1. 객체지향언어
1.1 객체지향언어의 역사
과학, 군사적 모의실험(simulation)을 위해 컴퓨터를 이용한 가상세계를 구현하려는 노력으로부터 객체지향이론이 시작되었다.
객체지향이론의 기본 개념은 '실제 세계는 사물(객체)로 이루어져 있으며, 발생하는 모든 사건들은 사물간의 상호작용이다.'라는 것이다.
실제 사물의 속성과 기능을 분석한 다음, 데이터(변수)와 함수로 정의함으로써 실제 세계를 컴퓨터 속에 옮겨 놓은 것과 같은 가상세계를 구현하고 이 가상세계에서 모의실험을 함으로써 많은 시간과 비용을 절약할 수 있었다.
객체지향 이론은 상속, 캡슐화, 추상화 개념을 중심으로 점차 구체적으로 발전되었으며 1960년대 중반에 객체지향이론을 프로그래밍언어에 적용한 시뮬라(Simula)라는 최초의 객체지향언어가 탄생하였다.
그 당시에는 FORTRAN이나 COBOL과 같은 절차적 언어들이 주류를 이루었으며, 객체지향언어는 널리 사용되지 못하고 있었다. 1980년대 중반에 C++을 비롯하여 여러 객체지향언어가 발표되면서 객체지향 언어가 본격적으로 개발자들의 관심을 끌기 시작하였지만 여전히 사용자층이 넓지 못했다.
그러나 조금씩 입지를 넓혀가고 있었다.
자바가 1995년에 발표되고 1990년대 말에 인터넷의 발전과 함께 크게 유행하면서 객체지향언어는 이제 프로그래밍언어의 주류로 자리 잡았다.
1.2 객체지향언어
- 코드의 재사용성이 높다.
- 새로운 코드를 작성할 때 기존의 코드를 이용하여 쉽게 작성할 수 있다.
- 코드의 관리가 용이하다.
- 코드간의 관계를 이용해서 적은 노력으로 쉽게 코드를 변경할 수 있다.
- 신뢰성이 높은 프로그래밍을 가능하게 한다.
- 제어자와 메서드를 이용해서 데이터를 보호하고 올바른 값을 유지하도록 하며, 코드의 중복을 제거하여 코드의 불일치로 인한 오동작을 방지할 수 있다.
2. 클래스와 객체
2.1 클래스와 객체의 정의와 용도
클래스의 정의 - 클래스란 객체를 정의해 놓은 것이다.
클래스의 용도 - 클래스는 객체를 생성하는데 사용된다.
객체의 정의 - 실제로 존재하는 것. 사물 또는 개념
객체의 용도 - 객체가 가지고 있는 기능과 속성에 따라 다름유형의 객체 - 책상, 의자, 자동차, TV와 같은 사물
무형의 객체 - 수학공식, 프로그램 에러와 같은 논리나 개념
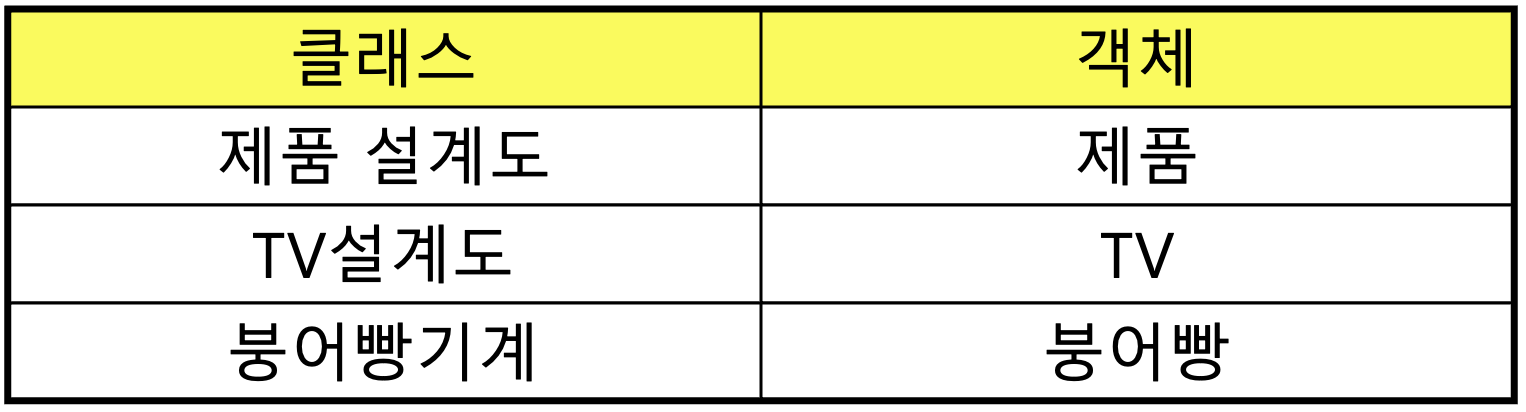
클래스와 객체의 예
2.2 객체와 인스턴스
클래스로부터 객체를 만드는 과정을 클래스의 인스턴스화(instantiate)라고 하며, 어떤 클래스로부터 만들어진 객체를 그 클래스의 인스턴스(instance)라고 한다.

인스턴스와 객체는 같은 의미이므로 두 용어의 사용을 엄격히 구분할 필요는 없지만, 위의 예에서 본 것과 같이 문맥에 따라 구별하여 사용하는 것이 좋다.

2.3 객체의 구성요소 - 속성과 기능
객체는 속성과 기능, 두 종류의 구성요소로 이루어져 있으며, 일반적으로 객체는 다수의 속성과 다수의 기능을 갖는다. 즉, 객체는 속성과 기능의 집합이라고 할 수 있다. 그리고 객체가 가지고 있는 속성과 기능을 그 객체의 멤버(구성원, member)라 한다.
클래스란 객체를 정의한 것이므로 클래스에는 객체의 모든 속성과 기능이 정의되어있다. 클래스로부터 객체를 생성하면, 클래스에 정의된 속성과 기능을 가진 객체가 만들어지는 것이다.
속성과 기능은 아래와 같이 같은 뜻의 여러 가지 용어가 있으며, 앞으로 이 중에서도 '속성'보다는 '멤버변수'를, '기능'보다는 '메서드'를 주로 사용할 것이다.
속성(property) - 멤버변수(member variable), 특성(attribute), 필드(field), 상태(state)
기능(function) - 메서드(method), 함수(function), 행위(behavior)
객체지향 프로그래밍에서는 속성과 기능을 각각 변수와 메서드로 표현한다.
속성(property) -> 멤버변수(variable)
기능(function) -> 메서드(method)채널 -> int channel
채널 높이기 -> channelUp() { ... }
위에서 분석한 내용을 토대로 Tv클래스를 만들어 보면 다음과 같다.
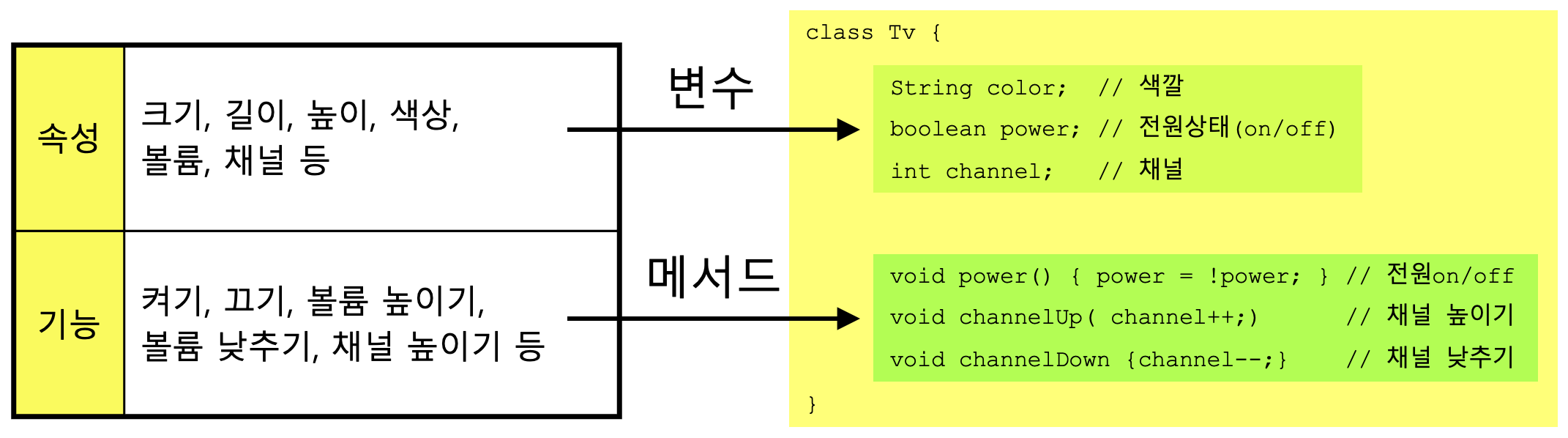
실제 TV가 갖는 기능과 속성은 이 외에도 더 있지만, 프로그래밍에 필요한 속성과 기능만을 선택하여 클래스를 작성하면 된다.
각 변수의 자료형은 속성의 값에 알맞은 것을 선택해야한다. 전원상태(power)의 경우, on과 off 두 가지 값을 가질 수 있으므로 boolean형으로 선언했다.
power()의 'power = !power;'이 문장에서 power의 값이 true면 false로, false면 true로 변경하는 일을 한다. power의 값에 관계없이 항상 반대의 값으로 변경해주면 되므로 굳이 if문을 사용할 필요가 없다.
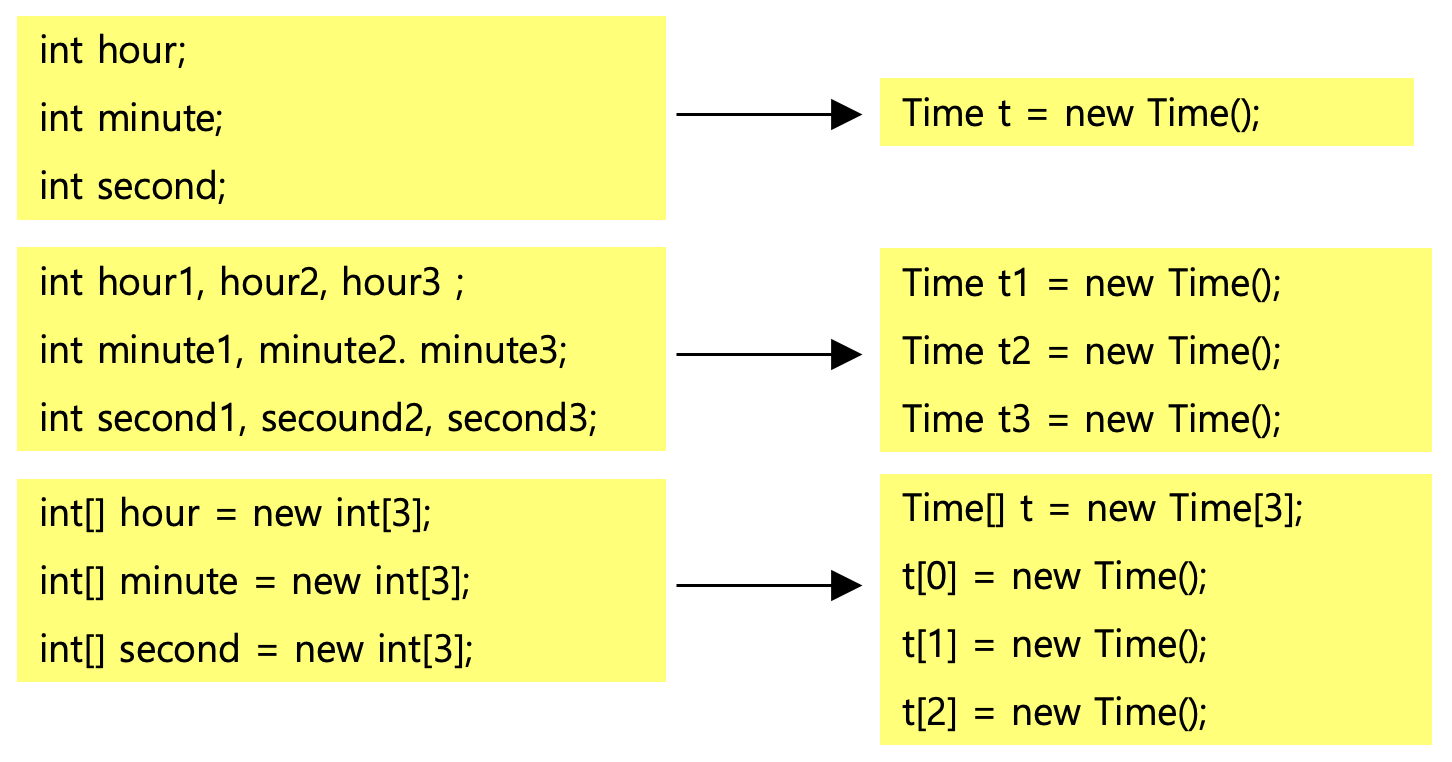
2.4 인스턴스의 생성과 사용
Tv클래스를 선언한 것은 Tv설계도를 작성한 것에 불과하므로, Tv인스턴스를 생성해야 제품(Tv)를 사용할 수 있다. 클래스로부터 인스턴스를 생성하는 방법은 여러 가지가 있지만 일반적으로는 다음과 같이 한다.
클래스명 변수명; // 클래스의 객체를 참조하기 위한 참조변수를 선언
변수명 = new 클래스명(); // 클래스의 객체를 생성 후, 객체의 주소를 참조변수에 저장
Tv t; // Tv클래스 타입의 참조변수 t를 선언
t = new Tv(); // Tv인스턴스를 생성한 후, 생성된 Tv인스턴스의 주소를 t에 저장인스턴스는 참조변수를 통해서만 다룰 수 있으며, 참조변수의 타입은 인스턴스의 타입과 일치해야한다.
2.5 객체 배열
객체 역시 배열로 다루는 것이 가능하며, 이를 '객체 배열'이라고 한다. 그렇다고 객체 배열 안에 객체가 저장되는 것은 아니고, 객체의 주소가 저장된다. 사실 객체 배열은 참조변수들을 하나로 묶은 참조 변수 배열인 것이다.
2.6 클래스의 또 다른 정의
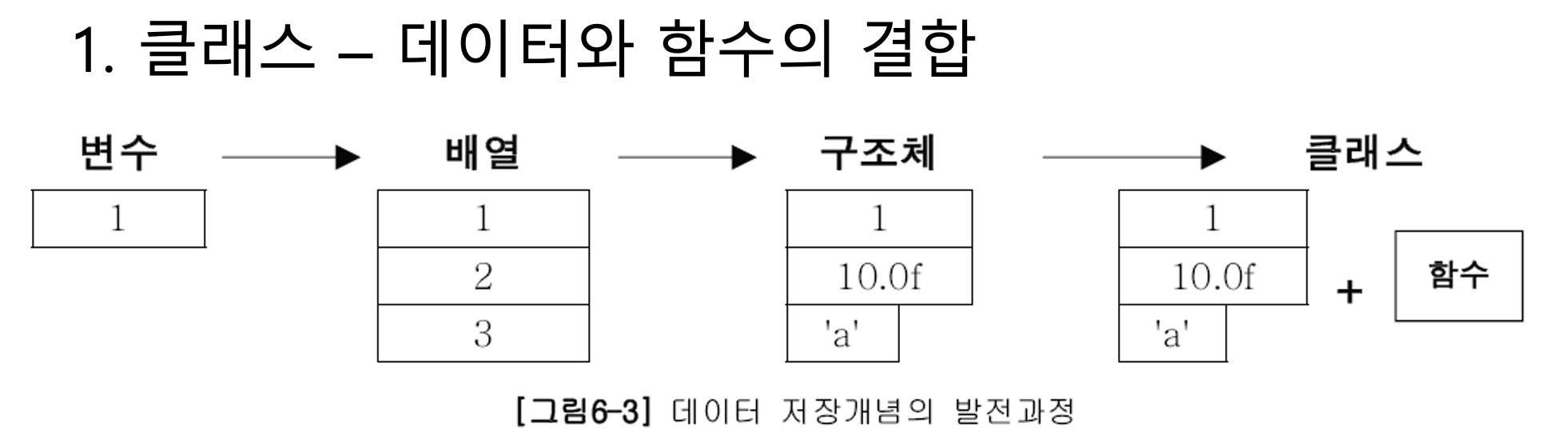
- 변수 - 하나의 데이터를 저장할 수 있는 공간
- 배열 - 같은 종류의 여러 데이터를 하나의 집합으로 저장할 수 있는 공간
- 구조체 - 서로 관련된 여러 데이터를 종류에 관계없이 하나의 집합으로 저장할 수 있는 공간
- 클래스 - 데이터와 함수의 결합(구조체 + 함수)

비객체지향적 코드와 객체지향적 코드의 비교
3. 변수와 메서드
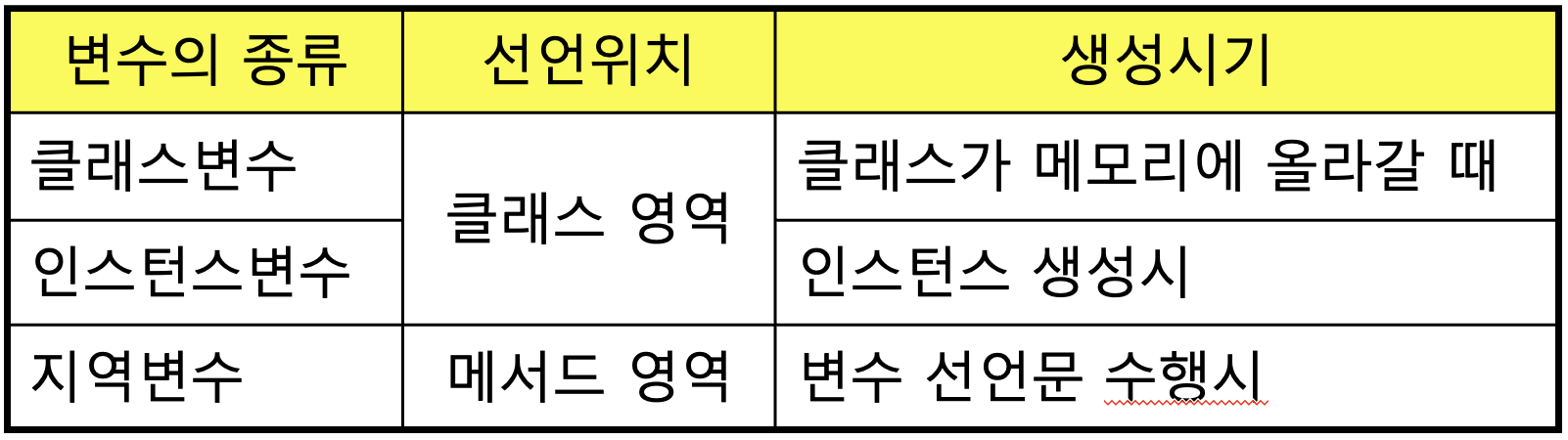
3.1 선언위치에 따른 변수의 종류
변수는 클래스변수, 인스턴스변수, 지역변수 모두 세 종류가 있다. 변수의 종류를 결정짓는 중요한 요소는 '변수의 선언된 위치'이므로 변수의 종류를 파악하기 위해서는 변수가 어느 영역에 선언되었는지를 확인하는 것이 중요하다. 멤버변수를 제외한 나머지 변수들은 모두 지역변수이며, 멤버변수 중 static이 붙은 것은 클래스변수, 붙지 않은 것은 인스턴스변수이다.
아래의 그림에는 모두 3개의 int형 변수가 선언되어 있는데, iv와 cv는 클래스 영역에 선언되어있으므로 멤버변수이다. 그리고 lv는 메서드인 method()의 내부, 즉 '메서드 영역'에 선언되어 있으므로 지역변수이다.

변수의 종류와 특징
1. 인스턴스변수(instance variable)
클래스 영역에 선언되며, 클래스의 인스턴스를 생성할 때 만들어진다. 그렇기 때문에 인스턴스 변수의 값을 읽어 오거나 저장하기 위해서는 먼저 인스턴스를 생성해야한다.
인스턴스는 독립적인 저장공간을 가지므로 서로 다른 값을 가질 수 있다. 인스턴스마다 고유한 상태를 유지해야하는 속성의 경우, 인스턴스변수로 선언한다.
2. 클래스변수(class variable)
클래스 변수를 선언하는 방법은 인스턴스변수 앞에 static을 붙이기만 하면 된다. 인스턴스마다 독립적인 저장공간을 갖는 인스턴스변수와는 달리, 클래스변수는 모든 인스턴스가 공통된 저장공간(변수)을 공유하게 된다. 한 클래스의 모든 인스턴스들이 공통적인 값을 유지해야하는 속성의 경우, 클래스변수로 선언해야 한다. 클래스 변수는 인스턴스변수와 달리 인스턴스를 생성하지 않고도 언제라도 바로 사용할 수 있다는 특징이 있으며, '클래스이름.클래스변수'와 같은 형식으로 사용한다. 예를 들어 Varriables클래스의 클래스변수 cv를 사용하려면 'Variables.cv'와 같이 하면 된다.
클래스가 메모리에 '로딩(loading)'될 때 생성되어 프로그램이 종료될 때 까지 유지되며, public을 앞에 붙이면 같은 프로그램 내에서 어디서나 접근할 수 있는 '전역변수(global variable)'의 성격을 갖는다.
3. 지역변수(local variable)
메서드 내에 선언되어 메서드 내에서만 사용 가능하며, 메서드가 종료되면 소멸되어 사용할 수 없게 된다. for문 또는 while문의 블럭 내에 선언된 지역변수는, 지역변수가 선언된 블럭{} 내에서만 사용 가능하며, 블럭{}을 벗어나면 소멸되어 사용할 수 없게 된다. 우리가 6장 이전에 선언한 변수들은 모두 지역변수이다.
3.2 클래스변수와 인스턴스변수
클래스변수와 인스턴스변수의 차이를 이해하기 위한 예로 카드 게임에 사용되는 카드를 클래스로 정의해보자.

카드 클래스를 작성하기 위해서는 먼저 카드를 분석해서 속성과 기능을 알아 내야한다.
속성으로는 카드의 무늬, 숫자, 폭, 높이 정도를 생각할 수 있을 것이다.
이 중에서 어떤 속성을 크래스 변수로 선언할 것이며, 또 어떤 속성들을 인스턴스변수로 선언할 것인지 한번 생각해보자.
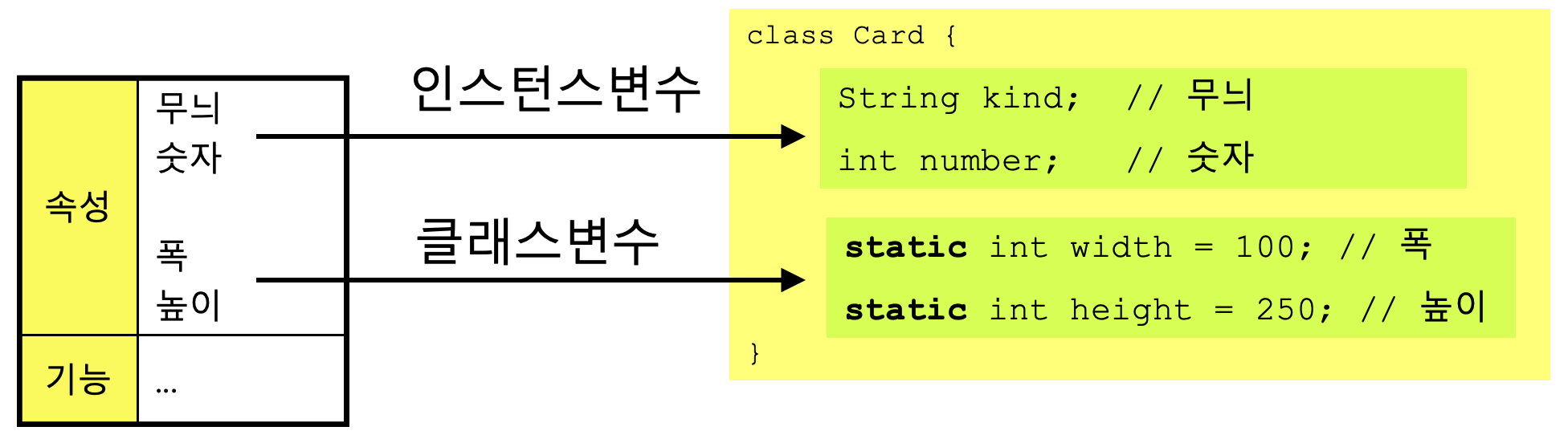
각 Card인스턴스는 자신만의 무늬(kind)와 숫자(number)를 유지하고 있어야 하므로 이들을 인스턴스변수로 선언하였고, 각 카드의 폭(width)과 높이(height)는 모든 인스턴스가 공통적으로 같은 값을 유지해야하므로 클래스변수로 선언하였다.
카드의 폭을 변경해야할 필요가 있을 경우, 모든 카드의 width값을 변경하지 않고 한 카드의 widht값만 변경해도 모든 카드의 width값이 변경되는 셈이다.
인스턴스변수는 인스턴스가 생성될 때 마다 생성되므로 인스턴스마다 각기 다른 값을 유지할 수 있지만, 클래스 변수는 모든 인스턴스가 하나의 저장공간을 공유하므로, 항상 공통된 값을 갖는다.
3.3 메서드
'메서드(method)'는 특정 작업을 수행하는 일련의 문장들을 하나로 묶은 것이다. 기본적으로 수학의 함수와 유사하며, 어떤 값을 입력하면 이 값으로 작업을 수행해서 결과를 반환한다.
그저 메서드가 작업을 수행하는데 필요한 값만 넣고 원하는 결과를 얻으면 될 뿐, 이 메서드가 내부적으로 어떤 과정을 거쳐 결과를 만들어내는지 전혀 몰라도 된다. 즉, 메서드에 넣을 값(입력)과 반환하는 결과(출력)만 알면 되는 것이다. 그래서 메서드를 내부가 보이지 않는 '블랙박스(black box)'라고도 한다.
메서드를 사용하는 이유
1. 높은 재사용성(reusability)
이미 Java API에서 제공하는 메서드들을 사용하면서 경험한 것처럼 한번 만들어 놓은 메서드는 몇 번이고 호출할 수 있으며, 다른 프로그램에서도 사용이 가능하다.
2. 중복된 코드의 제거
프로그램을 작성하다보면, 같은 내용의 문장들이 여러 곳에서 반복해서 나타나곤 한다. 이렇게 반복되는 문장들을 묶어서 하나의 메서드로 작성해 놓으면, 반복되는 문장들 대신 메서드를 호출하는 한 문장으로 대체할 수 있다. 그러면, 전체 소스 코드의 길이도 짧아지고, 변경사항이 발생했을 때 수정해야할 코드의 양이 줄어들어 오류가 발생할 가능성도 함께 줄어든다.
3. 프로그램의 구조화
지금까지는 main메서드 안에 모든 문장을 넣는 식으로 프로그램을 작성해왔다. 길어야 100줄 정도 밖에 안되는 작은 프로그램을 작성할 때는 이렇게 해도 별 문제가 없지만, 몇 천줄, 몇 만줄이 넘는 프로그램도 이런 식으로 작성할 수는 없다. 큰 규모의 프로그램에서는 문장들을 작업단위로 나눠서 여러 개의 메서드에 담아 프로그램의 구조를 단순화 시키는 것이 필수적이다.
3.4 메서드의 선언과 구현
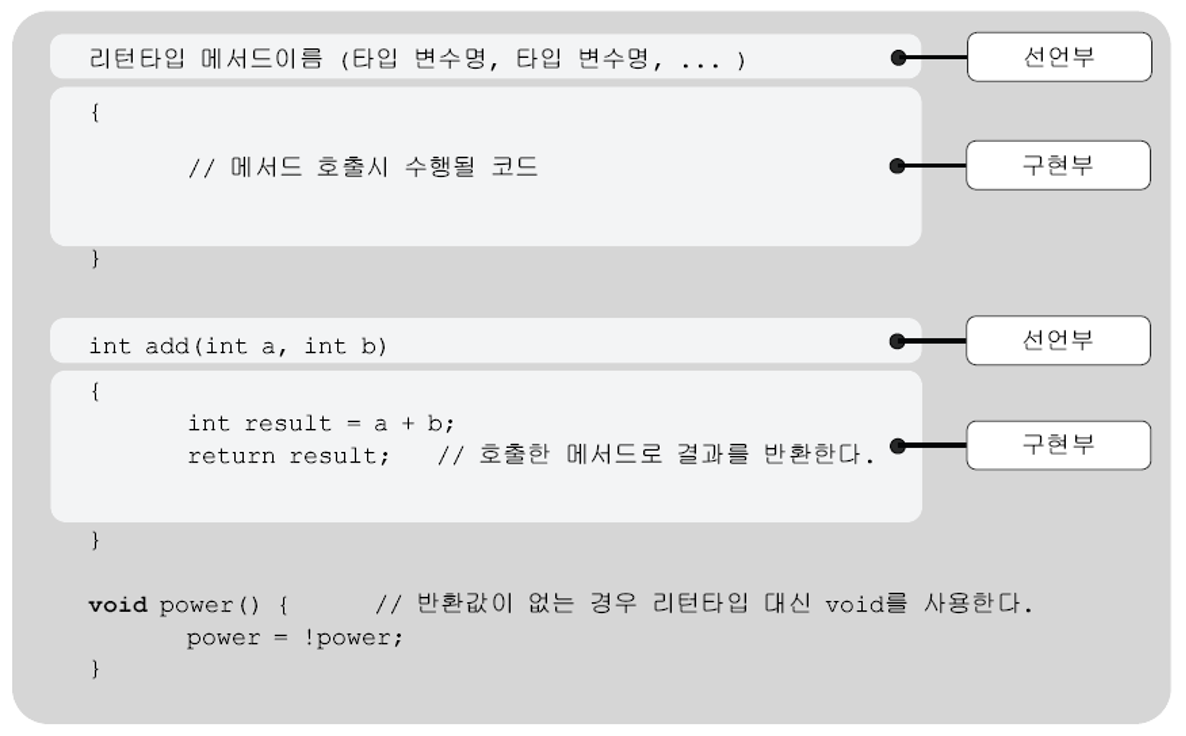
메서드는 크게 두 부분, '선언부(header, 머리)'와 '구현부(body, 몸통)'로 이루어져 있다.
메서드를 정의한다는 것은 선언부와 구현부를 작성하는 것을 뜻하며 다음과 같은 형식으로 메서드를 정의한다.
메서드 선언부(method declaration, method header)
메서드 선언부는 '메서드의 이름'과 '매개변수 선언', 그리고 '반환타입'으로 구성되어 있으며, 메서드가 작업을 수행하기 위해 어떤 값들을 필요로 하고 작업의 결과로 어떤 타입의 값을 반환하는지에 대한 정보를 제공한다.
예를 들어 아래에 정의된 메서드 add는 두 개의 정수를 입력받아서, 두 값을 더한 결과(int타입의 값)를 반환한다.

메서드의 선언부는 후에 변경사항이 발생하지 않도록 신중히 작성해야한다. 메서드의 선언부를 변경하게 되면, 그 메서드가 호출되는 모든 곳도 같이 변경해야 하기 때문이다.
매개변수 선언(parameter declaration)
매개변수는 메서드가 작업을 수행하는데 필요한 값들(입력)을 제공받기 위한 것이며, 필요한 값의 개수만큼 변수를 선언하며 각 변수 간의 구분은 쉼표','를 사용한다. 한 가지 주의할 점은 일반적인 변수선언과 달리 두 변수의 타입이 같아도 변수의 타입을 생략할 수 없다는 것이다.
int add(int x, int y) { ... } // OK.
int add(int x, y) { ... } // 에러. 매개변수 y의 타입이 없다.선언할 수 있는 매개변수의 개수는 거의 제한이 없지만, 만일 입력해야할 값의 개수가 많은 경우에는 배열이나 참조변수를 사용하면 된다. 만일 값을 전혀 입력받을 필요가 없다면 괄호() 안에 아무 것도 적지 않는다.
메서드의 이름(method name)
메서드의 이름도 앞서 배운 변수의 명명규칙대로 작성하면 된다. 메서드는 특정 작업을 수행하므로 메서드의 이름은 'add'처럼 동사인 경우가 많으면, 이름만으로도 메서드의 기능을 쉽게 알 수 있도록 함축적이면서도 의미있는 이름을 갖도록 노력해야 한다.
반환타입(return type)
메서드의 작업수행 결과(출력)인 '반환값(return value)'의 타입을 적는다. 반환값이 없는 경우 반환타입으로 'void'를 적어야한다.
메서드의 구현부(method body, 메서드 몸통)
메서드의 선언부 다음에 오는 괄호{}를 '메서드의 구현부'라고 하는데, 여기에 메서드를 호출했을 때 수행될 문장들을 넣는다. 우리가 그동안 작성해온 문장들을 모두 main메서드의 구현부 {}에 속한 것들이었으므로 지금까지 하던 대로만 하면 된다.
return문
메서드의 반환타입이 'void'가 아닌 경우, 구현부{}안에 'return 반환값;'이 반드시 포함되어 있어야 한다. 이 문장은 작업을 수행한 결과인 반환값을 호출한 메서드로 전달하는데, 이 문장은 작업을 수행한 결과인 반환값을 호출한 메서드로 전달하는데, 이 값의 타입은 반환타입과 일치하거나 적어도 자동 형변환이 가능한 것이어야 한다.
여러 개의 변수를 선언할 수 있는 매개변수와 달리 return문은 단 하나의 값만 반환할 수 있는데, 메서드로의 입력(매개변수)은 여러 개일 수 있어도 출력(반환값)은 최대 하나만 허용하는 것이다.
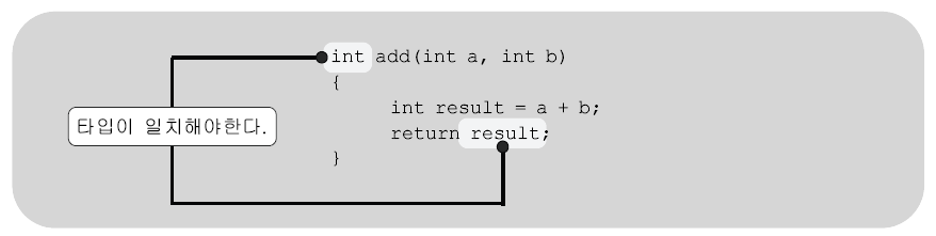
위의 코드에서 'return result;'는 변수 result에 저장된 값을 호출한 메서드로 반환한다. 변수 result의 타입이 int이므로 메서드 add의 반환타입이 일치하는 것을 알 수 있다.
지역변수(local variable)
메서드 내에 선언된 변수들은 그 메서드 내에서만 사용할 수 있으므로 서로 다른 메서드라면 같은 이름의 변수를 선언해도 된다. 이처럼 메서드 내에 선언된 변수를 '지역변수(local variable)'라고 한다.
int add(int x, int y) {
int result = x + y;
return result;
}
int multiply(int x, int y) {
int result = x * y;
return result;
}위에 정의된 메서드 add와 multiply에 각기 선언된 변수, x, y, result는 이름만 같을 뿐 서로 다른 변수이다.
3.5 메서드의 호출
메서드를 정의했어도 호출되지 않으면 아무 일도 일어나지 않는다. 메서드를 호출해야만 구현부{}의 문장들이 수행된다. 메서드를 호출하는 방법은 다음과 같다.
메서드이름(값1, 값2, ...); // 메서드를 호출하는 방법
print99danAll(); // void print99danAll(void)를 호출
int result = add(3, 5); // int add(int x, int y)를 호출하고, 결과를 result에 저장인자(argument)와 매개변수(parameter)
메서드를 호출할 때 괄호()안에 지정해준 값들을 '인자(argument)' 또는 '인수'라고 하는데, 인자의 개수와 순서는 호출된 메서드에 선언된 매개변수와 일치해야 한다. 그리고 인자는 메서드가 호출되면서 매개변수에 대입되므로, 인자의 타입은 매개변수의 타입과 일치하거나 자동 형변환이 가능한 것이어야 한다.

만일 아래와 같이 메서드에 선언된 매개변수의 개수보다 많은 값을 괄호()에 넣거나 타입이 다른 값을 넣으면 컴파일러가 경고를 발생시킨다.
int result = add(1, 2, 3); // 경고. 메서드에 선언된 매개변수의 개수가 다름
int result = add(1.0, 2.0); // 경고. 메서드에 선언된 매개변수의 타입이 다름반환타입이 void가 아닌 경우, 메서드가 작업을 수행하고 반환한 값을 대입연산자로 변수에 저장하는 것이 보통이지만, 저장하지 않아도 문제가 되지 않는다.
int result = add(3, 5); // int add(int x, int y)를 호출하고 결과를 result에 저장
add(3, 5); // OK. 메서드 add가 반환한 결과를 사용하지 않아도 된다.메서드의 실행흐름
같은 클래스 내의 메서드끼리는 참조변수를 사용하지 않고도 서로 호출이 가능하지만 static메서드는 같은 클래스 내의 인스턴스 메서드를 호출할 수 없다.
다음은 두 개의 값을 매개변수로 받아서 사칙연산을 수행하는 4개의 메서드를 가진 MyMath클래스를 정의한 것이다.
class MyMath {
long add(long a, long b) {
long result = a + b;
return result;
// return a + b; // 위의 두 줄을 이와 같이 한 줄로 간단히 할 수 있다.
}
long subtract(long a, long b) { return a - b; }
long multiply(long a, long b) { return a * b; }
double divide(double a, double b) { return a / b; }
}MyMath클래스의 'add(long a, long b)'를 호출하기 위해서는 먼저 'MyMath mm = new MyMath();'와 같이 해서, MyMath클래스의 인스턴스를 생성한 다음 참조변수 mm을 통해야한다. 참조변수 mm으로 add메서드를 호출하면, 다음과 같은 흐름으로 문장들이 수행된다.
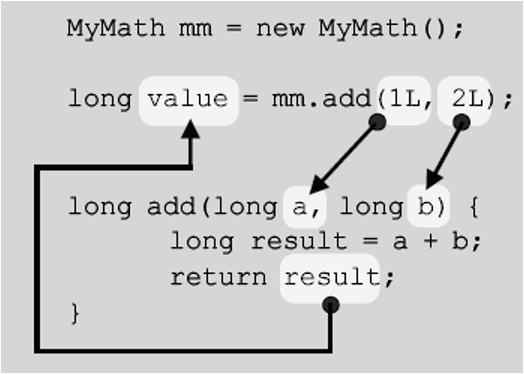
① main메서드에서 메서드 add를 호출한다. 호출시 지정한 1L과 2L이 메서드 add의 매개변수 a, b에 각각 복사(대입)된다.
② 메서드 add의 괄호{}안에 있는 문장들이 순서대로 수행된다.
③ 메서드 add의 모든 문장이 실행되거나 return문을 만나면, 호출한 메서드(main메서드)로 되돌아 와서 이후의 문장들을 실행한다.
메서드가 호출되면 지금까지 실행 중이던 메서드는 실행을 잠시 멈추고 호출된 메서드의 문장들이 실행된다. 호출된 메서드의 작업이 모두 끝나면, 다시 호출한 메서드로 돌아와 이후의 문장들을 실행한다.
위의 그림에서는 편의상 메서드 add의 호출결과가 바로 value에 저장되는 것처럼 그렸지만, 사실은 호출한 자리를 반환값이 대신하고 대입연산자에 의해 이 값이 변수 value에 저장된다.
long value = add(1L, 2L);
->long value = 3L'add메서드의 매개변수의 타입이 long이므로 long 또는 long으로 자동 형변환이 가능한 값을 지정해야한다. 호출시 매개변수로 지정된 값은 메서드의 매개변수로 복사된다. 위의 코드에서는 1L과 2L의 값이 long타입의 매개변수 a와 b에 각각 복사된다.
메서드는 호출시 넘겨받은 값으로 연산을 수행하고 그 결과를 반환하면서 종료된다. 반환된 값은 대입연산자에 의해서 변수 value에 저장된다. 메서드의 결과를 저장하기 위한 변수 value역시 반환값과 같은 타입이거나 반환값이 자동 형변환되어 저장될 수 있는 타입이어야 한다.
3.6 return문
return문은 현재 실행중인 메서드를 종료하고 호출한 메서드로 되돌아간다. 지금까지 반환값이 있을 때만 return문을 썼지만, 원래는 반환값의 유무에 관계없이 모든 메서드에는 적어도 하나의 return문이 있어야 한다. 그런데도 반환타입이 void인 경우, return문 없어도 아무런 문제가 없었던 이유는 컴파일러가 메서드의 마지막에 'return;'을 자동적으로 추가해주었기 때문이다.

그러나 반환타입이 void가 아닌 경우, 즉 반환값이 있는 경우, 반드시 return문이 있어야 한다. return문이 없으면 컴파일 에러가 발생한다.

아래의 코드는 두 값 중에서 큰 값을 반환하는 메서드 max이다. 이 메서드의 리턴타입이 int이고 int타입의 값을 반환하는 return문이 있지만, return문이 없다는 에러가 발생한다. 왜냐하면 if문 조건식의 결과에 따라 return문이 실행되지 않을 수도 있기 때문이다.

그래서 이런 경우 다음과 같이 if문의 else블럭에 return문을 추가해서, 항상 결과값이 반환되도록 해야 한다.

3.7 JVM의 메모리구조
응용프로그램이 실행되면, JVM은 시스템으로부터 프로그램을 수행하는데 필요한 메머리를 할당받고 JVM은 이 메모리를 용도에 따라 여러 영역으로 나누어 관리한다.
그 중 3가지 주요영역(method area, call stack, heap)에 대해서 알아보자.

1. 메서드 영역(method area)
- 프로그램 실행 중 어떤 클래스가 사용되면, JVM은 해당 클래스의 클래스파일(*.class)을 읽어서 분석하여 클래스에 대한 정보(클래스 데이터)를 이곳에 저장한다. 이 때, 그 클래스의 클래스변수(class variable)도 이 영역에 함께 생성된다.
- 힙(heap)
- 인스턴스가 생성되는 공간. 프로그램 실행 중 생성되는 인스턴스는 모두 이곳에 생성된다. 즉, 인스턴스변수(instance variable)들이 생성되는 공간이다.
- 호출스택(call stack 또는 execution stack)
- 호출스택은 메서드의 작업에 필요한 메모리 공간을 제공한다. 메서드가 호출되면, 호출스택에 호출된 메서드를 위한 메모리가 할당되며, 이 메모리는 메서드가 작업을 수행하는 동안 지역변수(매개변수 포함)들과 연산의 중간결과 등을 저장하는데 사용된다. 그리고 메서드가 작업을 마치면 할당되었던 메모리공간은 반환되어 비워진다.
호출스택의 특징
- 메서드가 호출되면 수행에 필요한 만큼의 메모리를 스택에 할당받는다.
- 메서드가 수행을 마치고나면 사용했던 메모리를 반환하고 스택에서 제거된다.
- 호출스택의 제일 위에 있는 메서드가 현재 실행 중인 메서드이다.
- 아래에 있는 메서드가 바로 위의 메서드를 호출한 메서드이다.
반환타입(return type)이 있는 메서드는 종료되면서 결과값을 자신을 호출한 메서드(caller)에게 반환한다. 대기상태에 있던 호출한 메서드(caller)는 넘겨받은 반환값으로 수행을 계속 진행하게 된다.

main()이 firstMethod()를 호출하고 firstMethod()는 secondMethod()를 호출한다. 객체를 생성하지 않고도 메서드를 호출할 수 있으려면, 메서드 앞에 'static'을 붙여야 한다.

예제의 실행 시 호출스택의 변화
3.8 기본형 매개변수와 참조형 매개변수
자바에서는 메서드를 호출할 때 매개변수로 지저한 값을 메서드의 매개변수에 복사해서 넘겨준다. 매개변수의 타입이 기본형(primitive type)일 때는 기본형 값이 복사되겠지만, 참조형(reference type)이면 인스턴스의 주소가 복사된다.
메서드의 매개변수를 기본형으로 선언하면 단순히 저장된 값만 얻지만, 참조형으로 선언하면 값이 저장된 곳의 주소를 알 수 있기 때문에 값을 읽어 오는 것은 물론 값을 변경하는 것도 가능하다.
기본형 매개변수 - 변수의 값을 읽기만 할 수 있다.(read only)
참조형 매개변수 - 변수의 값을 읽고 변경할 수 있다.(read & write)
3.9 참조형 반환타입
매개변수뿐만 아니라 반환타입도 참조형이 될 수 있다. 반환타입이 참조형이라는 것은 반환하는 값의 타임이 참조형이라는 얘긴데, 모든 참조형 타입의 값은 '객체의 주소'이므로 그저 정수값이 반환되는 것일 뿐 특별한 것이 없다.
3.10 재귀호출(recursive call)
메서드의 내부에서 메서드 자신을 다시 호출하는 것을 '재귀호출(recursive call)'이라 하고, 재귀호출을 하는 메서드를 '재귀 메서드'라 한다.
void method() {
method(); // 재귀호출. 메서드 자신을 호출한다.
}그런데 위의 코드처럼 오로지 재귀호출뿐이면, 무한히 자기 자신을 호출하기 때문에 무한반복에 빠지게 된다. 무한반복문이 조건문과 함께 사용되어야하는 것처럼, 재귀호출도 조건문이 필수적으로 따라다닌다.
void method(int n) {
if (n == 0)
return; // n의 값이 0일 때, 메서드를 종료한다.
System.out.println(n);
method(--n); // 재귀호출
}재귀호출은 반복문으로 바꿀 수 있으며 반복문보다 성능이 나쁘다. 하지만 반복문에 비해 단순한 구조로 바뀔 수 있기 때문에 사용을 한다.
대표적인 재귀호출의 예는 팩토리얼(factorial)을 구하는 것이다.
f(n) = n * f(n - 1), 단 f(1) = 13.11 클래스 메서드(static메서드)와 인스턴스 메서드
변수에서 그랬던 것과 같이, 메서드 앞에 static이 붙어 있으면 클래스메서드이고 붙어 있지 않으면 인스턴스 메서드이다.
클래스 메서드도 클래스변수처럼, 객체를 생성하지 않고도 '클래스이름.메서드이름(매개변수)'와 같은 식으로 호출이 가능하다. 반면에 인스턴스 메서드는 반드시 객체를 생성해야만 호출할 수 있다.
클래스는 '데이터(변수)와 데이터에 관련된 메서드의 집합'이므로, 같은 클래스 내에 있는 메서드와 멤버변수는 아주 밀접한 관계가 있다.
인스턴스 메서드는 인스턴스 변수와 관련된 작업을 하는, 즉 메서드의 작업을 수행하는데 인스턴스 변수를 필요로 하는 메서드이다. 그런데 인스턴스 변수는 인스턴스(객체)를 생성해야만 만들어지므로 인스턴스 메서드 역시 인스턴스를 생성해야만 호출할 수 있는 것이다.
반면에 메서드 중에서 인스턴스와 관계없는(인스턴스 변수나 인스턴스 메서드를 사용하지 않는) 메서드를 클래스 메서드(static메서드)로 정의한다.
물론 인스턴스 변수를 사용하지 않는다고 해서 반드시 클래스 메서드로 정의해야하는 것은 아니지만 특별한 이유가 없는 한 그렇게 하는 것이 일반적이다.

1. 클래스를 설계할 때, 멤버변수 중 모든 인스턴스에 공통적으로 사용해야하는 것에 static을 붙인다.
- 생성된 각 인스턴스는 서로 독립적이기 때문에 각 인스턴스의 변수(iv)는 서로 다른 값을 유지한다. 그러나 모든 인스턴스에서 같은 값이 유지되어야 하는 변수는 static을 붙여서 클래스 변수로 정의해야 한다.
2. 클래스 변수(static)는 인스턴스를 생성하지 않아도 사용할 수 있다.
- static이 붙은 변수(클래스변수)는 클래스가 메모리에 올라갈 때 이미 자동적으로 생성되기 때문이다.
3. 클래스 메서드(static메서드)는 인스턴스 변수를 사용할 수 없다.
- 인스턴스변수는 인스턴스가 반드시 존재해야만 사용할 수 있는데, 클래스메서드(static이 붙은 메서드)는 인스턴스 생성 없이 호출가능하므로 클래스 메서드가 호출되었을 때 인스턴스가 존재하지 않을 수도 있다. 그래서 클래스 메서드에서 인스턴스변수의 사용을 금지한다.
반면에 인스턴스 변수나 인스턴스메서드에서는 static이 붙은 멤버들을 사용하는 것이 언제나 가능하다. 인스턴스 변수가 존재한다는 것은 static변수가 이미 메모리에 존재한다는 것을 의미하기 때문이다.
4. 메서드 내에서 인스턴스 변수를 사용하지 않는다면, static을 붙이는 것을 고려한다.
- 메서드의 작업내용 중에서 인스턴스변수를 필요로 한다면, static을 붙일 수 없다. 반대로 인스턴스변수를 필요로 하지 않는다면 static을 붙이자. 메서드 호출시간이 짧아지므로 성능이 향상된다. static을 안 붙인 메서드(인스턴스메서드)는 실행 시 호출되어야할 메서드를 찾는 과정이 추가적으로 필요하기 때문에 시간이 더 걸린다.
- 클래스의 멤버변수 중 모든 인스턴스에 공통된 값을 유지해야하는 것이 있는지 살펴보고 있으면, static을 붙여준다.
- 작성한 메서드 중에서 인스턴스 변수나 인스턴스 메서드를 사용하지 않는 메서드에 static을 붙일 것을 고려한다.
3.12 클래스 멤버와 인스턴스 멤버간의 참조와 호출
같은 클래스에 속한 멤버들 간에는 별도의 인스턴스를 생성하지 않고도 서로 참조 또는 호출이 가능하다. 단, 클래스멤버가 인스턴스 멤버를 참조 또는 호출하고자 하는 경우에는 인스턴스를 생성해야 한다.
그 이유는 인스턴스 멤버가 존재하는 시점에 클래스 멤버는 항상 존재하지만, 클래스멤버가 존재하는 시점에 인스턴스 멤버가 존재하지 않을 수도 있기 때문이다.

위의 코드는 같은 클래스 내의 인스턴스 메서드와 static메서드 간의 호출에 대해서 설명하고 있다. 같은 클래스 내의 메서드는 서로 객체의 생성이나 참조변수 없이 직접 호출이 가능하지만 static메서드는 인스턴스 메서드를 호출할 수 없다.

이번엔 변수와 메서드간의 호출에 대해서 살펴보자. 메서드간의 호출과 마찬가지로 인스턴스메서드는 인스턴스변수를 사용할 수 있지만, static메서드는 인스턴스변수를 사용할 수 없다.
4. 오버로딩(Overloading)
4.1 오버로딩이란?
메서드도 변수와 마찬가지로 같은 클래스 내에서 서로 구별될 수 있어야 하기 때문에 각기 다른 이름을 가져야 한다. 그러나 자바에서는 한 클래스 내에 이미 사용하려는 이름과 같은 이름을 가진 메서드가 있더라도 매개변수의 개수 또는 타입이 다르면, 같은 이름을 사용해서 메서드를 정의할 수 있다.
이처럼, 한 클래스 내에 같은 이름의 메서드를 여러 개 정의하는 것을 '메서드 오버로딩(method overloading)' 또는 간단히 '오버로딩(overloading)'이라 한다.
오버로딩의 사전적 의미는 '과적하다.' 즉, 많이 싣는 것을 뜻한다. 보통 하나의 메서드 이름에 하나의 기능만을 구현해야하는데, 하나의 메서드 이름으로 여러 기능을 구현하기 때문에 붙여진 이름이라 생각할 수 있다. 앞으로는 '메서드 오버로딩'을 간단히 '오버로딩'이라고 하겠다.
4.2 오버로딩의 조건
- 메서드 이름이 같아야 한다.
- 매개변수의 개수 또는 타입이 달라야 한다.
비록 메서드의 이름이 같다 하더라도 매개변수가 다르면 서로 구별될 수 있기 때문에 오버로딩이 가능한 것이다. 위의 조건을 만족시키지 못하는 메서드는 중복 정의로 간주되어 컴파일 시에 에러가 발생한다. 그리고 오버로딩된 메서드들은 매개변수에 의해서만 구별될 수 있으므로 반환 타입은 오버로딩을 구현하는데 아무런 영향을 주지 못한다는 것에 주의하자.
4.3 오버로딩의 예
오버로딩의 예로 가장 대표적인 것은 println메서드이다. 다양하게 오버로딩된 메서드를 제공함으로써 모든 변수를 출력할 수 있도록 설계되었다.

println메서드를 호출할 때 매개변수로 넘겨주는 값의 타입에 따라서 위의 오버로딩된 메서드들 중의 하나가 선택되어 실행되는 것이다.

매개변수의 이름이 다른 것은 오버로딩이 아니다.

리턴타입은 오버로딩의 성립조건이 아니다.

매개변수의 타입이 다르므로 오버로딩이 성립한다.

오버로딩의 올바른 예 - 매개변수는 다르지만 같은 의미의 기능을 수행
4.4 오버로딩의 장점
오버로딩을 통해 여러 메서드들이 println이라는 하나의 이름으로 정이될 수 있다면, println이라는 이름만 기억하면 되므로 기억하기도 쉽고 이름도 짧게 할 수 있어서 오류의 가능성을 많이 줄일 수 있다. 그리고 메서드의 이름만 보고도 '이 메서드들은 이름이 같으니, 같은 기능을 하겠구나.'라고 쉽게 예측할 수 있게 된다.
또 하나의 장점은 메서드의 이름을 절약할 수 있다는 것이다. 하나의 이름으로 여러 개의 메서드를 정의할 수 있으니, 메서드의 이름을 짓는데 고민을 덜 수 있는 동시에 사용되었어야 할 메서드 이름을 다른 메서드의 이름으로 사용할 수 있기 때문이다.
4.5 가변인자(varargs)와 오버로딩
기존에는 메서드의 매개변수 개수가 고정적이었으나 JDK1.5부터 동적으로 지정해 줄 수 있게 되었으며, 이 기능을 '가변인자(variable arguments)'라고 한다.
가변인자는 '타입... 변수명'과 같은 형식으로 선언하며, PrintStream클래스의 printf()가 대표적인 예이다.
5. 생성자(constructor)
5.1 생성자란?
생성자는 인스턴스가 생성될 때 호출되는 '인스턴스 초기화 메서드'이다. 따라서 인스턴스 변수의 초기화 작업에 주로 사용되며, 인스턴스 생성 시에 실행되어야 할 작업을 위해서도 사용된다.
생성자 역시 메서드처럼 클래스 내에 선언되며, 구조도 메서드와 유사하지만 리턴값이 없다는 점이 다르다. 그렇다고 해서 생성자 앞에 리턴값이 없음을 뜻하는 키워드 void를 사용하지는 않고, 단지 아무 것도 적지 않는다. 생성자의 조건은 다음과 같다.
- 생성자의 이름은 클래스의 이름과 같아야 한다.
- 생성자는 리턴 값이 없다.
생성자는 다음과 같이 정의한다. 생성자도 오버로딩이 가능하므로 하나의 클래스에 여러개의 생성자가 존재할 수 있다.

연산자 new가 인스턴스를 생성하는 것이지 생성자가 인스턴스를 생성하는 것이 아니다. 생성자라는 용어 때문에 오해하기 쉬운데, 생성자는 단순히 인스턴스변수들의 초기화에 사용되는 조금 특별한 메서드일 뿐이다. 생성자가 갖는 몇 가지 특징만 제외하면 메서드와 다르지 않다.
Card클래스의 인스턴스를 생성하는 코드를 예로 들어, 수행되는 과정을 단계별로 나누어 보면 다음과 같다.

지금까지 인스턴스를 생성할 때는 반드시 클래스 내에 정의된 생성자 중의 하나를 선택하여 지정해주어야 한다.
5.2 기본 생성자(default constructor)
지금까지 클래스에 생성자를 정의하지 않고도 인스턴스를 생성할 수 있었던 이유는 컴파일러가 제공하는 '기본 생성자(default constructor)'덕분이었다.
컴파일 할 때, 소스파일(*.java)의 클래스에 생성자가 하나도 정의되지 않은 경우 컴파일러는 자동적으로 아래와 같은 내용의 기본 생성자를 추가하여 컴파일 한다.

컴파일러가 자동적으로 추가해주는 기본 생성자는 이와 같이 매개변수도 없고 아무런 내용도 없는 아주 간단한 것이다.
특별히 인스턴스 초기화 작업이 요구되어지지 않는다면 생성자를 정의하지 않고 컴파일러가 제공하는 기본 생성자를 사용하는 것도 좋다.
"모든 클래스에는 반드시 하나 이상의 생성자가 있어야 한다."
5.3 매개변수가 있는 생성자
생성자도 메서드처럼 매개변수를 선언하여 호출 시 값을 넘겨받아서 인스턴스의 초기화 작업에 사용할 수 있다. 인스턴스마다 각기 다른 값으로 초기화되어야 하는 경우가 많기 때문에 매개변수를 사용한 초기화는 매우 유용하다.
아래의 코드는 자동차를 클래스로 정의한 것인데, 단순히 color, gearType, door 세 개의 인스턴스변수와 두 개의 생성자만을 가지고 있다.

Car인스턴스를 생성할 때, 생성자 Car()를 사용한다면, 인스턴스를 생성한 다음에 인스턴스 변수들을 따로 초기화해주어야 하지만, 매개변수가 있는 생성자 Car(String color, String gearType, int door)를 사용한다면 인스턴스를 생성하는 동시에 원하는 값으로 초기화를 할 수 있게 된다.
인스턴스를 생성한 다음에 인스턴스변수의 값을 변경하는 것보다 매개변수를 갖는 생성자를 사용하는 것이 코드를 보다 간결하고 직관적으로 만든다.

위의 양쪽 코드 모드 같은 내용이지만, 오른쪽의 코드가 더 간결하고 직관적이다. 이처럼 클래스를 작성할 때 다양한 생성자를 제공함으로써 인스턴스 생성 후에 별도로 초기화를 하지 않아도 되도록 하는 것이 바람직하다.
5.4 생성자에서 다른 생성자 호출하기 - this(), this
같은 클래스의 멤버들 간에 서로 호출할 수 있는 것처럼 생성자 간에도 서로 호출이 가능하다. 단, 다음의 두 조건을 만족시켜야 한다.
- 생성자의 이름으로 클래스이름 대신 this를 사용한다.
- 한 생성자에서 다른 생성자를 호출할 때는 반드시 첫 줄에서만 호출이 가능하다.
다음의 코드는 생성자를 작성할 때 지켜야하는 두 조건을 모두 만족시키지 못했기 때문에 에러가 발생한다.
Car (String color) {
door = 5; // 첫 번재 줄
Car (color, "auto", 4); // 에러1. 생성자의 두 번째 줄에서 다른 생성자 호출
// 에러2. this(color, "auto", 4);로 해야함
}생성자 내에서 다른 생성자를 호출할 때는 클래스이름인 'Car'대신 'this'를 사용해야하는 데 그러지 않아서 에러이고, 또 다른 에러는 생성자 호출이 첫 번째 줄이 아닌 두 번째 줄이기 때문에 에러이다.
생성자에서 다른 생성자를 첫 줄에서만 호출이 가능하도록 한 이유는 생성자 내에서 초기화 작업도중에 다른 생성자를 호출하게 되면, 호출된 다른 생성자 내에서도 멤버변수들의 값을 초기화 할 것이므로 다른 생성자를 호출하기 이전의 초기화 작업이 무의미해질 수 있기 때문이다.
this - 인스턴스 자신을 가리키는 참조변수, 인스턴스의 주소가 저장되어 있다. 모든 인스턴스메서드에 지역변수로 숨겨진 채로 존재한다.
this(), this(매개변수) - 생성자, 같은 클래스의 다른 생성자를 호출할 때 사용한다.
5.5 생성자를 이용한 인스턴스의 복사
현재 사용하고 있는 인스턴스와 같은 상태를 갖는 인스턴스를 하나 더 만드록자 할 때 생성자를 이용할 수 있다. 두 인스턴스가 같은 상태를 갖는다는 것은 두 인스턴스의 모든 인스턴스 변수(상태)가 동일한 값을 갖고 있다는 것을 뜻한다.
하나의 클래스로부터 생성된 모든 인스턴스의 메서드와 클래스변수는 서로 동일하기 때문에 인스턴스간의 차이는, 인스턴스마다 각기 다른 값을 가질 수 있는 인스턴스변수 뿐이다.

위의 코드는 Car클래스의 참조변수를 매개변수로 선언한 생성자이다. 매개변수로 넘겨진 참조변수가 가리키는 Car인스턴스의 인스턴스변수인 color, gearType, door의 값을 인스턴스 자신으로 복사하는 것이다.
인스턴스를 생성할 때는 다음의 2가지 사항을 결정해야한다.
1. 클래스 - 어떤 클래스의 인스턴스를 생성할 것인가?
2. 생성자 - 선택한 클래스의 어떤 생성자로 인스턴스를 생성할 것인가?
6. 변수의 초기화
6.1 변수의 초기화
변수를 선언하고 처음으로 값을 저장하는 것을 '변수의 초기화'라고 한다. 변수의 초기화는 경우에 따라서 필수적이기도 하고 선택적이기도 하지만, 가능하면 선언과 동시에 적절한 값으로 초기화 하는 것이 바람직하다.
멤버변수는 초기화를 하지 않아도 자동적으로 변수의 자료형에 맞는 기본값으로 초기화가 이루어지므로 초기화하지 않고 사용해도 되지만, 지역변수는 사용하기 전에 반드시 초기화해야 한다.

위의 코드에서 x, y는 인스턴스 변수이고, i, j는 지역변수이다. 그 중 x와 i는 선언만 하고 초기화를 하지 않았다. 그리고 y를 초기화 하는데 x를 사용하였고, j를 초기화 하는데 i를 사용하였다.
인스턴스 변수 x는 초기화를 해주지 않아도 자동적으로 int형의 기본값인 0으로 초기화되므로, 'int y = x;'와 같이 할 수 있다. x의 값이 0이므로 y역시 0이 저장된다.
하지만, method1()의 지역변수 i는 자동적으로 초기화되지 않으므로, 초기화 되지 않은 상태에서 변수 j를 초기화 하는데 사용될 수 없다. 컴파일하면, 에러가 발생한다.
멤버변수(클래스변수와 인스턴스변수)와 배열의 초기화는 선택적이지만, 지역변수의 초기화는 필수적이다.
참고로 각 타임의 기본값(default value)는 다음과 같다.

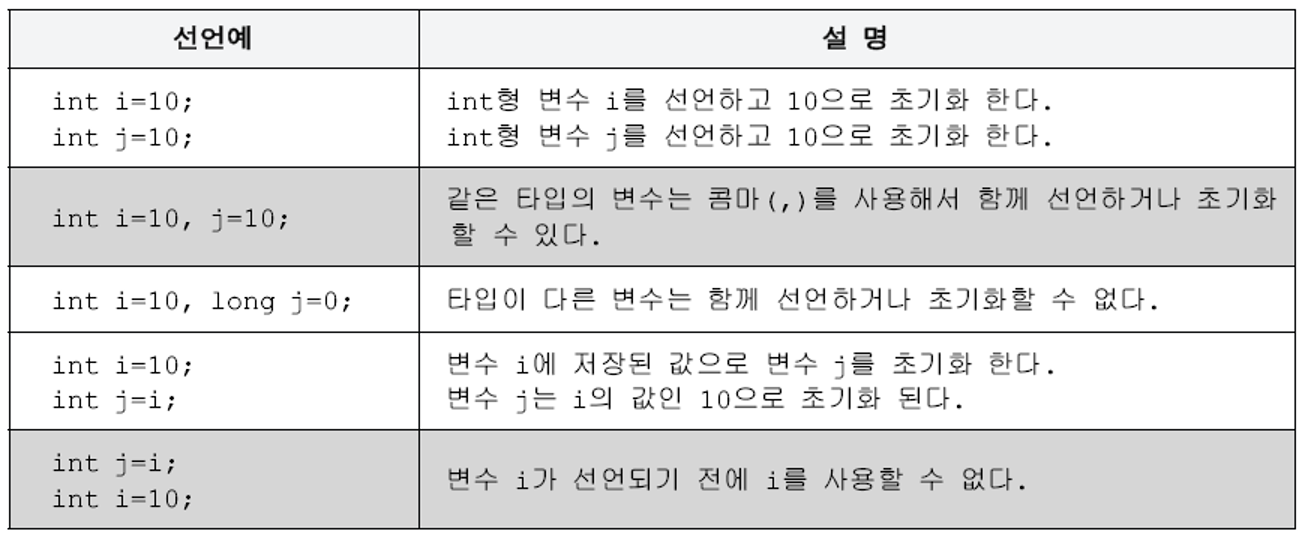
다양한 초기화 방법
멤버변수의 초기화는 지역변수와 달리 여러 가지 방법이 있는데 앞으로 멤버변수의 초기화에 대한 모든 방법에 대해 비교, 정리할 것이다.
▶︎ 멤버변수의 초기화 방법
1. 명시적 초기화(explicit initialization)
2. 생성자(constructor)
3. 초기화 블럭(initialization block)
-인스턴스 초기화 블럭: 인스턴스변수를 초기화 하는데 사용.
-클래스 초기화 블럭: 클래스변수를 초기화 하는데 사용.
6.2 명시적 초기화(explicit initialization)
변수를 선언과 동시에 초기화하는 것을 명시적 초기화라고 한다. 가장 기본적이면서도 간단한 초기화 방법이므로 여러 초기화 방법 중에서 가장 우선적으로 고려되어야 한다.

명시적 초기화가 간단하고 명료하긴 하지만, 보다 복잡한 초기화 작업이 필요할 때는 '초기화 블럭(initialization block)' 또는 생성자를 사용해야 한다.
6.3 초기화 블럭(initialization block)
초기화 블럭에는 '클래스 초기화 블럭'과 '인스턴스 초기화 블럭' 두 가지 종류가 있다. 클래스 초기화 블럭은 클래스변수의 초기화에 사용되고, 인스턴스 초기화 블럭은 인스턴스 변수의 초기화에 사용된다.
클래스 초기화 블럭 - 클래스변수의 복잡한 초기화에 사용된다.
인스턴스 초기화 블럭 - 인스턴스변수의 복잡한 초기화에 사용된다.
초기화 블럭을 작성하려면, 인스턴스 초기화 블럭은 단순히 클래스 내에 블럭{}만들고 그 안에 코드를 작성하기만 하면 된다. 그리고 클래스 초기화 블럭은 인스턴스 초기화 블럭 앞에 단순히 static을 덧붙이기만 하면 된다.
초기화 블럭 내에는 메서드 내에서와 같이 조건문, 반복문, 예외처리구문 등을 자유롭게 사용할 수 있으므로, 초기화 작업이 복잡하여 명시적 초기화만으로는 부족한 경우 초기화 블럭을 사용한다.

클래스 초기화 블럭은 클래스가 메모리에 처음 로딩될 때 한번만 수행되며, 인스턴스 초기화 블럭은 생성자와 같이 인스턴스를 생성할 때 마다 수행된다.
인스턴스 변수의 초기화는 주로 생성자를 사용하고, 인스턴스 초기화 블럭은 모든 생성자에서 공통으로 수행돼야 하는 코드를 넣는데 사용한다.
6.4 멤버변수의 초기화 시기와 순서
클래스변수의 초기화시점: 클래스가 처음 로딩될 때 단 한번 초기화 된다.
인스턴스변수의 초기화시점: 인스턴스가 생성될 때마다 각 인스턴스별로 초기화가 이루어진다.클래스변수의 초기화순서: 기본값 -> 명시적초기화 -> 클래스 초기화 블럭
인스턴스변수의 초기화순서: 기본값 -> 명시적초기화 -> 인스턴스 초기화 블럭 -> 생성자
프로그램 실행도중 클래스에 대한 정보가 요구될 때, 클래스는 메모리에 로딩된다. 예를 들면, 클래스 멤버를 사용했을 때, 인스턴스를 생성할 때 등이 이에 해당한다.
하지만, 해당 클래스가 이미 메모리에 로딩되어 있다면, 또다시 로딩하지 않는다. 물론 초기화도 다시 수행되지 않는다.

위의 InitTest클래스는 클래스변수(cv)와 인스턴스변수(iv)를 각각 하나씩 가지고 있다. 'new InitTest();'와 같이 하여 인스턴스를 생성했을 때, cv와 iv가 초기화되어가는 과정을 단계별로 자세히 살펴보도록 하자.

▶︎ 클래스변수 초기화(1 ~ 3): 클래스가 처음 메모리에 로딩될 때 차례대로 수행됨.
▶︎ 인스턴스변수 초기화(4 ~ 7): 인스턴스를 생성할 때 차례대로 수행됨.
[중요] 클래스변수는 항상 인스턴스변수보다 항상 먼저 생성되고 초기화 된다.
- cv가 메모리(method area)에 생성되고, cv에는 int형의 기본값인 0에 cv에 저장된다.
- 그 다음에는 명시적 초기화(int cv = 1)에 의해서 cv에 1이 저장된다.
- 마지막으로 클래스 초기화 블럭(cv = 2)이 수행되어 cv에는 2가 저장된다.
- InitTest클래스의 인스턴스가 생성되면서 iv가 메모리(heap)에 존재하게 된다. iv 역시 int형 변수이므로 기본값 0이 저장된다.
- 명시적 초기화에 의해서 iv에 1이 저장되고
- 인스턴스 초기화 블럭이 수행되어 iv에 2가 저장된다.
- 마지막으로 생성자가 수행되어 iv에는 3이 저장된다.
