번호를 지정하고, 오퍼랜드2는 기억장치 주소를 지정한다고 가정. 일반적으로 CPU 내부 레지스터의 수는 많지 않으므로 오퍼랜드1에는 4비트를 할당하고, 오퍼랜드2에는 나머지 8비트를 할당함. 그 결과, 사용할 수 있는 레지스터는 16개가 되고, 주소 지정 가능한 기억장치의 주소 범위는 0번지부터 255번지까지가 됨.
오퍼랜드를 한 개만 필요로 하는 명령어의 경우에는 두 개의 오퍼랜드 필드들을 합하여 12비트를 사용할 수 있음. 이 경우에 만약 오퍼랜드가 2의 보수로 표현되는 데이터라면, 그 표현 범위는 (-2048 ~ +2047)이 되고, 기억장치 주소라면 최대 2의 12승(4096개)의 기억장치 주소를 지정할 수 있음. 이와 같이 명령어를 구성하는 각 필드의 비트 수에 따라, 연산의 수와 데이터의 표현 범위 혹은 주소지정이 가능한 기억장치 영역이 결정됨.
1-주소 명령어 : 오퍼랜드를 한 개만 포함하는 명령어

2-주소 명령어 : 두 개의 오퍼랜드를 포함하는 명령어

3-주소 명령어 : 세 개의 오퍼랜드드들 포함하는 명령어

1-주소 명령어를 사용한 프로그램

프로그램의 길이 = 7
2-주소 명령어를 사용한 프로그램

프로그램의 길이 = 6
3-주소 명령어를 사용한 프로그램

프로그램의 길이 = 3
단점
• 명령어의 길이가 증가
• 명령어 해독 과정이 복잡해지고, 실행 시간이 길어짐
2.4.3 주소지정 방식
주소지정 방식 : 주소 비트들을 이용하여 오퍼랜드의 유효 주소를 결정하는 방법
다양한 주소지정 방식을 사용하는 이유 : 제한된 수의 명령어 비트들을 이용하여, 사용자가 여러 가지 방법으로 오퍼랜드의 주소를 결정하도록 해주며, 더 큰 용량의 기억장치를 사용할 수 있도록 하기 위함.
EA : 유효 주소, 즉 데이터가 저장된 기억장치의 실제 주소
A : 명령어 내의 주소 필드 내용
R : 명령어 내의 레지스터 번호
(A) : 기억장치 A번지의 내용
(R) : 레지스터 R의 내용
1) 직접 주소지정 방식
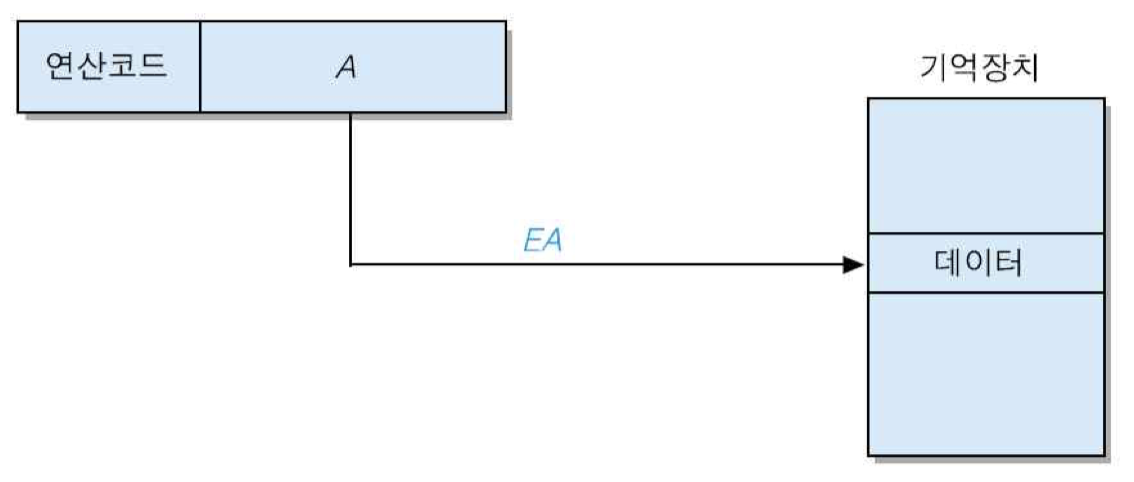
명령어 내 오퍼랜드 필드의 값을 유효 주소로 사용하여 연산에 필요한 데이터를 인출하는 방식
EA = A
장점 : 데이터 인출을위하여 한 번의 기억장치 액세스만 필요
단점 : 연산 코드를 제외하고 남은 비트들만 주소 비트로 사용될 수 있기 때문에 직접 지정할 수있는 기억장소의 수가 제한
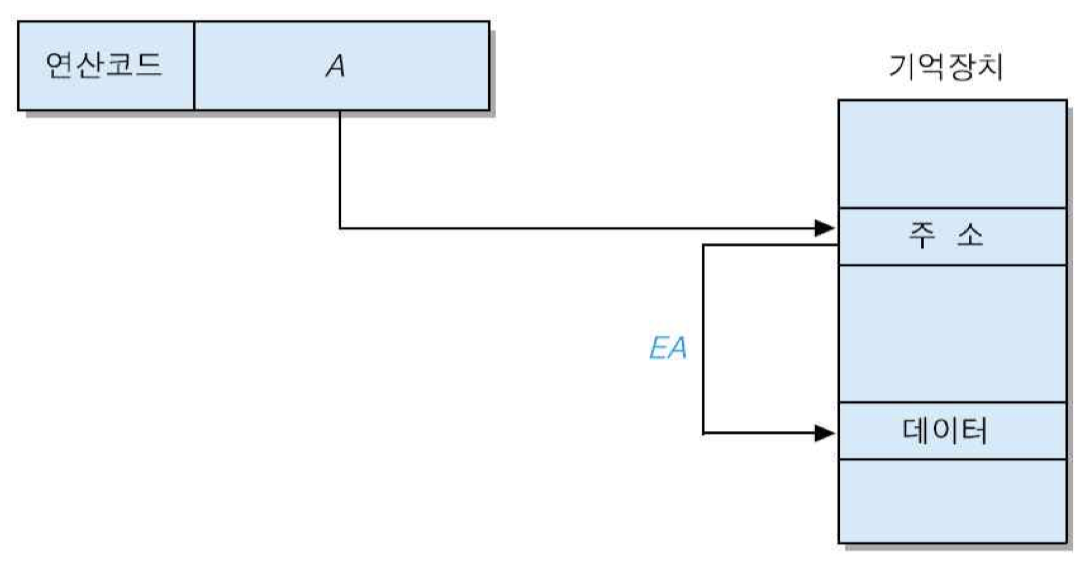
2) 간접 주소지정 방식
오퍼랜드가 가리키는 기억장치의 내용을 유효 주소로 사용하여 연산에 필요한 데이터를 인출하는 방식으로서, 두 번의 기억장치 액세스가 필요함
EA = (A)
장점 : 최대 기억장치용량이 단어의 길이에 의하여 결정 -> 주소지정 가능한 기억장치 용량 확장
• 단어 길이가 n 비트라면, 최대 2의 n승 개의 기억 장소에 대한 주소 지정이 가능
단점 : 실행 사이클 동안에 두 번의 기억장치 액세스가 필요
• 첫 번째 액세스 : 주소 인출
• 두 번째 액세스 : 그 주소가 지정하는 기억 장소로부터 실제 데이터 인출
명령어 형식에 간접비트(I) 필요
• 만약 I = 0이면, 직접 주소지정 방식
• 만약 I = 1이면, 간접 주소지정 방식

다단계(연속적) 간접 주소지정 방식이라고 부름
EA = ((..(A)..))
3) 묵시적 주소지정 방식
명령어 실행에 사용될 데이터가 묵시적으로 지정되어 있는 방식
'SHL' 명령어 : 누산기의 내용을 좌측으로 시프트
'PUSH R1' 명령어 : 레지스터 R1의 내용을 스택에 저장
장점 : 명령어 길이가 짧음
단점 : 종류가 제한됨
4) 즉시 주소지정 방식
명령어 내에 포함되어 있는 데이터를 연산에 직접 사용하는 방식
프로그램에서 레지스터나 변수의 초기 값을 어떤 산수값으로 세트하는 데 주로 사용
장점 : 데이터를 인출하기 위하여 기억장치를 액세스할 필요가 없음
단점 : 상수값의 크기가 오퍼랜드 필드의 비트 수에 의해 제한됨

5) 레지스터 주소지정 방식
명령어의 오퍼랜드가 가리키는 레지스터에 저장되어 있는 데이터를 연산에 사용하는 방식
EA = R
주소지정에 사용될 수 있는 레지스터들의 수 = 2의 k승 개
장점 : 오퍼랜드 필드의 비트 수가 적어도 됨. 데이터 인출을 위하여 기억장치 액세스가 필요 없음
단점 : 데이터가 저장될 수 있는 공간이 CPU 내부 레지스터들로 제한
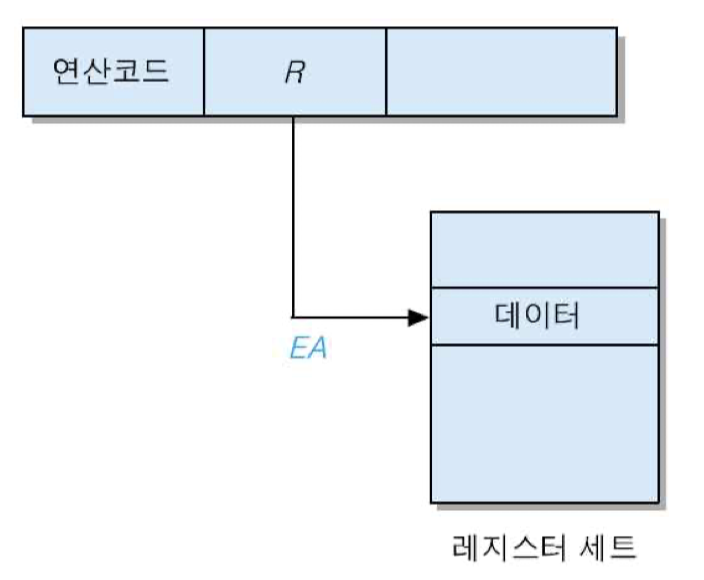
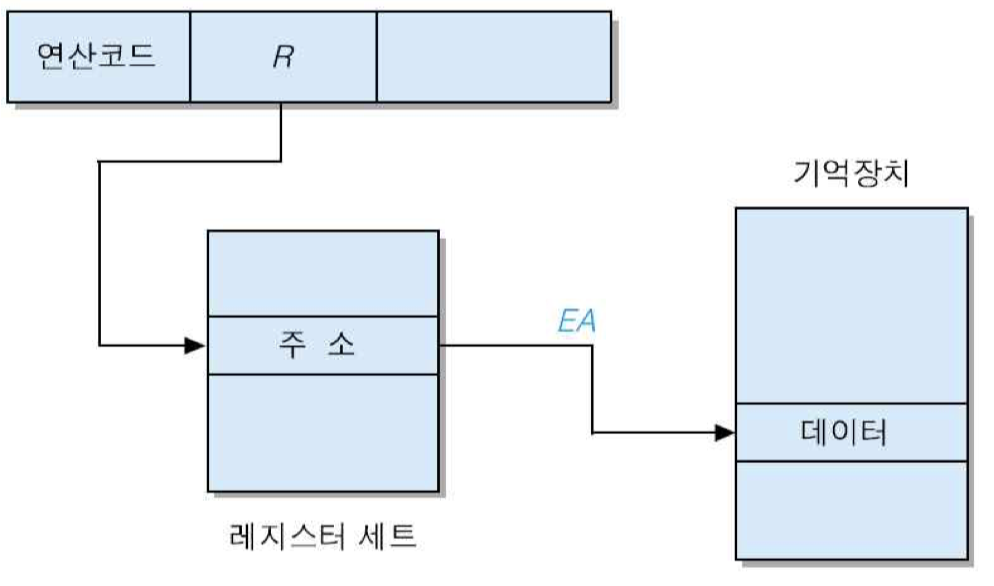
6) 레지스터 간접 주소지정 방식
지정된 레지스터의 내용을 유효 주소로 사용하여, 그 주소가 가리키는 기억장치로부터 읽어온 데이터를 연산에 사용하는 방식
EA = (R)
장점 : 주소지정 할 수 있는 기억장치 영역이 확장
• 레지스터의 길이 = 16 비트라면, 주소지정 영역 : 2의 16승(64Kword)
• 레지스터의 길이 = 32 비트라면, 주소지정 영역 : 2의 32승(4Gword)
7) 변위 주소지정 방식
지정된 레지스터의 내용과 명령어 내 오퍼랜드를 더하여 유효 주소를 결정하는 주소지정 방식
EA = A + (R)
사용되는 레지스터에 따라 여러 종류의 변위 주소지정 방식들이 정의될 수 있음
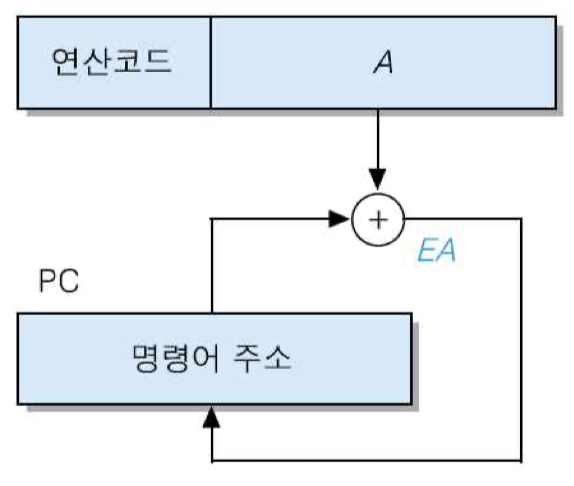
• 상대 주소지정 방식
프로그램 카운터의 내용과 명령어 내 오퍼랜드를 더하여 유효 주소를 결정하는 주소지정 방식
EA = A + (PC)
주로 분기 명령어에서 사용
• A > 0 : 앞방향으로 분기
• A < 0 : 뒷방향으로 분기
장점 : 전체 기억장치 주소가 명령어에 포함되어야 하는 일반적인 분기 명령어보다 적은 수의 비트만 필요
단점 : 분기 범위가 오퍼랜드 필드의 길이에 의해 제한
• 인덱스 주소지정 방식
인덱스 레지스터의 내용과 명령어 내 오퍼랜드를 더하여 유효 주소를 결정하는 주소지정 방식
EA = A + (IX)
(IX) : 인덱스 값을 저장하는 특수 레지스터
배열 데이터 액세스
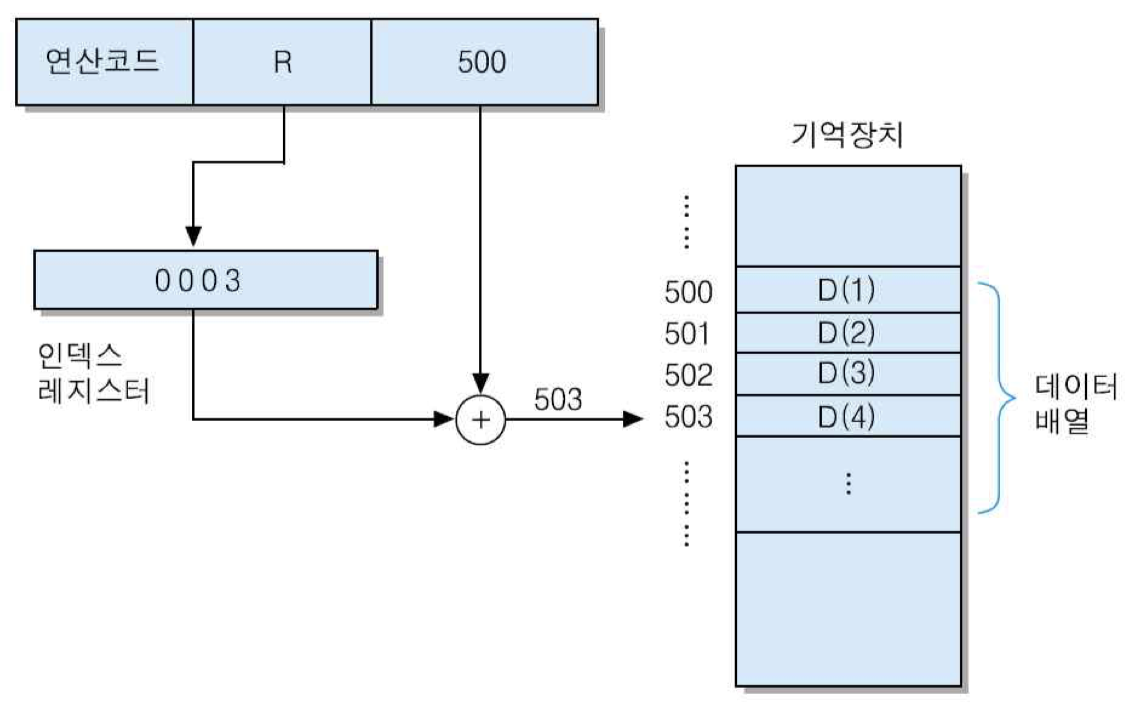
데이터 배열이 기억장치의 500번지로부터 저장되어 있고, 그 시작 주소를 가리키기 위하여 명령어의 주소 필드에 '500'이 저장되어 있음. 그리고 배열의 시작 주소로부터 각 데이터까지의 거리를 나타내는 인덱스 값은 인덱스 레지스터에 저장되어 있음. 인덱스 레지스터에 '3'이 저장되어 있어서 네 번째 데이터가 액세스되는 경우를 보여주고 있음. 그 데이터에 대한 처리를 수행한 후에 그 다음 데이터들을 순차적으로 액세스하려면, 인덱스 레지스터의 내용만 1씩 증가시키면 됨.
자동 인덱싱 : 연속된 데이터들을 차례대로 액세스하는 경우를 위하여 명령어 사이클 동안에 인덱스 레지스터의 내용이 자동적으로 증가 혹은 감소하도록 함
EA = A + (IX)
IX <- IX + 1
• 베이스-레지스터 주소지정 방식
베이스 레지스터의 내용과 명령어 내 오퍼랜드를 더하여 유효 주소를 결정하는 주소지정 방식
EA = A + (BR)
프로그램의 위치 지정에 사용
2.4.4 실제 상용 프로세서들의 명령어 형식
RISC 프로세서
• 명령어들의 수를 최소화
• 명령어 길이를 일정하게 고정
• 주소지정 방식의 종류를 단순화
ex) ATmega 마이크로 컨트롤러, ARM 프로세서
CISC 프로세서
• 명령어들의 수가 많음
• 명령어 길이가 일정하지 않음
• 주소지정 방식이 매우 다양함 -> 명령어 실행 시간이 긺
ex) PDP 계역 프로세서, Intel 펜티엄 계열 프로세서
1) PDP 계열 프로세서
PDP-10 프로세서 : 고정 길이의 명령어 형식 사용
• 단어의 길이 = 36 비트, 명령어의 길이 = 36 비트
• 연산 코드 = 9 비트 -> 최대 512 종류의 연산 허용(실제 365개)

PDP-11 프로세서 : 다양한 길이의 명령어 형식들 사용
• 연산 코드 = 4 ~ 16 비트
• 주소 개수 : 0, 1, 2 개
2) 펜티엄 계열 프로세서
선형 주소 : 프로세서가 발생하는 주소 = 유효 주소 + 세그먼트의 시작 주소
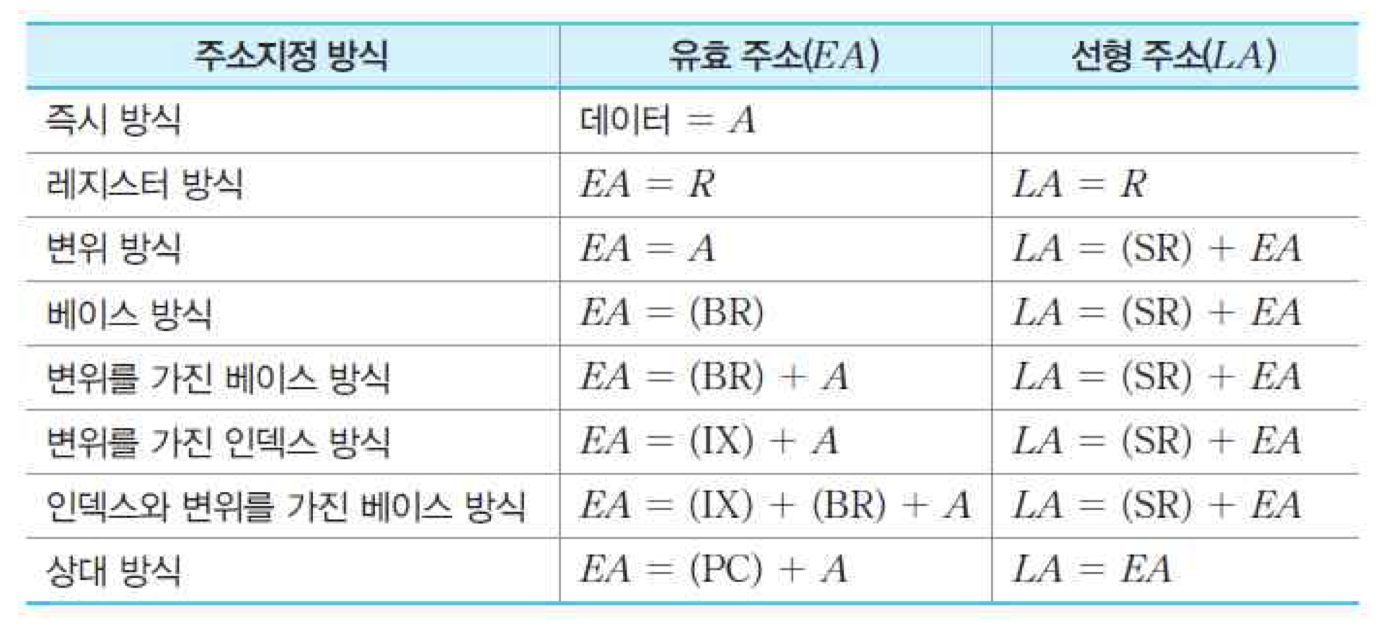
즉시 방식 : 데이터가 명령어에 포함되는 방식
• 데이터의 길이 = 바이트, 단어 혹은 2중 단어
레지스터 방식 : 유효 주소가 레지스터에 들어 있는 방식
변위 방식 : 명령어에 포함된 변위가 유효 주소로 사용되는 방식으로서, 직접 주소지정 방식에 전달
베이스 방식 : 레지스터 간접 주소지정에 해당
변위를 가진 베이스 방식 : 어떤 레지스터든 베이스 레지스터로 사용될 수 있음
변위를 가진 인덱스 방식 : 명령어가 인덱스 레지스터에 더해질 변위값을 포함
인덱스와 변위를 가진 베이스 방식 : 베이스 레지스터와 인덱스 레지스터의 내용과 변위를 모두 더하여 유효 주소를 결정
상대 방식 : 변위값과 프로그램 카운터의 값을 더하여 다음 명령어의 주소로 사용하는 방식
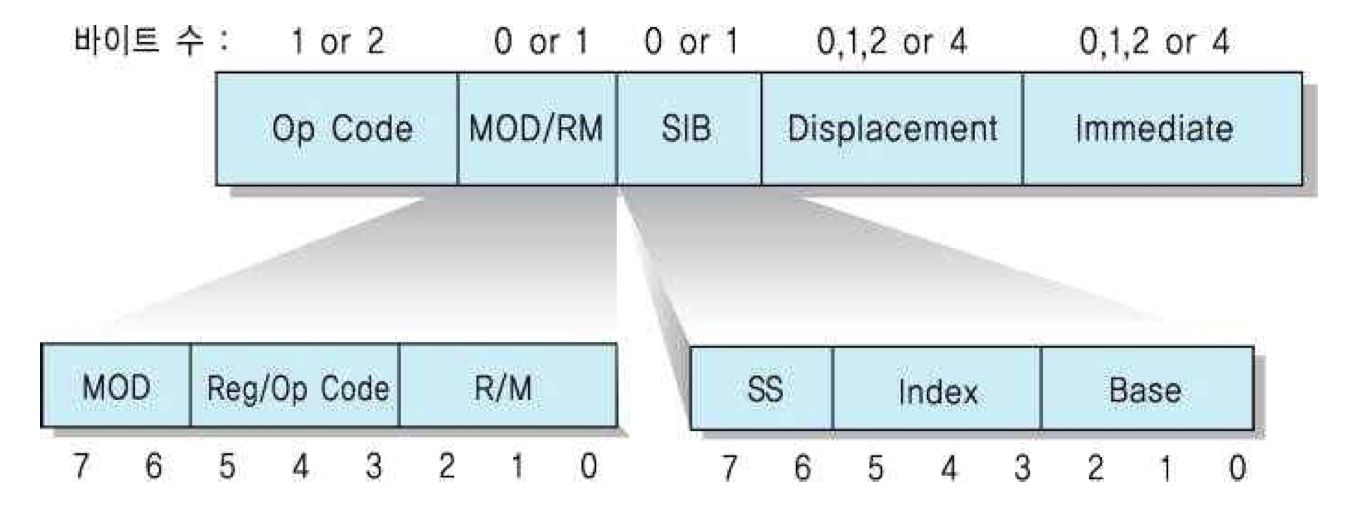
펜티엄 계열의 다양한 명령 형식의 필드들
• 연산 코드 : 연산의 종류 지정, 길이 = 1 또는 2바이트
• MOD R/M : 주소지정 방식 지정
• SIB : MOD/RM 필드와 결합하여 주소지정 방식을 완성
• 변위 : 부호화된 정수
• 즉시 : 즉시 데이터
3) ATmega 마이크로 컨트롤러
8-비트 CPU
대부분 명령어들의 길이 : 16비트
기억장치 액세스 명령어들 : 32비트
내부 레지스터 : 32개
RISC 프로세서
특징
• 연산 코드의 비트 수가 명령어에 따라 달라짐
• 오퍼랜드의 위치가 유동적
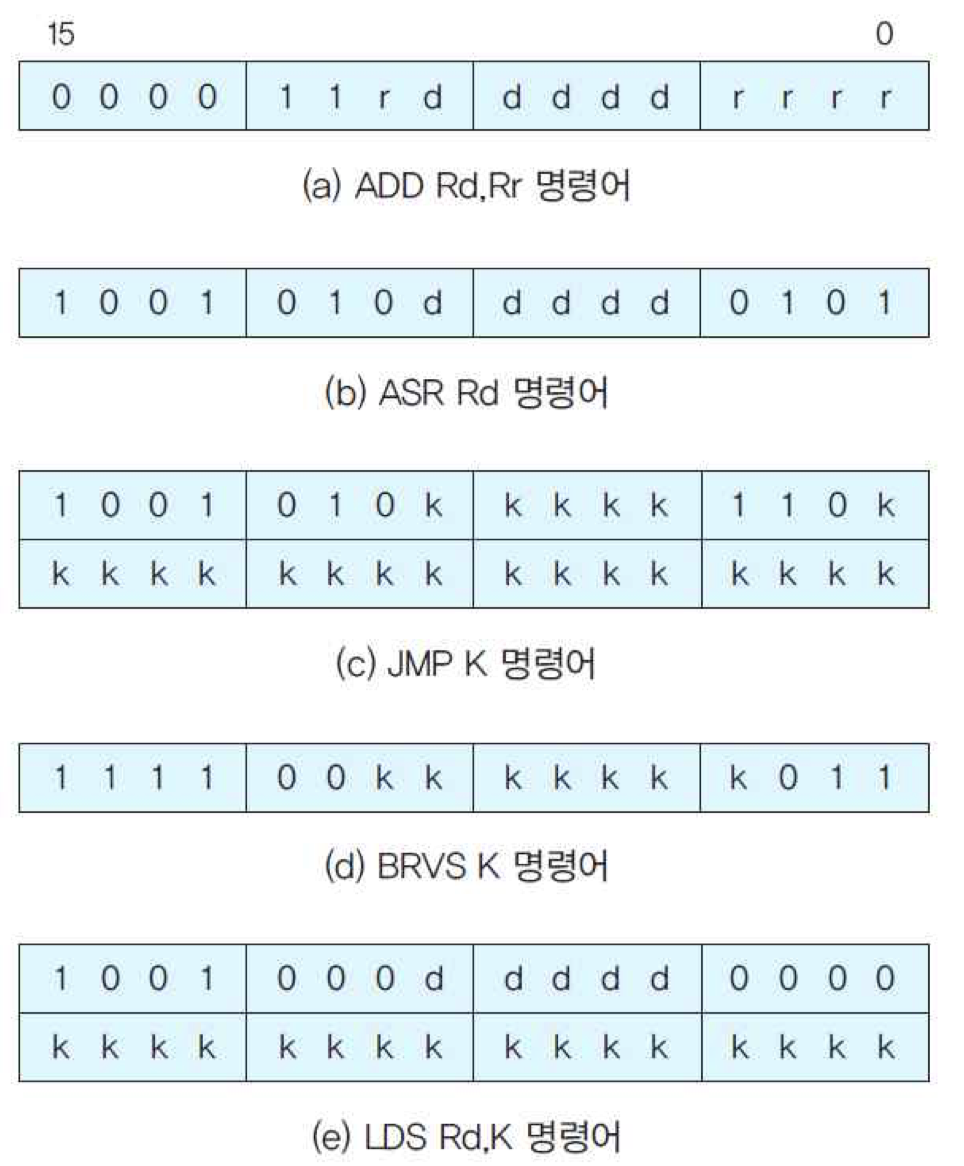
(a) ADD Rd,Rr : Rd <- Rd + Rs
(b) ASR Rd : 레지스터 Rd에 대하여 산술적 우측 시프트 수행
(c) JMP K : K 번지로 무조건 점프
(d) BRVS K : V 플래그가 세트 되었다면, K 번지로 분기
(f) LDS Rd,K : K 번지의 내용을 읽어서 Rd에 적재
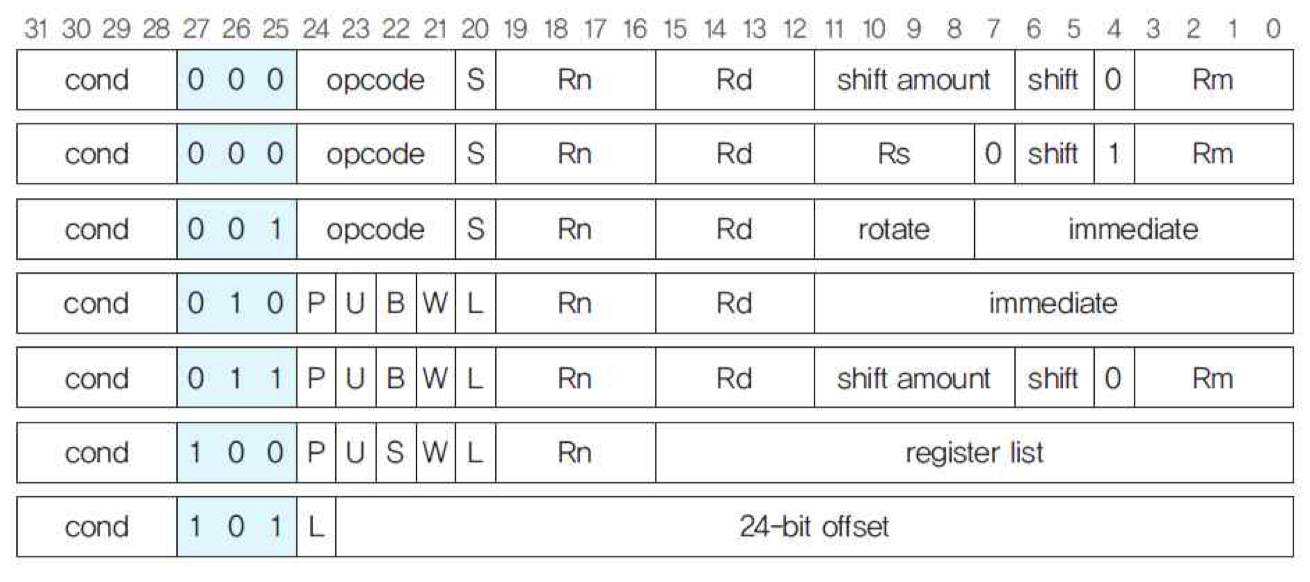
4) ARM 계열 프로세서
32-비트 RISC 프로세서
개방형 아키텍처
모바일 시스템용 프로세서로 널리 사용
명령어 필드들
• 분기조건 필드, 연산 필드, 오퍼랜드 필드 등
• 조건 플래그 : N, Z, C, V
• 레지스터 필드 : Rn, Rd, Rs
• P, U, W 비트 : 주소지정 방식 결정
• B 비트 : 연산처리 단위 결정
Thumb 명령어 : 컴파일 과정에서 원래의 32-비트 명령어들을 분석하여 새로운 패턴의 16-비트 명령어 형식으로 축소 -> 프로그램 기억장치 용량 감소
