
JCF (Java Collection Framework)
JCF란 자료의 집합 형태에 대한 표준적인 Framework를 정의한 인터페이스/유틸리티들의 목록이며 JDK 1.2에서 정의되었다.
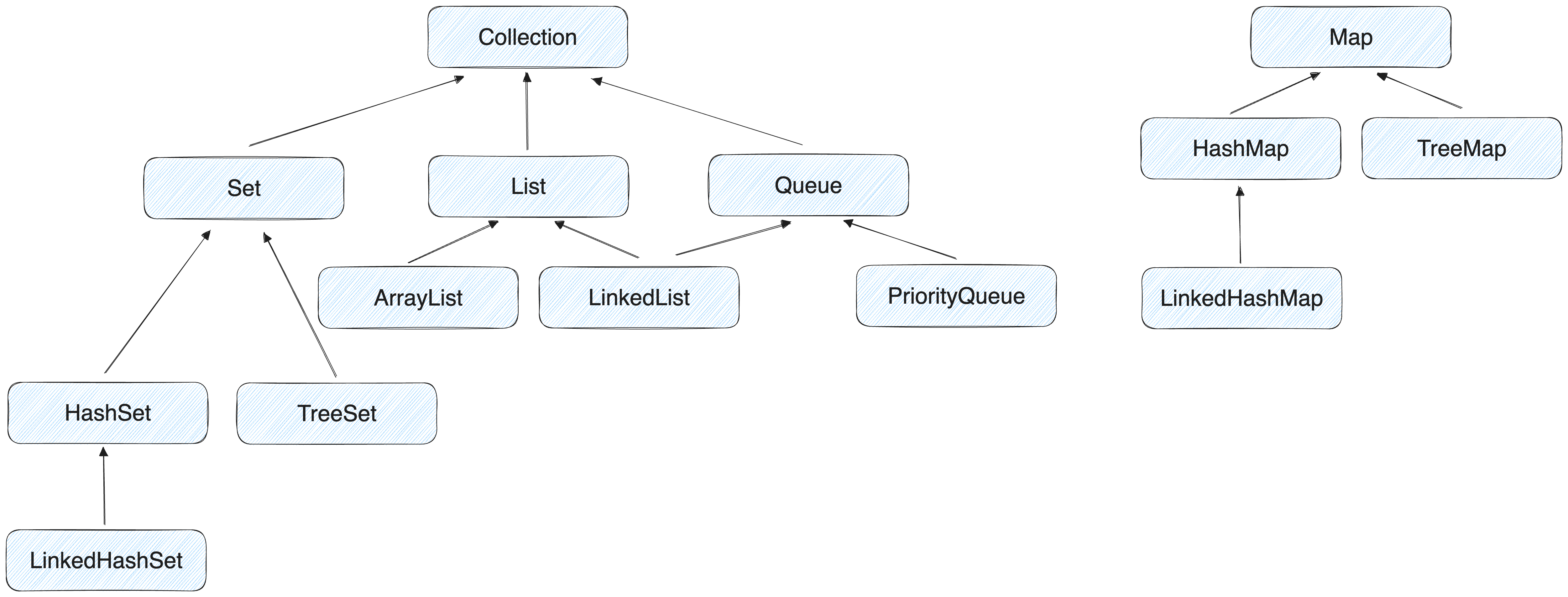
대표적으로 네 가지로 나누어진다.
- List: 순서가 있는 데이터의 집합
- Set: 순서를 유지하지 않는 데이터의 집합
- Queue: FIFO를 유지하는 데이터의 집합
- Map: Key, Value의 페어로 이루어진 데이터의 집합
자바에서는 List, Set, Queue는 Collection이라는 인터페이스를 구현하고 있다. 이 Collection 인터페이스는 java.util 패키지에 선언되어 있으며, 여러 개의 객체를 하나의 객체에 담아 처리할 때 공통적으로 사용되는 여러 메서드들을 선언되어 있다.
유일하게 Map만이 Collection과 관련 없는 별도의 인터페이스로 선언되어 있다.
List
List 인터페이스는 Collection 인터페이스를 확장하고 있다. Collection을 확장한 다른 인터페이스와 달리 List 인터페이스의 가장 큰 차이는 배열처럼 순서가 있다.
List 인터페이스를 구현한 대표적인 클래스로는 ArrayList, Vector, Stack, LinkedList 등이 존재한다.
ArrayList
ArrayList는 크기가 가변적인 배열로 구현된 리스트다. 요소들은 인덱스를 통해 접근할 수 있다. 요소를 추가하거나 삭제할 때, 내부적으로 배열의 크기를 조정하여 동적으로 크기를 확장한다.
ArrayList는 AbstractList를 확장하고 List, RandomAccess, Cloneable, Serializable을 구현받는다.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
}AbstractList의 상위 타입인 AbstractCollection은 Collection 인터페이스 중 일부 공통적인 메서드를 구현해 놓은 것이며, AbstractList는 List 인터페이스 중 일부 공통적인 메서드를 구현해 놓은 것이다.
Vector
Vector는 ArrayList와 유사하지만, 동기화된 메서드로 구성되어 스레드 안전성(Thread-Safe)을 보장한다. ArrayList보다는 성능이 떨어지지만, 멀티스레드 환경에서 안전하게 사용할 수 있다.
Stack
Stack은 후입선출(LIFO, Last In First Out)의 원리를 따르는 자료 구조다. push() 메서드로 요소를 스택의 맨 위에 추가하고, pop() 메서드로 요소를 꺼낸다.
LIFO 기능을 위해서 이 클래스를 쓰는 것을 권장하지 않는다. 왜냐하면 이 클래스보다 ArrayDeque라는 클래스가 존재하기 때문이다. Stack은 pop(), peek() 등의 연산에서 동기화가 되기 때문에 ArrayDeque 클래스보다 성능이 좋지 않다.
public class Stack<E> extends Vector<E> {
public Stack() {
}
public E push(E item) {
addElement(item);
return item;
}
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
}Set
Set은 순서에 상관 없이, 어떤 데이터가 존재하는지를 확인하기 위한 용도로 많이 사용된다. 즉, 중복되는 것을 방지하고 원하는 값이 포함되어 있는지 확인하는 것이 주 목적이다.
Set 인터페이스를 구현한 클래스로는 HashSet, TreeSet, LinkedHashSet이 있다.
HashSet
HashSet은 순서가 전혀 필요 없는 데이터를 해시 테이블에 저장하여 관리한다. 해시 테이블은 HashMap으로 구현되어 있다.
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
}Set은 데이터가 중복되는 것을 허용하지 않으므로, 데이터가 같은지 확인하는 작업은 Set의 핵심이다. 따라서 동등성 비교를 위한 equals(), hashcode()의 구현이 필수적이다.
TreeSet
저장된 데이터의 값에 따라서 정렬되는 Set이다. red-black Tree 타입으로 값이 저장되며, HashSet보다 약간 성능이 느리다.
LinkedHashSet
연결된 목록 타입으로 구현된 해시 테이블에 데이터를 저장한다. 저장된 순서에 따라서 값이 정렬된다. 대신 성능이 위 셋 중에 가장 나쁘다.
Queue
Queue는 먼저 들어온 데이터를 먼저 처리해주는 FIFO 기능을 처리하기 위해 사용된다.
Queue 인터페이스를 구현한 클래스로는 LinkedList가 있다.
LinkedList
LinkedList는 노드들이 링크로 연결된 리스트로 구현되어 있다. 요소를 인데스를 이용해 추가하거나 삭제할 때, ArrayList나 Vector보다는 느릴 수 있지만, 중간에 요소를 삽입하거나 삭제하는 것이 빠르다.
LinkedList의 인터페이스 중에 Deque이 존재한다. Deque는 Queue 인터페이스를 확장하였기 때문에, Queue의 기능을 전부 포함한다.
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable{}Map
Key와 그에 대응되는 Value의 쌍으로 구성되는 객체들을 모아 놓은 구조이다.
Map 인터페이스를 구현한 클래스로는 HashMap, TreeMap, LinkedHashMap이 있다.
HashTable
Map은 Collection View를 사용하지만, HashTable은 Enumeration 객체를 통해서 데이터를 처리한다. Map은 Key, Value, Key-Value를 통해 데이터를 순회할 수 있지만, HashTable은 이 중에서 Key-Value로 데이터를 순회할 수 없다. 또한 Map은 iterator 중에 데이터를 삭제하는 안전한 방법을 제공하지만, HashTable은 그러한 기능을 제공하지 않는다.
HashMap과의 차이점
| 기능 | HashMap | HashTable |
|---|---|---|
| 키나 값에 null 저장 가능 여부 | 가능 | 불가능 |
| Thread Safe | 불가능 | 가능 |
HashMap
TreeMap
TreeMap 클래스는 저장하면서, 키를 저장한다. 정렬되는 기본 순서는 숫자 > 알파벳 대문자 > 알파벳 소문자 > 한글 순이다.
TreeMap은 키의 추가가 있을 때마다 정렬을 해야하기 때문에 HashMap보다 느릴 수 있다. TreeMap이 키를 정렬하는 것은 SortedMap이라는 인터페이스를 구현했기 때문이다.
public class TreeMap<K,V> extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{}
public interface NavigableMap<K,V> extends SortedMap<K,V> {}Properties
LinkedHashMap
