1. java.lang패키지
java.lang패키지는 자바프로그래밍에 가장 기본이 되는 클래스들을 포함하고 있다. 그렇기 때문에 java.lang패키지의 클래스들은 import문 없이도 사용할 수 있게 되어 있다. 그 동안 String클래스나 System클래스를 import문 없이 사용할 수 있었던 이유가 바로 java.lang패키지에 속한 클래스들이기 때문이었던 것이다.
1.1 Object클래스
Object클래스는 모든 클래스의 최고 조상이기 때문에 Object클래스의 멤버들은 모든 클래스에서 바로 사용 가능하다.
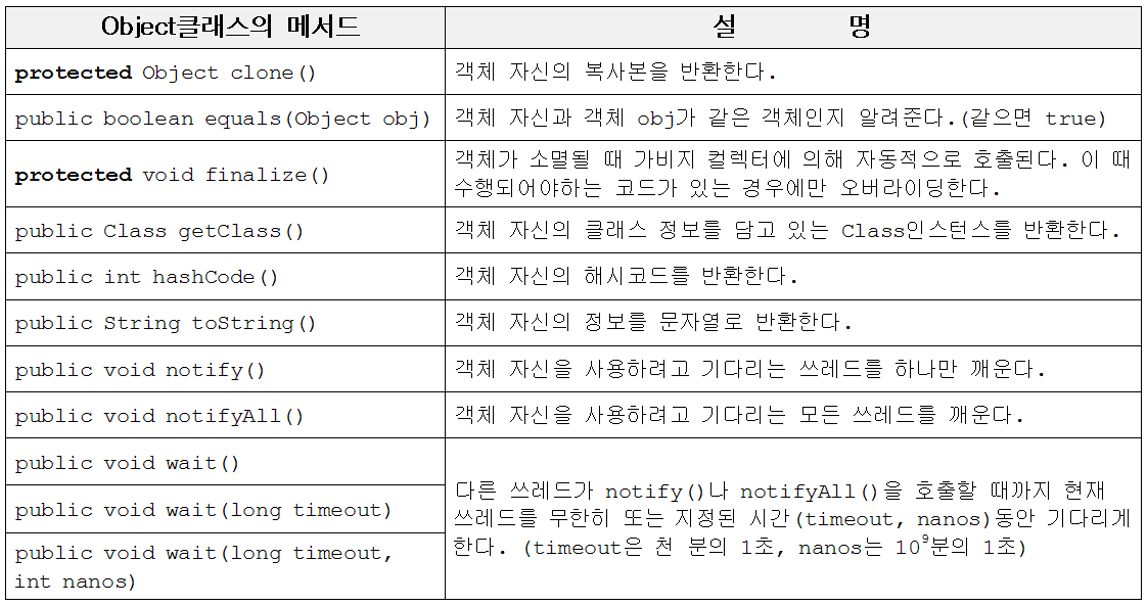
Object클래스는 멤버변수는 없고 오직 11개의 메서드만 가지고 있다. 이 메서드들은 모든 인스턴스가 가져야 할 기본적인 것들이며, 우선 이 중에서 중요한 몇 가지에 대해서 알아보도록 하자.
equals(Object obj)
매개변수로 객체의 참조변수를 받아서 비교하여 그 결과를 boolean값으로 알려 주는 역할을 한다. 아래의 코드는 Object클래스에 정의되어 있는 equals메서드의 실제 내용이다.

위의 코드에서 알 수 있듯이 두 객체의 같고 다름을 참조변수의 값으로 판단한다. 그렇기 때문에 서로 다른 두 객체를 equals메서드로 비교하면 항상 false를 결과로 얻게 된다.
hashCode()
이 메서드는 해싱(hashing)기법에 사용되는 '해시함수(hash function)'를 구현한 것이다.
해싱은 데이터관리기법 중의 하나인데 다량의 데이터를 저장하고 검색하는 데 유용하다.
해시함수는 찾고자하는 값을 입력하면, 그 값이 저장된 위치를 알려주는 해시코드(hash code)를 반환한다.
일반적으로 해시코드가 같은 두 객체가 존재하는 것이 가능하지만, Object클래스에 정의된 hashCode메서드는 객체의 주소값을 이용해서 해시코드를 만들어 반환하기 때문에 서로 다른 두 객체는 결코 같은 해시코드를 가질 수 없다.
앞서 살펴본 것과 같이 클래스의 인스턴스변수 값으로 객체의 같고 다름을 판단해야하는 경우라면 equals메서드 뿐 만아니라 hashCode메서드도 적절히 오버라이딩해야 한다. 같은 객체라면 hashCode메서드를 호출했을 때의 결과값인 해시코드도 같아야 하기 때문이다. 만일 hashCode메서드를 오버라이딩하지 않는다면 Object클래스에 정의된 대로 모든 객체가 서로 다른 해시코드값을 가질 것이다.
toString()
이 메서드는 인스턴스에 대한 정보를 문자열(String)로 제공할 목적으로 정의한 것이다.
인스턴스의 정보를 제공한다는 것은 대부분의 경우 인스턴스 변수에 저장된 값들을 문자열로 표현한다는 뜻이다.
Object클래스에 정의된 toString()은 아래와 같다.

클래스를 작성할 때 toString()을 오버라이딩하지 않는다면, 위와 같은 내용이 그대로 사용될 것이다. 즉, toString()을 호출하면 클래스이름에 16진수의 해시코드를 얻게 될 것이다.
clone()
이 메서드는 자신을 복제하여 새로운 인스턴스를 생성하는 일을 한다. 어떤 인스턴스에 대해 작업을 할 때, 원래의 인스턴스는 보존하고 clone메서드를 이용해서 새로운 인스턴스를 생성하여 작업을 하면 작업이전의 값이 보존되므로 작업에 실패해서 원래의 상태로 되돌리거나 변경되기 전의 값을 참고하는데 도움이 될 것이다.
Object클래스에 정의된 clone()은 단순히 인스턴스변수의 값만을 복사하기 때문에 참조변수 타입의 인스턴스 변수가 정의되어 있는 클래스는 완전한 인스턴스 복제가 이루어지지 않는다.
예를 들어 배열의 경우, 복제된 인스턴스도 같은 배열의 주소를 갖기 때문에 복제된 인스턴스의 작업이 원래의 인스턴스에 영향을 미치게 된다. 이런 경우 clone메서드를 오버라이딩해서 새로운 배열을 생성하고 배열의 내용을 복사하도록 해야 한다.
공변 반환타입
JDK1.5부터 '공변 반환타입(covariant return type)'이라는 것이 추가되었는데, 이 기능은 오버라이딩할 때 조상 메서드의 반환타입을 자손 클래스의 타입으로 변경을 허용하는 것이다.
얕은 복사와 깊은 복사
clone()은 단순히 객체에 저장된 값을 그대로 복제할 뿐, 객체가 참조하고 있는 객체까지 복제하지는 않는다. 기본형 배열인 경우에는 아무런 문제가 없지만, 객체배열을 clone()으로 복제하는 경우에는 원본과 복제본이 같은 객체를 공유하므로 완전한 복제라고 보기 어렵다. 이러한 복제(복사)를 '얕은 복사(shallow copy)'라고 한다. 얕은 복사에서는 원본을 변경하면 복사본도 영향을 받는다.
반면에 원본이 참조하고 있는 객체까지 복제하는 것을 '깊은 복사(deep copy)'라고 하며, 깊은 복사에서는 원본과 복사본이 서로 다른 객체를 참조하기 때문에 원본의 변경이 복사본에 영향을 미치지 않는다.
getClass()
이 메서드는 자신이 속한 클래스의 Class객체를 반환하는 메서드인데, Class객체는 이름이 'Class'인 클래스의 객체이다. Class클래스는 아래와 같이 정의되어 있다.
public final class Class implements ... { // Class클래스
...
}Class객체는 클래스의 모든 정보를 담고 있으며, 클래스당 단 1개만 존재한다. 그리고 클래스 파일이 '클래스 로더(ClassLoader)'에 의해서 메모리에 올라갈 때, 자동적으로 생성된다.
클래스 로더는 실행 시에 필요한 클래스를 동적으로 메모리에 로드하는 역할을 한다. 먼저 기존에 생성된 클래스 객체가 메모리에 존재하는지 확인하고, 있으면 객체의 참조를 반환하고 없으면 클래스 패스(classpath)에 지정된 경로를 따라서 클래스 파일을 찾는다.
못 찾으면 ClassNotFoundException이 발생하고, 찾으면 해당 클래스 파일을 읽어서 Class객체로 반환한다.
파일 형태로 저장되어 있는 클래스를 읽어서 Class클래스에 정의된 형식으로 변환하는 것이다. 즉, 클래스 파일을 읽어서 사용하기 편한 형태로 저장해 놓은 것이 클래스 객체이다.
Class객체를 얻는 방법
클래스의 정보가 필요할 때, 먼저 Class객체에 대한 참조를 얻어 와야 하는데, 해당 Class객체에 대한 참조를 얻는 방법은 여러 가지가 있다.
Class cObj = new Card().getClass(); // 생성된 객체로 부터 얻는 방법
Class cObj = Card.class; // 클래스 리터럴(*.class)로 부터 얻는 방법
Class cObj = Class.forName("Card"); // 클래스 이름으로 부터 얻는 방법특히 forName()은 특정 클래스 파일, 예를 들어 데이터베이스 드라이버를 메모리에 올릴 때 주로 사용한다.
Class객체를 이용하면 클래스에 정의된 멤버의 이름이나 개수 등, 클래스에 대한 모든 정보를 얻을 수 있기 때문에 Class객체를 통해서 객체를 생성하고 메서드를 호출하는 등 보다 동적인 코드를 작성할 수 있다.
Card c = new Card(); // new연산자를 이용해서 객체 생성
Card c = Card.class.newInstance(); // Class객체를 이용해서 객체 생성동적으로 객체를 생성하고 메서드를 호출하는 방법에 대해 더 알고 싶다면, '리플렉션 API(reflection API)'로 검색하면 된다.
1.2 String클래스
기존의 다른 언어에서는 문자열을 char형의 배열로 다루었으나 자바에서는 문자열을 위한 클래스를 제공한다. 그것이 바로 String클래스인데, String클래스는 문자열을 저장하고 이를 다루는데 필요한 메서드를 제공한다.
변경 불가능한(immutable) 클래스
String클래스에는 문자열을 저장하기 위해서 문자형 배열 변수(char[]) value를 인스턴스 변수로 정의해놓고 있다. 인스턴스 생성 시 생성자의 매개변수로 입력받는 문자열은 인스턴스변수(value)에 문자형 배열(char[])로 저장되는 것이다.

한번 생성된 String인스턴스가 갖고 있는 문자열은 읽어 올 수만 있고, 변경할 수는 없다.
예를 들어 아래의 코드와 같이 '+'연산자를 이용해서 문자열을 결합하는 경우 인스턴스내의 문자열이 바뀌는 것이 아니라 새로운 문자열("ab")이 담긴 담긴 String인스턴스가 생성되는 것이다.

이처럼 덧셈 연산자'+'를 사용해서 문자열을 결합하는 것은 매 연산 시 마다 새로운 문자열을 가진 String인스턴스가 생성되어 메모리공간을 차지하게 되므로 가능한 한 결합횟수를 줄이는 것이 좋다.
문자열 간의 결합이나 추출 등 문자열을 다루는 작업이 많이 필요한 경우에는 String클래스 대신 StringBuffer클래스를 사용하는 것이 좋다. StringBuffer인스턴스에 저장된 문자열은 변경이 가능하므로 하나의 StringBuffer인스턴스만으로도 문자열을 다루는 것이 가능하다.
문자열의 비교
문자열을 만들 때는 두 가지 방법, 문자열 리터럴을 지정하는 방법과 String클래스의 생성자를 사용해서 만드는 방법이 있다.

String클래스의 생성자를 이용한 경우에는 new연산자에 의해서 메모리할당이 이루어지기 때문에 항상 새로운 String인스턴스가 생성된다. 그러나 문자열 리터럴은 이미 존재하는 것을 재사용하는 것이다.
아래의 그림은 위의 코드가 실행되었을 때의 상황을 나타낸 것이다.
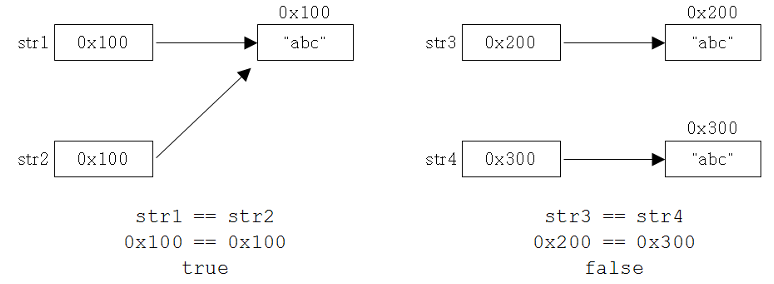
equals()를 사용했을 때는 두 문자열의 내용("abc")을 비교하기 때문에 두 경우 모두 true를 결과로 얻는다. 하지만, 각 String인스턴스의 주소를 등가비교연산자'=='로 비교했을 때는 결과가 다르다.
문자열 리터럴
자바 소스파일에 포함된 모든 문자열 리터럴은 컴파일 시에 클래스 파일에 저장된다. 이때 같은 내용의 문자열 리터럴은 한번만 저장된다. 문자열 리터럴도 String인스턴스이고, 한번 생성하면 내용을 변경할 수 없기 때문에 하나의 인스턴스를 공유하면 되기 때문이다.
빈 문자열(empty string)
'String s = "";'과 같은 문장이 있을 때, 참조변수 s가 참조하고 있는 String인스턴스는 내부에 'new char[0]'과 같이 길이가 0인 char형 배열을 저장하고 있는 것이다.

길이가 0이기 때문에 아무런 문자도 저장할 수 없는 배열이라 무의미하게 느껴지겠지만 어쨌든 이러한 표현이 가능하다.
그러나 'String s = "";'과 같은 표현이 가능하다고 해서 'char c = '';'와 같은 표현도 가능한 것은 아니다. char형 변수에는 반드시 하나의 문자를 지정해야한다.

일반적으로 변수를 선언할 때, 각 타입의 기본값으로 초기화 하지만 String은 참조형 타입의 기본값인 null 보다는 빈 문자열로, char형은 기본값인 '\u0000' 대신 공백으로 초기화 하는 것이 보통이다.
String클래스의 생성자와 메서드



join()과 StringJoiner
join()은 여러 문자열 사이에 구분자를 넣어서 결합한다. 구분자로 문자열을 자르는 split()과 반대의 작업을 한다고 생각하면 이해하기 쉽다.
String animals = "dog, cat, bear";
String[] arr = anmals.split(", "); // 문자열을 ','를 구분자로 나눠서 배열에 저장
String str = String.join("-", arr); // 배열의 문자열을 '-'로 구분해서 결합
System.out.println(str); // dog-cat-bearjava.util.StringJoiner클래스를 사용해서 문자열을 결합할 수도 있는데, 사용하는 방법은 간단하다. 아래의 코드를 보는 것만으로도 이해가 될 것이다.
StringJoiner sj = new StringJoiner("," , "[", "]");
String[] strArr = { "aaa", "bbb", "ccc" };
for(String s : strArr)
sj.add(s.toUpperCase());
System.out.println(sj.toString()); // [AAA, BBB, CCC]유니코드의 보충문자
메서드 중의 매개변수의 타입이 char인 것들이 있고, int인 것들도 있다. 문자를 다루는 메서드라니 매개변수의 타입이 char일 것 같은데 왜 int일까? 그것은 확장된 유니코드를 다루기 위해서이다.
유니코드는 원래 2 byte, 즉 16비트 문자체계인데, 이걸로도 모자라서 20비트로 확장하게 되었다. 그래서 하나의 문자를 char타입으로 다루지 못하고, int타입으로 다룰 수밖에 없다. 확장에 의해 새로 추가된 문자들을 '보충 문자(supplementary characters)'라고 하는데, String클래스의 메서드 중에서는 보충 문자를 지원하는 것이 있고 지원하지 않는 것도 있다. 이들을 구별하는 방법은 쉽다. 매개변수가 'int ch'인 것들은 보충문자를 지원하는 것이고, 'char ch'인 것들은 지원하지 않는 것들이다. 보충 문자를 사용할 일은 거의 없기 때문에 이정도만 알아두자.
문자 인코딩 변환
getBytes(String charsetName)를 사용하면, 문자열의 문자 인코딩을 다른 인코딩으로 변경할 수 있다. 자바가 UTF-16을 사용하지만, 문자열 리터럴에 포함되는 문자들은 OS의 인코딩을 사용한다. 한글 윈도우즈의 경우 문자 인코딩으로 CP949를 사용하며, UTF-8로 변경하려면, 아래와 같이 한다.
byte[] utf8_str = "가".getBytes("UTF-8"); // 문자열을 UTF-8로 변환
String str = new String(utf8_str, "UTF-8"); // byte배열을 문자열로 변환서로 다른 문자 인코딩을 사용하는 컴퓨터 간에 데이터를 주고받을 때는 적절한 문자 인코딩이 필요하다. 그렇지 않으면 알아볼 수 없는 내용의 문서를 보게 될 것이다.
String.format()
format()은 형식화된 문자열을 만들어내는 간단한 방법이다. printf()하고 사용법이 완전히 똑같으므로 사용하는데 별 어려움은 없을 것이다.
String str = String.format("%d 더하기 %d는 %d입니다.", 3, 5, 3 + 5);
System.out.println(str); // 3 더하기 5는 8입니다.기본형 값을 String으로 변환
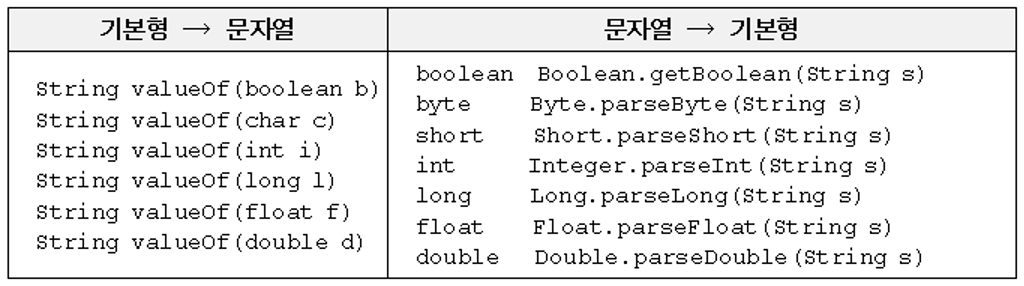
숫자로 이루어진 문자열을 숫자로, 또는 그 반대로 변환하는 경우가 자주 있다. 이미 배운것과 같이 기본형을 문자열로 변경하는 방법은 간단하다. 숫자에 빈 숫자열""을 더해주기만 하면 된다. 이 외에도 valueOf()를 사용하는 방법도 있다. 성능은 valueOf()가 더 좋지만, 빈 문자열을 더하는 방법이 간단하고 편하기 때문에 성능향상이 필요한 경우에만 valueOf()를 쓰자.

String을 기본형 값으로 변환
반대로 String을 기본형으로 변환하는 방법도 간단하다. valueOf()를 쓰거나 앞서 배운 parseInt()를 사용하면 된다.

기본형과 문자열간의 변환방법을 정리하면 다음과 같다.
1.3 StringBuffer클래스와 StringBuilder클래스
String클래스는 인스턴스를 생성할 때 지정된 문자열을 변경할 수 없지만 StringBuffer클래스는 변경이 가능하다. 내부적으로 문자열 편집을 위한 버퍼(buffer)를 가지고 있으며, StringBuffer인스턴스를 생성할 때 그 크기를 지정할 수 있다.
이 때 편집할 문자열의 길이를 고려하여 버퍼의 길이를 충분히 잡아주는 것이 좋다. 편집 중인 문자열이 버퍼의 길이를 넘어서게 되면 버퍼의 길이를 늘려주는 작업이 추가로 수행되어야하기 때문에 작업효율이 떨어진다.
StringBuffer클래스는 String클래스와 유사한 점이 많다. 아래의 코드에서 알 수 있듯이, StringBuffer클래스는 String클래스와 같이 문자열을 저장하기 위한 char형 배열의 참조 StringBuffer클래스는 String클래스와 같이 문자열을 저장하기 위한 char형 배열의 참조변수를 인스턴스변수로 선언해 놓고 있다. StringBuffer인스턴스가 생성될 대, char형 배열이 생성되며 이 때 생성된 char형 배열을 인스턴스변수 value가 참조하게 된다.

StringBuffer의 생성자
StringBuffer클래스의 인스턴스를 생성할 때, 적절한 길이의 char형 배열이 생성되고, 이 배열은 문자열을 저장하고 편집하기 위한 공간(buffer)으로 사용된다.
StringBuffer인스턴스를 생성할 때는 생성자 StringBuffer(int length)를 사용해서 StringBuffer인스턴스에 저장될 문자열의 길이를 고려하여 충분히 여유있는 크기로 지정하는 것이 좋다. StringBuffer인스턴스를 생성할 때, 버퍼의 크기를 지정해주지 않으면 16개의 문자를 저장할 수 있는 크기의 버퍼를 생성한다.
public StringBuffer(int length) {
value = new char[length];
shared = false;
}
public StringBuffer() {
this(16);
{
public StringBuffer(String str) {
this(str.length() + 16);
append(str);
}StringBuffer의 변경
String과 달리 StringBuffer는 내용을 변경할 수 있다.
StringBuffer의 비교
String인스턴스간의 비교에 대해서 학습하면서 등가비교연산자'=='에 의한 비교와 equals메서드에 의한 비교의 차이점을 자세히 알아봤다.
String클래스에서는 equals메서드를 오버라이딩해서 문자열의 내용을 비교하도록 구현되어 있지만, StringBuffer클래스는 equals메서드를 오버라이딩하지 않아서 StringBuffer클래스의 equals메서드를 사용해도 등가비교연산자(==)로 비교한 것과 같은 결과를 얻는다.

반면에 toString()은 오버라이딩되어 있어서 StringBuffer인스턴스에 toString()을 호출하면, 담고있는 문자열을 String으로 반환한다.
그래서 StringBuffer인스턴스에 담긴 문자열을 비교하기 위해서는 StringBuffer인스턴스에 toString()을 호출해서 String인스턴스를 얻은 다음, 여기에 equals메서드를 사용해서 비교해야한다.

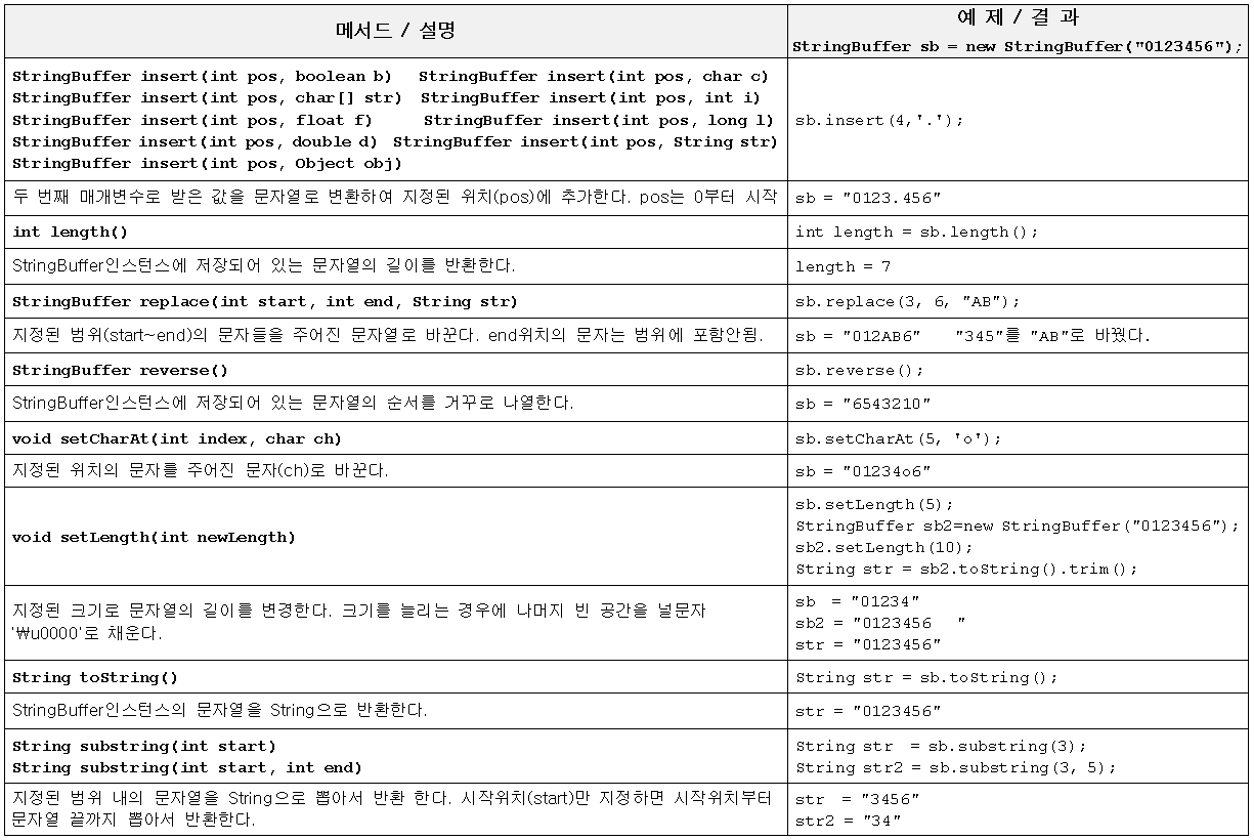
StringBuffer클래스의 생성자와 메서드

StringBuilder란?
StringBuffer는 멀티쓰레드에 안전(thread safe)하도록 동기화되어 있다. 아직은 멀티쓰레드나 동기화에 대해서 배우지 않았지만, 동기화가 StringBuffer의 성능을 떨어뜨린다는 것만 이해하면 된다. 멀티쓰레드로 작성된 프로그램이 아닌 경우, StringBuffer의 동기화는 불필요하게 성능만 떨어뜨리게 된다.
그래서 StringBuffer에서 쓰레드의 동기화만 뺀 StringBuilder가 새로 추가되었다. StringBuilder는 StringBuffer와 완전히 똑같은 기능으로 작성되어 있어서, 소스코드에서 StringBuffer대신 StringBuilder를 사용하도록 바꾸기만 하면 된다. 즉, StringBuffer타입의 참조변수를 선언한 부분과 StringBuffer의 생성자만 바꾸면 된다는 말이다.
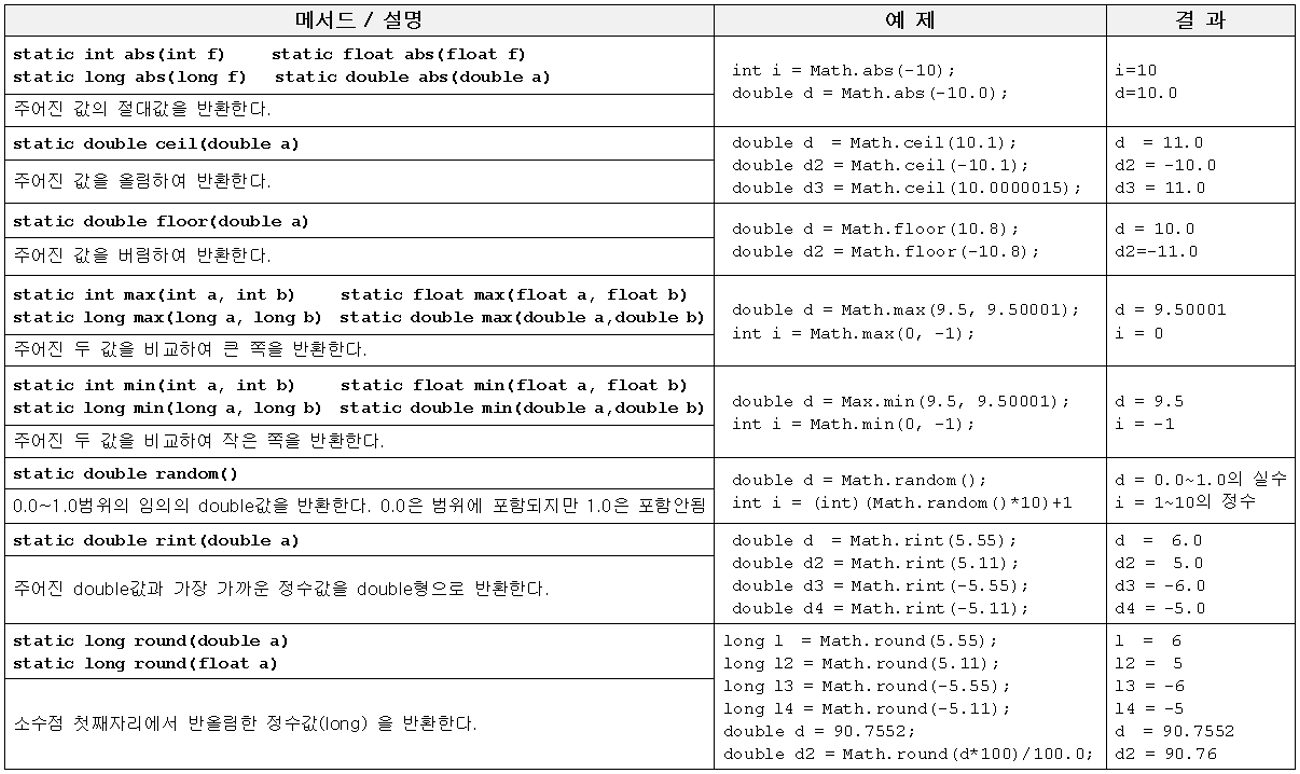
1.4 Math클래스
Math클래스의 메서드
1.5 래퍼(wrapper) 클래스
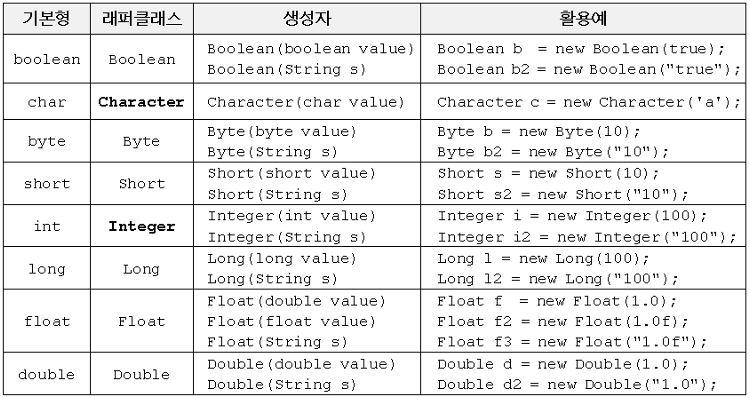
Number클래스
이 클래스는 추상클래스로 내부적으로 숫자를 멤버변수로 갖는 래퍼 클래스들의 조상이다. 아래의 그림은 래퍼 클래스의 상속계층도인데, 기본형 중에서 숫자와 관련된 래퍼 클래스들은 모두 Number클래스의 자손이라는 것을 알 수 있다.
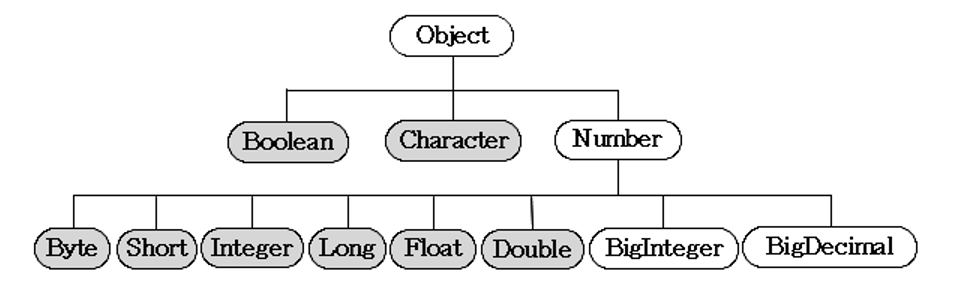
그 외에도 Number클래스 자손으로 BigInteger와 BigDecimal 등이 있는데, BigInteger는 long으로도 다룰 수 없는 큰 범위의 정수를, BigDecimal은 double로도 다룰 수 없는 큰 범위의 부동 소수점수를 처리하기 위한 것으로 연산자의 역할을 대신하는 다양한 메서드를 제공한다.
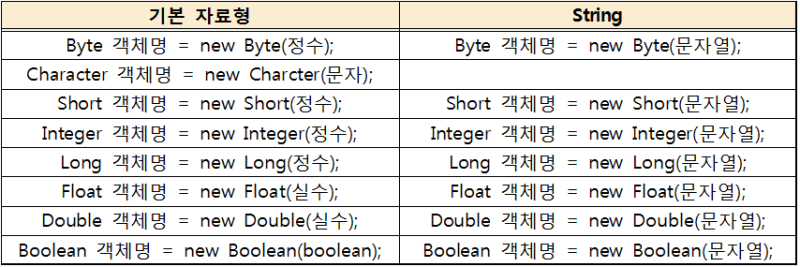
문자열을 숫자로 변환하기
2. 유용한 클래스
2.1 java.util.Objects클래스
Object클래스의 보조 클래스로 Math클래스처럼 모든 메서드가 'static'이다. 객체의 비교나 널 체크(null check)에 유용하다.
isNull()은 해당 객체가 널인지 확인해서 null이면 true를 반환하고 아니면 false를 반환한다. nonNull()은 isNull()과 정확히 반대의 일을 한다. 즉, !Ojbects.isNull(obj)와 같다.
2.2 java.util.Random클래스
난수를 얻는 방법을 생각하면 Math.random()이 떠오를 것이다. 이 외에도 Random클래스를 사용하면 난수를 얻을 수 있다. 사실 Math.random()은 내부적으로 Random클래스의 인스턴스를 생성해서 사용하는 것이므로 둘 중에서 편한 것을 사용하면 된다.
2.3 정규식(Regular Expression) - java.util.regex패키지
정규식이란 텍스트 데이터 중에서 원하는 조건(패턴, pattern)과 일치하는 문자열을 찾아내기 위해 사용하는 것으로 미리 정의된 기호와 문자를 이용해서 작성한 문자열을 말한다. 원래 Unix에서 사용하던 것이고 Perl의 강력한 기능이었는데 요즘은 Java를 비롯해 다양한 언어에서 지원하고 있다.
정규식을 이용하면 많은 양의 텍스트 파일 중에서 원하는 데이터를 손쉽게 뽑아낼 수도 있고 입력된 데이터가 형식에 맞는지 체크할 수도 있다. 예를 들면 html문서에서 전화번호나 이메일 주소만을 따로 추출한다던가, 입력한 비밀번호가 숫자와 영문자의 조합으로 되어 있는지 확인할 수도 있다.
Java API문서에서 java.util.regex.Pattern을 찾아보면 정규식에 사용되는 기호와 작성방법이 모두 설명되어 있지만, 처음부터 이 내용만으로는 정규식을 어떻게 작성해야할지 이해하기가 쉽지는 않을 것이다.
정규식을 자세히 설명하자면 책 한 권 분량이 될 정도로 광범위하기 때문에 깊이 있게 학습하는 것보다는 자주 쓰이는 정규식의 작성 예를 보고 응용할 수 있을 정도까지만 학습하고 넘어가는 것이 좋을 것 같다.
정규식을 정의하고 데이터를 비교하는 과정
- 정규식을 매개변수로 Pattern클래스의 static메서드인 Pattern compile(String regex)을 호출하여 Pattern인스턴스를 얻는다.
Pattern p = Pattern.compile("c[a-z]*");- 정규식으로 비교할 대상을 매개변수로 Pattern클래스의 Matcher (CharSequenceinput)를 호출해서 Matcher인스턴스를 얻는다.
Matcher m = p.matcher(data[i]);- Matcher인스턴스에 boolean matches()를 호출해서 정규식에 부합하는지 확인한다.
if(m.matches())
2.4 java.util.Scanner클래스
Scanner는 화면, 파일, 문자열과 같은 입력소스로부터 문자데이터를 읽어오는데 도움을 줄 목적으로 JDK5.1부터 추가되었다. Scanner에는 다음과 같은 생성자를 지원하기 때문에 다양한 입력소스로부터 데이터를 읽을 수 있다.
Scanner(String source)
Scanner(File source)
Scanner(InputStream source)
Scanner(Readable source)
Scanner(ReadableByteChannel source)
Scanner(Path source)또한 Scanner는 정규식 표현을 이용한 라인단위의 검색을 지원하며 구분자에도 정규식 표현을 사용할 수 있어서 복잡한 형태의 구분자도 처리가 가능하다.
Scanner useDelimiter(Pattern pattern)
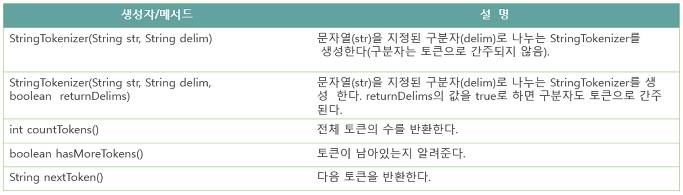
Scanner useDelimiter(String pattern)2.5 java.util.StringTokenizer클래스
StringToken는 긴 문자열ㅇ르 지정된 구분자를 기준으로 토큰이라는 여러 개의 문자열로 잘라내는 데 사용된다. 예를 들어 "100,200,300,400"라는 문자열이 있을 때 ','를 구분자로 잘라내면 "100", "200", "300", "400"이라는 4개의 문자열(토큰)을 얻을 수 있다.
StringTokenizer의 생성자와 메서드
2.6 java.math.BigInteger클래스
정슈형으로 표현할 수 있는 값의 한계가 있다. 가장 큰 정수형 타입인 long으로 표현할 수 있는 값은 10진수로 19자리 정도이다. 이 값도 상당히 큰 값이지만, 과학적 계산에서는 더 큰 값을 다뤄야할 때가 있다. 그럴 때 사용하면 좋은 것이 BigInteger이다.
BigInteger는 내부적으로 int배열을 사용해서 값을 다룬다. 그래서 long타입보다 훨씬 큰 값을 다룰 수 있는 것이다. 대신 성능은 long타입보다 떨어질 수밖에 없다.
2.7 java.math.BigDecimal클래스
double타입으로 표현할 수 있는 값은 상당히 범위가 넓지만, 정밀도가 최대 13자리 밖에 되지 않고 실수형의 특성상 오차를 피할 수 없다. BigDecimal은 실수형과 달리 정수를 이용해서 실수를 표현한다. 앞에서 배운 것과 같이 실수의 오차는 10진 실수를 2진 실수로 정확히 변환할 수 없는 경우가 있기 때문에 발생하는 것이므로, 오차가 없는 2진 정수로 변환하여 다루는 것이다. 실수를 정수와 10의 제곱의 곱으로 표현한다.

