모든 컴퓨터시스템은 프로그램과 데이터를 저장하기 위한 장치로서 주기억장치와 보조저장장치를 가지고 있음. 그러나 최근 CPU와 기억장치들 간의 속도 차이가 커지고 필요한 저장 용량이 증가함에 따라, 시스템 성능을 향상시키고 가격대성능비를 개선하기 위하여 다양한 유형의 기억장치들을 시스템에 포함시키고 있음. 기억장치는 CPU가 직접 액세스할 수 있는 내부 기억장치와 장치 제어기를 통하여 앨세스할 수 있는 외부 기억장치로 구성됨.
5.1 기억장치의 분류와 특성
• 액세스 : 기억장치에 대한 읽기 및 쓰기 동작
• 순차적 액세스 : 기억장치에 저장된 정보를 처음부터 순서대로 액세스하는 방식
• 직접 액세스 : 읽기/쓰기 장치를 정보가 위치한 근처로 직접 이동시킨 다음에, 순차적 검색으로 최종 위치에 도달하여 액세스하는 방식
• 임의 액세스 : 기억 장소들이 임의로 선택될 수 있으며, 기억장치 내의 어떤 위치든 액세스에 걸리는 시간이 동일한 방식
• 연관 액세스 : 각 기억 장소에 포함된 키값의 검색을 통하여 액세스할 위치를 찾아내는 방식
기억장치 시스템을 설계하는 데 있어서 고려해야할 주요 특성 : 용량, 액세스 속도
기억장치에서 용량을 나타내는 단위 : 바이트 or 단어
전송 단위 : 한 번의 기억장치 액세스에 의해 읽거나 쓸 수 있는 비트 수
블록 : 외부 기억장치에서는 데이터가 단어보다 훨씬 더 큰 단위로 전송되는 단위
주소지정 단위 : 하나의 주소에 의해 액세스되는 비트들의 그룹
• 액세스 시간 : 주소와 읽기/쓰기 신호가 기억장치에 도착한 순간부터 데이터가 저장되거나 읽혀지는 동작이 완료될 때까지의 시간
• 기억장치 사이클 시간 : 액세스 시간과 데이터 복원 시간을 합한 시간
• 데이터 전송률 : 기억장치로부터 초당 얽혀지거나 쓰여질 수 있는 비트수 : (1 / 액세스 시간) x (한 번에 읽혀지는 데이터 바이트의 수)
기억장치의 세 가지 유형
반도체 기억장치 : LSI 또는 VLSI 기술을 이용
자기-표현 장치 : 디스크 및 테이프와 같이 자력을 이용
광 저장장치 : 레이저광을 이용
기억장치는 데이터를 저장하는 성질에 따른 두 가지 유형
휘발성 기억장치 : 전력공급이 중단되면 저장된 내용이 사라지는 기억장치
비휘발성 기억장치 : 전력공급이 중단되어도 저장된 내용이 그대로 유지되는 기억장치
5.2 계층적 기억장치시스템
계층적 기억장치시스템 : 속도, 가격 및 크기가 다양한 기억장치들을 계층적으로 설치함으로써 성능대가격비를 높이는 시스템 구성 방식
5.2.1 필요성 및 효과
필요성 : 기억장치들은 속도, 용량 및 가격 측면에서 매우 다양
-> 적절한 성능, 용량 및 가격의 기억장치 구성 필요
효과 : 기억장치시스템의 성능대가격비 향상
기억장치 특성
• 액세스 속도가 높아질수록, 비트당 가격도 높아짐
• 용량이 커질수록, 비트당 가격은 낮아짐
• 용량이 커질수록, 액세스 속도는 낮아짐
2-단계 기억장치 계층
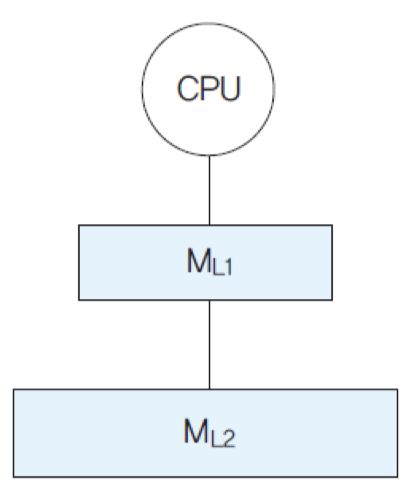
원하는 데이터가 첫 번째 계층 기억장치(ML1)에 있다면 즉시 액세스하고, 만약 없다면, 두 번째 계층의 기억장치(ML2)를 액세스
데이터가 첫 번째 계층의 기억장치에 있는 비율에 따른 평균 액세스 시간

지역성의 원리 : CPU가 기억장치의 한정된 몇몇 영역들을 집중적으로 액세스하면서 작업을 수행한다는 원리
5.2.2 기억장치 계층
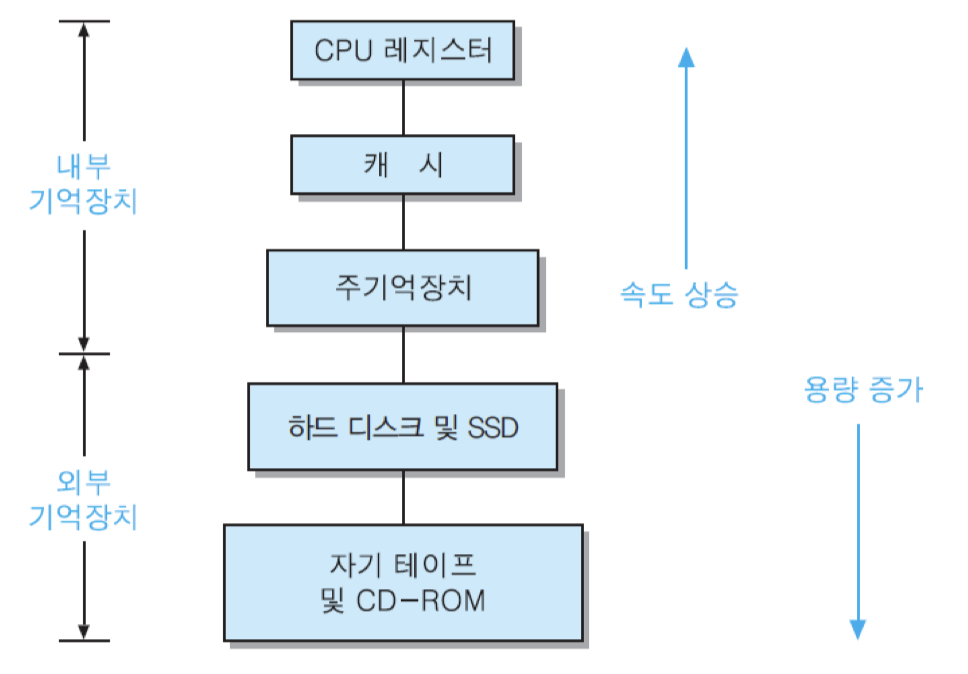
그림은 전형적인 기억장치 계층을 보여주고 있는데, 상위 계층으로 올라갈수록 다음과 같은 현상들이 나타남
• 비트당 가격이 높아짐
• 용량이 감소
• 액세스 시간은 짧아짐
• CPU에 의한 액세스 빈도는 높아짐
그림의 계층 구조에서 최상위 계층의 기억장치, 즉 가장 빠르고, 가장 용량이 적으며, 비트당 가격이 가장 높은 기억장치는 프로세서 내부에 있는 레지스터들임.
기억장치 계층에서 세 번째에 위치한 주기억장치는 반도체 기억장치 칩들로 구성되지만, 액세스 시간은 대략 수십 내지 수백 ns 정도로서 레지스터 액세스 시간보다 훨씬 더 긺. 따라서 프로그램 실행 중에 CPU가 필요로 하는 데이터가 레지스터에 없는 경우에 주기억장치로부터 읽어오기 위하여 상당히 긴 시간을 기다려야 함.
그러한 문제를 해결하기 위하여 대부분의 컴퓨터시스템에서는 CPU와 주기억장치 사이에 속도가 빠르지만 용량은 작은 캐시 메모리를 설치
내부 기억장치 : CPU가 직접 액세스 할 수 있는 기억장치들
외부 기억장치 : CPU가 직접 액세스 할 수 없으며, 장치 제어기를 통해서만 액세스 할 수 있는 기억장치들
2차 기억장치 or 보조저장장치 : CPU가 직접 액세스할 수는 없으며, 각 저장장치의 제어기 혹은 I/O 프로세서를 통해서만 데이터 저장 및 검색이 가능한 저장장치
하위 계층으로 내려갈수록 용량이 더 커지고 비트당 가격은 떨어지는 반면에, 지역성의 원리로 인하여 액세스 빈도가 더 낮아짐.
5.3 반도체 기억장치
5.3.1 RAM
RAM(Random Access Memory) : 읽기와 쓰기가 모두 가능한 반도체 기억장치
특성
임의 액세스 방식
반도체 직접회로 기억장치
데이터 읽기와 쓰기가 모두 가능
휘발성 : 전원 공급이 중단되면 내용이 지워짐
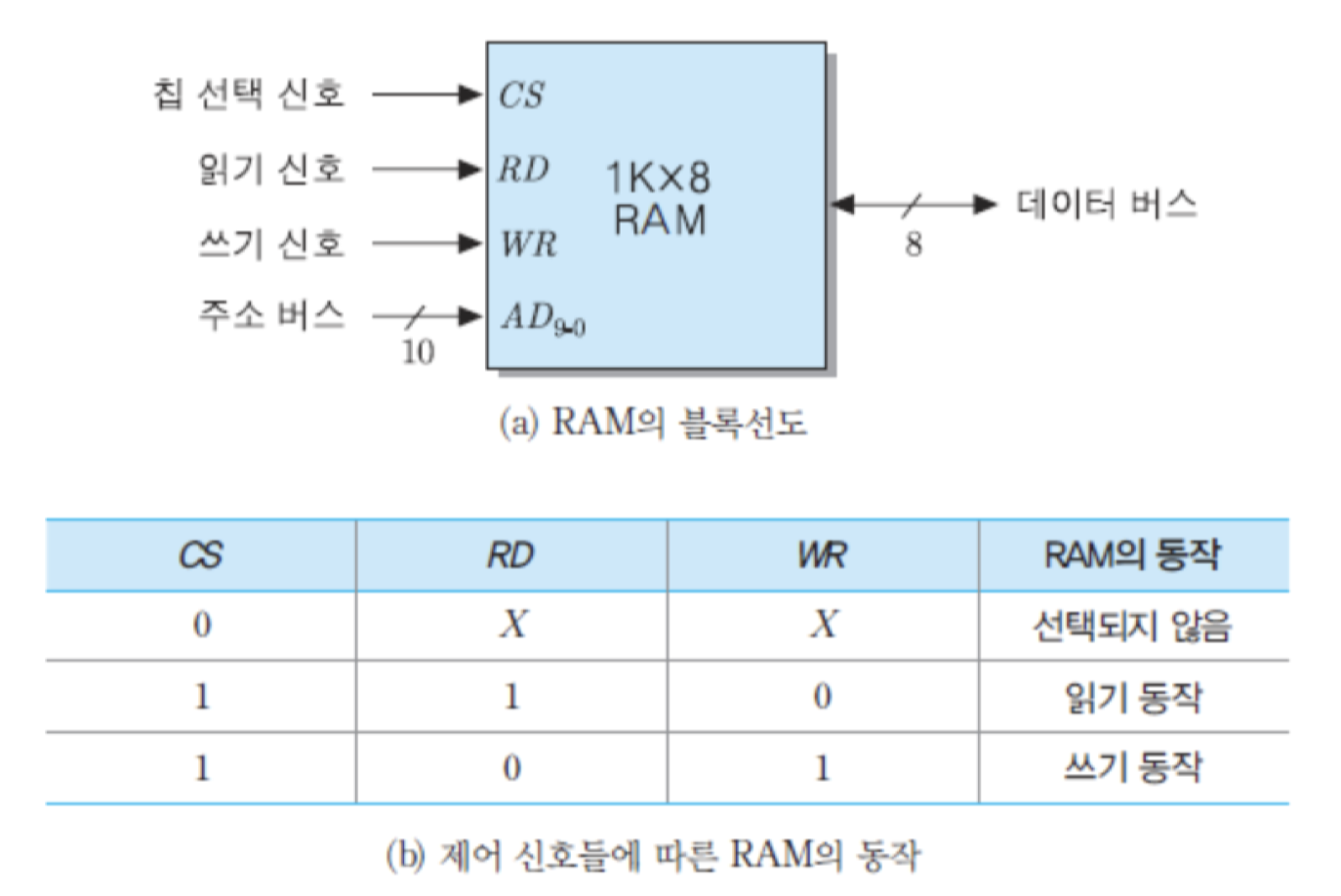
그림은 1K x 8비트 용량의 RAM에 대한 블록선도와 제어 신호들을 보여주고 있음. RAM의 내부 조직에는 여러 가지 유형들이 있는데, 이 그림의 1K x 8비트 조직은 8비트로 구성된 기억 장소들이 1024개가 비열되어 있는 경우임. 이 칩의 용량은 1K 바이트가 되며, 주소 비트는 1K = 2의 10승이므로 10개가 필요함. 그리고 데이터 입출력은 한 번에 8비트씩 이루어지기 때문에, 데이터 버스의 폭은 8비트가 됨.
그림 (a)에서 제어 입력 신호인 RD는 읽기 명령 신호이고, WR은 쓰기 명령 신호임. 기억장치시스템이 여러 개의 칩들로 구성되는 경우에는 칩 선택 신호인 CS에 의해 칩의 선택 여부가 결정됨. CS 신호가 1로 활성화되면, 칩은 주소와 제어 신호에 따라 적절한 동작을 수행함. 만약 RD = 1이고 WR = 0이라면, 주소가 지정하는 기억 장소로부터 8비트 데이터가 읽혀서 데이터 버스를 통하여 출력됨. 만약 RD = 0이고 WR = 1이면, 데이터 버스를 통하여 들어오는 8-비트 데이터가 주소에 의해 지정되는 기억 장소에 저장됨. 그러나 CS 신호가 0인 경우에는 이 칩이 선택되지 않은 것이므로, 제어 신호들이나 데이터 입출력 통로가 모두 전기적으로 단절된 상태가 됨. 그림 (b)에서는 X는 해당 신호가 0혹은 1중의 어느 값이든 상관없다는 것을 의미함.
제조 기술에 따른 분류
DRAM
• 캐패시터에 전하를 충전하는 방식으로 데이터를 저장 하는 기억 소자들로 구성
-> 집적 밀도가 높음
• 데이터의 저장 상태를 유지하기 위하여 주기적인 재충전 필요
• 집적 밀도가 더 높으며, 같은 용량의 SRAM 보다 비트당 가격이 더 저렴
• 용량이 큰 주기억장치로 사용
SRAM
• 기억 소자로서 플립-플롭을 이용
-> 집적 밀도가 낮음
• 전력이 공급되는 동안에는 재충전 없이도 데이터 계속 유지 가능
• DRAM보다 다소 더 빠르다
• 높은 속도가 필요한 캐시 메모리로 사용
64-비트 RAM의 조직
1) 8 x 8비트 조직
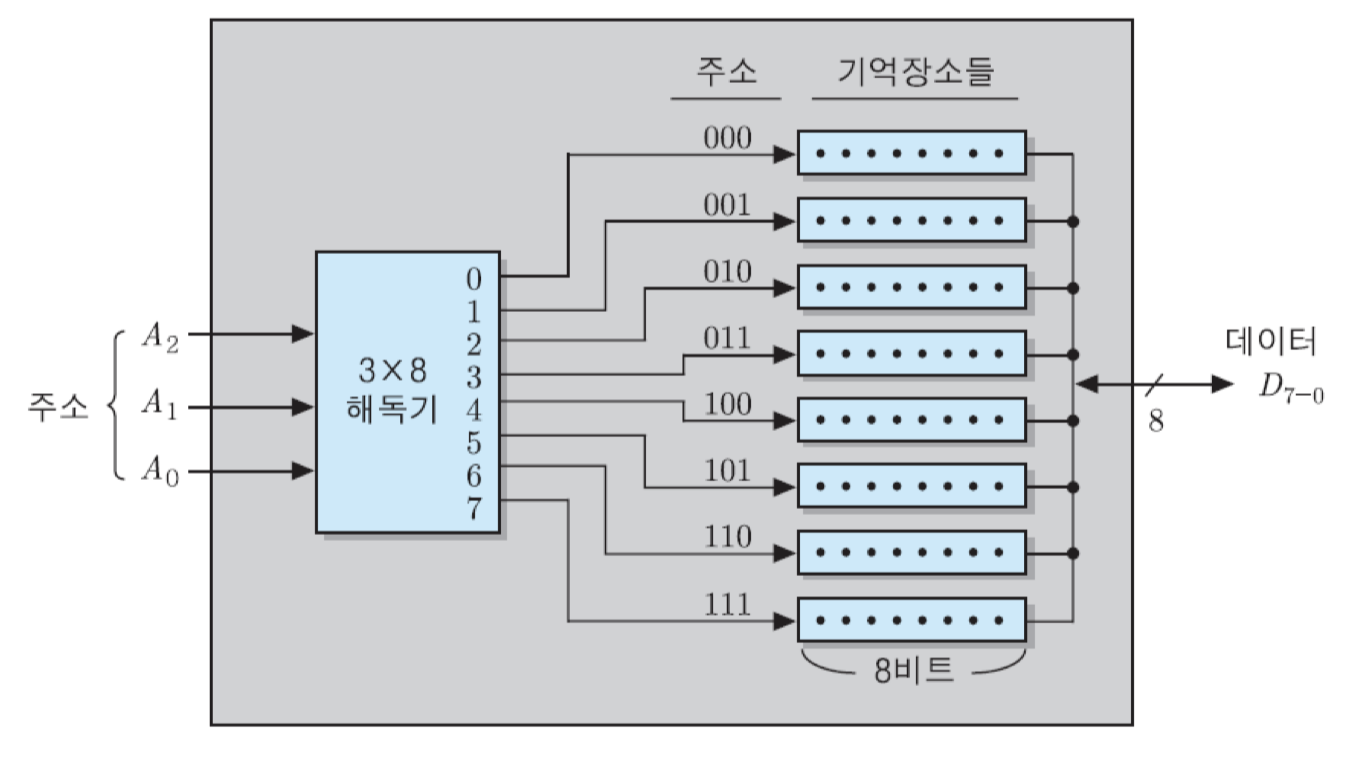
8개의 기억 장소들로 구성되며, 각 기억 장소에는 8비트씩 저장됨. 따라서 전체 용량은 64비트가 됨. 그리고 기억 장소는 8개이므로 세 개의 주소 비트들로 그들의 주소를 모두 지정할 수 있으며, 주소의 범위는 0번지부터 7번지까지가 됨. 칩 내의 3 x 8 해독기는 주소 비트들을 해독하여 8개의 출력들 중의 하나를 활성화시킴. 그러면 그 출력 선이 연결된 기억 장소가 선택되고, 제어 신호에 따라 읽기 혹은 쓰기 동작이 수행됨. 한 번의 읽기 혹은 쓰기 동작이 수행될 때 동시에 입출력되는 데이터 비트 수가 8개이기 때문에, 데이터 입출력 선은 8개가 필요함.
2) 16 x 4비트 조직
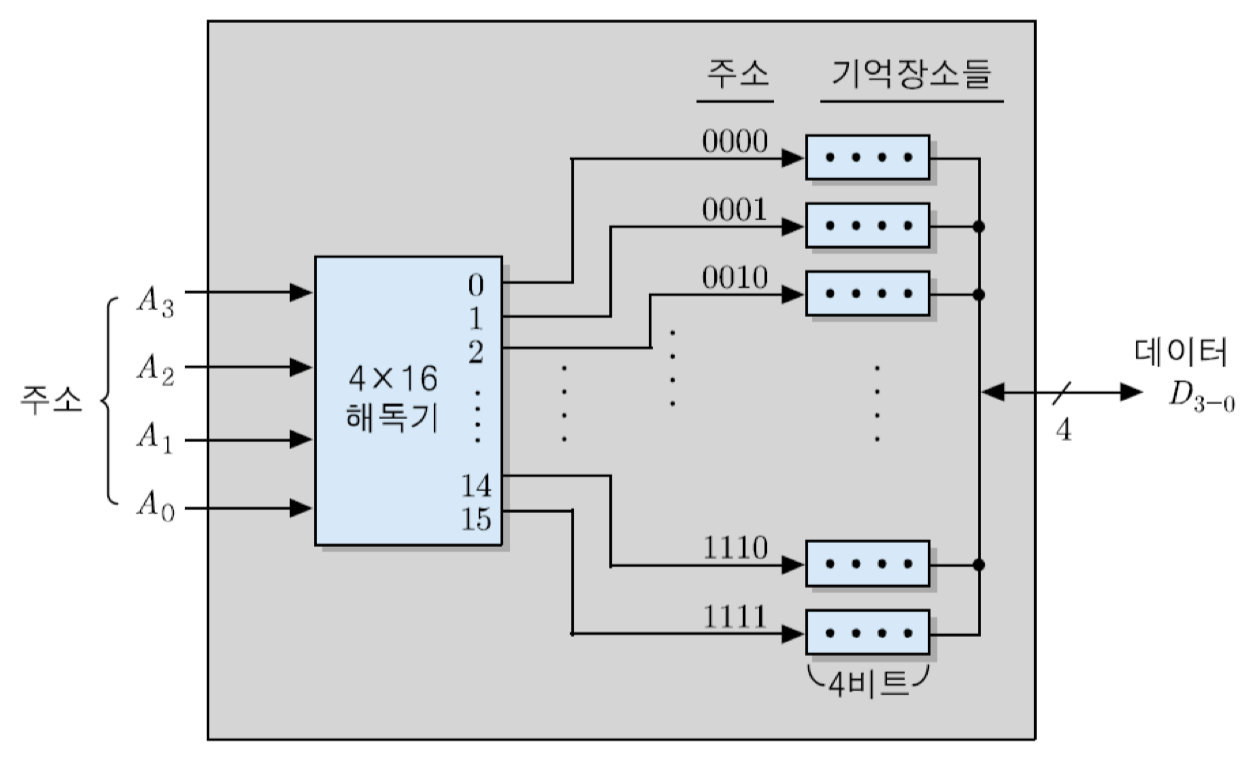
16 x 4비트 조직의 RAM에서는 16개의 기억 장소들이 서로 다른 주소를 할당받으며, 각 기억 장소에는 4-비트 데이터가 저장됨. 이 칩에 대한 주소지정을 위해서는 16 = 2의 4승, 즉 4-비트 주소가 필요하게 됨. 따라서 그림과 같이 4 x 16 해독기가 16개의 출력 신호들 중의 하나를 활성화시킴으로써 각 기억 장소가 선택됨. 이 경우에 칩 내부 기억장소들의 주소 범위는 0번지부터 15번지까지가 되며, 데이터 입출력 선은 4개가 있으면 됨.
3) 64 x 1비트 조직
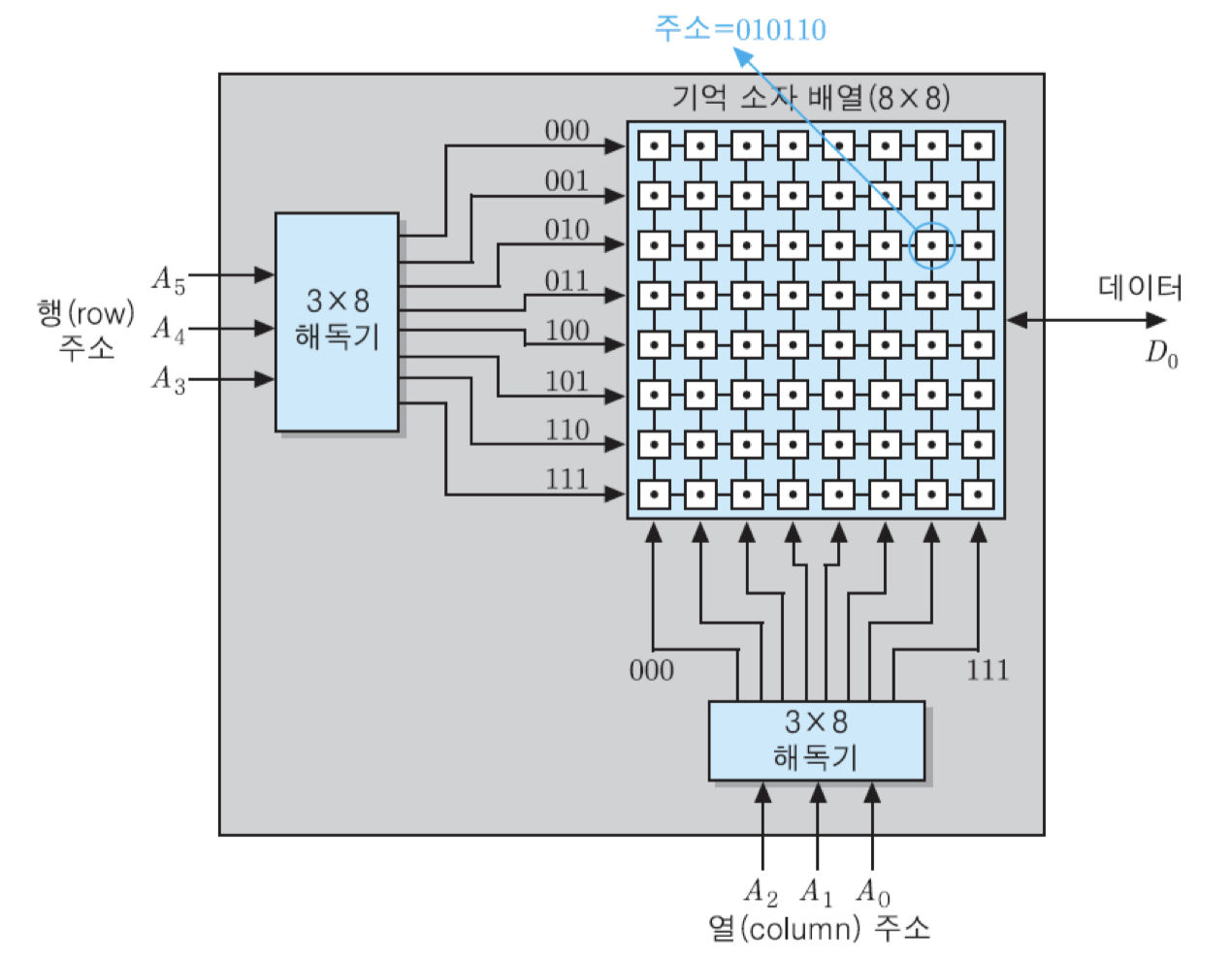
64 x 1비트 조직의 RAM에서는 그림에서 보는 바와 같이 8x8의 장방형 구조에 위치한 64개의 기억 소자들에 대하여 읽기 및 쓰기가 한 비트 단위로 이루어짐. 따라서 이러한 조직에서는 데이터 입출력 선이 한 개만 있으면 됨. 그리고 각 기억 장소가 별도의 주소를 가지므로 64 = 2의 6승, 즉 여섯 개의 주소 비트들이 필요함.
그런데 이러한 조직에서는 일반적으로 주소 비트들이 두 그룹으로 나누어져 별도로 해독됨. 주소 비트들 중에서 상위 세 비트는 8개의 행들 중에서 한 개를 선택하고, 하위 세 비트들은 8개의 열들 중에서 한 개를 선택함. 따라서 두 개의 3 x 8 해독기가 필요함. 이 방법으로 주소가 지정되는 예를 보면, 그림에서 세 번째 행의 일곱 번째 기억 소자의 주소는 010110이 됨.
4) 16M x 4비트 조직
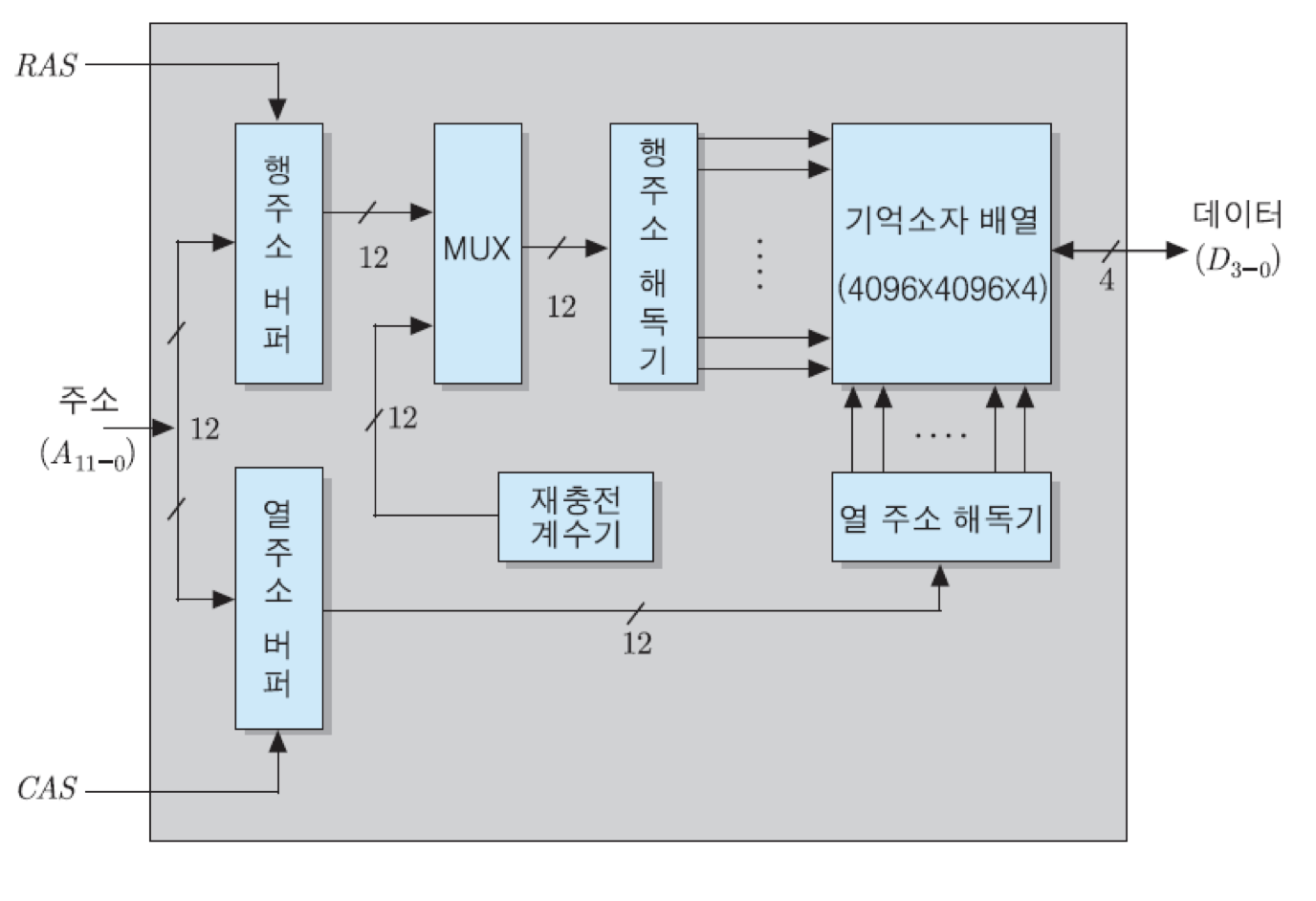
16M x 4비트 조직을 가진 64Mbit DRAM의 내부 조직인 그림을 분석해보면, 이 칩의 주소 입력 단에는 주소 버퍼들이 있고, 두 개의 해독기들이 각각 행 주소와 열 주소를 해독함. 이 조직의 핵심부인 기억 소자 배열은 4096x4096x4비트로 표시되는데, 그 의미는 기억 장소들이 4096개의 행과 4096개의 열들로 이루어진 장방형 구조로 배열되어 있으며, 각 기억 장소에는 네 개의 데이터 비트들이 저장된다는 것을 말함. 이 칩의 전체 기억 장소의 수는 16M개이기 때문에, 그들을 구분하기 위해서는 24비트의 주소가 필요함.
그림과 같은 조직에서 기억 소자의 행과 열을 구분하기 위해서는 각 방향으로 12비트씩의 주소가 필요함. 즉, 전체적으로 24개의 주소 비트들이 들어와야 함. 그러나 실제로 칩으로 접속되는 주소 선은 12개만 있어도 되는데, 그것이 가능한 이유를 아래의 그림의 읽기 동작에 대한 타이밍도를 통하여 살펴봄.
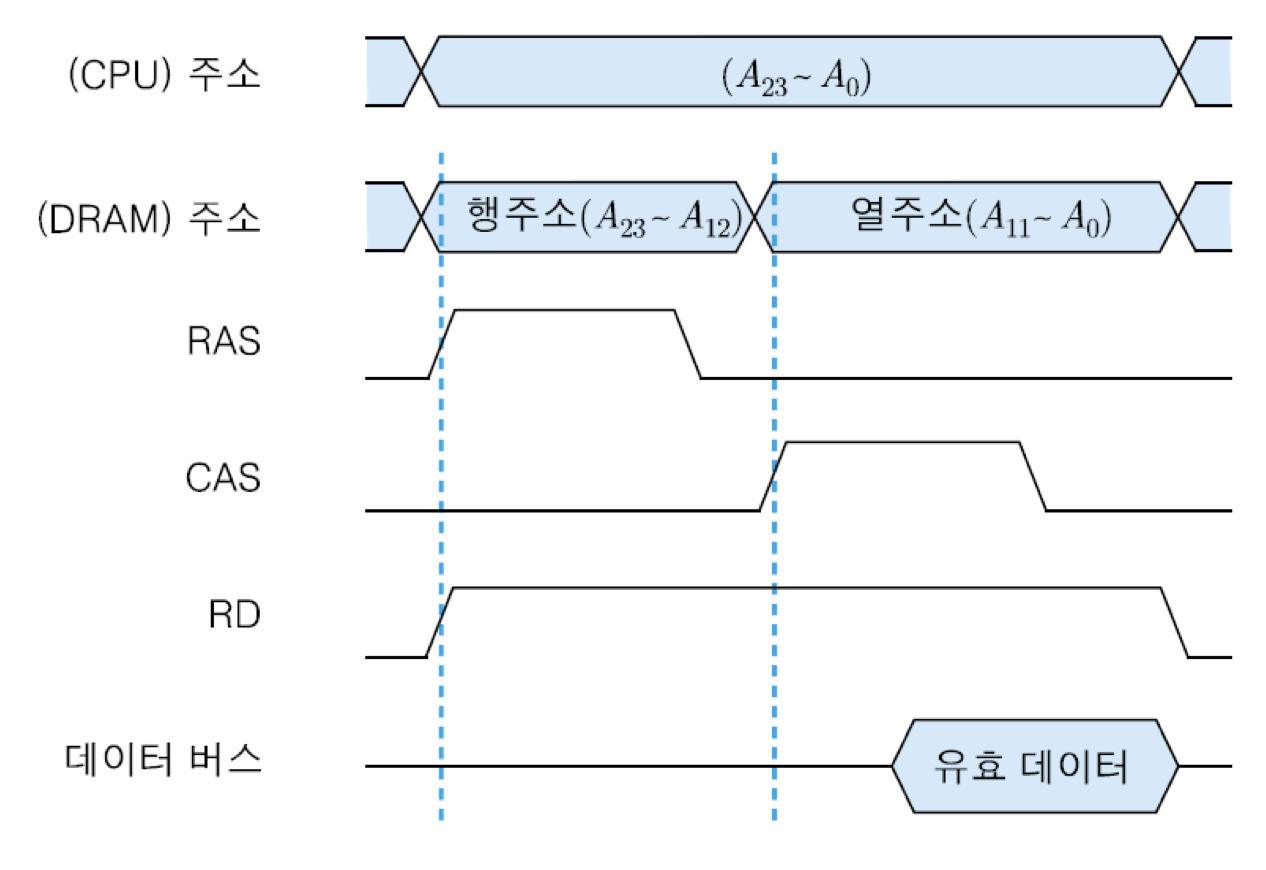
그림에서 'CPU 주소'란 CPU가 발생한 전체 24개의 주소 비트들을 말하는데, 그들 중에서 상위 12개 비트들이 먼저 선택되어 DRAM칩의 주소 입력으로 들어옴. 그 상위 주소 비트들은 4096개의 행들 중의 하나를 선택하는 행 주소로 사용되는데, 그들은 RAS(기억장치의 행 주소 래치 신호) 신호에 의해 행 주소 버퍼에 래치 됨. 그 다음 순간에는 열 주소로 사용될 하위 12비트들이 선택되어 DRAM으로 전송되는데, 그들은 CAS(기억장치의 열 주소 래치 신호) 신호에 의해 열 주소 버퍼에 래치 됨.
그와 같이 CPU가 생성한 주소를 행 주소와 열 주소로 나누어 순차적으로 DRAM으로 보내주고, 그에 맞추어 PAS 및 CAS 신호를 발생시키는 동작은 기억장치 제어기(CPU와 기억장치 사이에 위치하여 주소 및 데이터 전송을 제어하는 장치)가 담당. CPU와 기억장치 사이에 위치하는 기억장치 제어기는 노스 브리지라고 부르는 칩셋으로 구현되기도 하며, 지연을 줄이기 위하여 CPU 칩 내부에 포함시키는 경우도 있음.
두 버퍼에 래치 된 주소들은 각각 행 주소 해독기와 열 주소 해독기에 의해 해독되어 해당 기억 장소를 선택하게 됨. 이와 같은 주소 래치 방식을 이용함으로써, DRAM으로 주소를 12비트만 공급하더라도 모든 주소지정이 가능해지는 것임. 이것은 기억장치 칩의 핀 수를 줄일 수 있게 해주어 패키지의 크기를 줄이는데 많은 도움이 됨. 그림은 DRAM 읽기 동작에 대한 타이밍도로서, 주소 전송과 함께 RD 신호가 활성화되며, 열 주소가 인가된 순간부터 칩의 액세스 시간만큼 지난 후에 4-비트 데이터가 읽혀져 데이터 버스에 실리게 됨.
DRAM에는 그림에서 보는 바와 같이 재충전 회로가 포함되어 있음. 이 회로의 핵심 요소인 재충전 계수기는 0부터 4095까지의 주소를 순서대로 발생하며, 그 주소는 기억장치 액세스가 일어나지 않는 사이클 동안에 내부의 멀티플렉서에 의해 선택되어 행 주소 해독기로 보내짐. 그러면 그 주소가 지정하는 행에 위치한 모든 기억 소자들이 동시에 선택되어 재충전됨. 재충전 동작은 각 행에 공통으로 접속된 재충전 신호 선으로 전기를 인가하여 '1'이 저장되어 있는 기억 소자들을 충전함으로써 이루어짐.
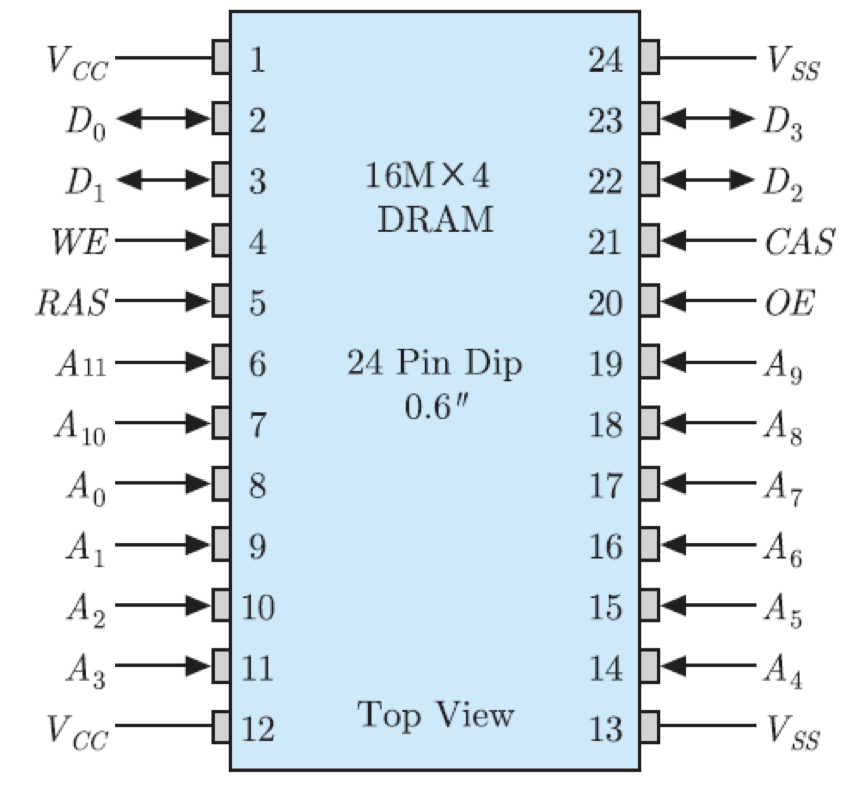
그림은 위의 DRAM을 패키징하여 24개의 핀들을 가진 칩으로 만들어진 모습을 보여주고 있음. 그림에서 Vcc는 전원 공급 핀이며, Vss는 접지 핀을 나타냄. 2번, 3번, 22번 및 23번이 데이터 입출력 핀들이며, 아래편의 12개 핀들이 주소 핀임. 4번의 WE 핀은 쓰기 신호 선이고, 20번의 OE 핀은 출력 활성화 신호, 즉 읽기 신호 핀을 가리킴. 그리고 5번과 21번 핀으로는 각각 RAS 및 CAS 신호가 인가됨.
5.3.2 ROM
ROM(Read Only Memory) : 저장된 내용을 읽는 것만 가능한 반도체 기억 장치
ROM에 주로 저장되는 내용
• 시스템 초기화 및 진단 프로그램
• 번번히 사용되는 함수들과 서브루틴들
• 제어 유니트의 마이크로프로그램
전원 공급이 중단되어도 내용을 잃어버리지 않고 영구 저장할 수 있음.
-> 프로그램이나 데이터가 영구 저장되므로 보조저장장치로부터 매번 이동시킬 필요가 없기 때문에 액세스 시간이 짧아짐.
그러나 쓰기 동작이 불가능하기 때문에, 변경할 필요가 없는 프로그램 코드나 데이터를 저장하는 데만 사용됨.
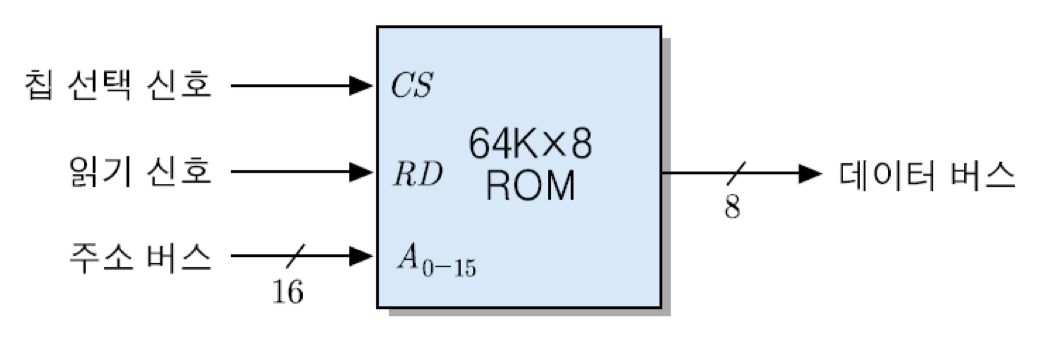
그림은 64Kx8비트 조직을 가진 ROM의 블록 선도를 보여주고 있음. ROM은 읽기만 가능하기 때문에 WR 신호는 필요 없고 RD 신호만 있으면 됨. 또한 64K = 2의 16승 이므로, 16비트의 주소가 입력되어야 함. 칩 선택 신호인 CS와 읽기 신호가 활성화되면, 주소가 지정하는 기억 장소로부터 데이터가 읽혀져서 데이터 버스에 실리게 됨. 대부분의 ROM은 데이터 출력 선이 8개인 조직을 사용하며, 용량도 바이트 단위로 표시함. 따라서 그림의 칩은 64KByteROM이라고 부름.
ROM의 종류
• PROM : 한 번은 쓰는 것도 가능한 ROM
• EPROM : 자외선을 입력하여 저장된 내용을 삭제할 수 있어서, 여러 번의 갱신이 가능한 PROM
• EEPROM : 전기적으로도 삭제할 수 있는 PROM
• 플래시 메모리 : 삭제에 걸리는 시간이 매우 짧은 EEPROM이며, 쓰기 동작과 삭제 동작시의 데이터 크기가 서로 다름
5.4 기억장치 모듈의 설계
컴퓨터의 단어 길이가 N비트이고 기억장치 칩의 데이터 입출력 비트 수가 B개일 때, 한 번에 한 단어씩의 데이터 액세스가 가능하도록 하기 위해서는 N/B개의 칩들로부터 동시에 B비트식 액세스 할 수 있어야 함. 그렇게 하기 위해서는 기억장치 칩들을 병렬로 접속해야 함.
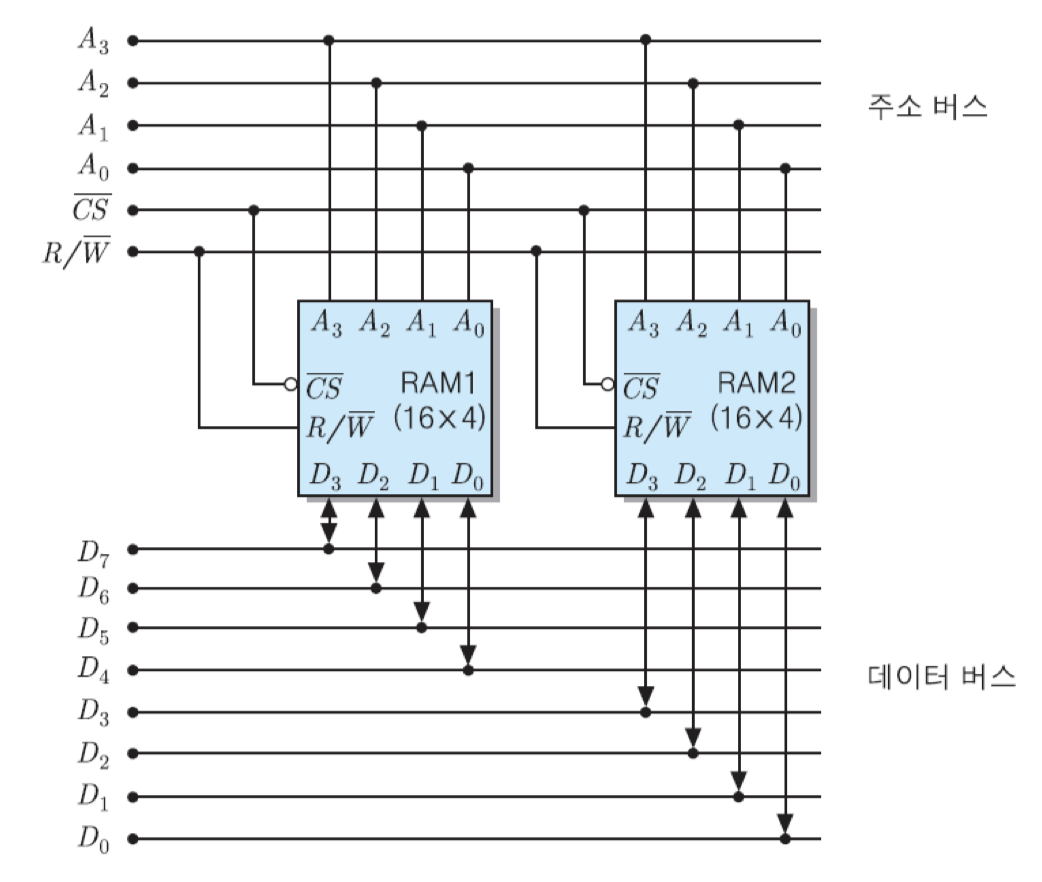
단어 길이가 8비트인 컴퓨터에서 두 개의 16x4bit RAM 칩들을 이용하여 기억장치를 구성한다면, 그 칩들을 병렬로 접속하여 한 번에 8비트씩 읽기/쓰기가 가능하도록 해야 함. 병렬접속을 위해서는 그림과 같이 모든 주소 비트들을 두 칩에 공통적으로 인가하며, 칩 선택 신호도 같은 것을 접속함.
그렇게 되면, 두 RAM 칩에서 동일한 위치에 있는 기억 장소들에게 같은 주소가 배정됨. 즉, 이 예의 경우에 두 칩의 첫 번재 기억 장소들에게 모두 '0000'번지가 배정되며, 다음 기억 장소에는 '0001', ..., 그리고 마지막 기억장소에는 '1111'번지가 배정됨. 결과적으로, 전체 주소 영역은 0000~1111번지가 됨. 그리고 RAM1의 데이터 입출력 선들은 상위 데이터 버스 선들과 접속하고, RAM2의 데이터 선들은 하위 데이터 버스 선들과 접속함. 이와 같이 구성하게 되면, 어떤 한 기억 장소가 선택되었을 때 각 칩에서 4비트씩, 전체적으로 8-비트 데이터가 동시에 입력 혹은 출력되는 것임.
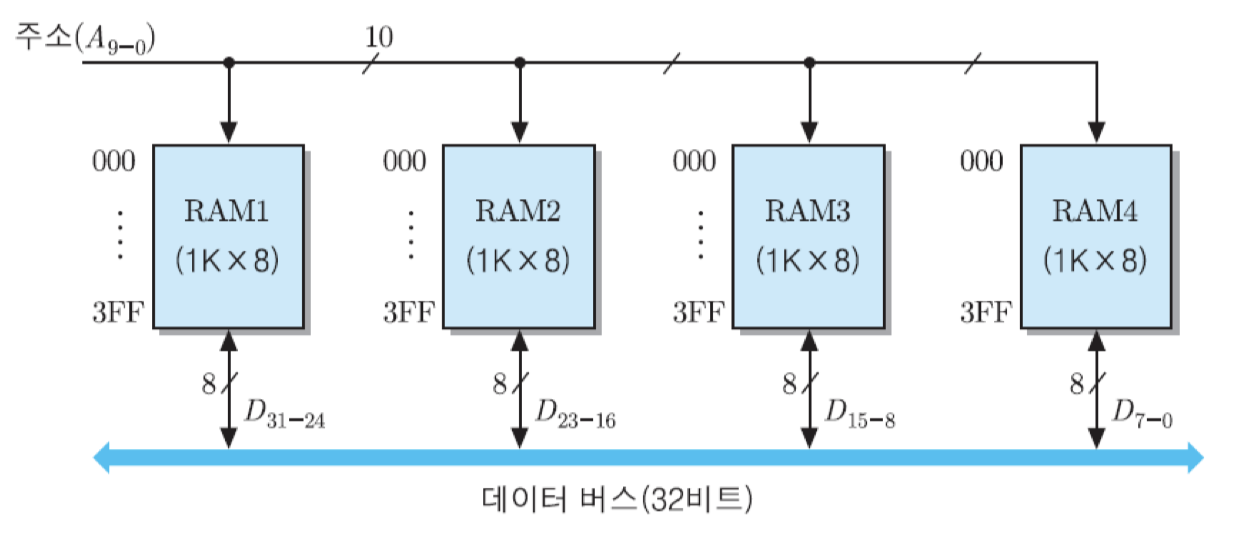
그림과 같이 32/8=4개의 RAM 칩들로 병렬로 접속하면 됨. 그렇게 접속하면, 모듈 내의 모든 칩들에 같은 주소를 가진 기억 장소들이 한 개씩 존재하게 됨. 이 경우에 각 주소에 저장될 32비트 데이터 중에서 최상위 8비트는 그림의 맨 좌측 칩에 저장하고, 그 다음 칩들에 순서대로 D23~D16, D15~D8, 그리고 맨 우측 칩에 최하위 비트들인 D7~D0를 각각 저장하면 됨.
직렬접속을 이용하여 기억 장소의 수를 확장하는 방법
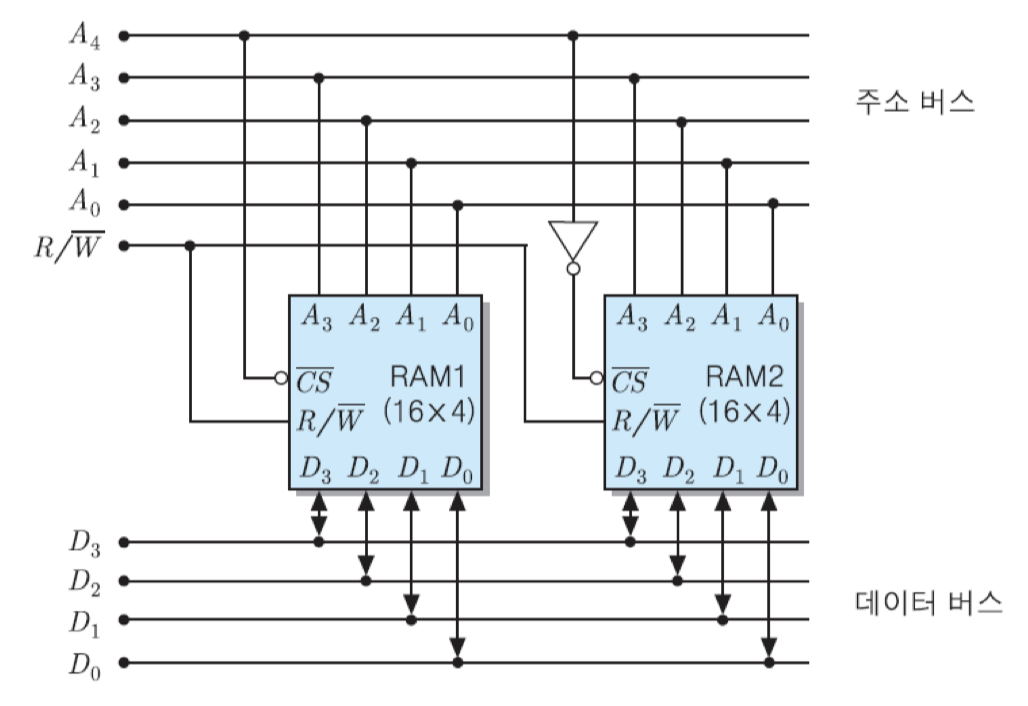
칩들을 직렬로 접속하기 위해서는 먼저 그림에서와 같이 최상위 주소 비트인 A4를 RAM1의 CS핀으로 인가하고, 그 비트를 반전시킨 값을 RAM2의 CS핀으로 연결함. 그런데 그림에서 보는 바와 같이 CS신호는 'active low'이기 때문에, 그 값이 '0'일 때 해당 칩이 선택됨. 따라서 A4 = 0일 때는 RAM1이 선택되고, A4 = 1일 때는 RAM2가 선택됨. 그리고 하위 주소 비트들은 두 RAM 칩들에 공통적으로 접속하여 칩 내부의 기억 장소들에 대한 주소를 지정하도록 함. 그렇게 구성하면 두 RAM 칩들에게는 각각 아래와 같은 주소 영역들이 배정됨.
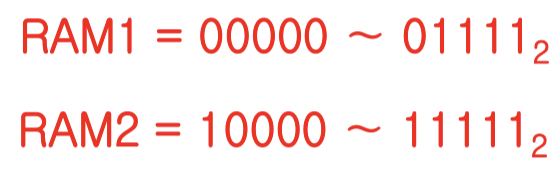
결과적으로, 전체 32개 기억 장소들의 주소는 00000번지부터 11111번지가 배정됨. 이 경우에 RAM 칩의 데이터 입출력 선들을 데이터 버스 선들과 공통으로 접속하게 되면, 각 주소가 인가될 때마다 해당 기억 장소가 위치한 RAM 칩으로부터 4비트씩 얽혀지거나 쓰여짐.
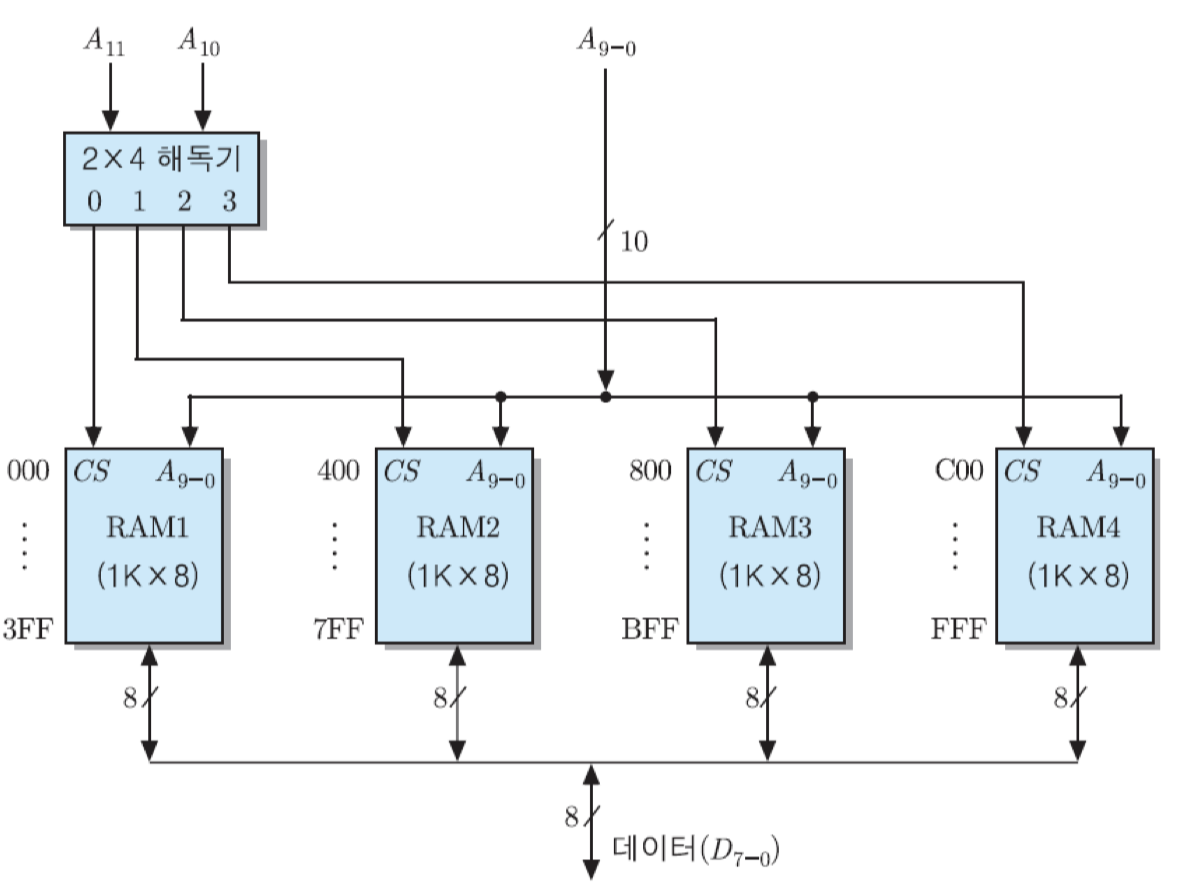
전체 용량이 4KByte가 되도록 하기 위해서는 모든 RAM 칩들이 순차적인 주소 영역을 가지도록 해야 함. 그와 같은 기억장치 모듈을 구성하기 위해서는 그림과 같이 네 개의 RAM 칩들을 직렬로 연결하면 됨.
이 경우에 기억장치 모듈의 전체 기억 장소 수는 4K=2의 12승=4096개가 되므로, 주소 비트는 12개가 필요하게 됨. 그런데 각 RAM 칩에는 1024개씩의 기억장소들이 존재하므로, 주소의 하위 10비트는 모든 칩들에 공통으로 접속해야함. 그리고 RAM 칩의 수가 모두 네 개이므로, 그들을 구분하기 위한 칩 선택 신호를 그 수만큼 발생해야 함. 따라서 주소 비트들 중에서 최상위의 두 비트들을 2x4 해독기로 접속하여, 네 개의 CS 신호들을 발생시킴. 그리고 그림에서와 같이 해독기의 첫 번째 출력은 RAM1의 CS 입력으로 연결하고, 두 번째 출력은 RAM2, 세 번재 출력은 RAM3, 그리고 네 번째 출력은 RAM4로 각각 연결함.
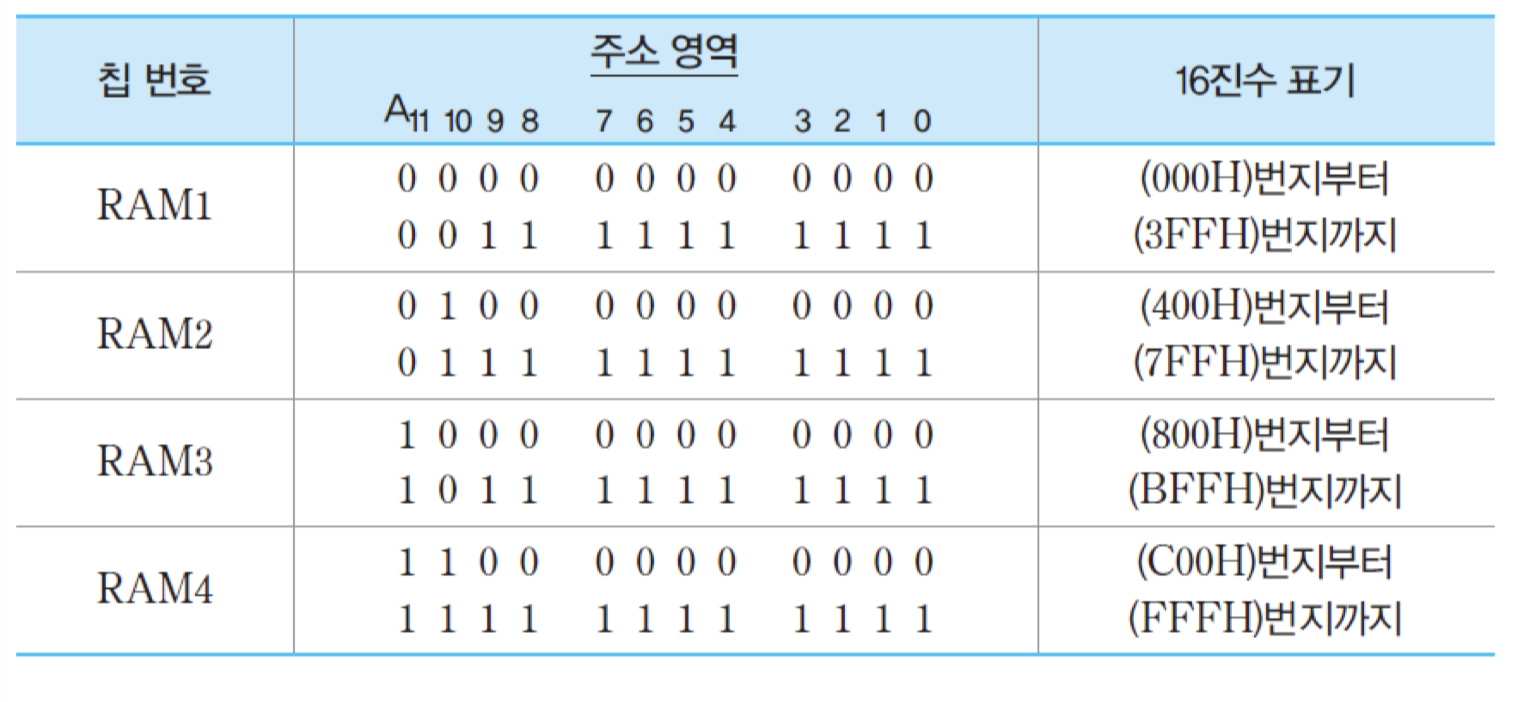
결과적으로, 직렬접속을 이용한 기억장치 모듈의 전체 구성도는 그림과 같아지며, 아래의 표는 각 칩에 배정되는 주소 영역들을 보여줌. 표에서 'H'는 해당 수가 16진수라는 것을 가리킴.
기억장치 모듈의 설계 순서
① 컴퓨터에 필요한 전체 기억장치 용량을 결정
② 사용가능한 칩들을 조사하고, 그들에 대한 주소 표를 작성
③ 세부적인 회로를 설계
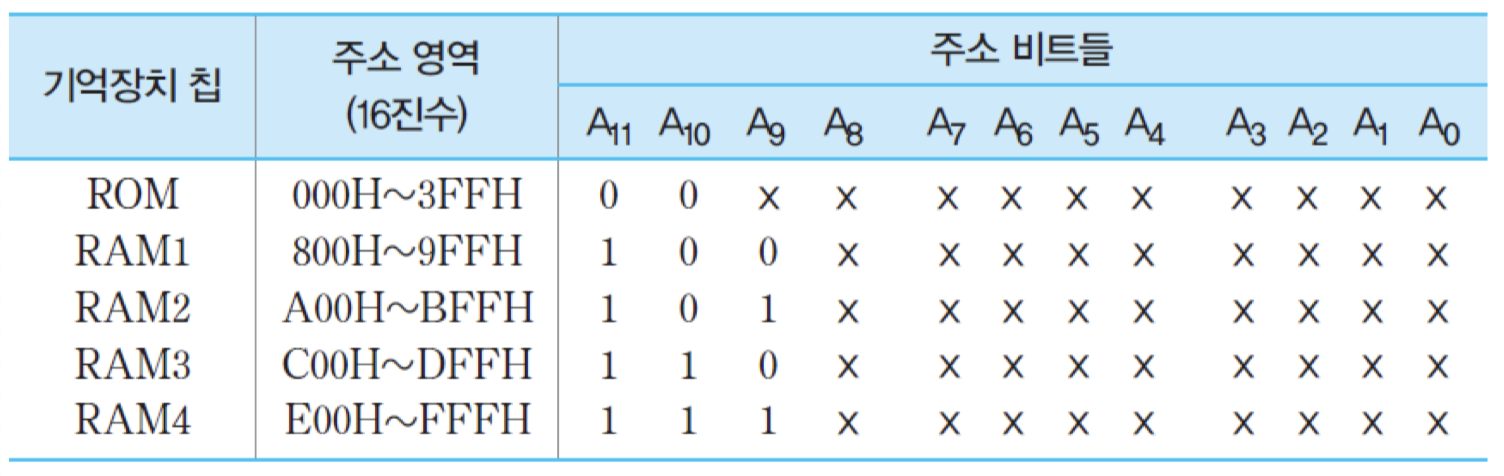
여기서 X는 0이나 1 중의 어느 값이든 가질 수 있다는 표시임.
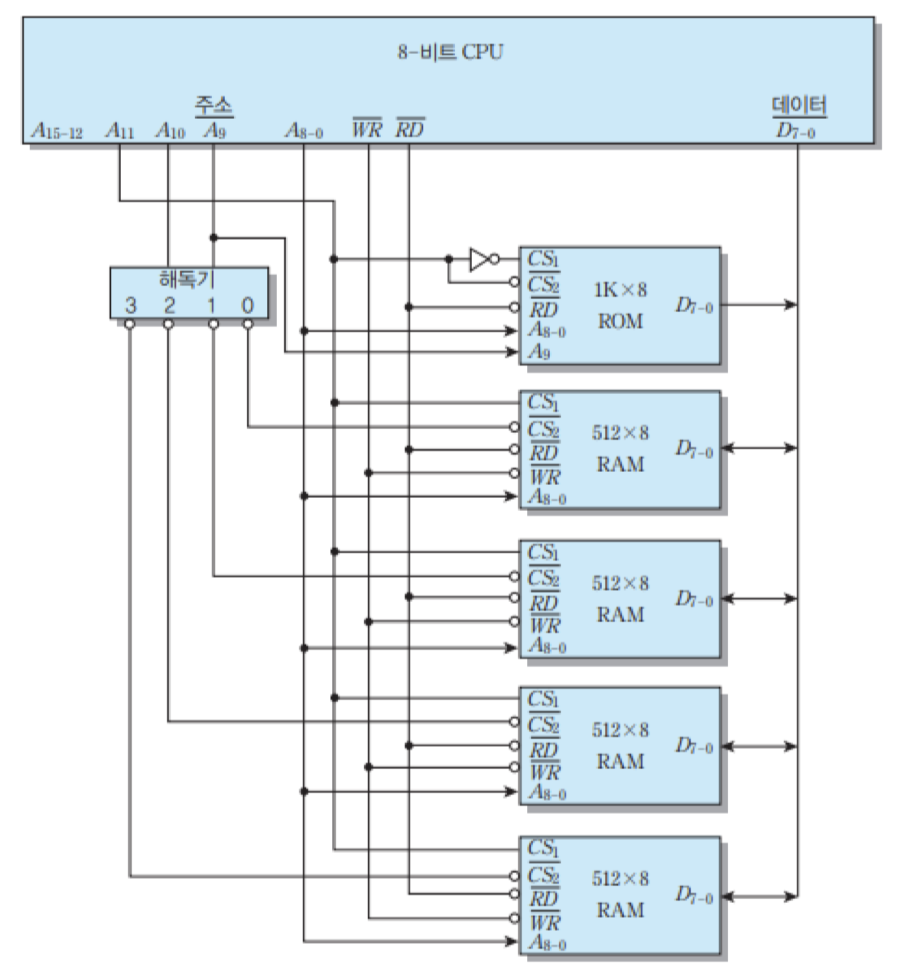
ROM 및 RAM 칩들이 주소 버스와 데이터 버스를 통하여 CPU와 접속된 모습을 보여주고 있음. 먼저, ROM으로는 주소의 하위 10비트들이 공급되어서 2의 10승 = 1024바이트 = 1K개의 바이트들 중의 하나를 선택하게 됨. 그리고 RAM 칩들은 각각 512개의 기억 장소들을 가지고 있으므로, 주소의 하위 9비트들을 공통으로 연결해주면 됨.
5.5 캐시 메모리
캐시 메모리 : CPU와 주기억장치의 속도 차이를 보완하기 위하여 그 사이에 설치하는 반도체 기억장치
특징 : 주기억장치보다 액세스 속도가 더 높은 칩 사용, 가격 및 제한된 공간 때문에 용량이 적음.
캐시 적중 : CPU가 액세스하려는 데이터가 이미 캐시에 적재되어 있는 상태
캐시 미스 : CPU가 액세스하려는 데이터가 캐시에 없어서 주기억장치로부터 인출해 와야하는 상태
캐시 적중률
캐시 적중률 : 전체 기억장치 액세스들 중에서 캐시에 적중되는 비율

미스율 = 캐시에 없을 확률 = (1 - H)
평균 기억장치 액세스 시간

지역성 : CPU가 주기억장치의 특정 위치에 저장되어 있는 명령어들이나 데이터를 빈번히 혹은 집중적으로 액세스하는 현상
• 시간적 지역성 : 최근에 액세스된 프로 그램이나 데이터가 가까운 미래에 다시 액세스 될 가능성이 높음
• 공간적 지역성 : 기억장치내에 인접하여 저장되어 있는 데이터들이 연속적으로 액세스 될 가능성이 높음
• 순차적 지역성 : 분기가 발생 하지 않는 한, 명령어들은 기억장치에 저장된 순서대로 인출되어 실행
캐시 설계에 있어서의 공통적인 목표
• 캐시 적중률의 극대화 : CPU가 원하는 정보가 캐시에 있을 확률을 높여야 함
• 캐시 액세스 시간의 최소화 : 캐시 적중 시에 캐시로부터 CPU로 정보를 인출해오는 데 걸리는 시간을 가능한 한 단축시켜야 함
• 캐시 실패에 따른 지연시간의 최소화 : 캐시 미스가 발생한 경우에 주기억장치로부터 캐시로 정보를 읽어오는 데 걸리는 시간을 최소화시켜야 함
• 주기억장치와 캐시간의 데이터 일관성 유지 및 그에 따른 오버헤드의 최소화 : CPU가 캐시의 내용을 변경하였을 때, 주기억장치에 그 내용을 갱신하는 절차 때문에 발생하는 지연 시간을 최소화시켜야 함
5.5.1 캐시 용량
용량이 커질수록 적중률이 높아지지만, 비용이 증가
용량이 커질수록 주소 해독 및 정보 인출을 위한 주변 회로가 더 복잡해지기 때문에 액세스 시간이 다소 더 길어짐
5.5.2 인출 방식
요구 인출 : 캐시 미스가 발생한 경우, CPU가 필요한 정보만 주기억장치로부터 캐시로 인출해오는 방식
선인출 : CPU가 필요한 정보 외에도 그와 인접해 있는 정보들을 함께 캐시로 인출해오는 방식
블록 : 주기억장치를 액세스할 때 함께 인출되는 정보들의 그룹
캐시 라인 : 주기억장치로부터 캐시로 인출되는 단위인 한 블록이 적재되는 캐시 내 공간
태그 : 캐시 라인을 공유하는 블록들 중에서 어느 것이 적재되어 있는지를 가리키는 비트들
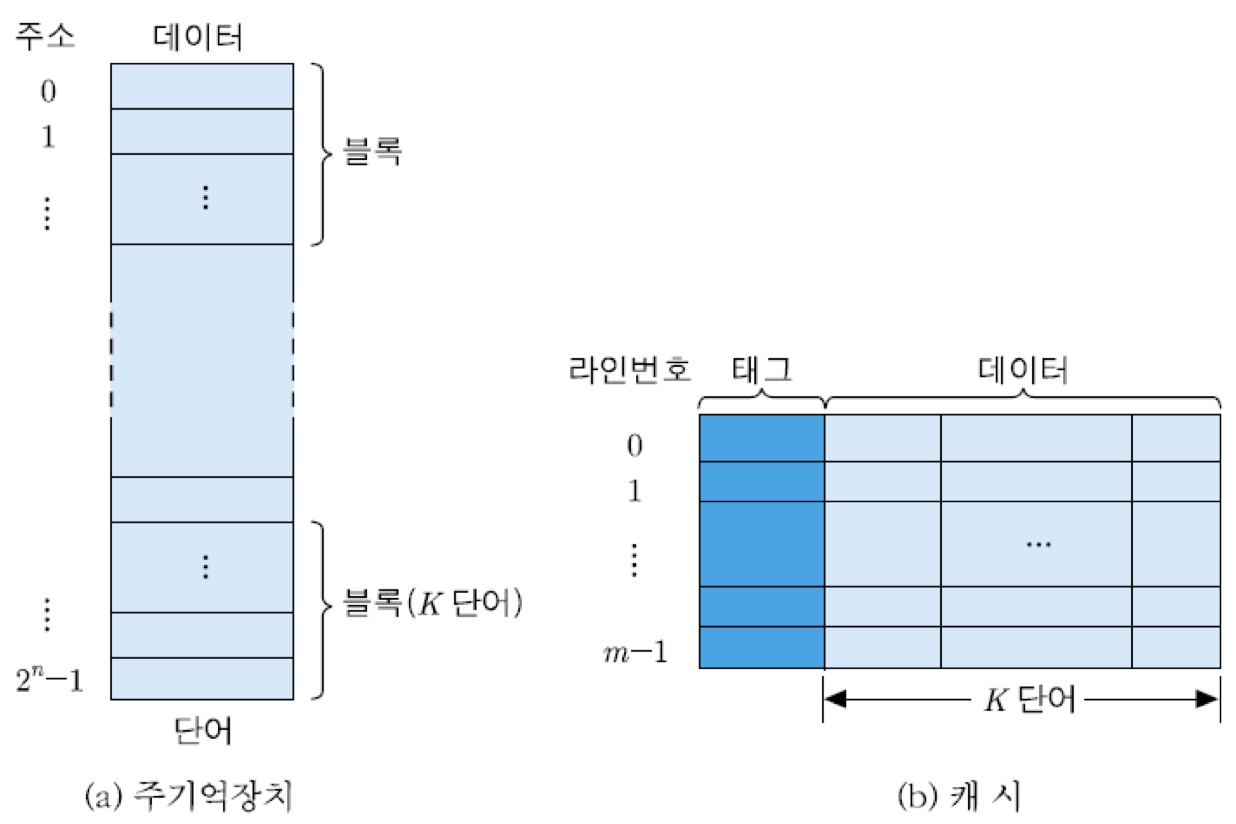
그림은 블록으로 나누어진 주기억장치와 그에 따른 캐시의 조직을 보여주고 있음. 주기억장치는 2의 n승개의 단어들로 구성되며, 각 단어는 n비트의 주소에 의해 지정됨. 선인출을 위하여 주기억장치를 K개의 단어들로 이루어진 블록으로 나눌 경우에 전체 블록들의 수는 2의 n승/K개가 됨.
5.5.3 사상 방식
사상 방식 : 주기억장치 블록이 어느 캐시 라인에 적재될 수 있는지를 결정해주는 알고리즘
사상 방식 세 가지
• 직접 사상
• 완전-연관 사상
• 세트-연관 사상
1) 직접 사상
주기억장치 블록이 지정된 어느 한 라인에만 적재될 수 있는 사상 방식

이 주소의 상위 (t+l) 비트들은 주기억장치의 2의 t+l승개의 블록들 중의 하나를 지정해줌. 그리고 최하위 w비트들은 2의 w승개의 단어들로 구성된 각 블록 내의 단어들을 구분하는 데 사용됨. 캐시 제어기는 최상위 t개의 비트들을 태그 번호로 해석하고, 그 다음 l개의 비트들은 라인 번호로 해석함. 라인 번호는 캐시의 m = 2의 l승개의 라인들 중에서 그 블록이 적재될 수 있는 라인을 지정해줌. 그리고 태그 번호는 같은 캐시 라인을 공유하는 주기억장치 블록들을 서로 구분하는 데 사용됨.
이 방식에서 주기억장치의 블록 j가 적재될 수 있는 캐시 라인의 번호 i는 식과 같은 모듈로 함수에 의해 결정됨.


각 캐시 라인은 2의 t승개의 블록들에 의해 공유됨. 따라서 어떤 블록이 지정된 라인에 적재되었을 때, 그 라인을 공유하는 다른 블록들과 구분될 수 있도록 하기 위하여 그 블록에 태그를 붙여야 함. 주기억장치의 주소의 태그 필드 비트들이 그 용도로 사용됨. 결과적으로, 캐시의 각 라인에는 태그와 데이터 블록이 함께 저장되며, 캐시 적중 여부는 주소의 태그 비트들과 라인에 저장된 태그 비트들을 비교함으로써 결정됨. 직접 사상 방식을 이용한 캐시의 내부 조직을 보면 아래의 그림과 같음.
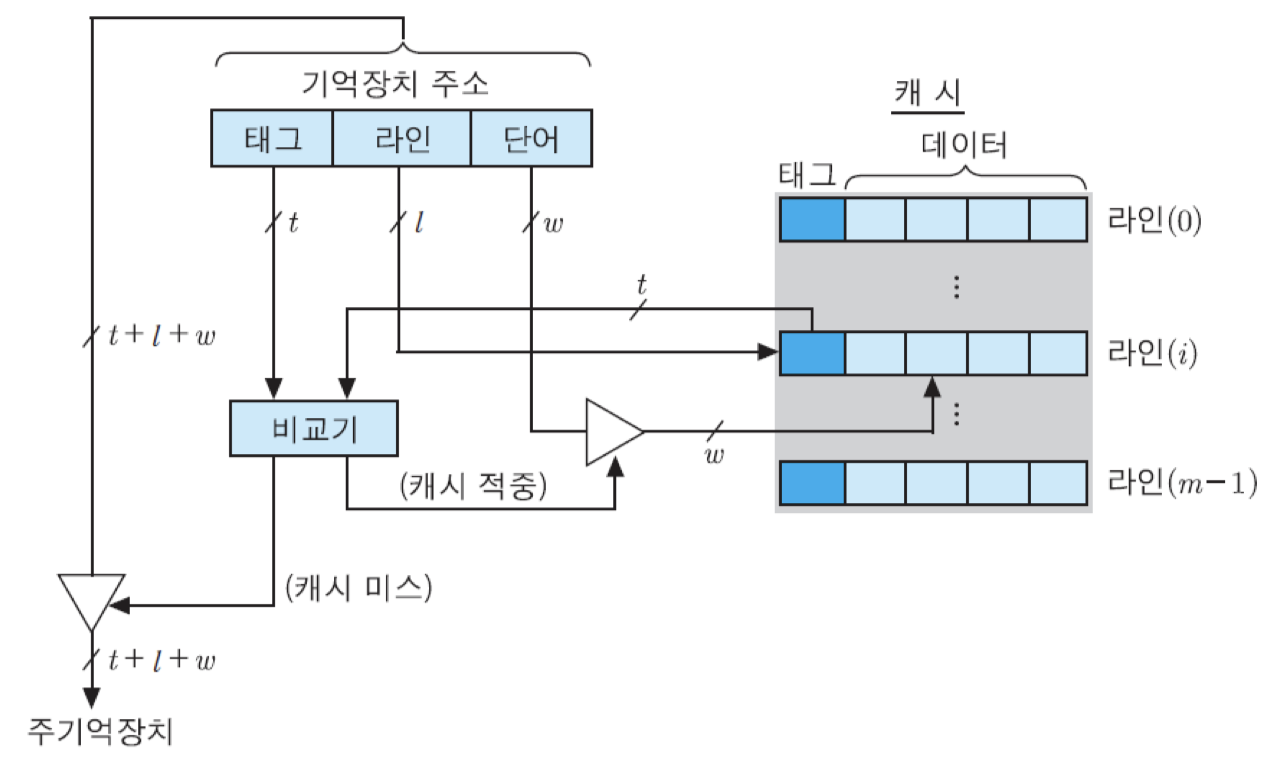
이 조직에서 읽기 동작은 다음과 같이 진행됨. 캐시로 기억장치 주소가 보내지면, 그 주소 비트들 중에서 라인 필드의 l비트들에 의해 캐시의 해당 라인이 선택됨. 그러면 선택된 라인의 태그 비트들이 읽혀져서 주소의 태그 비트들과 비교됨. 만약 그 두 태그값이 일치하면, 캐시가 적중된 것임. 그 경우에는 주소의 최하위에 있는 w개의 비트들을 이용하여 라인 내의 단어들 중에서 하나가 선택되고, 그 단어는 인출되어 CPU로 보내짐.
그러나 만약 태그값이 일치하지 않는다면 캐시가 미스 되었다는 것을 의미하므로, 기억장치 주소 전체가 주기억장치로 보내져서 한 블록을 인출해오게 됨. 인출된 블록은 지정된 캐시 라인에 적재되며, 주소의 태그 비트들이 그 라인의 태그 필드에 저장됨. 그런데 만약 그 라인을 공유하는 다른 블록이 이미 그 라인에 적재되어 있는 상태라면, 원래의 블록은 지워지고 새로이 인출된 블록이 적재됨.
주기억장치와 캐시의 예
• 주기억장치의 용량은 128바이트
-> 주기억장치의 주소는 7비트이며, 바이트 단위로 주소가 지정
• 단어의 길이는 한 바이트인 것으로 가정
• 주기억장치의 블록 크기를 4단어로 함
-> 블록의 수는 128/4 = 32개
• 캐시의 크기는 32바이트
• 주기억장치의 블록 크기가 4바이트이므로 캐시 라인의 크기도 4바이트가 되어야 하며, 결과적으로 라인의 수 m = 32/4 = 8개
이 예의 경우에 블록 내의 단어 수가 네 개이기 때문에 각 단어를 구분하기 위하여 w = 2비트가 필요하고, 라인의 수가 8개이므로 l = 3비트, 그리고 태그 필드는 나머지 2비트가 됨. 결과적으로 기억장치 주소의 각 필드는 다음과 같이 구성됨.

이 예에서 캐시 라인의 수 m = 8이므로, 각 기억장치 블록이 공유하게 될 캐시 라인의 번호는 i = j mod 8에 의해 결정됨. 따라서 직접 사상 방식을 적용했을 때 각 캐시 라인에 적재될 수 있는 주기억장치 블록들은 밑의 표와 같아짐.
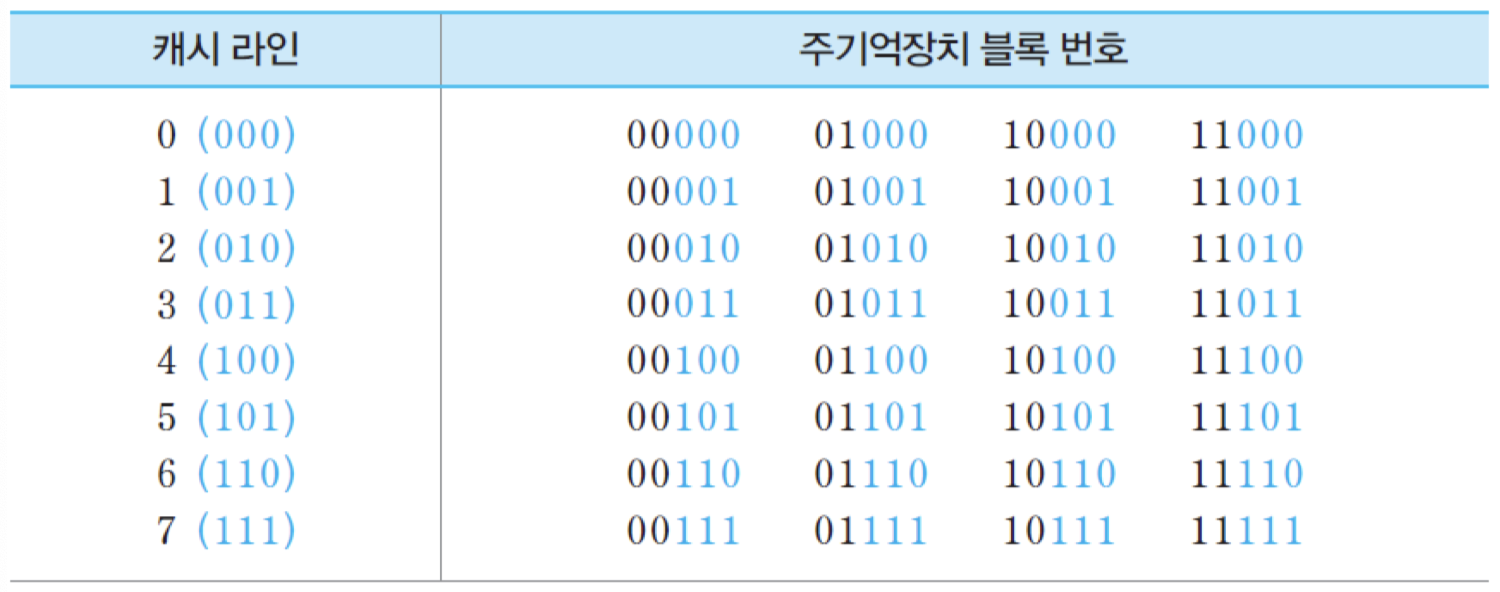
표에는 각 캐시 라인을 공유하는 네 개의 블록들의 번호가 나열되어 있음. 여기서 2진수로 표현된 블록 번호는 그 블록에 대한 기억장치 주소의 상위 5비트에 해당함. 각 블록은 네 개의 단어로 구성되므로, 블록 번호의 우측에 '00'을 추가하면 해당 블록의 첫 번째 단어의 주소가 됨. 표에서 보면, 각 캐시 라인을 공유하는 블록 번호의 하위 세 비트는 주기억장치 주소에서 라인 필드에 들어가는 비트들로서, 해당 캐시 라인 번호를 나타내는 비트들과 동일하다는 것을 알 수 있음.
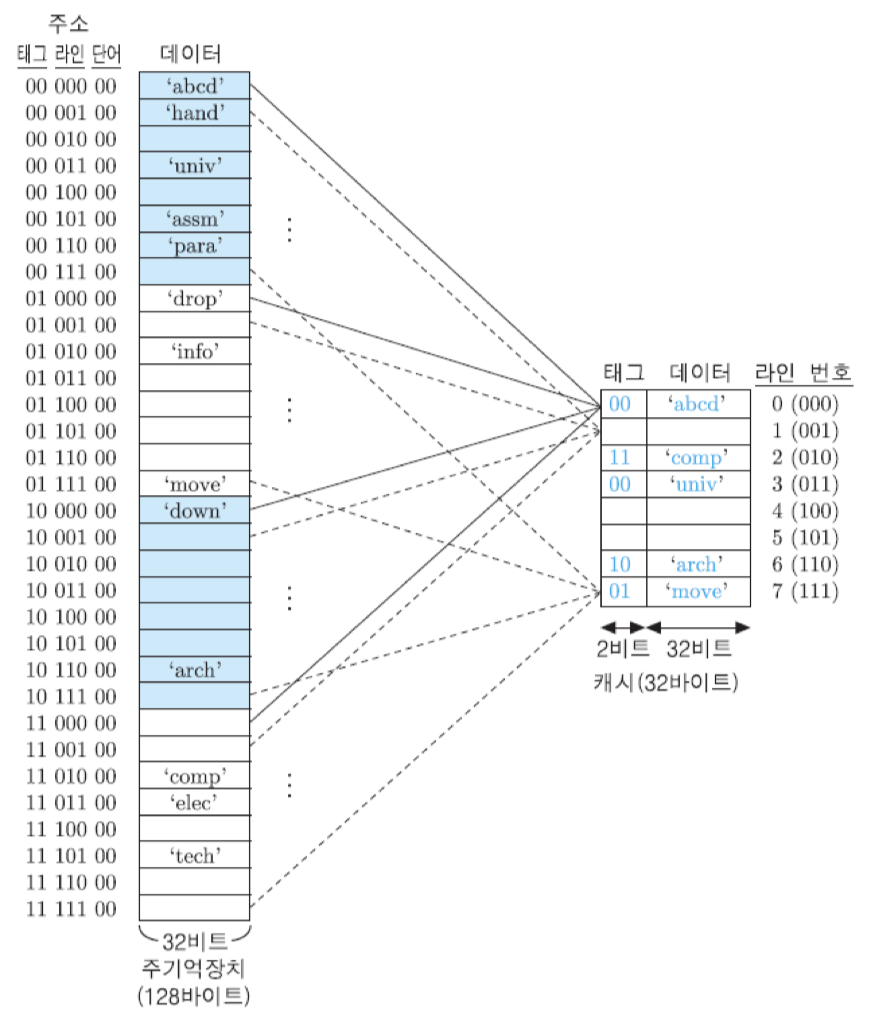
그림은 이 예에 직접 사상 방식을 적용한 경우의 기억장치 조직을 보여주고 있음. 주기억장치는 동일한 태그값을 가지는 블록들로 이루어진 네 개의 그룹으로 나눌 수 있음. 각 그룹은 8개의 블록들로 이루어지며, 각 블록에는 네 단어씩 저장됨. 7-비트 길이의 주기억장치 주소는 각 블록의 첫 번째 단어가 저장된 위치를 가리키기 때문에, 마지막 두 비트는 모두 '00'임.
그림에서 보는 바와 같이, 각 그룹의 첫 번재 블록들 네 개는 0번 캐시 라인을 공유하며, 두 번째 블록들은 1번 라인, 그리고 마지막 여덟 번째 블록들은 7번 라인을 공유함. 이러한 공유 관계는 표에서와 마찬가지로 이 그림에서도 각 기억장치 주소의 두 번째 필드인 라인 비트들과 해당 캐시 라인의 번호를 나타내는 비트들이 동일하다는 것을 통하여 다시 확인될 수 있음.
직접 사상 방식의 장단점
장점 : 간단하고, 구현하는 비용이 적게 듦
단점 : 각 주기억장치 블록이 적재될 수 있는 캐시 라인이 한 개뿐임.
-> 만약 어떤 프로그램의 수행 과정에서 같은 라인에 사상되는 두 개의 블록들로부터 데이터들을 번갈아 읽어와야 한다면, 그 블록들은 캐시에서 반복적으로 교체될 것이고, 결과적으로 적중률이 낮아짐.
2) 완전-연관 사상
주기억장치 블록이 캐시의 어느 라인으로든 적재될 수 있는 사상 방식

캐시 액세스 과정에서 주기억장치 주소가 태그 필드와 단어 필드로만 구성된 것으로 해석됨.
결과적으로, 태그값이 주기억장치 블록 번호와 같아짐. 따라서 어떤 블록이 캐시로 적재될 때, 그 주소의 태그 필드의 모든 비트들이 그 라인의 태그 부분에 저장되어야 함.
이 방식에서는 주기억장치 블록이 캐시의 어떤 라인에든 적재될 수 있으므로, 캐시 적중 여부를 검사할 때는 캐시의 모든 라인들의 태그들과 주기억장치 주소의 태그 필드 내용을 비교하여 일치하는 것이 있는 지 확인해야함. 만약 일치하는 라인이 있다면 캐시가 적중된 것이므로, 단어 필드의 값을 이용하여 그 라인에 저장되어 있는 단어들 중의 하나를 인출하여 CPU로 전송함. 그러나 만약 태그가 일치하는 라인이 없다면, 캐시 미스가 발생한 것임. 이 경우에는 주소를 주기억장치로 보내어 해당 단어가 포함된 블록을 인출해 옴.
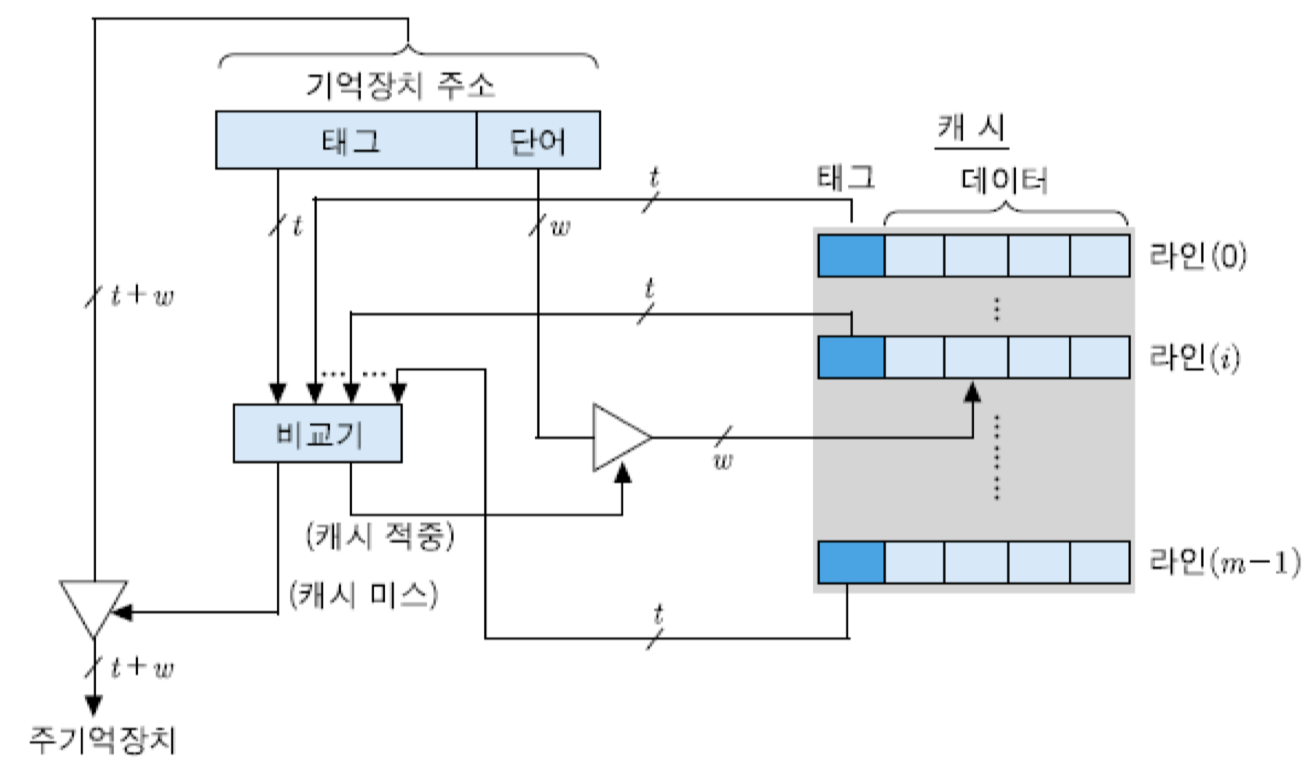
그림은 이 방식을 위한 캐시 조직을 보여주고 있음. 그림에서 보는 바와 같이 기억장치 주소의 태그 비트들은모든 캐시 라인의 태그들과 비교되어야 함. 그런데 이 비교를 하나씩 순차적으로 수행하면 많은 시간이 걸릴 것이므로, 5.1절에서 설명하였던 연관 기억장치 등을 이용하여 비교 동작이 병렬로 신속히 이루어질 수 있도록 하드웨어가 구성되어야 함. 만약 어떤 라인의 태그값도 일치하지 않는다면, 그것은 캐시 미스를 의미하므로 주기억장치 액세스가 시작됨. 그렇지 않다면, 단어 필드의 값을 이용하여 그 라인으로부터 한 단어를 인출하여 CPU로 보냄.
이 방식에서는 주기억장치로부터 인출된 데이터 블록을 캐시의 어느 라인에 적재할 것인지를 결정해야 함. 캐시에 빈 라인들이 있다면, 라인 번호에 따라 차례대로 적재하면 됨. 그런데 만약 비어 있는 라인 없이 캐시가 완전히 채워진 상태일 때 새로운 블록이 인출되어 온다면, 적절한 교체 알고리즘을 이용하여 라인들 중의 하나를 선택한 다음에 새로운 블록을 적재해야 함. 이때 그 라인에 먼저 적재되어 있던 블록은 지워지게 됨. 따라서 만약 그 블록이 캐시에 적재되어 있던 동안에 새로운 내용으로 변경된 적이 있었다면, 그 블록을 주기억장치에 갱신한 다음에 새로운 블록을 그 라인에 적재해야 함. 물론 변경된 적이 없다면 그런 과정은 필요하지 않음. 라인들 중에서 교체될 라인을 선택하는 방법으로는 여러 가지가 있음. 예를 들어, 적재된 지 가장 오래된 블록이 저장되어 있는 라인을 선택할 수도 있고, 최근에 액세스된 횟수가 가장 적은 라인을 선택할 수도 있음.
직접 사상에서 사용하였던 예에 완전-사상 방식을 적용

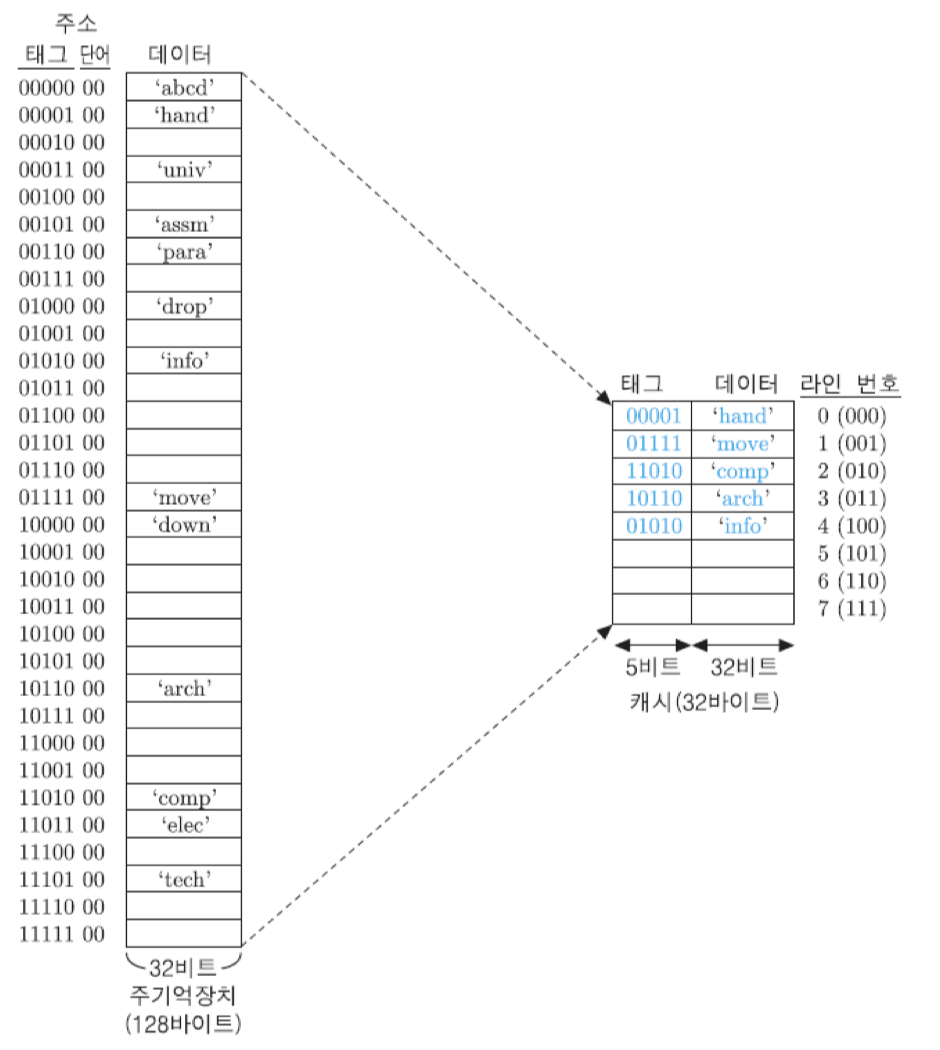
그림은 완전-연관 사상을 적용한 기억장치 조직과 실제 몇몇 블록들이 캐시에 적재되어 있는 예를 보여주고 있음. 주기억장치 블록들은 비어있는 어느 캐시 라인에든 적재될 수 있으며, 5-비트 태그가 캐시의 각 라인에 32-비트 데이터 블록과 함께 저장된다는 것을 확인할 수 있음.
그림에서 현재 캐시에 적재되어 있는 블록들은 다음과 같음. 0번 라인에는 0000100번지의 블록, 1번 라인에는 0111100번지의 블록, 2번 라인에는 1101000번지의 블록, 3번 라인에는 1011000번지의 블록, 그리고 4번 라인에는 0101000번지의 블록이 각각 적재되어 있음. 각 라인의 태그 부분에는 주소의 단어 필드를 제외한 상위 5비트가 저장되어 있어서, 어느 블록이 적재되어 있는 지를 가리키고 있음. 여기서 캐시에 적재된 블록들의 주소와 그들이 적재된 라인들의 번호 사이에는 아무런 상관이 없다는 것을 알 수 있음. 이 시점에서는 0번 라인부터 4번 라인까지 채워져 있고, 아래 세 개의 라인들은 비어있는 상태임. 이때 만약 새로운 블록이 캐시로 적재된다면, 비어있는 첫 번재 라인인 5번 라인이 사용됨.
완전-연관 사상 캐시의 장단점
장점
• 새로운 블록이 캐시로 적재될 때 라인의 선택이 매우 자유로움
• 지역성이 높다면, 적중률이 매우 높아짐
단점
• 캐시 라인들의 태그들을 병렬로 검사하기 위하여 가격이 높은 연관 기억장치 및 복잡한 주변 회로가 필요
3) 세트-연관 사상
주기억장치 블록이 지정된 어느 한 세트로만 적재될 수 있으며, 각 세트는 두 개 이상의 라인들로 구성된 사상 방식
캐시는 먼저 v개의 세트들로 나누어지며, 각 세트는 k개의 라인들로 구성됨. 따라서 전체 캐시 라인의 수 m과 그 변수들 간의 관계는 m = v x k와 같아지며, 각 주기억장치 블록이 적재될 수 있는 캐시 세트의 번호 i는 아래의 식에 의해 결정됨.

각 세트에 라인이 두 개가 있는 경우를 2-way 세트-연관 사상이라고 말하며, 네 개가 있는 경우를 4-way 세트-연관 사상이라고 말함. 즉, 세트당 라인이 k개씩 있으면 k-way 세트-연관 사상이라고 부름.
세트-연관 사상을 사용하면 주기억장치의 블록 Bj는 지정된 세트 i 내의 어떤 라인으로든 사상될 수 있음. 이 경우에 캐시 제어회로는 주기억장치 주솔ㄹ 다음과 같은 세 개의 필드로 나누어 해석함.

여기서, s개의 세트 비트들은 캐시의 v = 2의 s승개 세트들 중에서 해당 주기억장치 블록이 적재될 수 있는 세트를 선택하는 데 사용되고, 태그 필드의 t비트들은 그 세트 내에 있는 라인들의 태그들과 비교되어 캐시 적중 여부를 확인하는 데 사용됨.
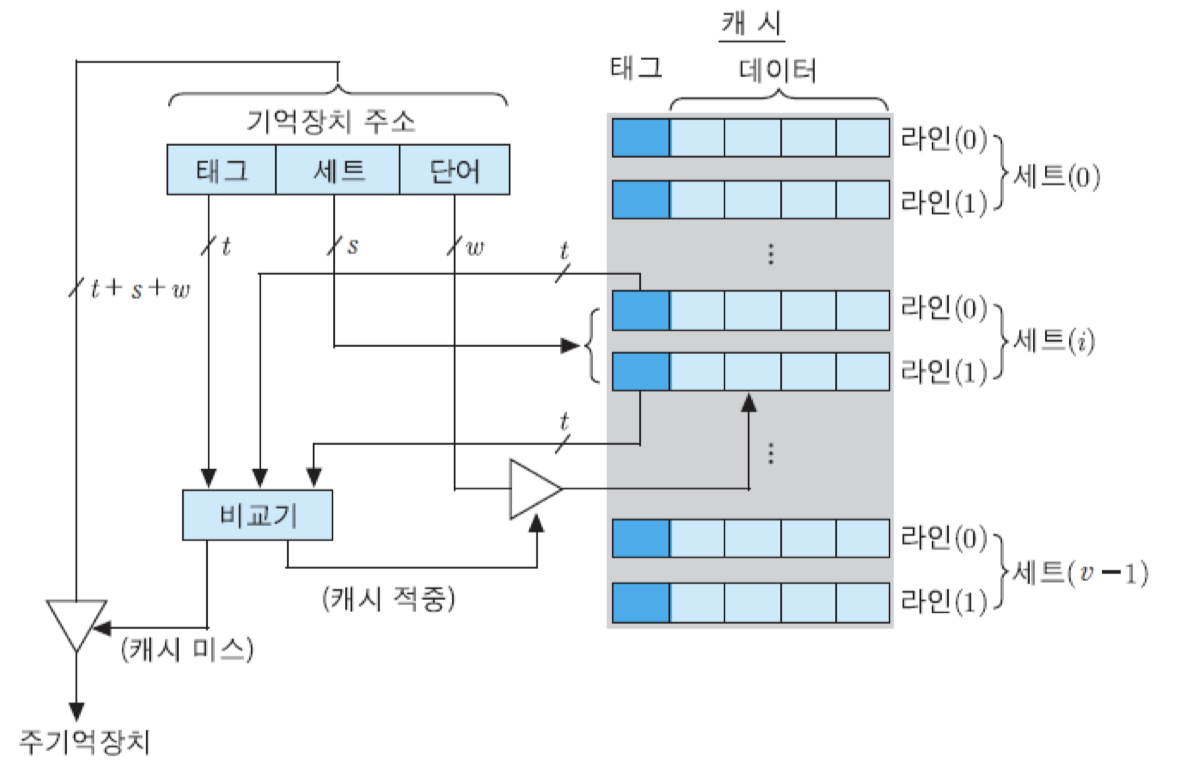
그림은 캐시의 각 세트가 두 개의 라인들로 구성된 경우, 즉 2-way 세트-연관 사상 캐시의 조직을 보여주고 있음. 그림에서 보는 바와 같이, 지정된 세트에 포함된 라인의 태그들이 기억장치 주소의 태그와 비교됨. 만약 일치되는 태그가 있다면, 캐시가 적중된 것이므로 w개의 비트에 의해 그 라인 내 2의 w승개의 단어들 중 하나가 선택되어 인출됨. 그러나 만약 그 세트 내 어느 라인의 태그와도 일치하지 않는다면, 캐시가 미스 된 것이므로 주기억장치 액세스가 시작됨.
이 방식을 사용하면 주기억장치 블록은 지정된 어느 한 세트에 적재될 수 있음. 그런데 각 세트에는 다수의 라인들이 있으므로, 직접 사상 방식에 비하여 기억장치 블록이 적재될 수 있는 공간이 더 많아짐. 그러나 캐시의 전체 용량은 고정되어 있기 때문에 세트의 수는 그만큼 감소함.
앞에서 사용하였던 예에 2-way 세트-연관 사상 방식을 적용

각 세트를 공유하는 주기억장치 블록들
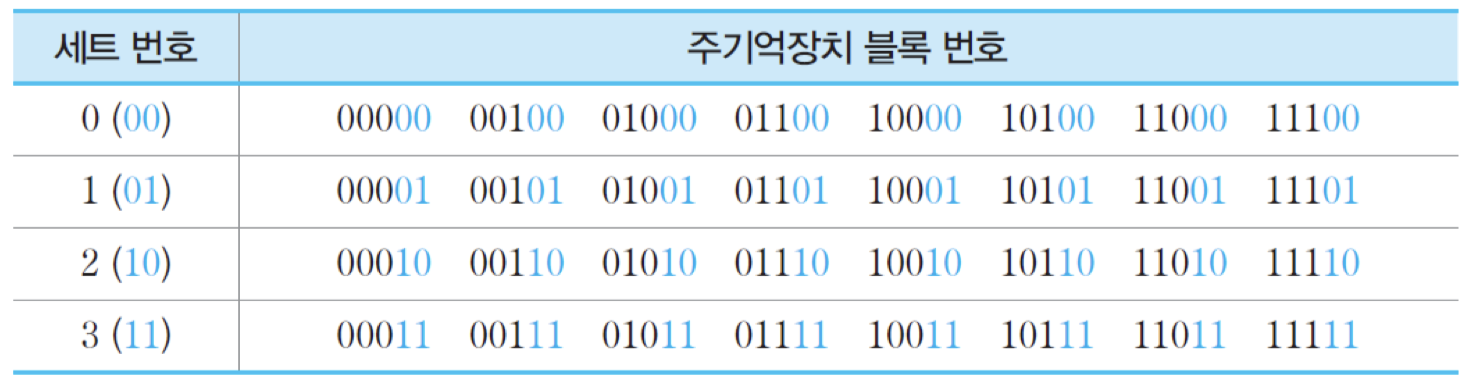
표를 보면, 주기억장치 블록 번호의 하위 두 비트가 '00'인 블록들은 모두 0번 세트를 공유하며, '01'인 블록들은 1번 세트, '10'인 블록들은 2번 세트, 그리고 '11'인 블록들은 3번 세트를 공유한다는 것을 알 수 있음. 그리고 각 세트를 공유하는 8개의 블록들은 앞의 세 비트들, 즉 태그값에 의해 구분될 수 있다는 것을 확인할 수 있음. 같은 세트를 공유하는 블록들 중의 두 개는 세트 내 두 라인들 중의 어느 곳에든 동시에 적재될 수 있음.
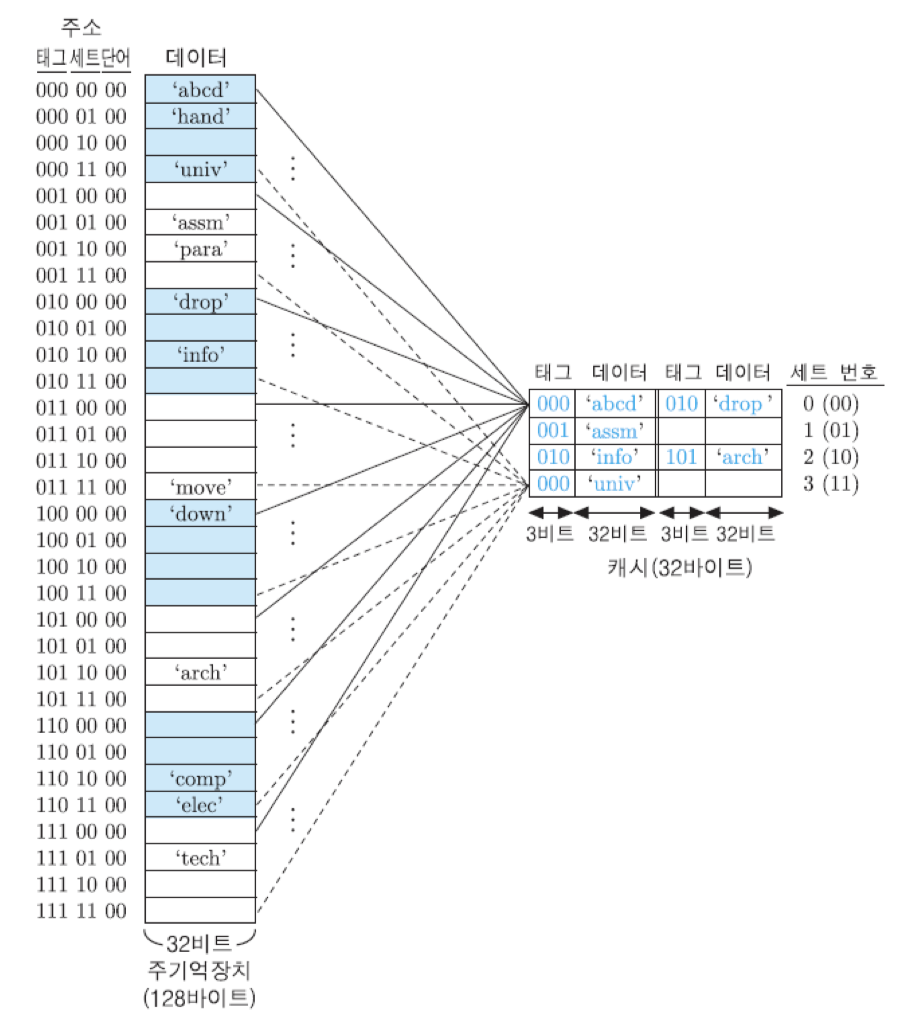
그림은 그와 같은 2-way 세트-연관 사상을 위한 조직과 사상 관계를 보여주고 있음. 먼저 주기억장치는 주소의 상위 세 비트, 즉 태그 값이 동일한 네 블록씩 모두 8개의 그룹으로 나누어짐. 각 그룹의 첫 번째 블록들이 0번 세트를 공유하며, 두 번째 블록들은 1번 세트, 세 번째 블록들은 2번 세트, 마지막 네 번째 블록들은 3번 세트를 공유함. 이와 같은 세트 번호는 주소의 중간에 위치한 두 개의 세트 비트들에 의해 지정됨. 그룹이 모두 8개이므로, 각 세트는 8개의 블록들에 의해 공유되는 것임.
그림에는 몇몇 블록들이 실제 캐시에 적재되어 있는 예를 보여주고 있는데, 0번 세트의 첫 번째 라인에는 0000000번지의 블록이 적재되어 있고, 두 번째 라인에는 0100000번지의 블록이 적재되어 있음. 이때 만약 0번 세트를 공유하는 다른 블록이 캐시로 인출되어 온다면, 적절한 교체 알고리즘에 의하여 두 라인 중의 하나를 선택한 다음에 그 라인에 새로운 블록을 적재하게 됨. 이 경우에, 먼저 있던 블록은 지워짐. 1번과 3번 세트에는 현재 한 라인씩만 블록이 적재되어 있고, 다른 라인은 비어있음. 따라서 주기억장치로부터 새로운 블록이 인출되는 경우에는 그 세트의 빈 라인으로 적재될 것임.
CPU에 의해 기억장치 주소가 발생되어 캐시 액세스 동작이 시작되면, 먼저 2-비트 세트 번호를 이용하여 세트를 선택함. 그런 다음에는 그 세트 내 라인들의 태그 중에서 기억장치 주소의 태그와 일치하는 것이 있는 지 검사함. 만약 태그가 일치하는 라인이 있다면, 캐시가 적중된 것이므로 최하위 두 비트들을 이용하여 그 라인에 저장된 네 단어들 중의 하나를 선택하여 인출함. 만약 세트 내의 어느 태그도 주소의 태그와 일치하지 않는다면, 캐시 미스가 발생한 것이므로 주기억장치 액세스가 시작됨.
실제 시스템에서 사용되고 있는 기억장치 및 캐시의 용량에 대하여, 세트-연관 사상 방식으로 캐시 조직을 구성하고 분석
• 주기억장치의 용량은 16M바이트
-> 주기억장치의 주소는 24비트, 바이트 단위로 주소가 지정
• 주기억장치는 4-바이트 크기의 블록들 4M개로 구성. 그리고 단어의 길이는 한 바이트
• 캐시의 용량은 64K바이트
• 주기억장치의 블록 크기가 4바이트이므로 캐시 라인의 크기도 4바이트가 되어야 하며, 결과적으로 라인의 수 m = 16K개
2-way 세트-연관 사상 방식을 사용한다면, 기억장치 주소는 아래와 같이 세 개의 필드들로 나누어짐

캐시에는 전체적으로 2의 14승개의 라인들이 있지만, 그들이 2의 13승개의 세트들로 나누어지므로 각 세트에는 라인이 두 개씩 있게 됨. 따라서 13비트의 세트 번호는 세트들 중의 하나를 선택해줌. 주소의 태그 필드는 9비트이므로 각 세트를 공유하는 블록들의 수는 2의 9승 = 512개이며, 그들 중의 두 개가 동시에 그 세트 내에 적재되어 있을 수 있음.
각 세트를 공유하는 주기억장치 블록들
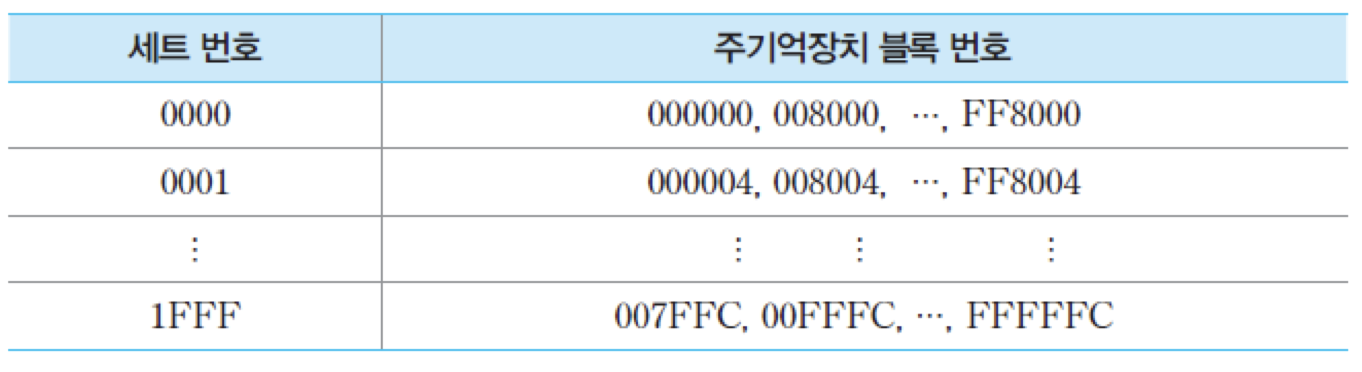
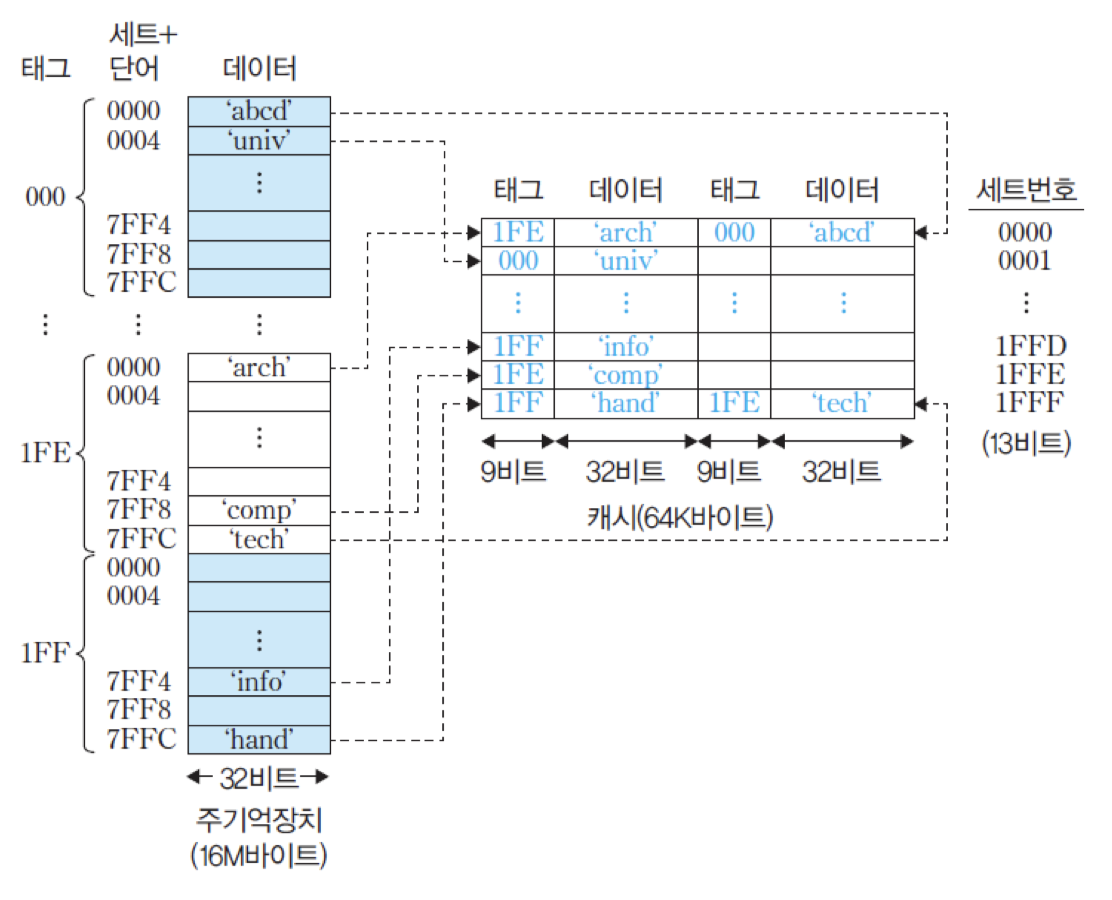
그림은 이와 같은 2-way 세트-연관 사상을 위한 조직을 보여주고 있음. 주기억장치에는 같은 태그값을 가지는 블록들이 캐시의 세트 수와 같은 8K개씩 있음. 예를 들어, 태그가 16진수로 '000'인 블록들이 그 수만큼 있으며, 각각 다른 태그를 가지는 그러한 그룹들이 모두 512개가 있음. 같은 태그를 가지는 블록들은 서로 다른 캐시 세트를 공유함. 따라서 캐시의 각 세트는 512개의 블록들에 의해 공유됨. 즉, 512개의 블록들이 지정된 세트 내의 두 라인들 중 어느 곳으로 적재될 수 있음.
세트-연관 사상에서 만약 세트의 수가 캐시 라인의 수와 같고, 세트 내 라인의 수 k=1이라면, 이 방식은 직접 사상과 같아짐. 또한, 만약 세트의 수 v=1이고, 세트 내 라인 수가 캐시의 전체 라인 수와 같다면, 완전-연관 사상에 해당함.
5.5.4 교체 알고리즘
LRU 알고리즘 : 세트 라인에 적재되어 있는 블록들 중에서 최근의 사용 빈도가 가장 낮은 블록을 선택하여 교체하는 방식
FIFO 알고리즘 : 캐시에 적재된 지 가장 오래된 블록을 교체하는 방식
LFU 알고리즘 : 캐시에 적재된 이래 사용된 빈도가 가장 낮은 블록을 교체하는 방식
5.5.5 쓰기 정책
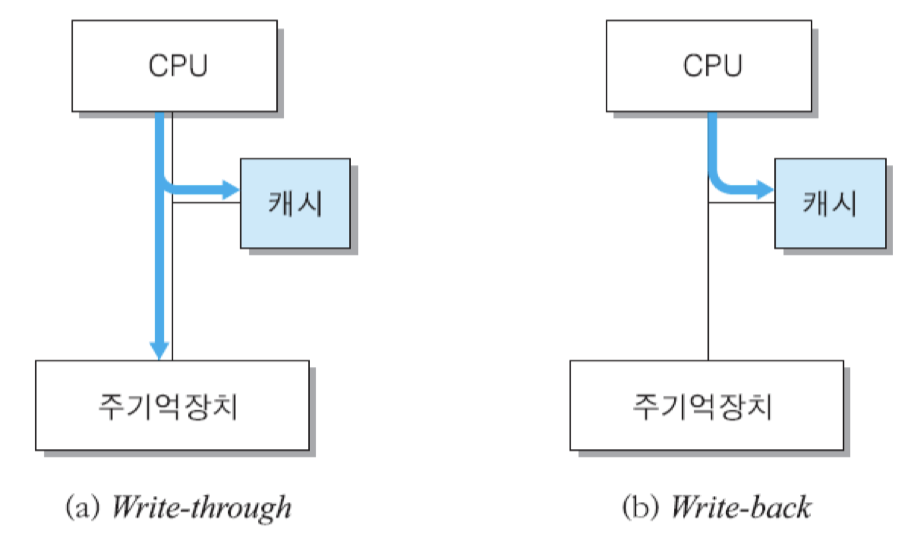
쓰기 정책 : 캐시에 적재된 데이터를 새로운 값으로 변경할 때 주기억장치에 갱신하는 시기와 방법을 결정하는 방식
• write-through : 캐시에 쓰기 동작을 수행할 때 주기억장치에도 동시에 이루어지는 방식
장점 : 캐시에 적재된 블록의 내용과 주기억장치에 있는 그 블록의 내용이 항상 같음
단점 : 모든 쓰기 동작이 주기억장치 쓰기를 포함하므로, 쓰기 시간이 길어짐
• write-back : 쓰기 동작이 캐시까지만 이루어지는 방식
장점 : 기억장치에 대한 쓰기 동작의 횟수가 최소화되고, 쓰기 시간이 짧아짐
단점 : 캐시의 내용과 주기억장치의 해당 내용이 서로 다름
-> 캐시의 데이터가 수정된 적이 있는 경우에는, 블록을 교체할 때 주기억장치에 갱신하는 동작이 선행되어야 하며, 그를 위해 각 캐시 라인이 상태 비트를 가지고 있어야 함
상태 비트 = 0 : 유효
= 1 : 수정
5.5.6 다중 캐시
1) 온-칩 캐시와 계층적 캐시
온-칩 캐시 : CPU 칩 내부에 포함되어 있는 캐시
계층적 캐시 : 여러 레벨의 캐시들을 계층적으로 설치한 구조
온-칩 캐시를 1차 캐시로 사용하고, 칩 외부에 더 큰 용량의 2차 캐시를 추가로 설치하는 방식
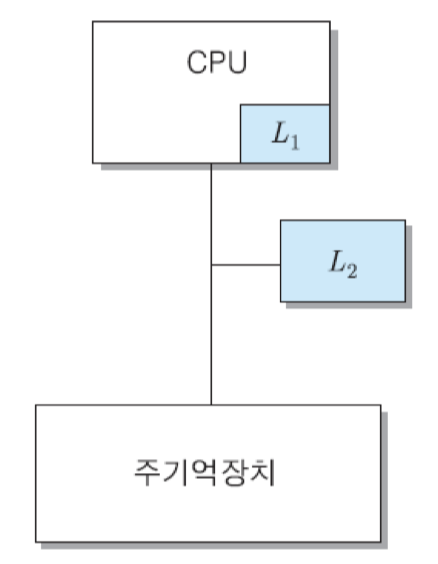
L2는 L1의 슈퍼-세트 : L2의 용량이 L1보다 크며, L1의 모든 내용이 L2에도 존재
먼저 L1을 검사하고, 만약 원하는 정보가 L1에 없다면, L2를 검사하며, L2에도 없는 경우에는 주기억 장치를 액세스
L1은 속도가 빠르지만 용량이 작기 때문에, L2보다 적중률은 더 낮음
2-단계 캐시 시스템의 평균 기억장치 액세스 시간
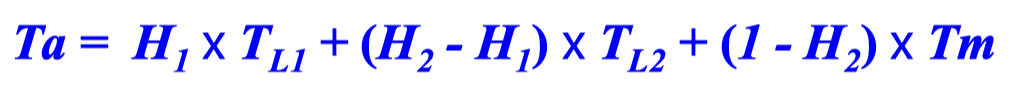
L1의 액세스 시간과 적중률 : TL1, H1
L2의 액세스 시간과 적중률 : TL2, H2
단, H2는 전체 기억장치 액세스들에 대한 L2의 적중률을 의미
주기억장치의 액세스 시간 : Tm
H2가 L1에서 미스 된 액세스들에 대한 L2의 적중률
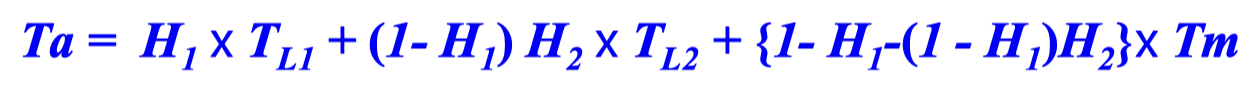
2) 분리 캐시
명령어 캐시 : 온-칩 캐시를 명령어만 저장
데이터 캐시 : 데이터만 저장
분리 캐시 : 명령어와 데이터를 분리하여 별도로 저장하는 캐시 구조
5.6 DDR SDRAM
CPU는 반도체 기술의 발달과 내부 구조의 개선을 통하여 속도가 계속 높아지고 있지만, 기억장치의 속도는 그 상승률을 따라가지 못하고 있음. 수십 년 전부터 주기억장치로 사용되어 온 DRAM은 집적도가 높아져 칩 당 용량은 증가하고 있지만, 액세스 속도는 CPU에 비하여 현저히 떨어지고 있음. 동영상 처리나 음성/영상 압출 등과 같이 대규모 데이터가 연속적으로 CPU와 주기억장치 사이에 전송되어야 하는 최근의 컴퓨터 응용 환경 속에서, 주기억장치 속도로 인한 병목은 반드시 해결되어야 할 문제임
-> 문제점을 극복하거자 여러 가지 새로운 기술들이 개발
SDRAM, DDR SDRAM
5.6.1 SDRAM
동기식 DRAM(SDRAM) : 액세스 및 데이터 전송 동작이 시스템 클록 신호에 동기화되어 수행되는 DRAM
DRAM에서는 필요한 정보와 제어 신호가 들어오는 즉시 액세스 동작을 수행하여 응답함. 즉, 쓰기 동작에서는 전송된 데이터를 즉시 해당 기억 장소에 저장하며, 읽기 동작에서는 인출 동작을 수행한 다음에 즉시 데이터를 버스를 통해 전송함. 그런데 DRAM 에서는 이러한 기억장치 액세스 동작들이 연속적으로 발생하기 때문에, CPU는 그 시작 순간부터 종료될 때까지 다른 일을 하지 못하고 기다려야 함. 또한 그 동안 시스템 버스도 다른 용도로는 사용될 수 없음. 따라서 DRAM의 액세스 속도가 느린 경우에는 시스템의 전체 동작 시간이 지연됨.
반면에, SDRAM을 사용하는 시스템에서는 기억장치 액세스를 위한 동작들이 시스템 클록 신호에 맞추어 수행됨.
ex) 읽기 동작
① CPU는 한 클록 주기 동안에 시스템 버스를 통하여 주소와 읽기 신 호를 기억장치로 보낸 후, 그 결과를 기다리지 않고 내부적으로 다 른 연산을 수행
② SDRAM은 주소와 읽기 신호를 받은 즉시 읽기 동작을 시작하며, 그 동작이 완료되면 시스템 버스 사용권을 획득한 후, 다음 클록 주기 동안에 버스를 통하여 CPU로 데이터 전송
③ CPU는 그 데이터를 받아서, 다음 연산을 수행
SDRAM의 내부 조직
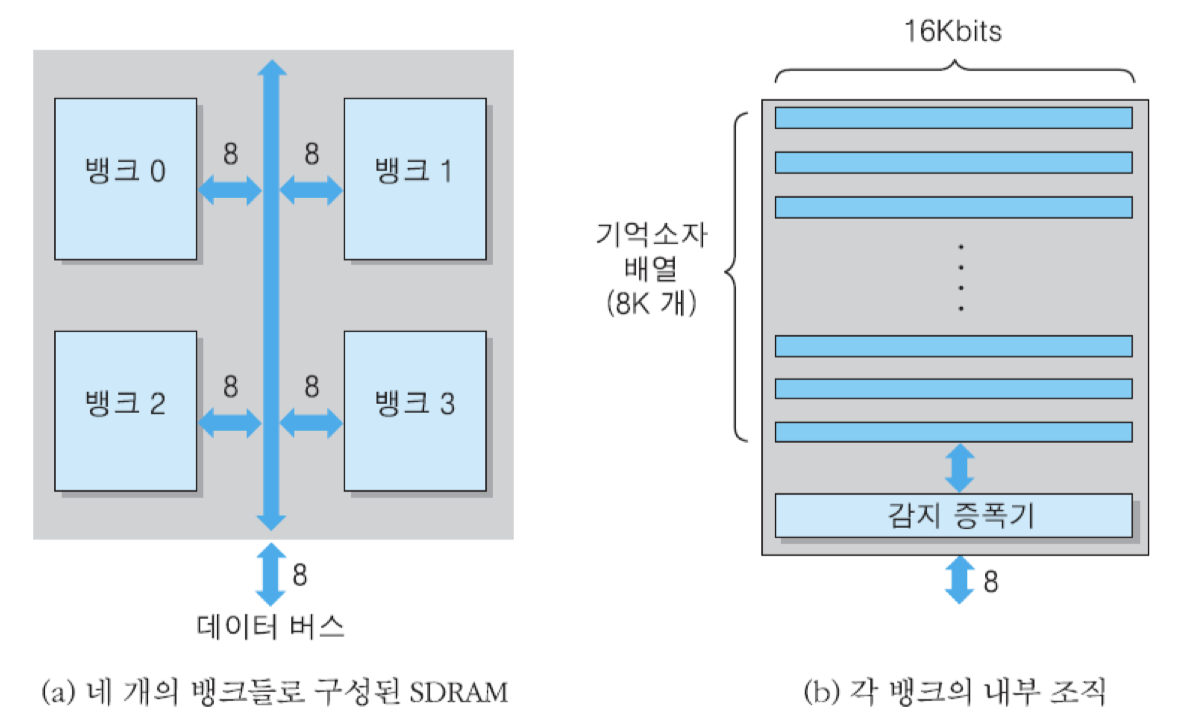
(a) : 512Mbit SDRAM
(b) : 16M x 8bit
그림 (a)부터 이 칩은 각각 16M x 8bit의 저장 용량을 가지는 네 개의 뱅크들로 구성되며, 그 뱅크들은 모두 칩의 내부 버스에 접속되어 주소와 데이터 및 제어 신호들을 주고받음. 이 칩에 필요한 주소 비트의 수는 모두 26개인데, 그들 중에서 최상위 2비트는 뱅크 선택을 위해 사용됨. 그리고 나머지 24비트는 각 뱅크 내부의 주소지정에 사용됨. 그림 (b) 이 조직에서는 행 방향으로 8K개의 기억소자 배열들이 있으며, 각 배열에는 16Kbit씩 저장됨. 그런데 이 칩의 데이터 입출력 선의 수가 8개이므로, 각 행의 배열마다 2Kbyte씩 저장되어 있는 것임. 따라서 행 주소로 13비트가 필요하고, 열 주소로서 11비트가 필요하게 됨
그런데 각 뱅크에서 행 주소에 의해 하나의 행이 선택되었을 때, 그 행에 저장된 16K개의 비트들은 모두 감지 증폭기로 이동됨. 이 동작을 '행을 연다'라고 말함. 그와 같이 열린 행에 포함된 비트들은 열 주소에 의해 바이트 단위로 선택되어 데이터 버스에 실리게 됨. 그런데 한 번의 읽기 동작에서 한 바이트만 전송하는 것이 아니라, 여러 개의 바이트들을 연속적으로 전송할 수 있음. 이와 같은 연속 전송 동작을 버스트 모드라고 하며, 한 번의 버스트 모드 동안에 전송되는 데이터 바이트들의 수를 버스트 길이라고 함. 일반적으로 버스트 길이는 2, 4 혹은 8임. 데이터 액세스에서 가장 오래 걸리는 동작이 데이터 값들을 기억 소자로부터 인출하여 감지 증폭기까지 이동시키는 것이기 때문에, 이미 증폭기로 이동된 데이터 비트들을 버스로 전송하는 동작은 매 버스 클록 때마다 발생시킬 수 있음.
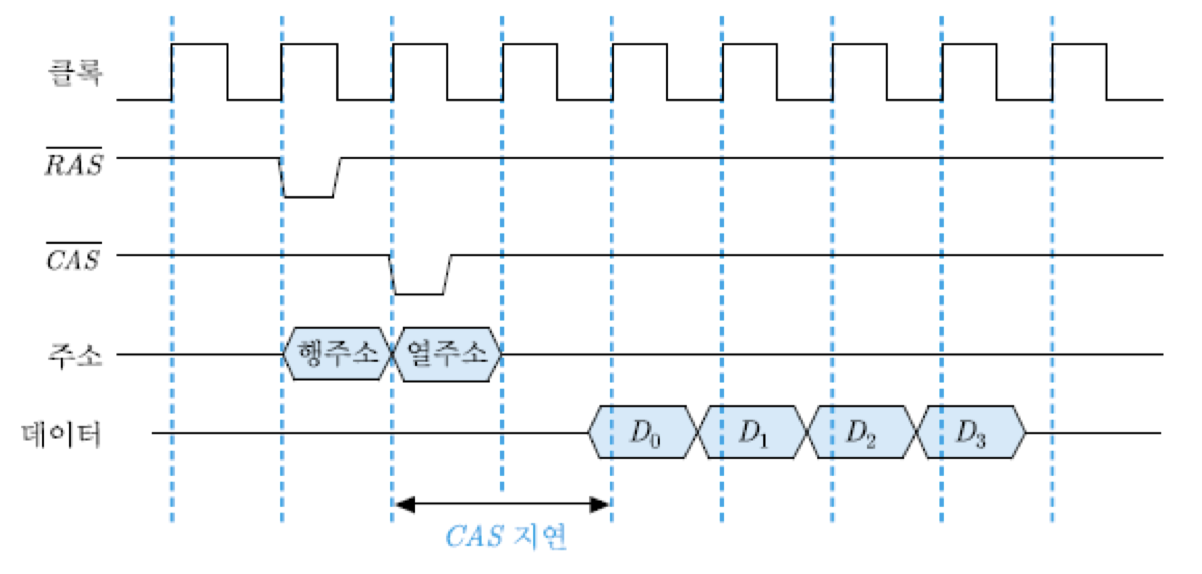
그림은 네 개의 바이트들을 연속적으로 CPU로 전송하는 버스트 읽기 동작에 대한 타이밍 도를 보여주고 있음. 클록 신호의 상승 에지에서 RAS 신호와 CAS 신호가 한 주기 간격으로 들어오며, 그에 따라 행 주소와 열 주소가 각각 래치 되어 읽기 동작이 시작됨. CAS 신호와 열 주소가 인가되는 순간부터 데이터가 인출되어 버스에 실릴 때까지의 시간을 CAS 지연이라고 하는데, 일반적으로 두 클록 주기 정도임. 그리고 실제 칩에서는 RAS 신호와 CAS 신호가 'active-low'이기 때문에, 이 그림에서도 그 신호들을 각각 RAS 및 CAS로 표시함.
결과적으로 SDRAM으로부터 인출된 데이터가 매 클록 주기마다 CPU로 전송되기 때문에, 주기 당 한 바이트씩 연속적으로 읽혀지는 것과 같은 효과를 얻게 되는 것임. 그리고 만약 같은 칩 내의 다른 뱅크에서도 그 동안 어떤 행에 대한 열기가 이루어졌다면, 그 데이터들의 전송도 지연 없이 발생될 수 있으므로 많은 데이터들을 연속적으로 CPU로 공급할 수 있음.
버스트 쓰기 동작의 경우는 그림과는 달리 주소와 함께 데이터들도 인가되는데, 행 주소가 인가된 다음 주기에 열 주소가 들어오는 순간부터 SDRAM에 연속적으로 네 개의 데이터들이 저장될 수 있음. 즉, SDRAM에서는 쓰기 지연이 발생하지 않음.
5.6.2 DDR SDRAM
DDR : SDRAM에서 액세스된 데이터들을 전송할 때 버스 클록의 상승 예지와 하강 예지에서 각각 하나씩 전송함으로써 클록 당 두 번 전송하는 기법
DDR SDRAM : DDR 전송 방식이 사용되는 SDRAM
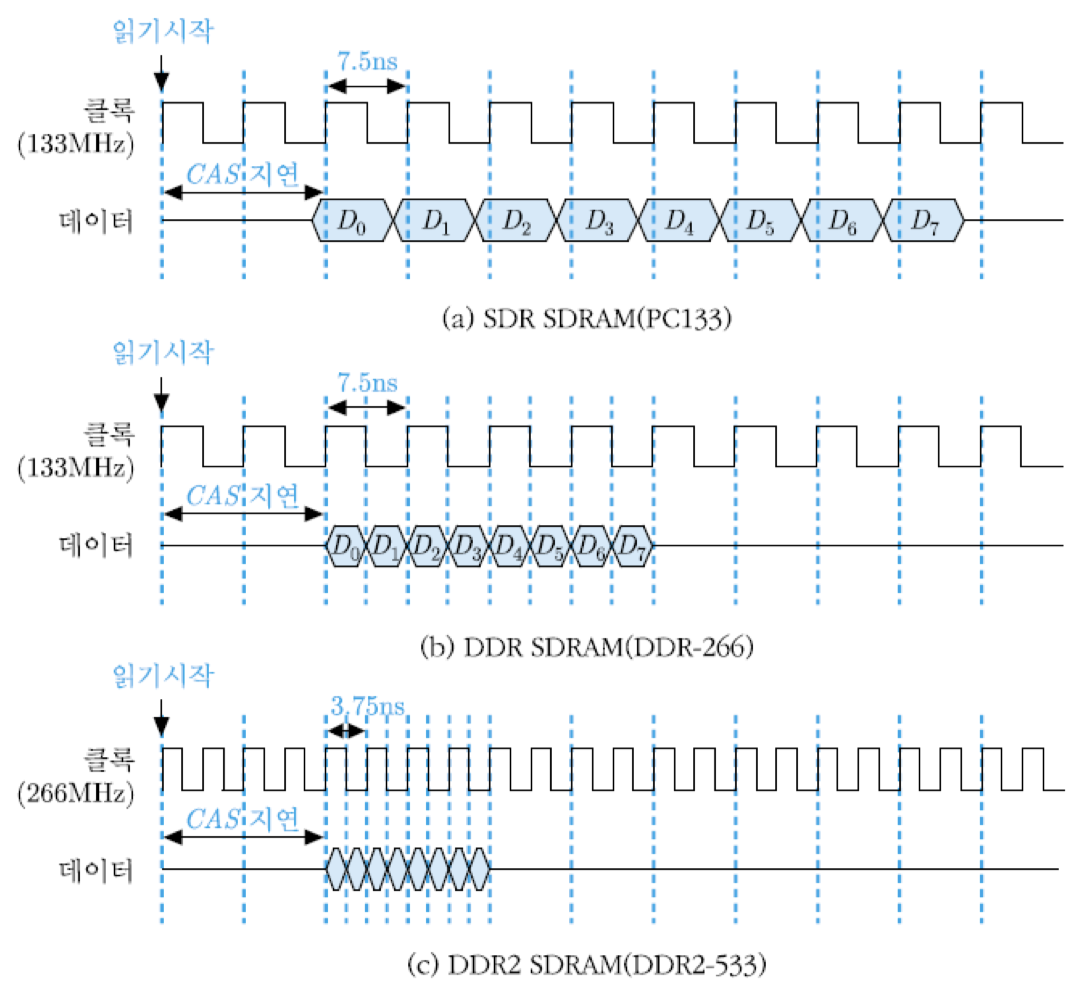
그림 (a)를 보면, 클록에 맞추어 동작하는 기억장치 표준을 PC133이라고 부르는데, 이 경우에는 클록 주기가 그림에서 표시된 바와 같이 7.5ns이며, 클록의 상승 에지마다 64-비트 데이터를 하나씩 전송함. 따라서 버스트 길이=8인 경우에 8개의 데이터들을 전송하는데 8 클록 주기, 즉 60ns가 소요됨. 그리고 CAS 지연까지 합하면 모두 75ns가 걸리게 됨.
그와는 달리, DDR SDRAM의 경우에는 그림 (b)에서 보는 바와 같이 데이터가 클록 상승 에지뿐 아니라 하강 에지에서도 전송됨. 즉, 첫 번째 데이터는 클록의 상승 에지에서 전송되고, 하강 에지에서는 두 번째 데이터가 전송됨. 따라서 4 클록 주기만에 8개의 데이터들을 모두 전송할 수 있게 됨. 그런데 여기서도 SDRAM의 내부 액세스 속도는 그대로이기 때문에 CAS 지연은 2 클록 주기임. 결과적으로, 전체 데이터 전송시간은 = 15ns + 30ns + 45ns로 줄어들게 됨. 이 경우 버스 클록 주파수는 위의 SDR과 같은 133MHz이지만 두 배의 전송 속도를 가지므로 DDR-266이라고 부름. 그 외에도 DDR SDRAM의 클록 주파수로는 166MHz, 200MHz 등이 사용되고 있으며, 각각은 해당 주파수의 두 배를 나타내는 수치를 사용하여 DDR-333 및 DDR-400이라는 명칭으로 불림.
DDR2 SDRAM은 근본적인 동작 원리가 DDR SDRAM과 거의 같으며, 버스 클록 주파수만 두 배로 높여서 데이터 전송률을 그만큼 증가시킨 것임.
DDR 기술의 기본 원리
• 버스 클록의 상승 에지와 하강 에지에서 각각 데이터 전송
• 기억장치 제어기 및 버스 인터페이스 회로의 개선을 통하여 버스 클록 주파수 향상
기억장치 대역폭 : 기억장치로부터 CPU로 제공될 수 있는 단위시간당 데이터 전송량
5.6.3 기억장치 랭크
기억장치 랭크 : 데이터 입출력 폭이 64비트가 되도록 구성한 기억장치 모듈
SIMM : 칩들과 접속 핀들을 한 면에만 부착한 기억장치 모듈 기판
DIMM : 칩들과 접속 핀들을 양면에 모두 부착한 기억장치 모듈 기판
단일-랭크 모듈 : 단면 모듈(SIMM) 상에 x8 조직의 SDRAM 8개를 병렬접속 하여 하나의 랭크 를 구성함으로써, 64비트 데이터가 한 번에 버스를 통하여 전송되도록 구성한 기억장치 모듈
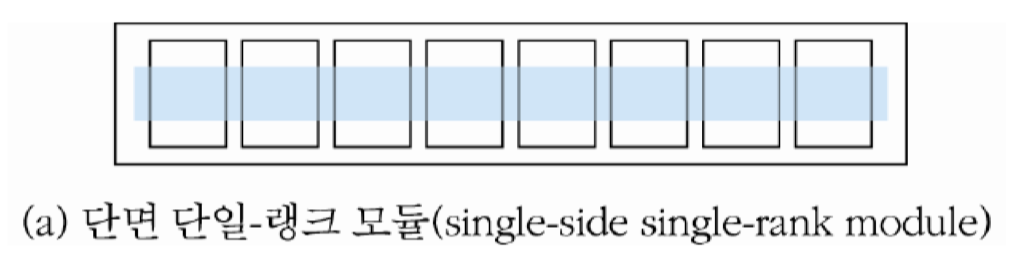
2중-랭크 모듈 : 양면 모듈(DIMM)에 서, x8 조직의 SDRAM들을 각 면에 8개씩 병렬 접속 하여 두 개의 랭크를 구성한 기억장치 모듈

x4 조직의 SDRAM들을 사용하는 경우 : 16개를 병렬접속하여 양면 모듈에 하나의 랭크를 구성
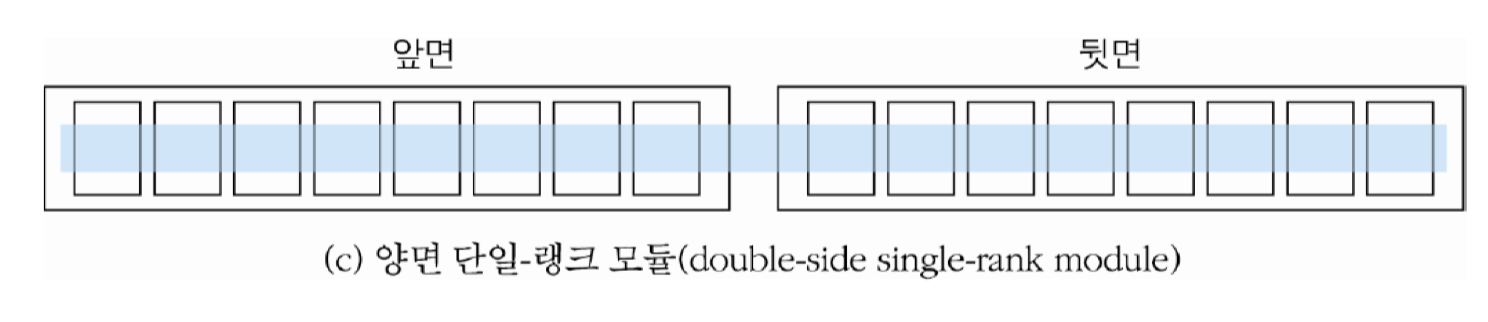
• 읽기 동작 시, 주소가 인가되면 각 칩에서 4비트씩 인출되어 전체적으로 64비트가 데이터 버스로 전송
4중-랭크 모듈 : x16 조직의 SDRAM 칩들을 사용, 네 개의 랭크들로 구성된 기억장치 모듈로서, 양면 기판의 면 당 두 개씩의 랭크들 매치, 용량은 앞의 조직들과 동일
서버 컴퓨터나 슈퍼컴퓨터와 같이 높은 신뢰도가 요구되는 시스템에서는 데이터 8비트 당 한 비트씩의 오류 검출 코드(ECC)를 추가하여 기억 장치 모듈을 구성.
-> 각 랭크의 입출력 데이터 폭이 72비트가 되기 때문에, SIMM 및 DIMM의 각 면에 SDRAM 칩을 9개씩 장착해야 함.
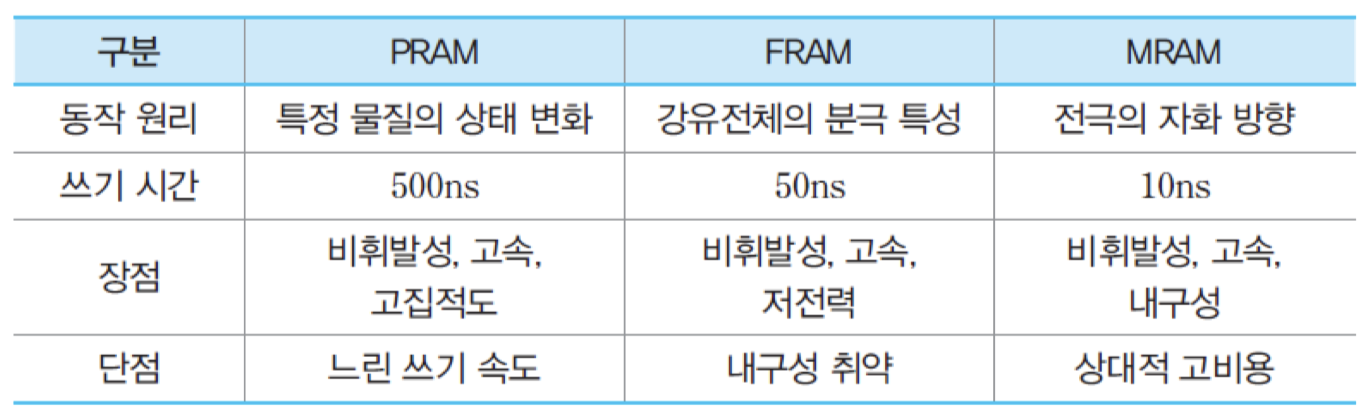
5.7 차세대 비휘발성 기억장치
PRAM, FRAM 및 MRAM
비휘발성
플래시 메모리에 비하여 액세스 속도가 1000배 정도 더 빠름
DRAM보다 속도는 느리지만, 집적도는 별 차이가 없으며, 전력 소모가 더 적음
5.7.1 PRAM
PRAM : 화합물 반도체의 상태 변화를 이용하여 2진 정보를 저장하는 RAM
인가되는 전압의 높이에 따라 내부 구조가 변하여 저항이 낮은 고체 상태 혹은 저항이 높은 액체 상태가 됨.
고체 상태: 결정 상태(polycrystalline phase)
액체 상태: 비정질 상태(amorphous phase)
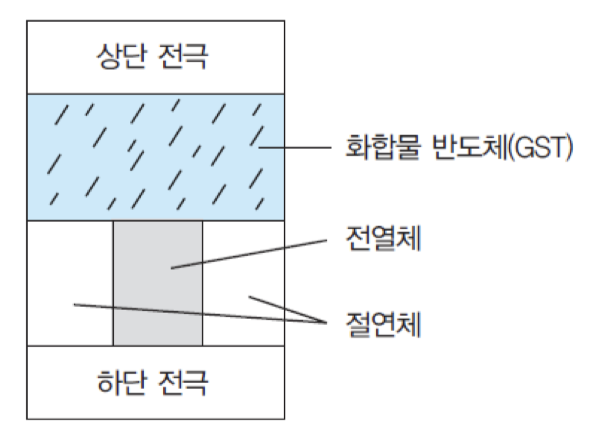
PRAM의 각 메모리 셀은 그림과 같이 두 개의 전극 사이에 화합물 반도체와 전열체를 삽입시킨 형태로 제조됨. 그리고 두 전극들 간에 짧은 시간 동안 상대적으로 높은 전압을 인가하면, 전열체에 의해 열이 발생하여 낮은 저항을 가지는 결정 상태로 바귀게 되는데, 그 상태는 '1'을 나타내게 됨. 반면에, 낮은 전압을 상대적으로 긴 시간동안 인가하면 저항이 높은 비정질 상태가 되는데, 그 상태는 '0'을 가리킴
읽기 동작은 상태 변화를 야기하지 않을 정도로 낮은 전압의 전기를 두 전극들 사이에 인가함으로써 이루어짐. 삽입된 물질은 상태에 따라 저항의 크기가 다르기 때문에 전기가 인가되었을 때 두 전극들 간에 흐르는 전류 양에 차이가 발생하며, 그 차이를 이용하여 데이터의 값을 구분함. 즉, 읽기 전압이 인가되었을 때 저항이 낮은 결정 상태라면 전류가 많이 흐르므로 '1'로 인식되며, 비정질 상태라면 저항이 높아 전류가 적게 흐르므로 '0'으로 인식됨.
이와 같은 상태 변화 물질은 DVD나 CD-RW와 같은 저장매체에 사용되는 것과 유사한 유형의 물질이지만, 그 장치들에서는 쓰기 및 삭제 동작에 전원보다 더 높은 전압이 필요하기 때문에 회로가 복잡해짐. 그러나 PRAM은 인가되는 전원 전압 범위에서 모든 전기적인 동작들이 이루어질 수 있기 때문에, 회로가 간단하고 전력 소모도 적다는 장점을 가지고 있음. PRAM은 차세대 기억 장치들 중에서 가장 빠르게 기술이 발전되고 있고, 시장성도 가장 높게 평가받고 있음.
5.7.2 FRAM
FRAM : 강유전체에 전극 위치를 조절하여 2진 정보를 저장하는 반도체 기억장치
강유전체 : 전기를 인가하지 않은 자연 상태에도 전기적 극성을 띠고 있는 물질
한쪽 면은 양전극, 다른 쪽 면은 음전극의 고유 성질을 가진 강유전체 물질에 전기를 가하면 전극의 위치가 바뀌게 되며, 전기 공급이 중단되어도 그대로 유지됨. 따라서 각 메모리 셀에 '0'을 저장하고자 할 때는 전기를 인가하지 않음으로써 원래의 전극 위치를 유지하게 하고, '1'을 저장할 때는 전기를 인가하여 전극 위치를 - + 상태가 되도록 바꾸는 것.
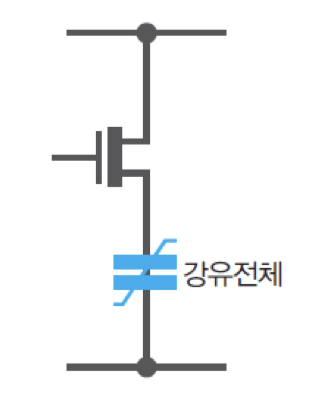
데이터를 읽을 때는 메모리 셀에 전기장을 가한 다음에, 감지되는 전하의 양에 따라 '0'과 '1'을 구분함. 그 전하의 양은 전극의 위치에 따라 달라짐. FRAM의 각 메모리 셀은 그림과 같이 한 개의 강유전체 캐패시터와 한 개의 트랜지스터로 구성됨. 따라서 FRAM은 강유전체가 캐패시터 역할을 한다는 점만 다를 뿐, 그 구조와 동작 원리가 DRAM과 유사하다고 볼 수 있음. FRAM은 차세대 기억장치들 중에서 가장 먼저 상용화된 제품이 개발되었는데, 최근 IC 카드와 같은 외장형 기억장치로 사용하기 위한 연구 개발이 활발히 진행되고 있음.
5.7.3 MRAM
MRAM : 강자성체에서 자화되는 방향을 조절하여 2진 정보를 저장하는 반도체 기억장치
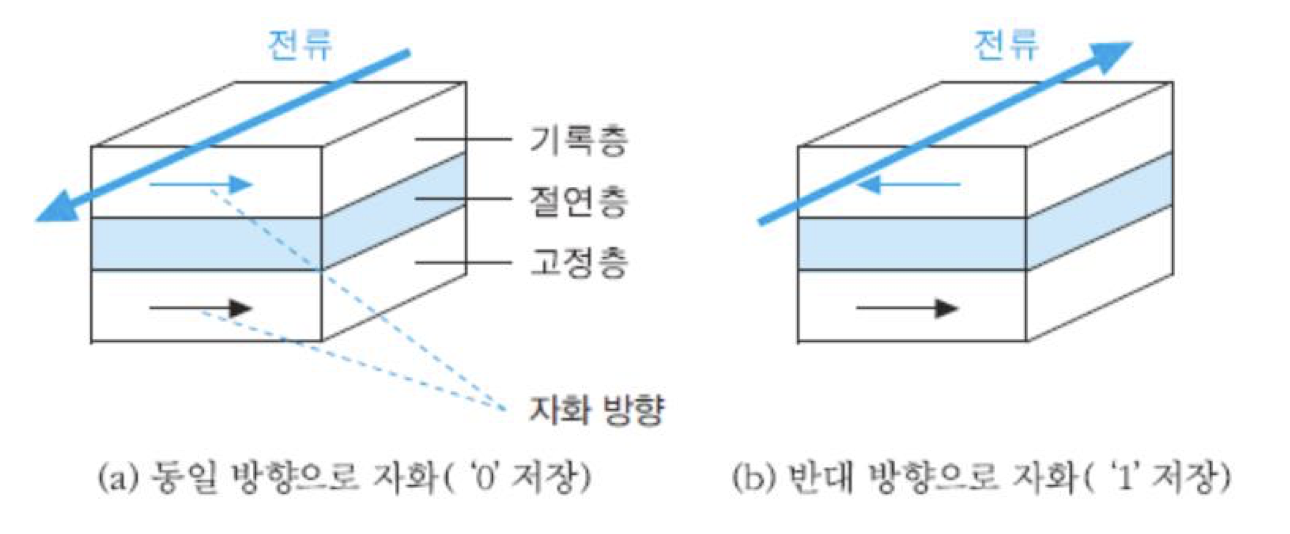
기본 구조는 그림과 같이 상부와 하부에 설치되는 두 개의 강자성체들 사이에 절연체가 삽입된 형태임. 하부 강자성체의 자화 방향은 고정되어 있어서 고정층이라고 부르는데, 일반적으로 철을 사용함. 절연층은 터널링 자기저항 현상이 일어날 수 있도록 충분히 얇아야 하며, 상부 강자성체에는 2진 정보가 자화 방향에 따라 저장되므로 기록층이라 부름.
메모리 셀에 '0'을 쓸 때는 상부 기록층에 그림 (a)와 같은 방향으로 전류를 인가해주어 상부 강자성체와 하부 강자성체의 자화 방향이 일치되도록 자기장을 형성해주면 됨. 그리고 '1'을 쓸 때는 (b)와 같이 전류 방향을 반대로 인가하여 상부 및 하부 강자성체의 자화 방향이 서로 달라지게 하면 됨. 데이터를 읽을 때는 두 강자성체들 간에 전류를 흘려줌. 만약 강자성체 간의 자화 방향이 같은 상태라면, 절연층의 저항이 적어져 터널링 전류가 흐르기 때문에 상하부 층간의 전위차가 낮아져서 '0'으로 인식됨. 그러나 만약 자화 방향이 서로 반대가 된다면, 저항이 커져 전류가 흐르지 않으므로 상하부 층간의 전위차가 높아져서 '1'로 인식됨.
