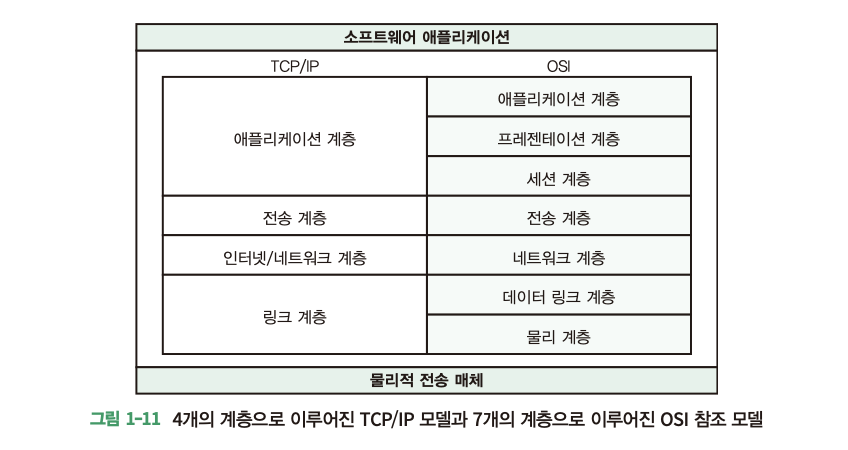
OSI 7계층
OSI 7 계층은 네트워크에서 통신이 일어나는 과정을 7단계로 나눈 것을 말한다.
Application Layer
사용자나 애플리케이션에서 네트워크에 접근할 수 있게 해주는 계층으로 웹, 전자우편 등의 서비스들을 제공하며 데이터를 메시지 단위로 구성해서 처리한다.
예) HTTP, FTP, DNS, SMTP, TELNET
Presentation Layer
전송받은 데이터를 공통으로 이해할 수 있는 데이터로 변환해 주는 과정으로, 데이터 단위를 메시지 단위로 구성해서 처리한다.
예) JPEG, MPEG, XDR
Session Layer
통신하는 사이에서 접속을 유지, 설정, 동기화, 종료시켜 주는 역할을 하는 계층으로, 데이터 단위를 메시지 단위로 구성하여 처리한다.
예) SSH, RPC, TLS
Transport Layer
메시지의 발신지와 목적지 간의 신뢰성을 보장하기 위한 계층으로, 데이터를 세그먼트 단위로 구성해서 통신 과정에서 발생하는 오류를 복구하고 흐름을 제어하는 계층이다. 예) TCP,UDP
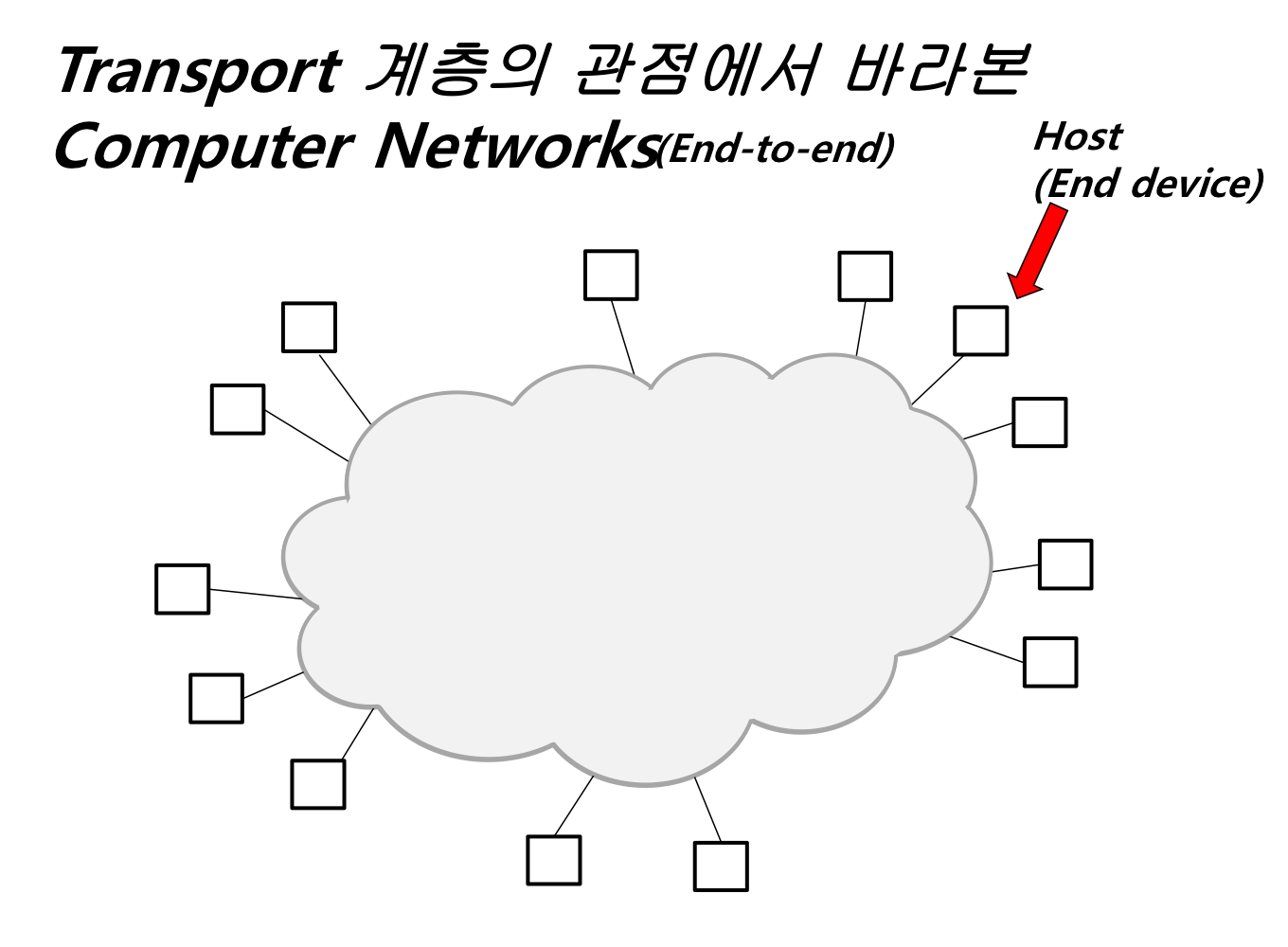
End-to-end의 연결이 관심사. (경로X)
Network Layer
데이터를 패킷 단위로 구성하여 데이터를 어디로 전송해야 하고 어떤 경로(라우팅)로 전송할 것인지를 책임지는 계층이다.
예) IP, ICMP, IGMP, X.25, ARP, OSPF
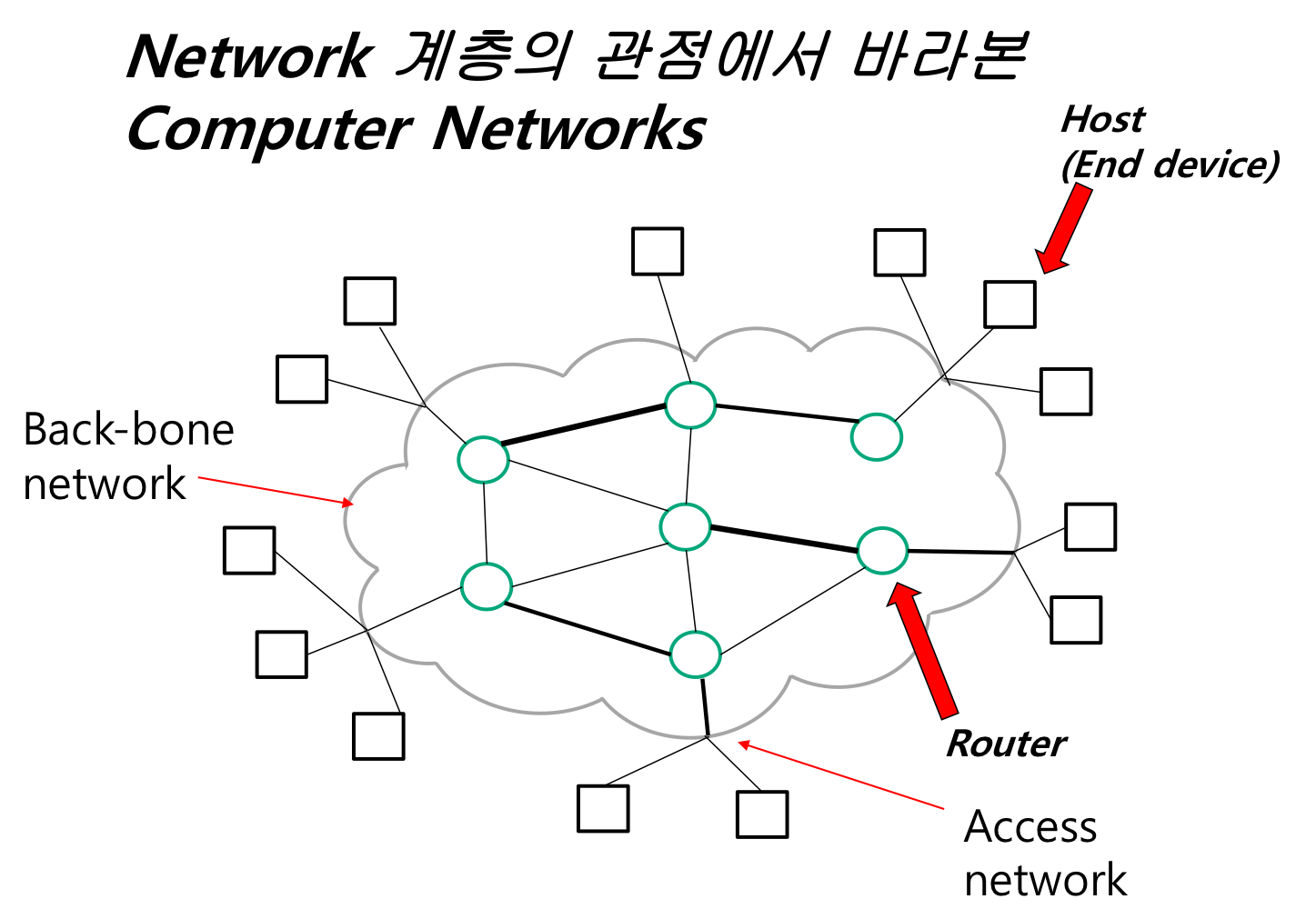
장비와 장비 사이의 경로가 관심사이다.
Data Link Layer
데이터에 오류가 없도록 비트(Bit)로 된 데이터 앞에 헤더와 뒤에 트레일러를 붙여 프레임이라는 논리적 단위로 만들어 전송하는 계층이다.
예) Ethernet, Token Ring, PPP, ISDN, WiFi, FDDI
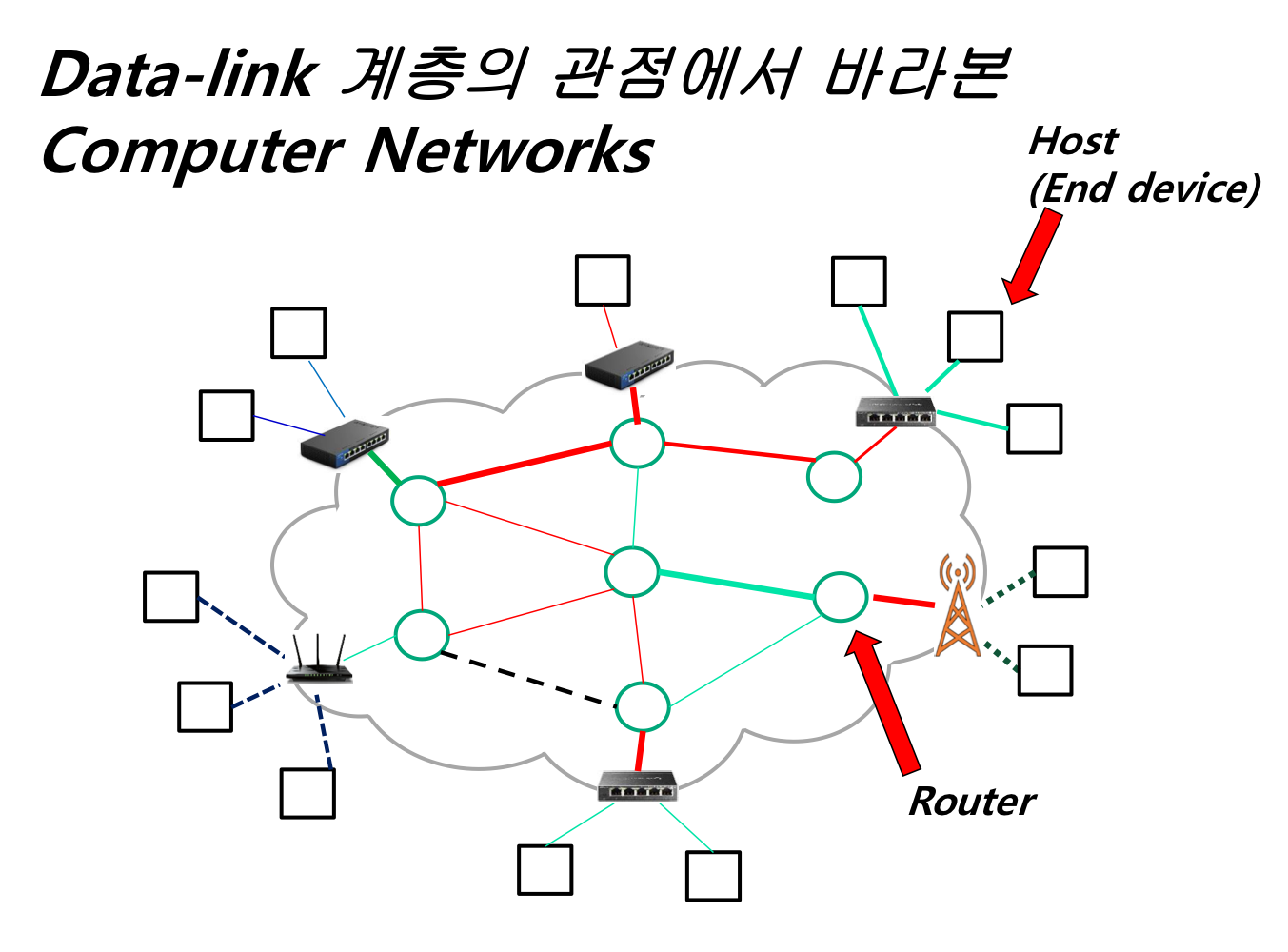
Physical Layer
0과 1로 표현된 비트(Bit)를 전기 신호로 변환하여 전송 매체를 통해 전송하는 계층이다.
예) 동축 케이블, 광섬유, 모뎀, DSU, CLU
TCP/IP Protocol suite
4계층 또는 5계층으로 나누기도 한다.
OSI 7계층의 단점
- OSI를 발표할 때 이미 대부분의 네트워크가 TCP/IP 프로토콜 형태로 구현되어 있었다.
- Presentation, Session 계층은 fully defined 되어 있지 않다.
- 전체적으로 TCP/IP protocol suite를 대체할 만큼 뛰어나지 않다.
TCP, IP는 OS 상에서 구현된다.
비교
Switching
Switching = routing + forwarding
Switch: 임의의 입력 포트와 임의의 출력 포트를 연결시켜 주는 통신 장비
Switching 방식
- Circuit Switching: 전용회선(전화망)
- 전송 순서가 보장한다.
- Bandwidth가 유지되어 데이터 손실이 없다.
- Packet switching: 공유회선(인터넷)
- 전용으로 사용하는 개념이 아니므로, 사용효율이 좋다.
- Packet 손실이 가능하고, 순서가 보장되지 않는다.
- Datagram switching(IP망)
- Virtual circuit switching: 기본적으로 Packet switching이면서 전송 순서가 보장되고 데이터의 loss를 확률적으로 보장하는 방법
Datagram Switching
- Simple connectionless service
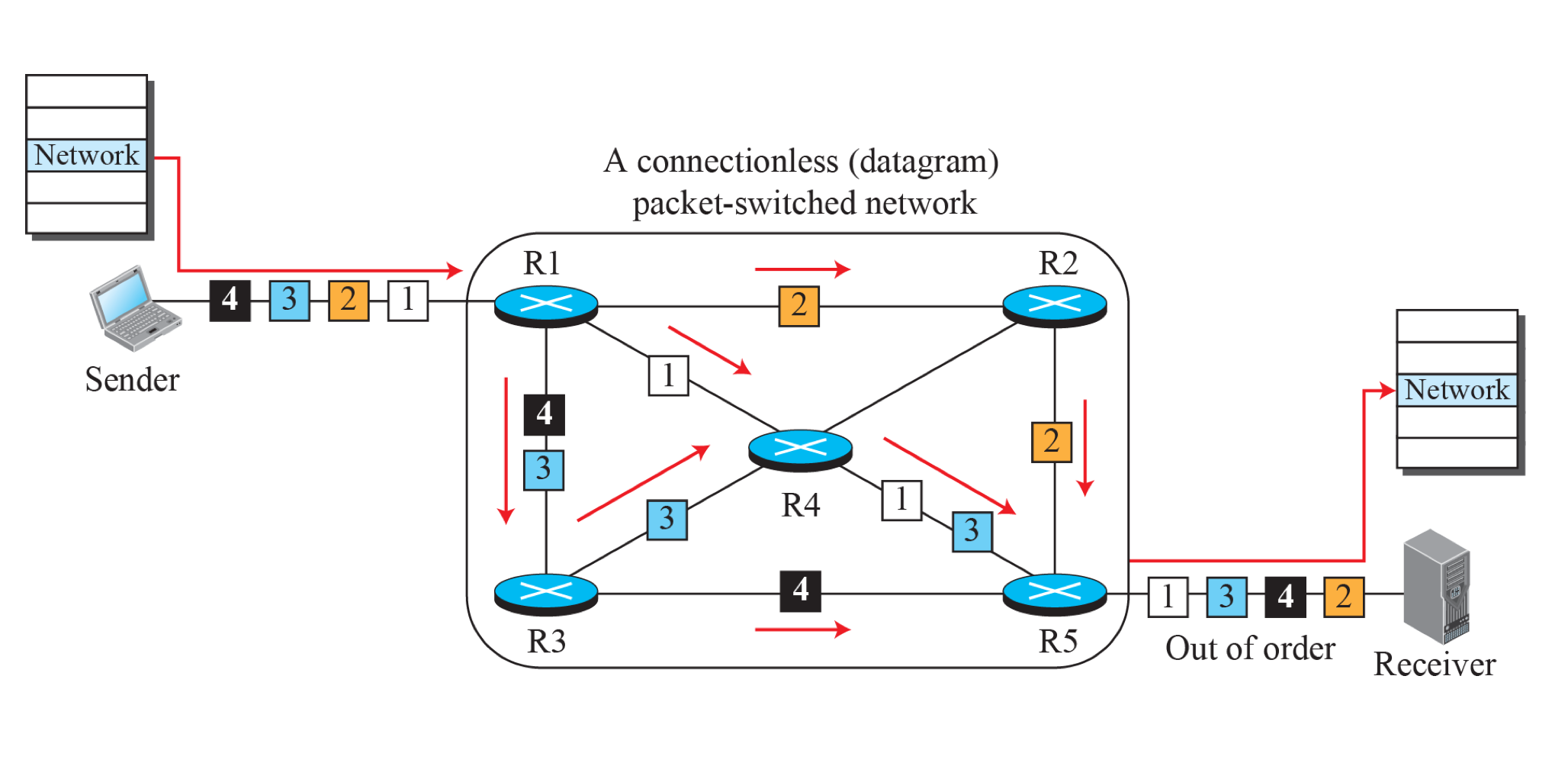
- 각 패킷을 독립적으로 목적지로 전송된다.
- 순서가 보장이 되지 않는다. 왜냐하면 라우터는 패킷이 도착하는 시점에 최적의 루트로 전송하기 때문이다.
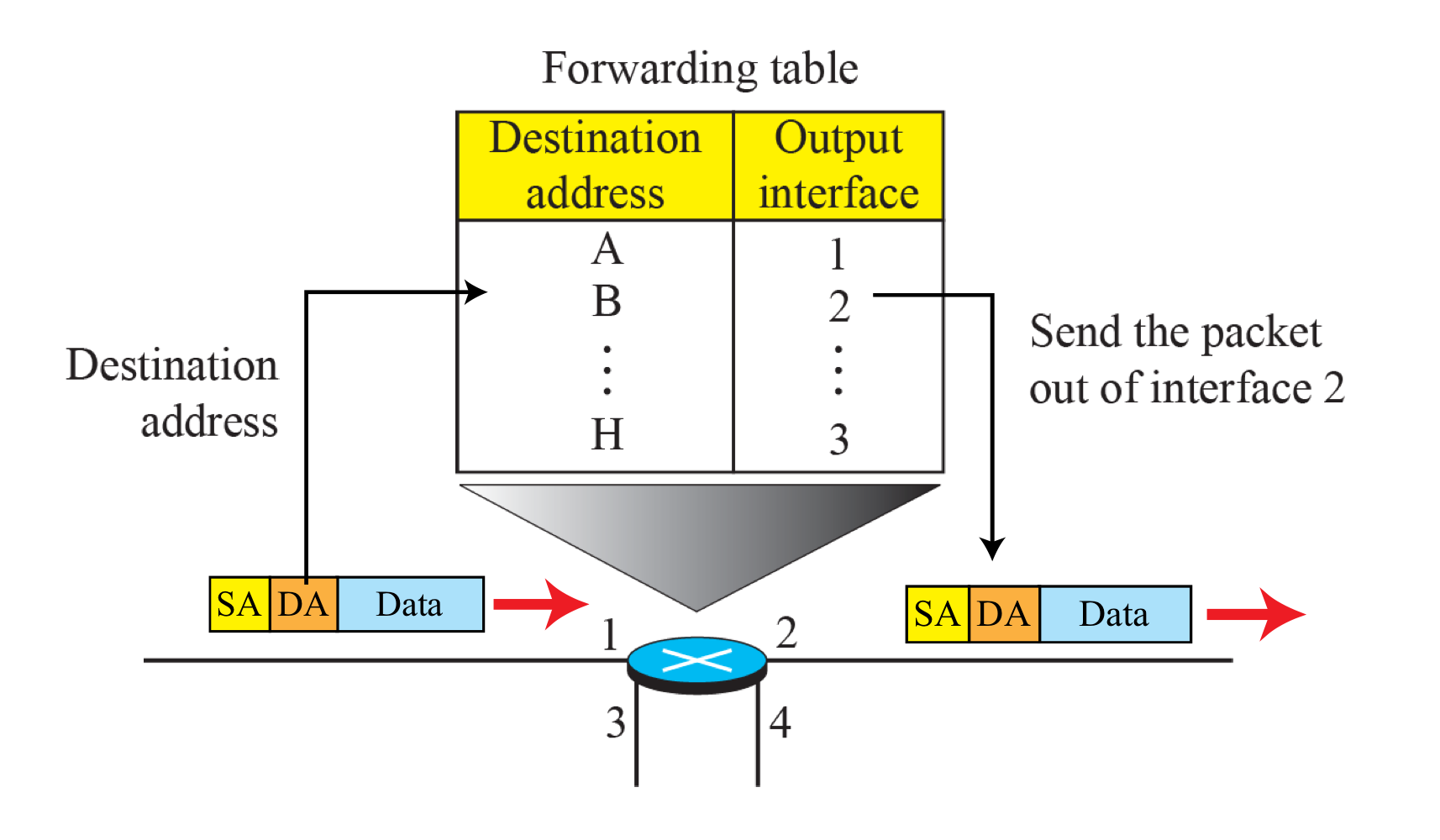
- SA와 DA를 통해 어느 Data Link로 보낼건지 Forwarding Table을 참고하여 Forwarding한다.
IPV4는 Datagram Switching으로 작동한다.
Virtual-Circuit Switching
- Connection-oriented service(경로가 일정함): Connection setup , release 절차가 존재.
- IPv6에서 사용됨.
- Flow label을 적용한다
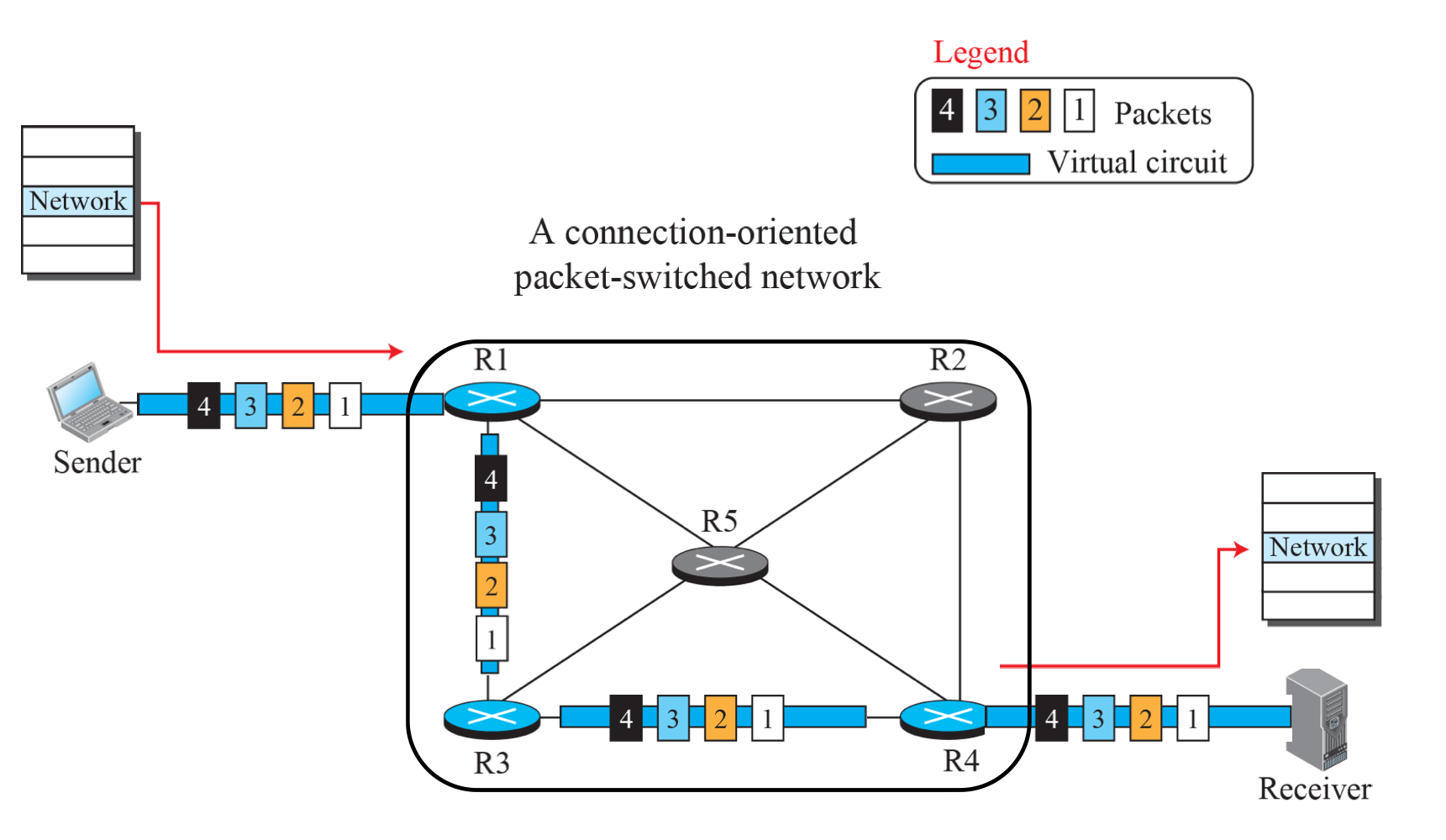
- 라우터들이 경로를 결정한다.
- 패킷 1, 2, 3, 4번은 모두 같은 레이블 번호를 갖는다.
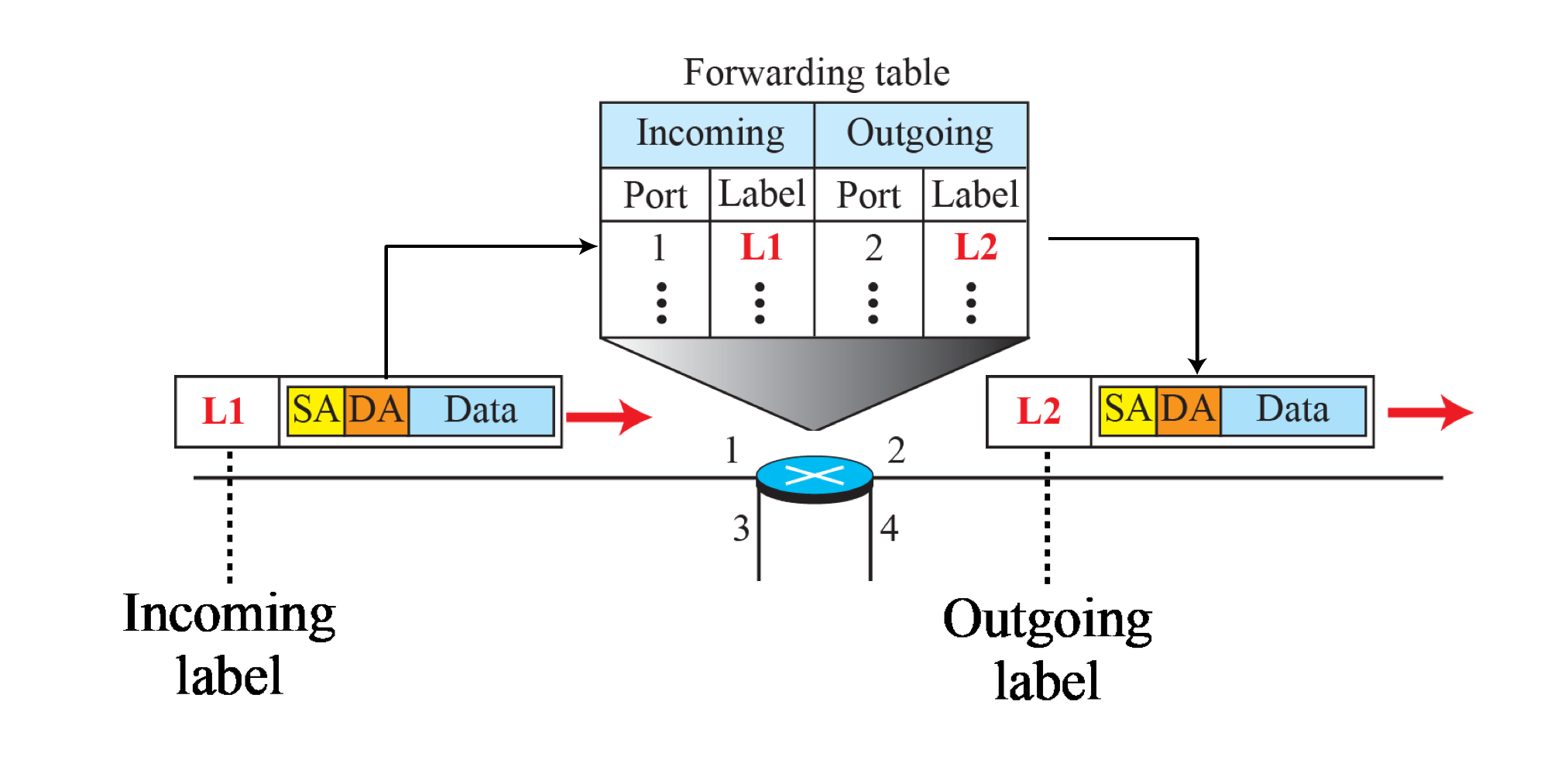
- IP 패킷에 레이블을 추가한다.
- DA를 보고 라우터들이 판단하지 않는다.
- 레이블 번호를 참고하여 Forwarding한다.
Application Layer
Application layer는 사용자에게 서비스를 제공한다.
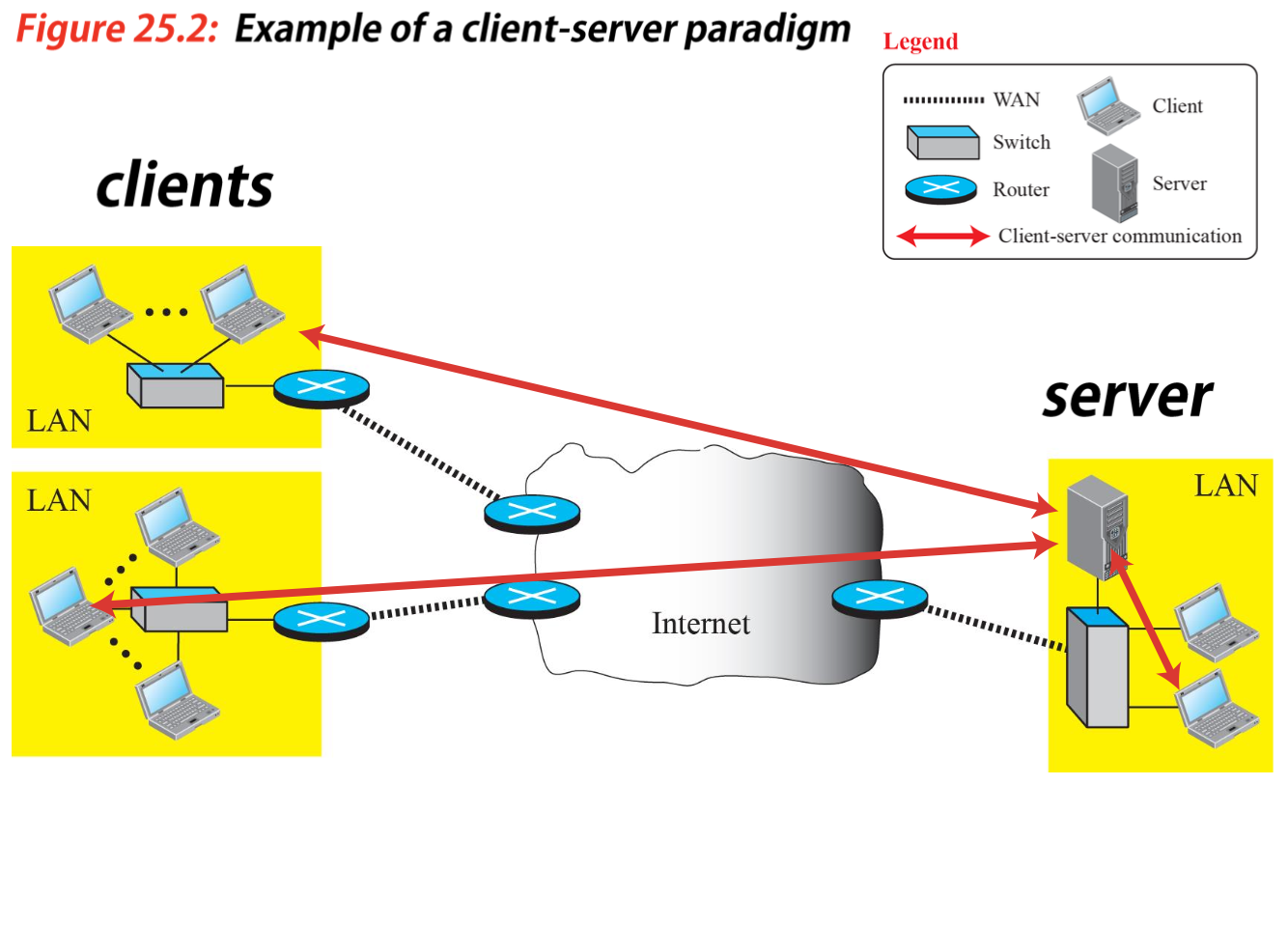
Client-server
- server는 항시 작동 중이다.
- client는 엑세스 가능하다.
- 큰 서버도 다운 가능
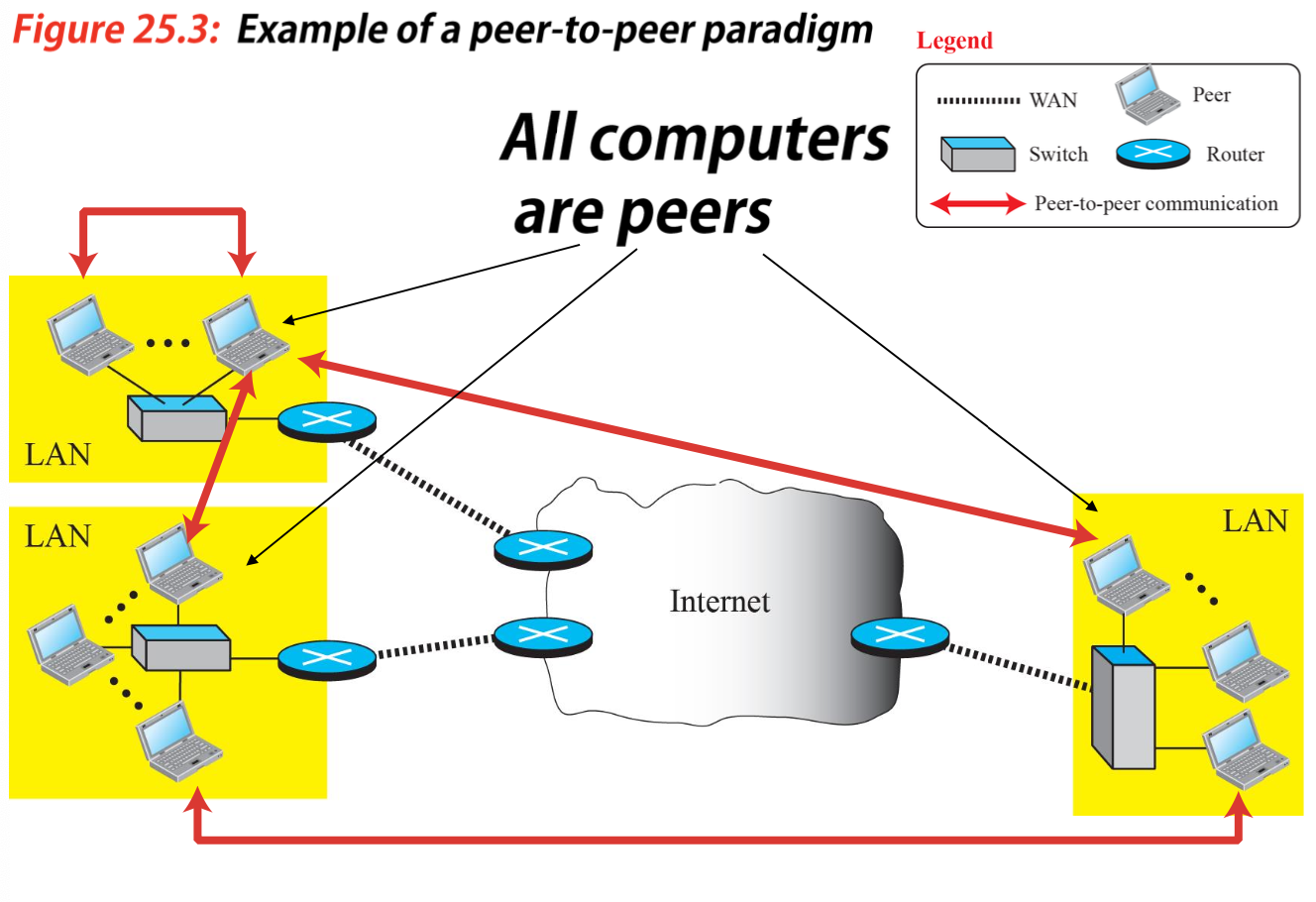
P2P(Peer to peer)
서버를 거치지 않고 클라이언트끼리 직접 통신하는 방식이다.
중앙서버 없이 컴퓨터간의 통신에 사용되며 파일교환이 쉽다는 장점이 있다.
- No need of Server to running all the time.
- Easily scalable
- Challenges
- security
Client-Server programming
API
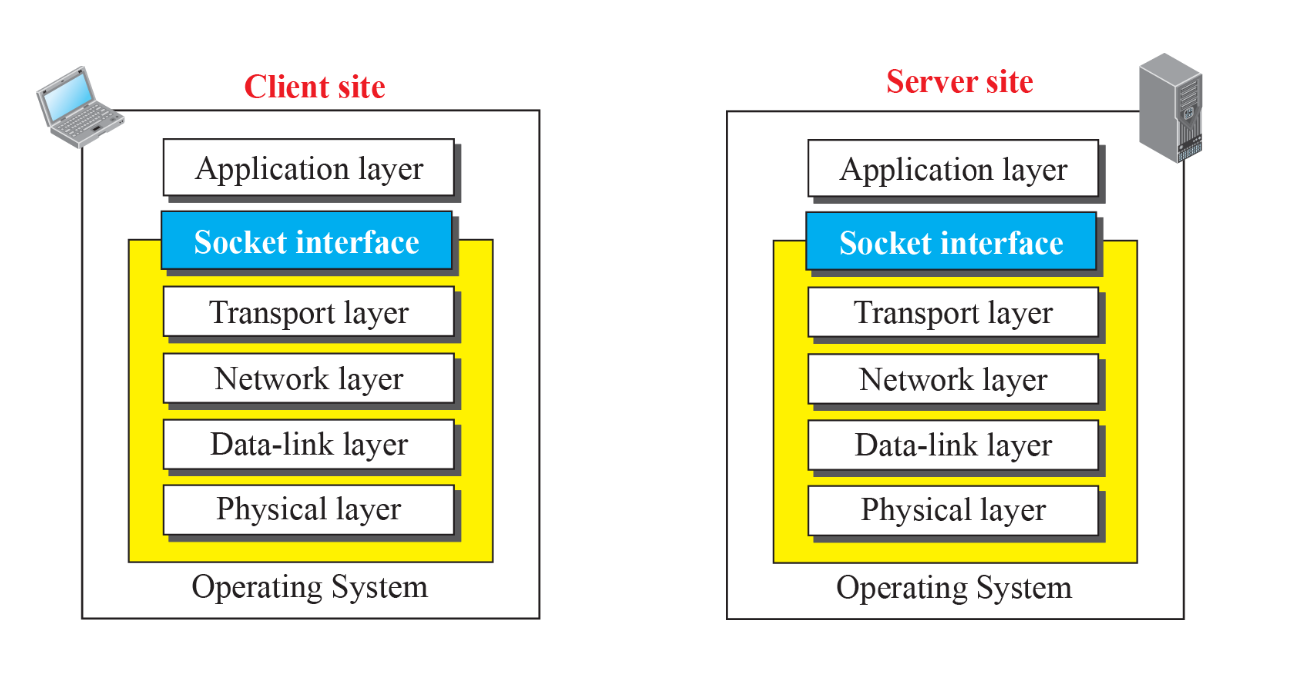
특정 layer를 의미하는 것은 아니다.
Client-Server programming protocols
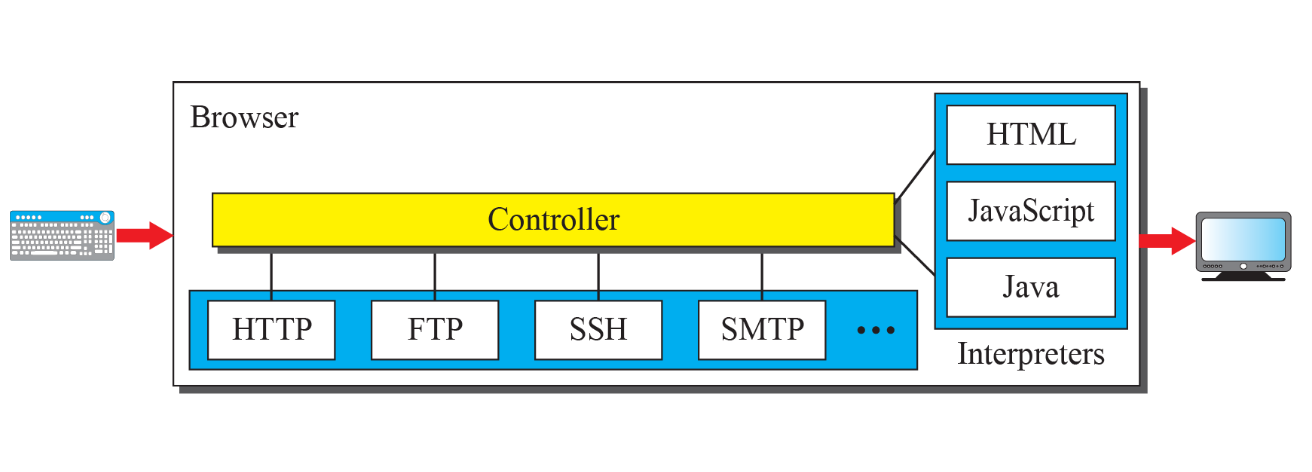
Browser
Controller + client protocols + interpreters
URL
인터넷 상의 특정 문서나 그림의 고유한 주소이다.
Protocol + host + post + path
- Protocol: HTTP, FTP, etc
- Host: www.naver.com
- Port: well known port number
- Path: location of file
HTTP
HTTP는 HTML 문서와 같은 리소스들을 가져올 수 있도록 해주는 프로토콜입니다. HTTP는 웹에서 이루어지는 모든 데이터 교환의 기초이며, 클라이언트-서버 프로토콜이다.
Request&Response
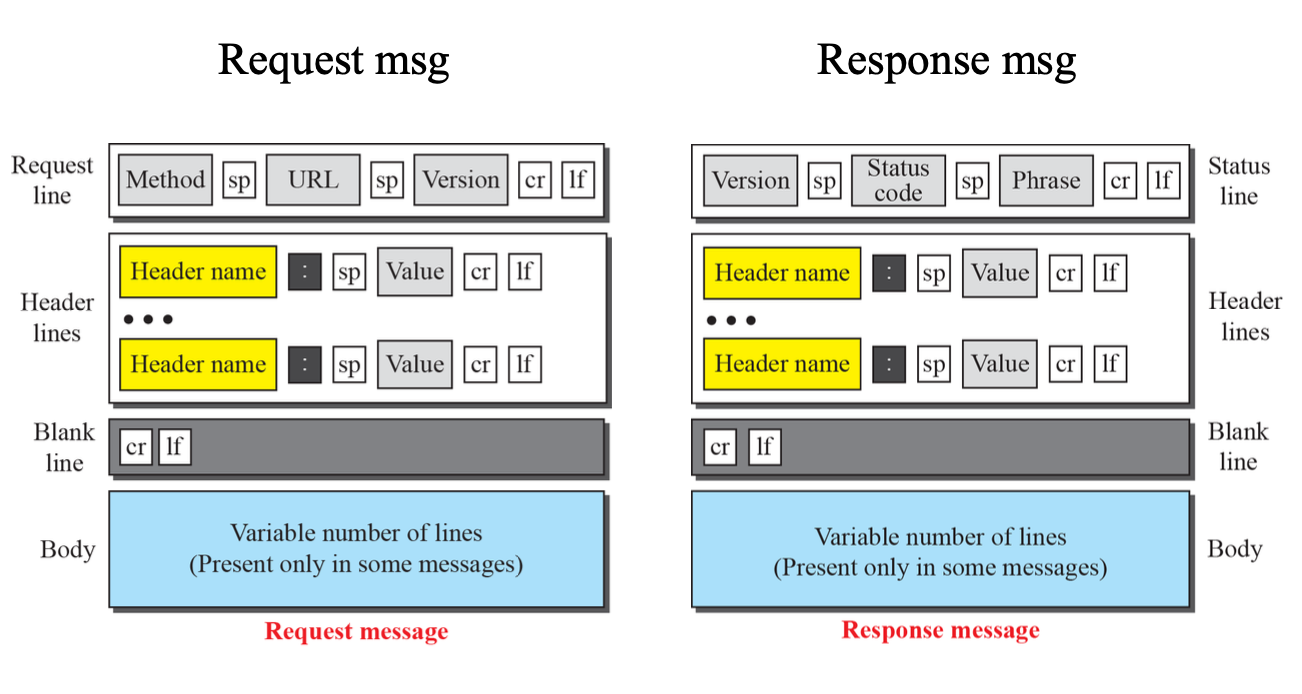
Method
HTTP(HyperText Transfer Protocol) 메서드는 웹 클라이언트가 서버에게 요청을 보내는 데 사용되는 행동 또는 명령을 나타낸다.

- GET: 서버에게 리소스를 요청하기 위한 메서드
- HEAD: 정확하게 GET처럼 행동하지만, 본문은 없고 헤더만 반환
- POST: 클라이언트가 서버에 입력 데이터를 등록하기 위해서 사용
- PUT: 클라이언트가 요청의 본문을 들고 수정하는데, 리소스의 모든 데이터를 수정한다.(전체 데이터를 넣는 용도) 전체 데이터를 보내지 않으면, 나머지 필드는 null이 될 수 있으니 주의해야 한다.
- 기존에 있던 값과 상관 없이 그냥 이 데이터를 넣어서 변경해줘
- 기존에 있던 값에 대해 이런 연산을 진행해서 이 데이터를 통해 데이터를 변경해줘
- PATCH: 클라이언트가 요청의 본문을 들고 수정하는데, 리소스의 일부를 수정한다.
- TRACE: 주로 진단을 위해 사용되며, 요청한 요청이 어떠한 연쇄 요청/응답을 거쳐가는지 알 수 있다
- OPTIONS: 어떤 요청 메서드가 있는지 서버에게 질문하는 용도로 많이 사용한다
- DELETE: 서버에게 요청 URL을 삭제해달라고 하지만, 삭제가 수행되는 것을 보장하지 못한다
멱등성과 안정성
- 멱등성: 동일한 내용의 여러 요청이 있을 때, 각 요청을 처리한 서버의 상태가 모두 동일한 것
- 안정성: 하나의 요청이 있을 때, 처리 전과 후의 서버의 상태가 동일한 것
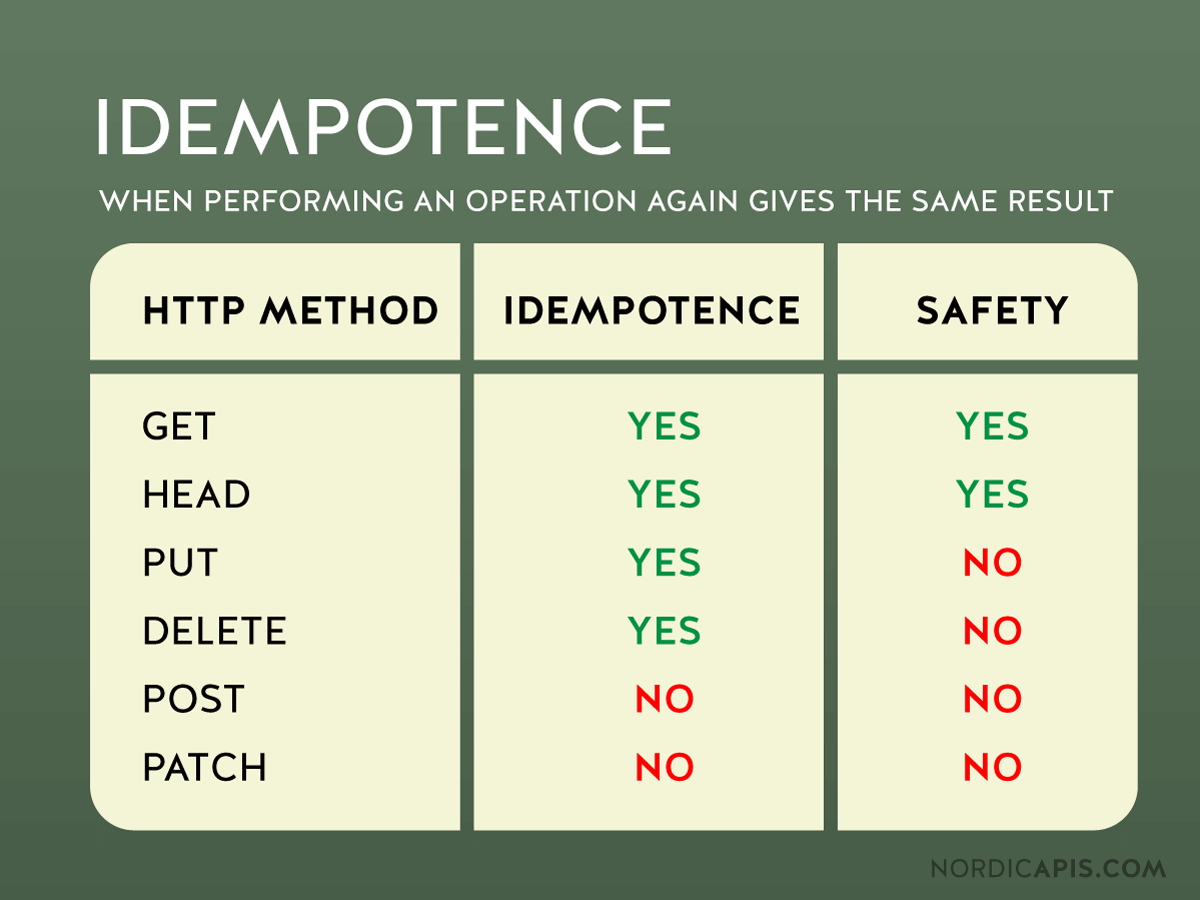
멱등성
- 멱등성은 서버가 동일한 요청을 몇 번 처리하건 간에, 연산을 처리한 후의 서버의 상태가 항상 동일함을 의미한다. 즉, 요청 내용이 동일할 때, 첫번째 요청을 처리한 후와 백 번째 요청을 처리한 후의 서버의 상태가 동일하다는 것이다.
- 멱등성이 보장되는 메소드 :
GET,HEAD,OPTIONS,PUT,DELETEGET: 서버에 존재하는 리소스를 단순히 읽어오기만 하는 메소드이기 때문에 당연히 여러번 수행되어도 결과값은 변하지 않는다. 마찬가지로HEAD,OPTIONS메소드도 조회에 대한 메소드이기 때문에 멱등하다고 할 수 있다.- ex : 내 통장 잔고를 100번 조회해도 잔고는 오르지 않는다.
PUT: 서버에 존재하는 리소스를 요청 내용에 따라 대체하므로, 올바르게 구현되었다면 여러번 수행해도 그 결과는 동일할 것이다.- ex : 완전히 동일한 빨간색 티셔츠 100개를 짱구에게 1번 갈아입히나, 100번 갈아입히나 짱구의 룩은 변하지 않는다
DELETE: 데이터의 존재 유뮤에 따라 응답 코드는 다르겠지만, 요청을 처리한 후에 파일이 존재하지 않는 서버의 상태는 동일하므로 올바르게 구현되었다면 멱등성이 보장될 것이다.- ex : 동일한 맥주잔에 대해 원샷하는 행위를 100번 했을 때, 원샷을 1번 때린 후의 맥주잔의 상태와 100번 때린 후의 맥주잔의 상태는 동일하다.
- 멱등성이 보장되지 않는 메소드 :
POST,**PATCH**POST: 메소드가 호출될 때 마다 서버에 데이터가 추가되어 상태가 변경되기 때문에 멱등성을 위배한다PATCH:PATCH메소드는 항상 멱등성을 보장한다고 할 수 없다.PATCH는 멱등성을 보장하도록 설계할 수 있지만, 멱등성을 보장하지 않도록 설계할 수도 있다.PUT은 요청에 대한 리소스를 통째로 바꿔버리기 때문에 멱등성이 보장되지만,PATCH는 리소스의 일부에 대하여 변화를 명령할 수 있기 때문이다.
위 요청을{ "operation": "add", "age": 10 }PATCH메소드로 실어 보낸다면, 해당하는 리소스의age필드는 요청마다 10씩 증가하게 될 것 이다. 따라서 단일 호출에 대한 응답과 다중 호출에 대한 응답에 대한 서버의 상태가 다를 것이고, 곧 이는 멱등하지 않음을 의미한다.
- 멱등성 보장의 이점
- 시스템의 예상치 못한 동작을 방지하고, 네트워크 통신의 문제로 인한 중복 요청이 발생하는 경우에도 안전성을 보장하는 데 도움이 된다
안정성
- 서버의 상태를 변경시키지 않는 HTTP 메소드
GET,OPTIONS,HEAD와 같이 조회에 사용되는 메소드를 안전하다고 이야기할 수 있다.- 모든 안전한 메소드는 멱등성을 갖지만, 그 역은 성립하지 않는다.
PUT과DELET메소드는 멱등성을 갖지만,PUT은 리소스를 수정하고,DELETE는 메소드를 제거하므로 안전한 메소드라고 할 수 없다.- 멱등성을 갖는 메소드가 서버의 상태를 변경하지 않는다고 오해하면 안된다. 멱등성을 갖는 메소드도 서버의 상태를 변경시킬 수 있다. 멱등성의 핵심은 "요청에 대한 서버의 상태가 항상 같은가?" 이다.
상태 코드 (Status Code)
HTTP 응답 상태 코드는 특정 HTTP 요청이 성공적으로 완료되었는지 알려준다. 응답은 5개의 그룹으로 나누어진다.
- 1XX (Informational, 정보 제공): 임시 응답으로 현재 클라이언트의 요청까지는 처리되었으니 계속 진행하라는 의미다. HTTP 1.1 버전부터 추가되었다.
- 2XX (Success, 성공): 클라이언트의 요청이 서버에서 성공적으로 처리되었다는 의미다.
- 3XX (Redirection, 리다이렉션): 완전한 처리를 위해서 추가 동작이 필요한 경우다. 주로 서버의 주소 또는 요청한 URI의 웹 문서가 이동되었으니 그 주소로 다시 시도하라는 의미이다.
- 4XX (Client Error, 클라이언트 에러): 없는 페이지를 요청하는 등 클라이언트의 요청 메시지 내용이 잘못된 경우를 의미한다.
- 5XX (Server Error, 서버 에러): 서버 사정으로 메시지 처리에 문제가 발생한 경우다. 서버의 부하, DB 처리 과정 오류, 서버에서 익셉션이 발생하는 경우를 의미한다.
주요 상태 코드
| 상태 코드 | 상태 | 의미 |
|---|---|---|
| 2XX | Success | 클라이언트가 요청한 동작을 수신하여 이해하였고 승낙하였으며 성공적으로 처리하였다. |
| 200 | Ok | 서버가 요청을 성공적으로 처리하였다. |
| 201 | Created | 요청이 성공적이었으며 그 결과로 새로운 리소스가 생성되었다. |
| 202 | Accepted | 요청을 수신하였지만 그에 응하여 행동할 수 없다. |
| 3XX | Redirection | 클라이언트는 요청을 마치기 위해 추가 동작을 취해야 한다. |
| 301 | Moved Permanently | 지정한 리소스가 새로운 URI로 이동하였다. |
| 303 | See Other | 다른 위치로 요청하라. |
| 307 | Temporary Redirect | 임시로 리다이렉션 요청이 필요하다. |
| 4XX | Client Error | 클라이언트가 요청한 동작을 수신하여 이해하였고 승낙하였으며 성공적으로 처리하였다. |
| 400 | Bad Request | 이 응답은 잘못된 문법으로 인하여 서버가 요청을 이해할 수 없음을 의미한다. |
| 401 | Unauthorized | 지정한 리소스에 대한 액세스 권한이 없다. |
| 403 | Forbidden | 지정한 리소스에 대한 액세스가 금지되었다. |
| 404 | Not Found | 지정한 리소스를 찾을 수 없다. |
| 5XX | Server Error | 클라이언트의 요청은 유효한데 서버가 처리에 실패하였다. |
| 500 | Internal Server Error | 서버가 처리 방법을 모르는 상황이 발생했다. 서버는 아직 처리 방법을 알 수 없다. |
| 501 | Not Implemented | 요청 방법은 서버에서 지원되지 않으므로 처리할 수 없다. |
| 502 | Bad Gateway | 서버가 요청을 처리하는 데 필요한 응답을 얻기 위해 게이트웨이로 작업하는 동안 잘못된 응답을 수신했음을 의미한다. |
-
200 응답: 성공의 의미는 HTTP 메소드에 따라 달라진다.
- GET: 리소스를 불러와서 메시지 바디에 전송되었다.
- HEAD: 개체 해더가 메시지 바디에 있다.
- PUT 또는 POST: 수행 결과에 대한 리소스가 메시지 바디에 전송되었다.
- TRACE: 메시지 바디는 서버에서 수신한 요청 메시지를 포함하고 있다.
-
202 응답: 요청 처리에 대한 결과를 이후에 HTTP로 비동기 응답을 보내는 것에 대해서 명확하게 명시하지 않다. 이것은 다른 프로세스에서 처리 또는 서버가 요청을 다루고 있거나 배치 프로세스를 하고 있는 경우를 위해 만들어졌다
HTTP 버전별 특징
HTTP 0.9
- 상태코드가 없다.
- Http Method가 GET으로 하나다.
HTTP 1.0
- HTTP 헤더(header) 개념이 도입되어 요청과 응답에 추가되며, 메타데이터를 주고 받고 프로토콜을 유연하고 확장 가능하도록 개선
- 버전 정보와 요청 method가 함께 전송
- 상태 코드 라인도 응답의 시작부분에 추가되어 브라우저 요청의 성공과 실패를 파악 가능
- Content-Type 도입으로 HTML 이외의 문서 전송 기능이 가능
- 커넥션 하나당 요청 하나와 응답 하나만 처리 가능
HTTP 1.1
- Persistent Connection 추가: 지정한 timemout 동안 커넥션을 닫지 않는 방법을 통해 커넥션의 사용성이 높아짐
- 기존 하나의 요청만 보낼 수 있던 한계 극복
- Pipelining 추가: 앞 요청의 응답을 기다리지 않고 순차적인 여러 요청을 연속적으로 보내고 그 순서에 맞춰 응답을 받는 방식
- HOL 문제 발생: 앞 요청의 응답으로 Blocking 발생
- Header 구조의 중복
HTTP 2.0
-
Binary Framing 계층 추가: 메세지를 Frame 단위로 분할하여 추가적으로 binary로 인코딩
- 바이너리 형식 사용으로 파싱속도 및 전송 속도가 빠르고 오류 발생 가능성이 낮아진다
-
동시 요청을 위한 Multiplexing: 요청마다 Stream이라는 흐름의 단위로 나누어 처리하게 한다. 하나의 커넥션이 여러 개의 stream을 통해 전달되면 다중화가 가능하게 되었다. -> HOL 해결
-
Stream Prioritization: 리소스간 우선순위 설정 가능
-
Header 압축: 연속된 요청의 경우 중복된 헤더의 전송으로 오버헤드가 많이 발생했다. Header의 메타 데이터를 압축하여 오버헤드 감소.
QUIC
-
성능 향상: HTTP/3.0은 QUIC 프로토콜을 기반으로 하며, 이는 TCP보다 빠른 연결 설정과 데이터 전송을 제공합니다. 병렬로 다수의 데이터를 송수신할 수 있어 전반적인 웹 페이지 로딩 속도를 향상시킵니다.
-
저렴한 핸드셰이크 비용: QUIC은 핸드셰이크를 줄이고 연결 설정 비용을 최소화하여 빠른 속도를 유지합니다.
-
기존 프로토콜과의 하위 호환성: HTTP/3.0은 기존의 HTTP/1.x 및 HTTP/2.0과 호환되도록 설계되어 있어 기존 웹 서버 및 브라우저에서도 사용이 가능합니다.
단점
-
도입의 복잡성: 기존의 HTTP/1.x 및 HTTP/2.0과는 다르게 새로운 프로토콜인 HTTP/3.0을 도입하는 것은 초기에는 일정한 도전과 적응이 필요합니다.
-
네트워크 관리의 어려움: QUIC은 UDP를 사용하기 때문에 기존의 TCP와는 다른 특성을 가지고 있습니다. 네트워크 관리 및 디버깅이 더 어려울 수 있습니다.
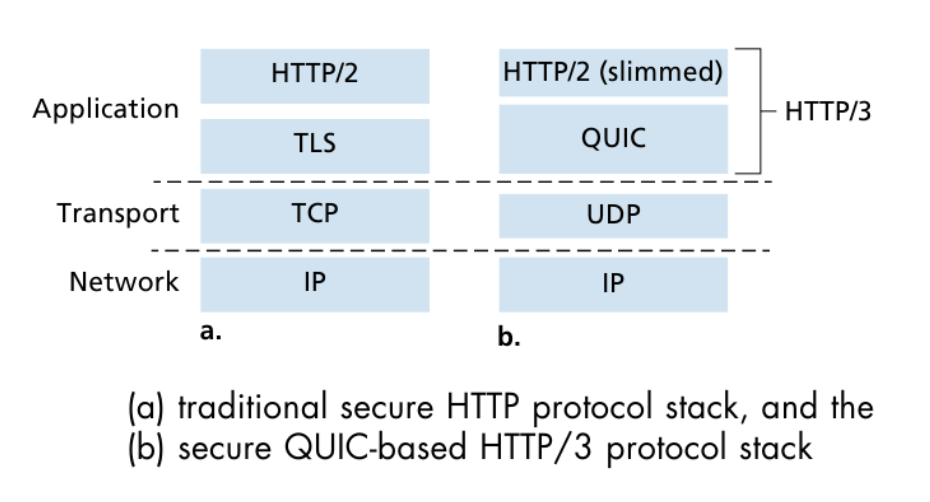
-
TCP는 congestion control로 한계가 존재하기 때문에, UDP를 이용해 구현한다.
-
보안이 기본적으로 들어가 있다.
HTTPS
대칭키 암호화 방식
공개키(비대칭키) 암호화 방식
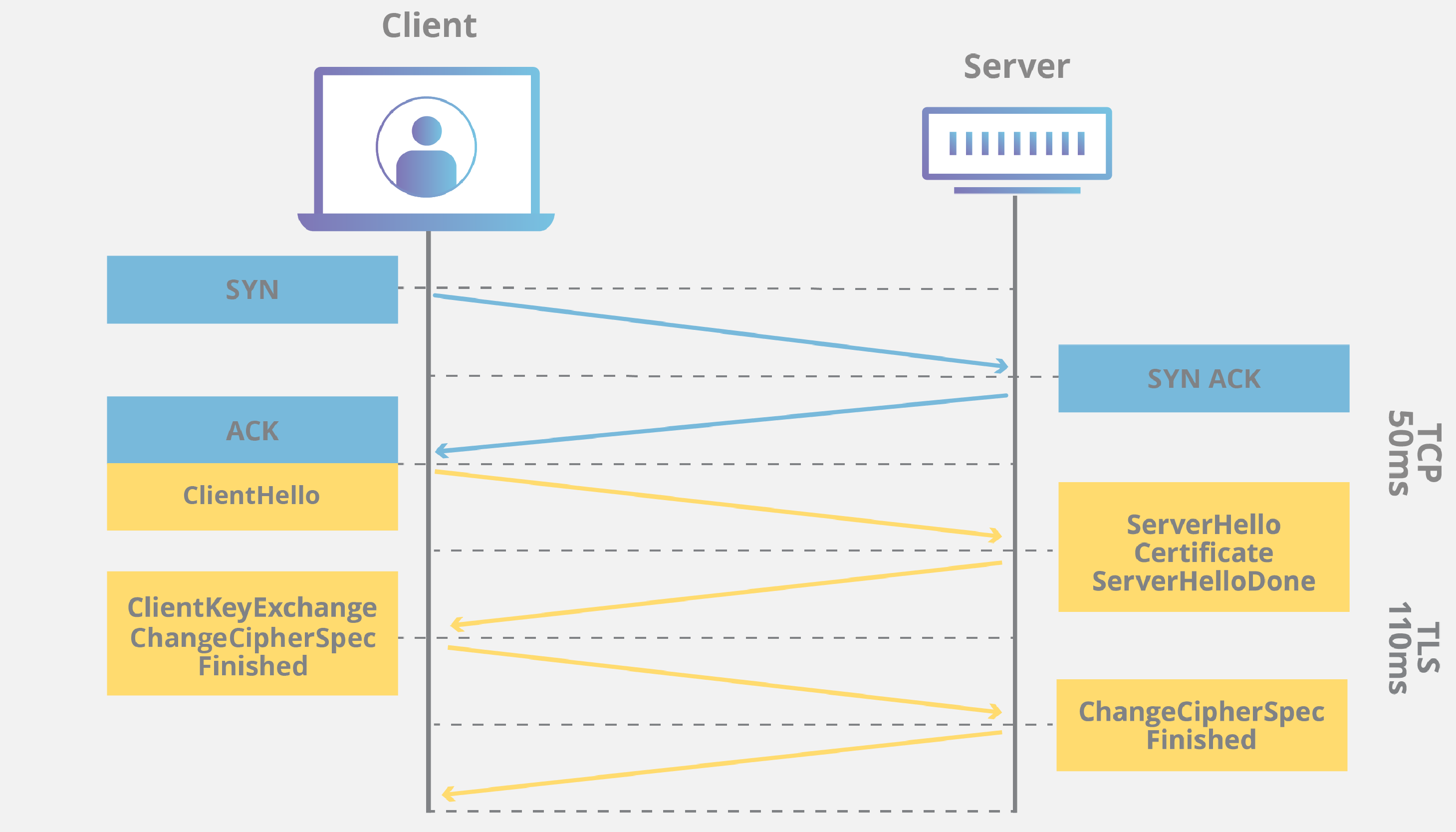
SSL, TLS
- 클라이언트 헬로 (ClientHello): 클라이언트 -> 서버
클라이언트는 서버와의 연결을 시작하기 위해 ClientHello 메시지를 전송한다.
이 메시지에는 클라이언트가 지원하는 TLS 버전, 암호화 스위트(Cipher Suite) 목록, 압축 방법, 세션 ID, 랜덤 데이터(Nonce) 등이 포함된다.
- 서버 헬로 (ServerHello): 클라이언트 <- 서버
서버는 클라이언트의 ClientHello 메시지를 수신하고, 이에 응답하는 ServerHello 메시지를 전송한다.
이 메시지에는 서버가 선택한 TLS 버전, 암호화 스위트, 세션 ID, 랜덤 데이터(Nonce) 등이 포함된다.
- 서버 인증 및 키 교환 (Server Certificate and Key Exchange): 클라이언트 <- 서버
서버는 클라이언트에게 자신의 디지털 인증서를 전송합니다. 이 인증서는 서버의 신원을 확인하기 위해 사용됩니다.
인증서에는 서버의 공개 키와 인증 기관(CA)의 서명이 포함됩니다.
- 서버 헬로 완료 (ServerHelloDone)
서버는 ServerHelloDone 메시지를 전송하여 초기 서버 메시지를 마무리합니다.
- 클라이언트 인증 및 키 교환 (Client Certificate and Key Exchange)
클라이언트 인증이 필요한 경우, 클라이언트는 자신의 인증서를 서버에 전송합니다.
클라이언트 키 교환:
클라이언트는 ClientKeyExchange 메시지를 전송하여 세션 키를 설정하는 데 필요한 키 교환 정보를 서버에 전송합니다.
보통 클라이언트는 서버의 공개 키를 사용하여 프리마스터 시크릿(Premaster Secret)을 암호화하여 서버에 전송합니다.
- 세션 키 생성 (Session Key Generation)
클라이언트와 서버는 서로 전송된 랜덤 데이터와 프리마스터 시크릿을 사용하여 대칭 키(세션 키)를 생성합니다.
이 세션 키는 이후의 데이터 암호화에 사용됩니다.
- 핸드셰이크 완료 (ChangeCipherSpec & Handshake Completion)
클라이언트는 ChangeCipherSpec 메시지를 전송하여 이후의 메시지가 협상된 암호화 및 압축 알고리즘을 사용할 것임을 알립니다.
클라이언트는 Finished 메시지를 전송하여 핸드셰이크가 완료되었음을 알립니다. 이 메시지는 협상된 세션 키로 암호화됩니다.
서버 완료 메시지:
서버도 ChangeCipherSpec 메시지를 전송하여 이후의 메시지가 협상된 암호화 및 압축 알고리즘을 사용할 것임을 알립니다.
서버는 Finished 메시지를 전송하여 핸드셰이크가 완료되었음을 알립니다. 이 메시지 역시 협상된 세션 키로 암호화됩니다.
SMTP(Simple Mail Transfer Protocol)
인터넷 이메일 시스템 구조
- User Agent: 사용자 장치에서 메일 작성, 읽기, 관리 기능을 수행한다.
- Mail Server: 다수 사용자들의 메일 박스 관리, 메일 송수신을 제어한다.
- SMTP: 메일 전송 프로토콜이다.
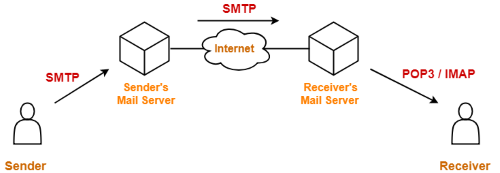
이메일 전송 과정
- 송신자 UA에서 메일 작성 후 메일 서버로 전달한다.
- 송신자 메일 서버의 출력 메시지 큐에 저장한다.
- 수신자 메일 서버로 전송한다.
- 수신자 메일 서버의 수신자 메일 박스에 저장한다.
- 수신자 UA에서 메일 서버의 메일박스에 메일 읽기 및 관리한다.
전송 불가시 30분 단위로 재전송 시도, 정해진 기간 동안 전송 불가지 중단 및 송신자에게 통보
수신자의 메일 서버는 항상 listening 중이지만, 수신자는 그렇지 않다. 따라서 5번 과정은 pull 과정인 POP3, IMAP으로 이루이진다.
SMTP
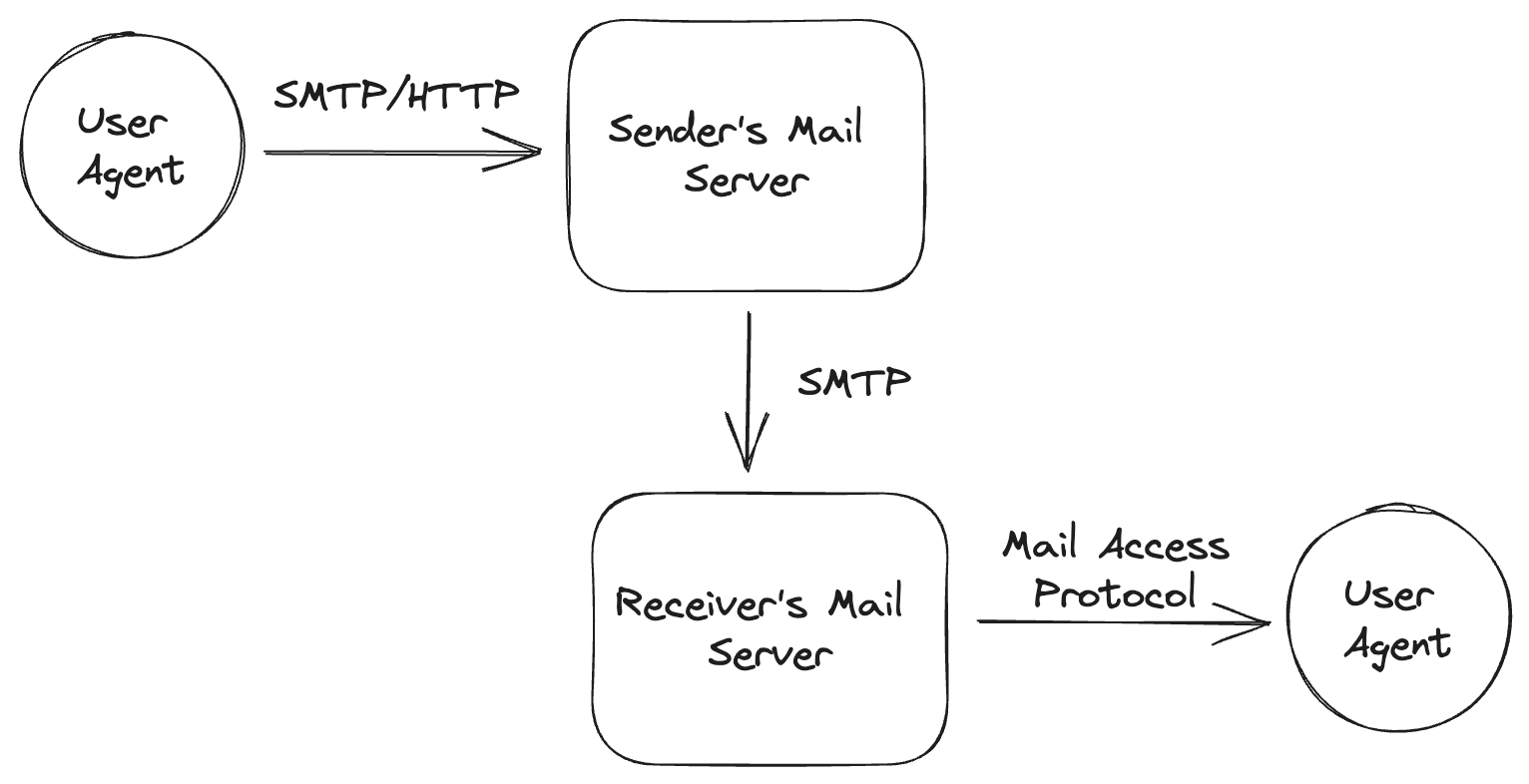
특징
- 클라이언트: 송신 메일 서버/UA
- 서버: 수신 서버 메일/송신 메일 서버
- TCP 프로토콜을 이용한다.
- ASCII 텍스트 프로토콜: 명령어와 메시지 모두 ASCII 그래픽 문자 + 제어 문자를 사용한다.
포트
- 포트 25는 SMTP 서버 사이를 연결하는 데 가장 많이 사용된다. 스팸 발송자가 이 포트를 악용해 스팸을 대량 전송하려고 하므로, 현재는 최종 사용자 네트워크의 방화벽에서 이 포트를 차단할 때가 많다.
- 한때 포트 465는 보안 소켓 계층(SSL) 암호화와 함께 SMTP에 사용하도록 지정되었다. 하지만 SSL은 Transport Layer Security(TLS)으로 대체되어, 최신 이메일 시스템에서는 이 포트를 사용하지 않는다. 레거시(이전) 시스템에서만 나타난다.
- 이제 포트 587이 이메일 제출용 기본 포트다. 이 포트를 통과하는 SMTP 통신은 TLS 암호화를 이용한다.
- 포트 2525는 SMTP와 공식적으로 연결되어 있지는 않지만, 일부 이메일 서비스에서는 앞서 언급한 포트가 차단되었을 경우 이 포트로 SMTP 전송이 제공된다.
전송 과정
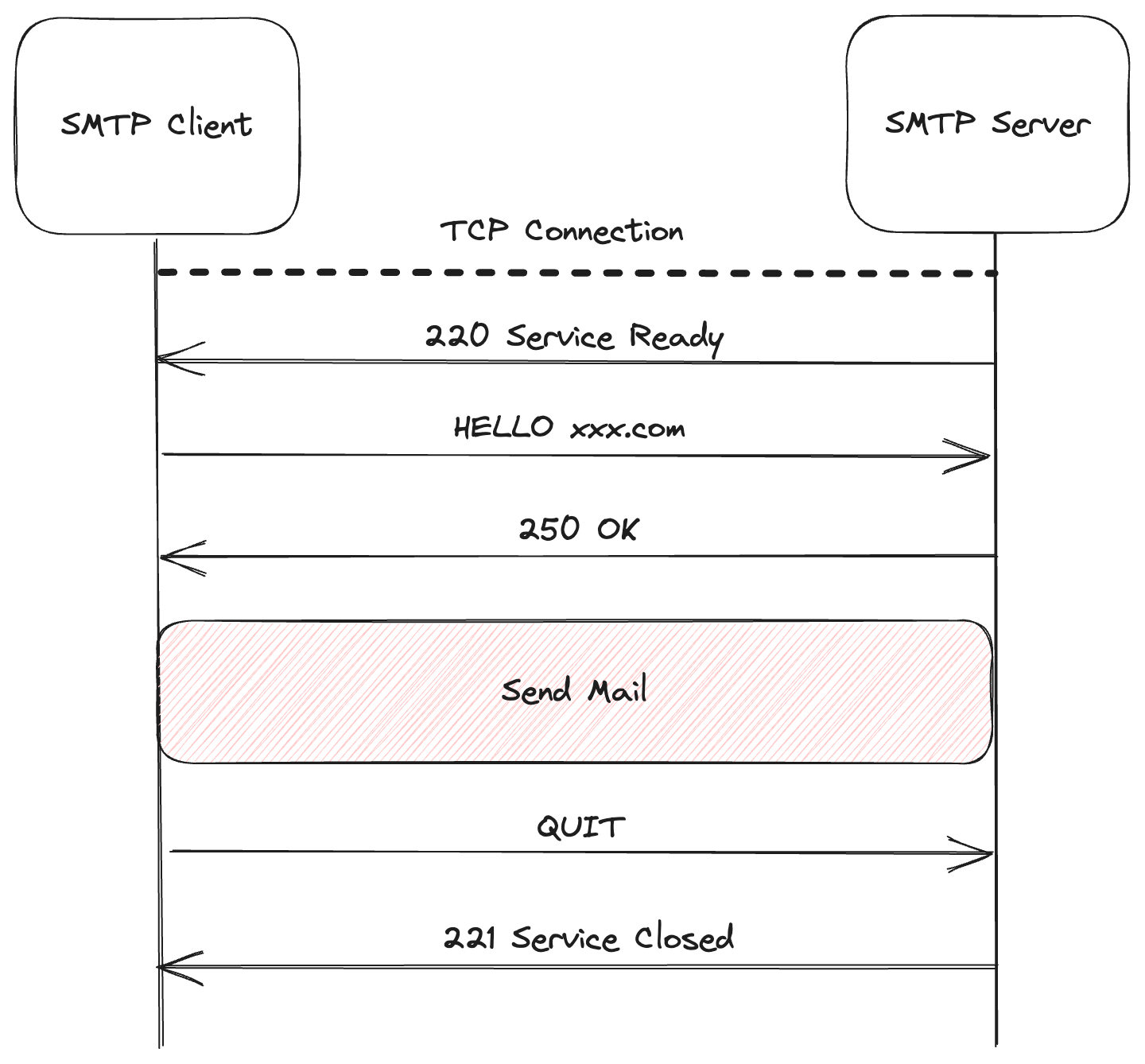
연결 수립
- TCP 연결 수립: 송신자(SMTP Client)와 수신자(SMTP Server) 사이의 메일 서버의 25번 포트에 대한 TCP 연결을 설정한다.
- 인사 (Greeting): 연결이 수립되면, 서버는 클라이언트에게 환영 메시지(
220 <서버 도메인 또는 IP 주소> ESMTP <서버 소프트웨어 정보>)를 보낸다. - 클라이언트 응답: 클라이언트는 서버의 환영 메시지에 응답하여 자신의 신원을 확인한다.
- 신원 확인 응답: 250 코드를 응답으로 서버는 클라이언트의 신원 확인을 성공적으로 받아들였음을 나타낸다.
연결 해제
- 전송 완료 및 종료: 메일이 성공적으로 전송되면, 클라이언트는 서버에게 전송이 완료되었음을 알리는 QUIT 명령어를 전송한다.
- 연결 해제: QUIT 명령어의 응답 메시지로 221 코드로 응답하고 클라이언트와 서버는 TCP 연결을 종료한다.
메일 전송
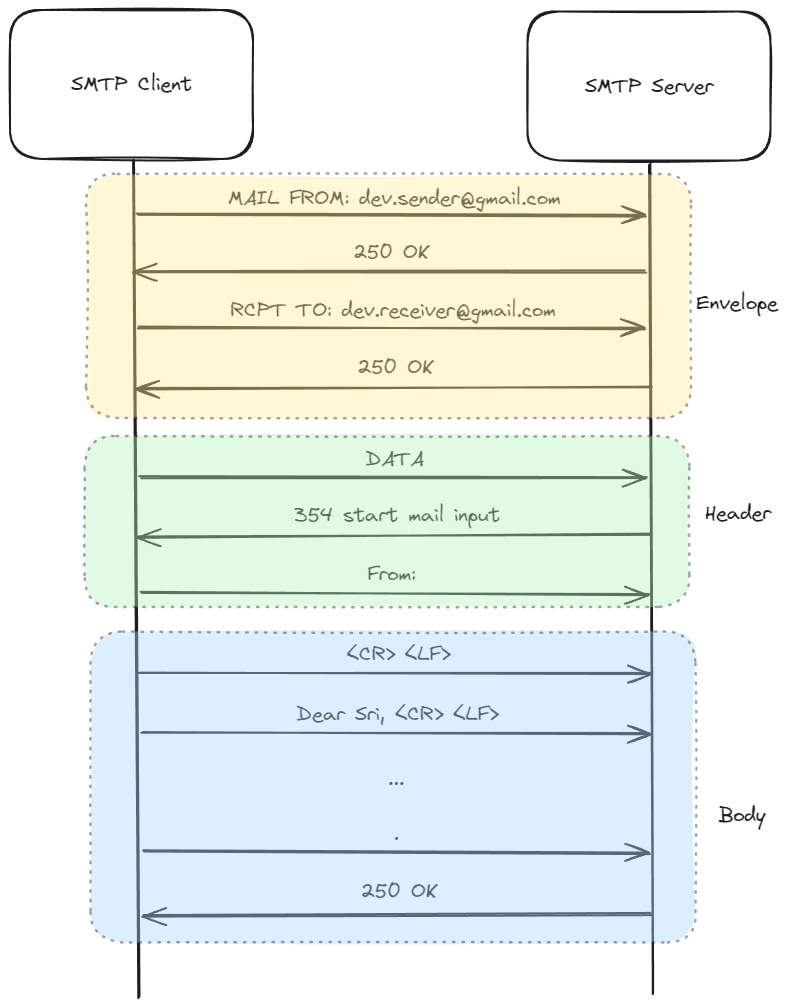
- MAIL FROM: 명령어: 송신자를 명시한다.
- RCPT TO: 명령어: 수신자를 명시한다.
- DATA 명령어: 메일의 본문과 헤더를 전송하기 위한 세션을 시작한다. 이후 클라이언트는 메일의 헤더와 본문을 서버로 전송합니다.
- 메일 전송 시작: 성공적인 경우, 서버는 354 코드를 반환하며, 클라이언트는 이후 메일의 헤더와 본문을 서버로 전송할 수 있다.
- 메일 본문 전송: 헤더 이후에는 메일의 본문을 전송합니다. 모든 라인은
<CR><LF>로 구분한다. - .(마침표) 입력: 메일의 헤더와 본문을 모두 전송한 후, .를 입력하여 전송을 완료한다.
메시지 포멧

MIME(Multipurpose Internet Mail Extensions)
메일 본문 전송에서는 ASCII만 지원된다. 하지만 실사용에서는 ASCII만의 활용은 한계(오디오, 비디오)가 존재한다. 따라서 MIME을 활용하여 ASCII Data가 아닌 것을 Base64 Encoder, Decoder를 활용하여 ASCII 문자로 변환하여 전송한다.
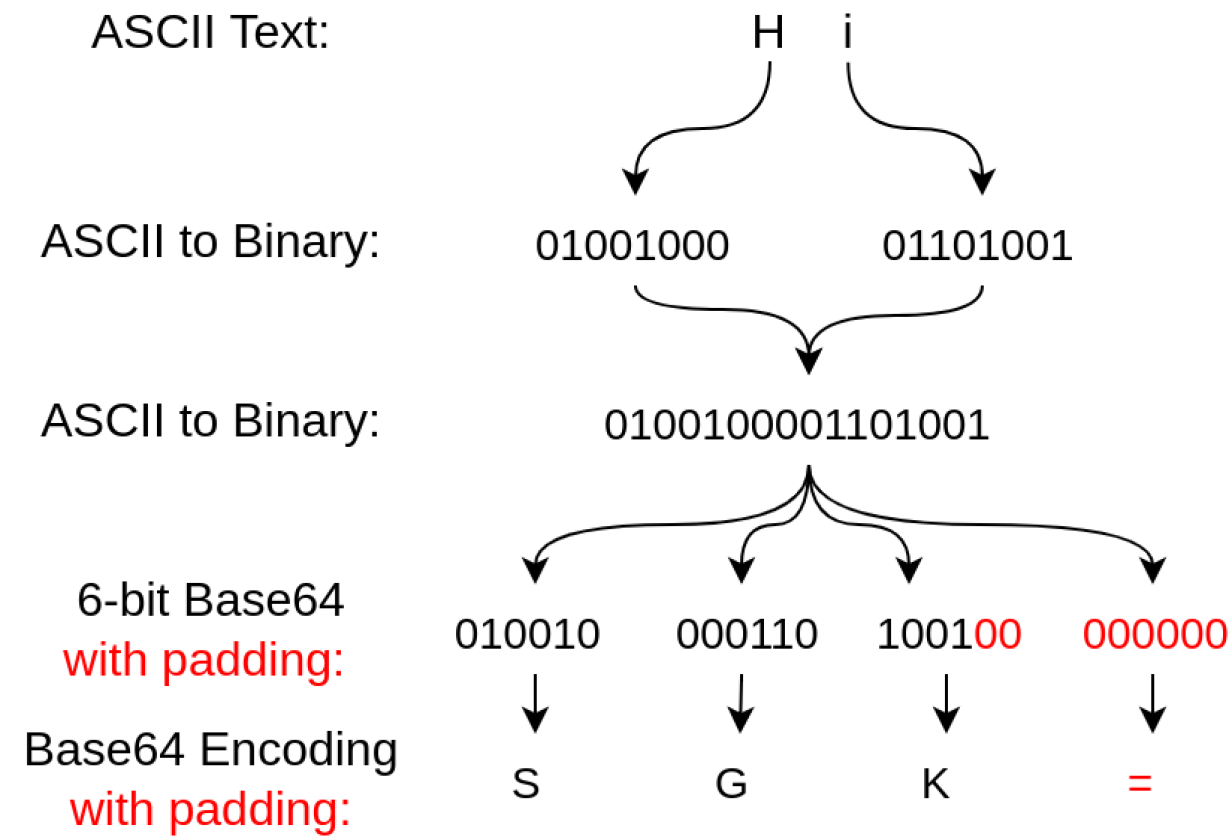
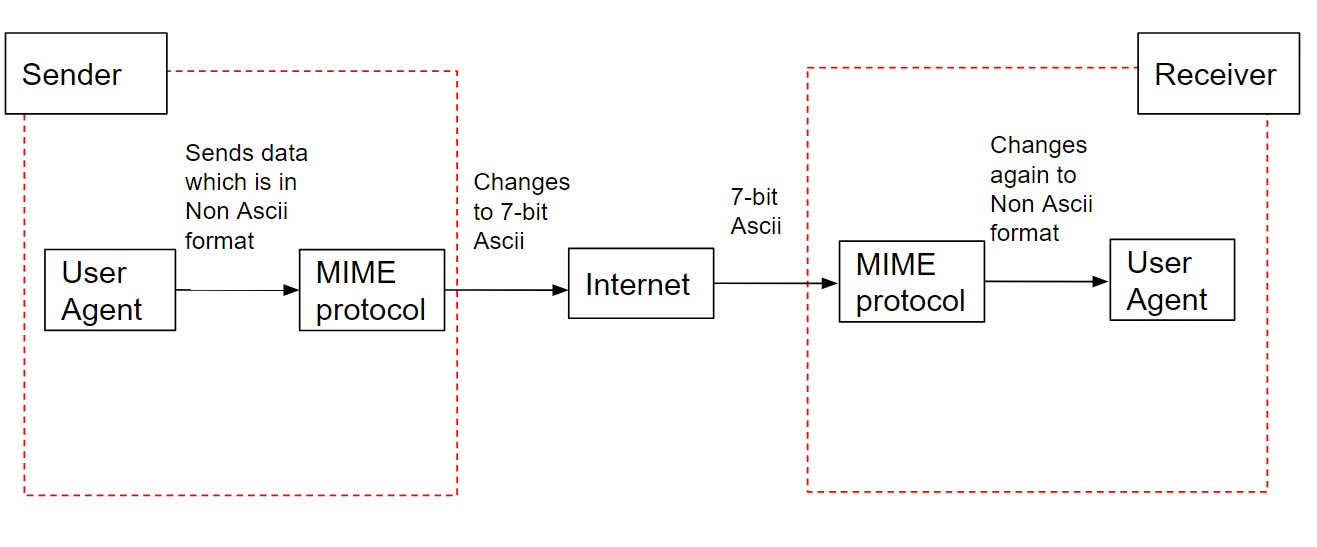
MIME은 전자 메일을 위한 확장 프로토콜로서, 다양한 종류의 데이터를 전자 메일로 전송하기 위한 표준을 정의한다.
MAP (Mail Access Protocol)
MAP (Mail Access Protocol)은 전자 메일을 서버에서 클라이언트로 전달하는 데 사용되는 프로토콜이다. 주로 이메일 클라이언트가 서버에 접근하여 전자 메일을 가져오는 데에 활용된다.
POP3
- Download&delete 또는 Download&keep: 메일을 한 번 다운로드하면 서버에서 삭제되거나 유지될지 선택할 수 있다.
- 메일 보관: 다운로드한 메일은 클라이언트의 로컬 디바이스에 저장되며, 서버에는 삭제되거나 유지될 수 있습니다.
- 메일함 동기화:
한 기기에서만 동작: POP3는 여러 기기에서 메일함 동기화를 제공하지 않습니다. - 기본적으로 보안 부족: 기본적인 POP3는 데이터를 암호화하지 않아 보안적인 취약성이 있다.
IMAP4
- 온라인 및 오프라인 모드 지원: 클라이언트는 온라인 및 오프라인에서 모두 메일에 액세스할 수 있습니다.
- 서버 보관: 메일은 서버에 유지되며, 클라이언트에서 읽은 상태도 서버에 반영됩니다.
- 여러 기기에서 동작: IMAP4는 여러 기기에서 메일함 동기화를 지원하여 어느 기기에서 메일을 읽거나 삭제하더라도 다른 기기에서도 동일한 상태를 유지할 수 있습니다.
- 암호화 지원: IMAPS(IMAP Secure)를 통해 SSL 또는 TLS를 사용하여 데이터를 암호화할 수 있습니다.
HTTP
메일 서버를 웹 서버로 구현하여 웹 브라우저에서 HTTP로 메일 서버에 접속하여 통신한다.
DNS (Domain Name System)
인터넷에서는 통신을 위해 숫자로 이루어진 IP주소를 이용한다. DNS(Domain Name System)는 숫자로 된 네트워크 IP 주소를 사람들이 알기 쉽게 문자와 숫자를 통해 식별할 수 있도록 변환해주는 시스템이다.
도메인명(Domain name)
인터넷 호스트에 부여되는 문자형의 유일한 이름이다. 계층적인 도메인 관리 구조에 의해 도메인명의 유일성이 유지된다.
장점
- 사용자 편리성: 사용자는 IP 주소를 매번 입력하기에 불편하다.
- 사용자 소속성: ISP가 IP주소를 빌려주어 사용하게 되는데, 서버의 IP주소는 언제든 바뀔 수 있기에 사용자의 소속성을 해칠 수 있다.
도메인 구조
유일한 도메인 이름을 관리하기 위해 계층적인 도메인 구조를 갖는다.
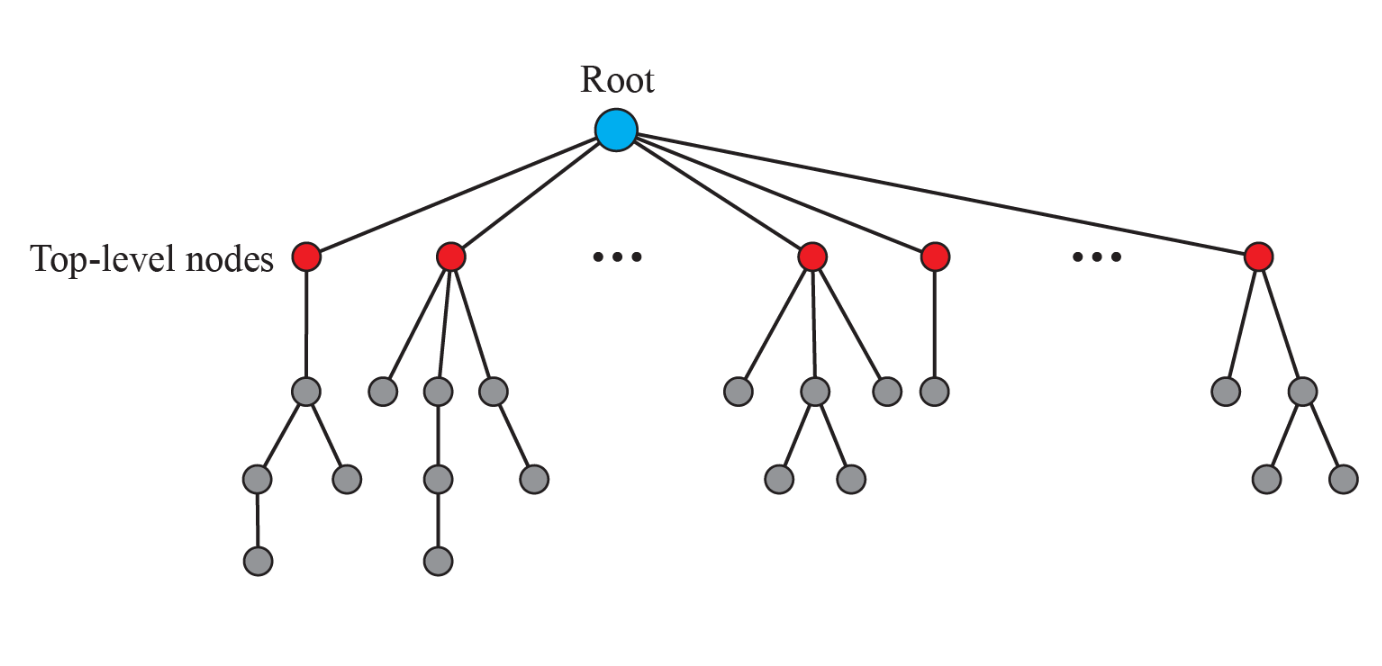
- 최상위 도메인: 7개 일반 도메인(.com, .org, .net, .int, .edu, .gov, .mil), 국가 도메인(.kr, .jp, .uk)
- 중간 도메인: .ac, .gov, .re, .or
- 책임 도메인: .uos.ac.kr
- 호스트 도메인: portal.uos.ac.kr
DNS 서비스 유형
- Hostname to IP Address(호스트명-IP 주소 변환 서비스): 사용자의 문자형의 호스트명(도메인명)을 TCP/IP가 사용하는 32비트 IP주소로 변환한다.
- Host aliasing(호스트 별칭 서비스): 사용자가 호스트 별칭을 복잡한 정규(실제) 호스트명(canonical hostname)으로 변환한다.
-
Mail server aliasing(메일 서버 별칭 서비스): 사용자의 메일서버 별칭을 복잡한 정규 호스트명으로 변환한다.
-
Load distribution(부하 분산 서비스): 동일 서버명(도메인명)으로 서로 다른 IP 주소의 다중 복제 서버를 배치할 수 있다. 동일 서버명에 대한 DNS 요청에 대해 다른 IP 주소를 돌아가며 응답하게 한다.
DNS 구조 유형
중앙집중형 구조
하나의 서버가 모든 DNS 질의를 처리하게 한다.
문제점
- Single point of failure: 중앙 서버 고장 시, 전체 네트워크가 고장날 수 있는 단일 장애 지점이다.
- Traffic volume: 중앙 서버에 부하 집중된다.
- Distant cetralized database: 원거리 중앙 서버의 응답 지연 시간 증가한다.
- Maintenance: 중앙 서버 유지 보수 어렵다.
분산 계층 구조 (Distributed & Hierarchical Architecture)
상위 서버는 하위(중간) 서버의 일부 정보만을 갖고 있다.
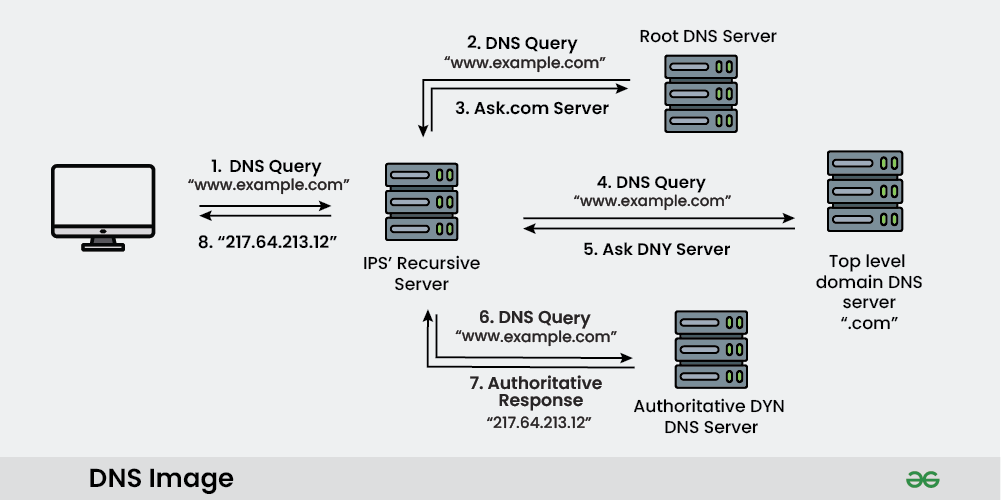
Root Server
TLD 서버들에 대한 IP 주소를 제공한다.전세계에 수백 개의 복제 서버가 존재한다. 13개의 관리 기관에 의해 관리된다.
사용자는 DNS에 query를 보내면 지역(Local, IPS Recursive) DNS 서버에 도착하고 이는 Root Server에게 전송되어 접속된다.
TLD(Top Level Domain) Server
최상위 도메인에 대한 DNS 서비스를 담당한다. 일반적으로 책임(Authoritative) DNS 서버에 대한 IP 주소를 제공한다.
.kr 도메인 관리는 KRNIC에서 관리한다.
Authoritative Server
특정 호스트의 도메인명 정보를 유지하고 있는 서버이다. 규모가 큰 기관은 대부분 자신의 호스트들에 대한 책임 DNS 서버를 유지한다. 소규모 기관은 외부의 책임 DNS 서버를 위탁한다.
Route 53이 대표적인 위탁 업체이다.
Local DNS Server
DNS 서비스를 요청하는 클라이언트 호스트가 소속된 DNS 서버이다. 소속된 호스트들의 DNS 서비스 요청을 대행한다.
반복적 질의(Iterative Queries)
해당 방법은 Local Server가 모든 DNS Server(Root Server, TLD Server, Authoritative Server)에게 query하는 방식으로 작동한다.
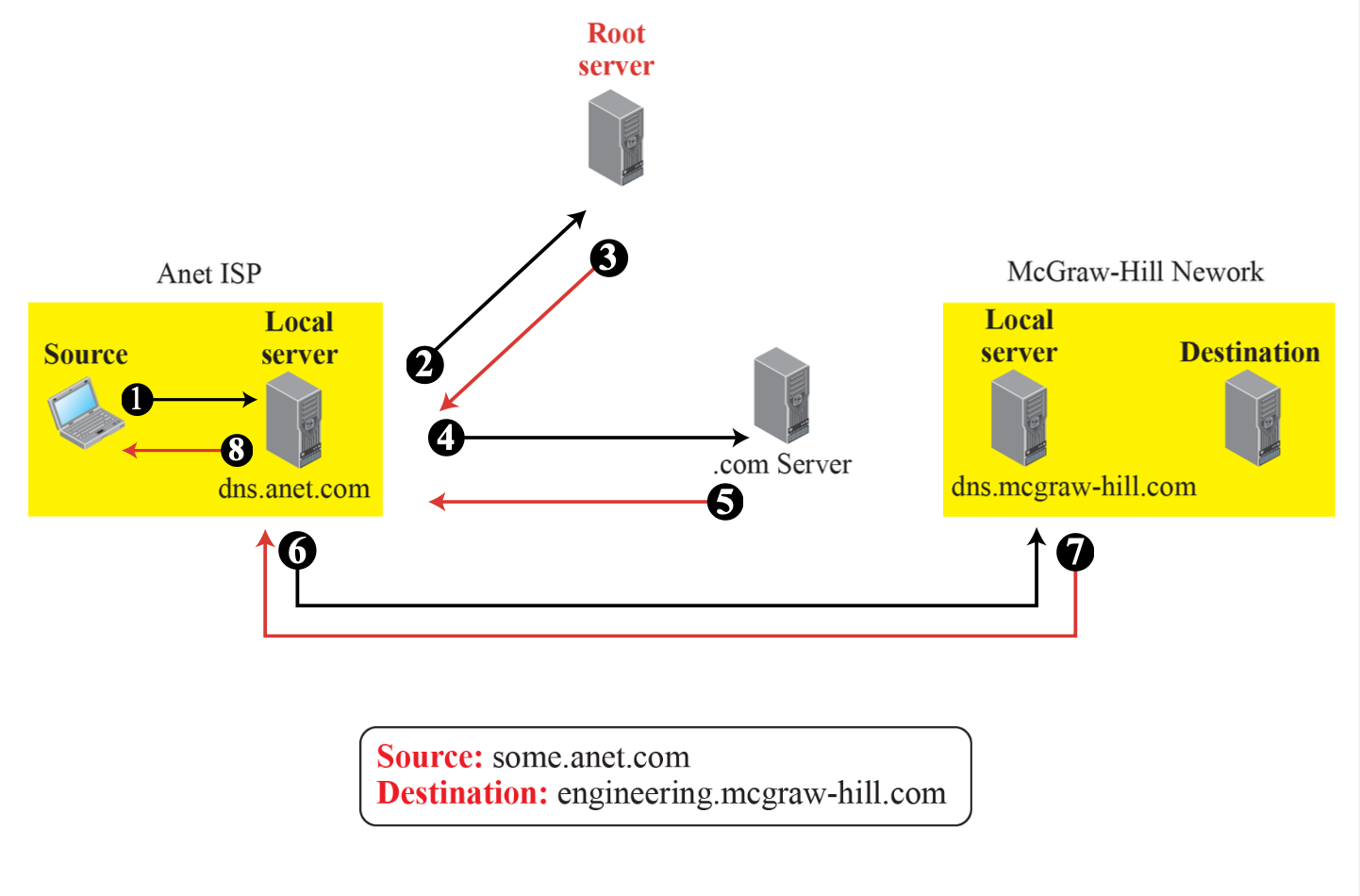
- Local DNS server로 DNS 요청 query를 전송한다.
- Local DNS server는 Root DNS server로 query를 전송한다.
- 호스트가 포함된 TLD domain server에 대한 정보(.com)를 알려준다.
- TLD domain DNS server에 authoritative server에 대한 정보를 묻는 query를 전송한다.
- 도메인명을 관리하는 authoritative server의 정보를 제공한다.
- Authoritative server로 해당 도메인에 대한 IP주소를 query한다.
- 해당 도메인에 대한 IP주소에 대한 답변을 받는다.
일반적으로 일반 사용자의 DNS 쿼리는 recursive 방식을 사용한다. 사용자가 웹 브라우저나 다른 네트워크 응용 프로그램을 통해 도메인 이름을 입력하면, 사용자의 로컬 DNS 서버는 해당 쿼리를 받고 이를 처리하기 위해 recursive 방식을 사용하게 된다.
재귀적 질의(Recursive Queries)
해당 방법은 Local Server가 하위 Server에게 query하여 찾아서 알려주는 방식으로 작동한다.
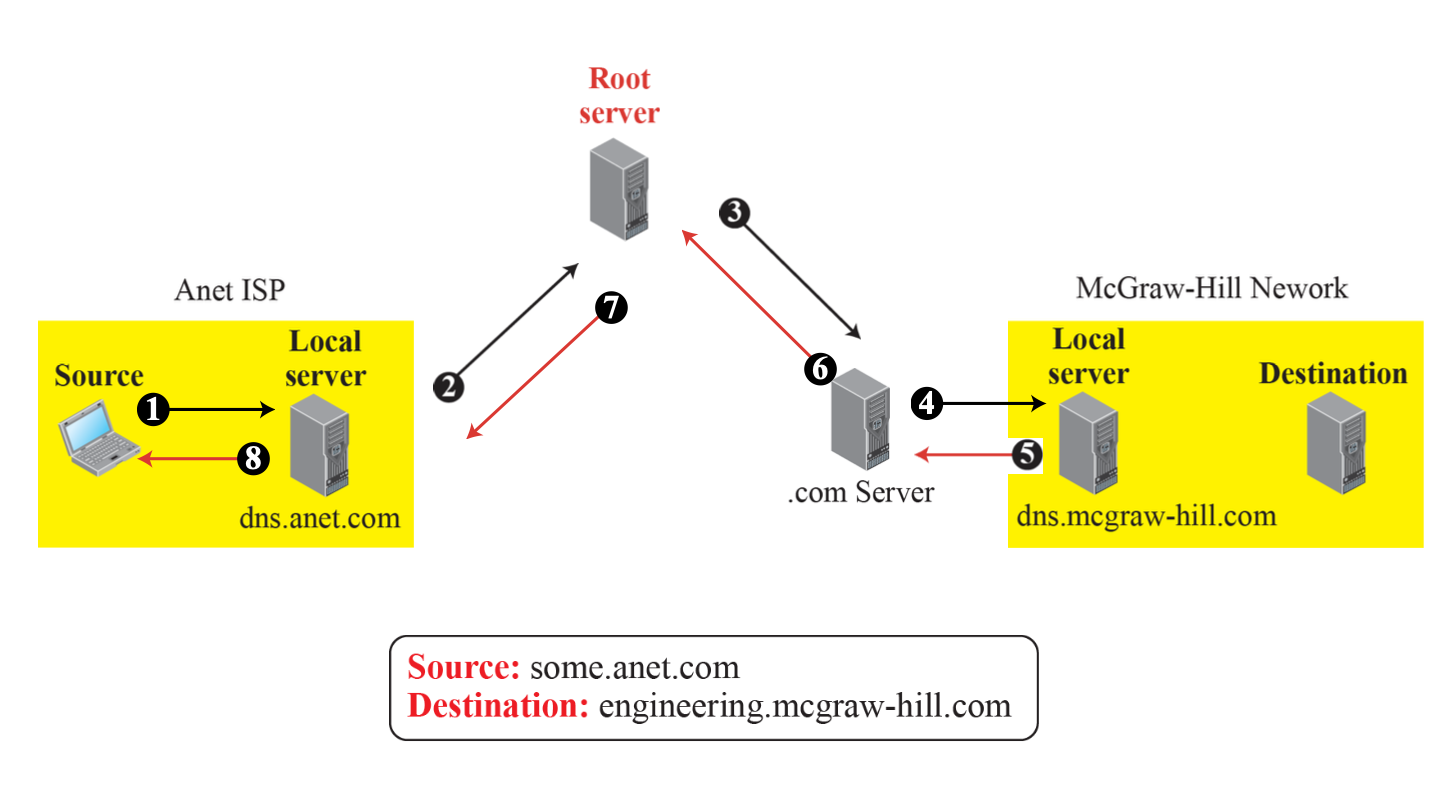
- Local DNS server로 DNS 요청 query를 전송한다.
- Local DNS server는 Root DNS server로 IP 주소 query를 전송한다.
- Root DNS server는 TLD domain server에게 IP 주소 query를 전송한다.
- TLD domain DNS server는 authoritative server에게 IP 주소 query를 전송한다.
- Authoritative server가 해당하는 도메인명의 IP 주소를 제공한다.
- TLD domain DNS server가 해당하는 도메인명의 IP 주소를 제공한다.
- Root DNS server가 해당하는 도메인명의 IP 주소를 제공한다.
DNS 서버가 다른 DNS 서버에 쿼리를 보낼 때 iterative 방식을 사용한다. 일반적으로 캐시된 정보가 없는 경우에는 iterative 방식으로 동작하게 된다.
DNS 캐싱 (DNS Caching)
특정 서버가 다른 서버에게 질의를 하고 응답을 받으면 이 정보를 클라이언트 방향으로 전달하기 전에 자신의 캐시 메모리에 저장한다.
해당 서버가 동일한 도메인명에 대한 해석을 요청하는 질의를 수신하면 다른 서버에게 질의 메시지를 전달하는 대신 캐시 메모리 정보를 응답한다.
문제점
특정 도메인명에 관한 정보가 해당 서버에 캐싱된 이후에 책임 서버에서 갱신되었다면 캐시 메모리는 잘못된 정보를 유지하게 된다.
따라서 이러한 캐싱 정보는 일정 시간(TTL)이 지나면 자동적으로 삭제하게 한다.
자원 레코드 (Resource Record)
DNS 서버에 정보가 저장되고 서비스되는 단위이다.
형식
(name TTL class type value)
- name: 리소스 레코드와 연관된 도메인 이름이나 호스트 이름이다.
- TTL: 리소스 레코드의 캐시 지속 시간을 나타낸다.
- class: 주로 "IN" (Internet)이 사용된다. 다른 클래스도 존재하지만, 대부분의 경우 "IN"이 사용된다.
- type: 리소스 레코드의 유형을 나타낸다. 몇 가지 일반적인 유형에는 A (IPv4 주소), AAAA (IPv6 주소), CNAME (별칭), MX (메일 교환), NS (네임 서버), 등이 있다.
- value: 리소스 레코드에 대한 실제 데이터 값이다.
type(유형)
- A: 도메인의 IPv4 주소를 지정한다. 예를 들어,
www.uos.ac.kr의 IPv4 주소를 나타낼 때 사용된다.
name=호스트명, value=IPv4 주소
- NS: 도메인의 네임 서버를 지정한다. 이 레코드는 도메인에 대한 authoritative 네임 서버의 정보를 제공한다.
name=도메인, value=Authoritative DNS server의 호스트명
- CNAME: 도메인의 별칭(Alias)을 정의한다. 이는 한 도메인이 다른 도메인을 가리키는 경우 사용된다.
name=별칭 호스트명, value=정규 호스트명
- MX: 메일 서버의 정보를 지정한다. MX 레코드에는 우선순위 값이 있어, 여러 메일 서버가 있을 경우 우선순위에 따라 메일을 전송한다.
name=호스트명, value=IP주소
- AAAA: A 레코드와 유사하지만, IPv6 주소를 나타낸다.
name=호스트명, value=IPv6 주소
- SOA(Start of Authority): 도메인의 소유자 및 기본 구성 정보를 나타낸다. 하나의 도메인에 대해 하나의 SOA 레코드만 존재해야 한다.
name, TTL, class, SOA, 주요 서버, 이메일, 시리얼, 갱신 간격 , 재시도 간격, 만료 간격, 최소 TTL
- 주요 서버: 이 도메인에 대한 주요 네임 서버의 FQDN (Fully Qualified Domain Name).
- 이메일: 도메인 관리자의 이메일 주소.
- 시리얼: SOA 레코드의 변경을 추적하기 위한 일련번호. 각 변경 시마다 증가시켜야 합니다.
- 갱신 간격: 이 SOA 레코드를 얼마나 자주 새로 고칠지를 나타냅니다.
- 재시도 간격: 실패한 새로 고침을 얼마나 자주 다시 시도할지를 나타냅니다.
- 만료 간격: 다른 네임 서버에게 이 도메인에 대한 정보를 얼마 동안 사용할 수 있는지 나타냅니다.
- 최소 TTL: 다른 서버에게 이 도메인에 대한 정보를 얼마 동안 캐시에 저장할지 나타냅니다.
DNS Message
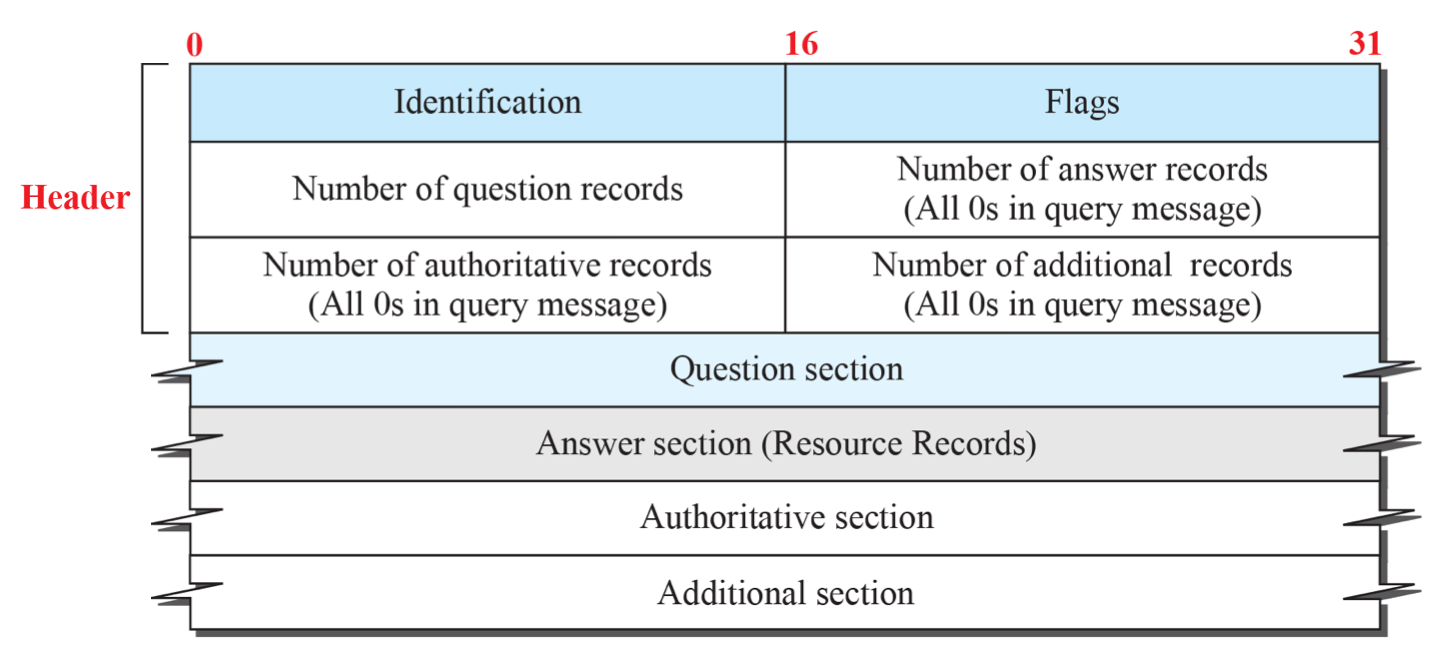
- Identifier: 각각의 DNS 메시지를 식별하는 고유한 식별자.
- Flags: DNS 메시지의 특성을 나타내는 플래그들로 구성된다.
등록 (Registrars)
등록자(도메인 관리자)
도메인명(uos.ac.kr)과 Authoritative Server(1차, 2차)의 IP 주소를 등록 기관에 제출한다.
웹 서버명과 IP 주소의 A 유형 RR을 Authoritative Server에 저장한다.
도메인명 등록기관 (Registrars)
등록 대상 도메인명의 유일성을 검증한다.
도메인을 담당하는 책임 DNS 서버에 대한 NS 유형 RR과 A 유형 RR을 상위 DNS 서버(ex. TLD)에 등록한다.
Session Layer 계층
SSH(Secure SHell)
SSH는 Secure Shell의 약자로, 네트워크 상의 다른 컴퓨터에 안전하게 접속하기 위해 사용되는 암호화된 네트워크 프로토콜이다. 주로 원격 로그인과 원격 명령어 실행을 위해 사용되며, 안전한 데이터 전송을 보장한다. SSH는 암호화된 연결을 통해 데이터와 명령어를 보호하며, 불법적인 도청 및 위변조로부터 네트워크 통신을 보호한다.
Transport Layer 계층
Transport Layer
Network Layer는 Host에서 Host의 데이터 전송 서비스를 제공한다. 반면에 Transport Layer는 Network Layer의 서비스를 이용해서 Host 내의 프로세스와 프로세스 간의 데이터 전송 서비스를 담당한다.
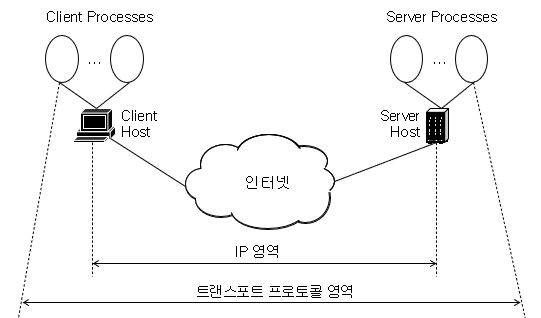
Transport Layer의 서비스
-
Segmentation: 응용 프로세스가 전송할 때 메시지를 네트워크 계층이 교환 가능한 크기로 나누는 것
-
Reassembly: 여러 개의 Segment를 모아서 원래의 메시지로 합치는 것
-
Multiplexing: 여러 프로세스의 정보(포트 번호)를 모아서 하나로 처리하는 것
-
Demultiplexing: 도착한 정보를 여러 해당 프로세스로 나누는 것
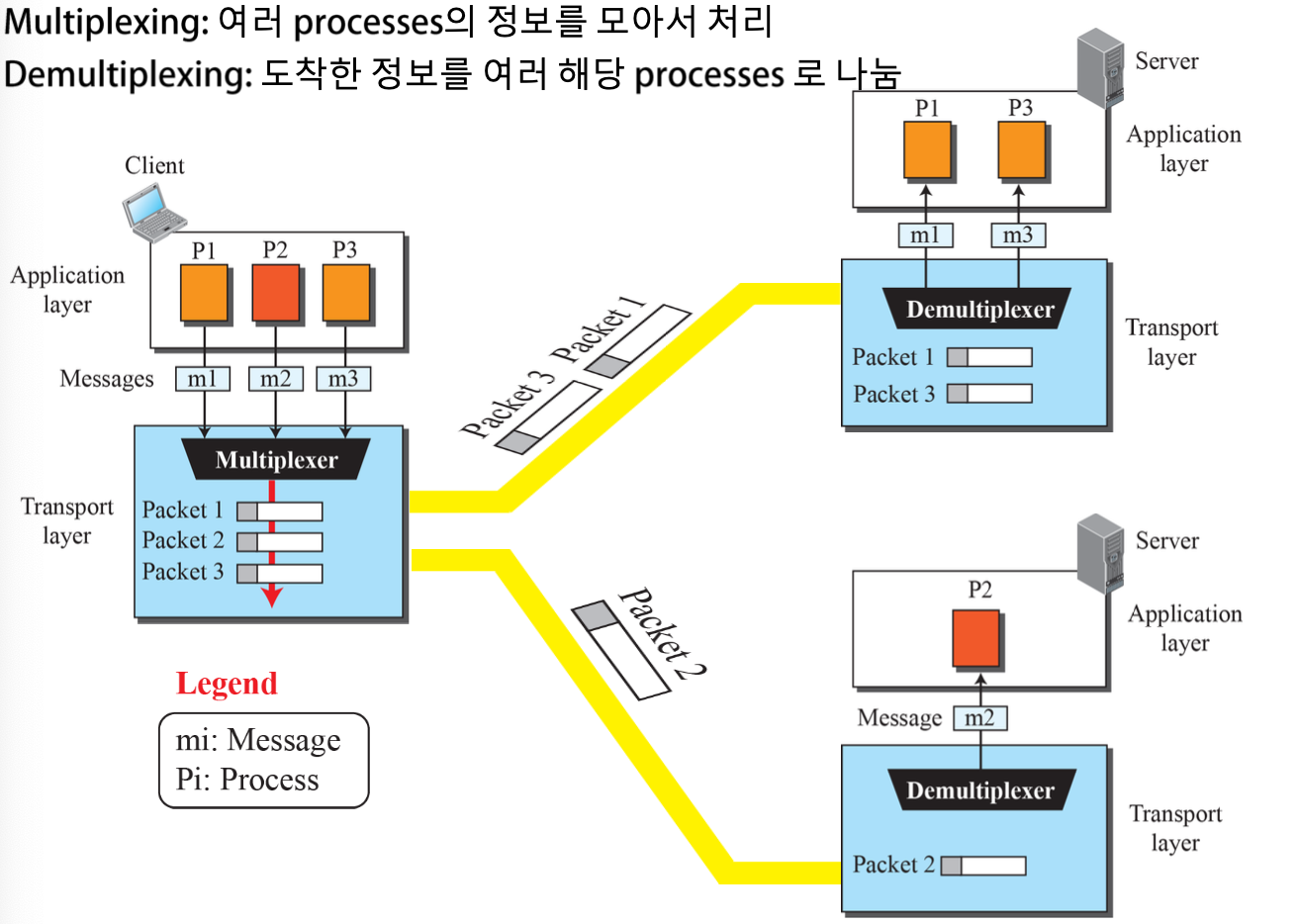
Multiplexing&Demultiplexing으로 하나의 IP(호스트) 내의 여러 프로세스를 포트 번호를 통해 식별한다.
윈도우 OS는
C:\Windows\System32\drivers\etc\services경로에 Well Known 포트를 저장하고 있다
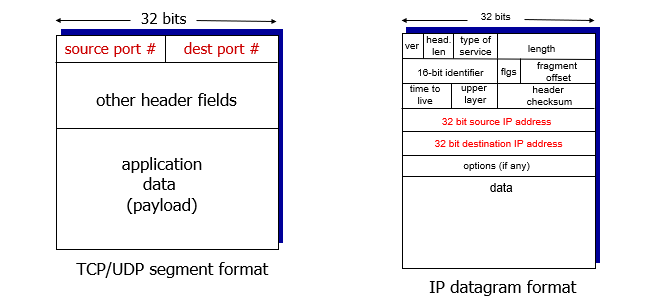
Transport layer의 Header가 IP 패킷의 data 영역의 들어가게 되고, Header에 포트 번호가 적힌다.
- 무결성 확인: Checksum으로 수신 세그먼트의 비트의 손상 여부를 확인한다.
- 신뢰 전송: Error Control과 Flow Control러 신뢰성 있는 통신을 보장한다.
- 혼잡 제어: 네트워크 혼잡도에 따라 전송량을 조절하여 회피 및 해소한다.
프로토콜 별 제공 서비스
| 서비스 | TCP | UDP |
|---|---|---|
| Segmentation&Reassembly | O | O |
| Multiplexing&Demultiplexing | O | O |
| 무결성 확인 | O | O |
| 신뢰 전송 | O | X |
| 혼잡 제어 | O | X |
Socket(소켓)
Transport layer이 제공하는 응용 프로세스 통신 통로의 자료구조이다.
소켓은 Source, Destination IP와 포트 번호의 쌍에 번호를 부여한 것이다.

Connection
Transport layer에서 제공되는 Connection의 종류에는 Connectionless와 Connection-oriented가 존재한다.
- Connectionless: 통신 소켓간에 1:1로 논리적 연결을 설정한다. ex) Datagram Switching, UDP
- Connection-Oriented: 통신 소켓간에 논리적 연결을 설정하지 않는다. Virtual-Circuit Switching, TCP
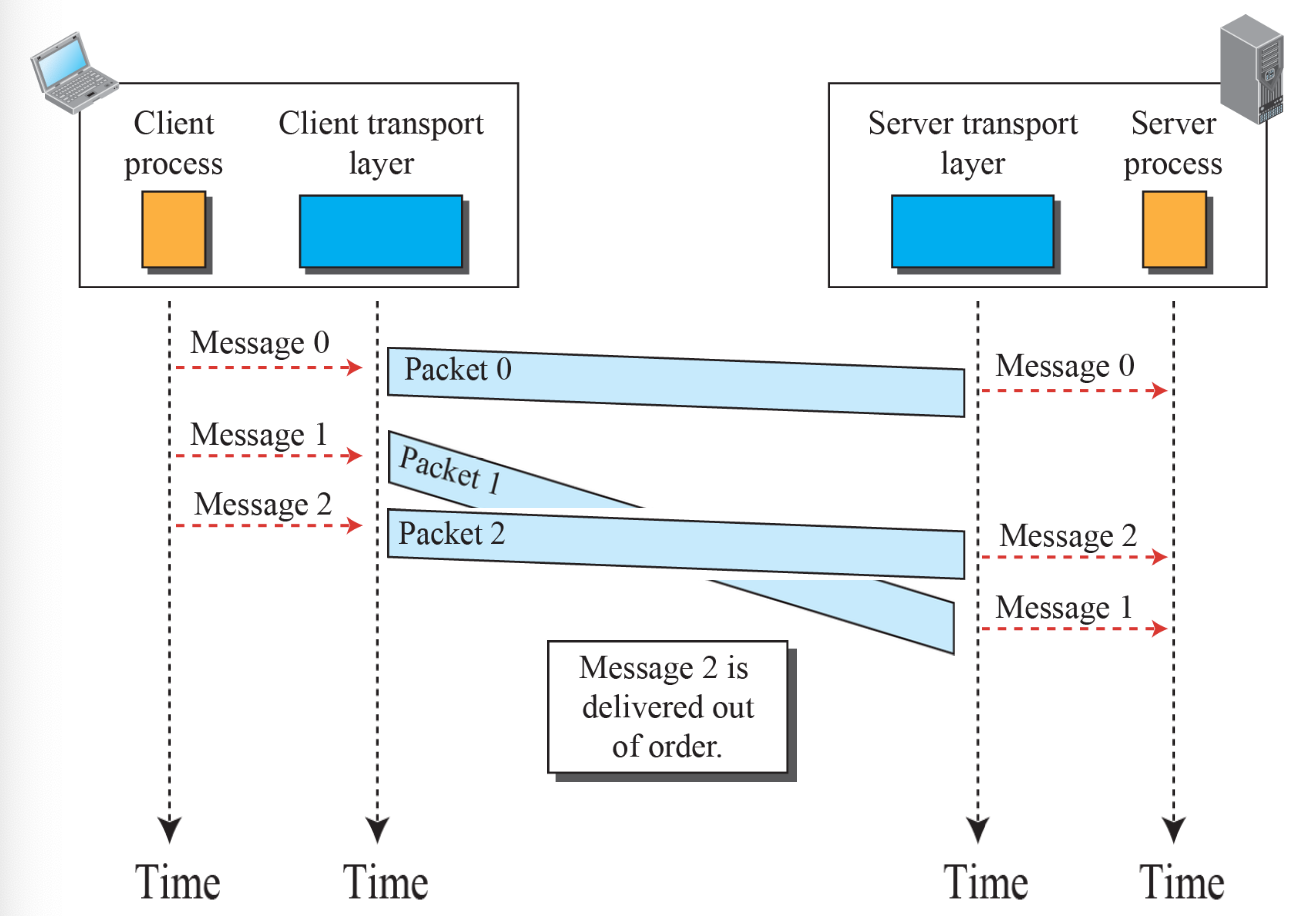
Connectionless
- 패킷이 독립적으로 전송된다.
- 순서가 보장되지 않는다.
- 데이터 청크가 사라질 수도 있다.
- 1:N으로 통신이 가능한다.
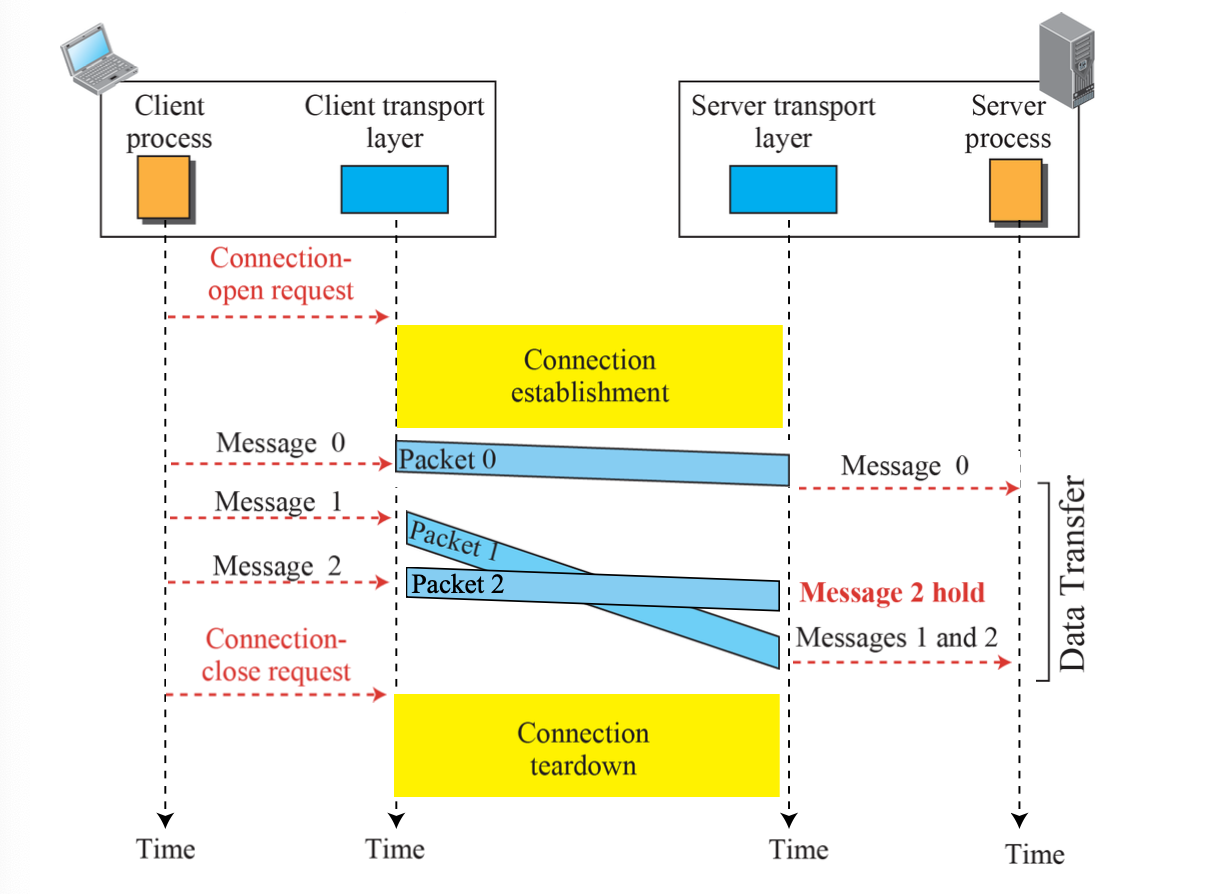
Connection-Oriented Service
- 연결을 위한 Setup phase 존재한다.
- 해제를 위한 Release 존재한다.
- 라우터들은 논리적 연결에 관여하지 않는다.
- 1:1로 통신이 가능한다.
- Flow, Error, Congestion Control
UDP (User Datagram Protocol)
Services
- Process-To-Process 통신
- Connectionless(비연결형) 전송 서비스: 통신 소켓 간의 연결 설정이 없으므로, 연결 설정을 위한 지연시간(Handshaking)을 회피한다.
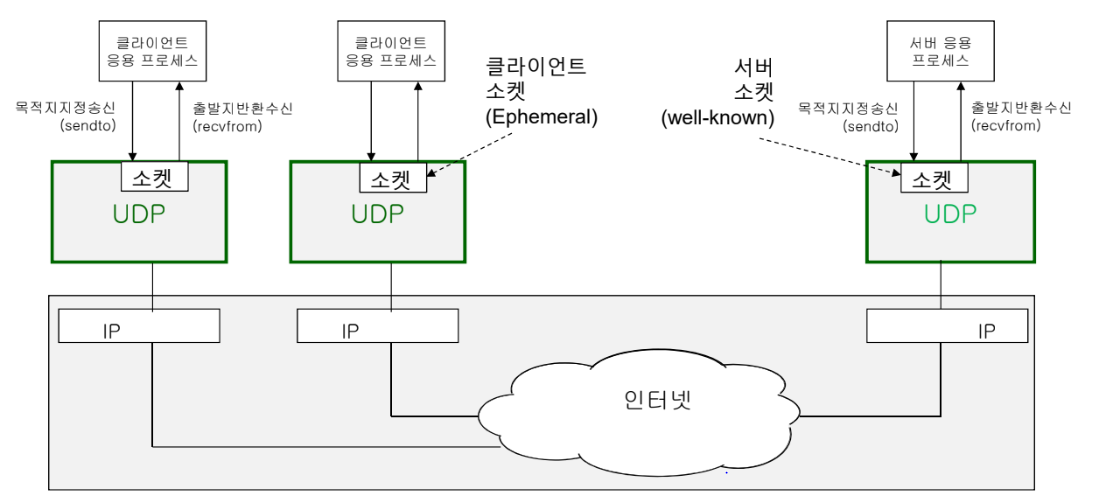
- 응용 프로세스로부터 데이터가 송신 소켓에 전달되면, 송신 UDP는 해당 데이터를 포함하는 UDP 데이터그램을 생성하여 IP를 통해 독립적으로 목적지 UDP 소켓에 전송한다.
- 목적지 IP 주소에 멀티캐스트 주소를 사용하여 다수의 목적지 소켓으로 데이터그램 전송이 가능하다. 또한 여러 개의 소켓으로부터 데이터그램 수신이 가능하다.
- No Flow control, No Error control: Checksum을 통해 확인 후에 에러 발생 시, 바로 discard한다.
- Checksum: pseudoheader + UDP header + Data
- No congestion control : 인터넷 초기에는 UDP 트래픽은 소량의 단순한 트래픽이었으나, 현재는 multimedia traffic이 UDP로 전송되고 있다.
Pseudoheader는 UDP checksum의 계산에 사용되는 보조 정보다. 이는 IP 헤더의 일부분과 함께 사용되는데, UDP 헤더와 데이터를 함께 검사하기 위해 IP 헤더의 일부(출발지 IP 주소, 목적지 IP 주소, 0으로 채워진 패딩 바이트, 상위 계층 프로토콜 필드, UDP 길이)와 UDP 헤더, 그리고 실제 데이터를 포함하여 checksum을 계산한다.
Datagram Format
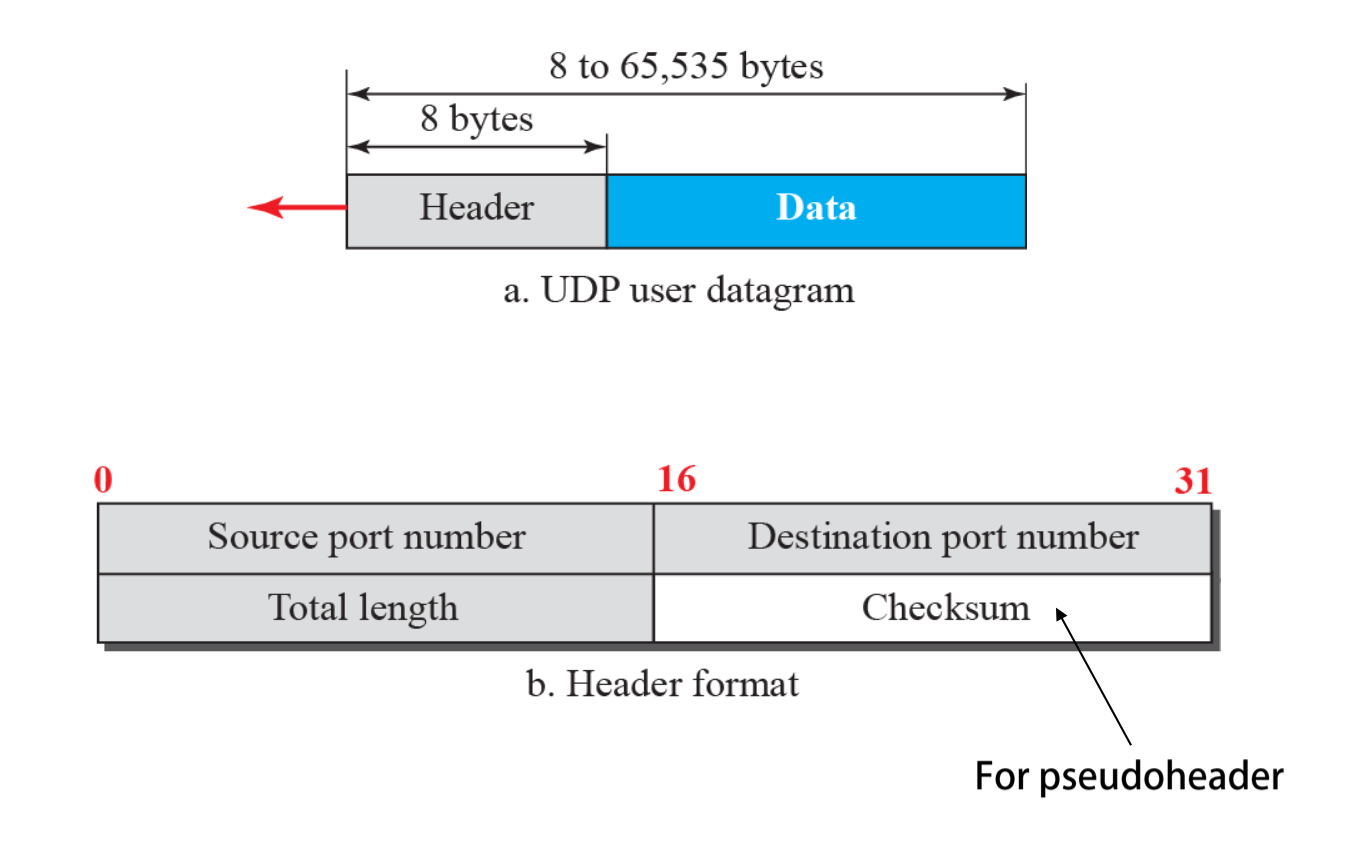
- Data: 응용 계층에서 내려온 데이터
- Header: UDP 헤더
- Source port number
- Destination port number
- Total length: 전체 길이
- Checksum: UDP 헤더 에러에 대한 checksum
Checksum Calculation
수신자가 Datagram을 받았을 때, 훼손 여부(무결성)를 판단할 수 있다.
송신자
- 송신하는 메시지를 정해지 길이의 데이터 단위(UDP=16bit)로 나눈다.
- 모든 데이터 단위를 1의 보수 연산으로 더하여 합을 구한다.
- 합의 1의 보수를 Checksum으로 생성하고, Checksum을 UDP Header에 추가한다.
수신자
- 수신된 메시지를 정해진 길이의 데이터 단위로 나눈다.
- 모든 데이터 단위를 1의 보수 연산으로 더하여 합을 구한다.
- 합이 0이면 성공적인 수신, 그렇지 않으면 오류 발생으로 간주한다.
1의 보수 연산
- 이진수 1의 보수: 각 비트 값 0과 1을 서로 바꾼 값을 의미한다. (0 -> 1, 1 -> 0)
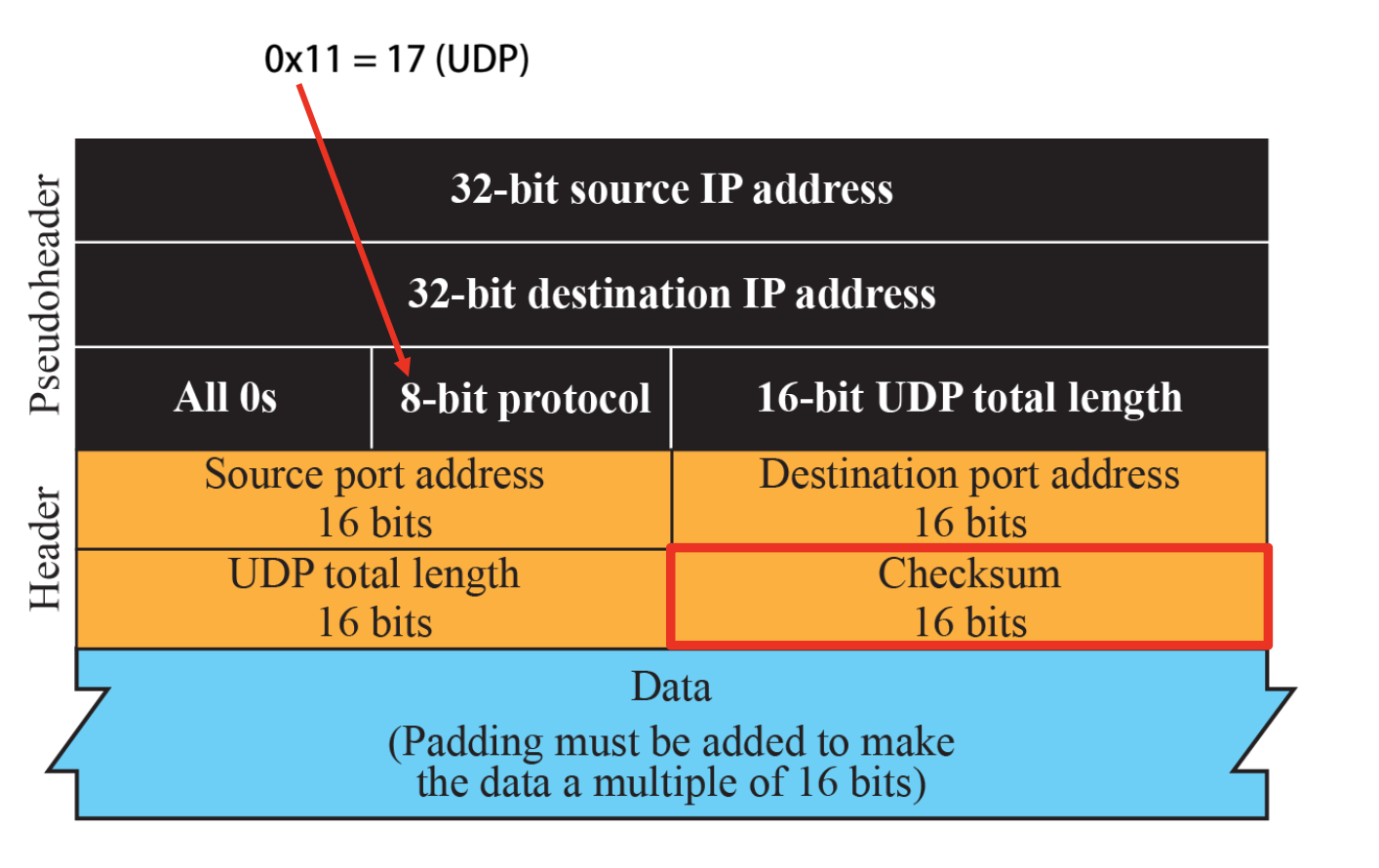
Checksum을 제외한 값을 전부 더해서 뺀 값을 Checksum에 저장한다. 수신 쪽에서 Checksum을 포함해서 0이 나와야 한다.
장단점
장점
- 높은 오류 검출 능력
- 단순함
- SW 구현에 적합
단점
- 각 데이터 단위에서 발생하는 오류의 합이 0이 되는 오류 검출 불가
- Checksum을 변경하지 않는 오류 검출 불가
응용
- 데이터그램 실시간 전송 서비스: 짧은 요청과 응답에 적합하다.(UDP: 2패킷, TCP: 9패킷)
- 인터넷 전화, DNS
- 1:N, N:1 데이터그램 통신 서비스
- 인터넷 TV 등 머티캐스트 응용
- 멀티미디어 통신에 적합
- UDP: bandwidth determined by the application
- TCP: inconstant bandwidth, useless retransmission
- SNMP(Simple Network Management Protocol)
- RIP(Route updating protocol)에 쓰임
- Interactive real-time applications에 적합
멀티미디어 데이터는 BPS가 어느 정도 유지되어야 한다. TCP는 전송 속도를 흐름 제어 때문에 마음대로 조절하기 때문에 적절하지 않다.
Stop-and-Wait Protocol
Segment Error 개념
- 훼손: 훼손된 세그먼트 도착(Checksum으로 확인)
- 손실: 세그먼트 미도착(중간 통신장치의 버퍼 오버플로우)
Segment를 정상적으로 수신한다면, 수신자는 ACK Segment를 회신한다. 훼손일 경우 수신자는 Segment를 폐기하고, 손실일 경우 수신자는 손실여부를 인지할 수 없다.
손실 Segment 인지/복구
- 손실을 보완하기 위해 송신자는 Segment 전송 후에 타이머(timer)를 시작한다.
- 타이머 종료 시(RTT를 고려한 값)까지 수신자로부터 ACK가 도착하지 않으면, 손실이 발생한 것으로 판단한다.
- Segment를 재전송하고 타이머를 재시작한다.
Stop-and-Wait ARQ (Automatic Repeat Request)
송신자는 ACK Segment를 받을 때까지 Segment를 반복해서 전송한다.
과정
- Segment 송신 후 복제본을 버퍼에 유지
- 재전송 타이머를 시작
- 타이머 종료 전 ACK 수신 시 복제본 폐기, 타이머 종료
- 타이머 종료 전 ACK 미수신 시 Segment 재전송, 타이머 재전송
문제점
- ACK Segment 자체에 오류 발생
- 송신자는 Segment를 재전송
- 수신자 송신자로부터 Segment 2개 수신
- 오류에 의한 재전송인지, 2개의 정상 Segment인지 구분 불가
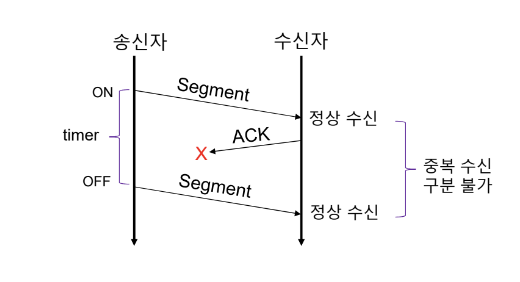
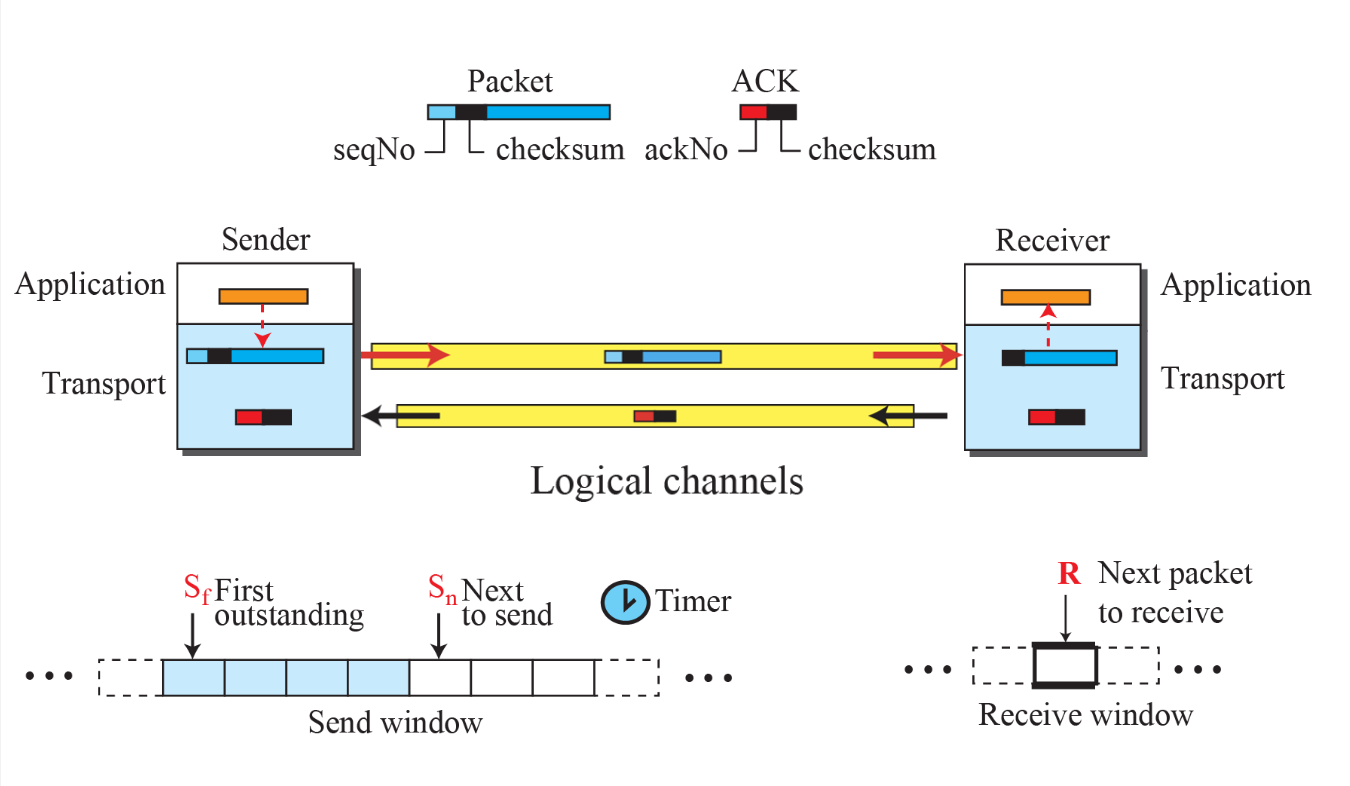
이를 해결하기 위해 SN(Sequnce Number)를 도입하였다.
Stop-and-Wait ARQ with SN
헤더에 SN(Sequence Number) 필드를 통해 각 Segment를 구분한다.
- 송신 SN: 현재 송신 Segment 번호
- ACK SN: 다음 송신 Segment 번호 (송신 SN + 1)
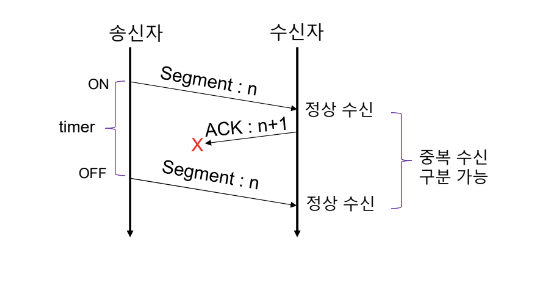
SN(Sequence Number)
TCP의 SN(Sequence Number) 필드는 32 bit이다. SN(Sequence Number)는 통신 과정에서 많이 필요할 수도 있는데, 몇 bit가 적합할까?
Alternative Protocol
SN(Sequence Number)를 1 bit만을 사용하는 프로토콜을 의미한다.
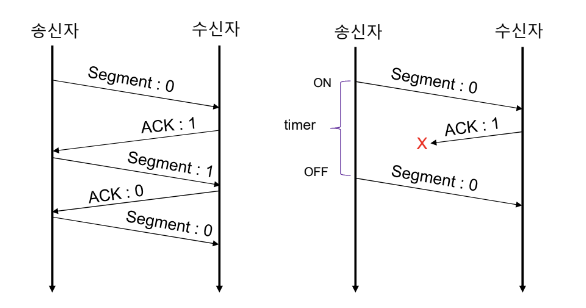
0과 1만으로도 손실을 파악할 수 있다. Flow, Error Control 모두 가능하다.
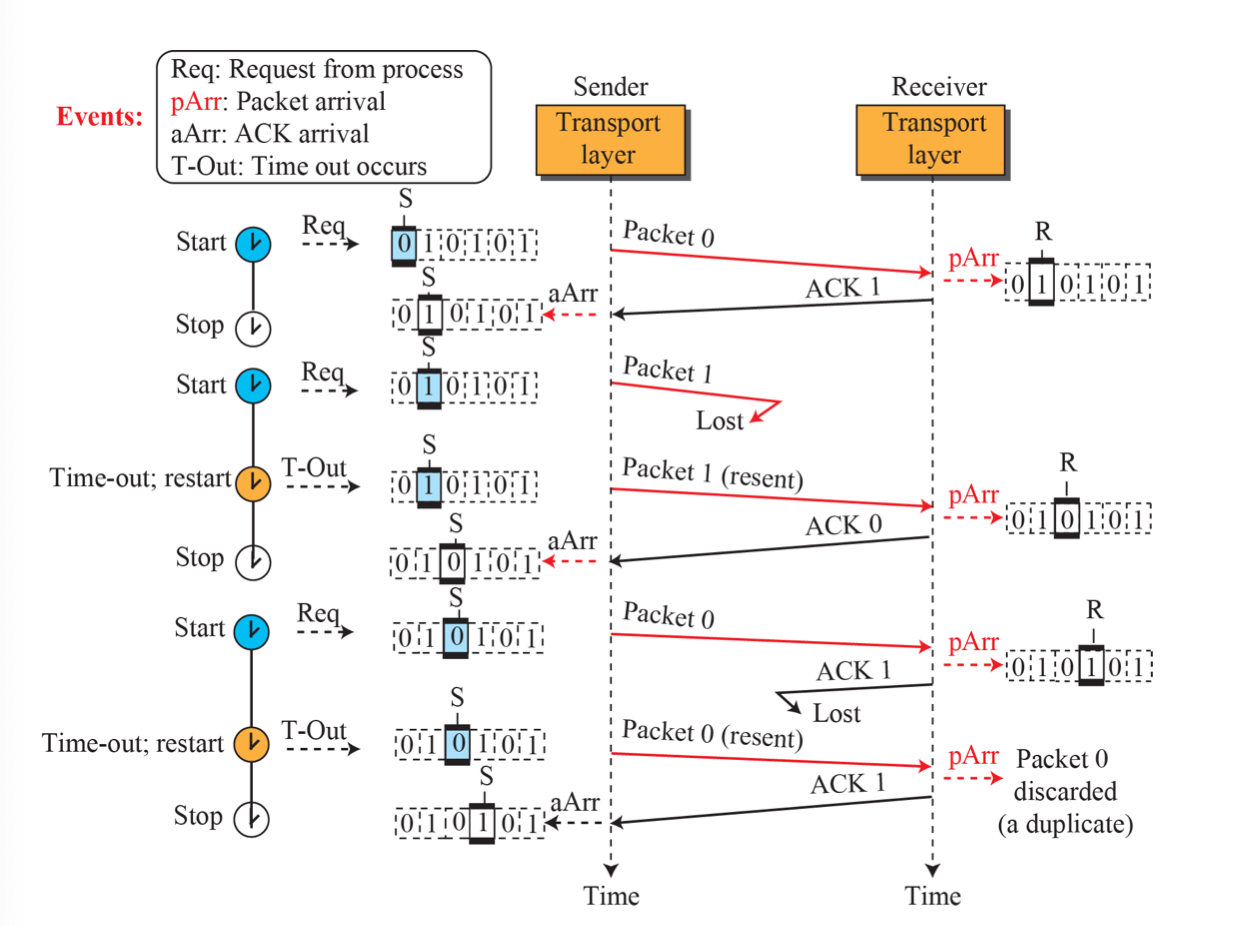
문제점
낮은 링크 사용 효율성이 문제다.
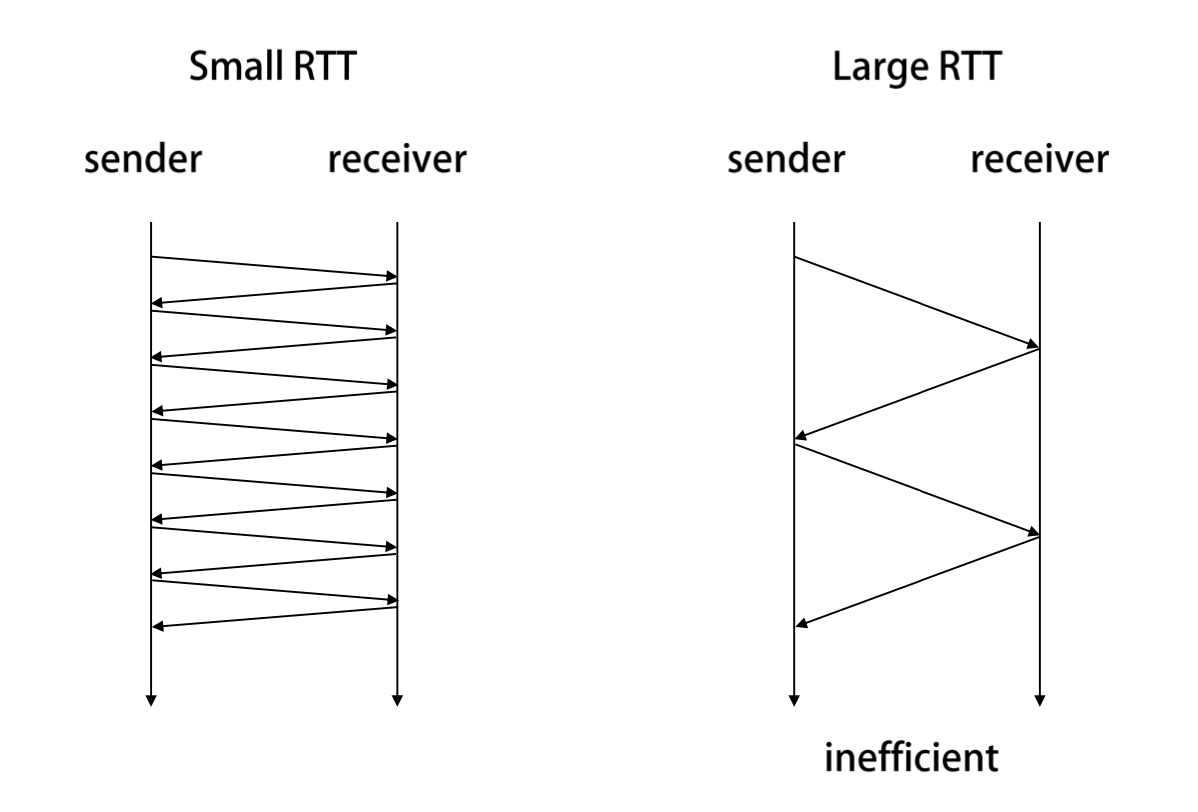
Large RTT에서 ACK 패킷이 도착할 때까지 기다려야하므로 비효율적으로 작동한다. 더 효율적으로 만들기 위해 pipelining 적용 가능하다.
Pipelining
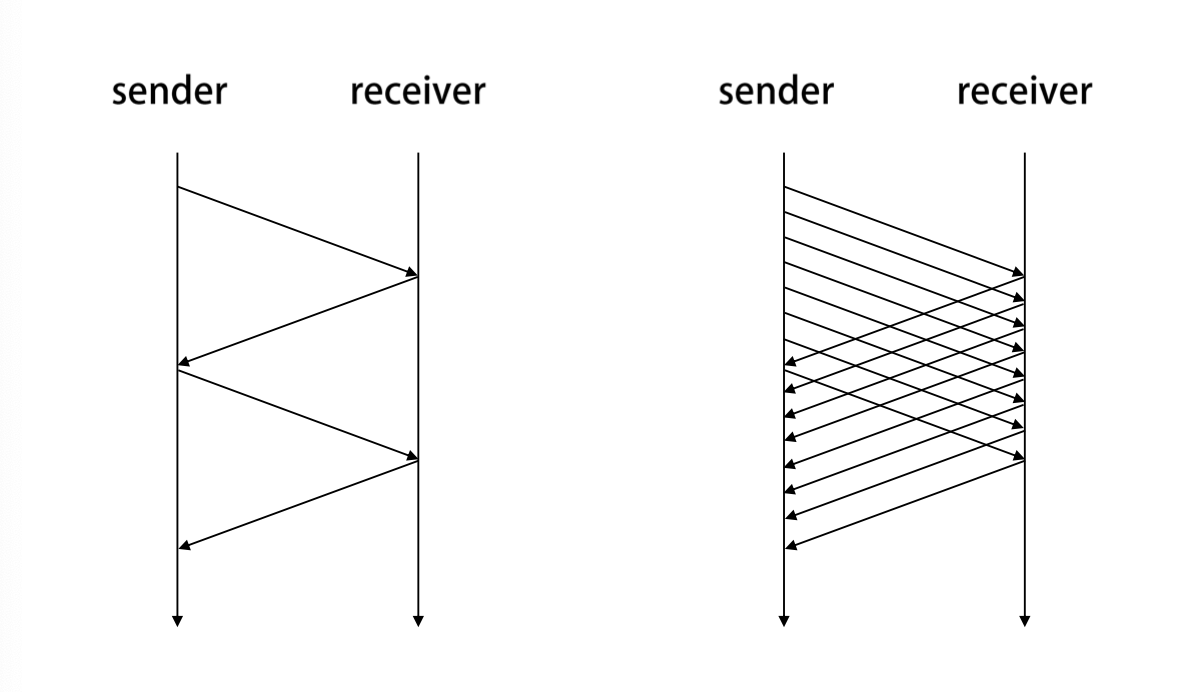
ACK가 회신 되기전 RTT 동안 M개의 Segment를 전송한다. 기존보다 M배 높은 효율을 가진다. 이때 최대 pipelining segment의 수(M)가 송신 윈도우 size가 되고 그만큼의 패킷을 보낼 수 있다.
- Go-Back-N Protocol
- Selective-Repeat Protocol
Go-Back-N Protocol
오류 Segment로부터 이후의 모든 Segment들을 재전송한다.
과정
- ACK가 회신되는 RTT 동안 링크에 최대 Ssize개의 Segment를 전송하고 버퍼에 유지한다.
- ACK가 수신되면 해당 Segment(첫번째 Segment)를 제거하고 Sender Window를 1칸 Sliding한다.
- Segment 재전송 타이머가 종료될때까지 ACK가 수신되지 않으면, 해당 Segment로부터 Sender Window의 모든 Segment를 재전송한다.
버퍼
송신자 버퍼
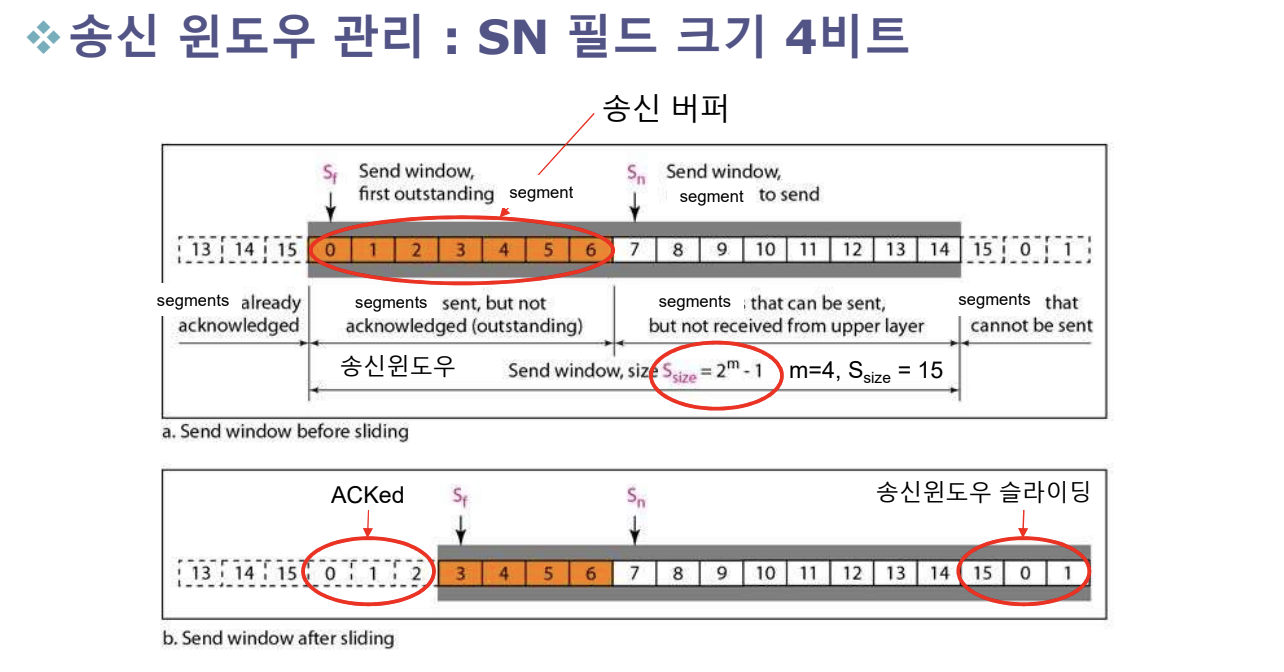
- Ssize: Sender sliding window size
- Ssize = , m은 SN(Sequence Number) 필드 크기
- Sf: ACK가 수신되지 않은 첫번째 Segment SN(Sequence Number)
- Sn: 다음 송신 Segment SN(Sequence Number)
- [Sf, Sn - 1]: Segment 재전송을 위해 버퍼에 유지
- time-out이 발생하면 Outstanding(패킷을 전송했지만, ACK를 못 받은 패킷)한 패킷을 모두 재전송
수신자 버퍼
- Receiver Window Size: 1
- Receiver Buffer Size: 1
- 다음 SN(Sequence Number) 의 Segment를 정상적으로 수신하여 ACK( + 1)을 회신
- 현재 받을 패킷()이 아닐 경우, 모두 폐기
Cumulative(Accumulative) ACK
Go-Back-N 프로토콜에서 Cumulative(Accumulative) ACK는 수신 측에서 송신 측으로 전송된 프레임을 정상적으로 수신했음을 알리는 확인 응답(ACK)이다.
Cumulative(Accumulative) ACK는 특정 시점까지의 모든 연속적인 프레임을 수신했음을 나타내므로, 그 시점 이전의 모든 프레임에 대한 확인이 된다.
즉, 현재 받을 패킷()이 아닐 경우, 모두 폐기하는 방식은 순차적으로 ACK를 확인하므로 이 방법을 Cumulative(Accumulative) ACK라 한다.
Sender window size
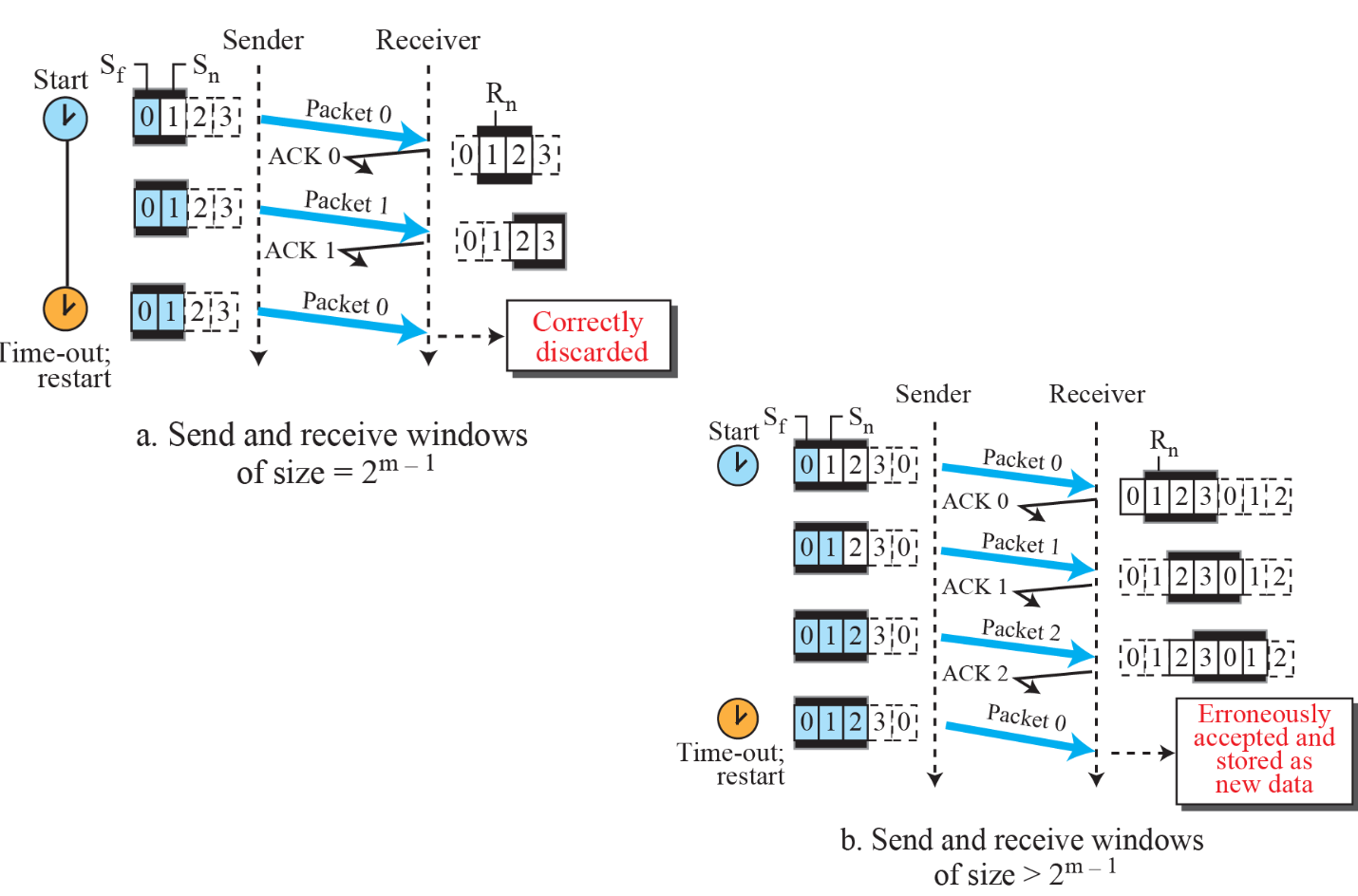
송신 후 버퍼에 유지되어서, 오류 발생 시 재전송한다.
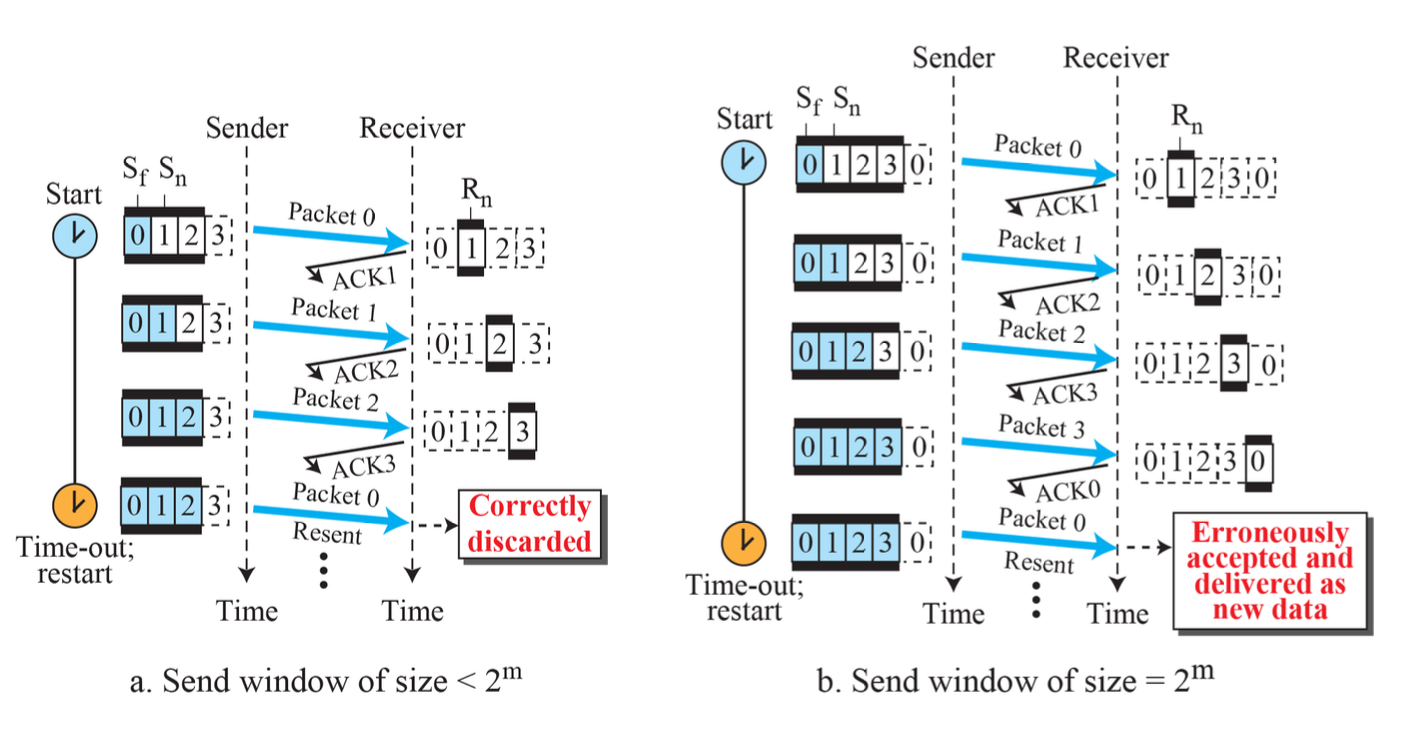
Sender의 window size를 적절하게 정하지 못해서 위 그림에서 문제가 발생한다. 0번 패킷과 4번 패킷을 같게 인식한다.
- Seq number 필드 크기: M 비트
- Ssize(Go-Back-N의 Sender 윈도우 사이즈): 2^M - 1
단점
윈도우 size가 크고 패킷 하나가 오류일 때, 많은 패킷들을 재전송해야 될 수도 있다.
Selective-Repeat Protocol
오류 Segment만 선택적으로 재전송한다.
과정
- ACK가 회신되는 RTT 동안 링크에 최대 Ssize개의 Segment를 전송하고 버퍼에 유지한다.
- Accumulative ACK가 수신되면 Sender Window를 수신한 Accumulative ACK 수 만큼 Sliding한다.
- Non-Accumulative ACK가 수신되면 해당 Segment의 ACK 수신 사실을 기록한다.
- Segment 재전송 타이머가 종료될때까지 ACK가 수신되지 않으면, 해당 Segment를 재전송한다.
버퍼 및 Window
송신자
- Accumulative ACK: 송신 Window 내에서 순서에 맞는 ACK
- Non-Accumulative ACK: 송신 Window 내에서 순서가 맞지 않는 ACK
수신자
- Receiver Window Size(Rsize) = Sender Window Size
- Accumulative ACK가 수신되면 ACK 회신하고 Accumulative ACK 수 만큼 Sliding
- Non-Accumulative ACK가 수신되면 ACK 회신하고 해당 Segment를 수신자 버퍼에 유지한다.
Sender window size
- Seq number 필드 크기: M 비트
- Ssize(최대 윈도우 사이즈) = 2M - 1
TCP
About TCP Connection
TCP는 1:1 소켓 연결을 지원하므로, 연결 설정 과정(handshaking)이 필요하다.
하나의 서버가 여러 클라이언트와 통신하기 위해서는 서버 IP와 서버 Port Number는 공유 가능하다.
GBN과 SR을 통합한 형태이다.
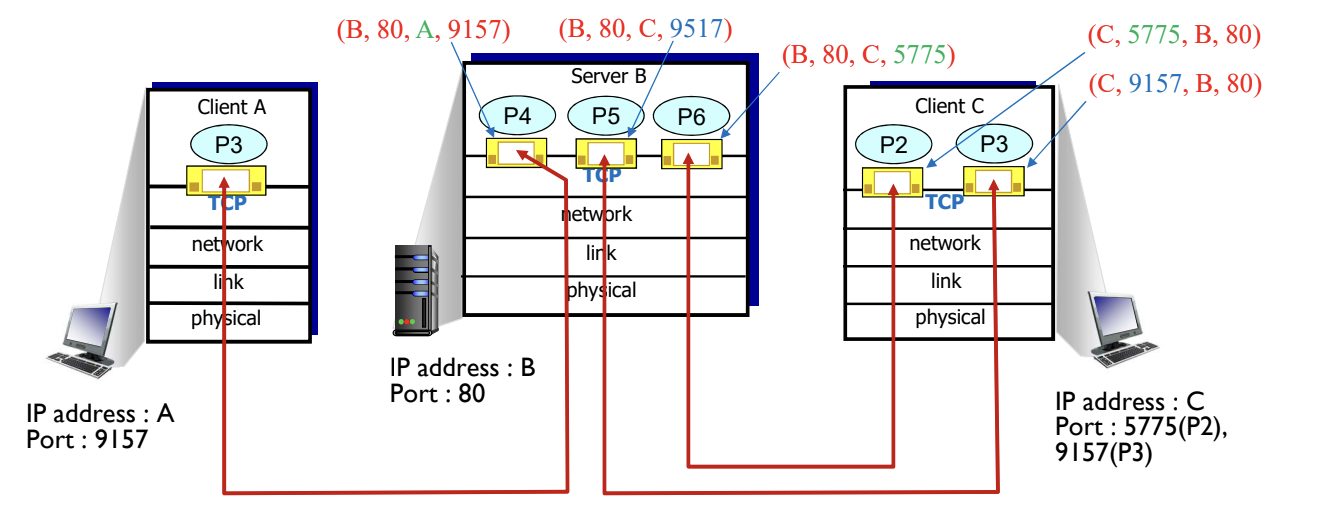
Multicasting은 지원 불가
1:1 Socket Connection
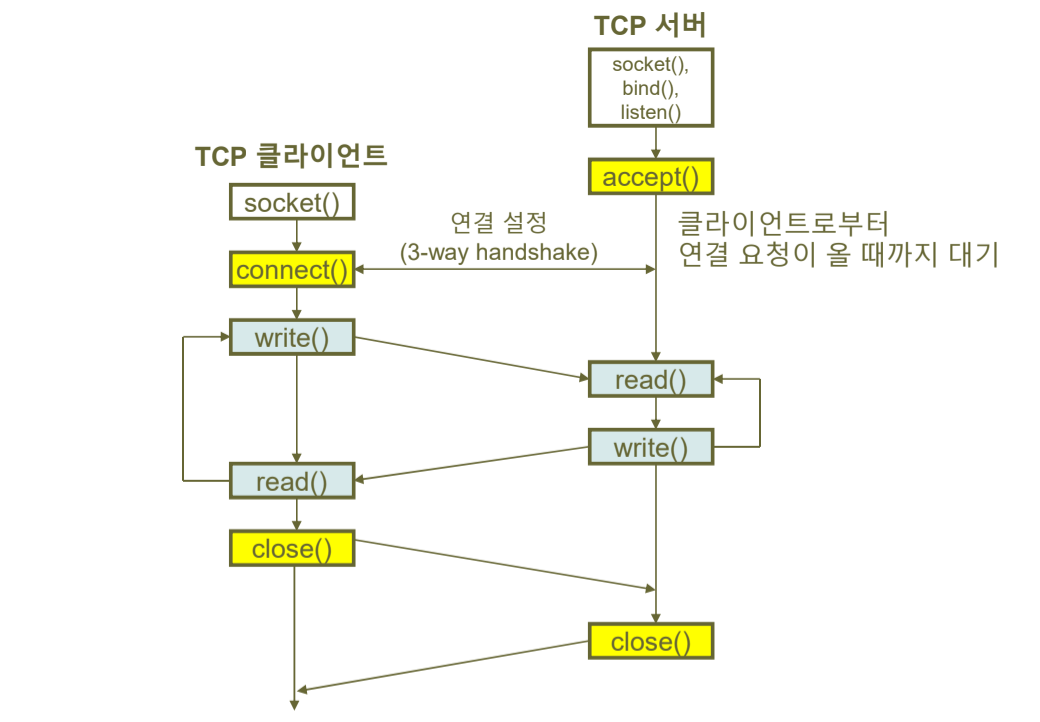
- Socket() 객체 생성
- connect()로 연결 수립
- read(), write()로 데이터 전송
- close()로 연결 종료
Full-duplex(전이중) 통신
- 연결 수립 후 양방향 데이터 통신(Full-duplex) 가능
- MSS: Segment의 데이터 필드 최대 크기(데이터 전송 단위)
- 보통 MSS는 1460 바이트 정도 사용
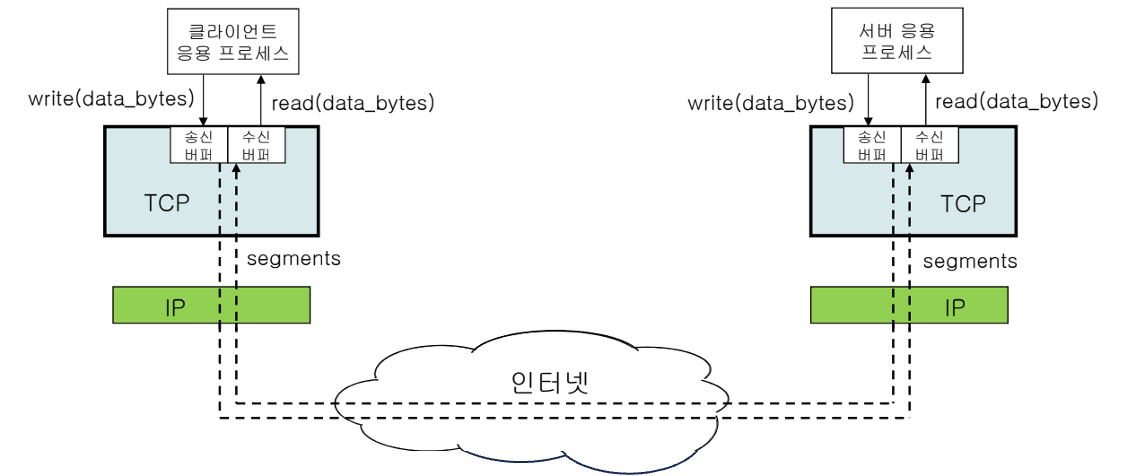
Byte Stream 전송
- 송신 프로세스가 소켓의 송신 버퍼에 전달(write)한 바이트 스트림을 수신 소켓의 수신 버퍼에 순서대로 전송한다.
- write() 10,000 byte할 경우, 세그먼트 단위(MSS)로 수신 버퍼에 전달한다.
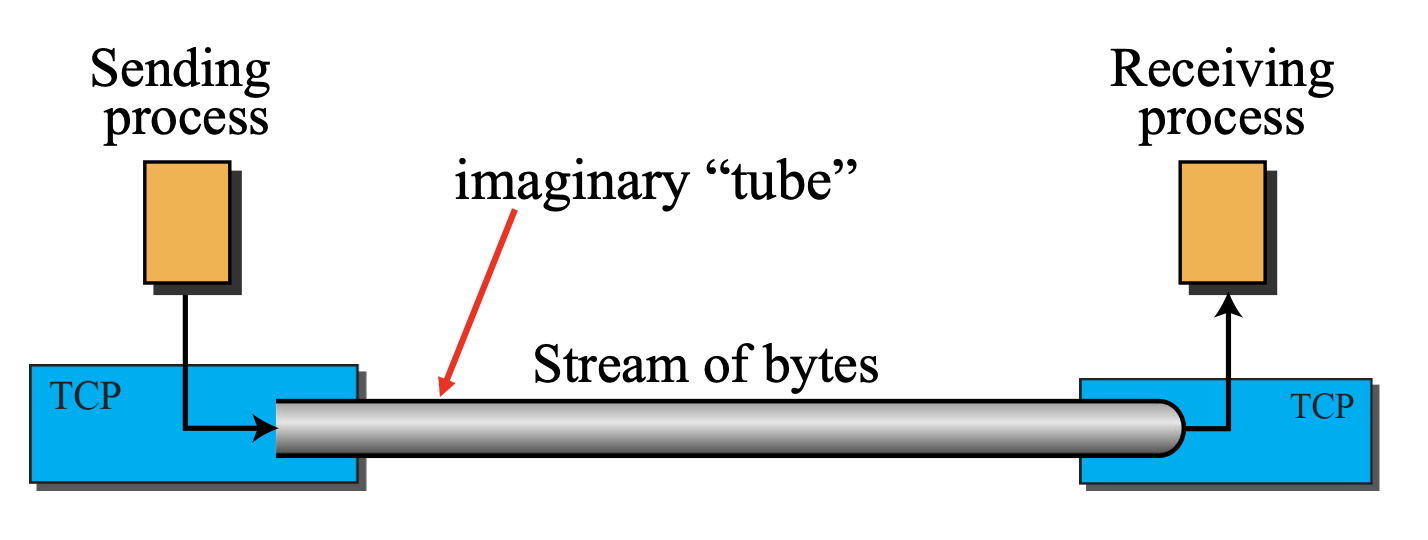
Buffer
sender와 receiver의 크기가 같을 필요는 없다.

TCP Connection (3-way Handshaking)
3-way Handshaking으로 클라이언트와 서버 간에 동기를 맞추는 과정이다.
- 동기 정보: 소켓 주소, 시작 SN, 수신 윈도우 크기
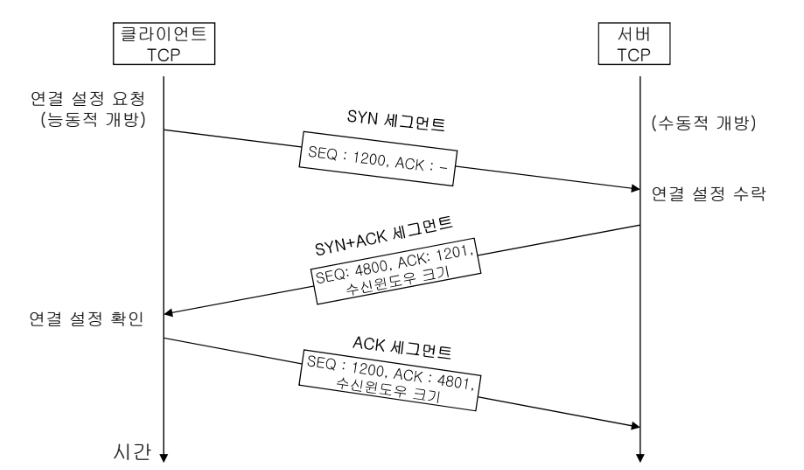
- 클라이언트가 동기화를 위한 SYN Segment를 전송한다.
- 서버는 응답을 허용한다는 ACK Segment와 클라이언트에 데이터를 보내기 위해 동기화를 위한 SYN Segment를 한번에 전송한다.
- 클라이언트는 SYN Segment를 받았다는 응답인 ACK Segment를 전송한다.
- SYN+ACK segment: cannot carry data, comsumes 1-byte seq.no
- ACK segment: carry data, if carrying no data -> consuming no seq.no
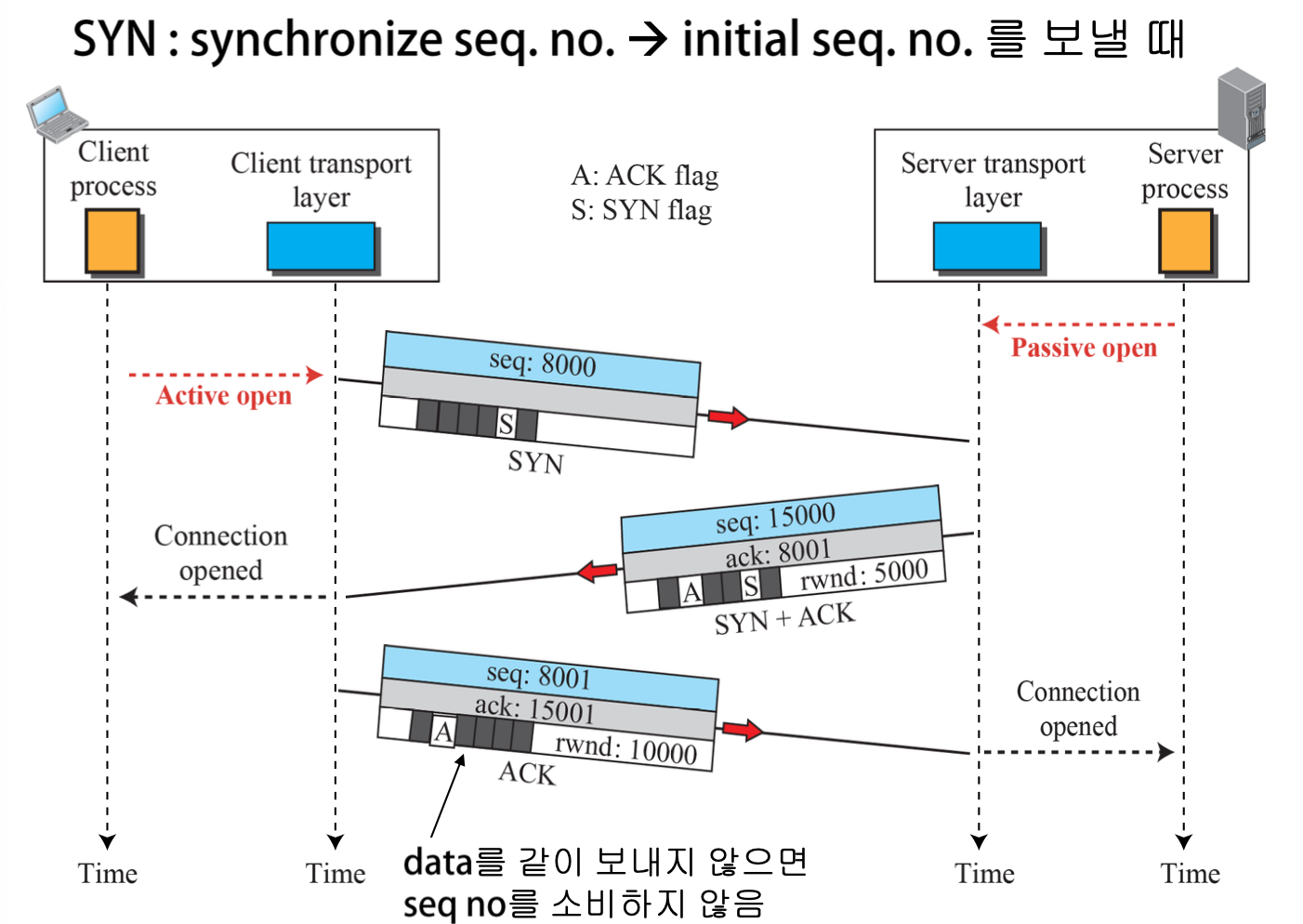
rwnd: 헤더의 윈도우 사이즈 필드 설정
SYN Segment
연결 설정을 위해 클라이언트 TCP가 서버 TCP에 전송한다.
- SYN Bit를 1로 설정
- ISN(Inintial Sequence Number)를 설정
- Cannot carry data (No Piggybacking)
- 세그먼트의 데이터 부분이 없음
- ACK를 위해 SN 1 소비
- 가상의 1 바이트 데이터 전송(헤더로 구현)
SYN+ACK Segment
SYN Segment를 수신한 서버 TCP가 클라이언트 TCP에 전송한다.
- SYN Bit와 ACK Bit를 1로 설정
- ISN(Inintial Sequence Number)를 설정
- 확인 번호(ACK) 설정
- 수신 윈도우 크기 설정
- ACK를 위해 순서번호 1 소비
- Cannot carry data
ACK Segment
SYN+ACK Segment를 수신한 클라이언트 TCP가 서버 TCP에 전송한다.
- ACK Bit를 1로 설정
- 확인 번호(ACK) 설정
- 수신 윈도우 크기 설정
- Can carry data
- Data가 없을 경우, SN을 소비하지 않음
- 이후 DATA Segment 전송
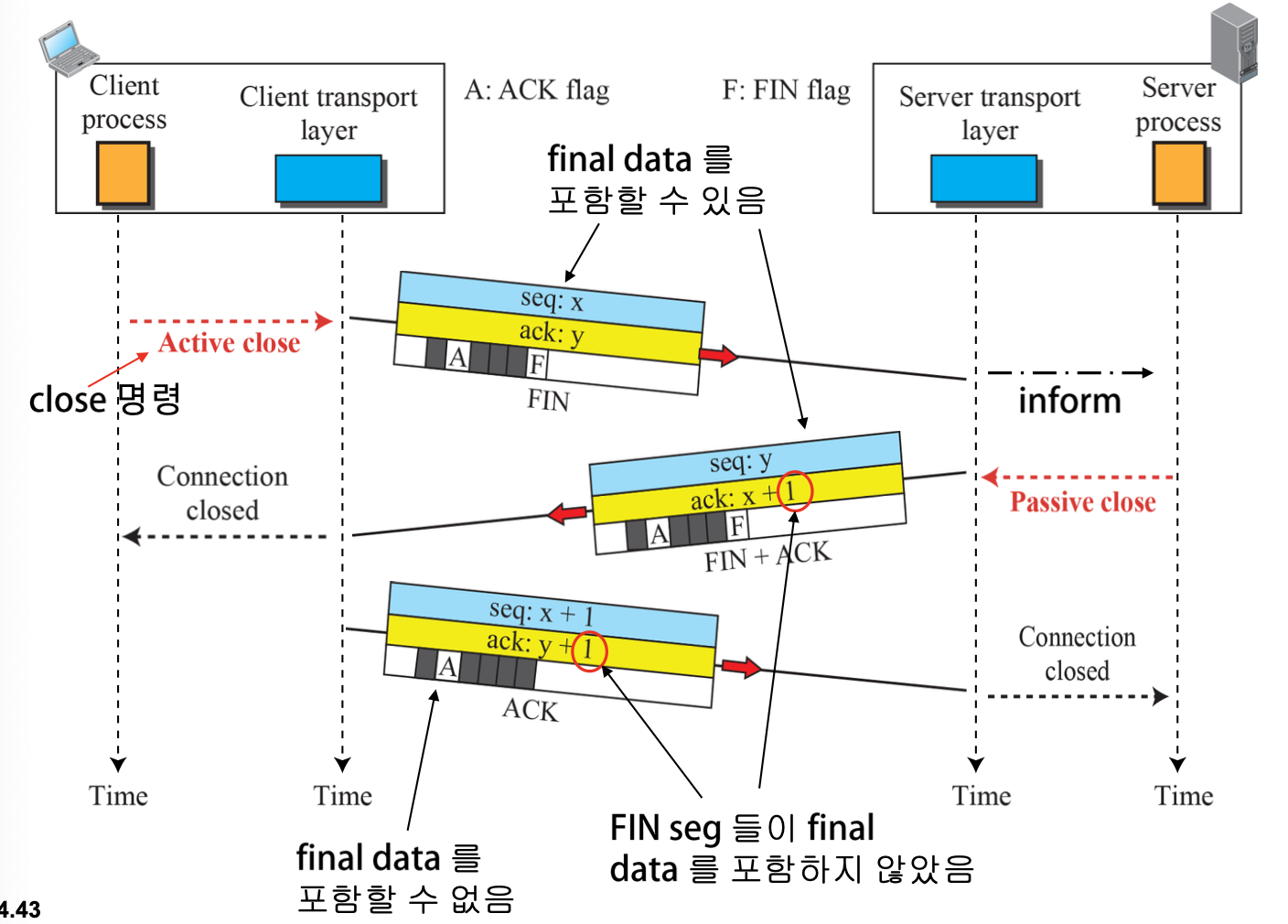
TCP Connection Termination
DATA 전송 후에는 TCP 연결 종료를 위해 4-Way Handshaking을 진행한다.
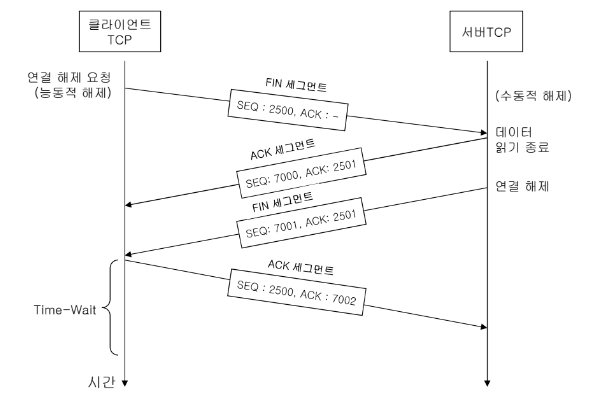
- 클라이언트는 종료를 위한 FIN Segment 전송
- FIN Segment에 대한 응답으로 ACK Segment 전송
- 서버도 종료를 위한 FIN Segment 전송
- FIN Segment에 대한 응답으로 ACK Segment 전송
Termination은 client와 server 중 아무나 먼저 요청 가능하다.
-
두 가지 옵션 존재
- Three-Way Handshaking: Full Close
- Four-Way Handshaking: Half Close(더 확실한 방식)
-
FIN Segment: ACK를 위해 SN 1 소비
-
ACK Segment: Data가 없으면 SN 소비 없음
Three-Way Handshaking Termination
Four-Way Handshaking Termination
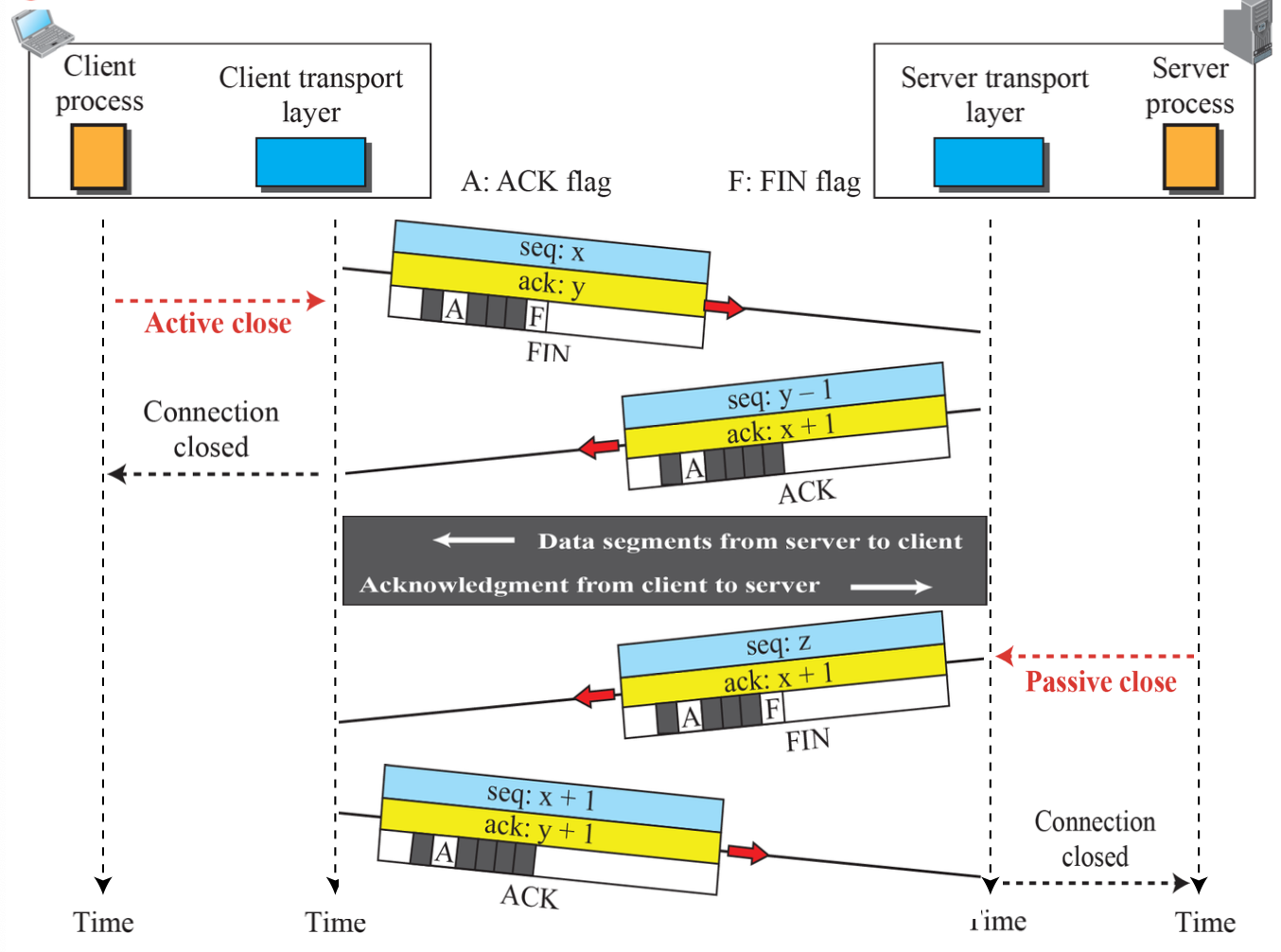
클라이언트 시간 대기(Time-Wait)를 통해 마지막 ACK Segemtn 손실 시에 재전송 되는 FIN Segment를 처리한다. 일반적으로 3초이다.
SYN Flooding Attack(DOS Attack)
- 악의적인 공격자가 여러 IP를 가진 client를 가장하여 짧은 시간에 많은 SYN segment를 server에게 보내는 공격
- Server는 SYN segment를 받을 때마다 resource(creating transfer control block table, ...)를 할당한다.
- 많은 SYN segment가 들어오면 server의 리소스는 고갈되며, 정상적인 client의 SYN segment가 들어와도 서비스를 거부한다.
- 복잡한 ISN 번호를 통해 예방한다.
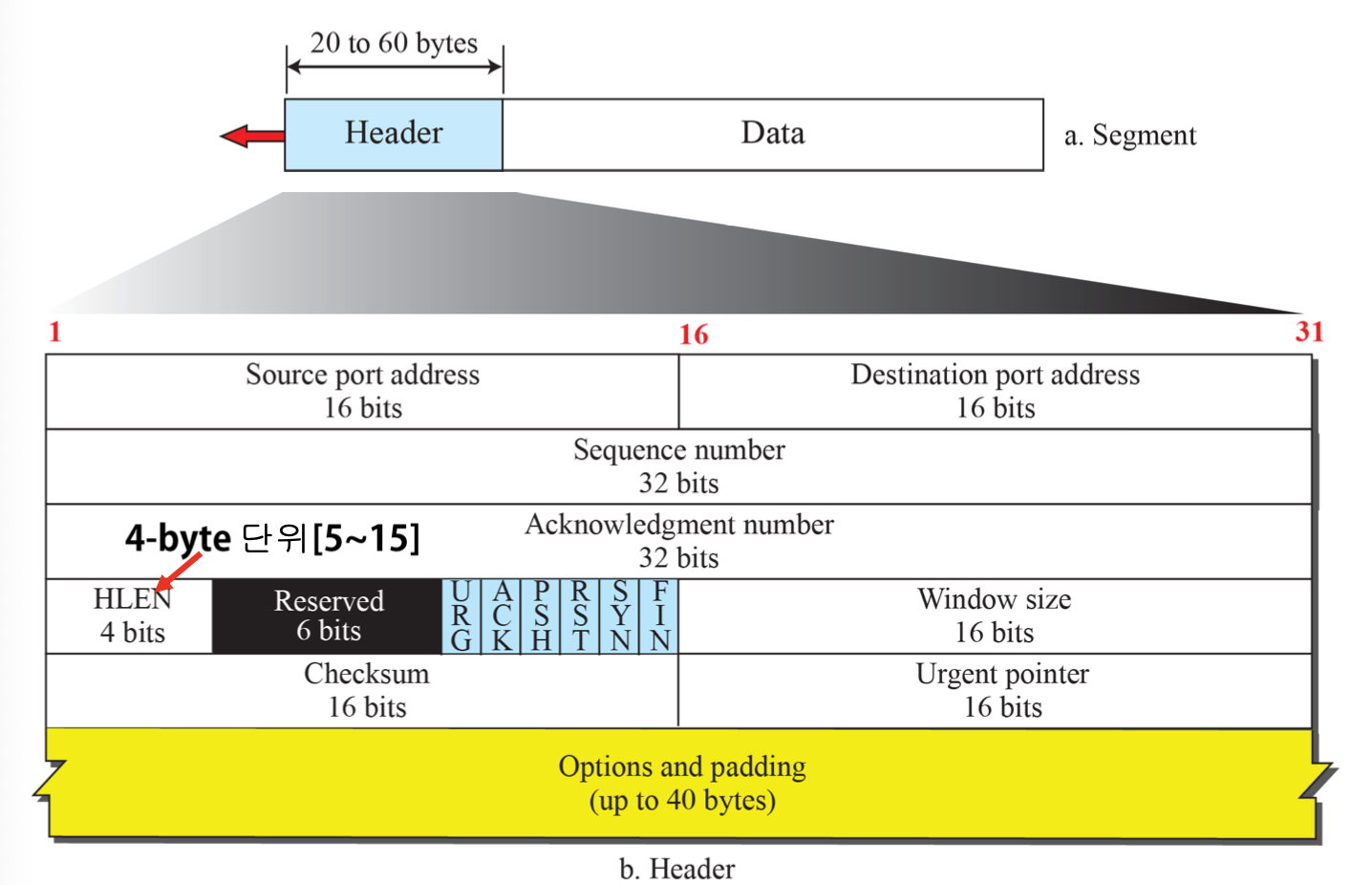
TCP Segment
TCP 계층에서 데이터는 byte stream이지만, IP 계층에서는 적당한 크기의 packet들로 보내야 하므로, TCP에서도 이에 맞춰 segment로 나누어 보낸다.
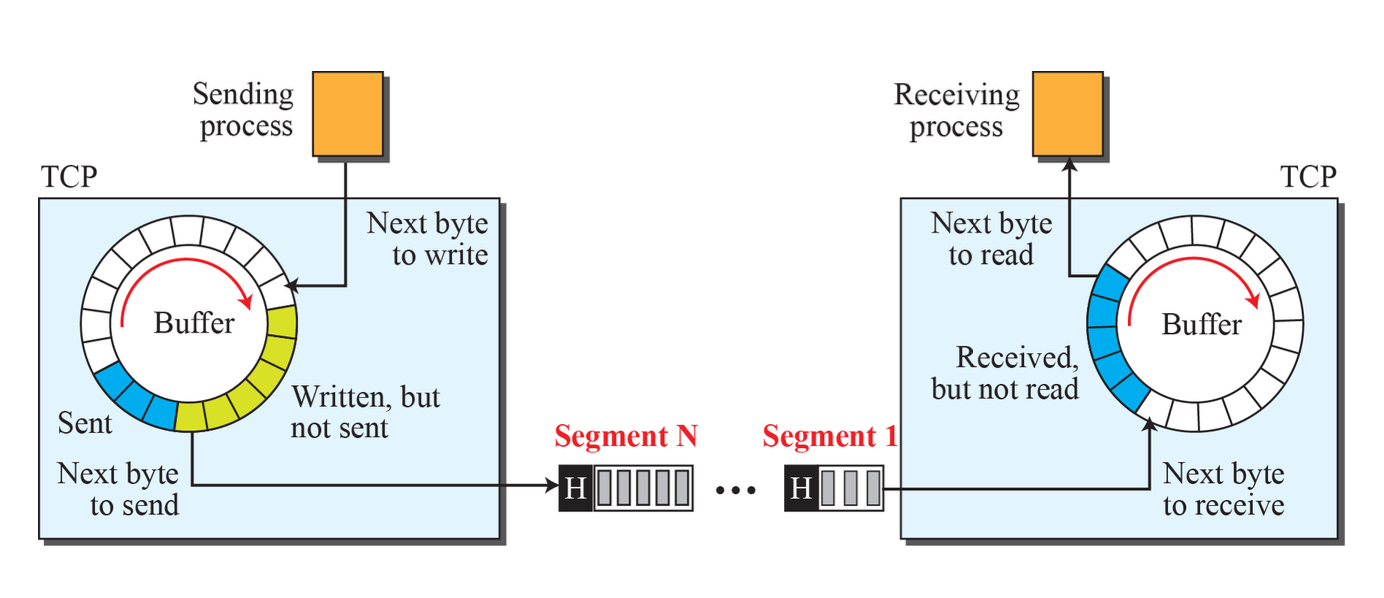
Application 계층에서 내려온 데이터를 TCP가 Segmentation되고 하위 계층으로 내려가면서 Encapsulatation이 된다.
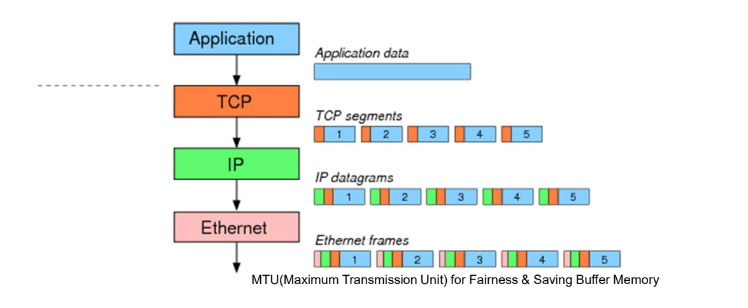
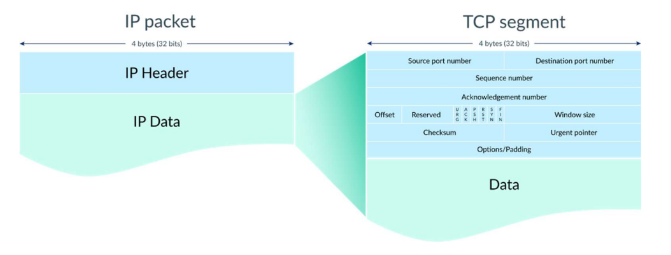
- TCP Segment = Header(Control Information) + Data(Payload) Field
MSS (Maximim Segment Size)
- 데이터 필드에 포함되는 응용 메시지 조각(chunk)의 최대 크기
- 데이터 링크의 MTU(Maximum Transmission Unit)에 의해 결정
- TCP Header 크기 + IP Header 크기+ MSS ≤ MTU
TCP Segment 구조
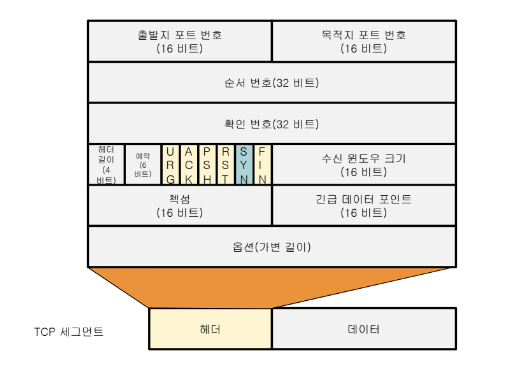
Base 20 + Optional 40 = 60이 최대 헤더 길이이다.
TCP 포트 번호(Port Number)
응용 프로토콜(프로세스)를 식별한다.
- 클라이언트 포트 번호 : 연결 설정 시에 임의의 포트 번호 할당(Ephemeral Port)
- 서버 포트 번호 : 연결 설정 전에 미리 할당(Well-known Port)
- 출발지(source) 포트 번호 : 세그먼트 송신자의 포트 번호, 16 비트
- 목적지(destination) 포트 번호 : 세그먼트 수신자의 포트 번호, 16 비트
순서 번호(Sequence Number)
시작 순서 번호(ISN)부터 이미 송신된 바이트의 다음 바이트 번호(데이터의 첫번째 바이트 번호), 세그먼트 송신자에 의해 부여된다.
- ISN + 송신된 바이트 수
확인 번호(Acknowledgement Number)
순서대로 수신된 세그먼트의 마지막 바이트의 다음 바이트 번호(수신을 기대하는 세그먼트의 순서 번호), 세그먼트 수신자에 의해 부여한다.
- 순서대로 수신된 세그먼트 순서 번호 + 수신 세그먼트 데이터 크기
- 누적 수신 확인(Cumulative Acknowledgement)
헤더 길이(Header Length)
헤더 필드 전체 길이(20~60 바이트), 4바이트 워드 단위로 표시(5~15)
수신 윈도우(Receive Window) 크기
- 수신 TCP가 수신 가능한 데이터 크기(버퍼 여유 공간)
- 수신 TCP가 ACK 세그먼트에 표시, 송신 윈도우(send window) 결정
- 최대 65,535 바이트(16 비트 필드)
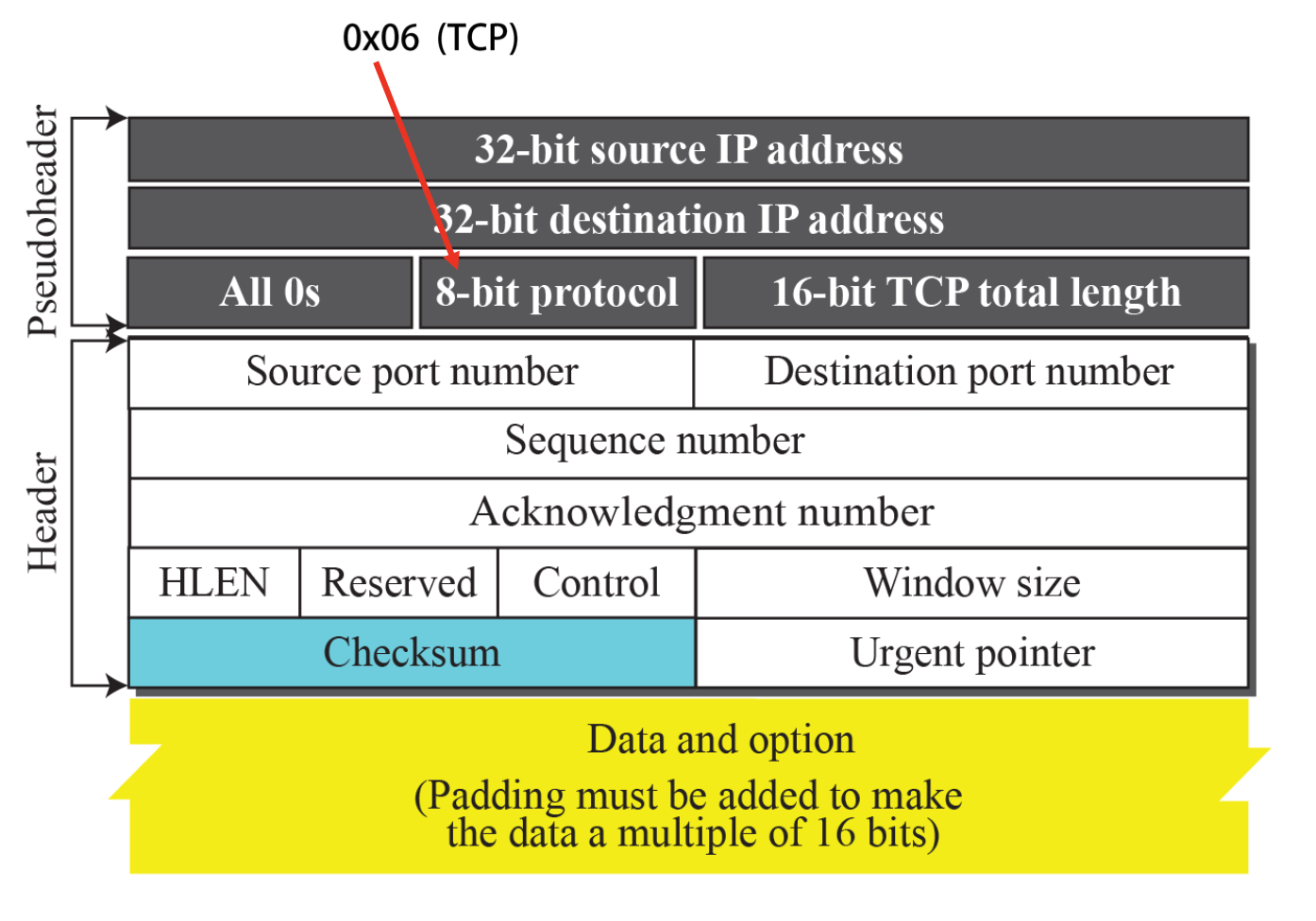
Checksum
제어 플래그(Control Flags)

긴급 데이터 포인터(Urgent Data Pointer)
긴급 데이터의 위치를 나타낸다.
TCP Data Transfer
- connection 수립 후에, 양방향 데이터 전송 가능
- client, server 모두 데이터와 ACK 전송 가능
- ACK는 데이터와 함께 piggybacked 된다.
- Pushing data: 보통 TCP receiver는 buffer에 어느정도 byte가 차야 application에 전달한다 그러나 delay sesitive한 interactive data 등의 경우에는, sender application의 지시에 의하여 TCP sender가 PSH flag를 setting하여 전송하고, TCP receiver는 수신 즉시 application으로 보낸다.
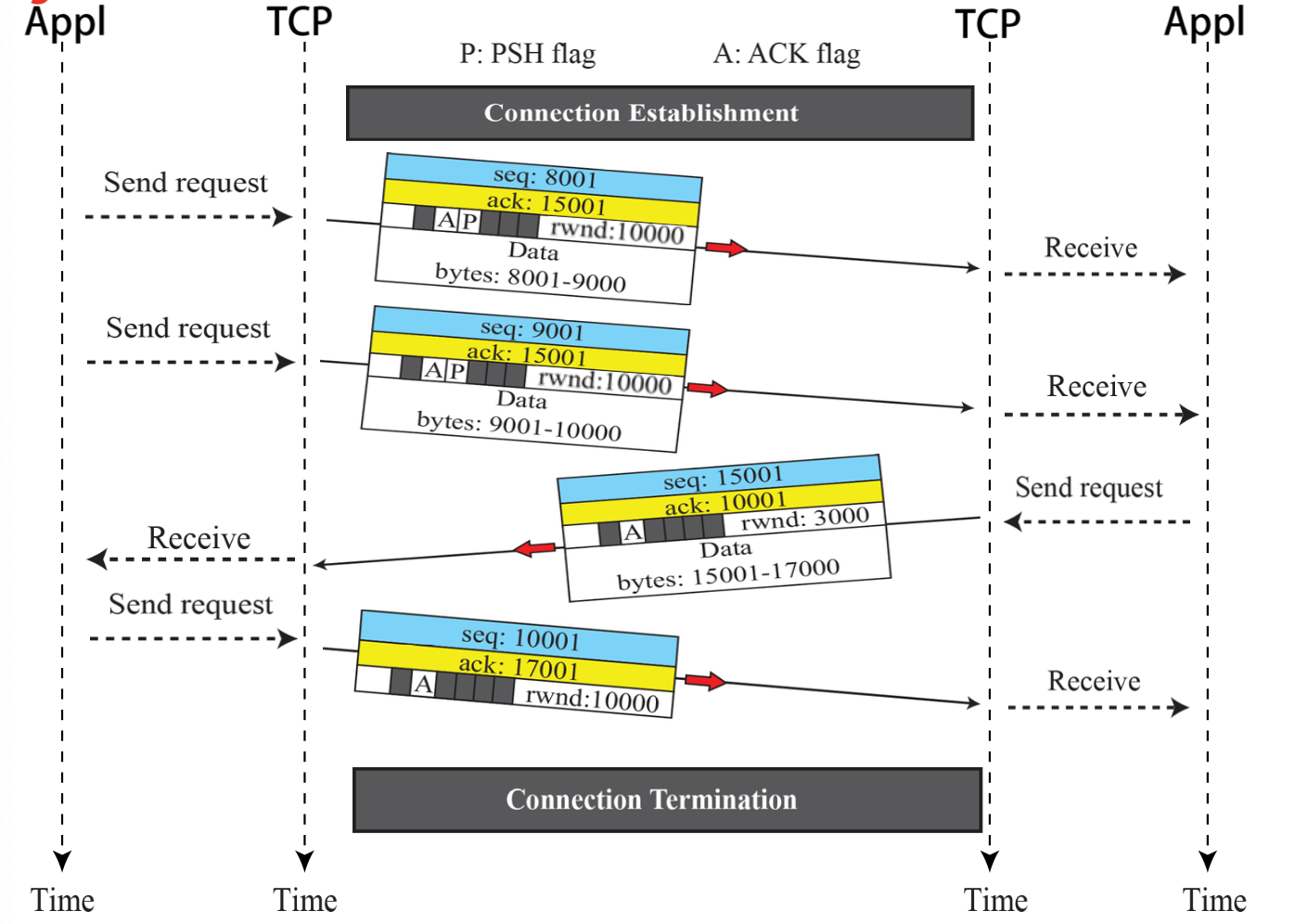
piggybacking으로 인해 확인 응답을 기존의 데이터 프레임에 함께 실어서 전송할 수 있다. 이렇게 하면 추가적인 데이터 전송이 필요 없어지고, 대역폭을 효율적으로 활용할 수 있다.
TCP RTT
Segment 송신 후 ACK 수신까지 걸리는 시간이다. 네트워크 혼잡도에 따라 가변적인 시간이다.
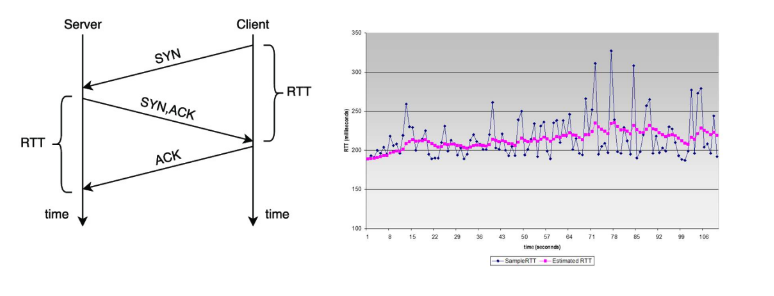
TCP RTT 추정
- α = 0.125
- 지수이동가중평균(exponential weighted moving average)
TCP RTT 분산 추정
- β = 0.25
Timeout
RTTm(측정한 RTT값)들의 평균인 RTTs를 계산한다.
-
RTTs = E[RTTm]
|RTTs - RTTm| 평균을 계산한다.
RTTd = E[|RTTs - RTTm|]
RTO = RTTs + 4RTTd -
TimeoutInterval = EstimatedRTT + 4*DevRTT
4배가 적절하다고 판단
TCP Segment Rules
Cumulative Acknowledgement(?)
- 누적적으로 완전하게 수신된 바이트 스트림 번호 확인
- 중복 ACK 세그먼트 수신 가능
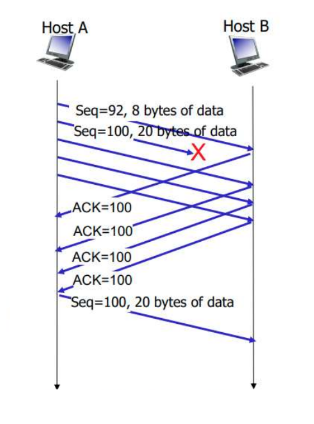
단일 타이머
누적 수신 확인이 되지 않은 가장 오래된 세그먼트에 대한 재전송 타이머 유지한다.
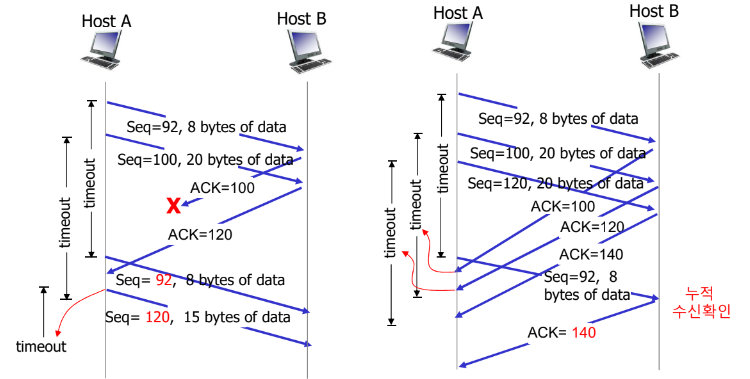
TCP Error Control
- TCP는 cumulative ACK.(그전까지는 빠짐 없이 받았다.)
- Piggybacked로 전송한다.
- Receiver에 데이터 도착했을 때, ACK를 보내기 위해 ACK Delaying을 한다.
- 보낼 데이터를 위해 잠깐 기다려본다.
- 그 다음 segment가 있을 수도 있기에, cumulative로 받기 위해 기다린다.
- Timeout(500ms)을 기다렸다가, 아무 일도 없으면 ACK segment를 전송한다.
- ACK를 안보낸 상태에서 다음 segment가 도착하면, 즉시 ACK를 전송한다.
- 순서에 맞지 않는 segment를 받을 경우, 즉시 ACK를 전송한다.
- Missing segment(빈 부분이 존재하는 segment)가 도착하면, 즉시 ACK를 전송한다.
- Duplicate segment(중복 segment)가 도착하면, 즉시 ACK를 전송한다.
- CheckSum에 의해 에러 발생 시, 버리고 ACK를 전송하지 않는다.
TCP Retransmission(Sender의 재전송)
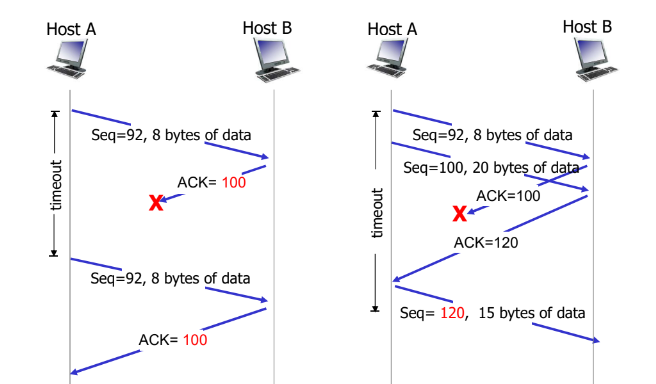
ACK를 받지 못한 Segment를 항상 재전송하는 것은 아니다.
Sender는 다음의 세 가지 경우에 segment를 재전송한다.
- ACK 미수신에 의한 Retransmission time-out
- 3개의 중복된 ACK
Sender의 TCP 헤더 Sequence Number 필드에 5001이 적어져 있고, Receiver가 그 데이터 바이트 크기를 계산해서 ACK 응답을 전송한다.
ACK 미수신에 의한 Retransmission time-out
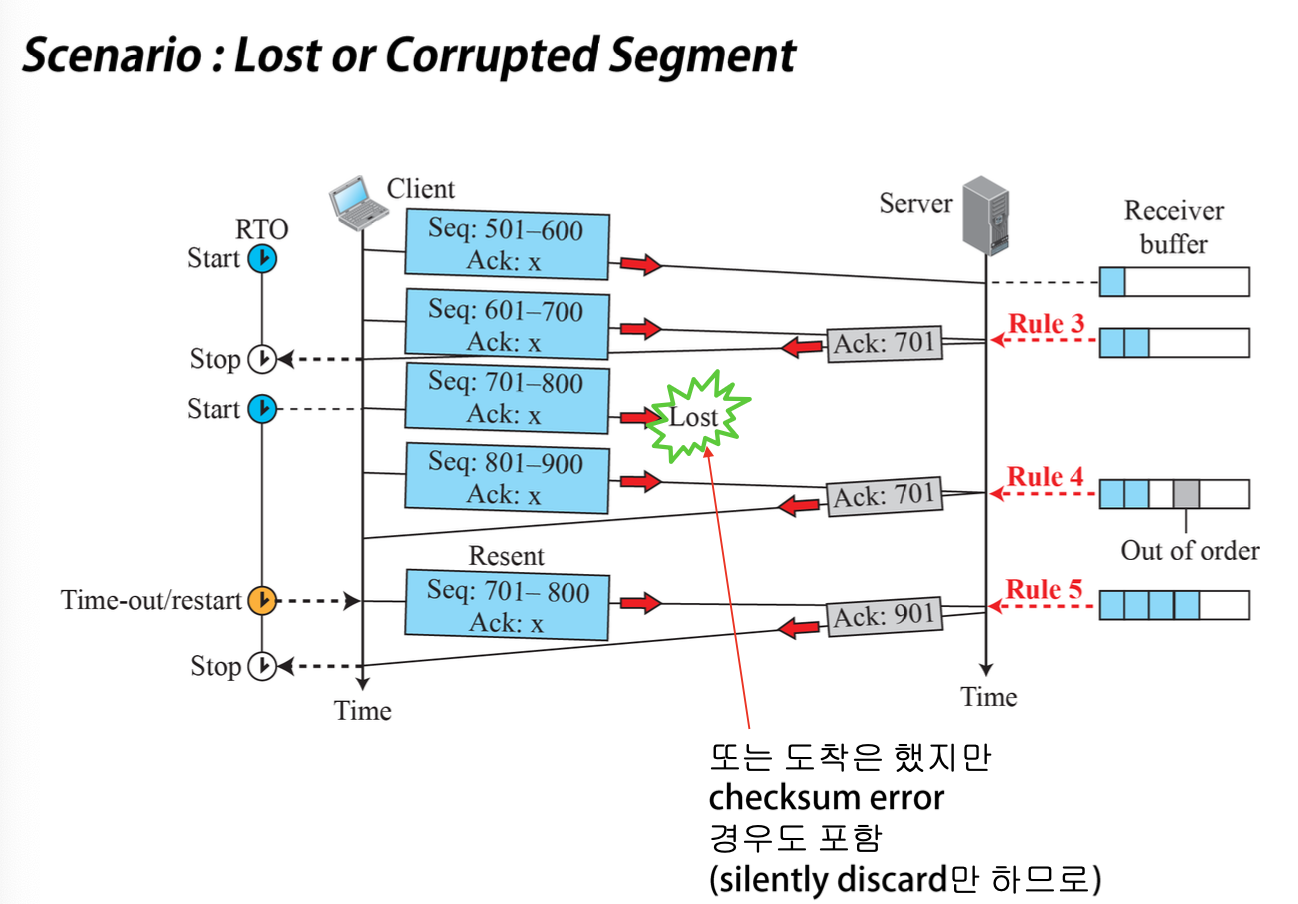
빠른 재전송(Fast Retransmission)
- 세그먼트가 손실된 상황에서 Timeout까지 불필요한 긴 시간 대기 회피
- 3개 중복 ACK 도착하면 Timeout과 무관하게 누적 수신 확인 다음 세그먼트 재전송
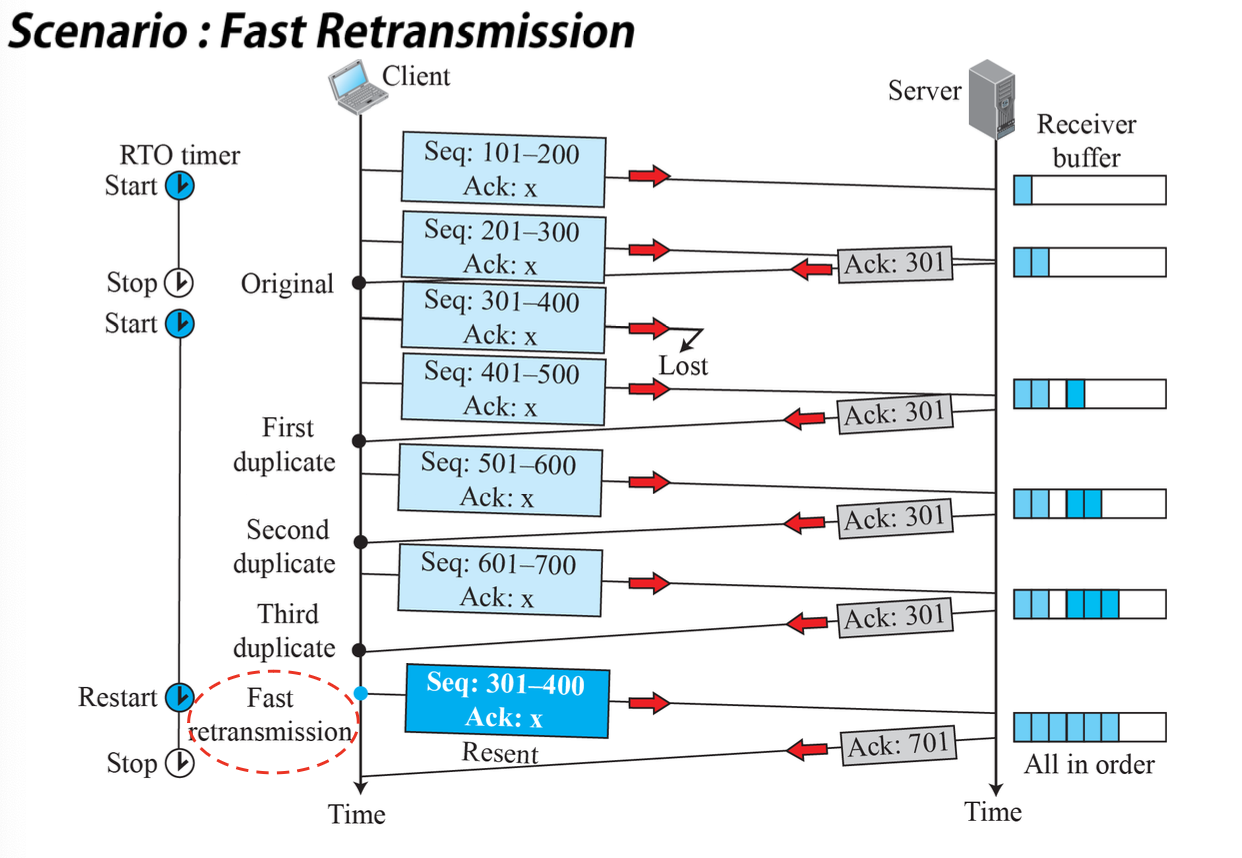
Timeout 전에 중복 ACK 발생하는 경우
- 순서가 바뀐 Segment 도착
- 1~2개의 중복 ACK 후에 정상 ACK 회신
- 연속된 세그먼트의 도착 시간에 큰 차이가 없음
- 3개 이상의 중복 ACK가 발생하면 순서 문제가 아니라고 판단 -> 손실이라 판단!
- 중간 Segment 손실
- 라우터에 경미한 버퍼 오버플로우 발생했을 때 손실됨
- 손실된 Segment를 재전송
TCP Flow Control
송신 TCP가 지나치게 많은 데이터를 한꺼번에 송신함으로써 수신 TCP의 버퍼가 넘쳐(overflow) 데이터 손실이 발생하는 문제를 방지하는 메카니즘이다.
수신 TCP는 자신의 수신 버퍼내의 여유 공간의 크기를 송신 TCP에게 알려주고, 송신 TCP는 통지된 여유 공간의 크기 보다 적은 양의 데이터를 송신한다.
Receive Window
rwnd: 수신할 수 있는 데이터의 양
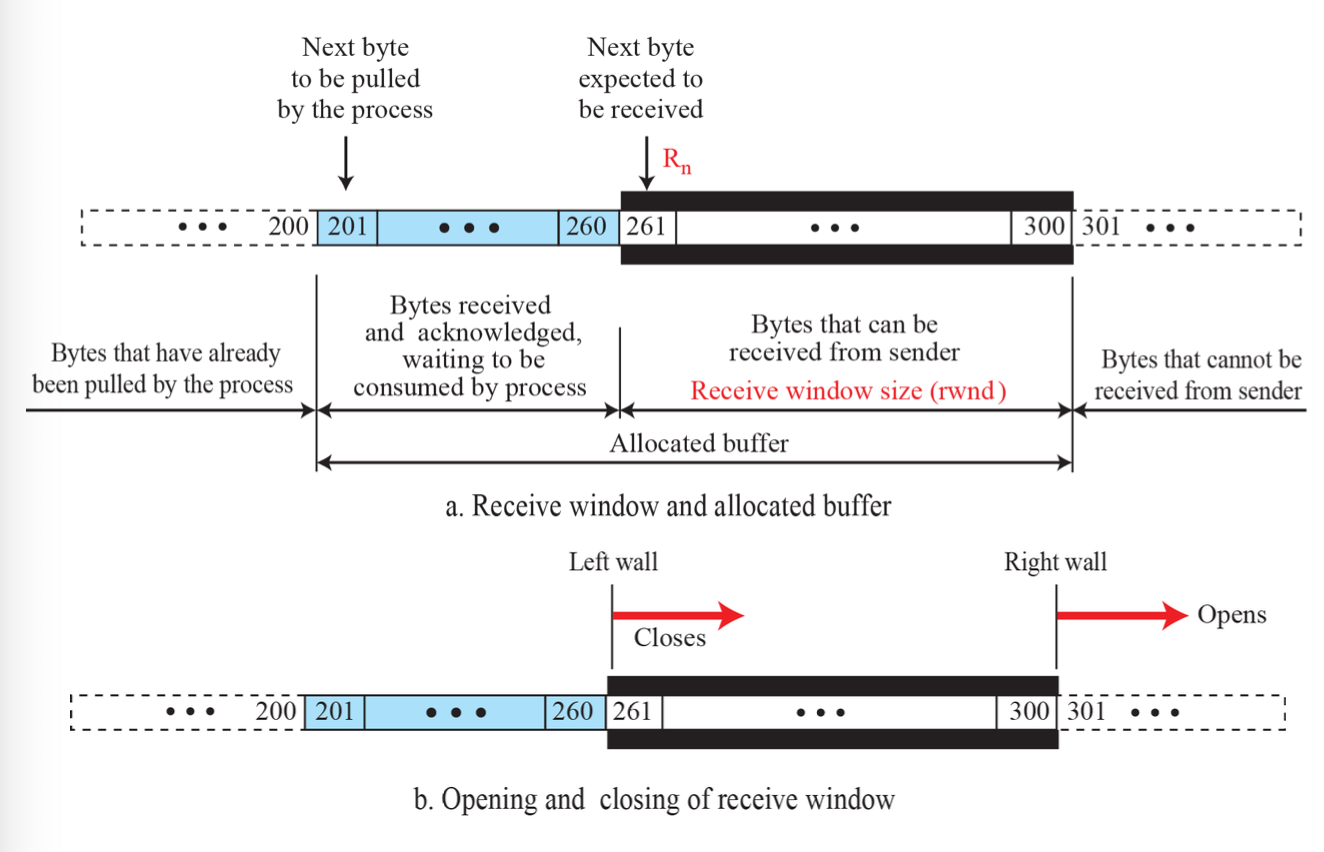
연결 설정 시에 수신버퍼크기와 동일하게 설정한다. 수신 데이터의 버퍼 저장과 응용 프로세스에 의한 버퍼 데이터 읽기 과정에서 수신 윈도우가 변화한다.
Send Window
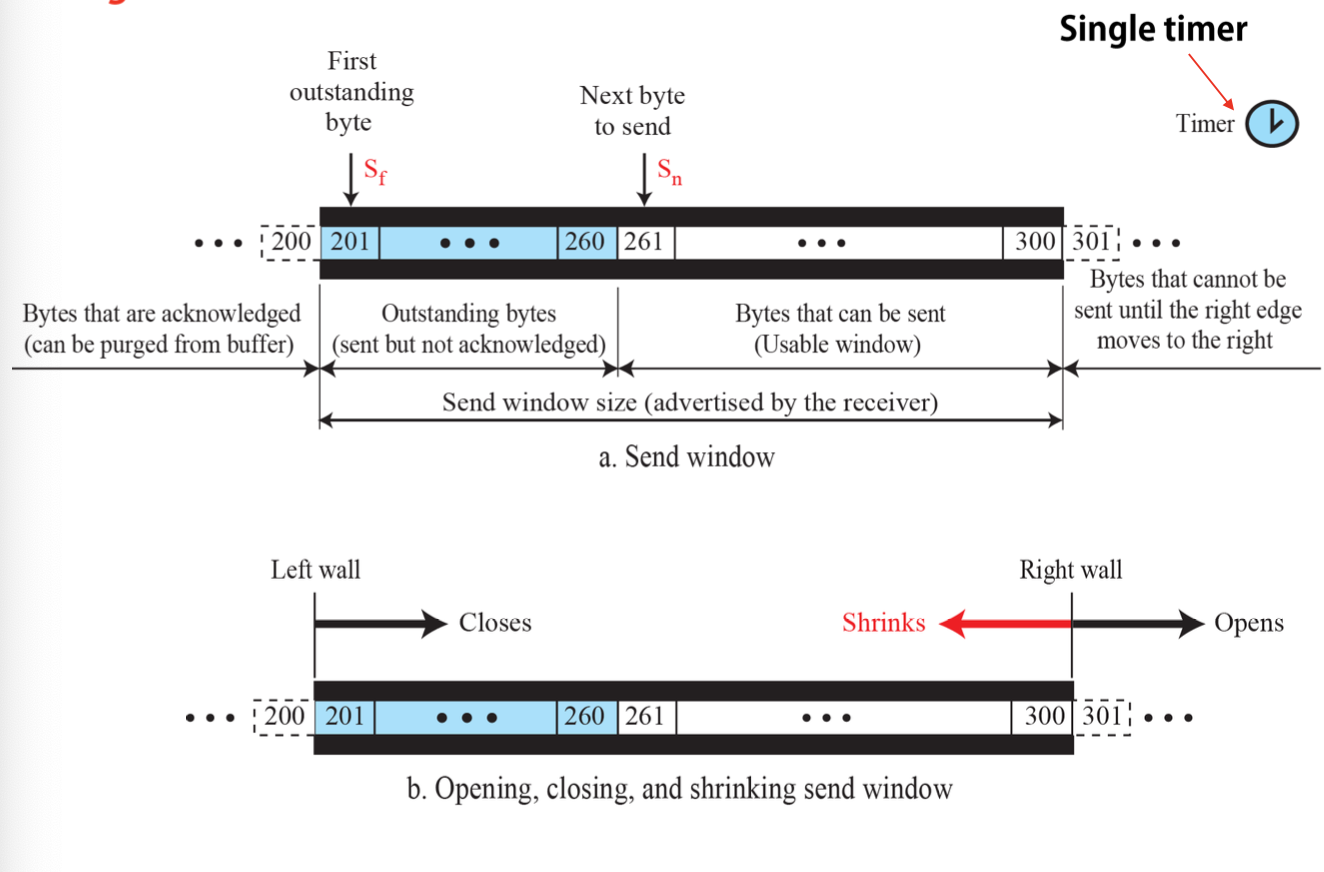
Sender의 Window: 응용 계층에서 데이터를 버퍼에 보내면 TCP가 그 데이터를 읽어주는 임시 버퍼이다.
마지막으로 송신한 바이트 번호와 확인 세그먼트를 통해 마지막으로 수신 확인된 바이트 번호의 차이가 항상 수신윈도우 보다 작게 유지해야 한다.
LastByteSent - LastByteAcked ≤ rwnd

Flow Control
수신 TCP가 송신 TCP로 전달하는 ACK Segment 수신윈도우 필드에 포함되어 통보한다.
윈도우 프로브(Probe) 세그먼트
IP계층에서 데이터가 계속 들어오고 응용 계층에서 데이터를 처리하지 못하면 rwnd가 0이 될 수 있다.
- 송신 TCP는 rwnd가 0이므로 데이터를 보내지 않는다.
- 송신 TCP가 데이터를 보내지 않으므로 수신 TCP는 ACK를 보내지 않는다.
- Deadlock 상태 진입
수신윈도우가 0이 되면, 송신 TCP가 수신 TCP에게 1 바이트 세그먼트를 주기적으로 전송하여 해결한다.
TCP Congestion Control
Receiver는 rwnd 값으로 send window 크기를 조절하여 flow control을 한다.
Congestion은 너무 많은 traffic의 유입으로 network 중간의 router들의 buffer가 overflow 되는 것이다. Receiver는 congestion에 대해 못하며, rwnd로는 조절할 수 없다. TCP는 congestion window (cwnd)를 이용하여 send window 크기를 조절한다. cwnd(Congestion Window의 크기) 값을 늘리거나 줄일 때의 단위로서 MSS(maximum segment size)가 관여한다.
LastByteSent - LastByteAcked ≤ min(rwnd, cwnd)
Congestion Detection
Send TCP는 오로지 ACK들을 가지고 네트워크의 상황으로 판단한다.
- Two types of signs for possible congestion
- Time-out (RTO)
- Three duplicate ACKs
- Time-out : due to severe congestion(강력한 congestion의 징후)
- Three duplicate ACKs : due to weak congestion or maybe due to data corruption caused by, for example, channel noise, etc.
- TCP earlier version : handles both signs similarly
- TCP later version : handles these two signs differently
Congestion Policy
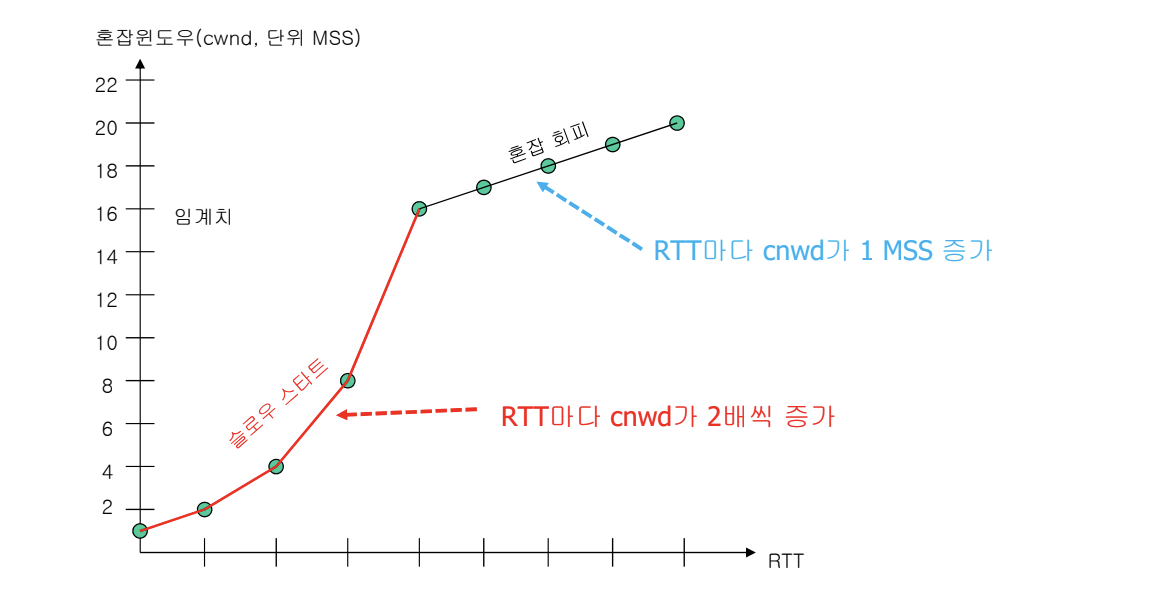
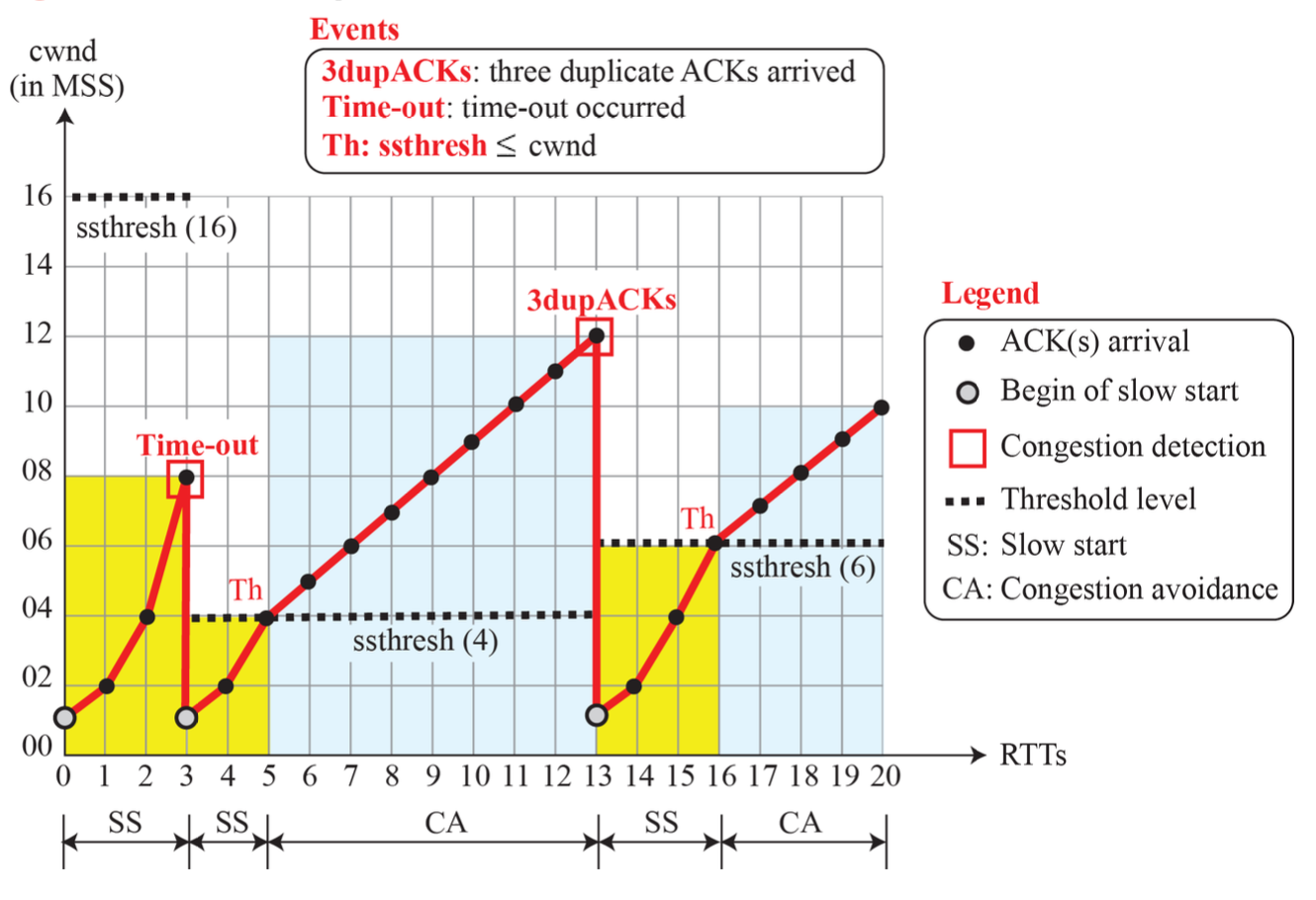
Slow Start algorithm
천천히 속도를 올려보는 방식이다.
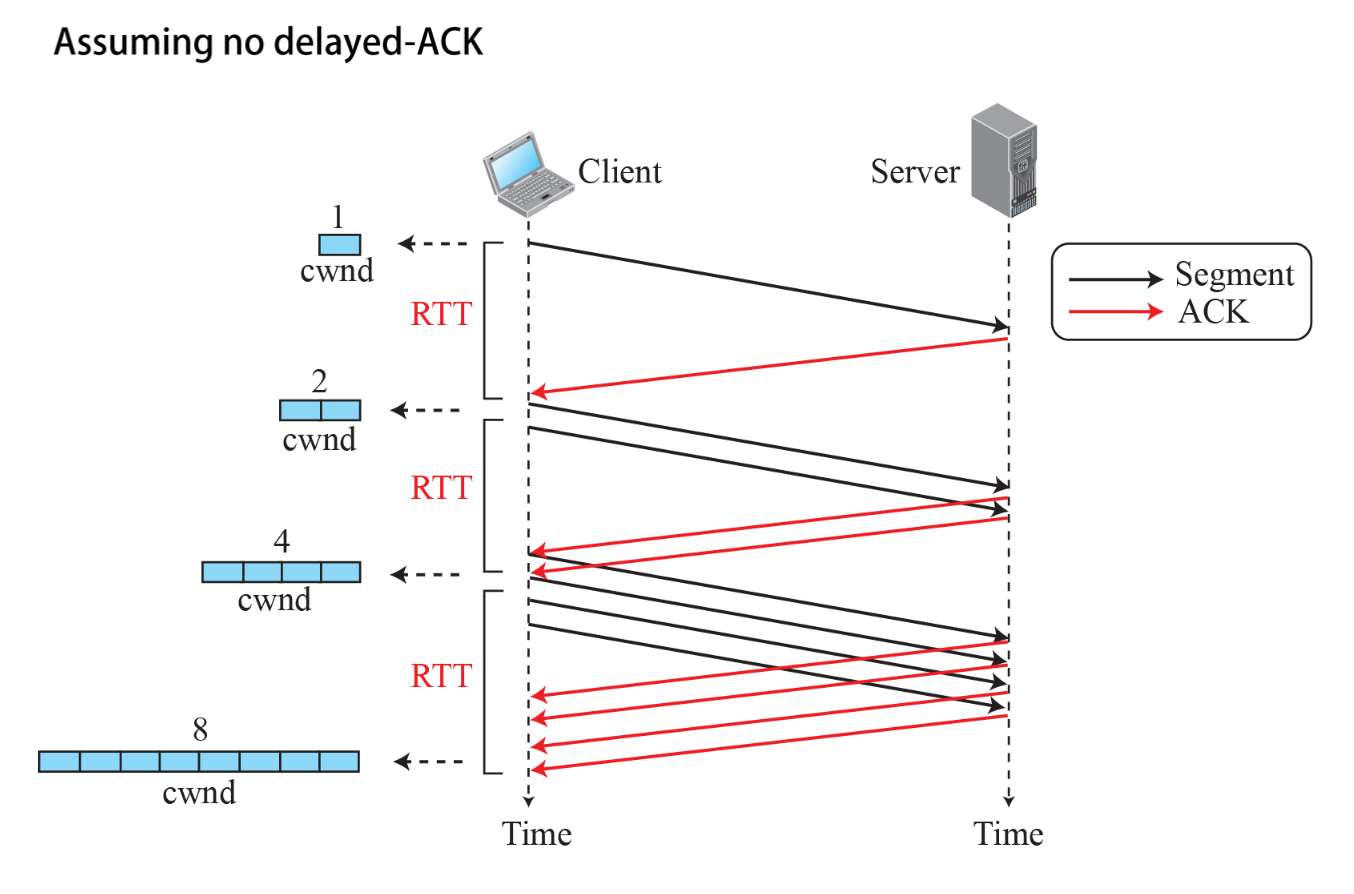
- TCP connection 이 establish 되고나서 처음 cwnd 의 값은 1 MSS로 시작한다. (MSS크기는 sender 와 receiver가 협상)
- 이후 ACK 하나를 받을 때마다 cwnd 의 값을 1 MSS씩 늘려나간다.
- 이 때, rwnd 값은 매우 클 것이므로, 결국 send window의 크기는 초기에는 cwnd 의 값으로 결정된다.
- TCP 연결 초기에는 그림과 같이 매 RTT 마다 cwnd 의 값이 2배로 증가(exponential increase)한다.
- Slow start algorithm은 cwnd 의 값이 slow-start threshold (ssthresh)가 될 때까지 적용된다.
즉, cwnd는 1씩 증가하지만, RTT 입장에서는 2배씩 증가하는 것이다.
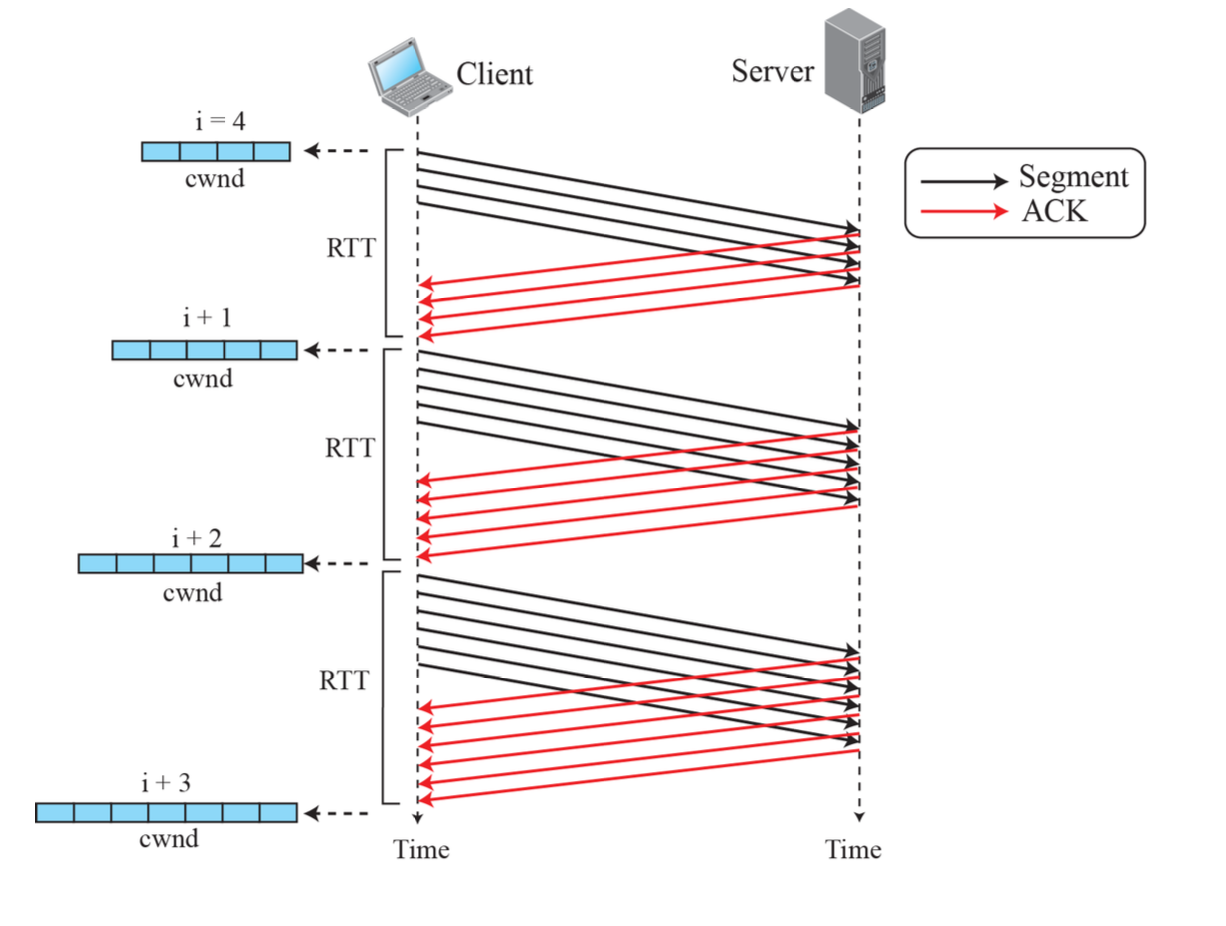
- TCP가 delayed-ACK를 사용한다면 2배로 증가하지 못하고 1.5배로 증가할 것이다.
Congestion Avoidance algorithm
만약 제한없이 cwnd 의 값을 exponentially increase 한다면, 결국 전송속도가 너무 커지고, 이는 network 의 congestion을 유발할 것이다.
이를 미리 회피 (congestion avoidance)하고자, ssthresh(임계치) 이후에는 ACK 하나를 받을 때마다 cwnd 의 값을 (1/ cwnd)만큼 증가시킨다.
이것은 send window 전체가 ACK를 받으면 RTT마다 cwnd의 값을 1 증가시키는 것과 같다. 결과적으로 그림과 같이 매 RTT 마다 cwnd 의 값이 1 증가하게 되며, 시간 함수로 그려보면 cwnd 의 값이 additive increase 하는 선형적(linear)인 증가를 나타낸다.
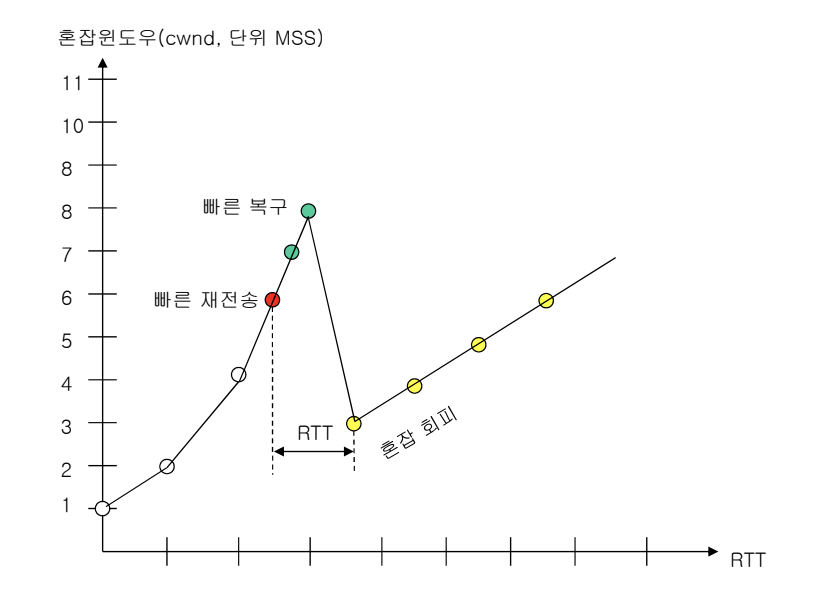
Fast Recovery algorithm
Three duplicate ACKs가 왔을 때, 경미한 혼잡 상황이라 판단하고 fast recovery 구간으로 진입한다. 정상 ACK가 수신되어 오류 복구가 완료되면 Slow Start 단계를 건너뛰고 Congestion Avoidance 단계로 진입한다.
- ssthresh(임계치)를 cwnd의 절반으로 설정한다. (ssthresh = cwnd / 2)
- 손실 Segment 재전송
- cwnd 값을 ssthresh + 3 으로 세팅한다.
- Fast recovery구간에서 duplicate ACKs 가 올 때마다 cwnd 를 1 씩 증가한다. -> exponential increase
- 정상 ACK가 도찾하면 fast recovery 구간을 벗어난다. 이때, cwnd 값을 ssthresh으로 세팅하고, Slow Start 단계를 건너뛰고 Congestion Avoidance 단계로 진입한다.
Classical congestion in TCP
- TCP Tahoe (1988) : Slow Start algorithm (SS) ,Congestion Avoidance algorithm (CA)
- TCP Reno (1990) : SS, CA, Fast Recovery (FR) -> one of the most common versions
- TCP New Reno (1999) : SS, CA, Fast Recovery (modified)
TCP는 운영체제의 커널에 설치되어 있다.
TCP Tahoe
- 인식: Timeout, 3개 중복 ACK를 동일하게 처리
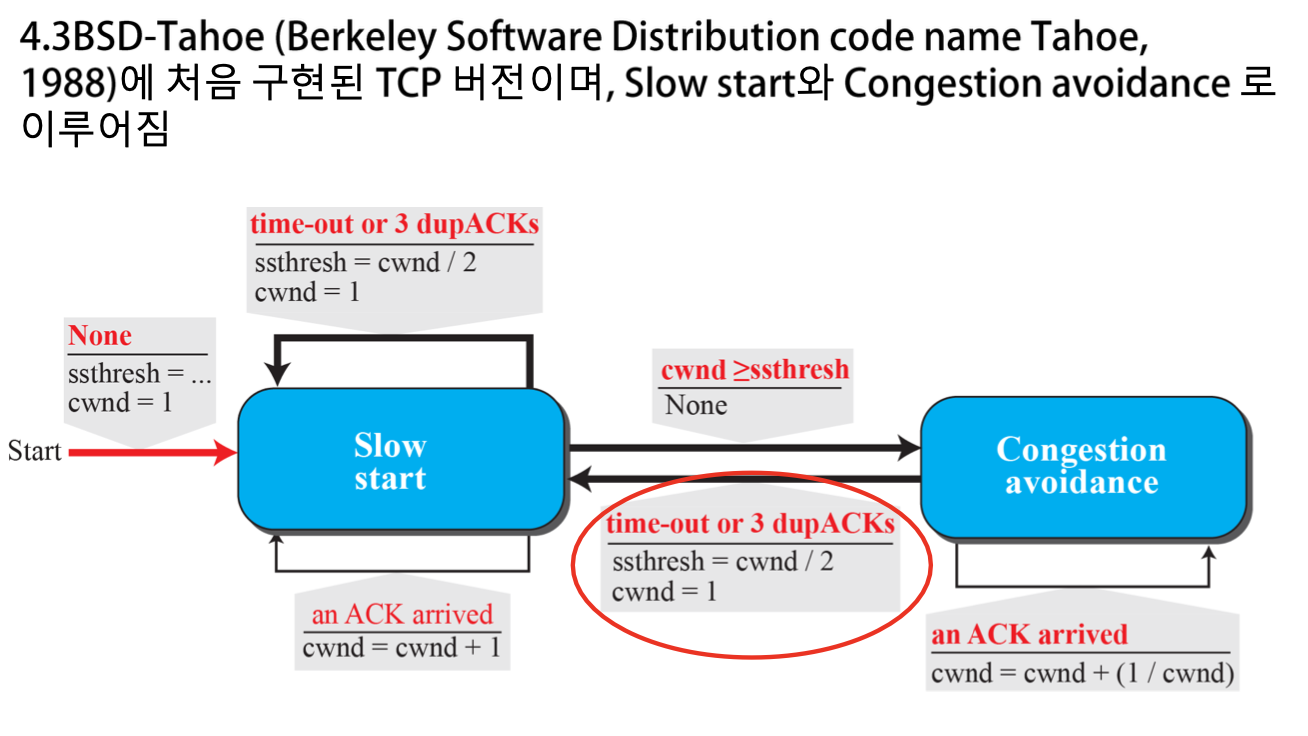
- ssthresh를 현재 cwnd의 절반으로 설정
- Slow Start start
- cwnd가 ssthresh에 다다르면 Congestion Avoidance algorithm 실행
TCP Reno
- 인식: Timeout, 3개 중복 ACK를 다르게 처리
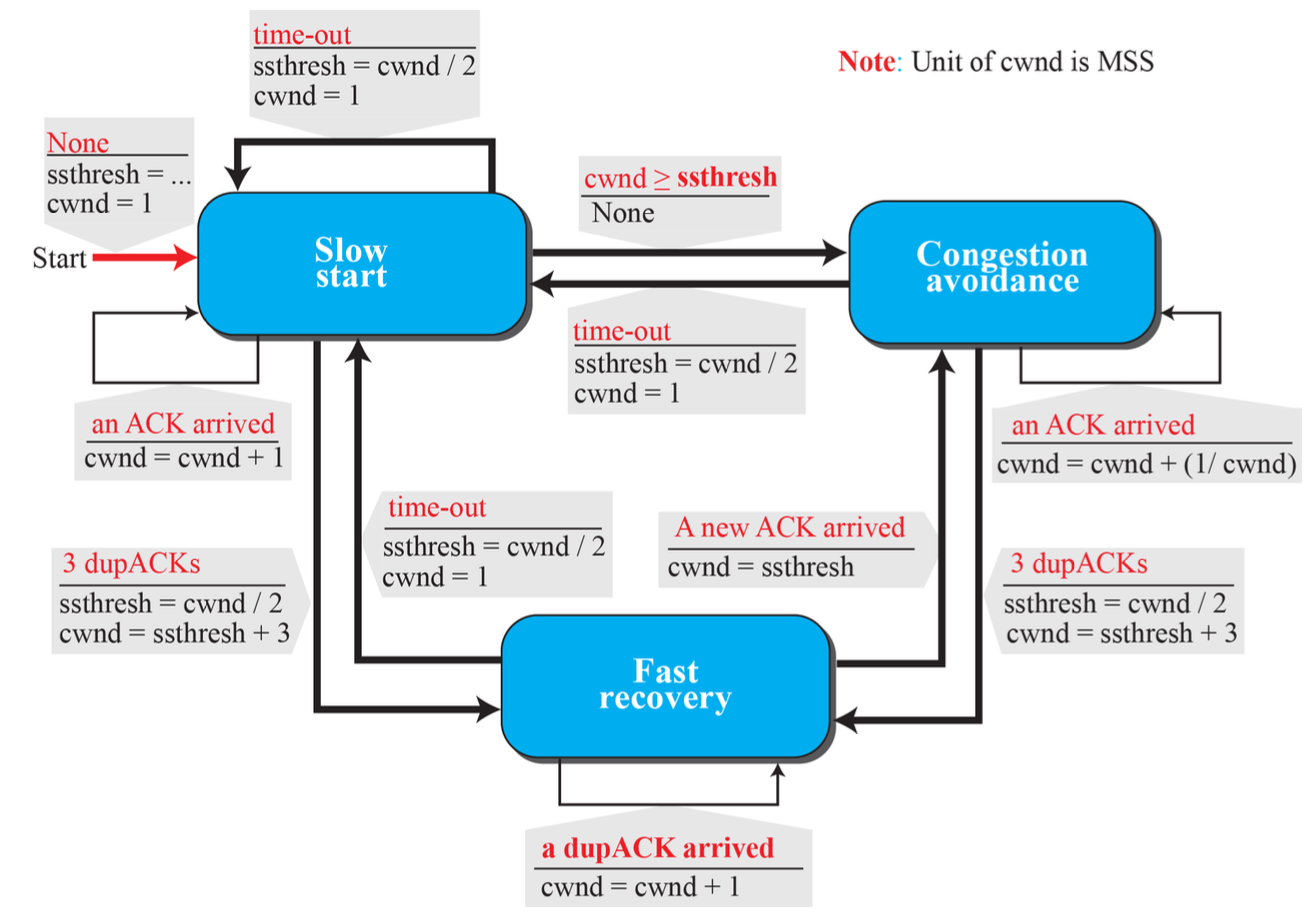
- Timeout 발생 시, TCP Tahoe와 동일하게 처리
- 3개 중복 ACK 발생 시 Fast Recovery algorithm 적용
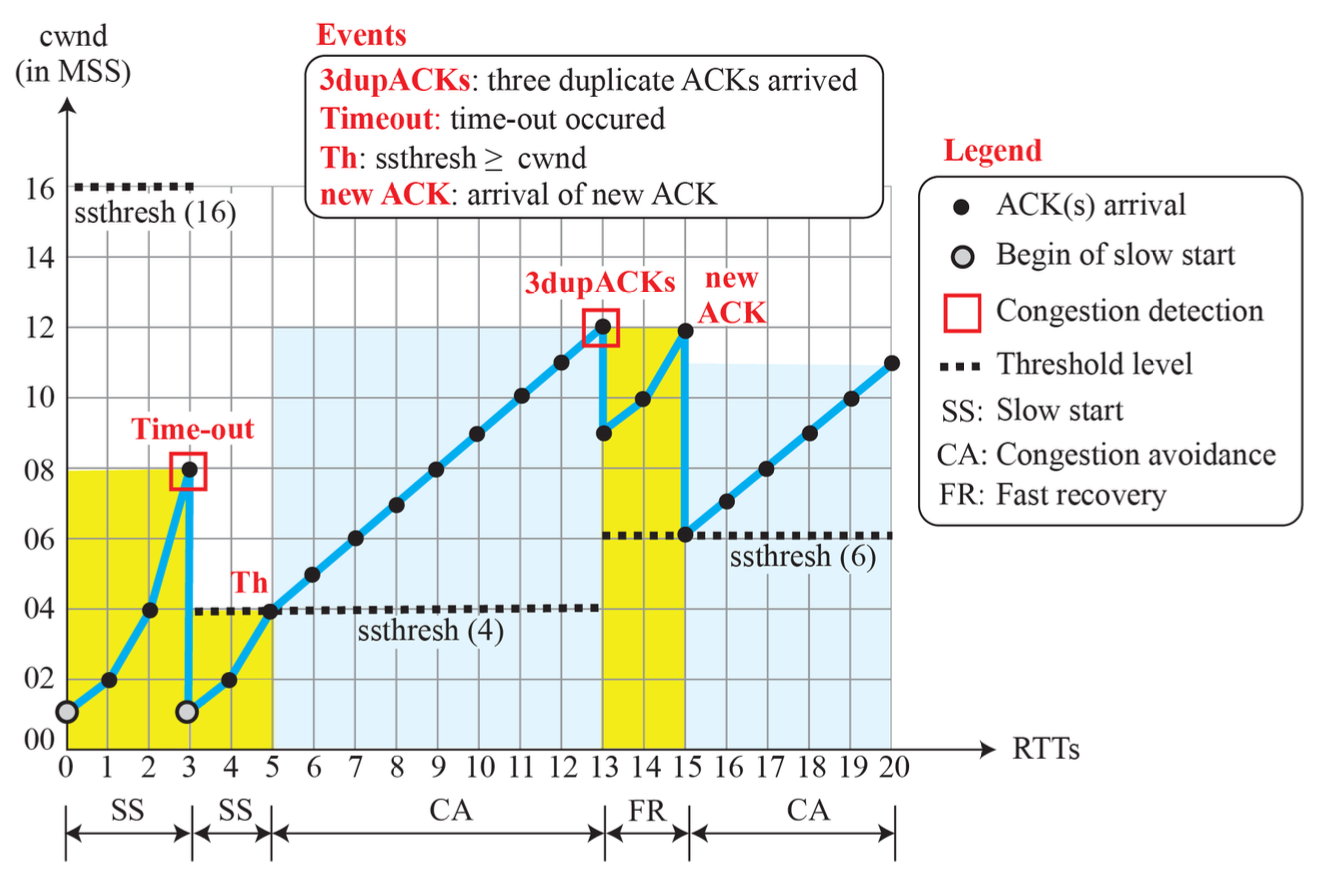
AIMD
TCP Congestion Control은 AIMD(Additive increase, multiplicative decrease) 패턴을 따른다.
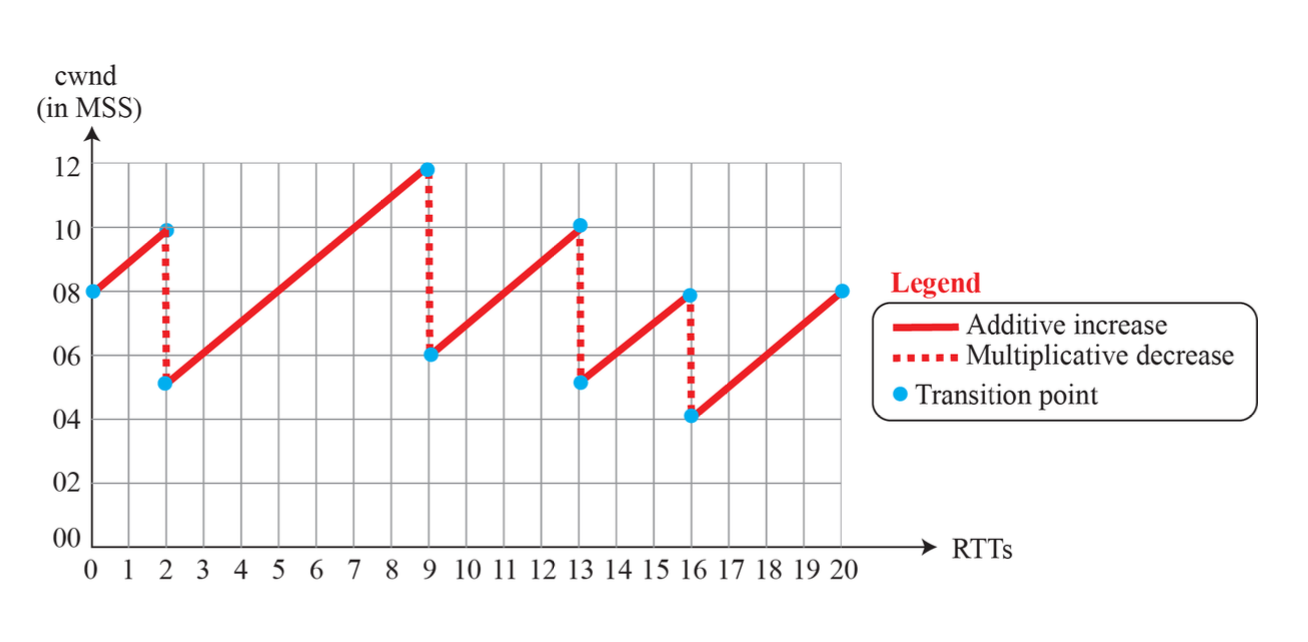
천천히 늘리고, 확 줄이는 방식으로 동작한다.
Throughput
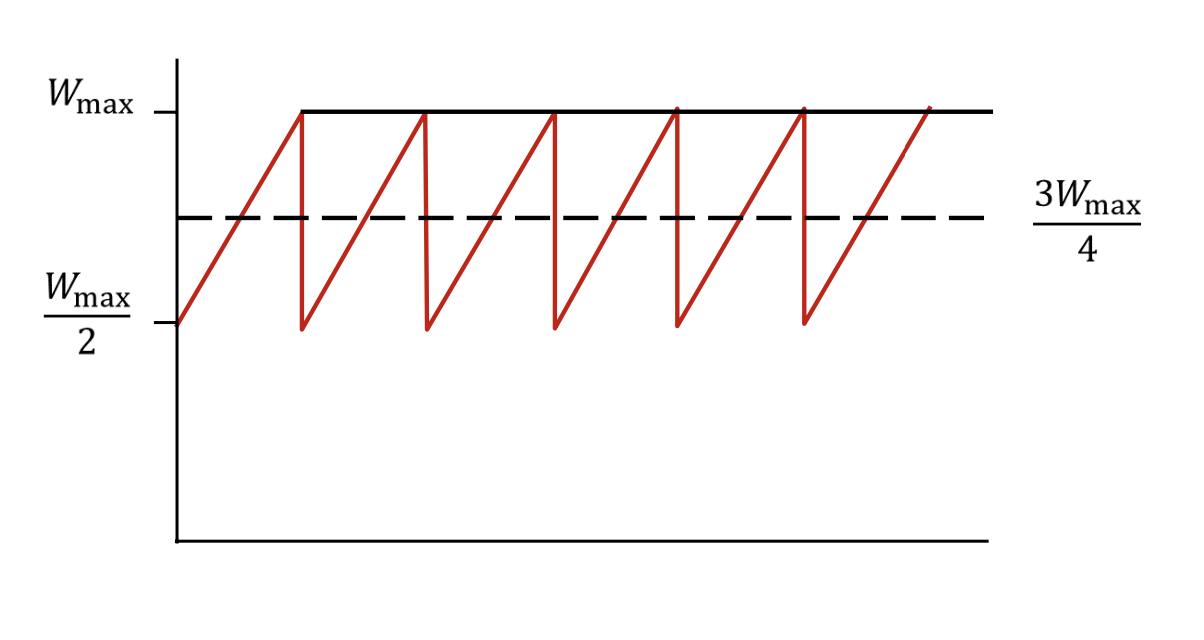
Wmax를 넘어가는 순간, bottle neck에서 segment loss가 발생하여 속도를 절반으로 감소한다. 따라서 troughput의 평균값은 (3/4) * Wmax가 된다.
Recent Congestion control
- CTCP(Microsoft)
- TCP CUBIC(Linux)
- TCP BBR(Google)
TCP CUBIC
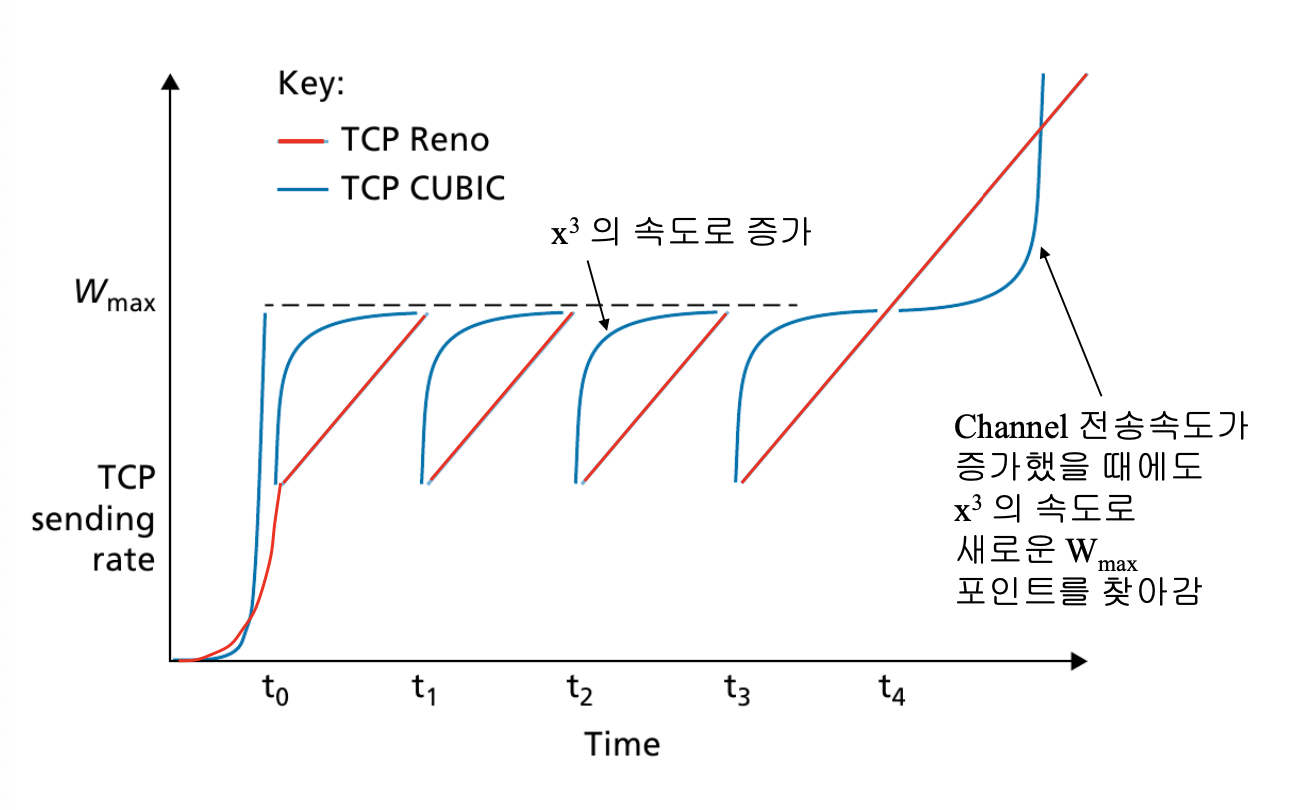
CUBIC은 상승할때, 지수함수의 꼴로 증가시킨다.
AIMD Fairness
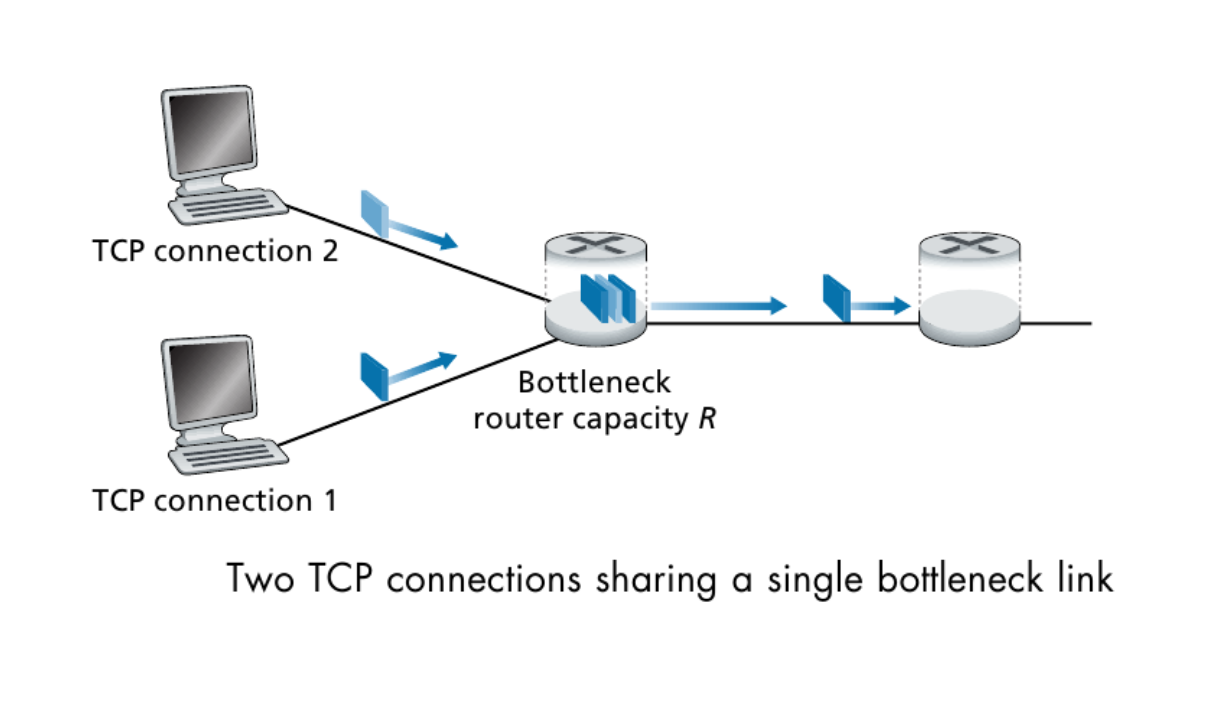
AIMD에 의해 두 TCP connection은 고르게 통신한다.
Fairness Issue
- Multimedia apps
- Using multiple parallel TCP connections
인터넷 프로토콜 IP
비연결형 서비스
- 연결 설정 과정 없음
IP간의 연결 설정이 전혀 없으며, 각 Datagram이 독립적으로 전달된다.
최선형 서비스
- 전송속도, 지연시간 보장 없음
- 오류 복구 서비스 미지원
서브넷 독립적 서비스
- 다양한 서브넷을 통해 IP데이터그램 전송 가능
- 서브넷 주소와 독립적인 IP주소 사용
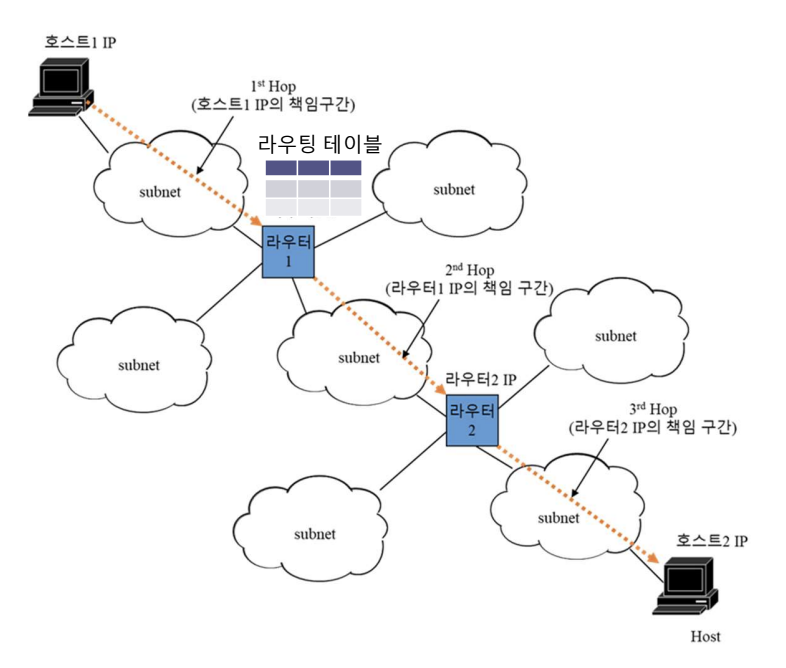
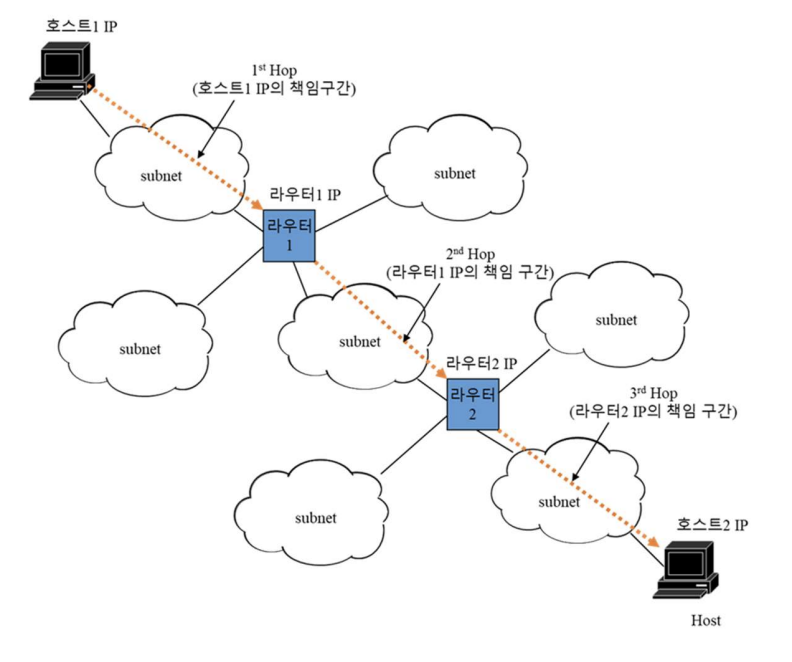
Hop-By-Hop 통신
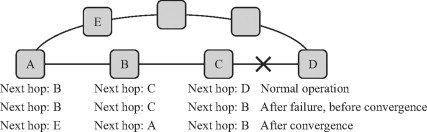
Hop이란 인터넷 연결의 구간을 의미한다. 예를 들어서 Host에서 라우타 사이의 경로, 라우터와 라우터 사이의 경로가 하나의 Hop에 해당된다. Ip는 Next Hop까지의 전달만을 책임진다. Next hop을 전달하는 라우팅테이블이 결정한다.
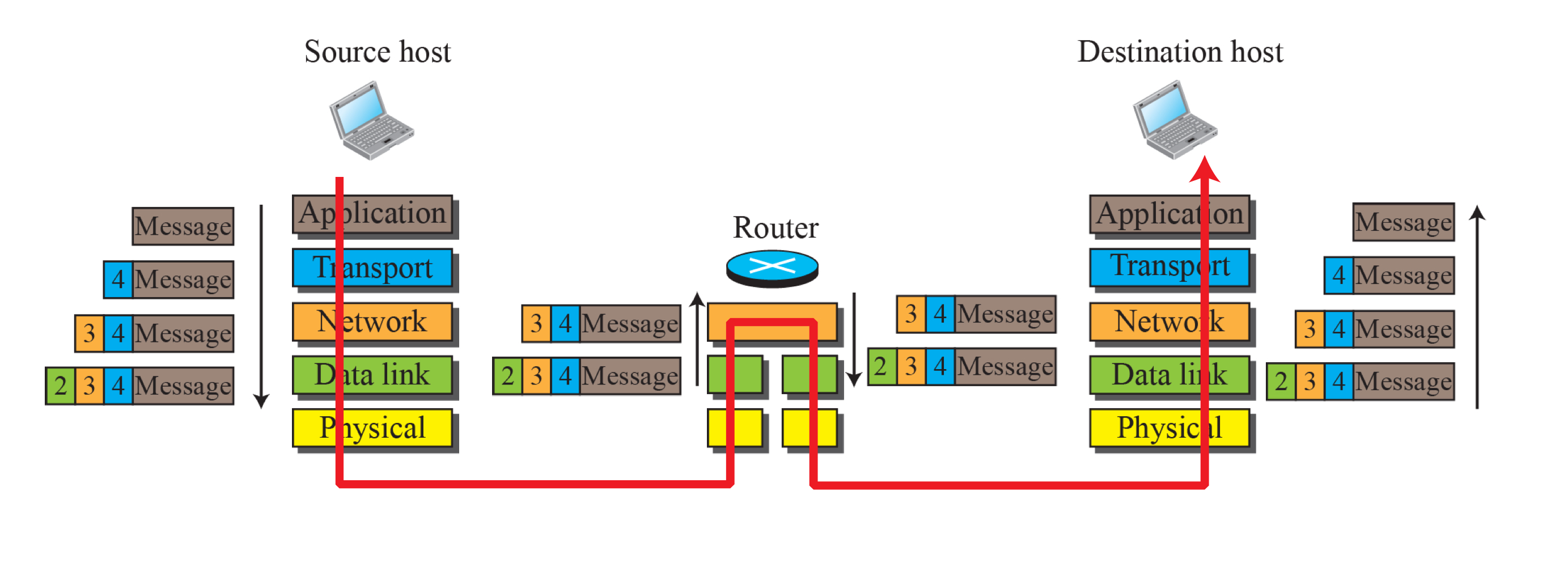
계층 구조
TCP/IP계층 모델에서 3계층에 해당되는 네트워크 계층이다. 데이터링크 계층의 여러 프로토콜과 통신할 수 있다.
IP Datagram
- Header + Data(Segment, Datagram)
IP의 Header는 필수 값(20Byte)와 옵션(40Byte)을 포함하기에 가변 길이를 가진다.
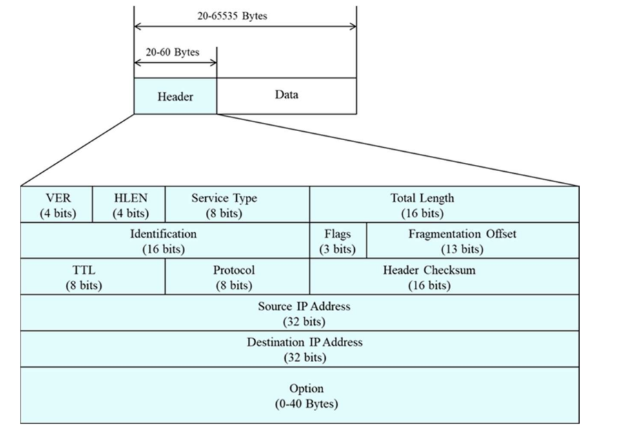
- Ver: IPv4
- HLEN: 헤더의 길이, WORD(4바이트) 단위로 나누어서 표현
- Service Type: Data의 속성을 정의하는 필드
- Total Length: Header + Data의 총 길이
- Identification, Flags, Fragmentation offset: IP datagram의 크기가 커서 서브넷을 통과할 수 없을 때, fragmentation에 관여하는 필드
- TTL: 최대 겨쳐갈 수 있는 Hop의 수.
- Protocol: 상위 프로토콜 Data의 종류(TCP, UDP)
- Header Checksum: 오류 검출
- Source, Destination IP Address: 출발지, 도착지 IP 주소
Service type과 Protocol의 차이점은?
IP Datagram Encapsulation
Ethernet 유선 LAN의 경우
MAC + TYPE + Ethernet data{ IP Header(Protocol field = TCP) + IP Data(TCP Segment)} + Frame
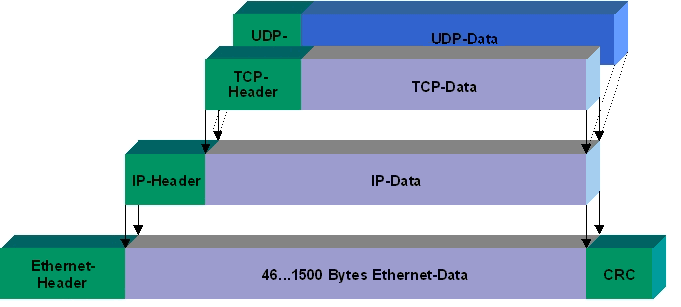
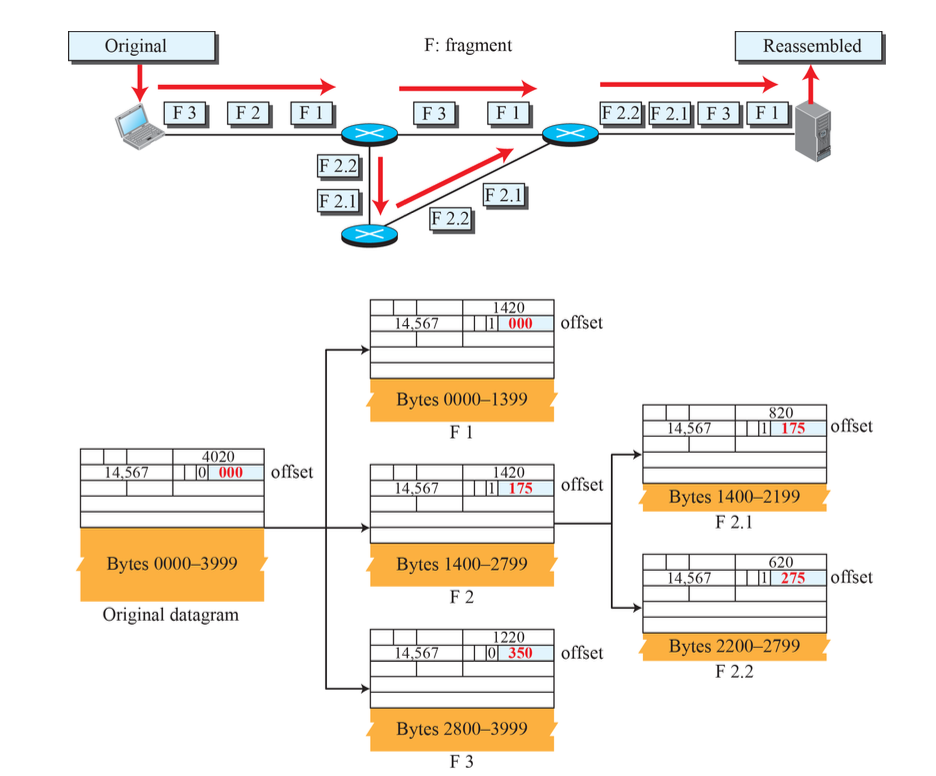
IP Datagram Fragmentation
TCP에서 MSS가 필요한 이유는 MTU가 네트워크마다 크기가 다르기 때문에 적용한다. 서브넷에 따라 MTU가 다르기 때문에 Fragmentation이 필요하다. 서브넷을 통과한 후에 또 Fragmentation 해야 될 수도 있기 때문에 최종 목적지에서 재조립된다.
각 Header를 자를 수는 없으니, Data를 잘라서 Fragmentation을 진행한다.
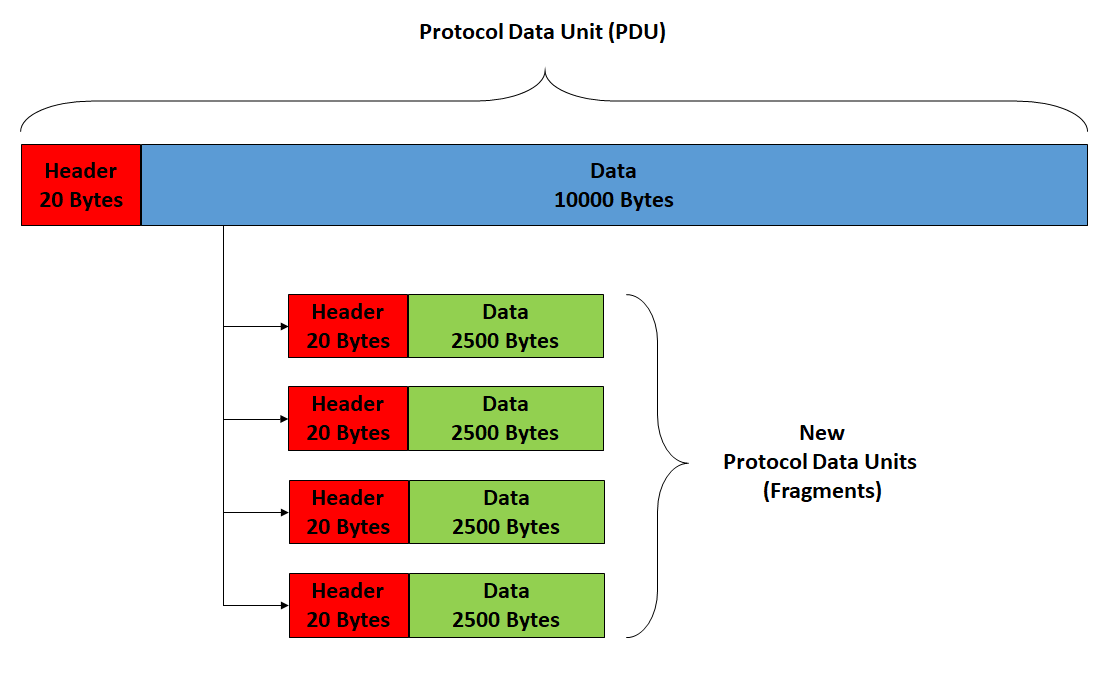
각 Fragmentation 마다 header 정보가 붙게 된다. 원본 Header에서 필드를 일부 수정해서 덧붙인다.
- Identification: 동일
- Flags: 마지막 Datagram은 0, 나머지는 1
- Fragmentation offset: 원래 Data 필드에서의 상대적 위치(바이트 / 8) 표시
0 ~ 1399, 1400~2799, 2800~일 경우, offset은 각각 0, 175, 350이 된다.
IP 주소: 구조와 할당
인터넷 구성과 주소 부여체계
- Internet: 네트워크를 라우터로 연결
- Subnet: 라우터로 연결되 서브넷은 유일한 ID를 가짐
- Host: 호스트는 서브넷에서 유일한 ID를 가짐
IP주소
인터넷에서 통신 장치를 유일하게 식별한다. IP주소는 Network ID + Host ID으로 구성한다. 여기서 Host ID가 0일 경우, 이를 네트워크 주소라 한다.
네트워크 주소 기반으로 라우팅을 활용하여 라우터에서 Network ID 기반으로 라우팅하게 된다.
왜 Network ID + Host ID로 나누었을까? 이는 분류의 편리성 때문이다. Host ID만으로 구분한다면, Host만으로 찾아가야하 라우팅 테이블이 굉장히 커지게 된다. 이 때문에 라우팅 테이블 탐색 시간의 오버헤드가 크다
아래 그림에서 네트워크의 수는?

라우터에 연결된 호스트를 이루는 네트워크 3개와 라우터 사이를 P2P로 이어주는 네트워크 3개가 이루어져 있다. 따라서 Network ID는 6개가 필요하다.
IP 주소 구조
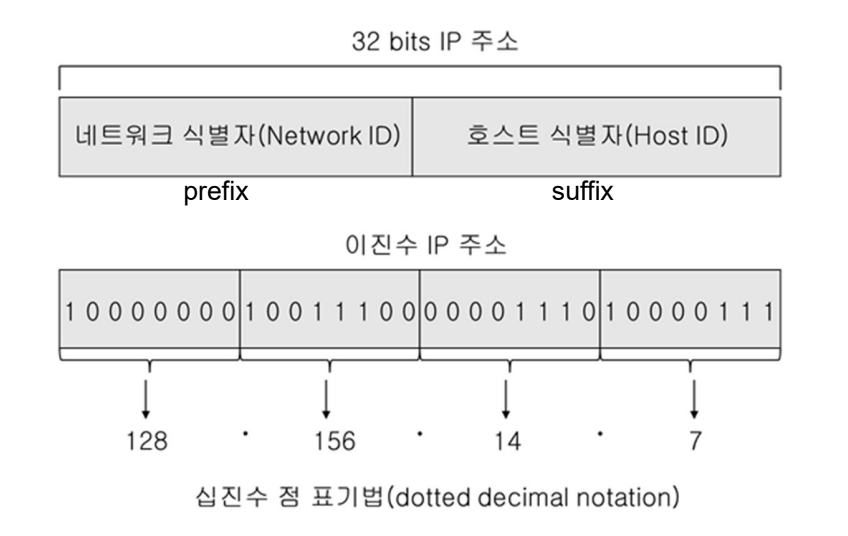
IP주소는 Network ID와 host ID로 구성된다. DDN IP 주소는 8비트씩 끊어서 십진수로 표현한 것을 의미한다.
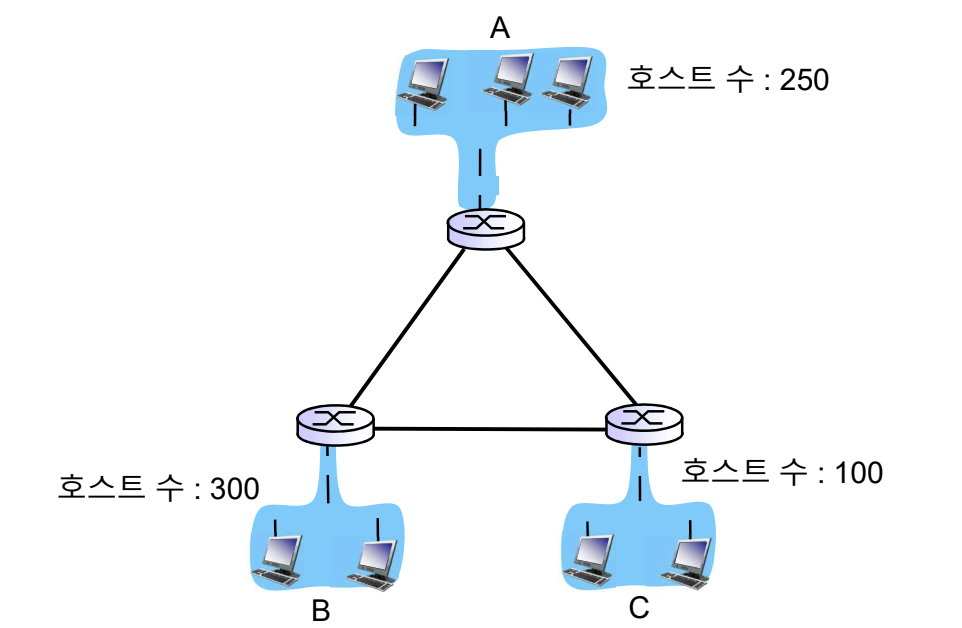
호스트의 개수가 250개이므로 최소 256개가 필요하다.
IP 구조 주소 활용 방식
클래스 주소(Classful Addressing): Network Id와 Host Id가 고정되어 있다.
비클래스 주소(Classless Addressing): Network Id의 크기가 가변적이다.
클래스 IP 주소(Classful IP Address)
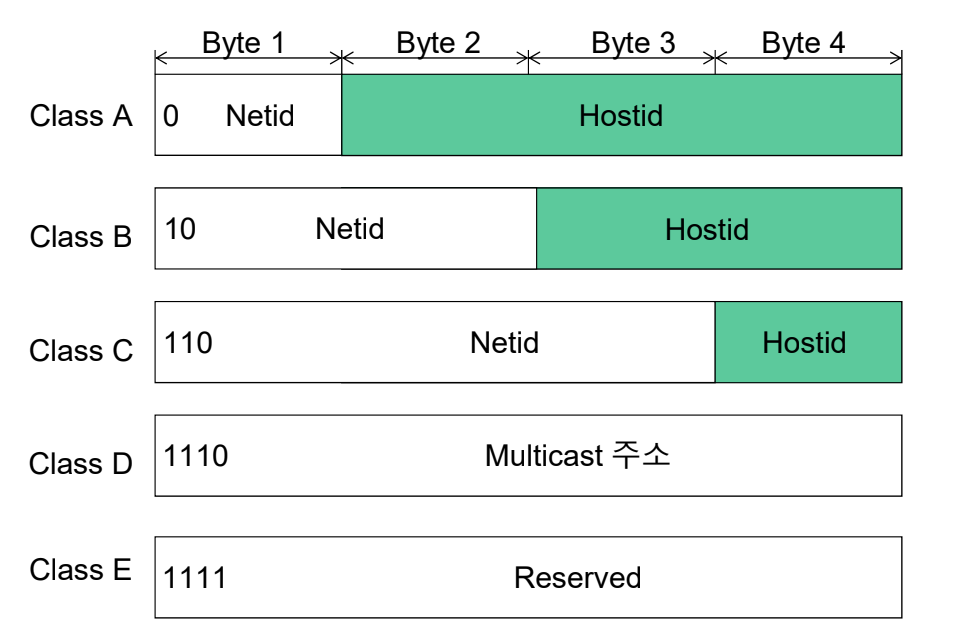
- Class A: Network Id는 8비트이고 첫 비트는 0으로 고정한다. 또한 특수 주소 2개도 존재한다. 따라서 network Id는 126개가 사용 가능하다. 장점으로는 Host Id를 많이 사용할 수 있다.
- Class B: Network Id는 16비트이고, 첫 비트는 10로 고정한다. 또한 특수 주소 2개도 존재한다. 따라서 network Id는 (216 - 2)개가 사용 가능하다. Host Id는 2^14 - 2개 사용할 수 있다.
- Class C:Network Id는 24비트이고, 첫 비트는 110으로 고정한다. 또한 특수 주소 2개도 존재한다. 따라서 network Id는 (2124 - 2)개가 사용 가능하다. Host Id는 2^14 - 2개 사용할 수 있다.
- Class D: 1110으로 구분하고 Multicast 주소
- Class E: Reserved
사설 IP주소는 여전히 Classful IP Address로 사용한다,
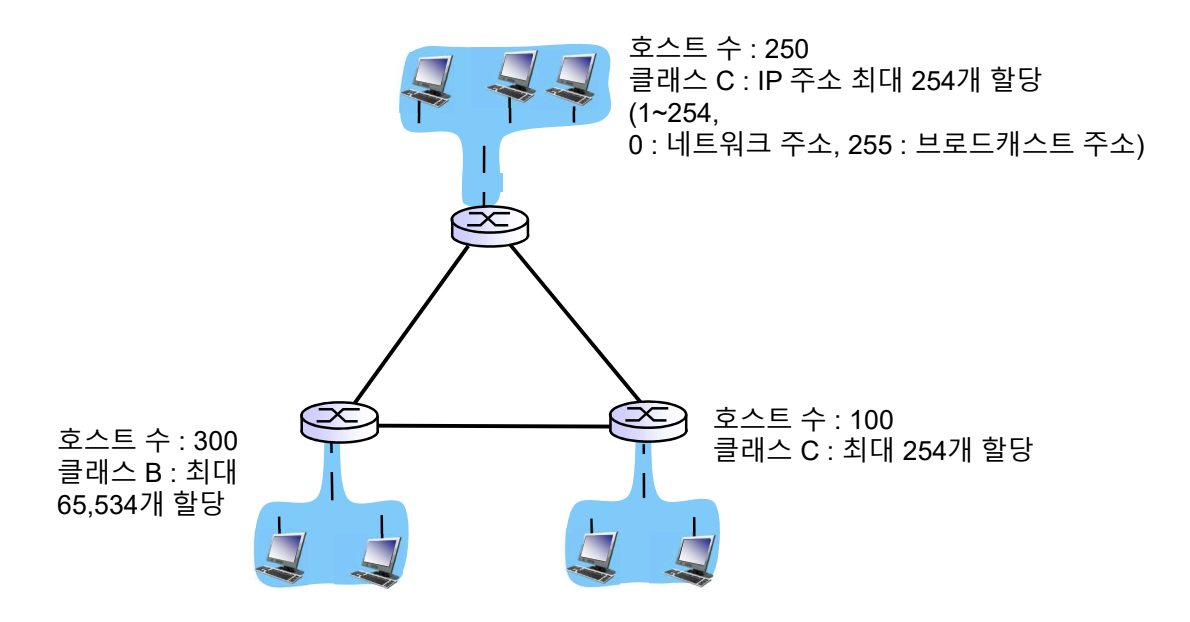
위와 같은 낭비되는 ip주소들 때문에 현재는 Classless IP 주소를 사용한다.
비클래스 IP 주소(Classless IP Address)
CIDR
클래스가 존재하지 않는 도메인간 라우팅 기법을 의미한다.
서브넷 마스크(Subnet Mask)
비클래스 IP 주소에서는 Network IP가 몇비트까지인지 확인할 방법이 없다. 따라서 IP 주소에서 Network ID의 길이를 표시하는 서브넷 마스크가 필요하다. 이를 통해 네트워크의 크기(Host 개수)를 결정한다.
표기법
- 프리픽스 표기법: /prefix_size 표시
- (prefix) 서브넷마스크: /24
- 이진 표기법: 프리픽스 비트를 모두 1로 표시
- 11111111 10000~
- DDN 표기법: 이진 서브넷 마스크를 DDN으로 표시
- 255.255.255.0
IP Special Addresses
- 0.0.0.0/32(this-host address): host가 IP datagram을 보내야하는데, 자신의 주소를 모를 때 sender address로 사용
- 255.255.255.255/32(limited-broadcast address): 하나의 라우터가 관장하는 network 안에서 broadcast
- 127.0.0.0/8(loopback address): 데이터 전송 시에 이 주소로 사용하면 데이터가 컴퓨터를 떠나지 않는다. 통신 프로그램을 개발할 때 사용
- Private addresses: 내부 network 안에서만 사용되는 고유한 사설 IP주소이며, 외부 인터넷에서 공인 IP 주소로 사용 불가능
- Multicast Address: 224.0.0.0/4 블록의 주소이며, 멀티캐스트용으로 사용됨
IP 종류
-
Unicast Address (유니캐스트 주소): 유니캐스트 주소는 단일 송신자와 단일 수신자 간의 통신을 위한 주소다. 네트워크에서 특정 호스트를 식별하고 특정 호스트에게 데이터를 전송하기 위해 사용된다. 대부분의 IP 주소가 유니캐스트 주소에 속합니다.
-
Broadcast Address (브로드캐스트 주소): 브로드캐스트 주소는 같은 네트워크 상의 모든 호스트에게 메시지를 보내기 위한 주소이다. IPv4에서는 특정 주소 (예: 모든 비트가 1로 설정된 주소)가 브로드캐스트 주소로 사용된다. 그러나 IPv6에서는 브로드캐스트 개념이 없으며, 다른 메커니즘을 통해 멀티캐스트를 사용한다.
-
Anycast Address (에니캐스트 주소): Anycast Address는 여러 호스트 중 하나를 식별하기 위한 주소로, 동일한 주소를 갖는 여러 호스트 중 가장 가까운 호스트에게 패킷이 전송된다. 에니캐스트는 주로 특정 서비스를 제공하는 여러 서버 간의 로드 밸런싱이나 회복성을 향상시키기 위해 사용된다.
Multicast Address (멀티캐스트 주소): 멀티캐스트 주소는 그룹 내 또는 다른 네트워크의 여러 호스트에게 동시에 데이터를 전송하기 위한 주소다. 특정 그룹에 속한 호스트들만 해당 데이터를 수신한다. 멀티캐스트는 효율적인 데이터 전송을 위해 사용되며, 주로 IPTV, 온라인 게임, 비디오 스트리밍 등에서 활용됩니다.
멀티캐스트 주소 범위는 IPv4에서는 224.0.0.0부터 239.255.255.255까지의 주소 범위이며, IPv6에서는 ff00::/8의 주소 범위를 사용한다.
IP 주소 할당
NIC 단위의 IP 주소 할당
NIC가 네트워크 할당의 단위가 된다.
- 라우터: 3개의 NIC로 네트워크 연결
- 라우터의 IP 주소: NIC 개수만큼 주소 할당
네트워크 3개면 네트워크 ID가 다른 NIC가 존재하게 된다.
Network-layer Performance
Delay
Source에서 Destination까지의 데이터 delay.
- Transmission delay(physical layer): bit rate에 의한 delay. bit rate를 높이면 줄여듬.
- Propagation delay(physical layer): 물리적으로 전기 신호에 의해 생기는 delay.
- Processing delay(all layers): 헤더를 분석하고 라우트 정하는 delay.
- Queuing delay(network layer): 네트워크 계층에서 일시적으로 라우터들이 버퍼에 쌓이는 delay.
Throughput
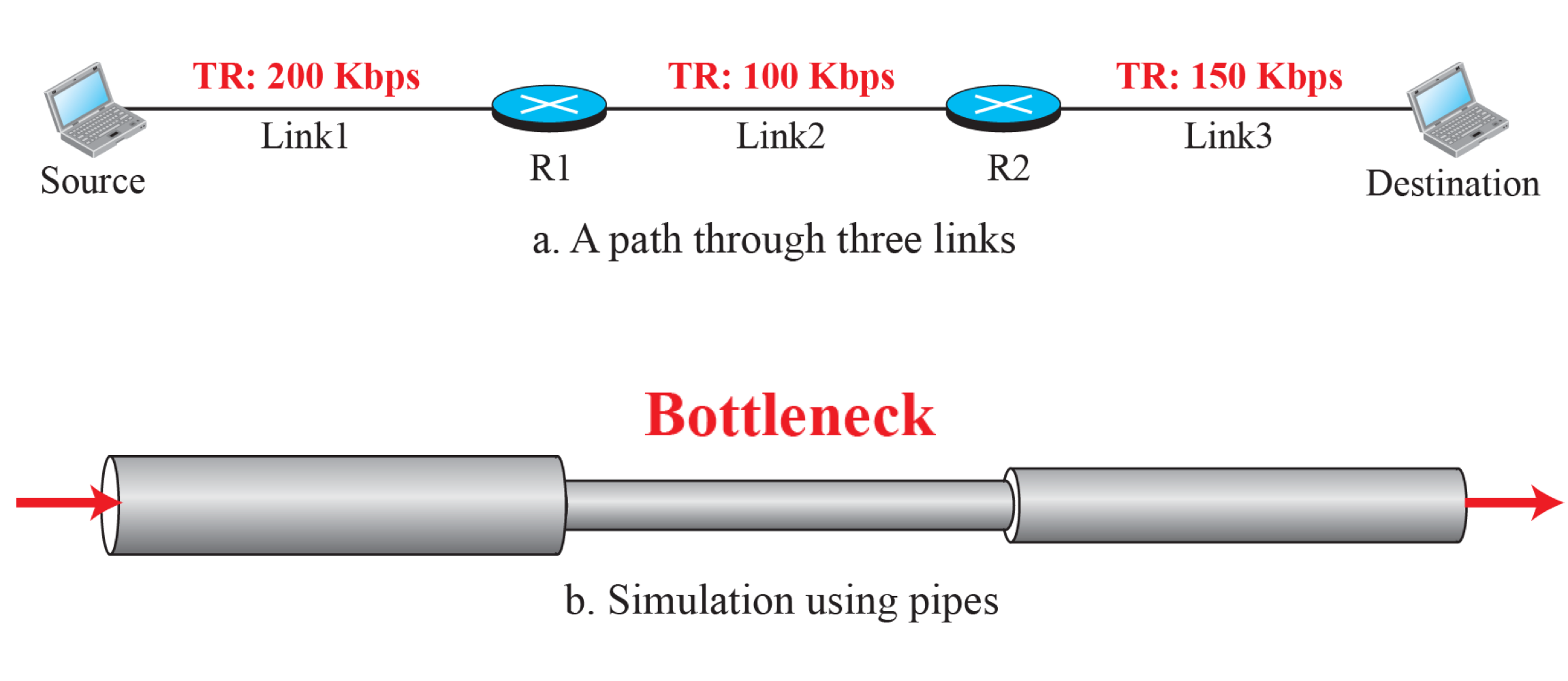
Throughput은 Bottleneck이 결정한다.
Packet loss
- Route Buffer에 의한 Packet loss
Packet 흐름의 양을 제어해야 한다.
- Bit Error에 의한 Packet loss
Packet 흐름을 높여야 한다.
IPv4 주소 부족
-
근본적인 해결: IPv6 주소체계 사용
IPv6를 적용하려면, 모든 라우터를 바꿔야한다는 문제점 존재
-
부분적인 해결: DHCP(동적 주소 할당), NAT(Network Address Translation)
DHCP(Dynamic Host Configuration Protocol)
라우팅에서 Hop-by-Hop으로 작동하기 위해서 Network ID를 식별할 수 있는 Subnet Mask가 필요하다.
라우터는 라우팅 테이블을 자료구조를 가지고 있는데, 호스트는 라우팅 테이블 정보가 존재하지 않는다. 따라서 다른 네트워크로 보내기 위해 어떤 라우터로 보내야하는지에 대한 구성정보를 알아야한다.
이러한 구성 정보를 자동으로 설정하게 하는 것이 DHCP 프로토콜이다.
DHCP란?
DHCP 서버에 의해 호스트 구성 정보를 동적(자동)으로 할당한다.
디폴트 게이트웨이란?
장점
- 사용자 편의성
- IP 주소 절약(필요할 때 적절한 IP 부여, 동시 접속자수만큼 할당)
호스트 구성 정보
- IP 주소: 호스트의 IP 주소
- 서브넷 마스크: 네트워크 ID 필드 크기, 네트워크 주소 구분을 위한 필수 정보
- 디폴트 게이트웨이 주소: 자신의 네트워크에 연결된 라우터의 주소, 목적지 주소가 동일 네트워크에 존재하지 않을 때 IP Datagram을 전달할 다음 Hop 주소
- Local DNS 서버 주소: Local DNS 서버의 주소, DNS query를 전달할 서버
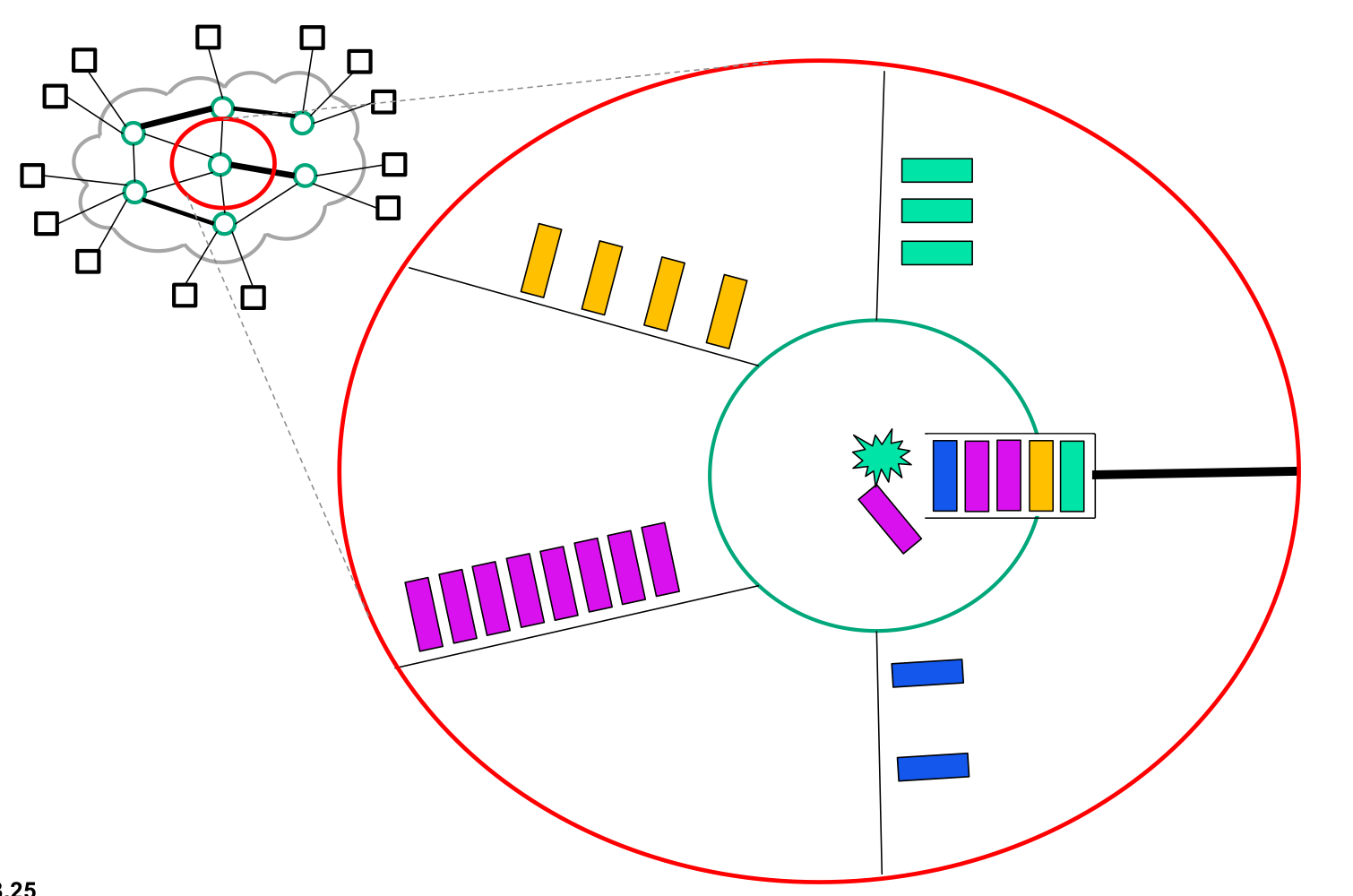
DHCP는 이중화,삼중화 필수이다. 단일 장애 포인트가 되므로 DHCP가 다운되면 고정 IP제외하고 나머지는 작동하지 않는다.
DHCP Message Format
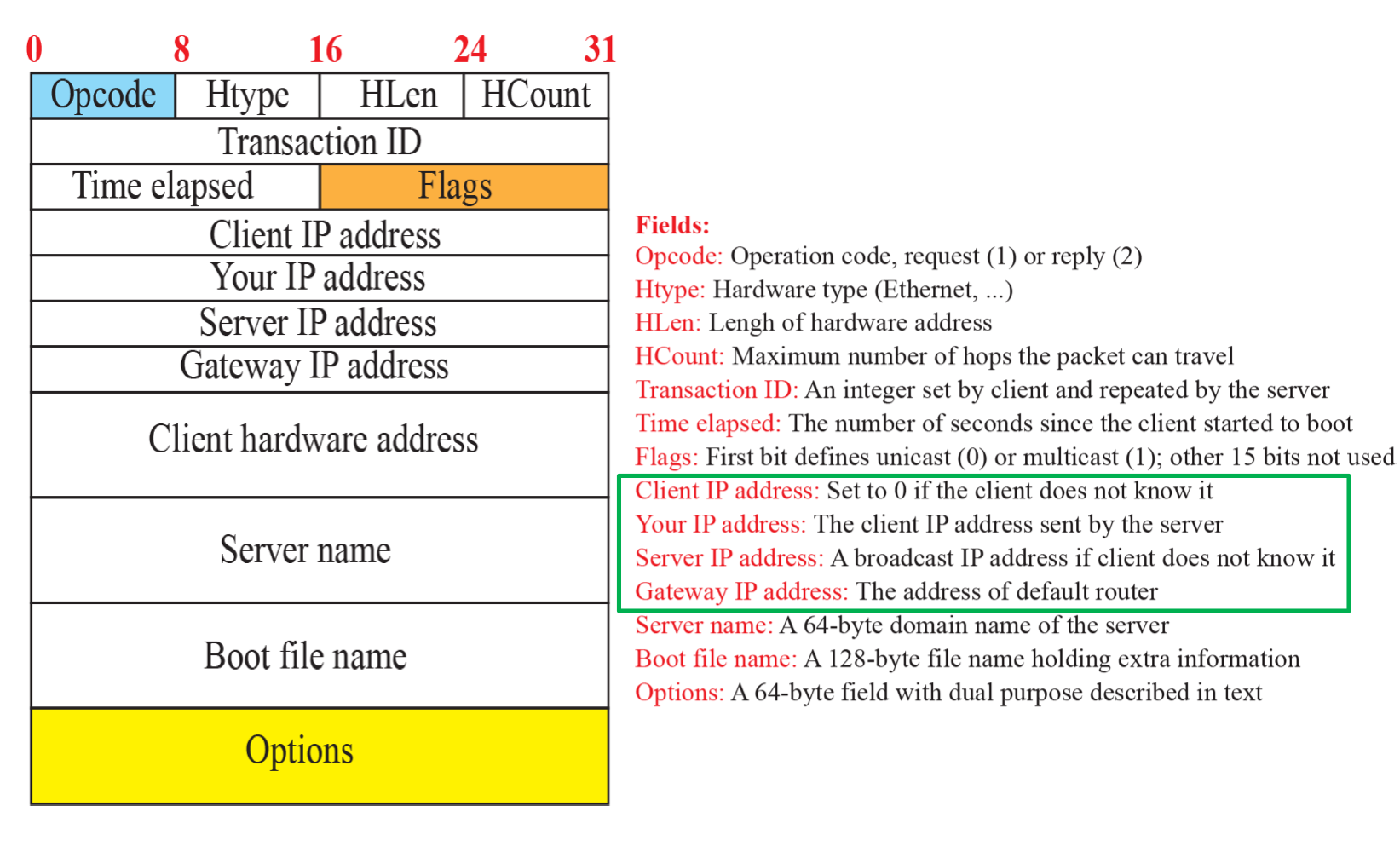
동작 절차
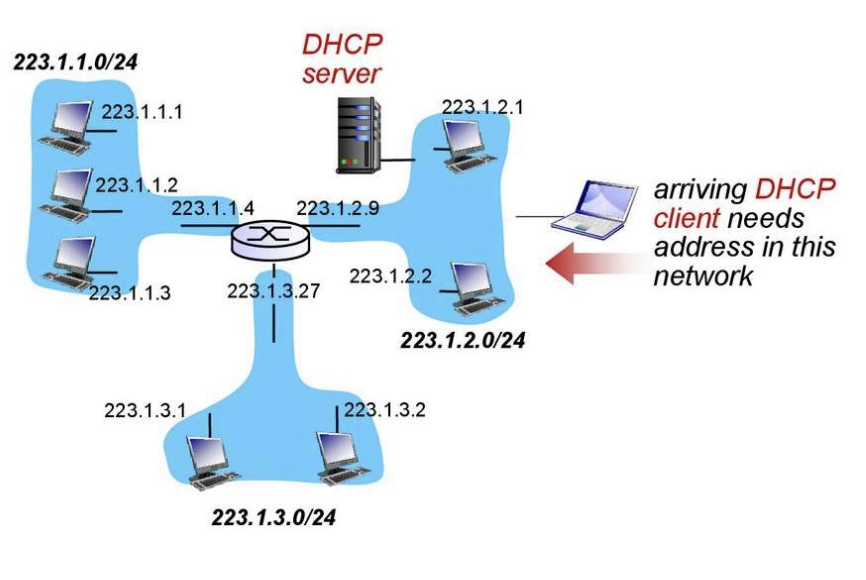
DHCP와 통신하기 위해 목적지, 출발지IP가 필요하다. 자신의 IP도 모르는데, 어떤 방식으로 여러 DHCP 중 하나로 구성 정보를 할당 받을 수 있을까?
Operation Format
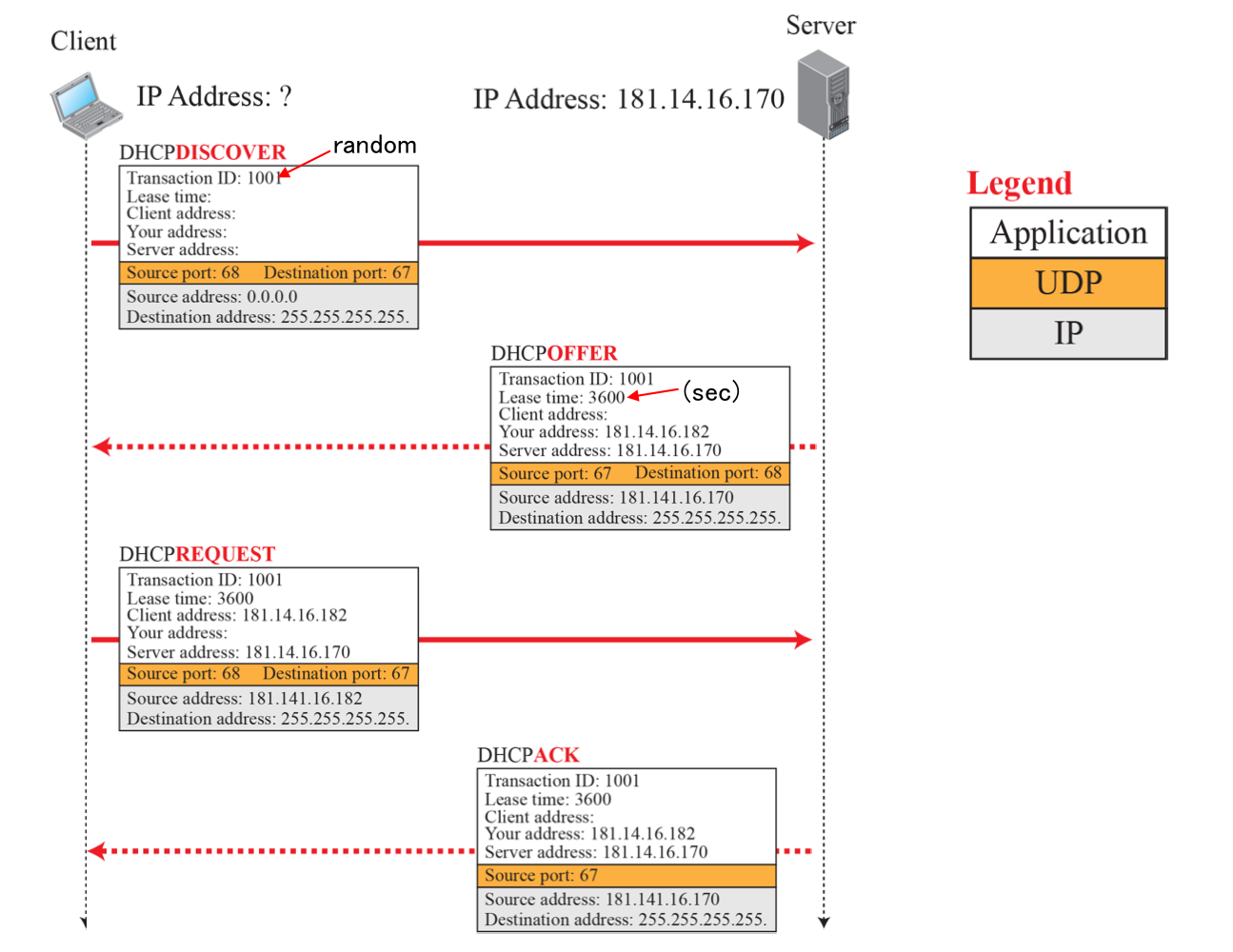
- DHCP discover: Source IP는 0으로 표시하고, Dest IP를 255.255.255.255로 표시한다. 이 주소는 broadcast 주소이다. 메시지 종류와 your address(할당할 주소)은 모르기 때문에 0.0.0.0으로 표시하고 여러 통신 구분을 위한 tranaction ID로 구분한다.
Broadcast ID란 IP에서 host ID 부분이 전부 1인 주소이다. 현재 클라이언트는 Network ID, Host ID를 모르기 때문에, 모든 비트가 전부 1인 주소를 자신이 소속된 broadcast 주소를 뜻한다.
-
DHCP offer: DHCP는 할당 여부를 판다하고, 승인되면 offer 메시지를 전송한다. Source IP에 DHCP 주소와 Dest IP는 여전히 broadcast 주소이다. your address(할당할 주소)를 작성하여 클라이언트에 IP를 할당한다. 어느 DHCP로부터 왔는지를 나타내는 DHCP Server ID를 작성한다(대부분 IP를 사용).할당하는 IP 주소의 TTL까지 전송한다.
-
DHCP request: 클라이언트는 여러 DHCP로부터 응답을 받을 수 있기 때문에, 그 중에 하나를 선택하여 선택된 DHCP서버에게 Request 메시지를 전송한다. Src IP는 아직 확정이 안되었기 때문에 0으로 표시하고, Dest IP는 여전히 Broadcast 주소를 사용한다.
여전히 dest IP를 broadcast주소로 사용하는 이유는? 모든 DHCP 서버에게 전송하여 나머지 DHC서버들이 클라이언트가 IP주소를 사용하지 않는 것을 알려주기 위함이다. 이를 통해 다시 해당 IP 주소를 IP 주소 풀에 그대로 유지한다.
-
DHCP ACK: Request에 대한 응답으로 ACK를 전송한다.
Relay Agent
Broadcast를 하게되면, 같은 네트워크에 연결된 DHCP에게만 전달된다. 그러면 네트워크 내에 DHCP가 존재하지 않는다면 어떻게 처리해야 할까?
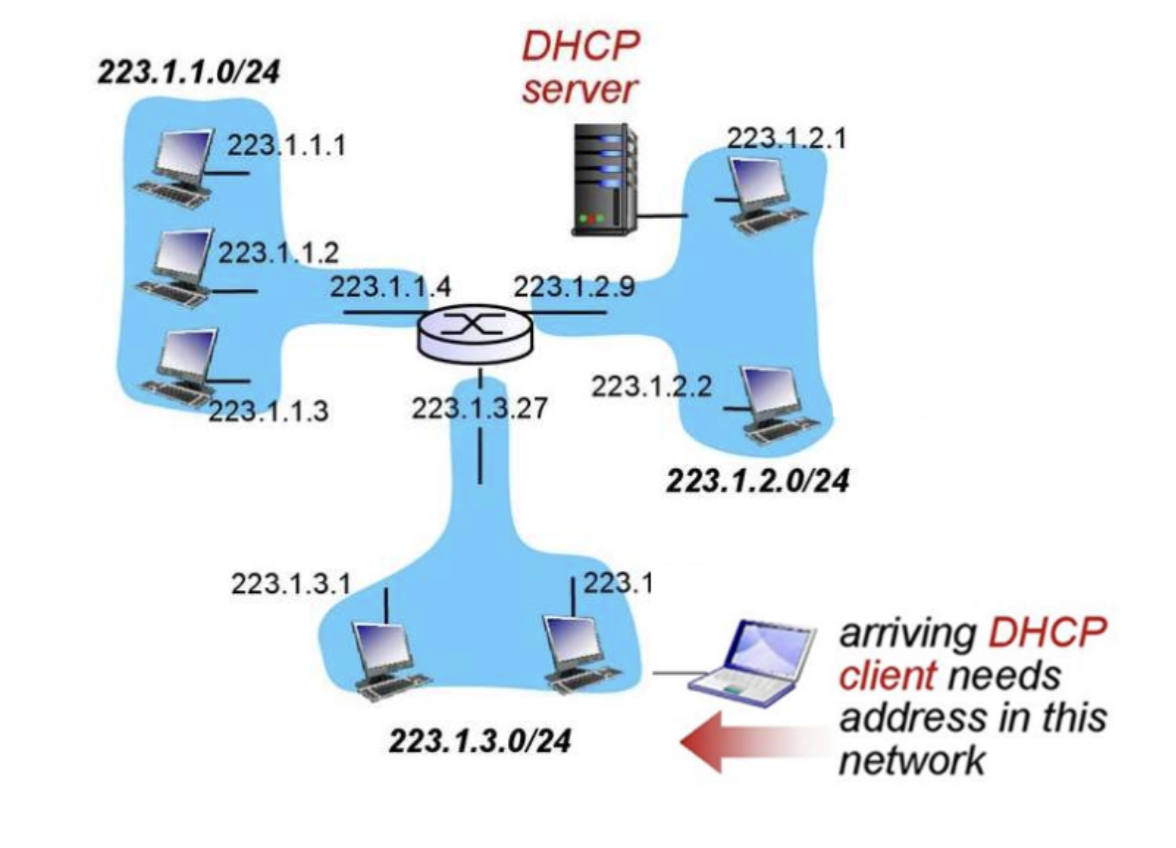
따라서 디폴트 게이트위이에 연결된 라우터에 Relay Agent를 설치해서 타 네트워크의 DHCP로부터 구성 정보를 받을 수 있다.
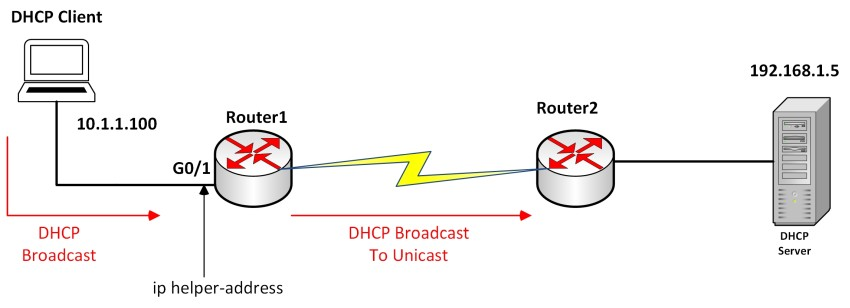
Relay Agent를 통해서 Discover, offer 메시지를 다른 네트워크에 전달한다. Relay Agent는 IP-Helper-Address 명령어를 통해 설정한다.
IP 주소 구분
공인 IP 주소
인터넷에서 사용되는 주소이며, 공인된 기관에 의해서 할당된 주소이다.
사설 IP 주소
사설 IP 주소는 내부 네트워크에서 사용되는 주소로, 인터넷에서 직접 접근할 수 없다. 인터넷 IP 주소 관리 대상에 불포함되며, 다른 네트워크에서 중복 사용 가능하다.
사설 IP 주소 범위
- 클래스 A : 10.0.0.0 ~ 10.255.255.255
- 클래스 B : 172.16.0.0 ~ 172.31.255.255
- 클래스 C : 192.168.0.0 ~ 192.168.255.255
사설 IP 주소는 라우터에서 처리가 안되기에 연결이 되지 않으며, 나머지는 공인 IP 범위이다.
NAT
NAT는 사설 IP 주소를 사용하는 내부 네트워크에서 외부로 나갈 때, 내부에서 사용된 사설 IP 주소를 공인 IP 주소로 변환한다. 요청과 응답에 대하여 NAT를 통해 변환되게 된다.
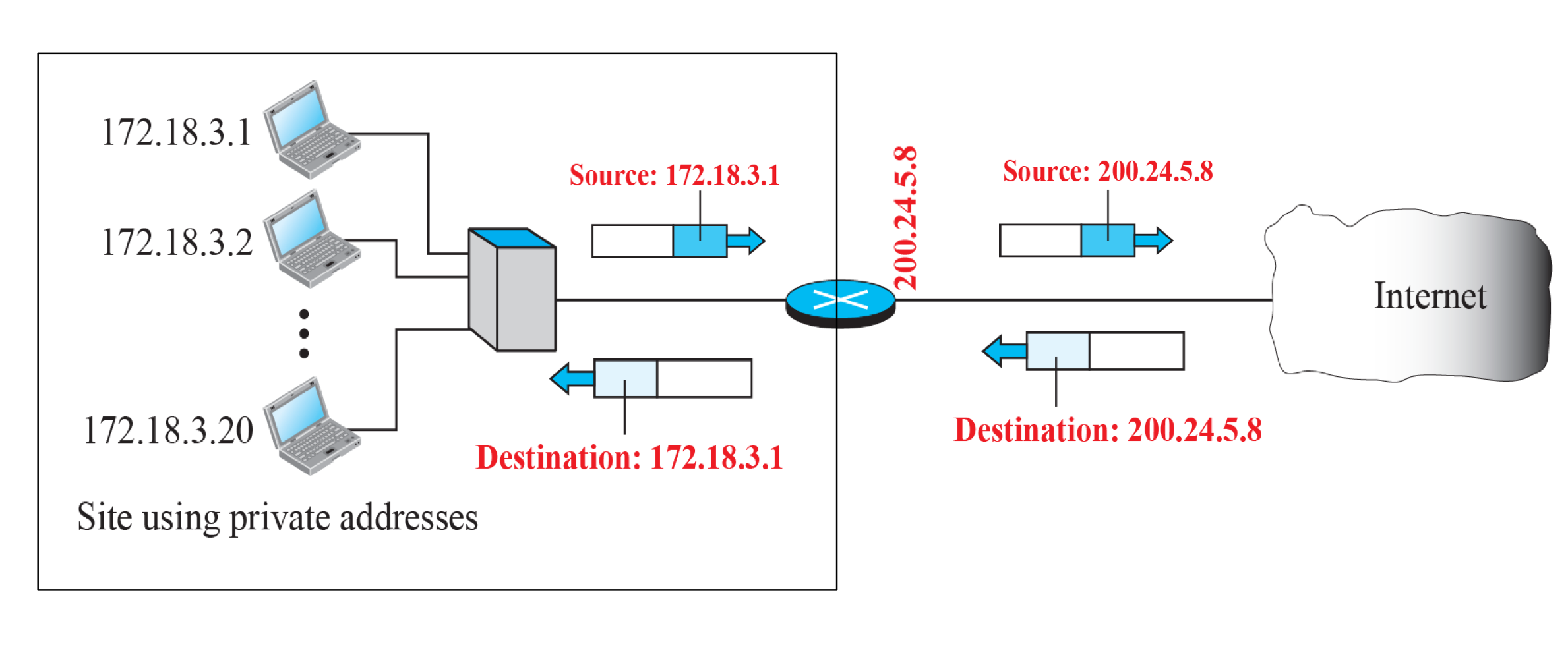
장점
- 인터넷을 접속할 때만 공인 IP주소를 사용한다.(절약)
- Host IP 주소 외부 노출 방지한다.(보안)
동작 절차
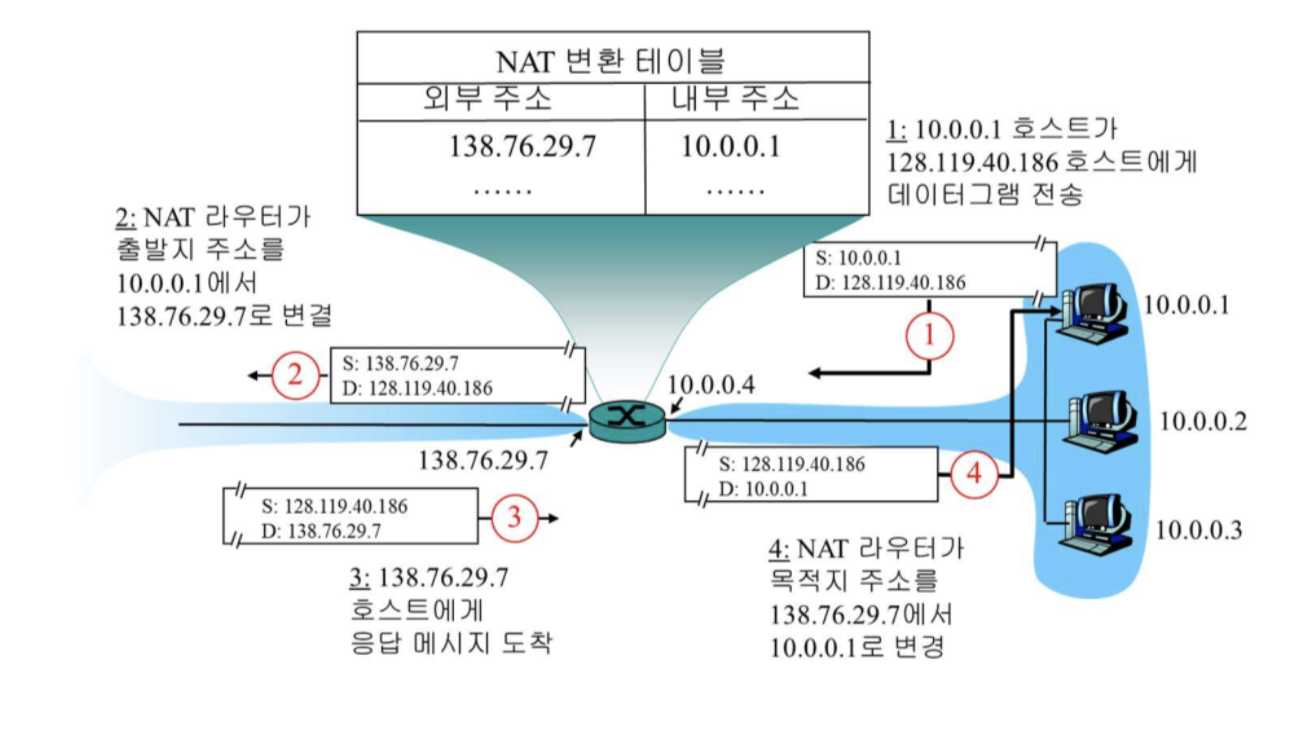
- 호스트가 공인 IP로 데이터그램 전송
- NAT 라우터 테이블에 작성
- 응답 메시지 도착
- 테이블을 통해 해당 호스트에게 전달
정적 NAT
정적 NAT은 내부 네트워크의 각 내부 IP 주소를 미리 정의된 하나의 공인 IP 주소와 일대일 대응시키는 방식이다.
동적 NAT
사용 가능한 공인 IP 주소 풀이 있으며, 내부 디바이스가 외부로 통신을 시도할 때마다 공인 IP 주소가 동적으로 할당된다.
위 방식은 IP 주소 풀의 개수만큼 인터넷 연결을 할 수 있다는 한계가 있다.
NAPT (Network Address and Port Translation)
NAPT는 사설 네트워크에서 여러 개의 서비스들의 포트 번호와 사설 IP 주소를 통해 하나의 공인 IP 주소에 여러 개의 사설 IP 주소를 변환한다.
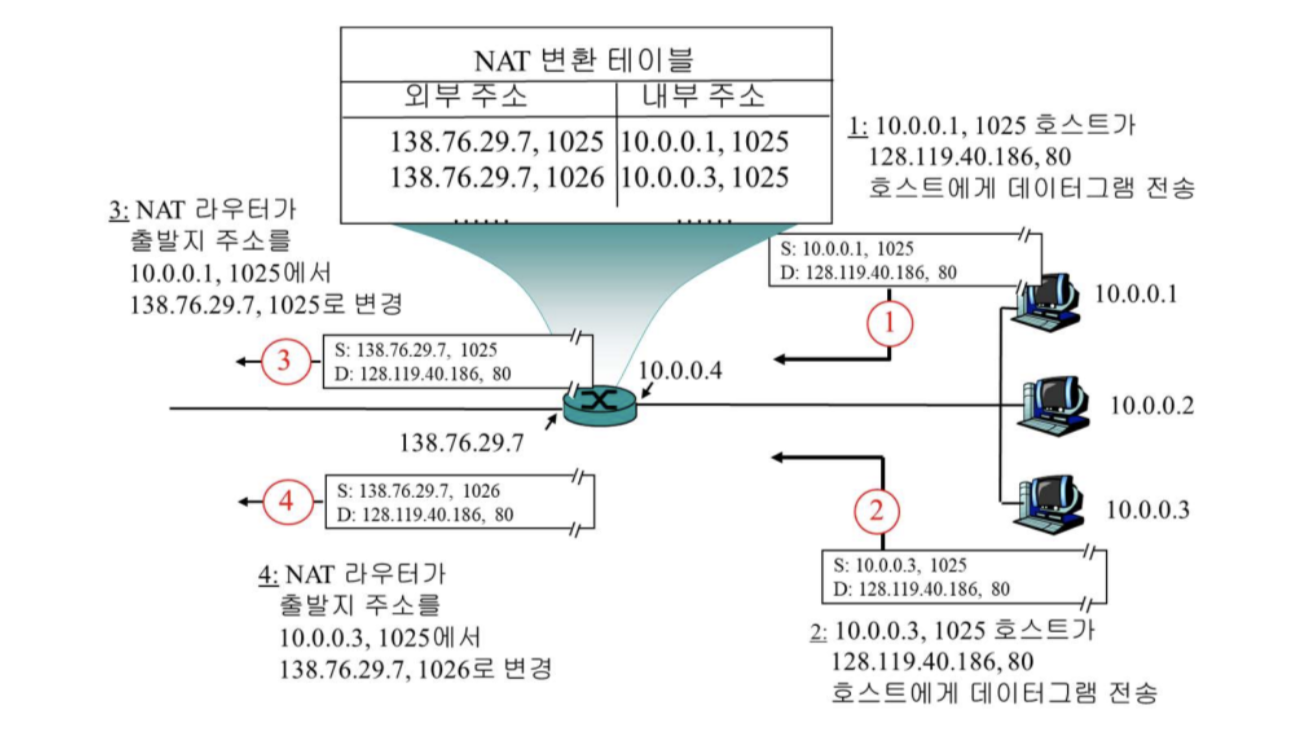
Translation Table
Private address뿐만 아니라 private port까지 고려하여 구분하므로 컴퓨터 내의 응용 프로그램의 프로세스 단위로 구분한다.

Routing
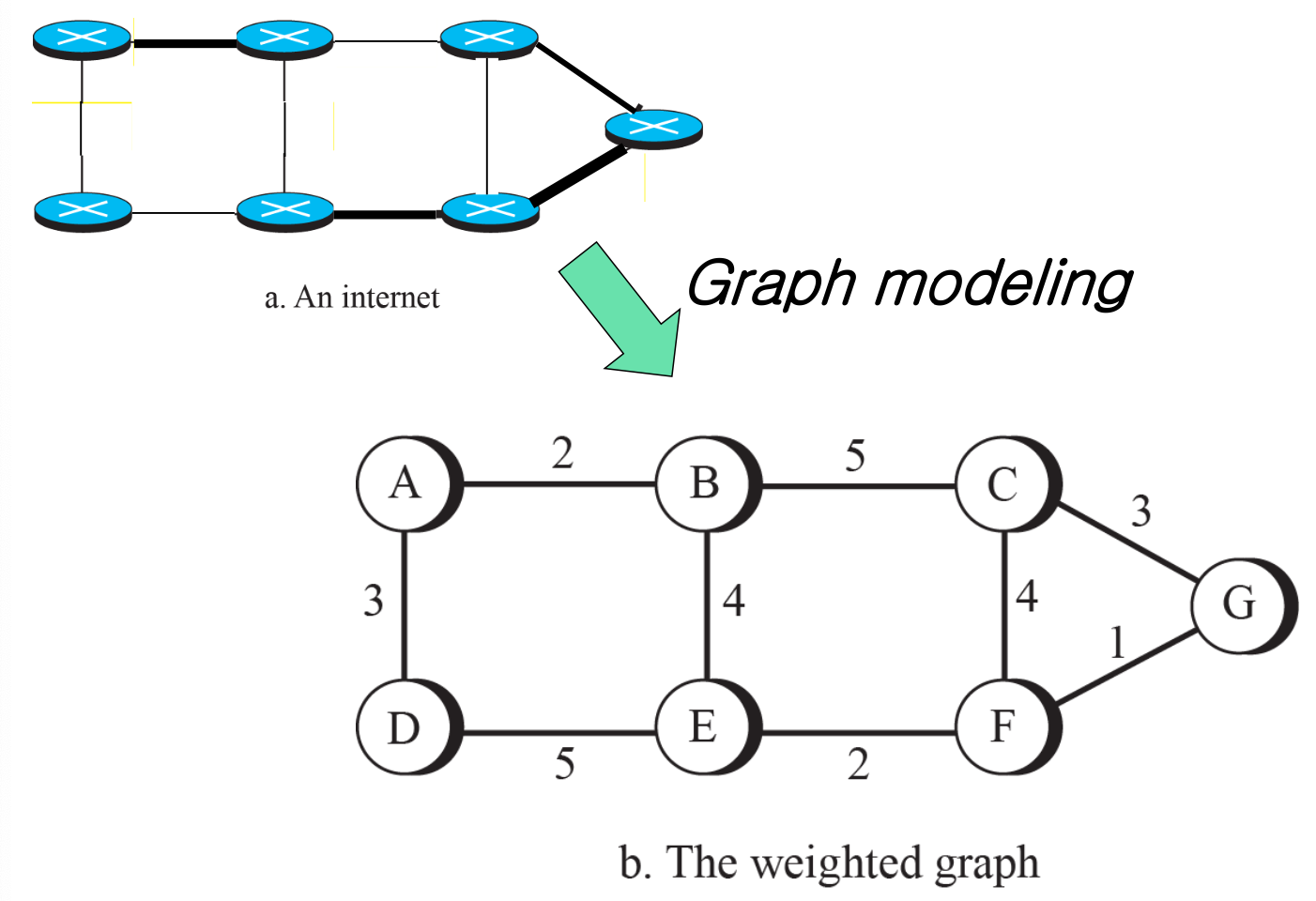
인터넷은 라우터들을 서로 연결되어 구성된다. 이러한 인터넷을 라우터와 링크를 각각 노드와 엣지로 표현할 수 있다. 기본 아이디어는 가중치가 있는 그래프로 표현한다.
Graph G = (N, E): N개의 노드와 E개의 간선으로 표현한다.
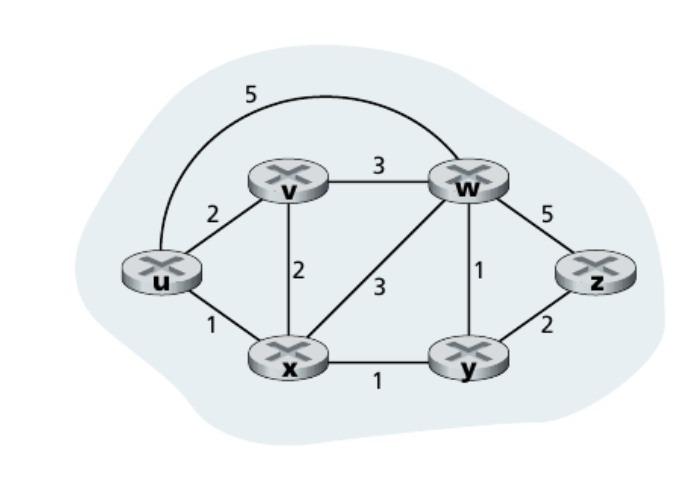
가중치는 전용선의 비용, 비트 에러의 정도 등으로 정의할 수 있다.
출발지 라우터와 목적지 라우터를 연결하는 경로 중 링크 비용의 합이 가장 작은 경로를 찾는다.
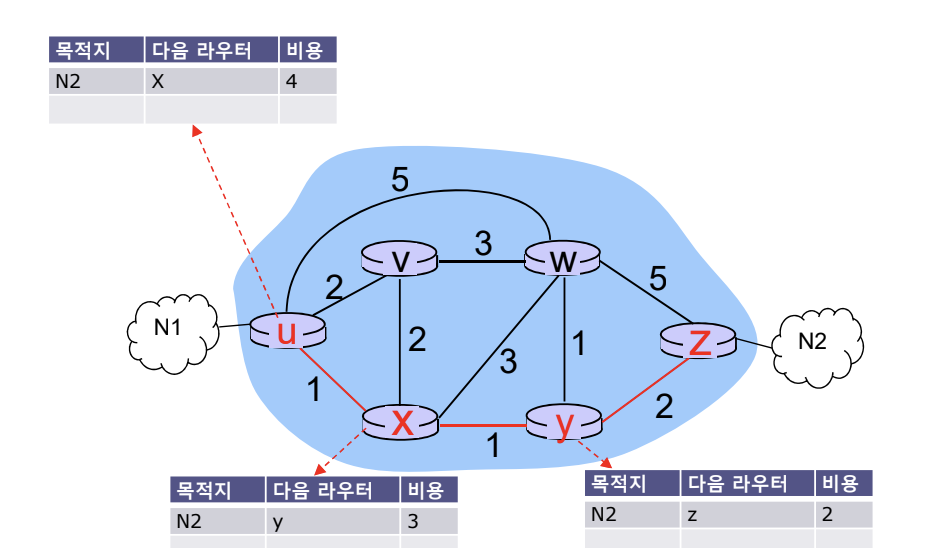
N1에서 N2까지의 모든 경로인 X, Y, Z를 저장하게 되면 라우팅 테이블이 커진다. 따라서 인터넷의 Hop-by-Hop 기술을 이용해 라우팅 테이블에 다음 라우터와 비용을 저장한다.
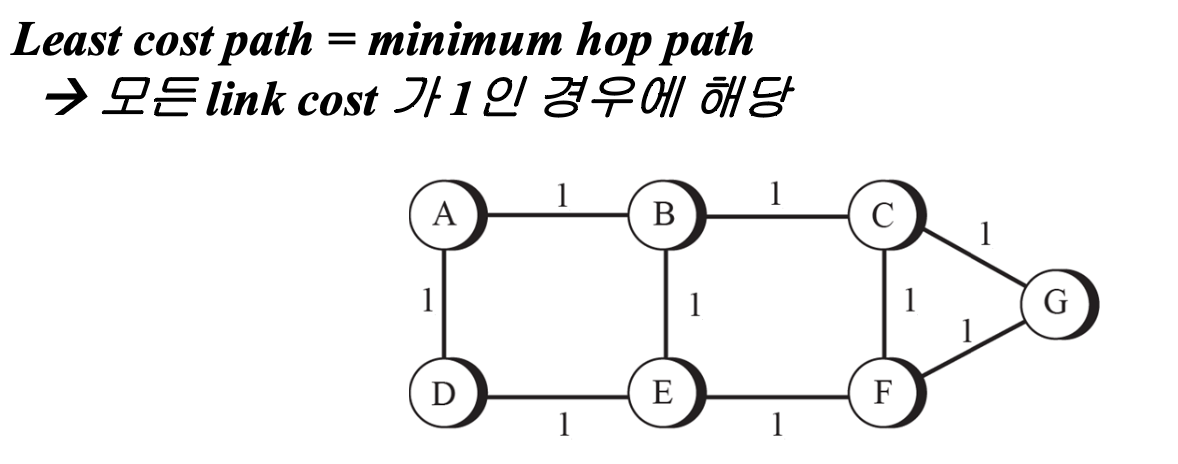
Least Cost Routing
인터넷을 가중치 그래프로 모델링할 수 있어야 한다. Least Cost Routing (LCR)은 네트워크에서 효율적인 경로를 선택하기 위한 알고리즘 중 하나이다.
-
가중치 그래프로 모델링
-
Graph에서 Tree로 해석한다.
Tree: Root로부터 모든 노드가 유일한 경로로 연결되어야 하고 Loop가 없다.
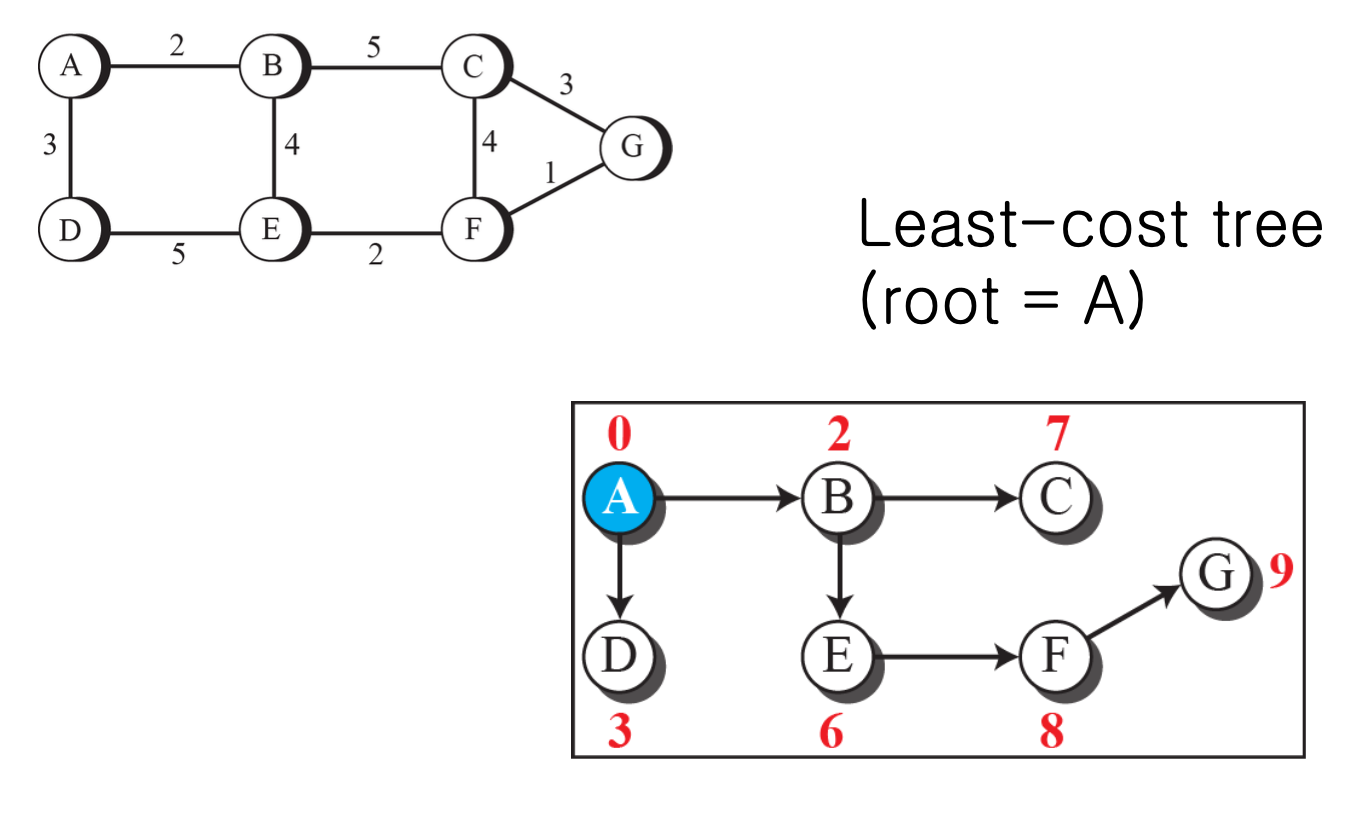
- A부터 시작해 각 노드들을 root로 하는 least-cost tree를 생성한다.
-
B
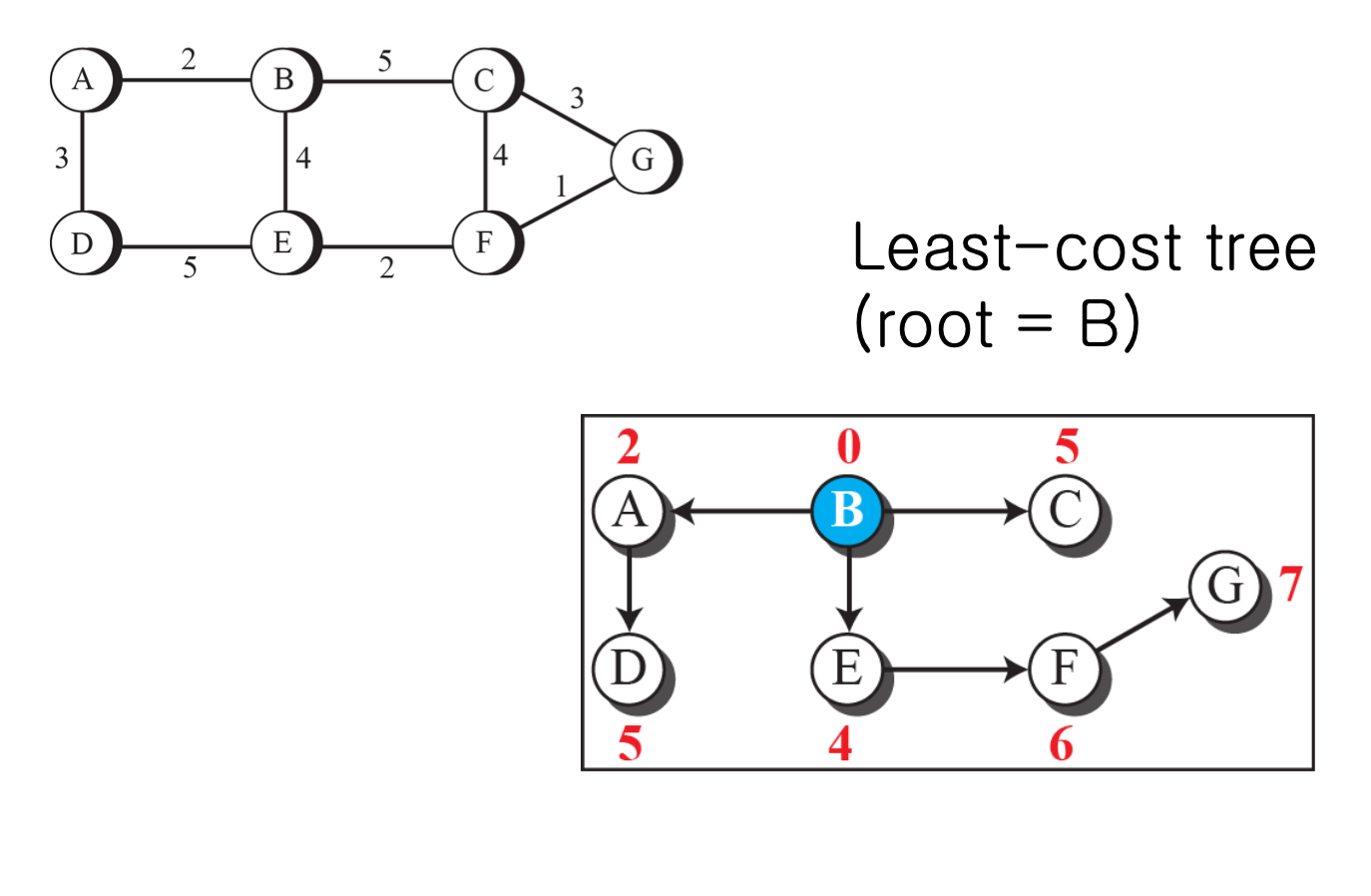
-
C
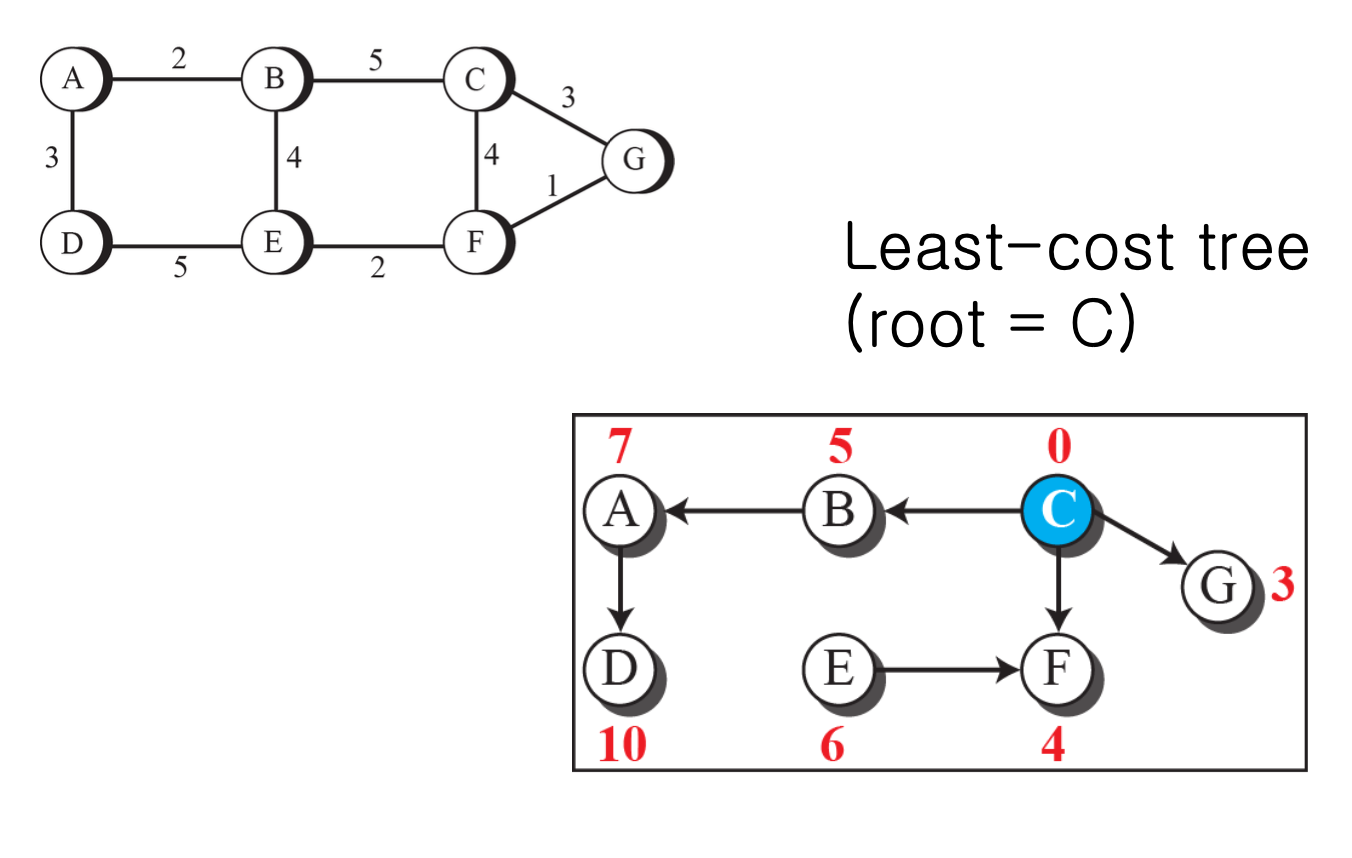
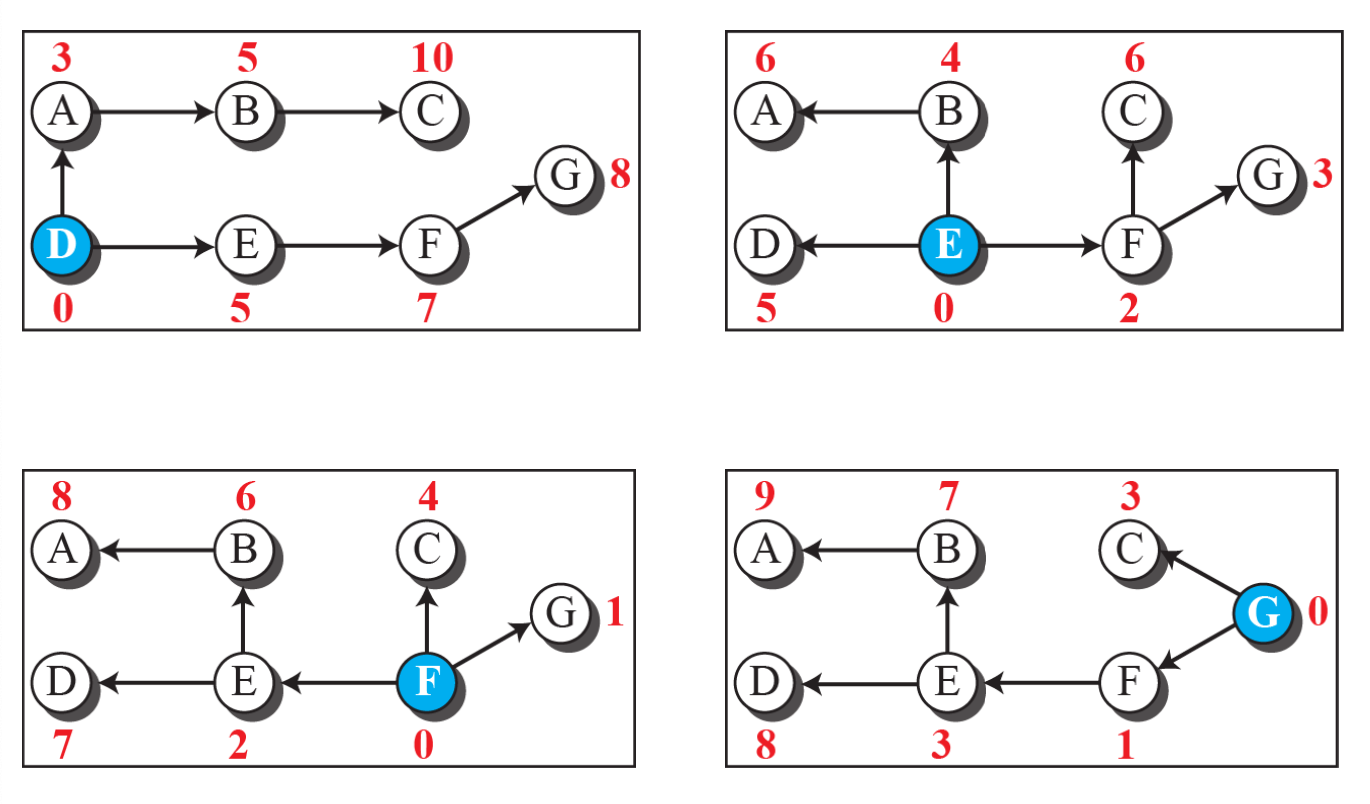
모든 경로에 대해 최소 경로를 찾을 수 있다.
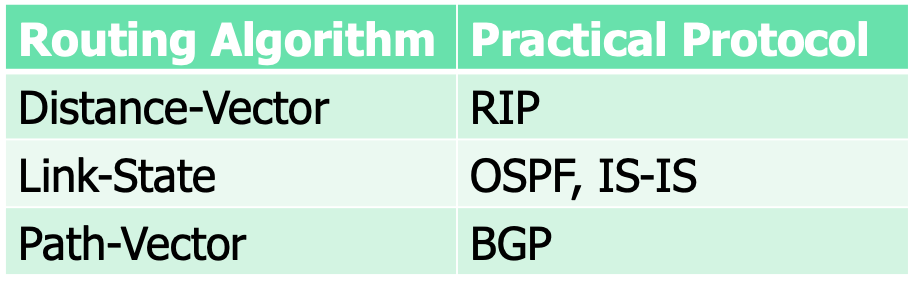
Routing Algorithm
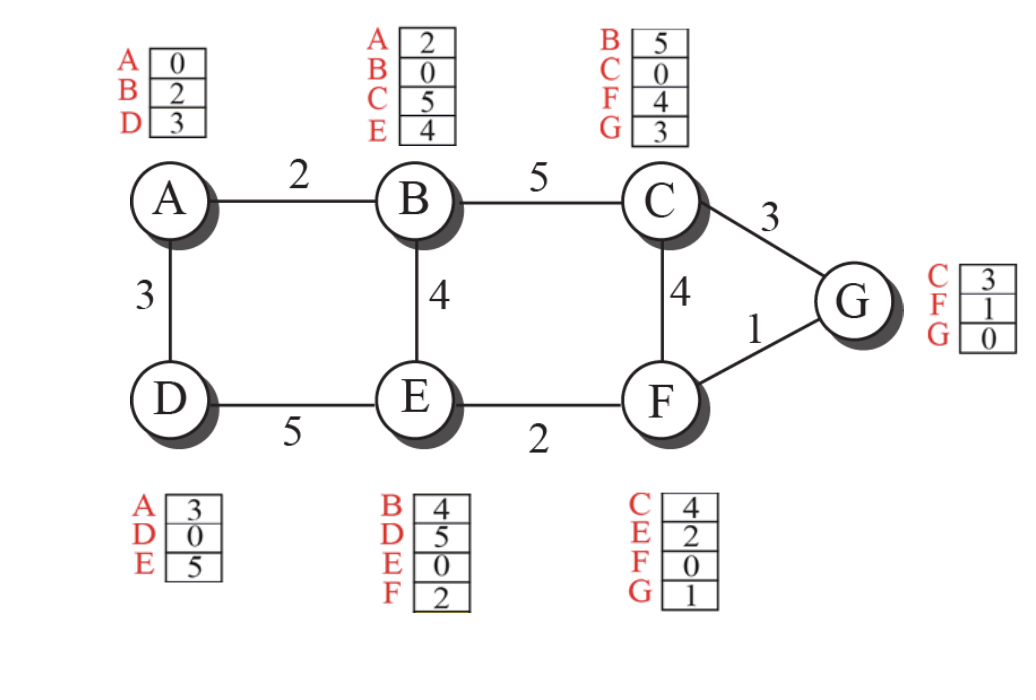
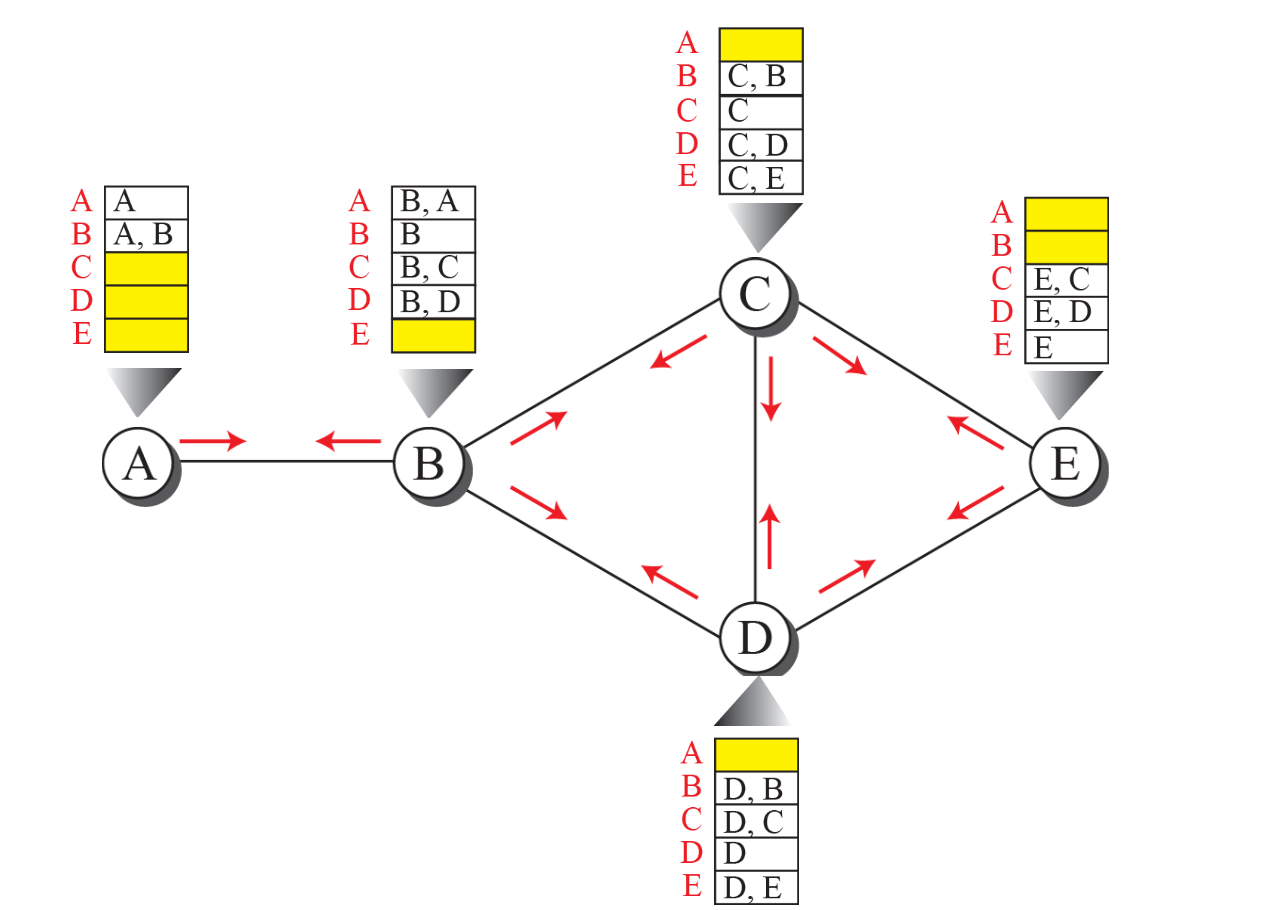
Distance Vector Routing
Distance vertor routing 알고리즘은 초기의 Distance vector를 통해 모든 Distance vector를 구할 수 있는 알고리즘이다.
특정한 노드를 루트로 가정하고, 자신으로부터 least cost tree를 만들고 다른 모든 노드들까지의 Distance vector의 초기값을 생성할 수 있다.
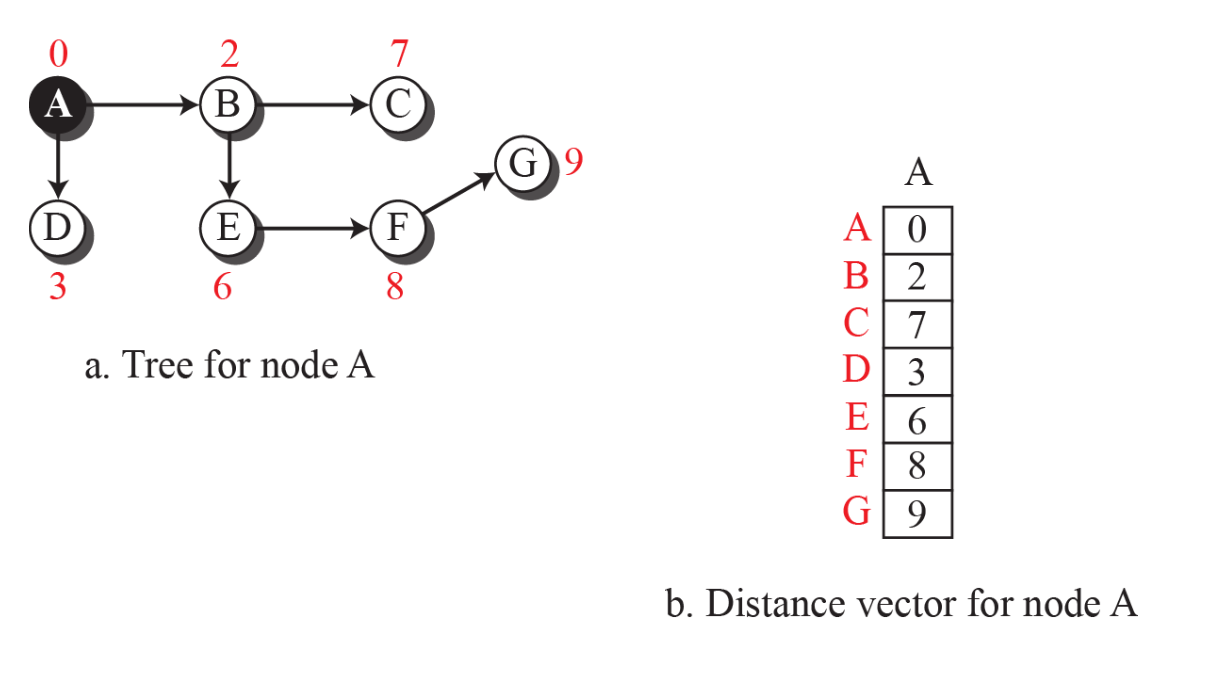
아직까지는 직접 연결되지 않은 노드들의 거리는 알 수 없다.
주기적으로 이웃 라우터와 패킷을 주고 받으며 링크의 상태를 파악한다.
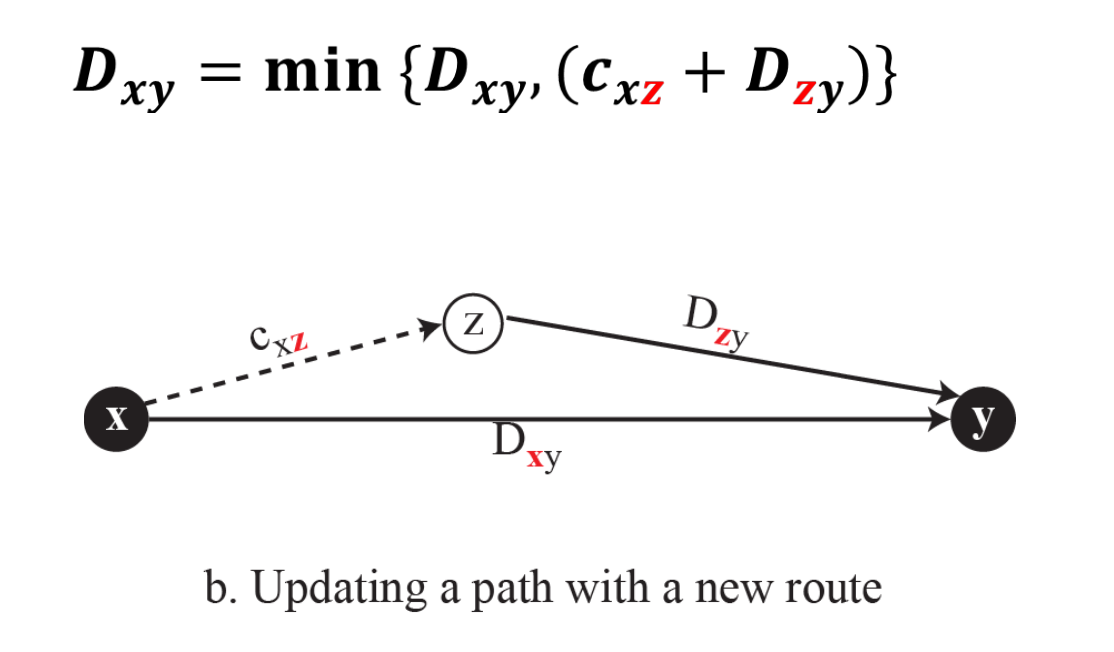
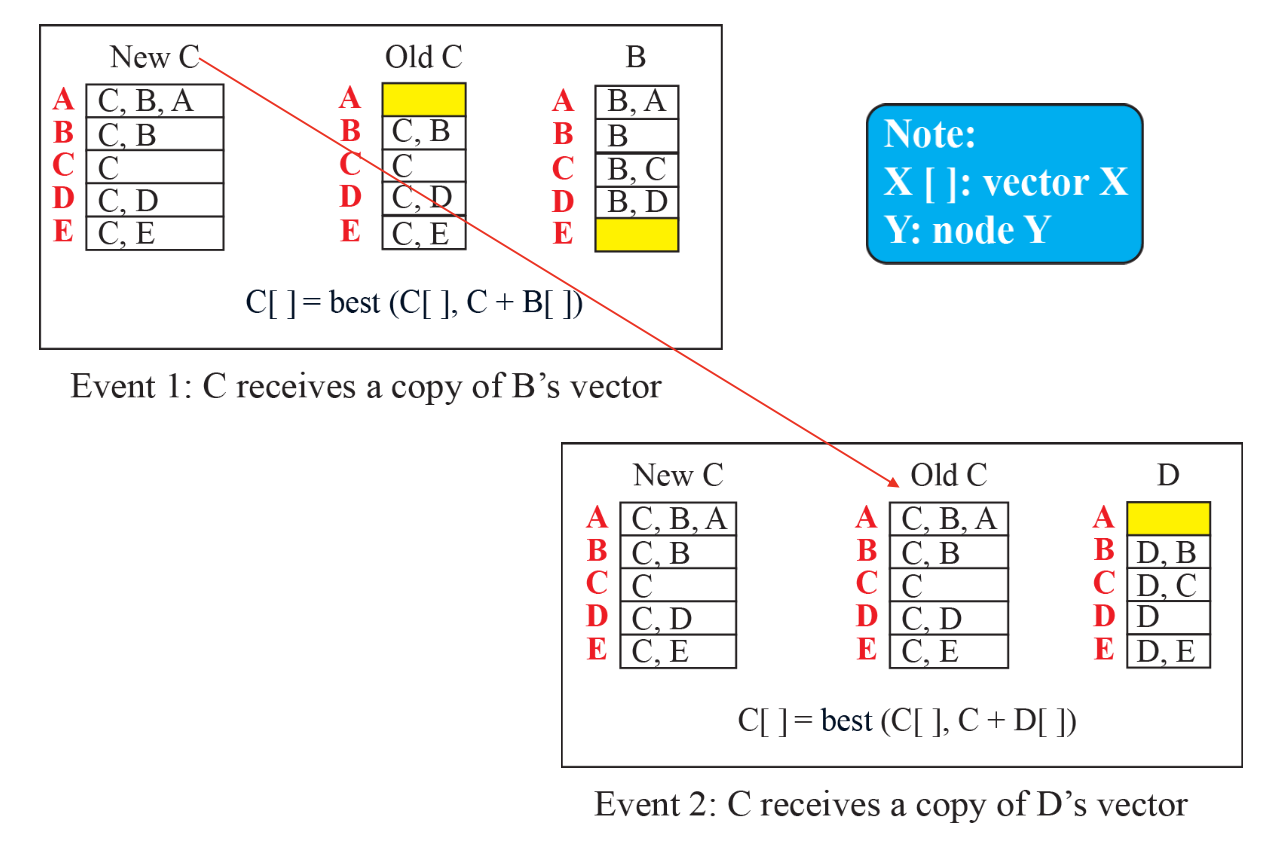
Bellman-Ford
Bellman-Ford 공식을 통해 경로를 업데이트한다.
- Dxy: 라우터 x에서 y까지의 최소 경로 비용
- cxz: 라우터 x에서 이웃 라우터 z까지 링크 비용
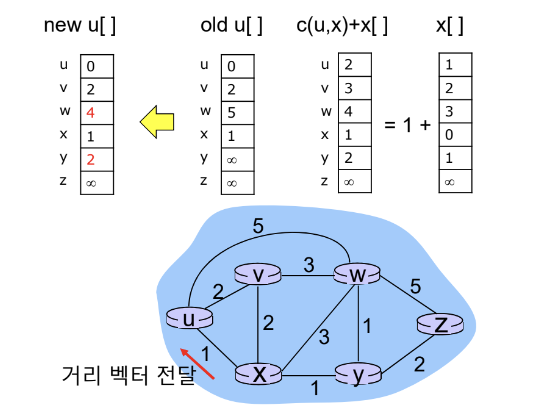
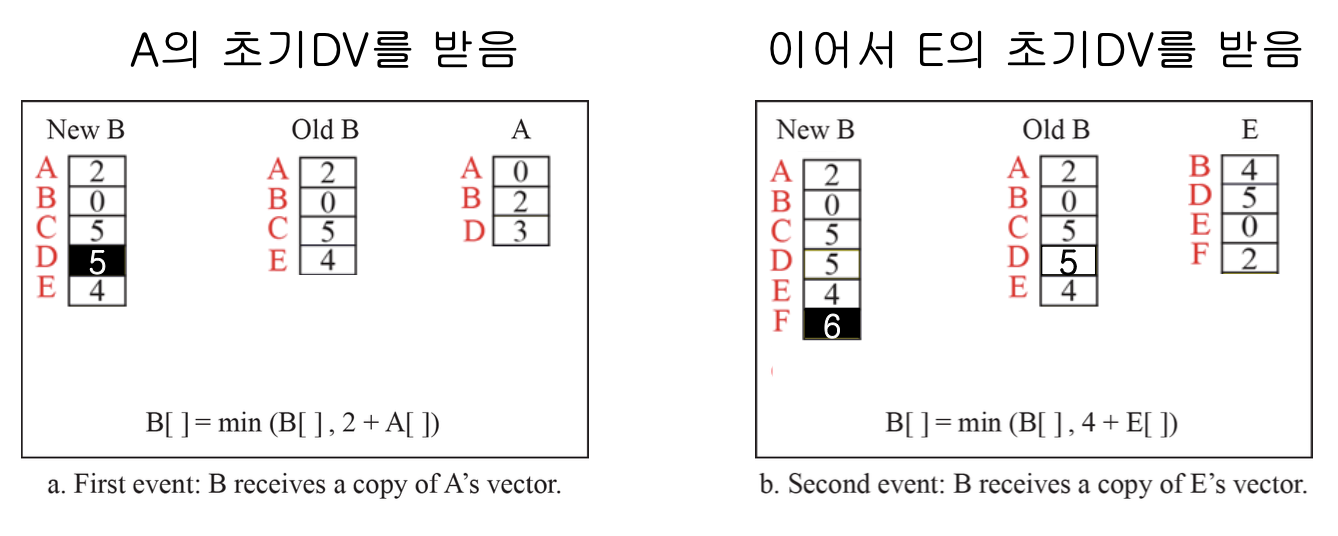
과정
- 이웃 라우터와 자신의 초기 Distance Vector 공유
- 이웃 라우터의 Distance Vector와 Bellman-Ford Equation를 적용한 자신의 Distance Vector 갱신
- 갱신된 Distance Vector를 이웃 라우터에 전달
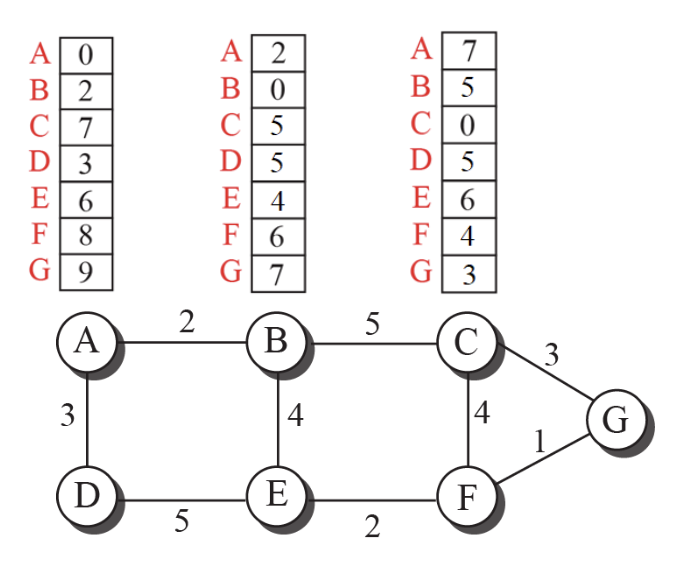
그림처럼 각 노드는 전체 노드들에 대하여 각자 Least-cost tree 기반의 DV를 갖도록 신속하게 수렴한다.
단점
Good news는 빨리 퍼지지만, Bad news(네트워크 끊어짐, ...)는 천천히 퍼져나간다.
이는 Count-to-infinity problem을 야기한다.
Count-to-infinity problem
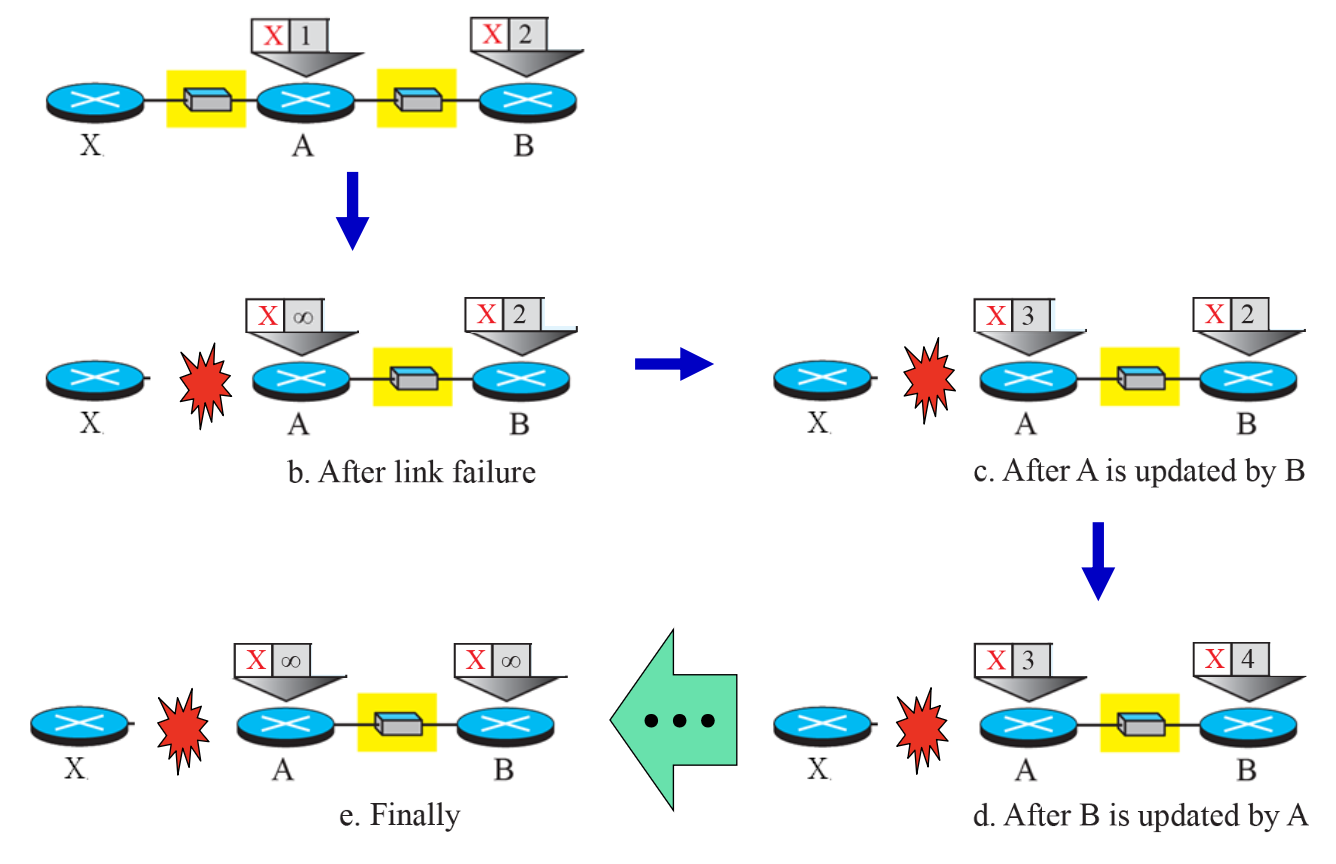
- 주기적으로 이웃 노드들끼리 확인한다.
- A는 X로부터 응답을 못 받아서 무한대로 갱신한다.
- B에서 X까지 거리가 2인 것을 알기에 A는 X가 3홉인 것으로 착각한다.
- B는 다시 X까지의 cost를 A를 통해 X를 4로 갱신한다.
- A, B 모두 무한대로 발산한다.
Split Horizon
특정 경로의 업데이트를 해당 경로로 전파하지 않도록 하는 원칙을 적용하는 방식이다.
- 앞의 슬라이드에서 B는 X까지의 distance가 A를 경유하는 path이므로, A에게는 X에 대한 내용이 삭제된 Distance Vector 정보를 보낸다.
- 그러나 세 노드 이상에서 발생하는 instability 문제는 split horizon 방식으로도 문제 해결이 보장되지 않는다.
- 그러므로 문제점들을 보완하기 위하여 실제 구현에서는 다양한 timer들을 이용하며, poisoning, poison reverse 등의 방법 등을 사용한다.
Poison Reverse
라우터가 더 이상 사용할 수 없는 경로에 대한 정보를 다른 라우터에게 전파할 때 해당 경로의 거리 값을 무한대(∞)로 설정하여 전달하는 방식이다.
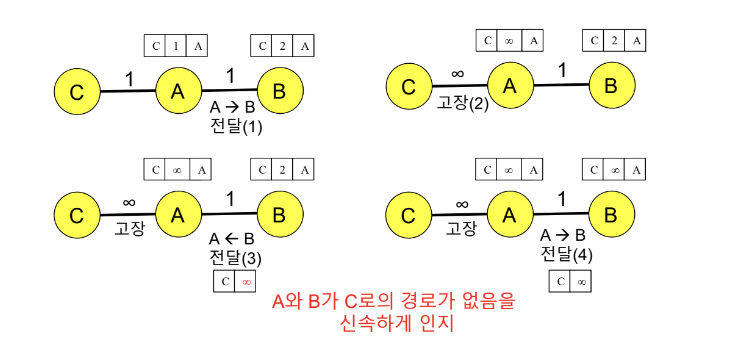
- B가 A에게 Distance Vector를 전달할 때, B는 A의 Distance Vector를 빠르게 참고하여 무한대(∞)로 설정하여 전달한다.
Three node Instability
3개 이상의 라우터 간에 순환 경로 발생 시 Poison Reverse가 Count-to-infinity problem을 보장받을 수 없다.
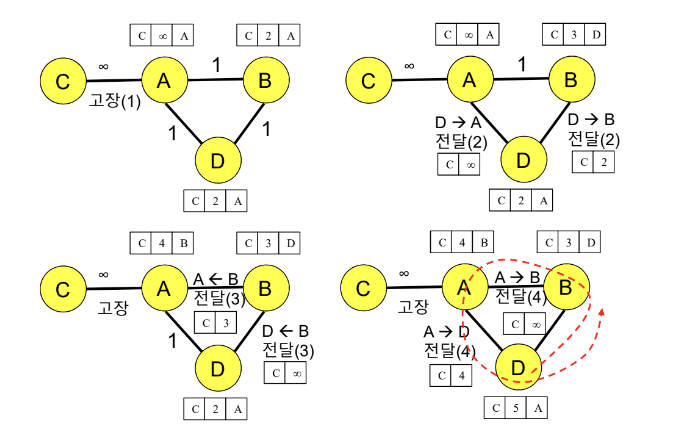
- A에서 C로 전달하는 링크가 고장났는데, B와 D의 무한대 패킷이 사라졌다.
- D는 C로 가는 Distance Vector를 Poison Reverse 방식으로 A에게 무한대로 전달한다.
- D는 C로 가는 Distance Vector를 Poison Reverse 방식으로 B에게 2로 전달한다.
- B는 ~~
Link State Routing
각 노드가 자신에게 붙어 있는 링크의 상태를 체크하고, 체크한 링크 정보를 모든 노드에 전파한다. 그 후 모든 노드들이 least cost tree를 생성한다.
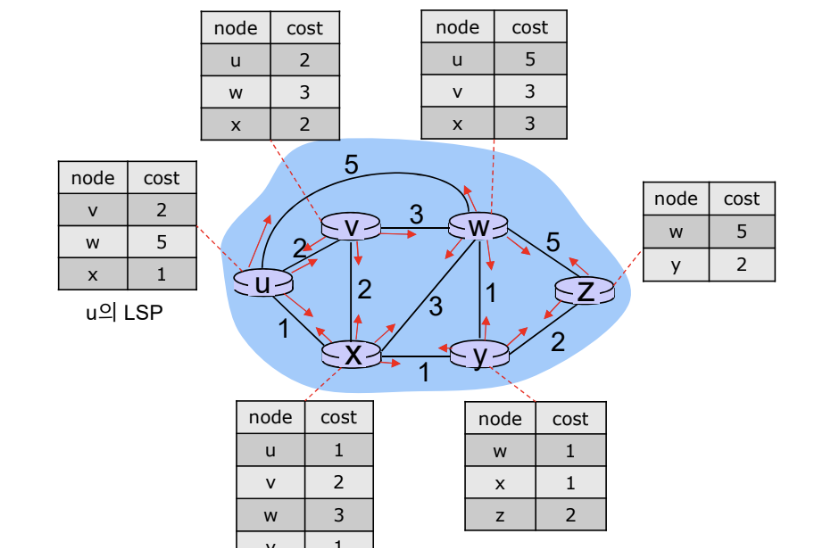
Link State Routing은 Global Routing으로 모든 라우터가 모든 링크의 비용 정보를 알고 있다.
LSP Flooding
자신의 링크 상태 정보(LSP)를 전체 라우터와 공유하여 모든 노드가 같은 정보를 유지하게 한다.
- Link-State DB
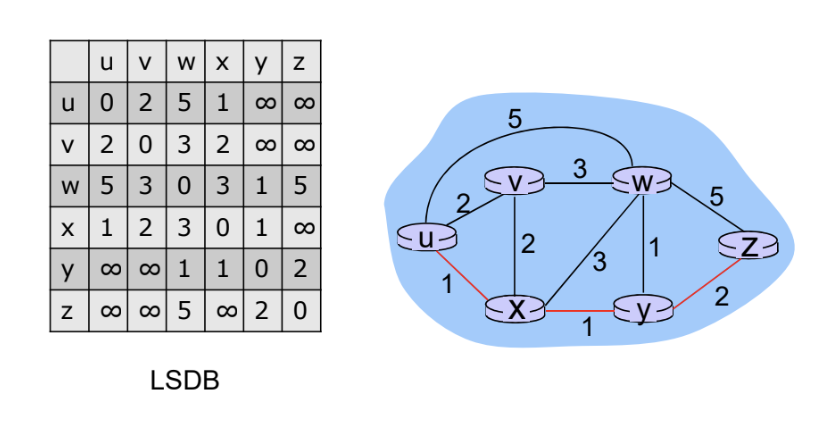
다익스트라 알고리즘과 별개의 라우팅 프로토콜에 의해 수행된다.
- 각 노드는 주기적으로 자신의 이웃들과 greeting 메시지를 주고 받으며 이웃 노드의 ID와 링크 상태를 파악한다.
- 이렇게 각 노드가 자신 주변의 링크 상태를 파악하여 정리한 것이 Link-state Packet(LSP)이다.
- Broadcast (flooding): 각 노드는 LSP를 자신의 모든 링크로 내보내고, 이 것을 받은 중간 노드들은 LSP가 들어온 interface를 제외한 모든 interface로 다시 내보낸다.
- Flooding은 자연스럽게 흐름이 멈춘다. Counter 값을 통해 TTL 역할을 하게 하여, 무한 루프를 방지한다.
Dijkstra Algorithm
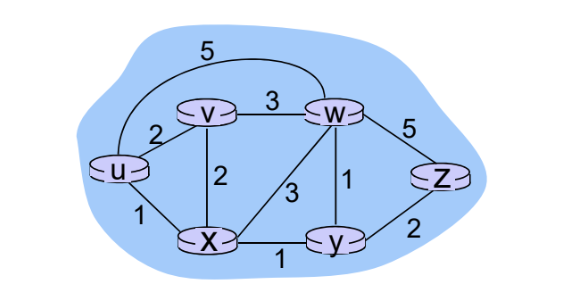
- 직접 연결된 링크 중에 비용이 가장 작은 링크의 라우터를 최소비용 경로 라우터로 선택한다.
- 최소 비용 경로로 선택된 라우터와 직접 연결된 라우터에 대한 경로 비용을 재계산하고, 기존 경로 비용과 비교하여 작으면 경로 비용 갱신한다.
- 경로 비용이 알려진 라우터들 중에 경로 비용이 가장 작은 라우터를 최소 경로 비용 라우터로 선택한다.
- 모든 라우터가 최소 경로 비용 라우터로 선택될 때까지 2,3번을 반복한다.
DV Routing vs LS Routing
- DV는 글로벌 정보를 이웃(로컬)에게만 공유하지만, Link state 정보(로컬 정보)를 모든 노드(글로벌)에게 공유한다.
LS의 단점은?
Path Vector Routing
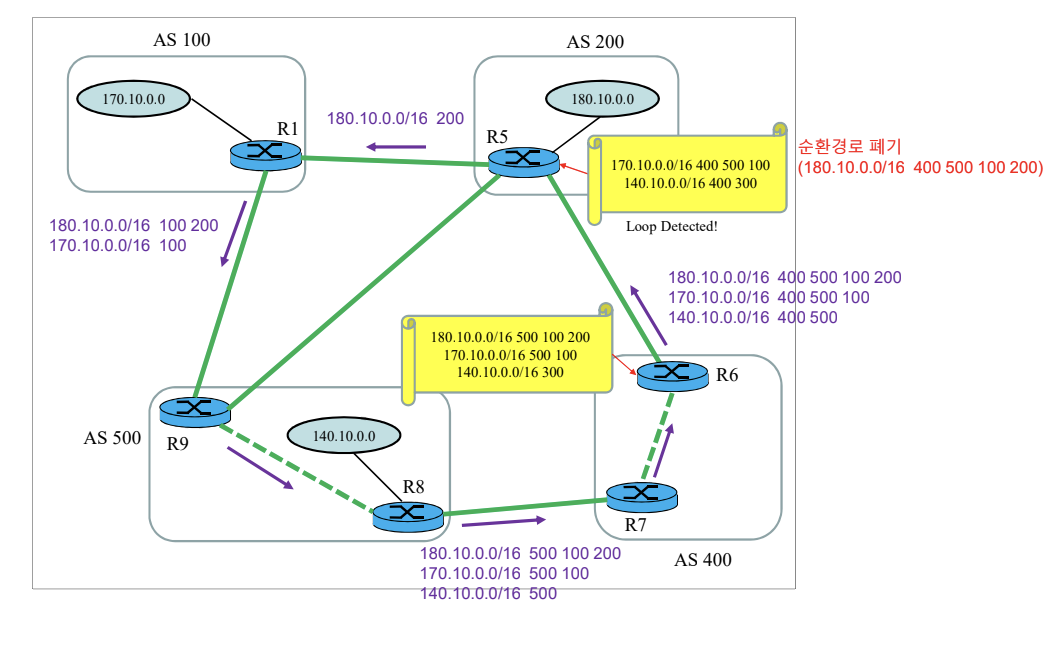
모든 목적지까지 전체 경로 정보(Entire Path) 자료 구조를 저장한다. 따라서 순환 경로(loop) 탐지 가능하다.
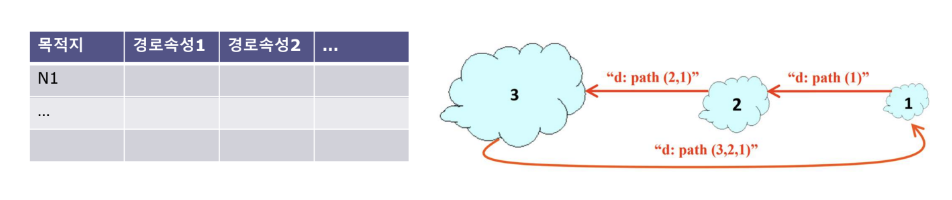
다양한 경로 속성들(Path Attributes)의 조합으로 경로 정보 제공한다. 송신자는 경로 벡터의 경로 속성들을 사용하여 다양한 경로를 조합하여 최적의 경로를 선택한다.
조합은 Policy는 cost나 선호하는 경로 등을 고려하여 종합적으로 정해진다.
Distance Vector는 distance와 next router의 정보만을 갖고 있다. 순환 경로 발생 가능하다.
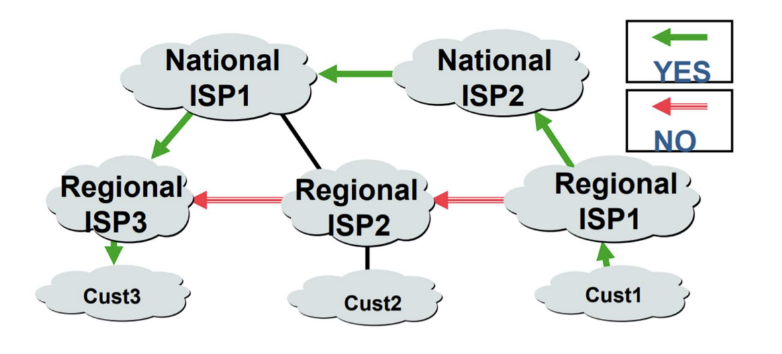
경쟁 ISP 회피
policy를 통해서 최소 비용만을 고려하는 것이 아닌 다양한 선택지를 제공할 수 있다.
과정
- Network가 시작되면 초기 path vector를 만든다.
- 만들어진 PV를 이웃 노드에게 알린다.
- Bellman-Ford 알고리즘을 적용하여 자신의 Path vector를 업데이트 한다.
즉, Path vector는 '어떤 경로를 거쳐서 간다'를 메모한 것.
갱신
Hierarchical Routing
전체 인터넷을 하나의 routing algorithm으로 구현하면 다음과 같은 문제가 발생한다.
- Scalability problem : Forwarding table에 인터넷의 모든 라우터 정보를 담아야 하므로 불가능하다.
- Administrative issue : ISP가 관리하는 네트워크마다 서로 다른 관리 규정을 적용할 수 있는 다양성 제공이 불가능하다.
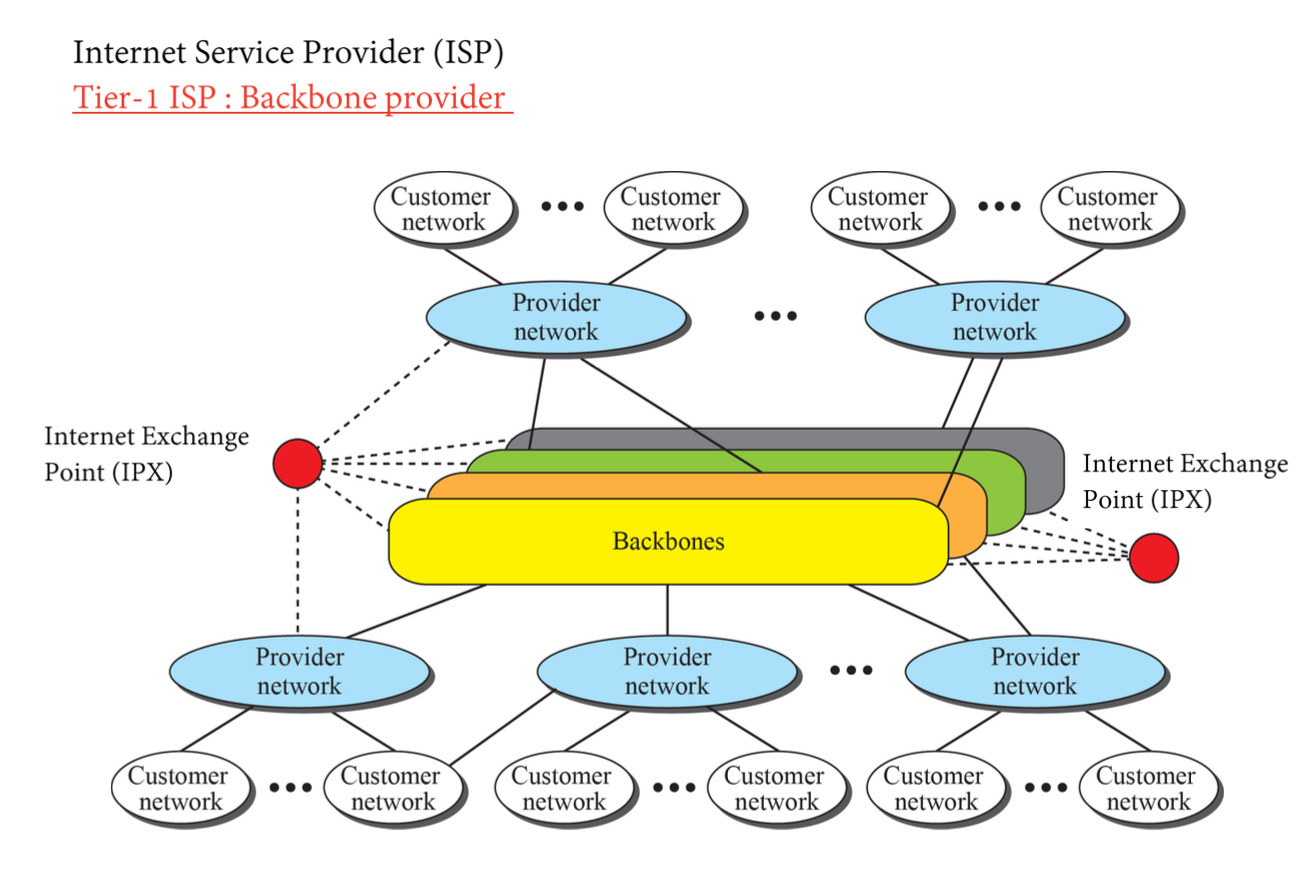
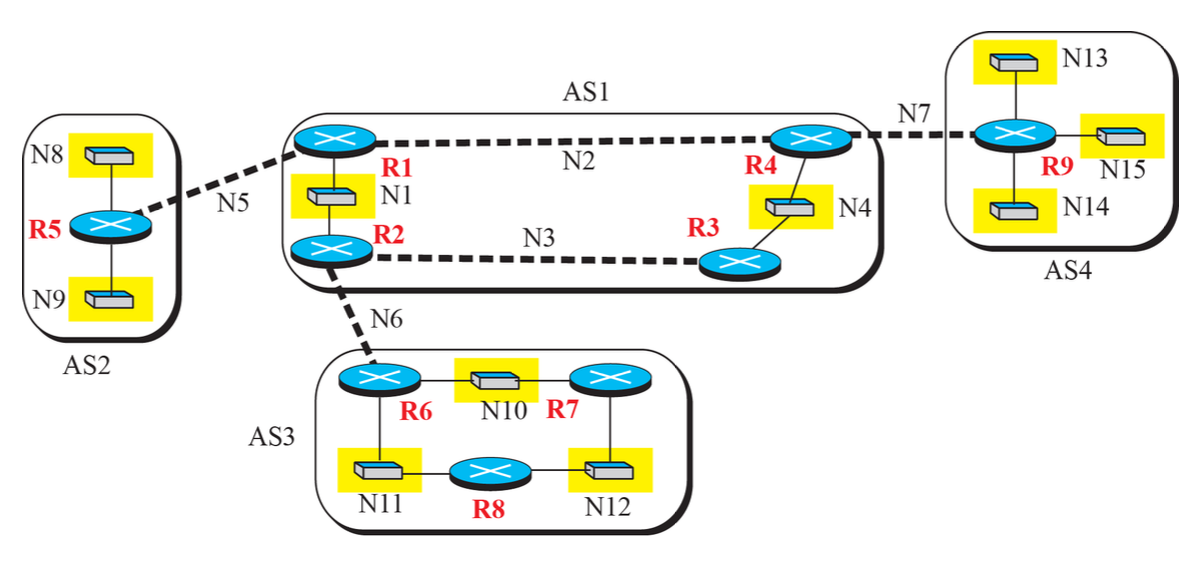
따라서 인터넷을 Autonomous System(AS)라는 영역들로 나누고, AS내에서는 하나의 intra-domain routing algorithm을 적용하고 AS 간에는 더 큰 개념의 inter-domain routing algorithm을 적용한다.
Rounting Protocol 입장에서 인터넷을 정의하면 AS(Autonomous System)들을 연결한 네트워크라 할 수 있다.
AS(Autonomous System)
인터넷에서의 네트워크 관리 단위로 정의되는 독립된 네트워크다. AS는 경로 선택 및 라우팅 결정을 자유롭게 수행할 수 있는 하나의 관리 도메인으로 간주된다.
보통 하나의 ISP가 관리하는 영역이며 ICANN으로부터 고유한 번호를 부여 받는다. 하나의 AS 내에서는 동일한 Routing Algorithm이 운용된다.
AS의 종류
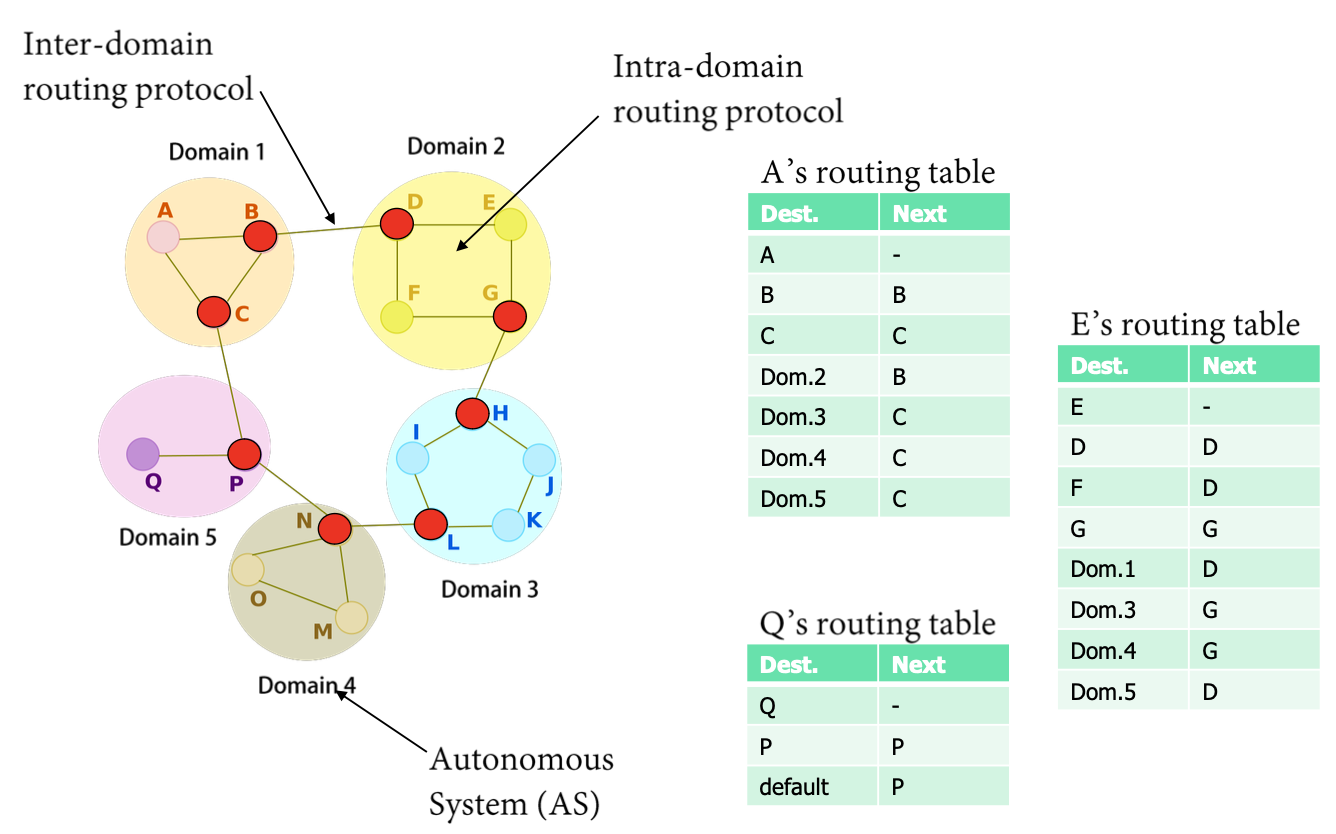
-
Single-Homed AS (단일 홈드 AS): 하나의 인터넷 서비스 제공자(ISP)에만 연결된 경우를 의미한다. 일반적으로 작은 기업이나 조직이 단일 ISP와의 연결을 통해 인터넷에 접속하는 경우에 해당한다. 한 가지 경로만을 통해 외부와 통신하기 때문에 라우팅 정책이 단순하다.
-
Multi-Homed AS (다중 홈드 AS): 둘 이상의 ISP와 연결된 경우를 나타낸다. Multi-Homed AS는 여러 경로를 통해 외부와 통신할 수 있으며, 이는 회복성과 성능 향상을 제공할 수 있다. 다중 홈드 AS의 경우 여러 ISP와의 계약을 통해 다양한 연결 옵션을 활용할 수 있다.
Domain 1의 경우, 두 개의 AS와 연결되어 있다. 하지만, Domain 5에서 Domain 2로 가는 data는 전달하지 않는다.
Transit AS: 외부 네트워크로 가는 트래픽을 다른 AS에게 전달하는 역할을 하는 AS다. 다른 AS들 간의 중계 역할을 수행한다. 예로서, Tier-1 또는 Tier-2 ISP 네트워크.
경유 AS로 사용 가능하다.
- Stub AS : 다른 AS와 트래픽을 공유하지 않고, 하나 이상의 Transit AS를 통해서만 외부와 연결되는 AS다. 보통 소규모의 조직이나 기업에서 사용된다. 주로 Customer network 이 해당한다.
위 그림에서 Domain 4 뒤에 Domain 6이 존재하고 Domain 4와만 연결되어 있으면 Domain 6이 Stub AS이다.
인터넷 라우팅
전체 인터넷을 여러 개의 AS로 구분하고, AS 내부는 각각 독립적인 라우팅 프로토콜을 적용한다. 따라서 AS간 라우팅은 각 AS를 연결하는 라우터들 간에 별도의 프로토콜러 수행된다.
구분
- Intra-AS 라우팅 프로토콜: AS 내부에 적용가능한 프로토콜(RIP, OSPF ...)
- Inter-AS 라우팅 프로토콜: AS 간에 적용가능한 라우팅 프로토콜(BGP, ...)
RIP (Routing Information Protocol)
Distance-Vector algorithm기반 Intra-domain routing protocol이다.
- 초기 IP와 함께 개발된 최초의 라우팅 프로토콜
- 현재 버전 2(RIPv2)
- 모든 링크의 비용은 1로 설정
- 최고 경로 비용을 15로 제한
- 경로 비용이 16인 경우, 무한대로 간주하여 유효하지 않는 경로로 처리
- UDP의 520 포트를 사용하여 전송
모든 링크의 비용은 1이므로 홉의 개수가 distance가 된다.
Count-in-infinity를 방지하기 위해 최대 16으로 설정했다.
RIP Message format

- Command: 요청, 응답 메시지의 여부
- IP Network Address: 네트워크 주소
- Subnet mask
- Next Hop
- Distance: 홉의 수
Network Address & Distance = Distance Vector
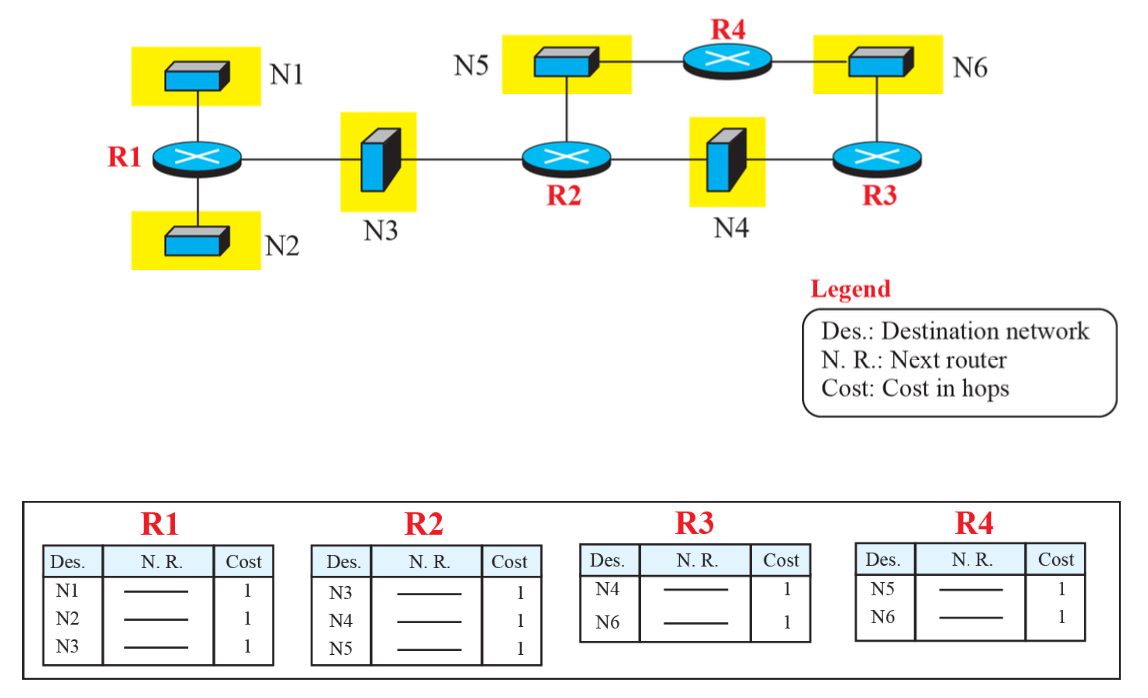
과정
- 모든 경로가 1로 초기화된다.
-
이웃끼리의 갱신이 이루어진다.
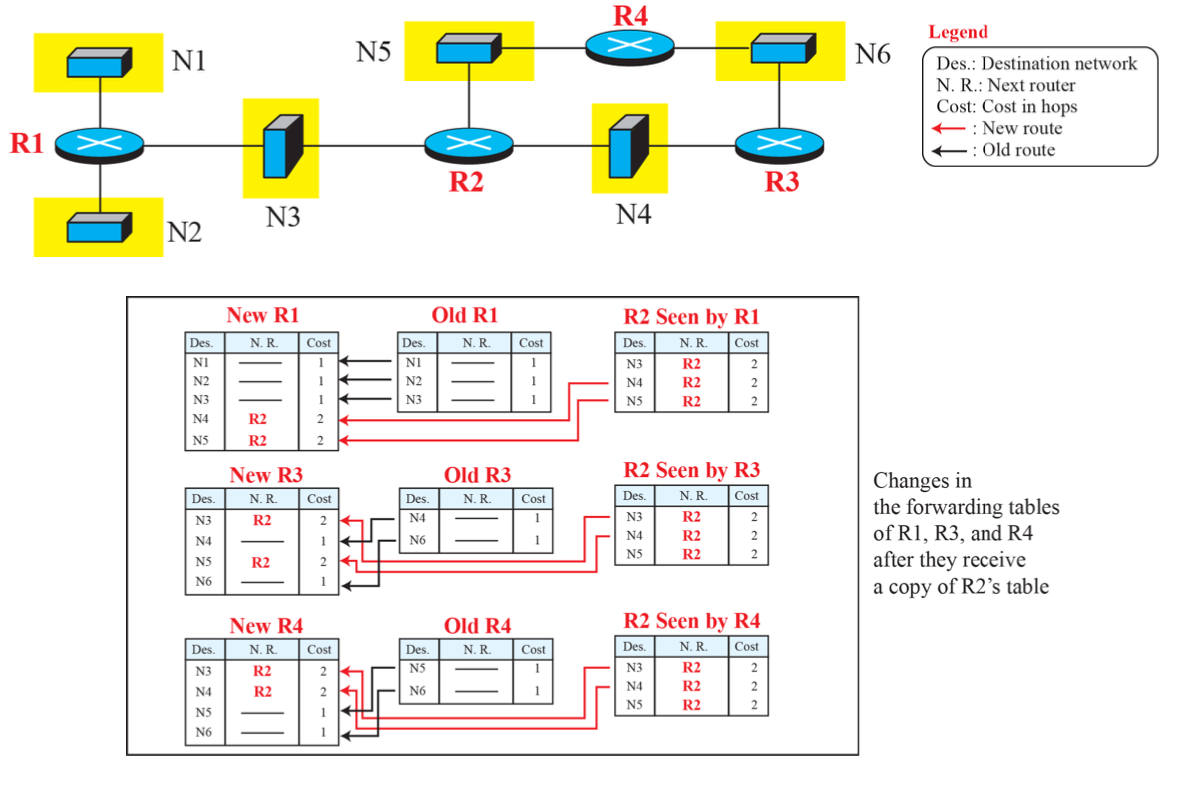
2-1. 수신된 경로가 기존 라우팅 테이블에 없으면 경로를 추가한다.
2-2. 수신된 경로의 거리가 라우팅 테이블의 기존 경로 거리보다 작으면 수신 경로로 갱신
2-3. 수신된 경로의 거리가 라우팅 테이블의 기존 경로 거리보다 크더라도 다음 라우터가 동일하면 수신 경로로 갱신한다. 이는 동일한 다음 홉 라우터를 경유하는 경로의 거리 비용이 증가한 경우이다.
2-4. 1~3번이 아닌 경우 수신된 경로 무시한다. -
안정이 되면, forwarding table이 완성이 된다.
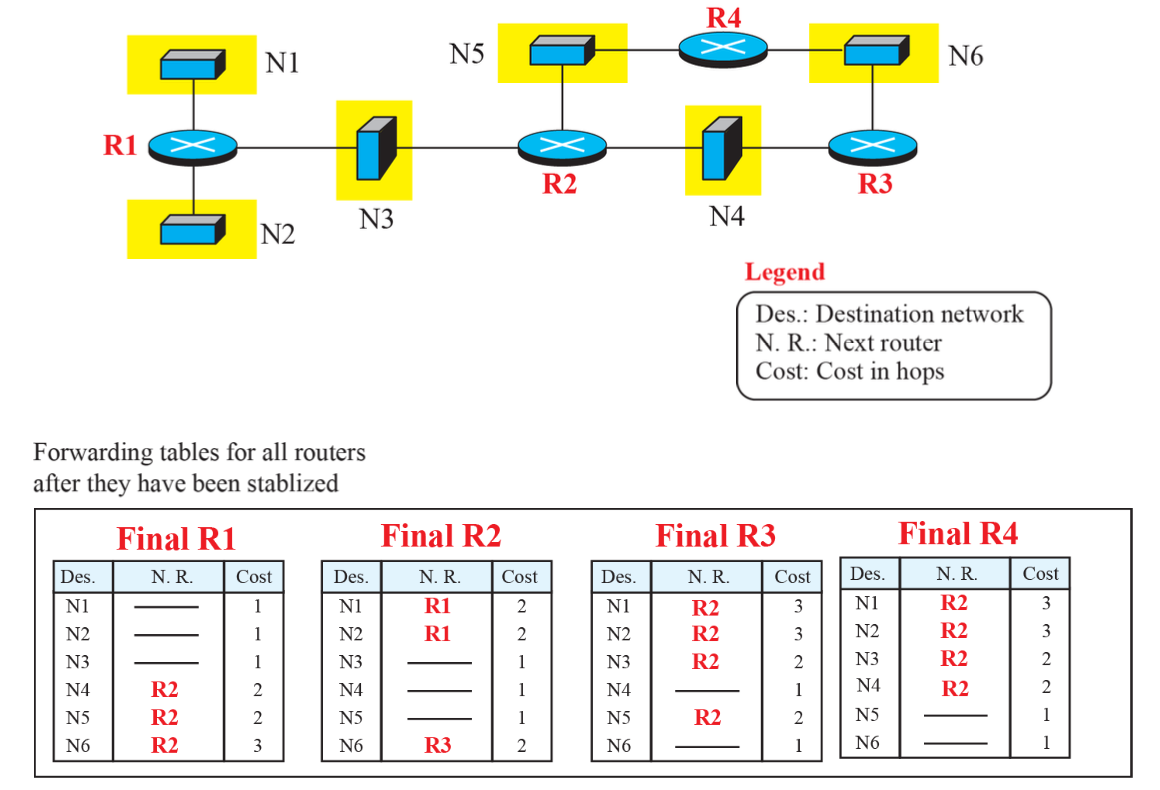
응답 메시지가 오면, 각 목적지에 대해 수신 경로 거리에 1을 더하여 새로운 경로 거리 계산 → RIP는 모든 링크의 비용을 1로 계산하기 때문이다.
Forwarding Tables
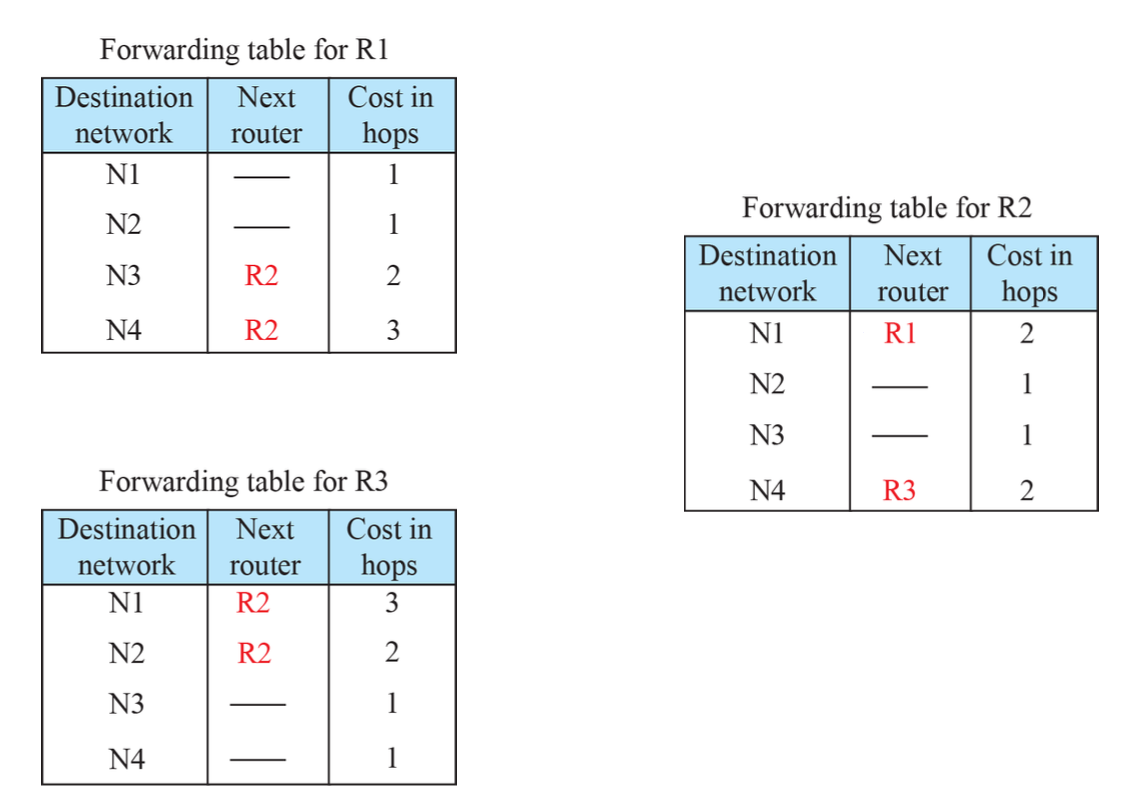
1번째 칼럼과 3번째 칼럼을 뺀 것이 DV이다.
Timers in RIP
- Periodic timer : 각 라우터는 25초~35초에서 random하게 정해진 주기를 가지고 이웃 노드에게 Advertisement Message를 전달한다.
- 트래픽 동시 발생을 회피하기 위해 25~30초 사이의 임의의 시간에 전송한다.
- Expiration timer : 180초 동안 어떤 network에 대한 소식을 듣지 못하면, 그 network 까지의 hop count = 16 (∞)로 설정한다.
- Garbage collection timer : 어떤 route에 대한 정보가 안들어올 때부터 일정시간(120s)이 지나면 forwarding table에서 지움
문제점
-
라우팅 트래픽 발생량
주기적으로 발생되는 RIP 메시지는 목적지 망 주소와 거리 정보를 포함하는 많은 목록의 라우팅 정보를 포함하므로 라우팅 트래픽 발생량이 많다. -
라우터의 성능 저하
짧은 주기로 발생되는 RIP 메시지를 수신할 때마다 라우터는 수신된 메시지의 목록의 각 항목을 자신의 거리 테이블의 관련 항목과 비교하고 처리해야하므로 라우터의 성능 저하가 초래하게 된다. -
느린 전파 속도
라우팅 테이블 갱신 정보는 한 번에 하나의 라우터씩 전달되기 때문에 갱신 정보의 전파 속도가 느리다. -
차등화된 라우팅 불가
RIP의 모든 링크 비용은 1로 설정되므로 요구되는 서비스 유형(예, 거리보다 전송 속도가 높은 경로 선택)에 따라 차등화된 경로 선택이 원천적으로 불가능하다.
OSPF (Open Shortest Path First)
Link-State routing 기반의 intra-domain routing protocol이다.
OSPF 메세지는 UDP/TCP 등을 사용하지 않고, 직접 IP 데이터그램(프로토콜 ID : 89)에 의해 운반된다.
Routing Protocol로도 분류되지만, 라우터들간의 Link-State를 공유하는 protocol로도 쓰인다.
원리
- 각 라우터는 링크의 상태에 변화가 있는 경우에만 변화의 내용을 모든 라우터에게 flooding함으로서 갱신된 상태 정보를 모든 라우터와 동시에 공유한다.
- 각 라우터는 동일한 정보를 갖고 있는 상태에서 글로벌 네트워크 상태 정보에 다익스트라 알고리즘(Dijkstra Algorithm)을 실행하여 모든 라우터에 대한 최소 비용 경로 계산한다.
- 최소 비용 경로 계산 결과에 따라 라우팅 테이블 갱신한다.
1번이 OSPF의 역할이다.
장점
- RIP에 비해 적은양의 라우팅 트래픽을 유발한다.
- 부분 갱신(Partial Update): RIP보다 라우팅 정보 관련 갱신 회수가 줄어들어 빈번한 처리 지연 발생으로 인한 라우터의 성능 저하 방지한다.
- 빠른 재수렴 (Fast Reconvergence): flooding 방식의 갱신 정보 전송으로 인해 갱신 정보 전파 속도가 빠르다.
- 링크 특징(예, 전송속도)에 따라 링크 비용을 다르게 설정하는 것을 허용한다.
절차
- OSPF가 설정된 라우터 간에 주기적(10초)으로 헬로(hello) 패킷을 주고 받으며 인접 이웃 관계를 형성하여 이웃관계를 찾는다.
- 각 라우터는 갱신된 링크 상태 정보가 포함된 링크 상태 패킷(LSP-Link State Packet) 또는 LSA(Link State Advertisement) 생성한다.
- LSA를 모든 라우터들에게 flooding함으로써 링크 상태 갱신 정보 공유한다.
- 모든 라우터는 동일한 링크 상태 데이터베이스(LSDB – Link State DataBase) 유지한다.
- 각 라우터는 자신의 LSDB에 대해 다익스트라 알고리즘을 적용하여 모든 라우터에 대한 최소 비용 경로 계산한다.
- 계산된 최소 비용 경로를 바탕으로 라우팅 테이블 설정한다.
1,2,3,4가 OSPF의 역할이다.
Message Format
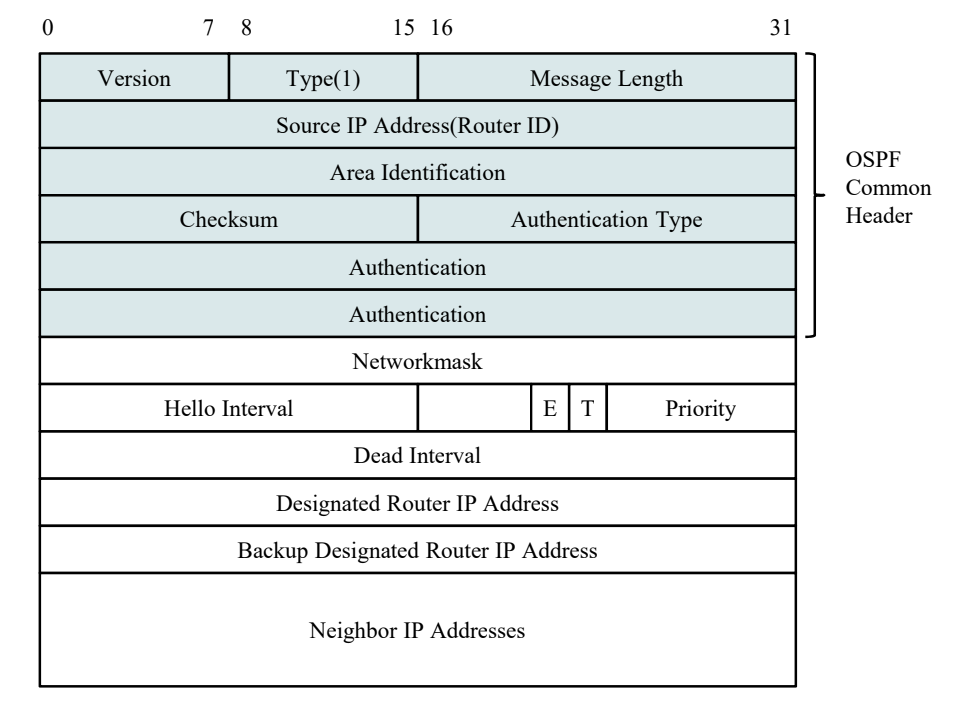
- Priority: DR 선정을 위한 우선순위 정보
- Neighbor IP Address: 해당 필드에 이웃 IP 주소가 적혀서 도착한다.
Hello Packet
이웃 관계 설정을 위해 멀티캐스팅을 이용한다. DR이 존재하는 경우, DR 라우터와만 이웃관계를 설정한다.
DR (Designated Router)
OSPF에서 네트워크에 연결된 모든 라우터는 OSPF 프로세스를 실행하고, 이들 라우터 간에 OSPF 메시지 교환을 통해 라우팅 정보를 공유한다. 하지만 이러한 메시지 교환을 전체 네트워크에서 수행하는 것은 비효율적일 수 있다.
이 때, 모든 라우터에 flooding하는 것이 아닌 대표 라우터에게만 flooding하는 DR (Designated Router)이 사용된다.
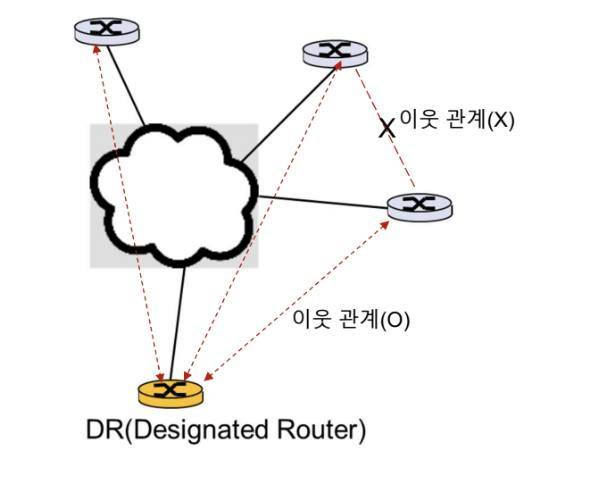
DR 선정
- Hello packet을 교환하면서 선정한다.
- OSPF가 우선순위가 가장 높은 라우터가 DR이 되고, 다음 라우터가 BDR(Backup Designated Router)이 된다.
- OSPF 우선순위가 동일하면 라우터 ID가 가장 높은 라우터가 DR이 되고, 그 다음 라우터가 BDR이 된다.
- DR이 다운되면 BDR이 DR이 되고 BDR은 새로 선정한다.
OSPF의 계층 구조
AS의 규모가 커지면, flooding으로 인한 라우터 트래픽과 네트워크 상태 정보의 양이 증가한다.
OSPF에서 하나의 AS에서 여러 개의 영역으로 나누어, 각 영역을 독립적으로 OSPF 라우팅을 수행한다. 영역 간의 라우팅은 백본 영역(Backbone Area)를 통해서 수행한다.
LSA
Packet

LSA 유형
Type 1 LSA - Router LSA
각 OSPF 라우터가 자신의 연결된 링크 정보를 포함하고 있는 LSA이다. 가장 대표적이며 대부분의 라우터가 보내는 LSP이다.
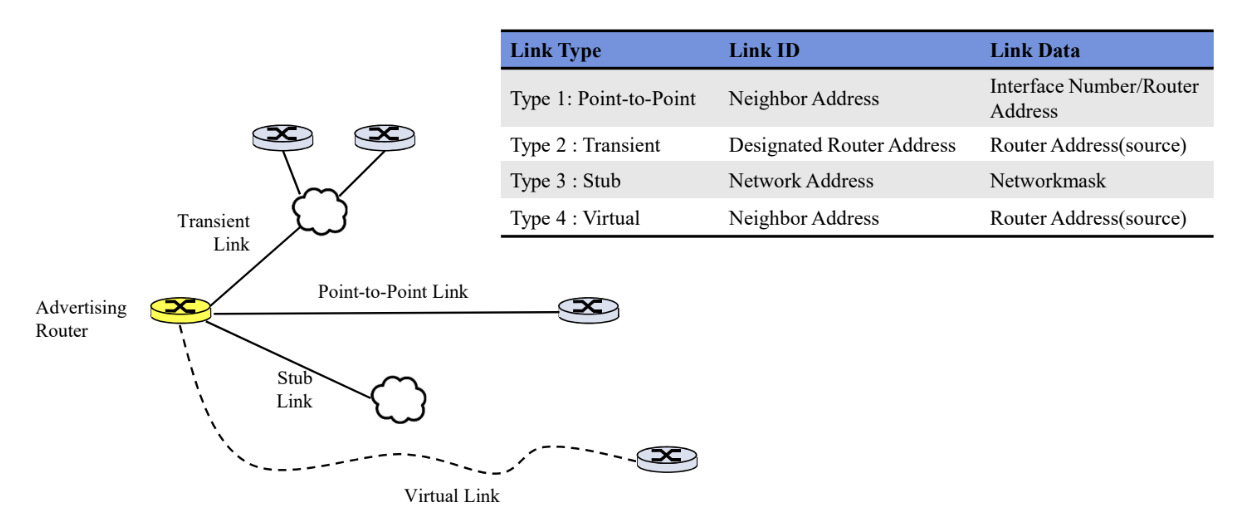
- Transient link : link to a transient network(여러 라우터 -> DR 라우터)
- Stub link : link to a stub network(라우터가 하나)
- Point-to-point link : point-to-point line
Type 2 LSA - Network LSA
OSPF 네트워크에서 DR (Designated Router)가 지정된 경우, DR은 해당 네트워크에 대한 Network LSA를 생성한다. 이 LSA에는 DR 및 BDR (Backup Designated Router)에 대한 정보가 포함되어 있다.
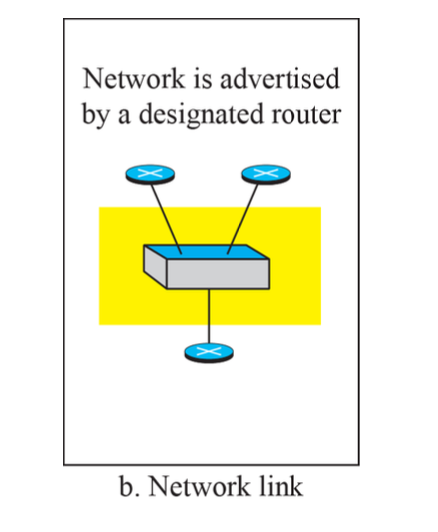
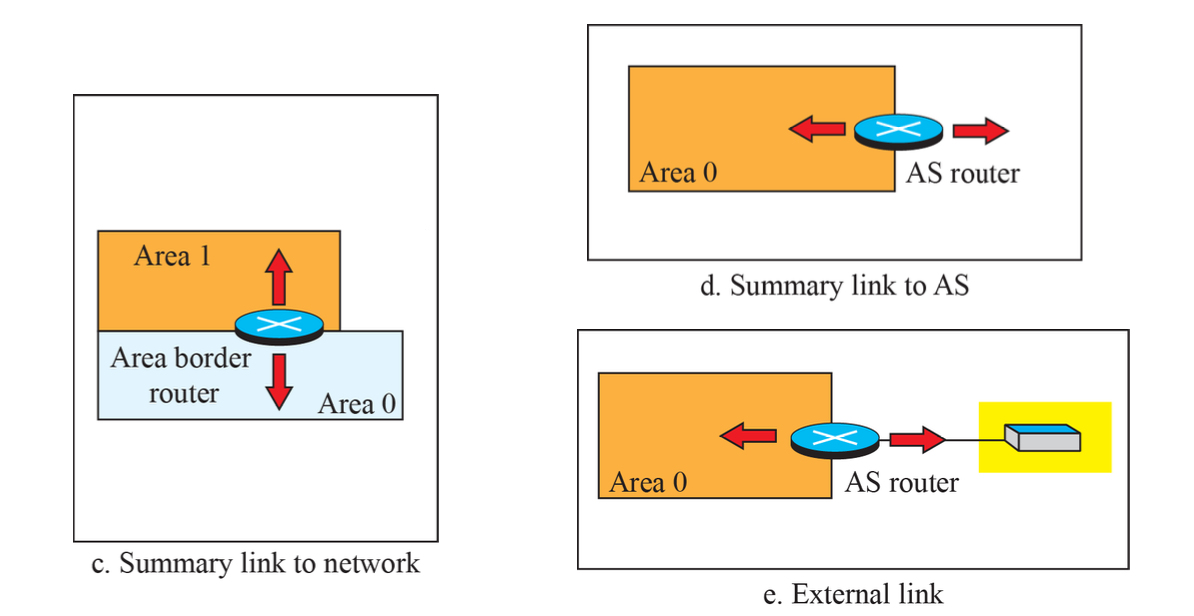
Type 3 LSA - Summary LSA (Summary link to network)
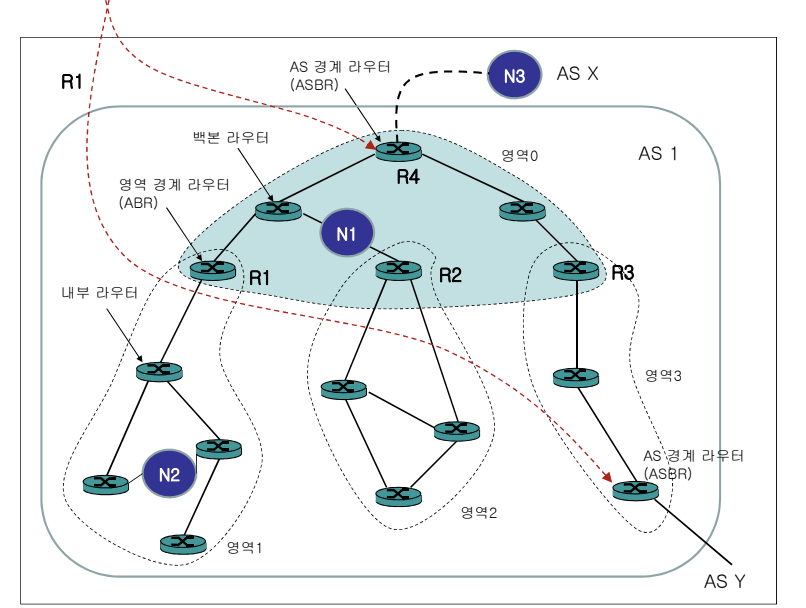
OSPF의 분할된 영역 간에 라우팅 정보를 교환하는 데 사용된다. ABR (Area Border Router)가 Type 3 LSA를 생성하여 다른 영역으로부터 받은 외부 라우팅 정보를 전달한다.
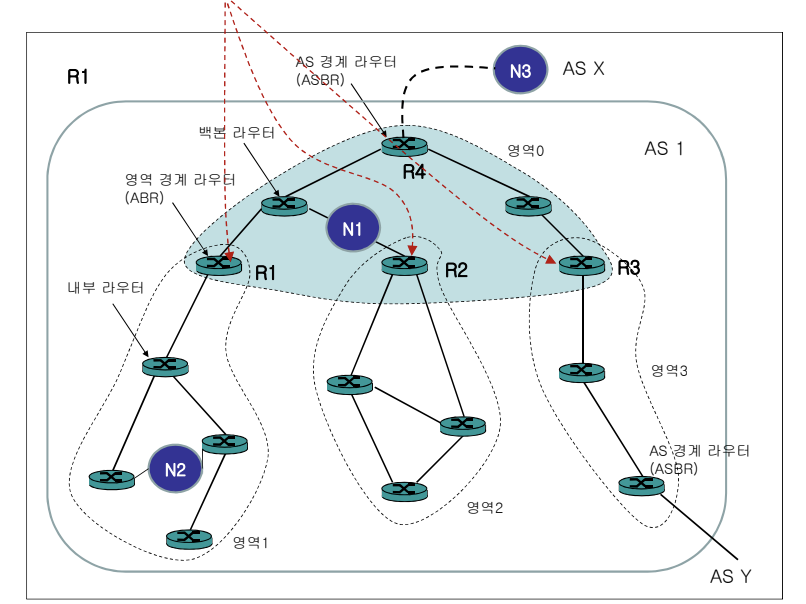
Type 4 LSA - ASBR Summary LSA (Summary link to AS)
OSPF의 다른 영역으로부터 외부 라우팅 정보를 가져올 때 사용된다. ABR는 이 정보를 Type 4 LSA로 변환하여 해당 정보를 다른 영역에 전파한다.
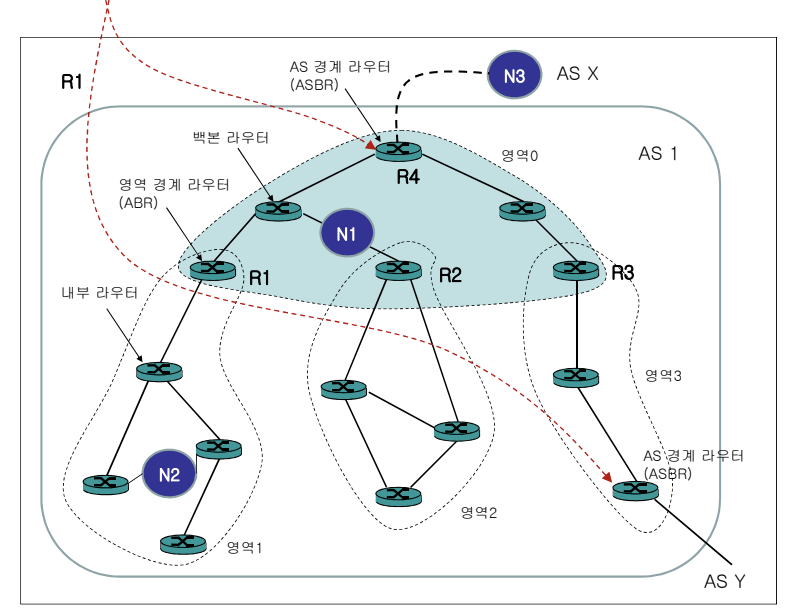
Type 5 LSA - External LSA
외부로부터 수신한 외부 라우팅 정보를 나타낸다. 이 LSA는 OSPF 네트워크에 외부 라우팅 정보를 주입하는 데 사용된다.
요약
BGP (Border Gateway Protocol)
Path Vector 기반의 AS간에 적용할 수 있는 유일한 inter-domain routing protocol이다.
- 모든 BGP 프로토콜들은 point-to-point protocol로 동작하며 TCP connection (port 179) 사용
- BGP를 수행하는 router 들은 서로 BGP peers (BGP speakers)가 되며 session 이라는 logical 연결을 맺음
BGP 표준 경로 속성 구분
- Well-known : 모든 라우터가 지원해야 하는 속성
- Optional : 선택적으로 지원 가능한 속성
- Mandatory : BGP UPDATE 메시지에 반드시 포함되는 속성
- Discretionary : BGP UPDATE 메시지에 포함되지 않아도 되는 속성
- Transitive : 수신한 후 다음 AS로 전달가능한 속성
- Intransitive : 수신한 후 다음 AS로 전달불가한 속성
AS-PATH 속성
목적지에 도착하기 위해 통과하는 AS의 목록이다. 순환 경로 탐지 가능하고, 반드시 구현되어야 한다.
- Well-known, mandatory
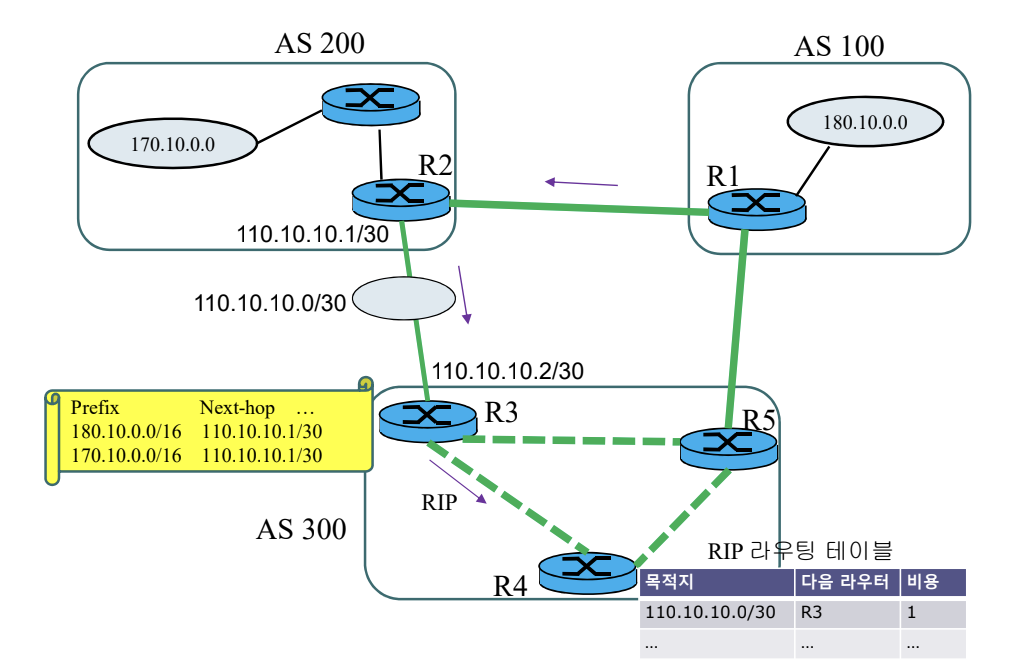
NEXT-HOP 속성
경로 벡터를 알려준 직전 AS의 라우터 주소를 알려준다.
NEXT-HOP 라우터의 네트워크 주소는 IGP(RIP/OSPF)에 의해 AS 내부 라우터에 공유된다.
- Well-known, mandatory
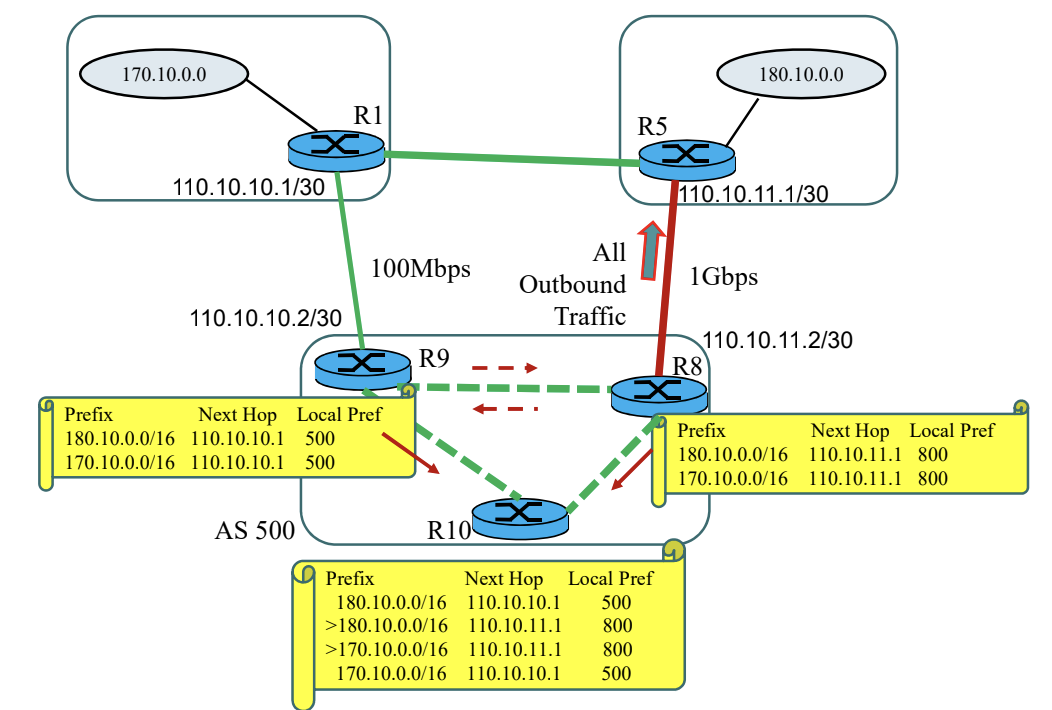
LOCAL-PREF 속성
AS의 외부로의 트래픽(Outbound Traffic)에 대한 최적 경로를 결정하기 위한 선호도를 지정한다. LOCAL-PREF를 확인해서 더 높은 것을 갱신한다.
- Well-known, Discretionary
MULTI-EXIT-DISC 속성
AS 내부로의 트래픽(Inbound Traffic)에 대한 최적 경로를 결정하기 위한 선호도를 지정한다. MED가 작은 경로로 전달하게 된다.
- Optional, Intransitive
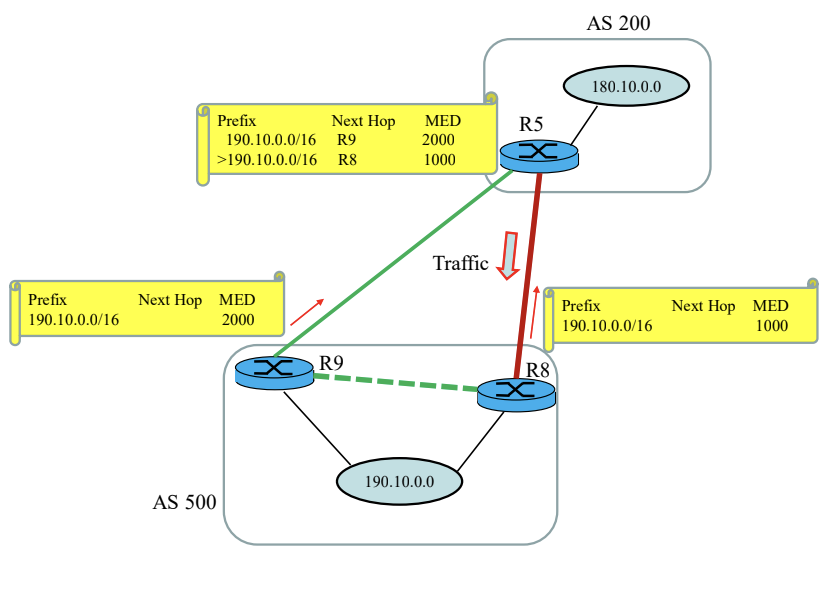
Local-Pref과 반대이다.
Hot-Potato Routing
AS 내부에서 NEXT-HOP에 대한 라우팅 비용이 가장 작은 경로를 선택한다.
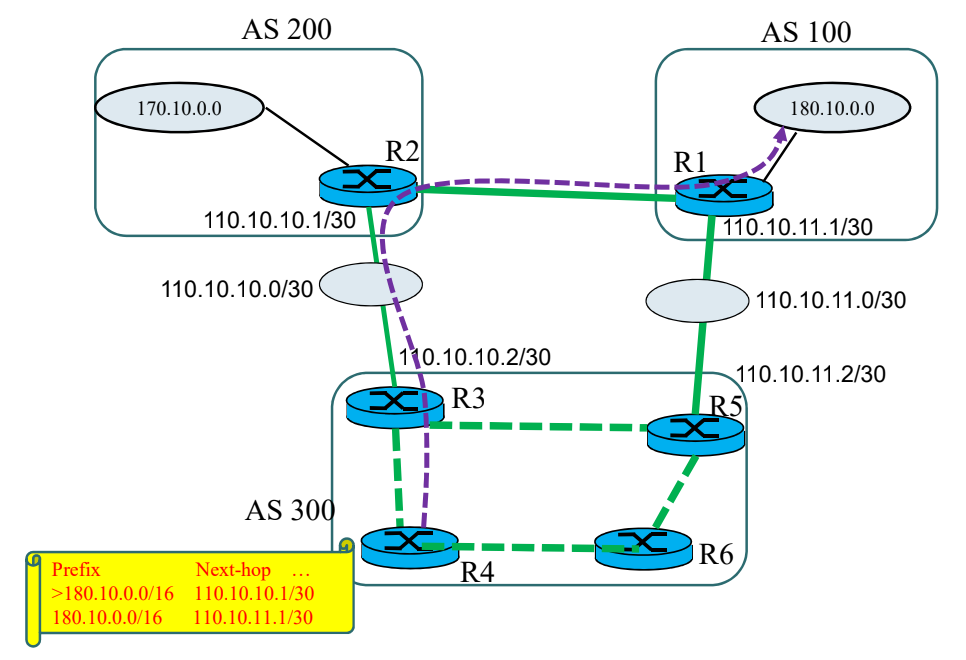
경로 선택 우선 순위
- LOCAL-PREF 속성이 가장 큰 경로
- MULTI-EXIT-DISC 속성이 가장 작은 경로
- AS-PATH 속성이 가장 짧은 경로 선택
- NEXT-HOP 속성이 비용이 가장 작은 경로 선택
BGP 동작 원리
BGP 구조: eBGP and iBGP
-
eBGP: AS 경계 라우터 간에 동작한다. TCP 연결로 eBGP 피어를 형성한다.
-
iBGP: AS 내의 라우터들 간에 동작한다. AS내의 라우터들 간에 1:1 TCP 연결을 통해 iBGP 피어를 형성한다.
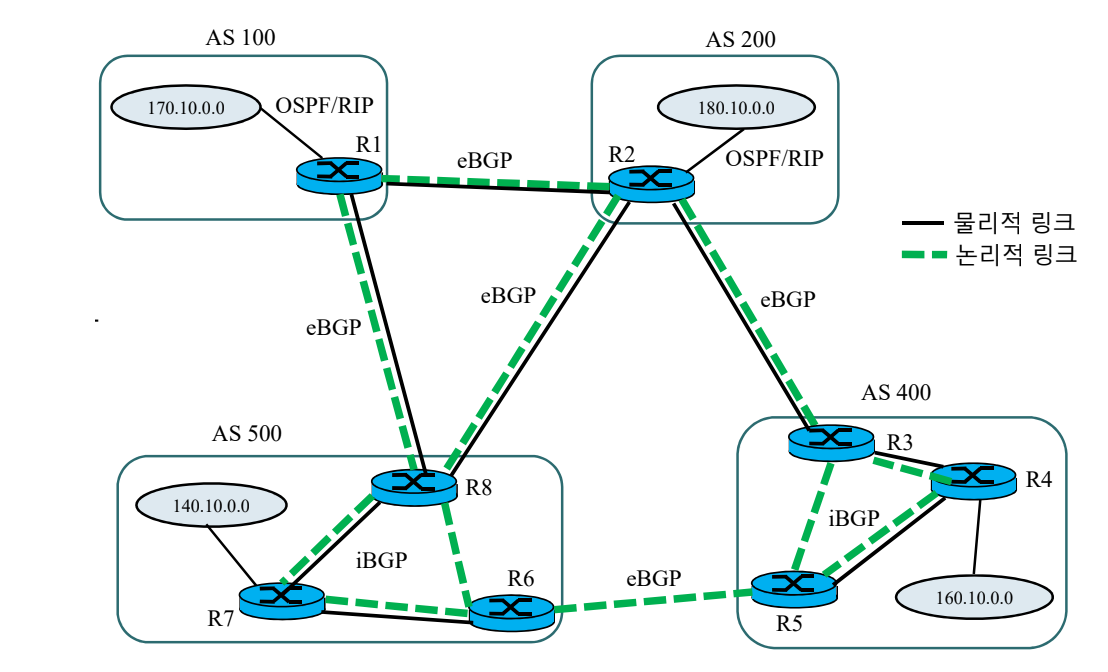
TCP 연결이기에 논리적 연결로도 가능하다.
AS 경계 라우터
eBGP, iBGP 내부 라우팅 프로토콜(RIP, OSPF)로 구현한다. EX). R8
AS 내부 라우터
iBGP, 내부 라우팅 프로토콜(RIP, OSPF) 구현한다. EX) R7
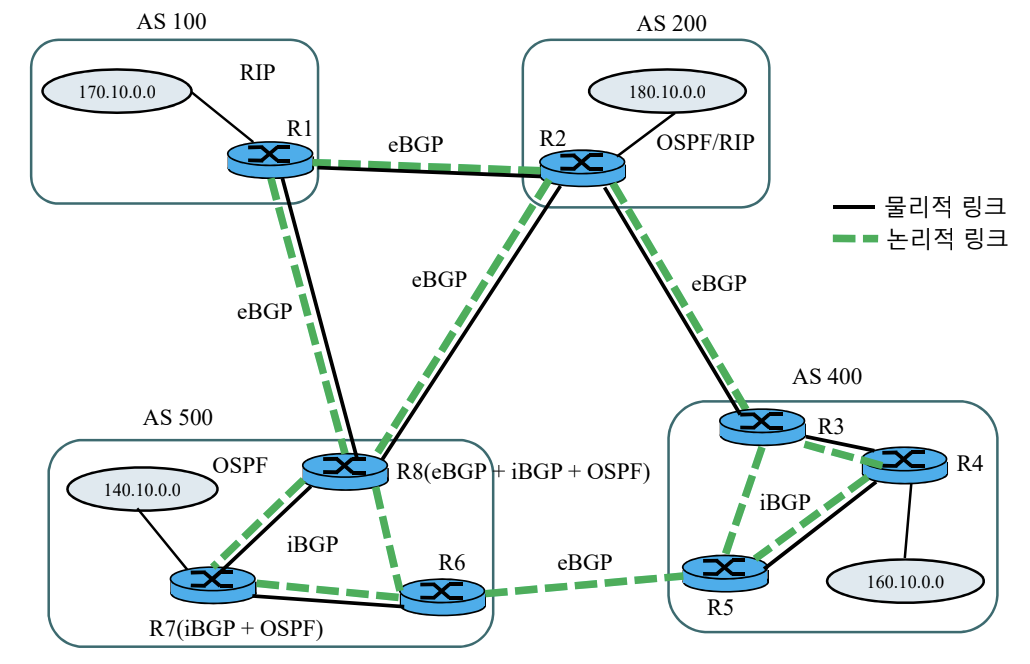
eBGP 동작 원리
- AS 경계 라우터 간에 path vector를 전달한다.
- 내부 라우팅 프로토콜로 생성한 path vector를 다른 AS로 전달한다.
- eBGP, iBGP로부터 수신한 path vector를 모두 다른 AS로 전달한다.
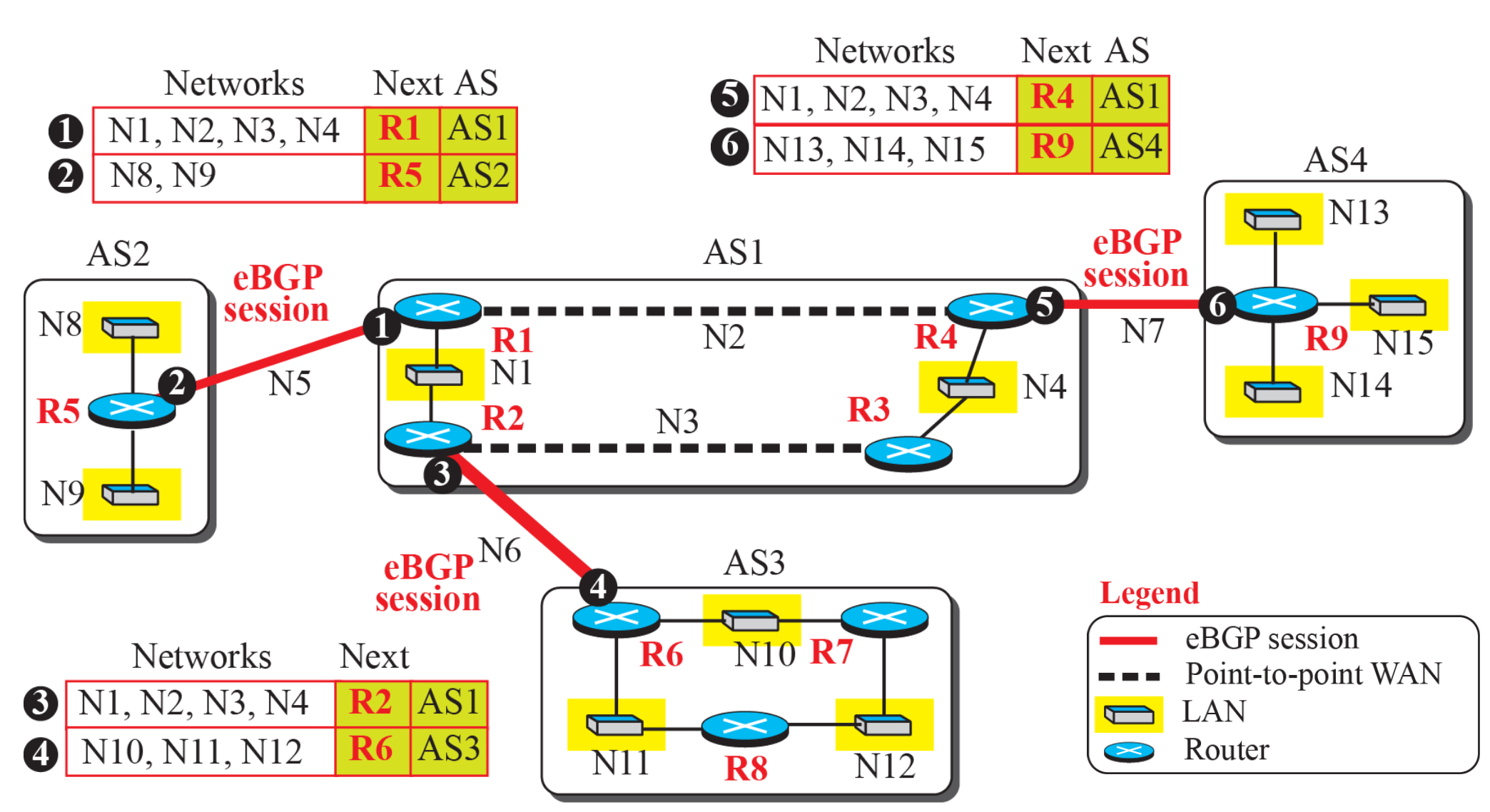
iBGP 동작 원리
- AS 내에서 모든 라우터들이 full mesh 형태로 iBGP 세션을 생성해 path vector를 교환한다.
- iBGP로 수신한 path vector를 전달하지 않는다.
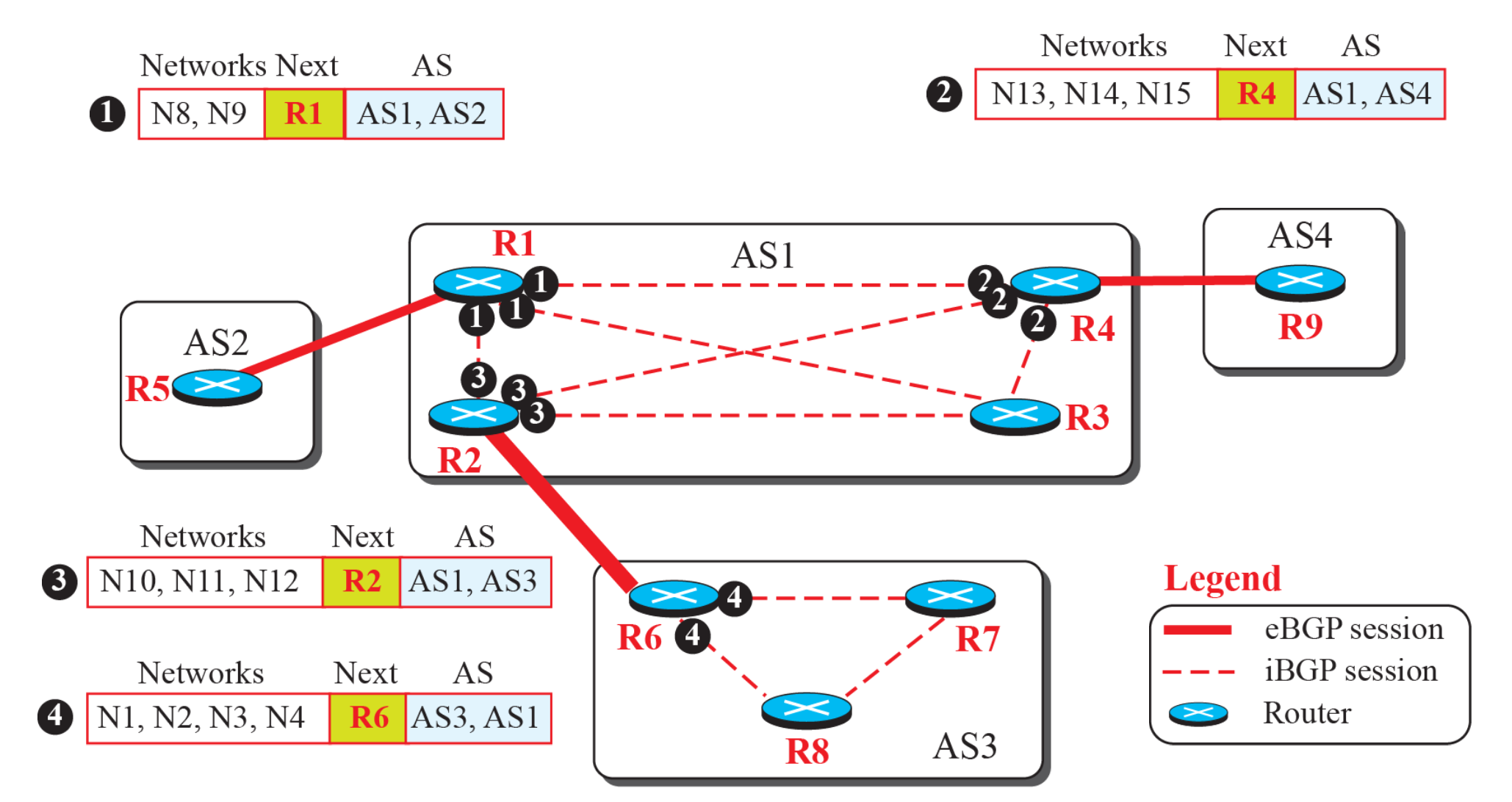
ICMP
IP의 특징으로 비연결형(상대방의 상태 미확인), 비신뢰적(전송 오류에 대한 미확인) 서비스라는 특징을 갖는다. 따라서 IP에 대하여 네트워크에서 발생하는 에러 메시지 및 제어 메시지를 전달하는 데 사용되는 프로토콜이다.
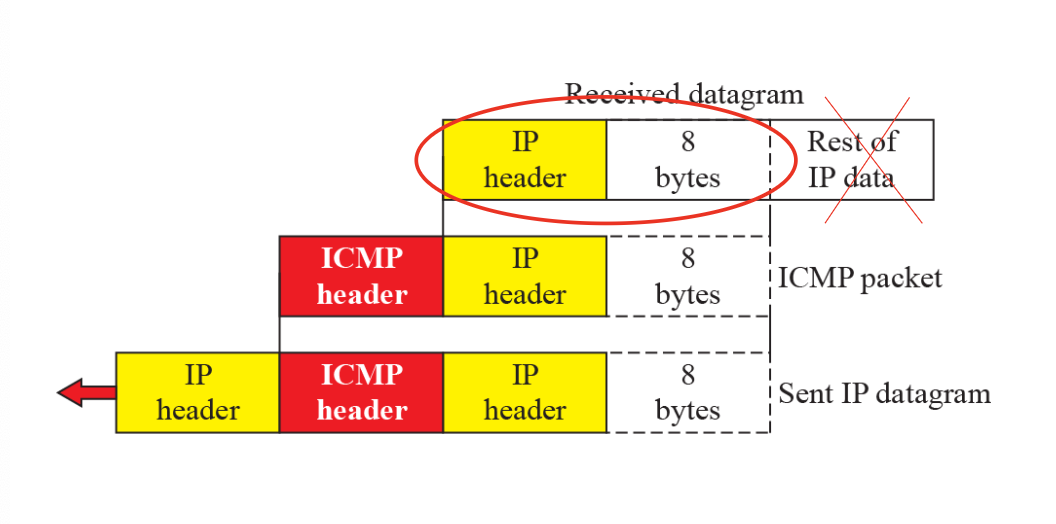
- IP 패킷을 제외하고 분리한다.
- ICMP 헤더를 붙인다.
- 다시 IP 헤더를 붙여서 sender에게 보낸다.
1번에서 IP 헤더와 3번에서의 IP 헤더 내용이 다르다. 3번에서의 IP의 source는 error reporting의 대상이고 destination은 누구지...?
서비스
- IP 데이터그램 전달 오류에 대한 보고 서비스
- IP 데이터그램 전달을 위한 상태 정보 질의 서비스(Ping)
Message Format
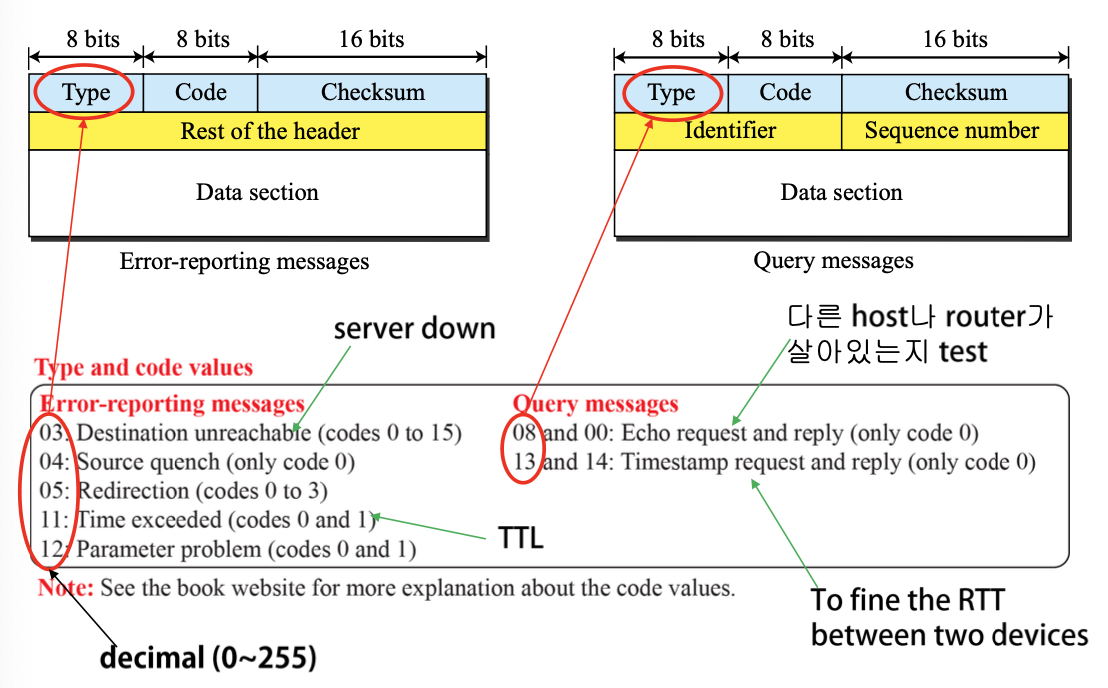
ICMP 오류 보고 메시지
오류 보고와 질의 메시지로 두 가지의 메시지 그룹으로 나눈다.
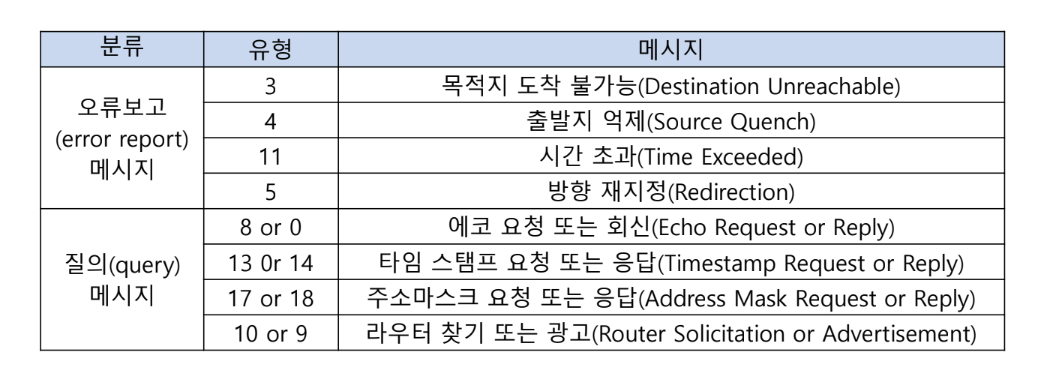
Error Report
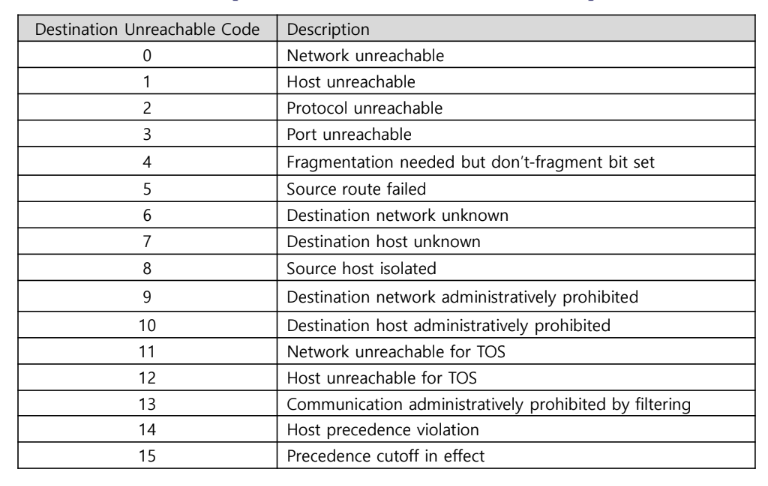
Destination unreachable
목적지 호스트 또는 네트워크에 도달할 수 없을 때 발생하는 오류 메시지이다.
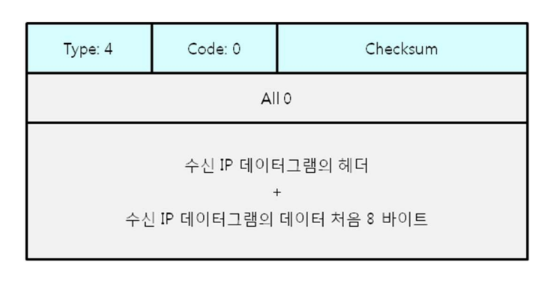
Source Quench
수신 호스트가 송신 호스트에게 트래픽을 감소시키도록 요청하는 메시지입니다. 네트워크 혼잡을 막기 위해 사용됩니다.
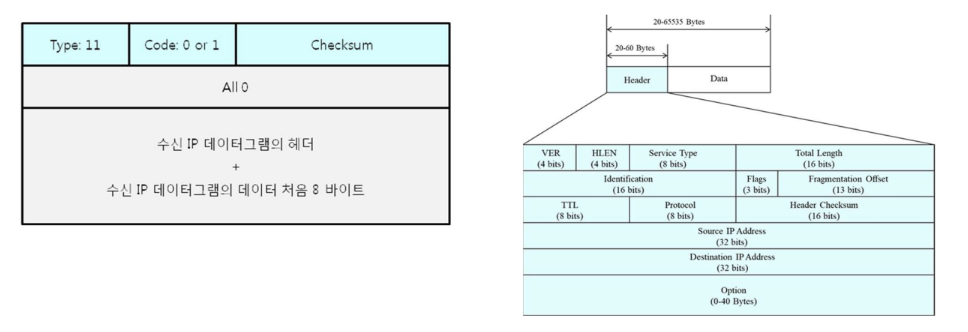
Time Exceeded
패킷이 목적지에 도달하지 못하고 TTL (Time-to-Live) 값이 0이 되거나, Fragmentation이 완료되기까지의 시간이 초과될 때 발생하는 오류 메시지이다.
Redirection
라우터가 호스트에게 다른 라우터를 통해 패킷을 전송하도록 경로를 변경하라고 알리는 메시지입니다.
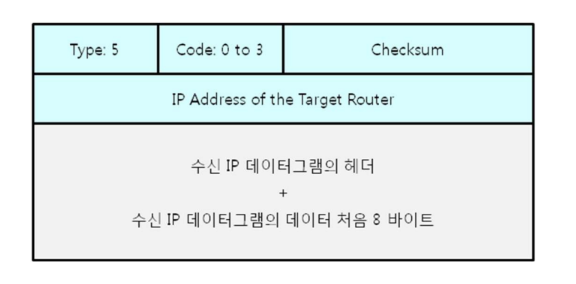
Parameter problem
IP 헤더나 데이터 부분에 오류가 있을 때 발생하는 메시지로, 잘못된 IP 헤더 또는 잘못된 TCP/UDP 헤더와 같은 오류를 나타낼 수 있습니다.
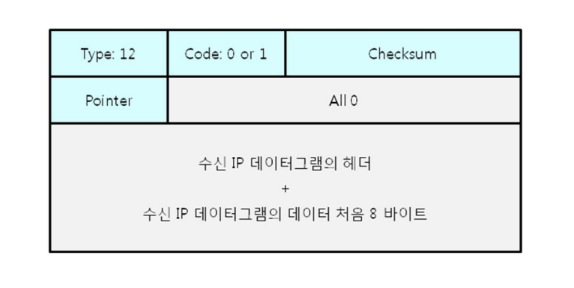
Query message
Echo request and reply
ping 명령을 통해 호스트 간에 상태를 확인하기 위해 사용되는 메시지이다. Echo Request는 요청을, Echo Reply는 응답을 나타낸다.
Address Mask Request or Reply
호스트가 자신의 IP 주소에 대한 넷마스크 정보를 알
지 못할 경우 사용한다. 하부 네트워크의 라우터에게 주소 마스크 요청 메시지를 직접 또는 방송(broadcast)으로 전송한다. 라우터는 주소 마스크 응답 메시지를 통해 넷마스크 정보를 제공한다.
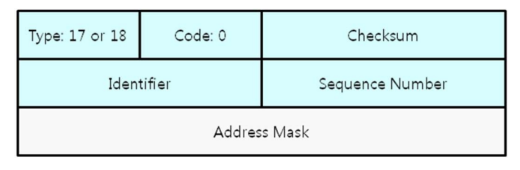
Timestamp request and reply
호스트의 현재 시간을 요청하고 응답하기 위해 사용되는 메시지이다.
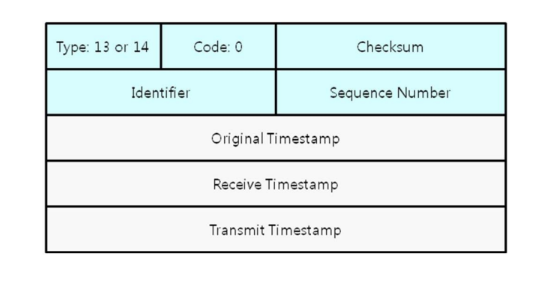
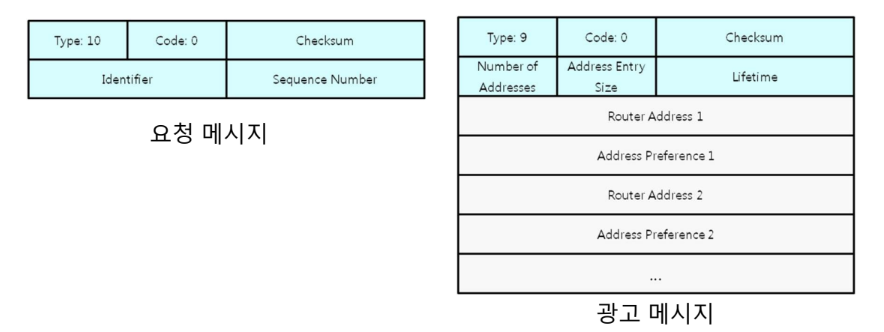
Router Solicitation or Advertisement
호스트가 같은 네트워크의 라우터에 관한 정보를 얻기 위해 라우터 요청 메시지 방송한다. 라우터 요청 메시지를 받은 라우터는 라우터 광고 메시지를 사용하여 자신의 주소 정보를 전송한다. 라우터는 주기적으로 광고 메시지 전송 가능하다.
Debugging Tool
Query message를 통해 네트워크 상황을 파악할 수 있다.
Ping
특정 라우터나 호스트가 alive, responding하는지 확인한다. ICMP의 echo request and reply를 이용한다.
traceroute or tracert
traceroute (Linux) or tracert (Windows)
- source에서 destination까지 경로를 확인할 수 있다.
- ICMP echo-request message를 전송하지만, 중간에 echo-reply가 오는 것이 아니고 error-reporting messages(time-exceeded)가 도착한다.
- 이를 위하여 여러 개의 ICMP 메시지를 TTL 값을 1부터 증가시켜가면서 차례로 전송한다.
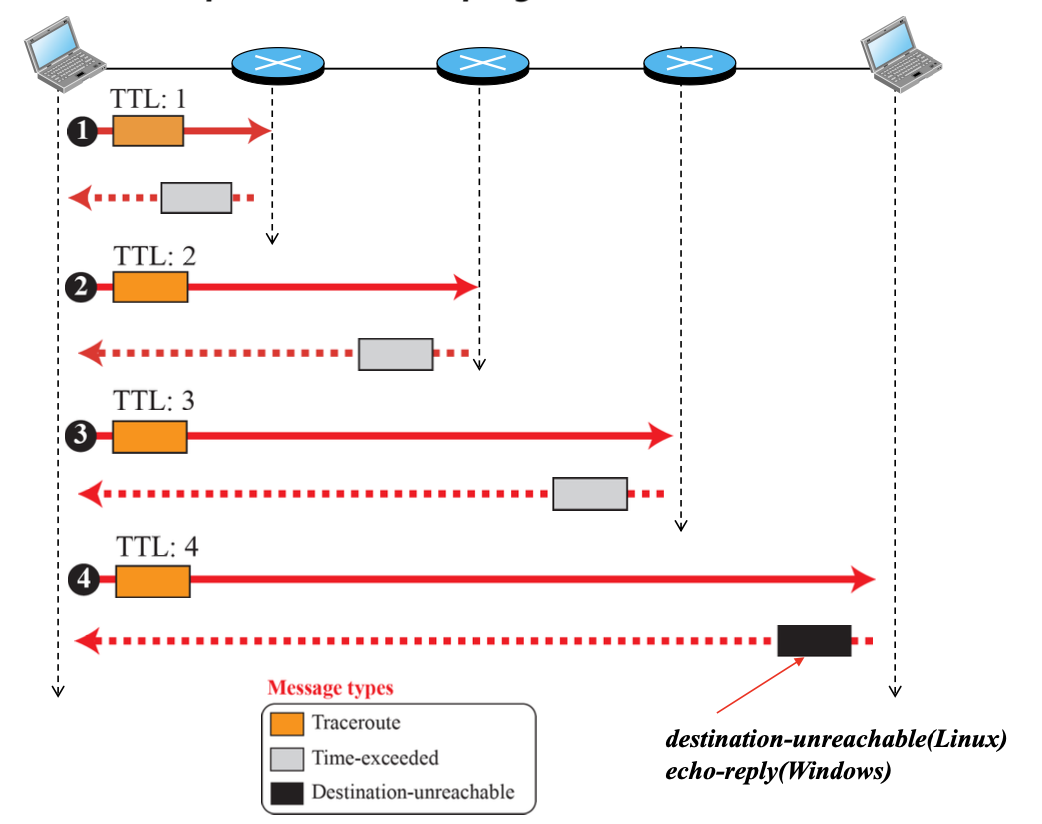
- TTL이 1인 ICMP echo-request message를 전송한다.
- error-reporting messages를 받는다.
- TTL이 2인 ICMP echo-request message를 전송한다.
- error-reporting messages를 받는다.
- 반복된다.
- destination host 도착한다.
ARP
인터넷에서는 주소를 IP주소와 MAC 주소를 사용한다. IP 주소는 인터넷 상에서 통신 장치를 지정할 때 사용하고 NIC가 물리적으로 통신할 때는 물리(MAC) 주소를 사용하게 된다.
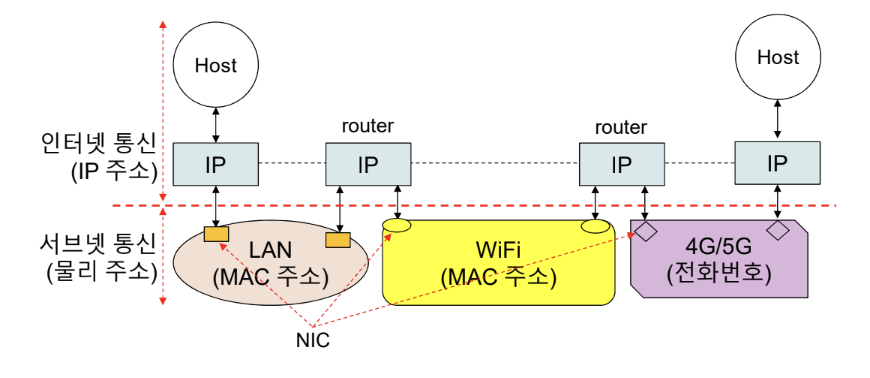
IP 데이터그램 전달 경우의 수
어떠한 경우에도 수신자의 IP 주소를 항상 알고 있다.
| 경우 | 송신자 | 수신자 |
|---|---|---|
| 1 | 출발지 호스트 | 목적지 호스트 |
| 2 | 출발지 호스트 | 지역 라우터 |
| 3 | 라우터 | 다음 라우터 |
| 4 | 라우터 | 목적지 호스트 |
송신자는 수신자의 IP주소는 알고 있지만, 물리 주소는 모르고 있는 상태이다. 따라서 송신자는 수신자 IP 주소에 대응되는 서브넷 주소(MAC 주소)를 획득해야 한다.
ARP 역할
수신자 IP 주소에 대응되는 서브넷 주소를 동적으로 변환한다.
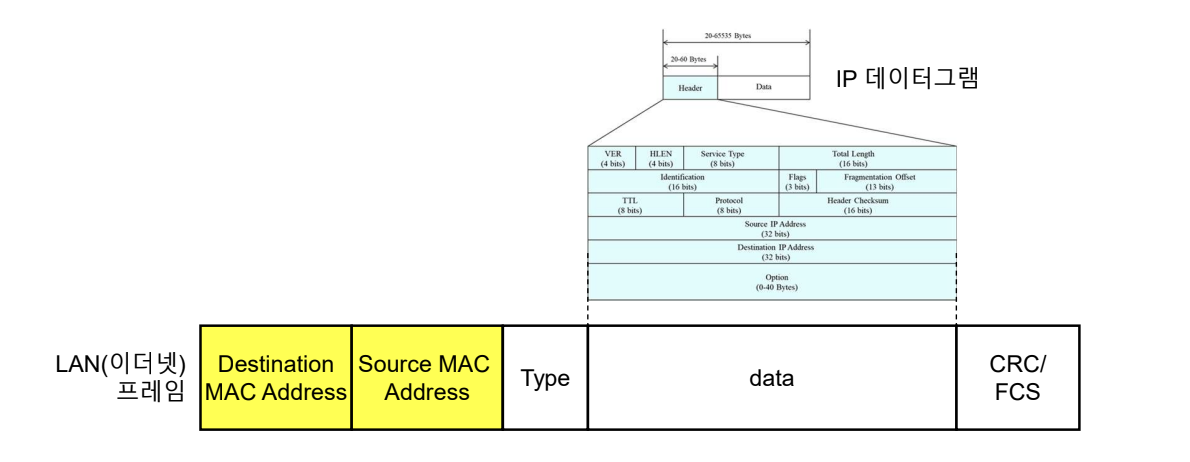
Message Format
ARP의 메시지는 Request와 Response를 사용하고, 모두 같은 format을 사용한다.
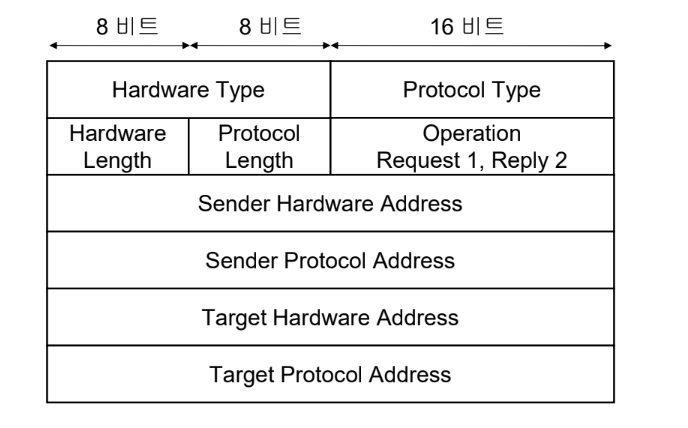
- 하드웨어 유형(Hardware Type): 하드웨어 유형 필드는 ARP가 동작하는 서브넷의 유형(예, 이더넷의 유형: 1)이다. ARP는 어떤 유형의 서브넷에서도 동작한다.
- 프로토콜 유형(Protocol Type): 프로토콜 유형 필드는 ARP를 사용하는 상위 계층 프로토콜(예, IP의 프로토콜 유형 값은 0x0800)이다. ARP는 어떤 상위 계층 프로토콜과도 함께 사용 가능하다.
- 하드웨어 길이(Hardware Length): 서브넷의 주소 길이를 바이트 단위로 표현(예, 이더넷의 하드웨어 길이는 6)한다.
- 프로토콜 길이(Protocol Length): 상위 계층 프로토콜이 사용하는 주소의 길이를 바이트 단위로 표현(예, IPv4의 프로토콜 길이는 4)한다.
- 동작(Operation): 메시지의 유형을 표현한다. ARP 요청 메시지(ARP Request)는 1, ARP 응답 메시지(ARP Reply)는 2이다.
- 송신자 하드웨어 주소(Sender Hardware Address): 송신자의 서브넷 물리 주소이다.
- 송신자 프로토콜 주소(Sender Protocol Address): 송신자의 상위 계층 프로토콜이 사용하는 주소이다.
- 목표 하드웨어 주소(Target Hardware Address): 목표 수신자의 서브넷 물리 주소이다. ARP 요청 메시지의 경우 목표 수신자의 하드웨어 주소를 알 수 없으므로 이 필드의 값은 0이다.
- 목표 프로토콜 주소(Target Protocol Address): 목표 수신자의 상위 계층 프로토콜이 사용하는 주소이다.
Encapsulation
- ARP의 동작 범위: 특정 서브넷 내에서만 동작한다.
- ARP 메시지 캡슐화: IP 데이터그램으로 캡슐화되어 전달될 필요가 없다. 서브넷의 데이터 전송 단위로 캡슐화되어 전달한다.
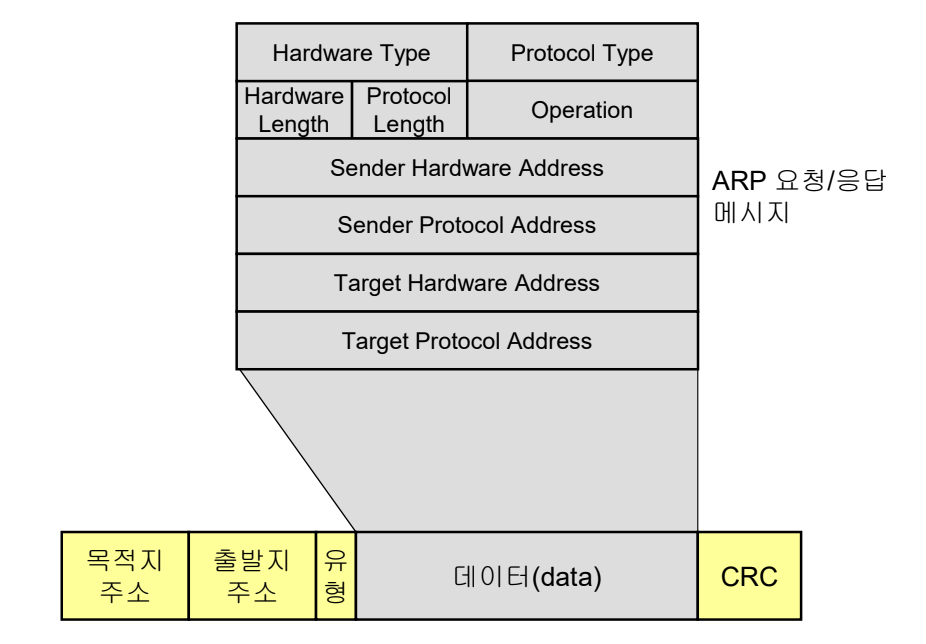
목적지 주소는 Broadcast 주소가 되어야 한다.
동작 절차
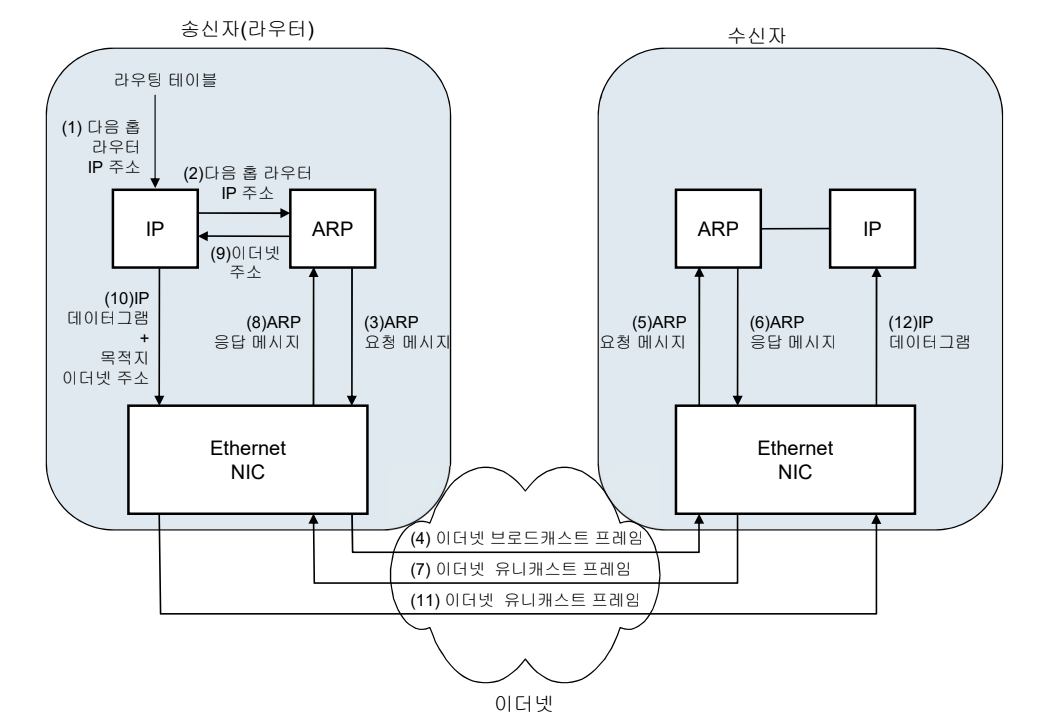
- 송신자 라우터의 IP는 목표 수신자인 다음 라우터의 IP 주소를 ARP에 전달하여 수신자의 이더넷 주소를 반환하도록 요구한다.
- 송신자 ARP는 목표 수신자 IP 주소를 포함하는 ARP 요청 메시지를 이더넷에 연결된 모든 수신자(호스트 또는 라우터)에게 broadcasting한다.
- ARP 요청 메시지에 포함된 IP 주소와 동일한 IP 주소를 가진 목표 수신자(다음 라우터)는 자신의 물리 주소를 담은 ARP 응답 메시지를 송신자에게 유니캐스트 프레임으로 전송한다.
- ARP 응답 메시지를 수신한 송신자 ARP는 목표 수신자의 이더넷 주소를 IP에게 전달한다.
ARP 캐싱
ARP를 매번 이더넷 주소를 요청하면, 시간이 소요된다.
기능
ARP 응답 메시지를 받은 송신자는 자신의 캐쉬 테이블(cache table)에 해당 수신자의 IP 주소와 물리 주소를 등록한다.
목적
동일한 IP 주소를 가진 수신자에게 데이터그램을 재전송할 때 캐쉬 테이블에서 신속하게 변환한다. 성능 향상에도 기여한다.
갱신
캐쉬 테이블에 저장된 주소 변환 정보는 일정 시간이 경과되도록 사용되지 않으면 삭제한다. 서브넷의 동적 변화를 적절하게 반영할 수 있게 하고 테이블 크기를 적절한 범위내로 유지한다.
IP Forwarding
라우팅: 최적의 경로를 찾는 것
포워딩: IP 패킷을 실제로 전송하는 작업
Connectionless
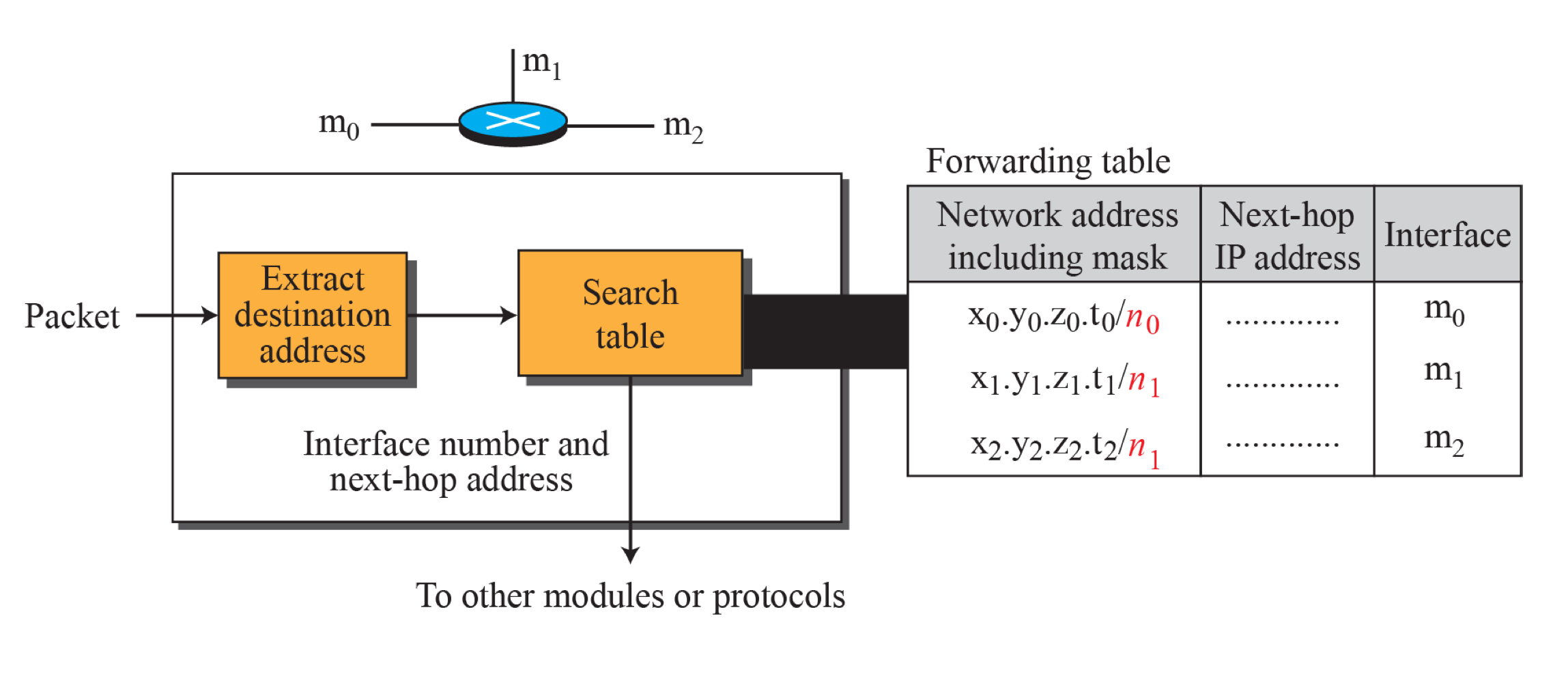
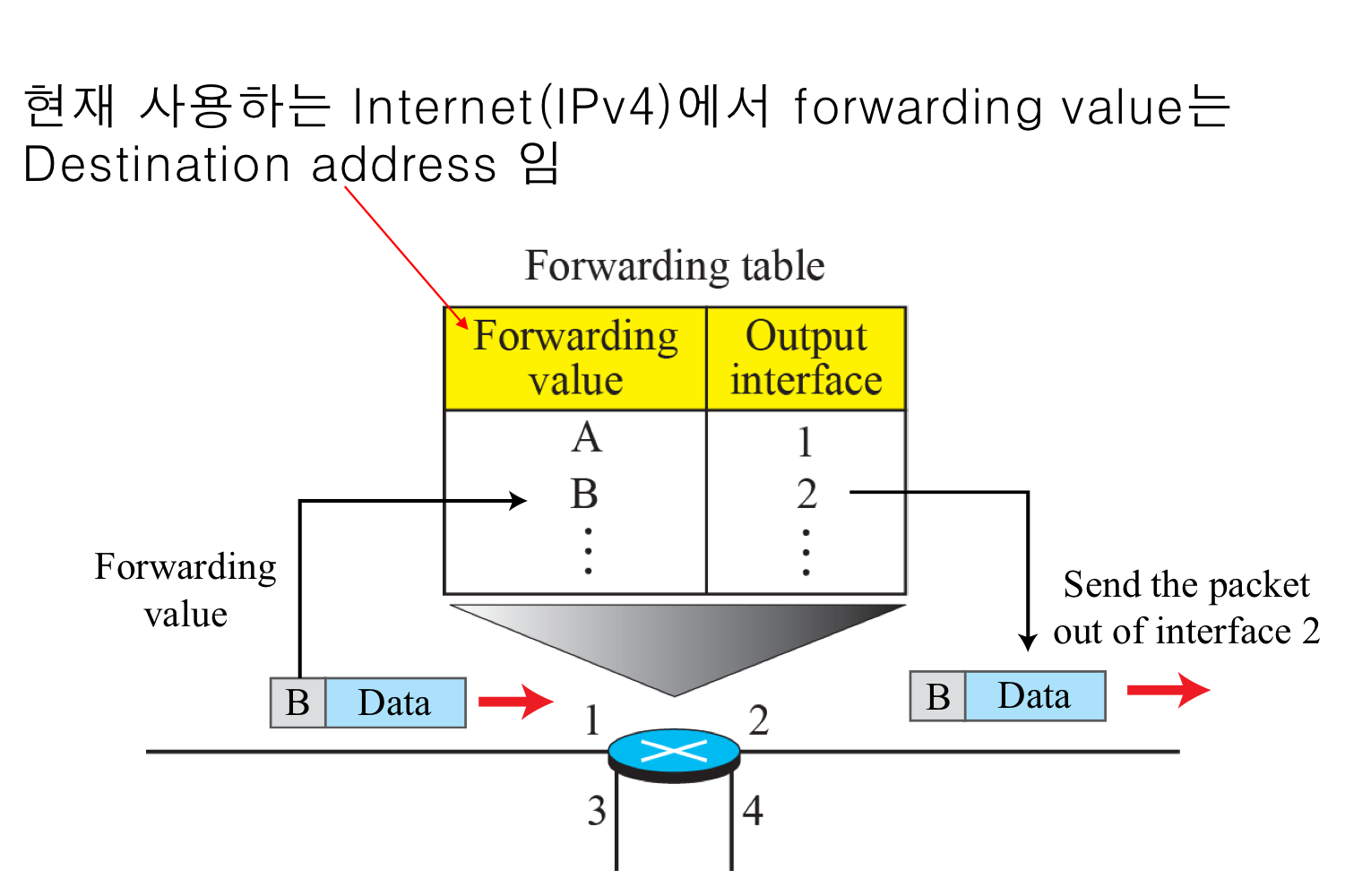
- 패킷으로부터 Destination address를 조회한다.
- Forwarding Table을 참고 한다.
- 패킷을 해당 interface로 전송한다.
hop은 라우터를 의미?

Forwarding table에 가장 긴 destination 부터 위로 정렬한다. 그러면 상위 row에서부터만 비교하여 매치될 경우, forwarding한다. Longest Matching 방식.

Default address는 0.0.0.0/0으로 작성한다.
Bidirectional Protocols
Piggybacking을 이용한다. 자신의 데이터의 정보를 포함하여 ACK 번호에 끼워서 보낸다.
Network Layer
Encapsulation & Decapsulation
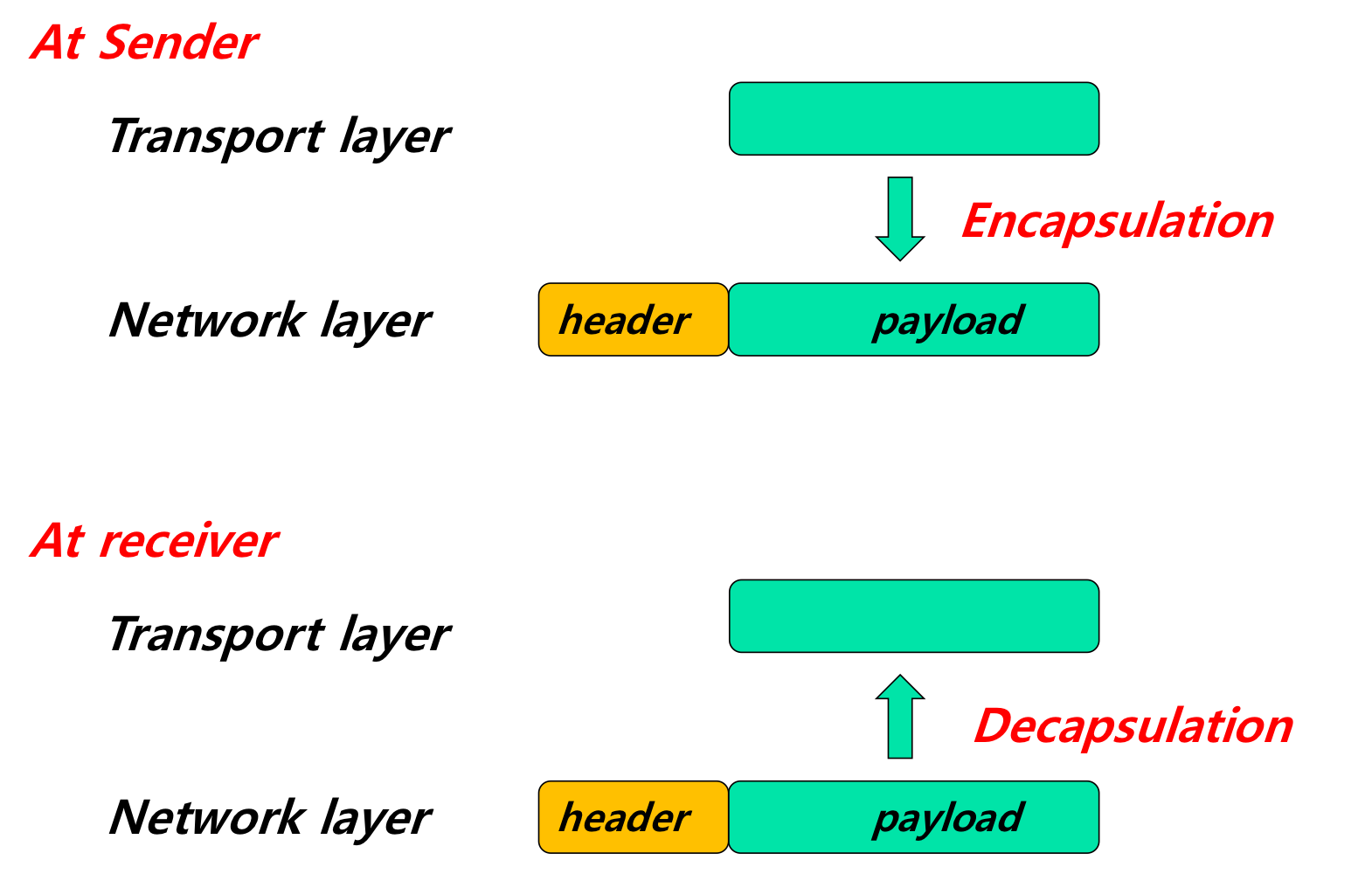
payload == sdu
Routing & Forwarding
Routing: 가장 좋은 경로를 찾는 것
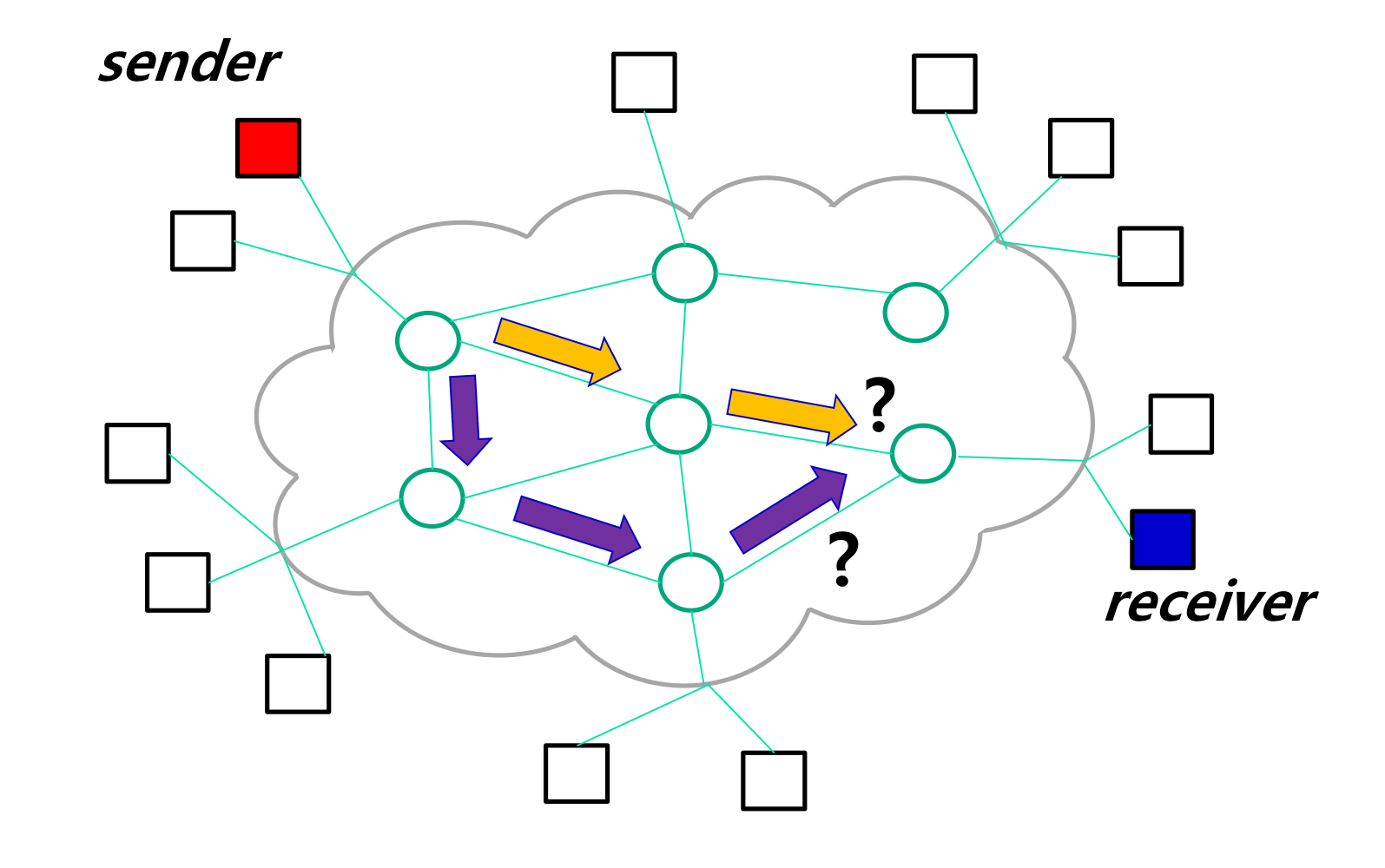
네트워크 계층 헤더의 Source IP Address와 Destination IP Address를 통해 찾아간다.
Forwarding Table(Routing Table)
Other Service
- Error Control: 가능하지만 4계층에서 처리
- Flow Control: 가능하지만 4계층에서 처리
- Congestion Control: 가능하지만 4계층에서 처리
- Quality of Service: 서비스별 loss 허용치(동영상의 노이즈, ...)
- Security(IPsec)
전송 과정
- Request 패킷 전송
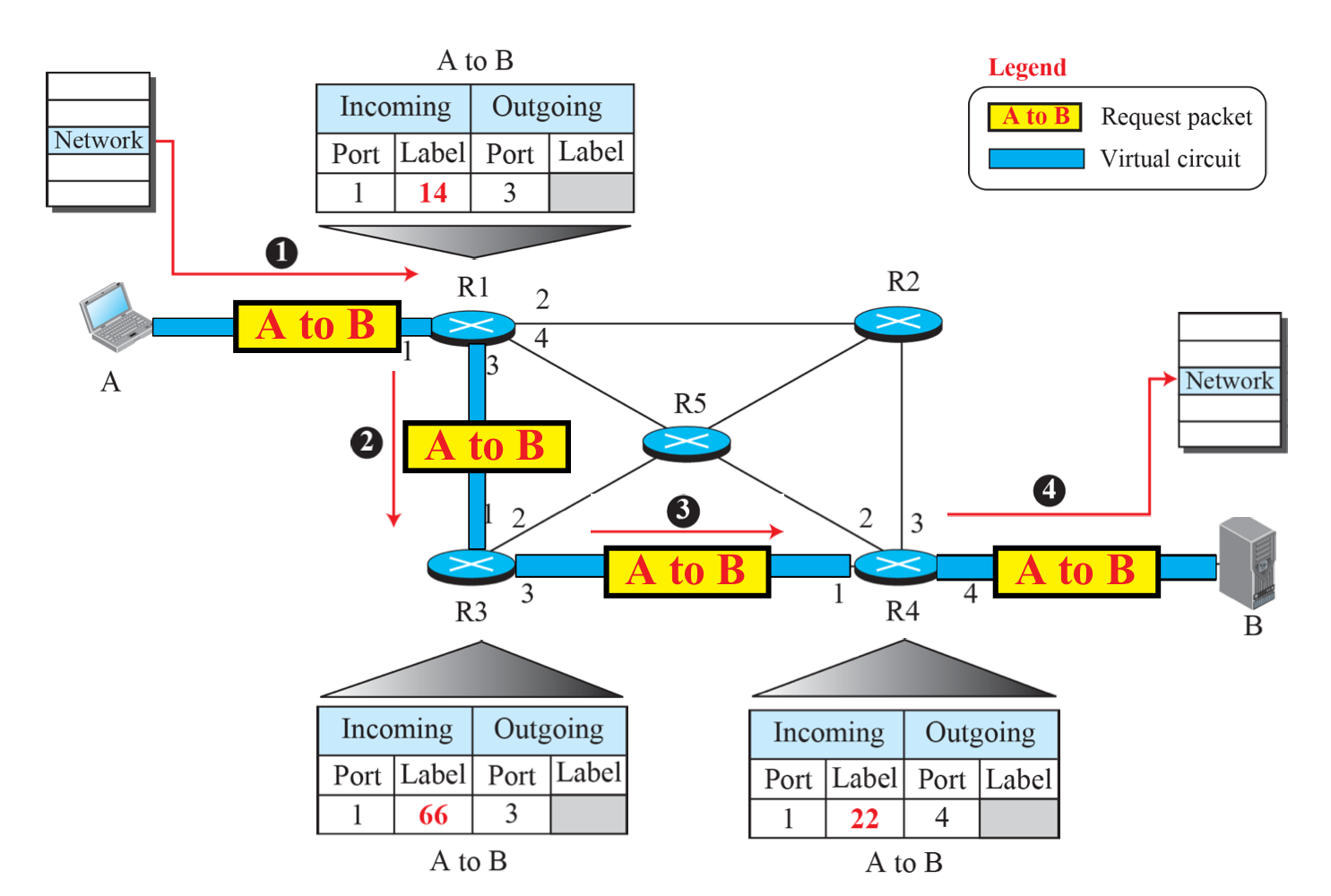
- Request 패킷을 통해 A->B을 Forwarding Table에 Incoming 레이블을 메모한다.
- Outgoing 레이블 작성
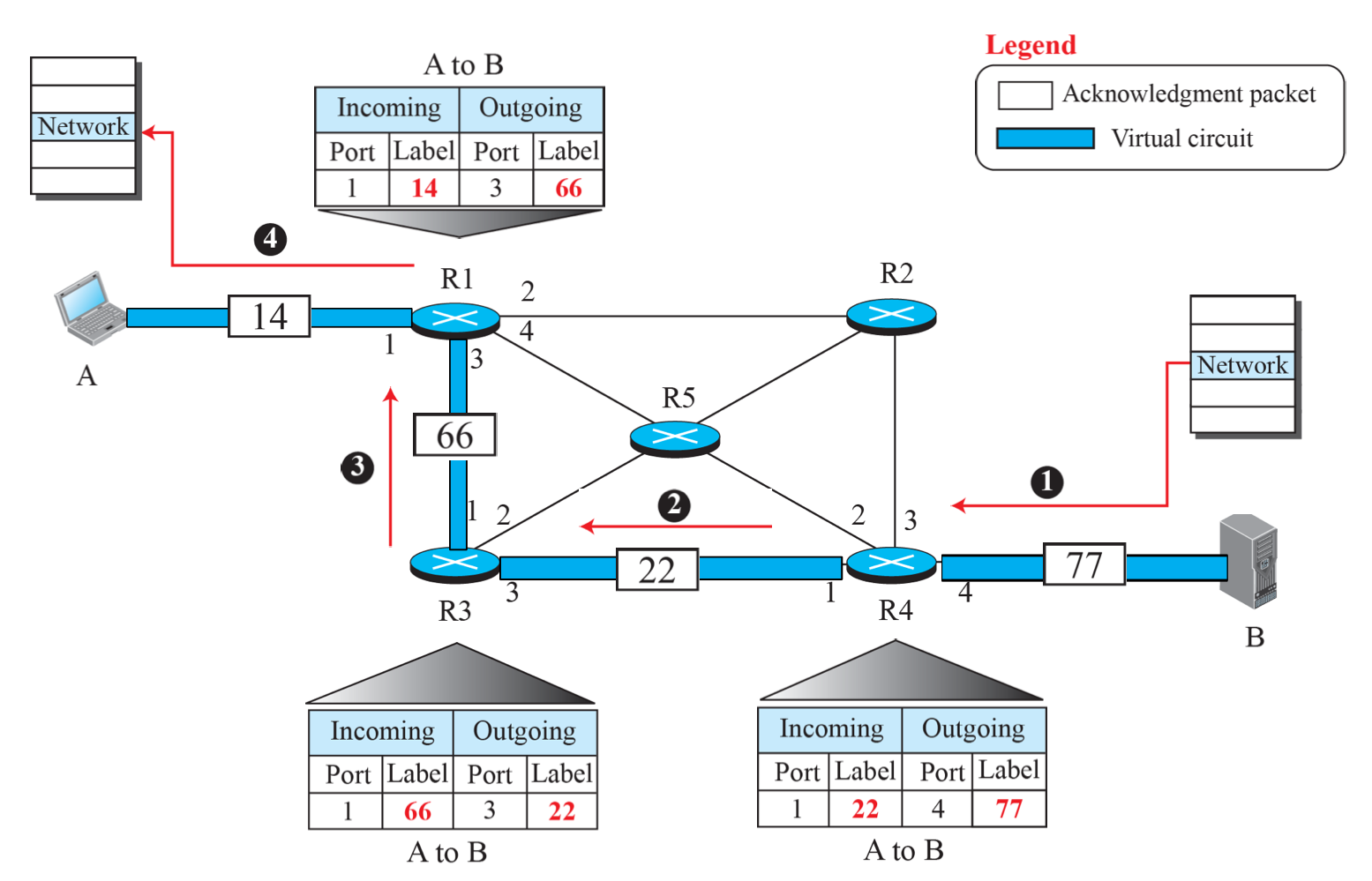
- B에서 연결 수립
- 각 라우터에서 Incoming 레이블을 이전 라우터에 Outgoing 레이블 메모하게 한다.
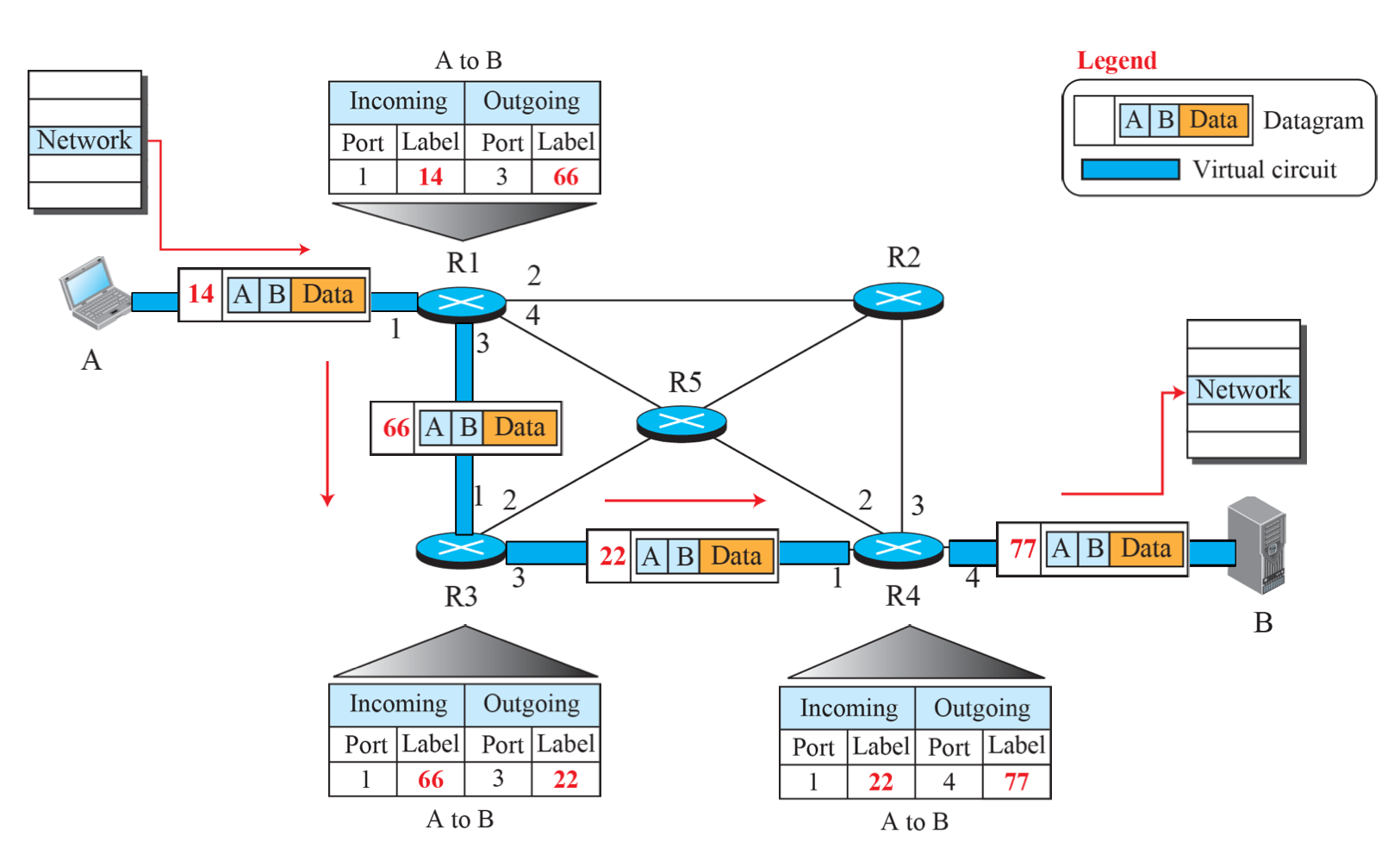
- 데이터 전송
IPv4 Address
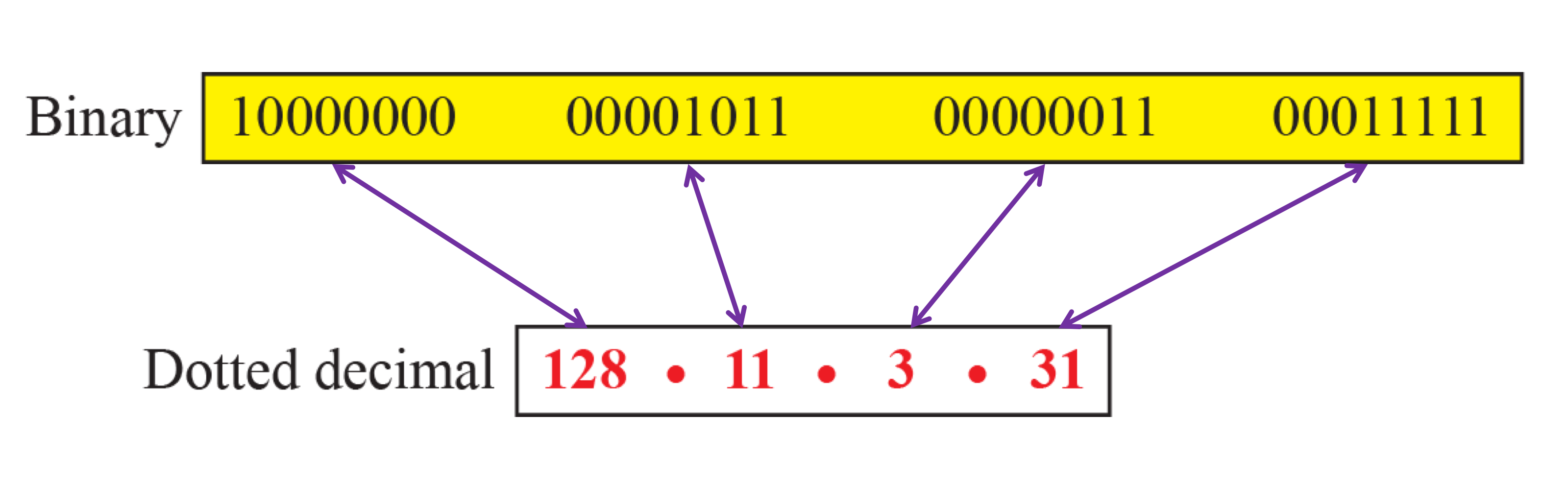
- 32 bit
- 4바이트 IP 주소 뒤에
/#를 붙여 prefix의 길이 표시
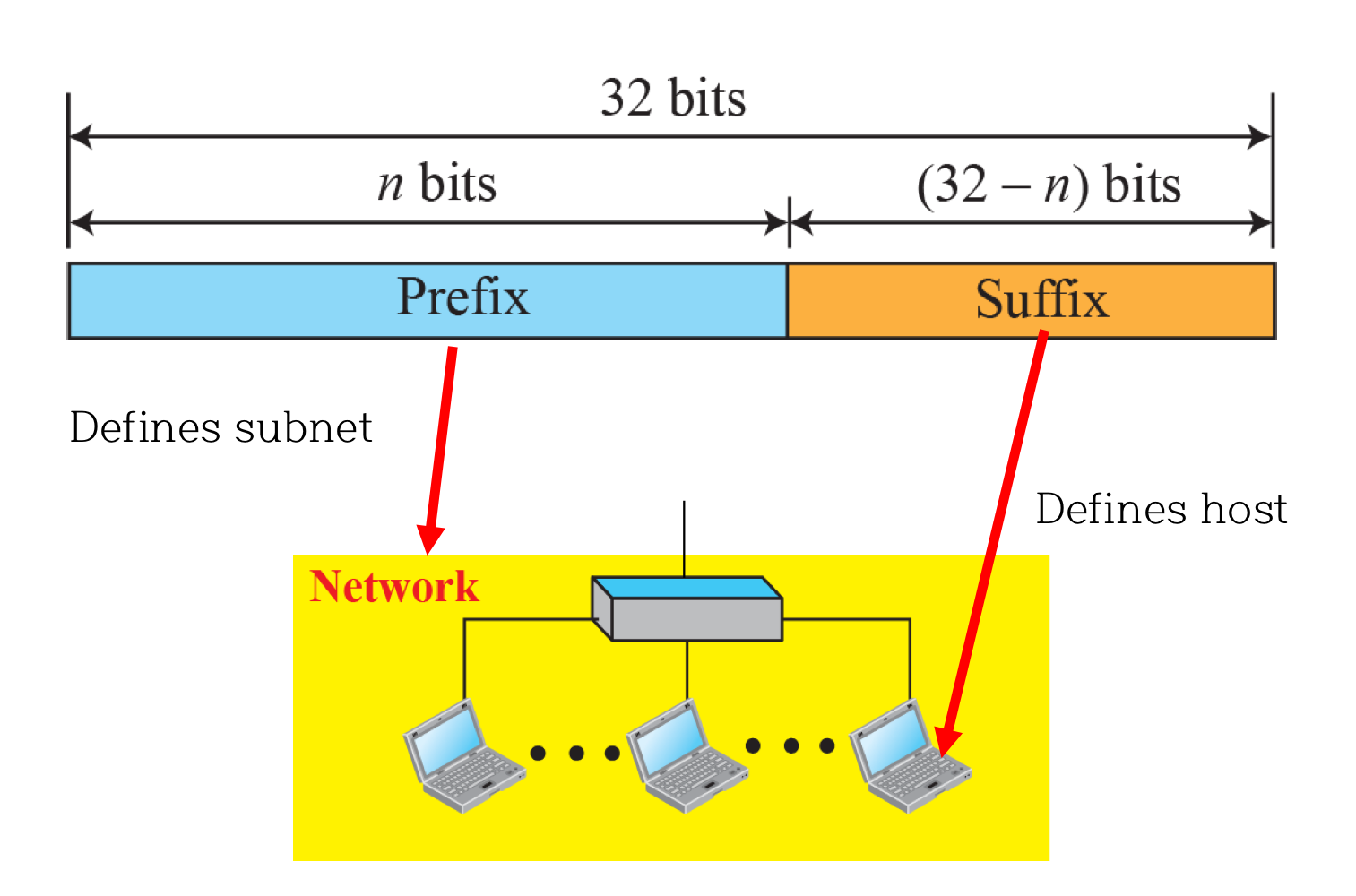
- Prefix: Network Address
- Suffix: Host Address
서브넷 마스크
- 서브넷 마스크: 네트워크 주소만을 추출하기 위한 마스킹
- 서브넷 주소: 서브넷 마스크와 IP주소의 AND 연산 결과
Window 10 IP 주소 및 subnet mask 확인 방법: cmd -> ipconfig
167.199.170.82/27
- 네트워크 주소의 비트 개수: 27
- 호스트 주소의 비트 개수: 32-27=5
- IP주소 비트 표현: 10100111 11000111 10101010 010/10010
- (00000~11111)32개의 주소를 가질 수 있다.
- 서브넷 마스크: 11111111 11111111 11111111 111/00000
- 서브넷 주소: 10100111 11000111 10101010 010/00000
네트워크 주소
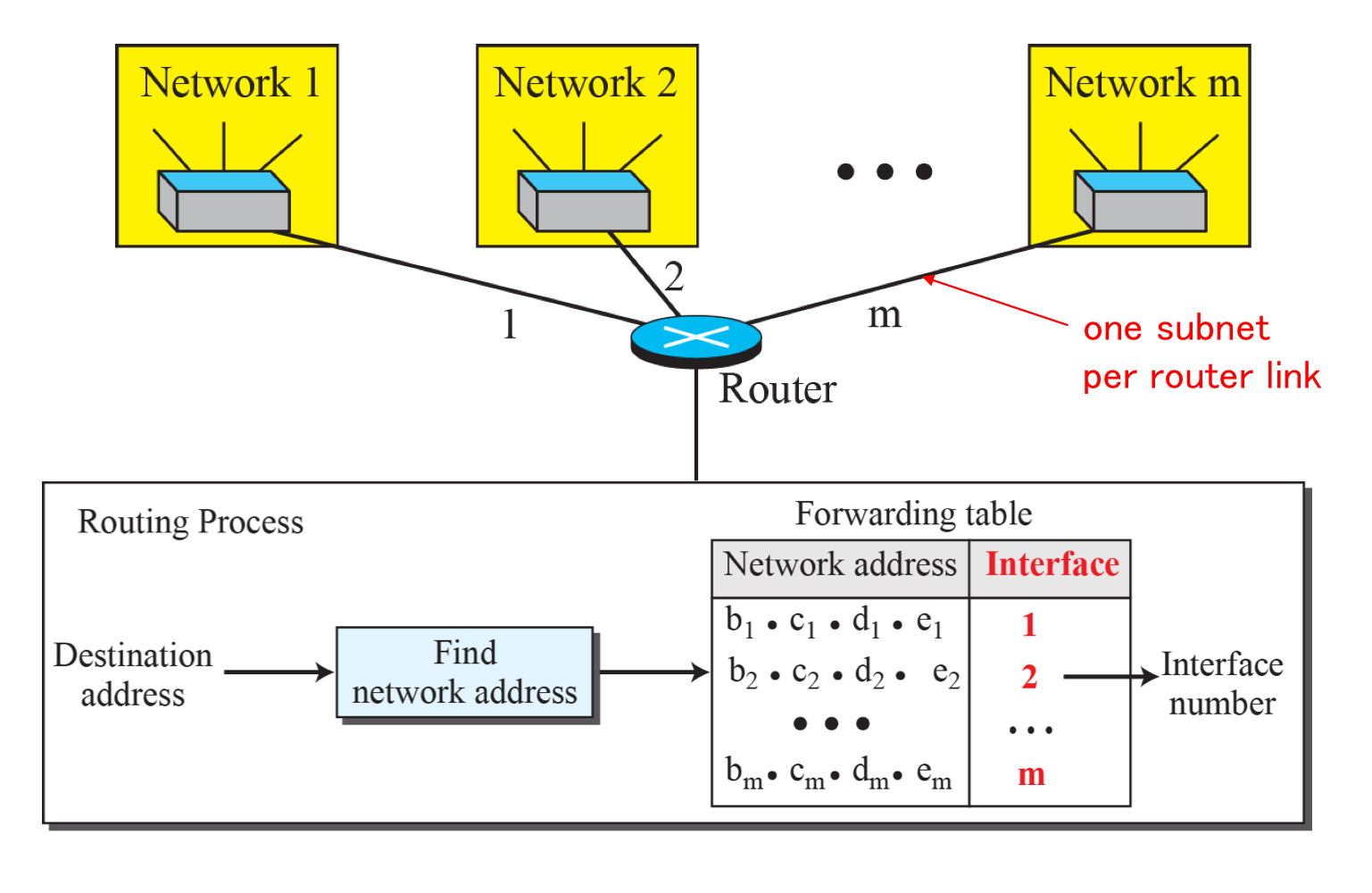
Forwarding Table에 Host 주소를 작성하게 되면 테이블이 비대해진다. 따라서 Host 주소가 아닌 네트워크 주소를 작성하게 된다. 즉, Forwarding Table에서는 네트워크 주소를 통해 라우팅된다.
ISP&ICANN
ICANN: 인터넷 주소 관리국
ISP가 1000개의 주소를 요청하면, 2의 지수 승인 1024개를 부여한다. 호스트 주소가 1024개이여야 하므로, 네트워크 주소로 18.14.12.0/22를 부연한다.
Address Aggregation
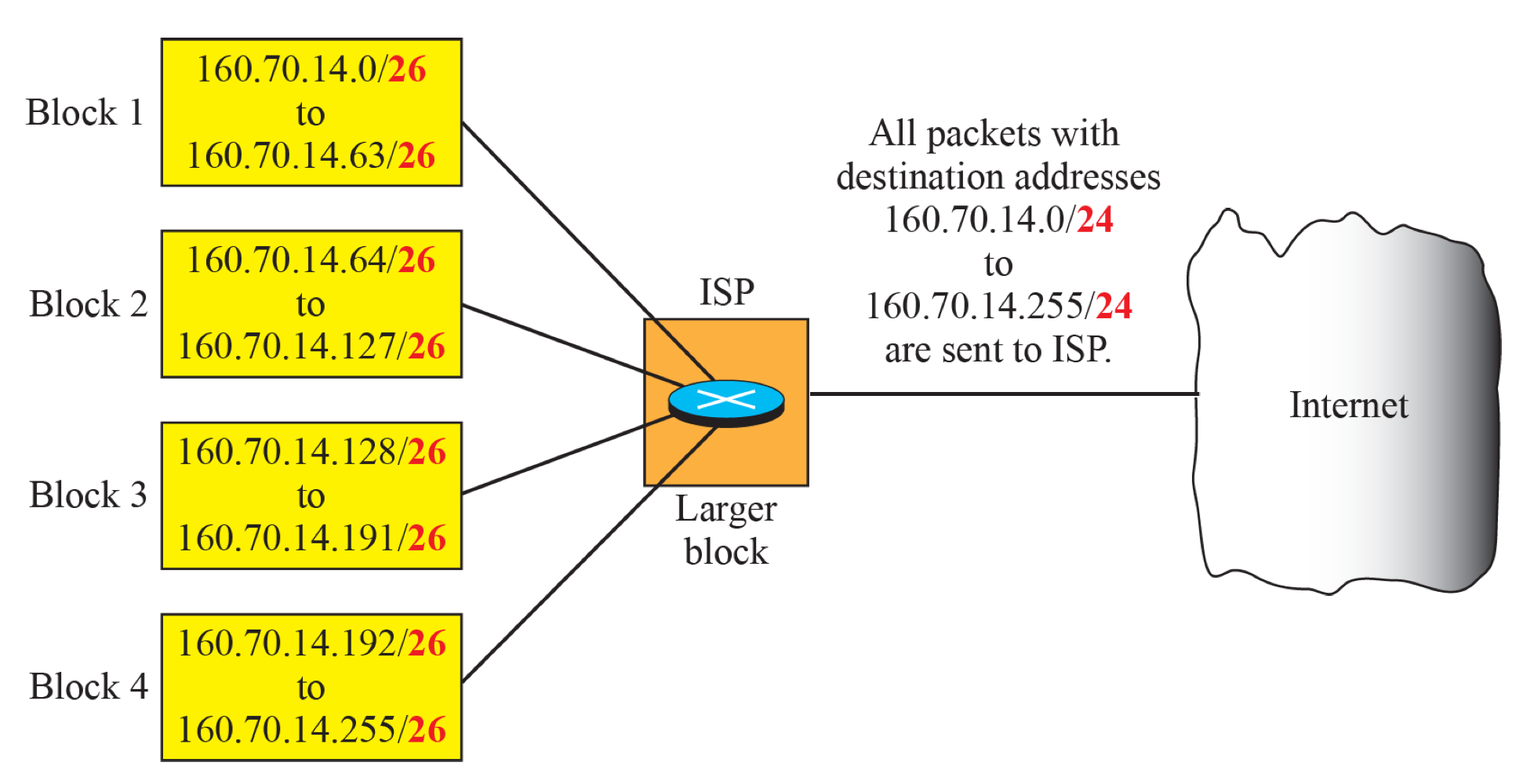
라우터 입장에서는 4개의 Block을 합치면 160.70.14.0/24로 합칠 수 있다.

라우터가 Forwarding Table을 만드는데 Block에 대하여 각각 Row를 만드는 것이 불필요할 수 있다. 아예 주소를 합쳐서 하나의 Row로 Forwarding Table에 작성하는 것이 효율적일 수 있다.
DHCP
Dynamic Host Configuration Protocol
컴퓨터가 DHCP로 부터 IP를 받고 떠나면 반납한다.
- 자신의 IP Address
- 자신의 Subnet Mask
- Default router address
- Domain Name Server address
접속 초기에 이러한 정보를 DHCP 서버에 요청하여 얻어온다.
응용계층의 프로토콜이고 UDP 기반으로 작동한다.
- TransactionID가 랜덤으로 생성
- DHCP|DISCOVER 메세지를 Value에 담아 전송
- DHCP는 67포트에서 Listening 중.
- 현재 Source address와 Destination Address를 모르므로, 각각 0.0.0.0과 255.255.255.255로 설정
- Broadcast로 전송
- DHCP.OFFER 메세지를 전송
- 받은 메세지와 같은 TransactionID 설정
- 제안할 주소를 Your Address에 설정
- DHCP의 주소를 Server Address에 설정
- Broadcast로 전송
- 서버가 제안한 주소를 사용
- DHCP.REQUEST 메세지를 전송
- DHCP.ACK 메세지를 전송
나머지 정보
- DNS 서버의 정보를 FTP로 받을 수 있도록 서버 내의 파일 경로를 알려줌
- Request 보내고 난 후 Reply를 못 받으면 random 시간 후에 다시 request
- DHCP 서버가 나누어 주는 IP주소는 관리자의 설정에 따라 public주소이거나 private 주소
IP Aggregation at Forwarding
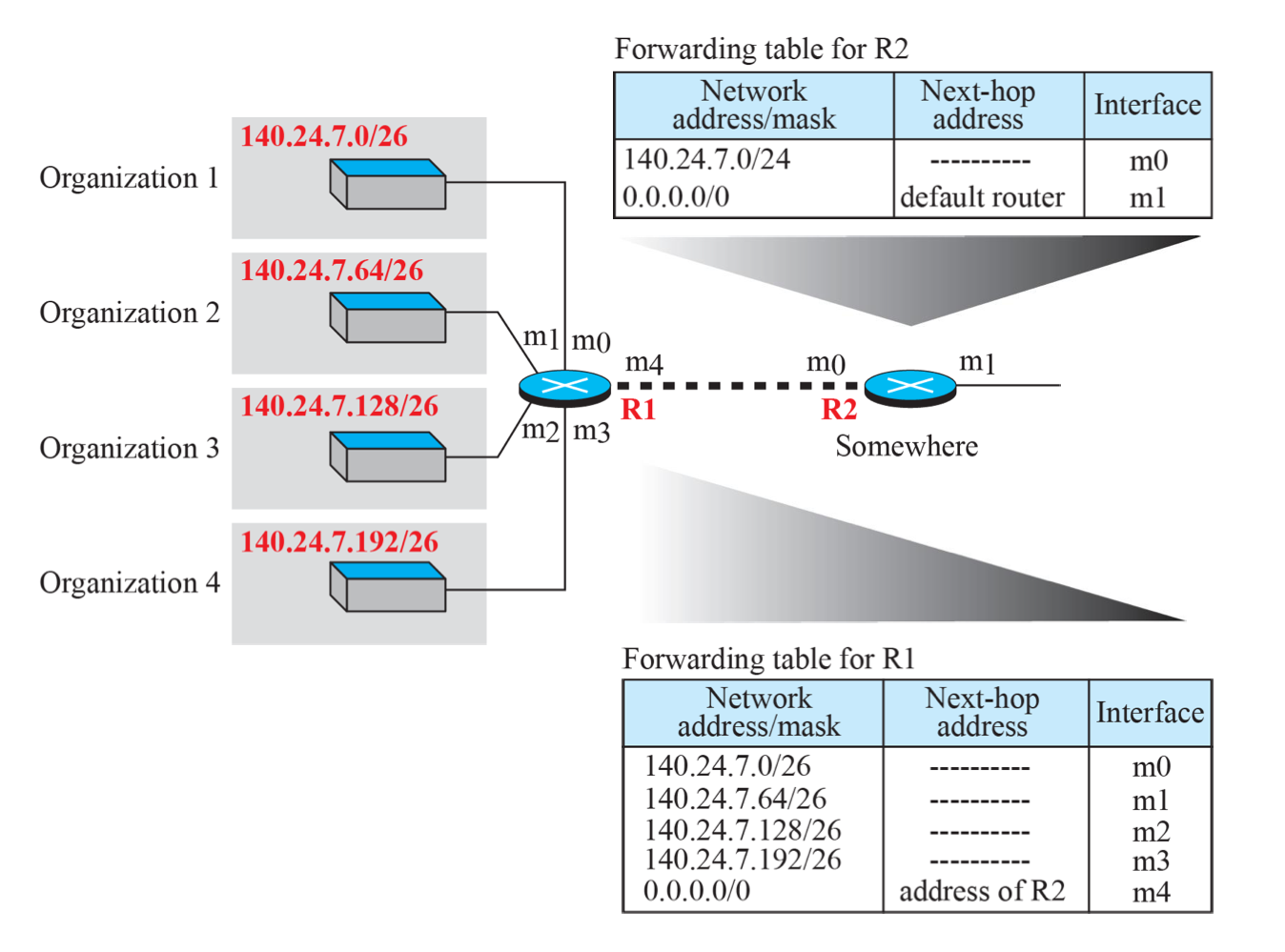
IP Aggregation을 진행하면, R2 라우터에 추가 row가 필요함
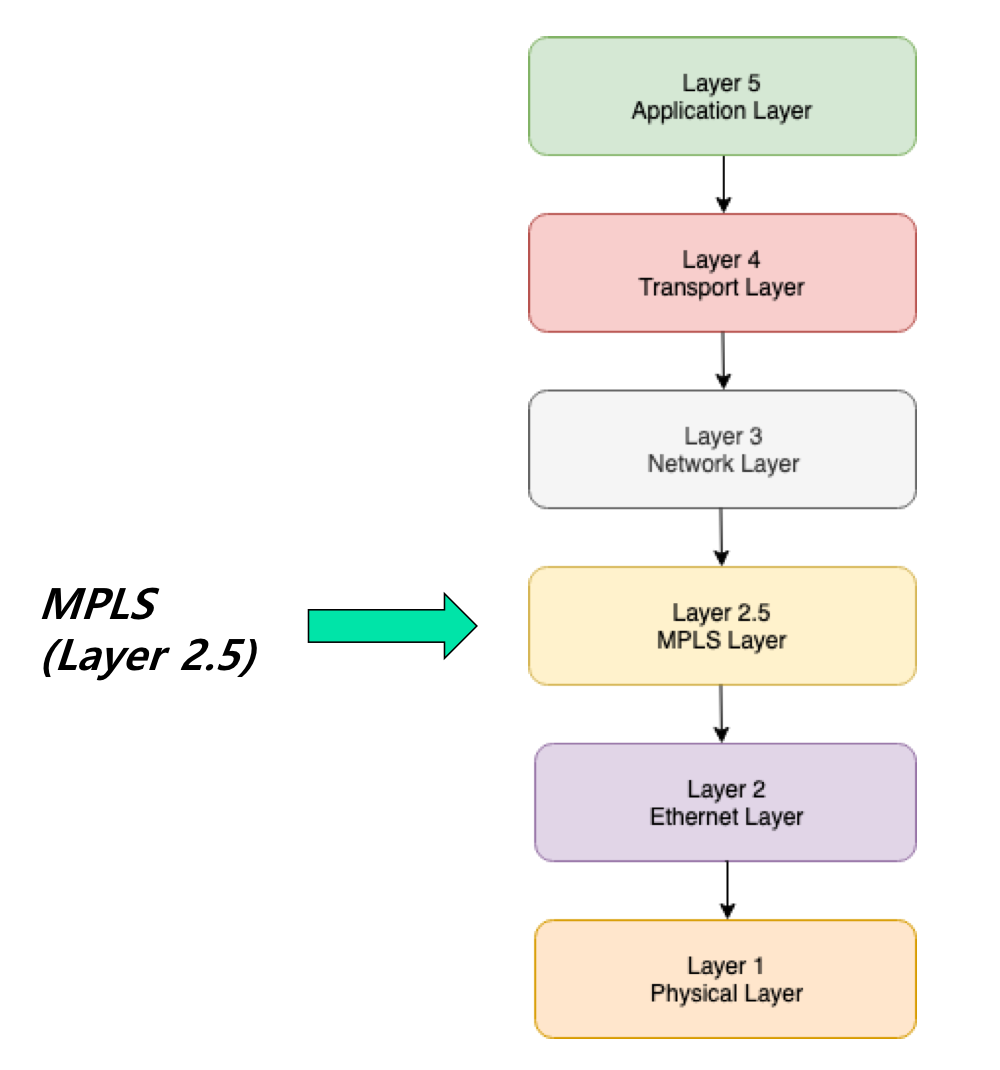
MPLS
기존 IPv4에서 레이블을 붙여서 옮겨감
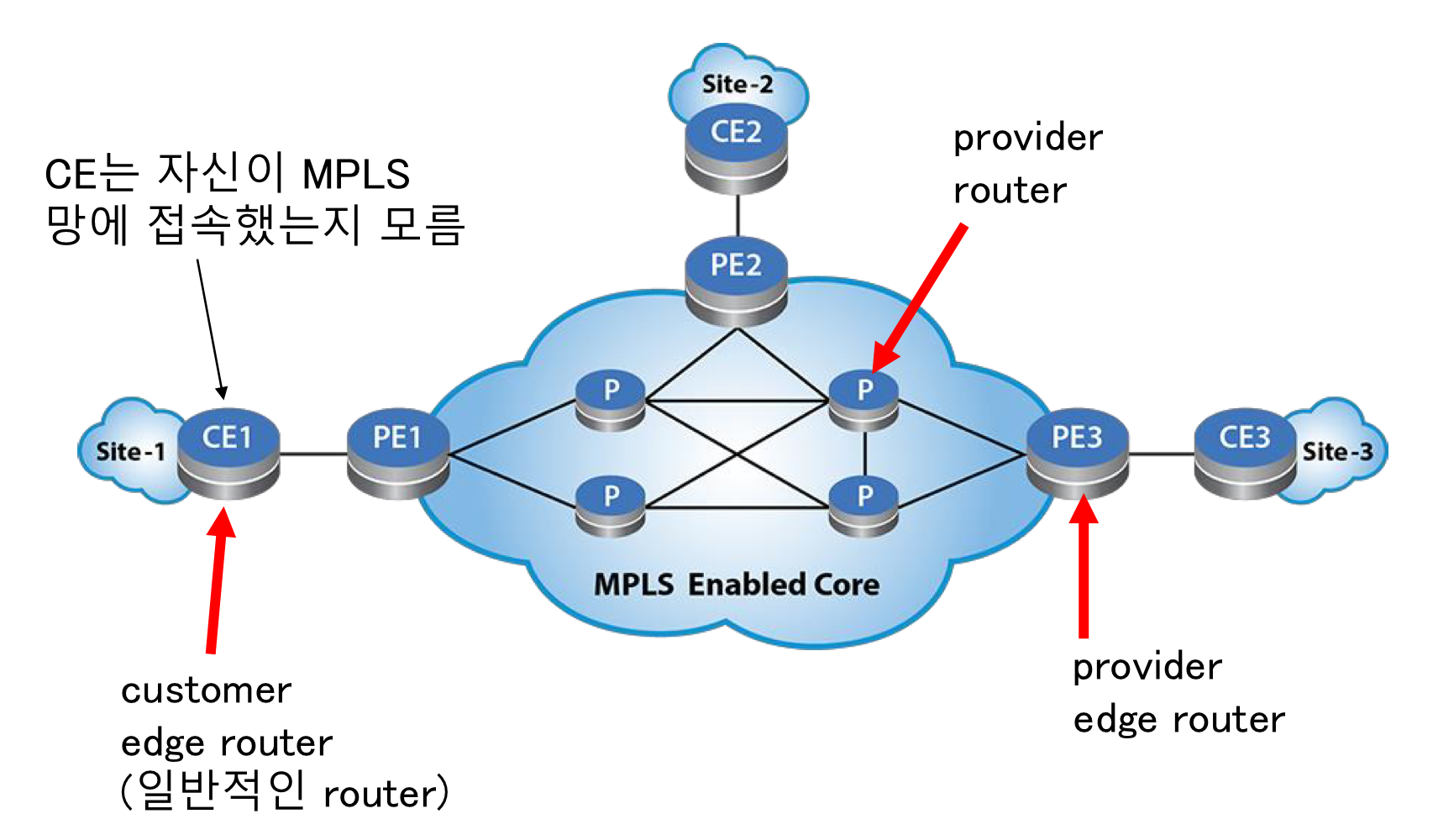
레이블 스위칭을 위한 계층
MPLS를 통한 virtual circuit을 사용 가능
IPv6에서 레이블 값을 넣을 수 있는 필드가 있다. 따라서 따로 계층이 필요없다.
Network Protocol
IPv4
Header
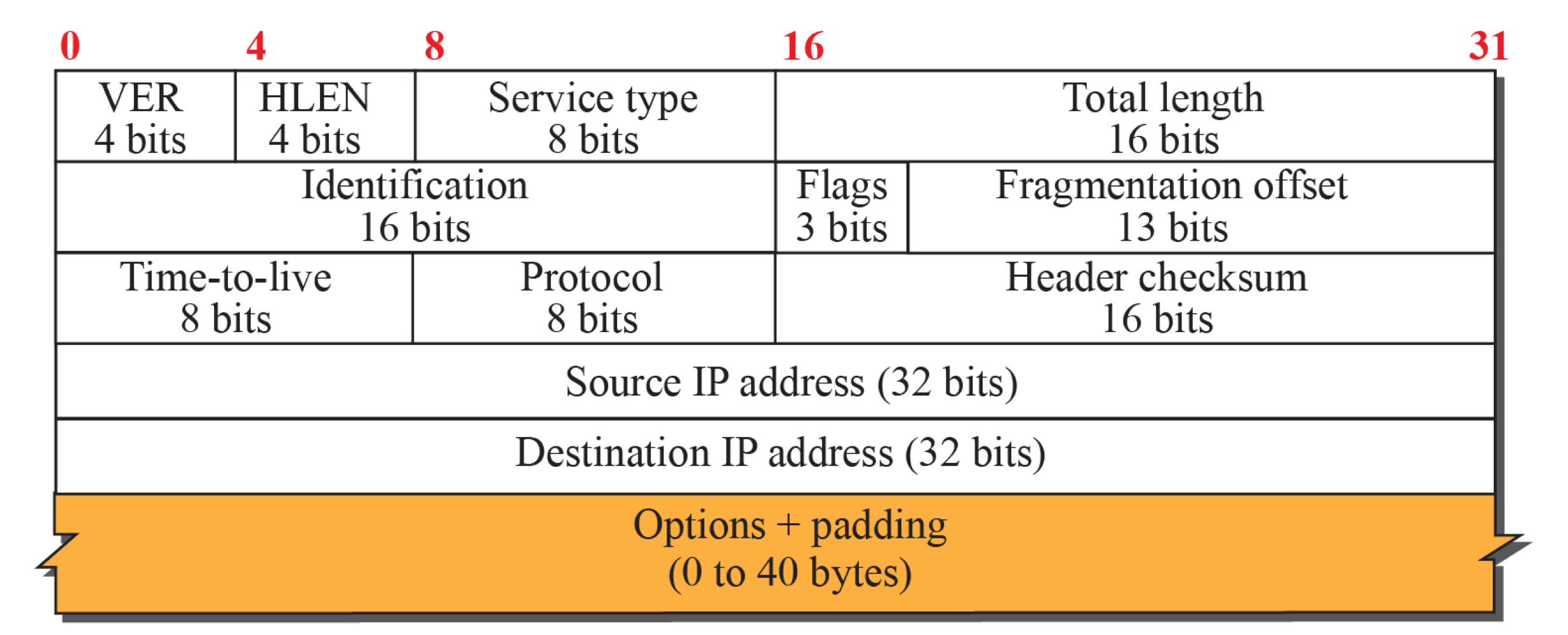
- 버전
- 헤더 길이
- Total length: 헤더 + payload의 길이
- Service Type
- IP의 전체 길이
- TTL: 라우터를 거칠 때마다 -1을 진행하여 0이 되면 패킷을 버린다. 라우팅 알고리즘에 의해 loop가 형성될 수 있다. TTL이 무한대면 이것이 무한 루프를 형성한다. TTL을 이를 방지한다.
- Protocol: TCP인지 UDP인지
- Header Checksum: 에러가 있는지 테스트
Protocol Field
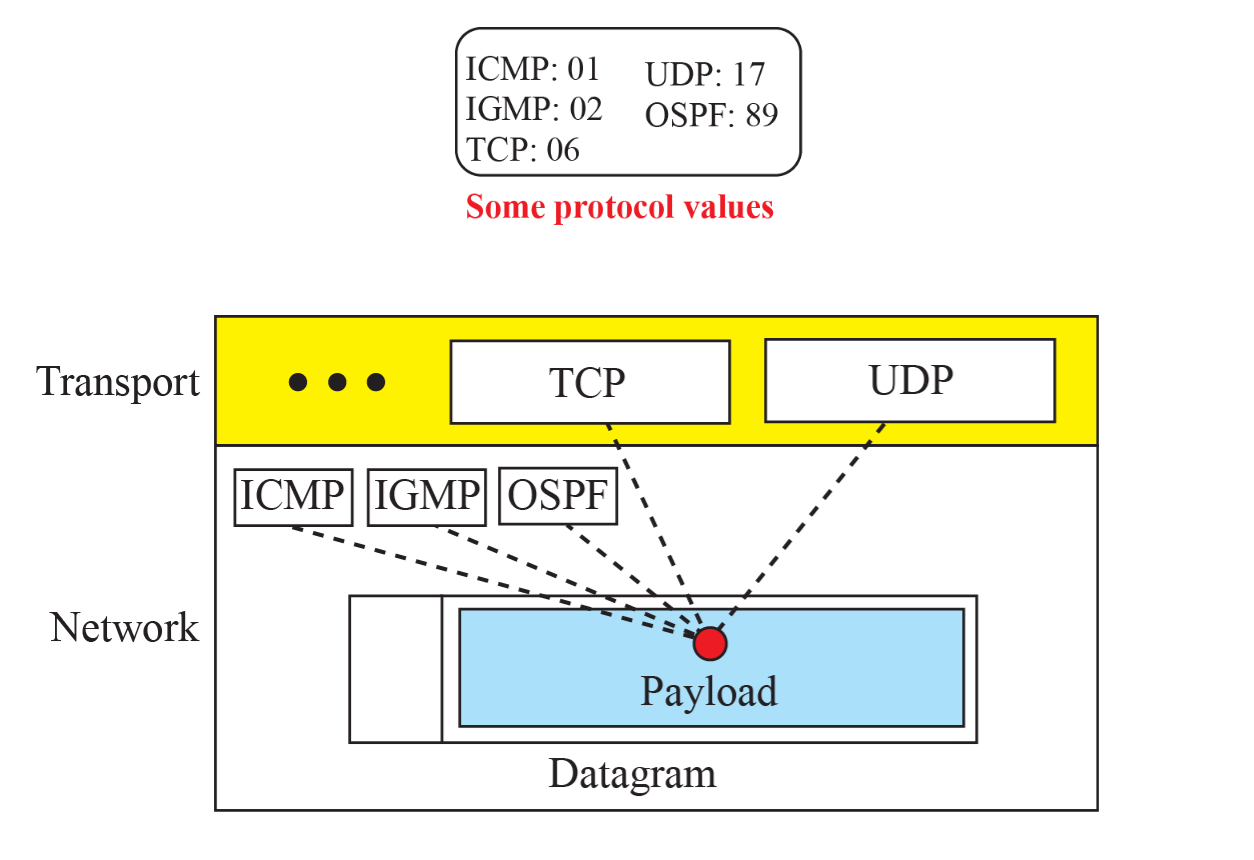
TCP, UDP, ICMP, IGMP, OSFP는 페이로드에 들어간다.
ICMP, IGMP, OSFP는 네트워크 계층의 페이로드에 들어간다. 전송 계층에 들어가는 것 같지만, 역할은 네트워크 계층에서의 역활과 같기 때문에 네트워크 계층으로 분류한다.
Example
(45000028000100000102 ...)_16 IPv4 패킷이 도착하면 8개의 숫자가 32비트이다. 따라서 (45000028/00010000/0102 ...)_16이고 헤더에서 (01)_16이 TTL이다. 즉, 하나의 hop으로 이동 가능하다.
Checksum Header
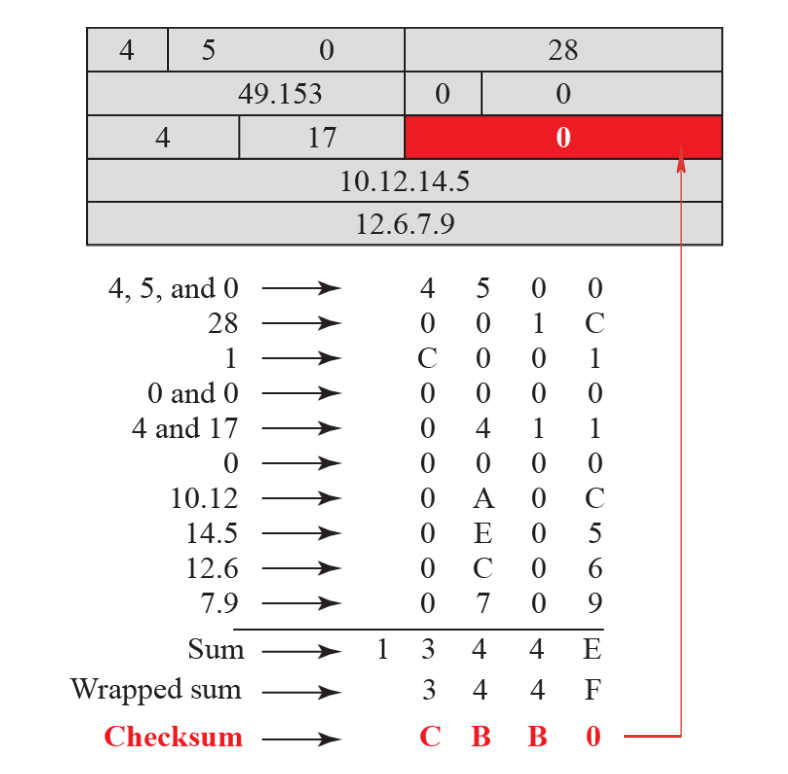
Wrapped Sum의 보수를 Checksum 값에 대입한다. 따라서 Error의 여부는 Wrapped Sum과 Checksum의 합이 0인지 아닌지를 판단한다.
Payload에 대한 Error를 체크하는 것이 아니다. Error에 대한 해결이 아니다.
Fragmentation
IP packet은 전송 중에 다양한 형태의 네트워크를 통과하는데, 경우에 따라 크기가 작은 조각들로 나누어지는 때가 있음
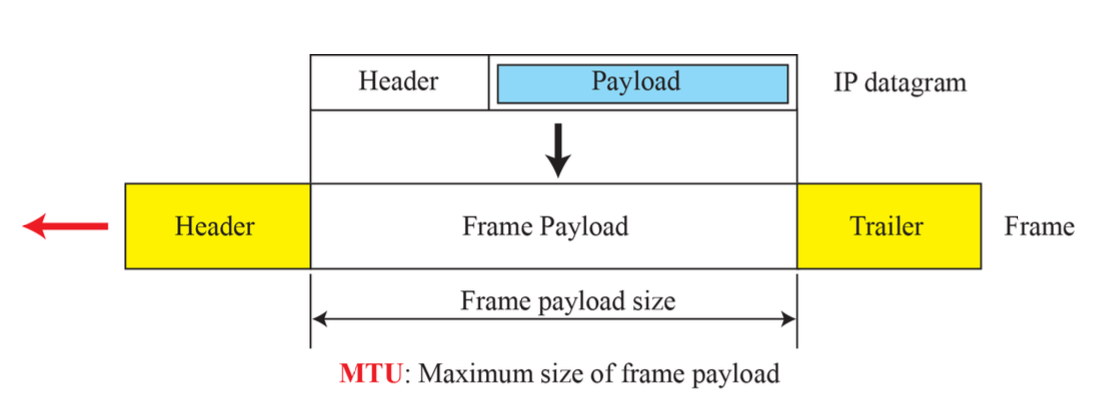
- MTU: 페이로드의 최대 길이
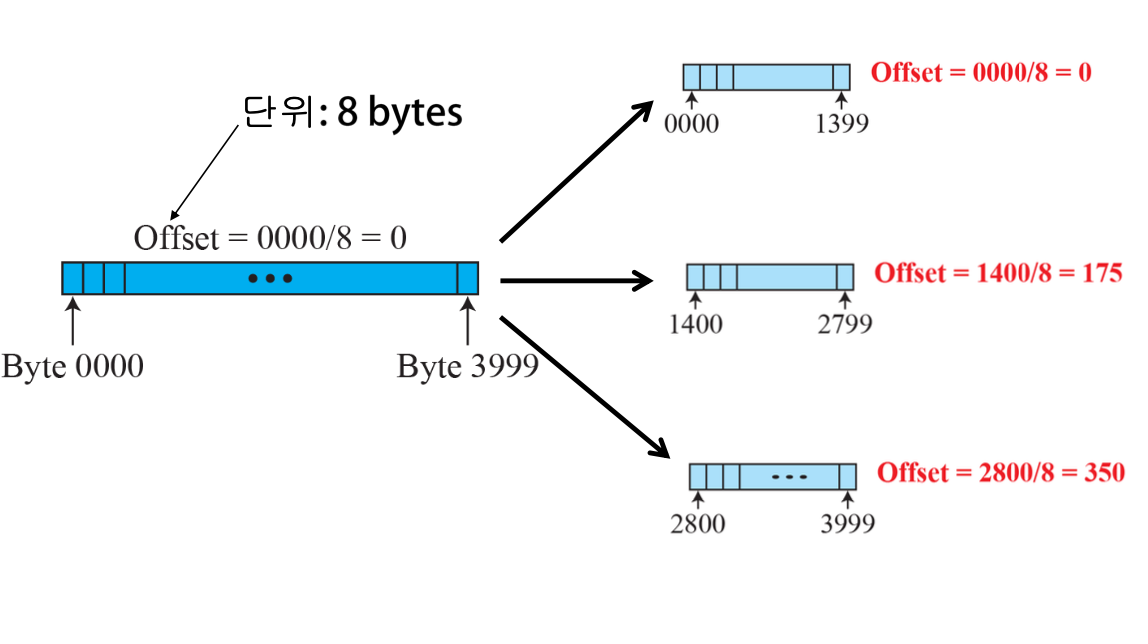
패킷 처리 단위 사이즈가 작다면, fragmentation 과정을 통해 작게 만들어 처리한다.
Security
- packet sniffing: 지나가는 IP packet의 내용을 엿보는 공격. 감지하기 어려움. -> encryption으로 예방
- packet modification: 지 나 가 는 IP packet 의 내 용 을 변경함 -> data integrity mechanism(MD5, SCH)으로 감지
- And IP spoofing: 제 3자가 다른 사람으로 가장(masquerade)하고 IP packet을 보냄. -> origin authentication mechanism 으로 방지
IP 보안 관련 프로토콜: IPSec
Mobile IP
이동 단말에 대해 IP 서비스를 중단 없이 제공하기 위한 Mobile IP 표준이다.
하지만, Cellular 망과 WiFi의 발전으로 주목 받지 못함.
IGMP
그룹 관리 프로토콜
IPv6
Colon Hex 방법으로 IPv6 128-bit 주소 체계를 나타낸다.
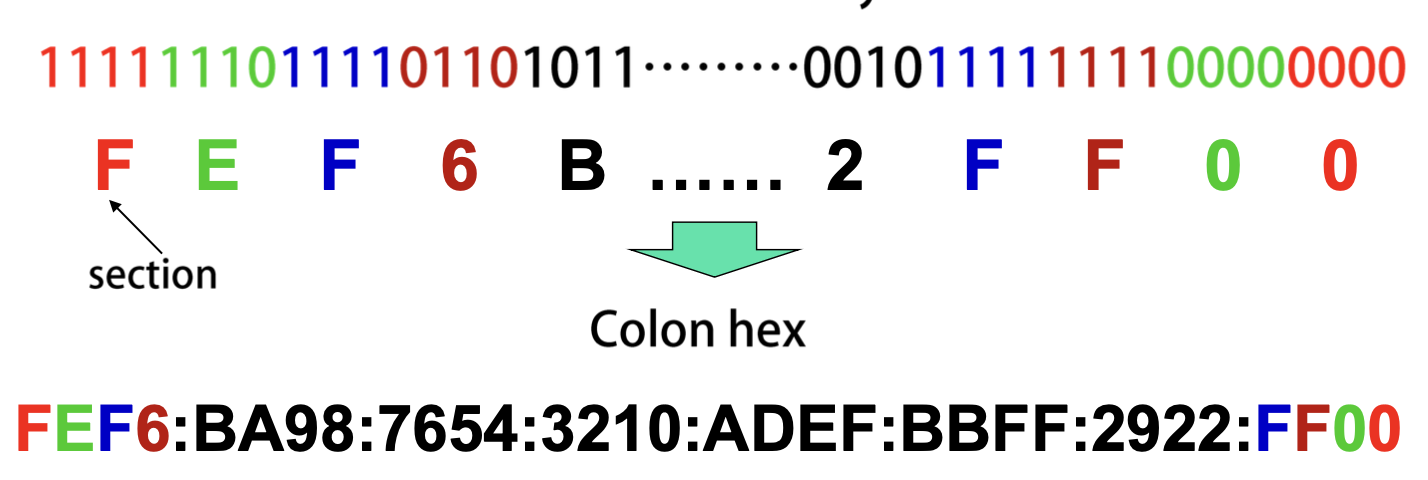
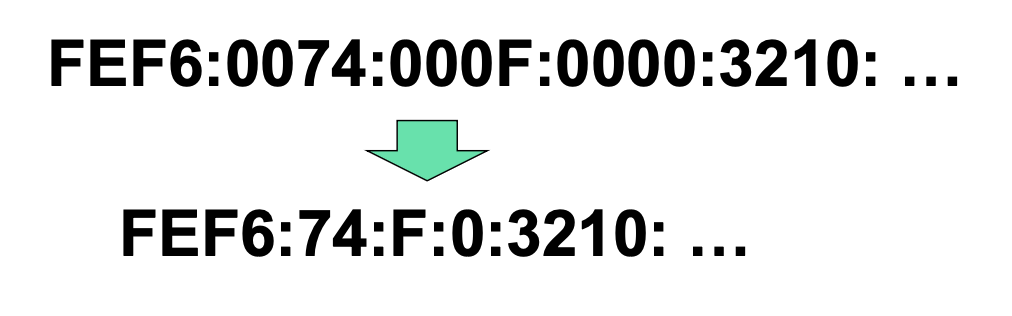
Colon hex로 표현해도 여전히 길고 중간에 많은 0을 포함하기 때문에 colon hex 표현에서 다음과 같이 축약함
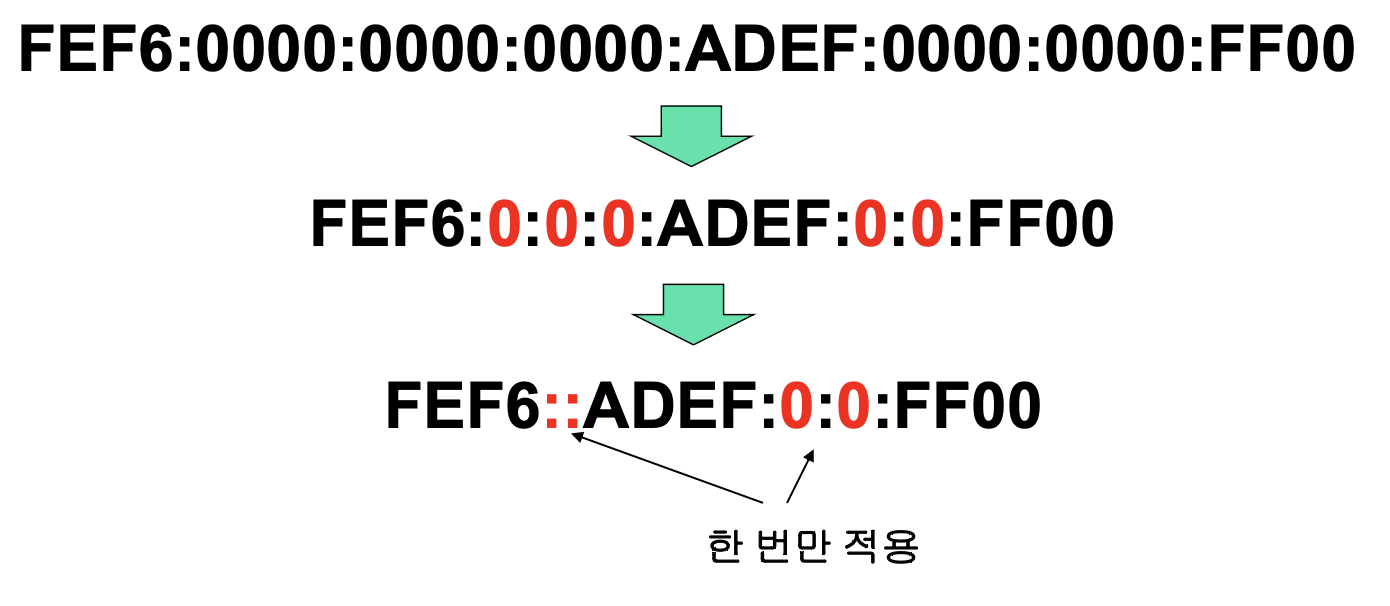
Zero Compression
- 연속된 0 section들은 축약해서 더블 콜론(::)으로 표현
- 하나의 IPv6 주소에서 한 번만 적용 가능
Three Address Scopes
Unicast Address
(one-to-one):
• It defines a single interface. It is for one-to-one
communications.
Anycast Address
(one-to-any):
• It defines a group of computer that all share a
single address.
• 목적지 주소가 anycast 인 패킷은 목적지
그룹 내에서 중 하나의 computer 에게 전송
예) DNS 서버그룹
• Anycast address 도 unicast address 블록에서
할당받으므로 IP 주소만 봐서는 구분이 안됨.
Multicast Address
(one-to-many):
• 수신자 그룹 내의 모든 computer 가 데이터를
수신함.
• Multicast address 블록이 준비되어 있음.
Broadcast Address
(one-to-all))
• IPv6에는 broadcast address 가 따로 없음.
• All-node multicast address로 broadcast 기능을
대체함
Global Unicast Address
- Block prefix -> 2000::/3
-> 제일 처음 3비트가 001로 시작하는 모든 주소
-> 첫 16진수가 2 또는 3으로 시작하는 모든 주소
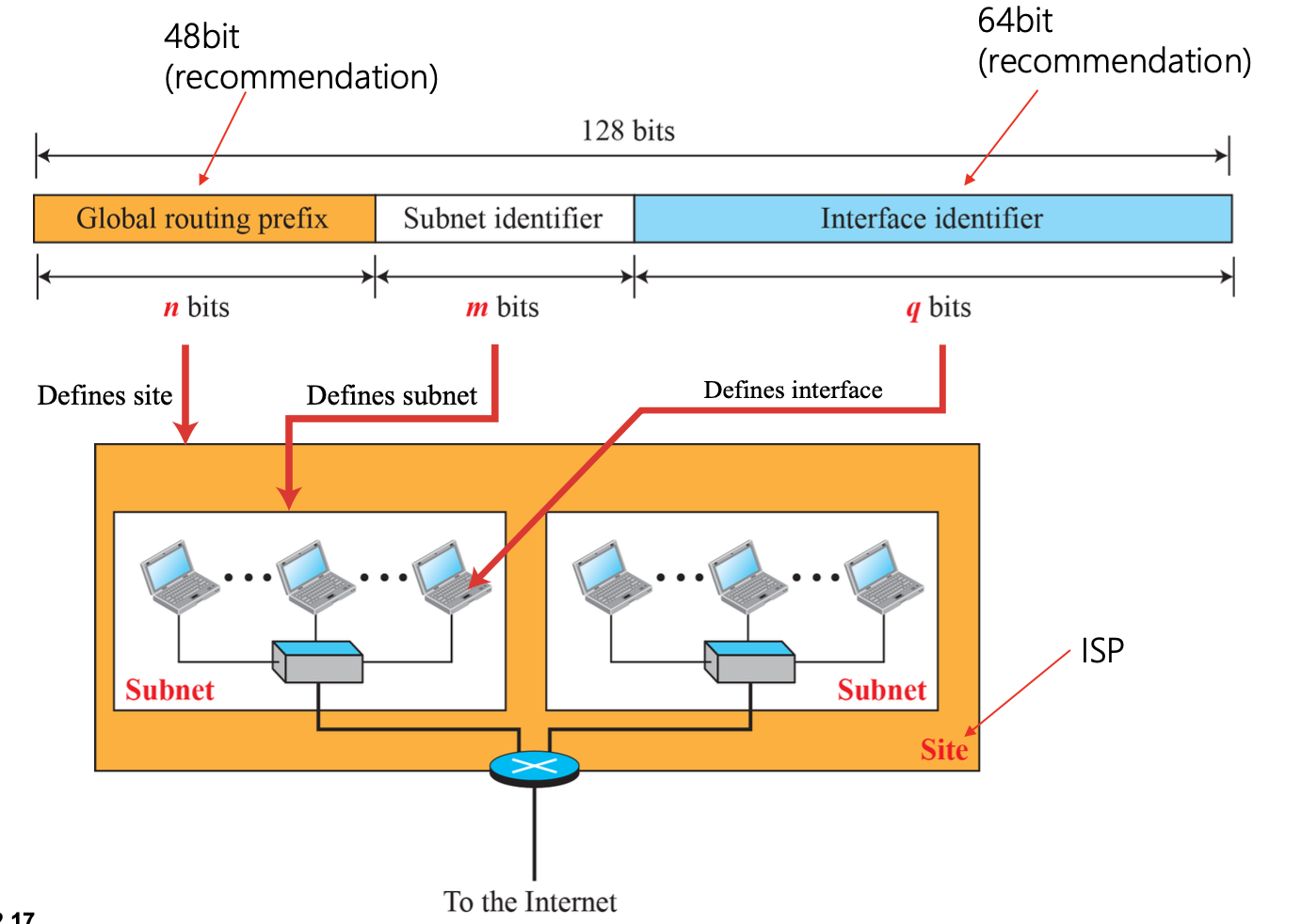
Interface ID

• Random 64-bit value (Windows)
• EUI-64 (Linux, Mac OS) using MAC address
• CGA(Cryptographically Generated Address)
Autoconfiguration
- Router Solicitation
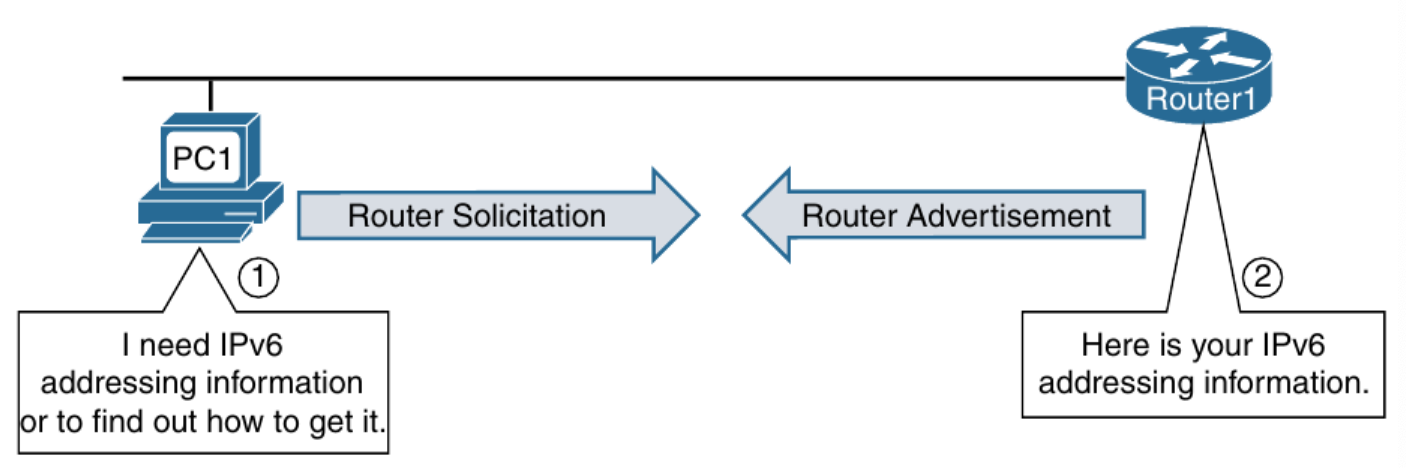
RA(Router Advertisement)
- Network prefix
- Default Gateway address(첫 번째 Router)
- Configuration flags
- DNS server address
Configuration Flag
- Method 1: SLAAC
- Method 2: SLAAC and Stateless DHCPv6
- Method 3: Stateful DHCPv6
State는 메모리...?
IPv6
IPv6 NAT
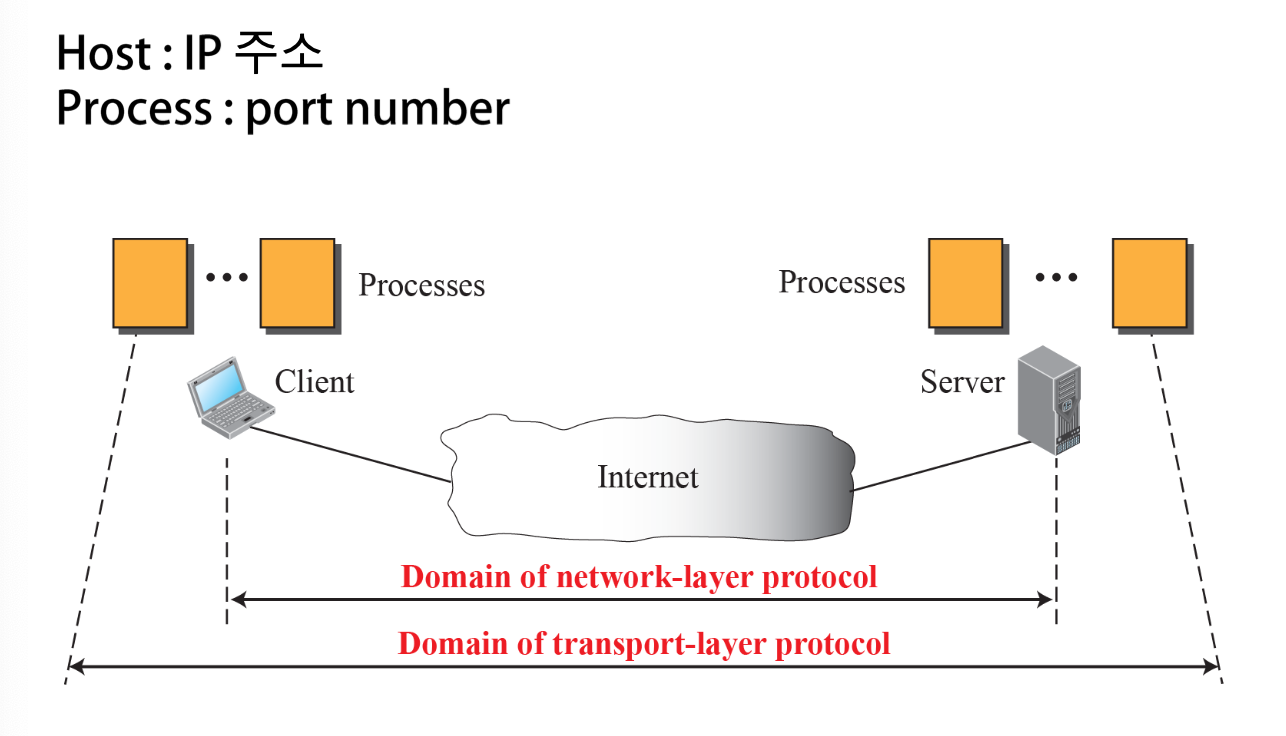
Transport layer
- 프로세스 to 프로세스 communication 연결
- Application layer에 서비스를 제공하고 network layer로부터 서비스를 받는다.
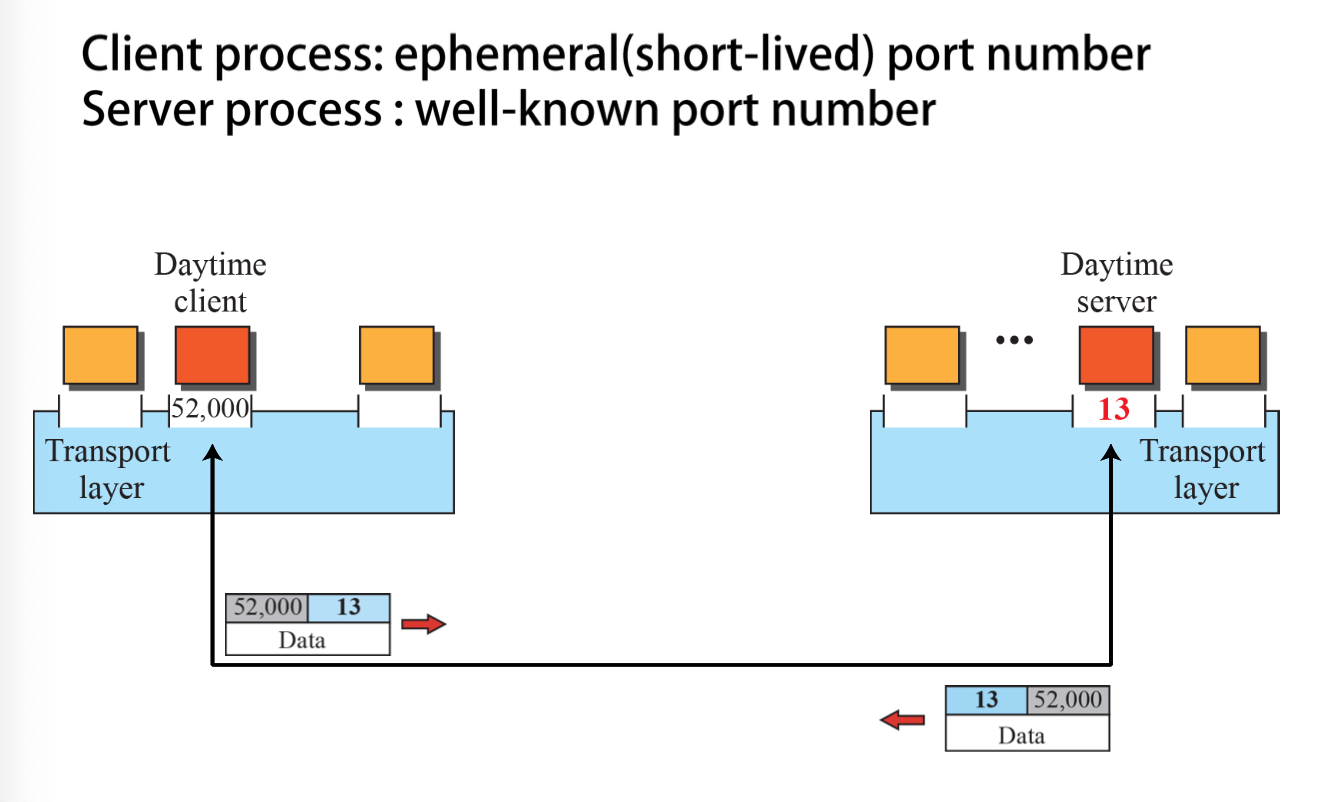
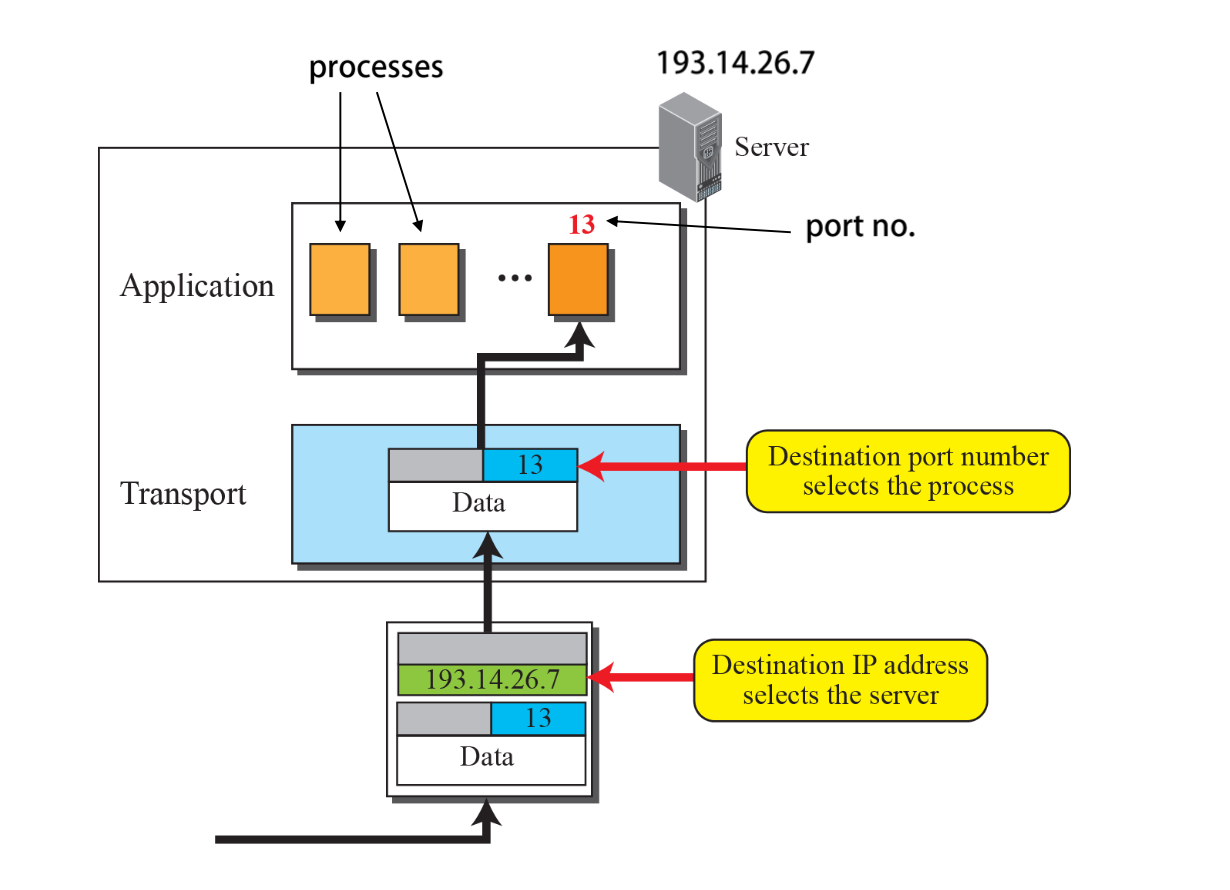
- IP를 통해 패킷이 도착한다.
- 포트 번호를 통해 프로세스를 찾아간다.

- Well Known Port:
- Registered Port:
- Dynamic Port:
Registered와 Dynamic는 딱히 구분하지 않는다.
Encapsulation & decapsulation
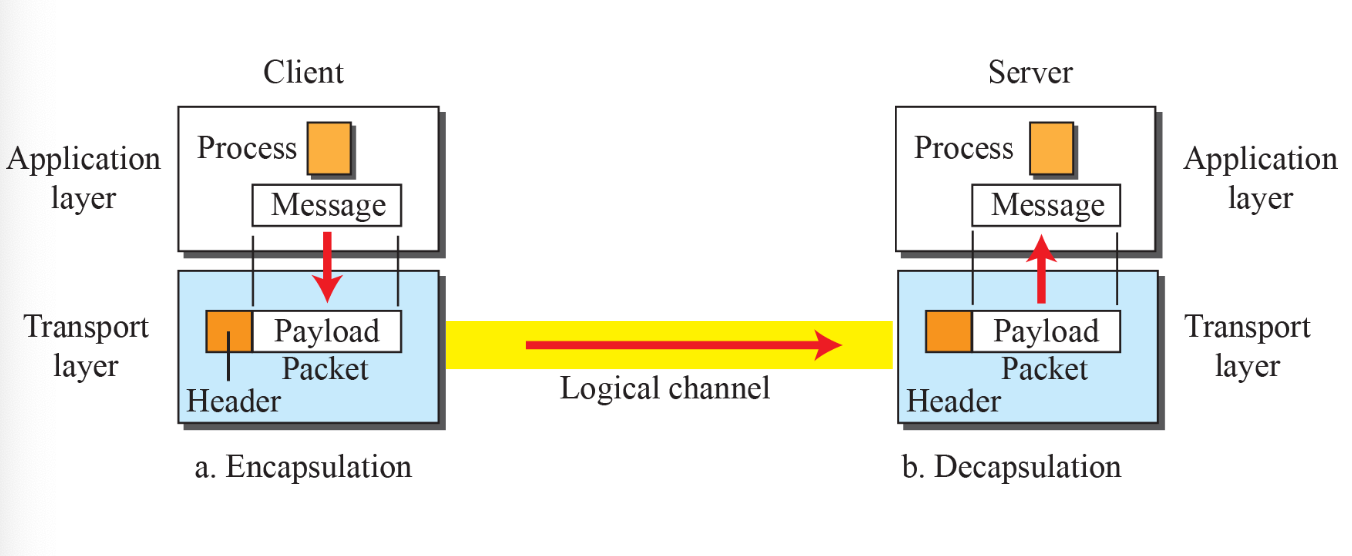
Flow Control
전송 속도 조절을 하는 것.
Receiver가 받을 수 있는 속도에 맞춰 Sender의 속도를 조절하는 것.
- Sender가 빠르게 보낼 경우, 데이터가 버려진다.
- Sender가 느리게 보낼 경우, BandWidth 낭비된다.
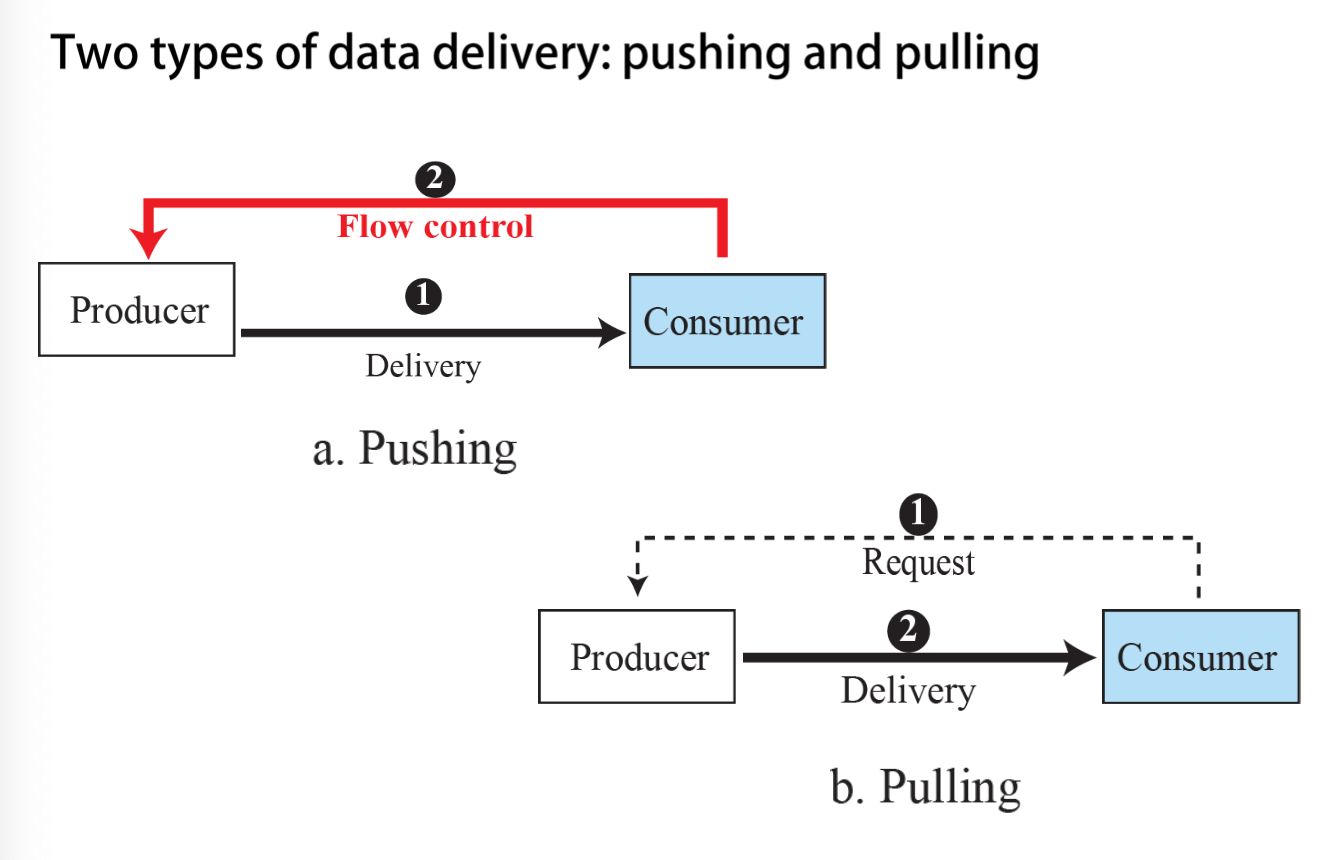
Pushing, pulling
-
Pushing: 일단 데이터를 보내고, Consumer가 데이터 속도에 대한 알림(push)를 보낸다.
-
Pulling: 데이터를 전송하기 전에 Consumer가 데이터를 받을 준비가 되면 Producer에게 데이터 요청을 보낸다.
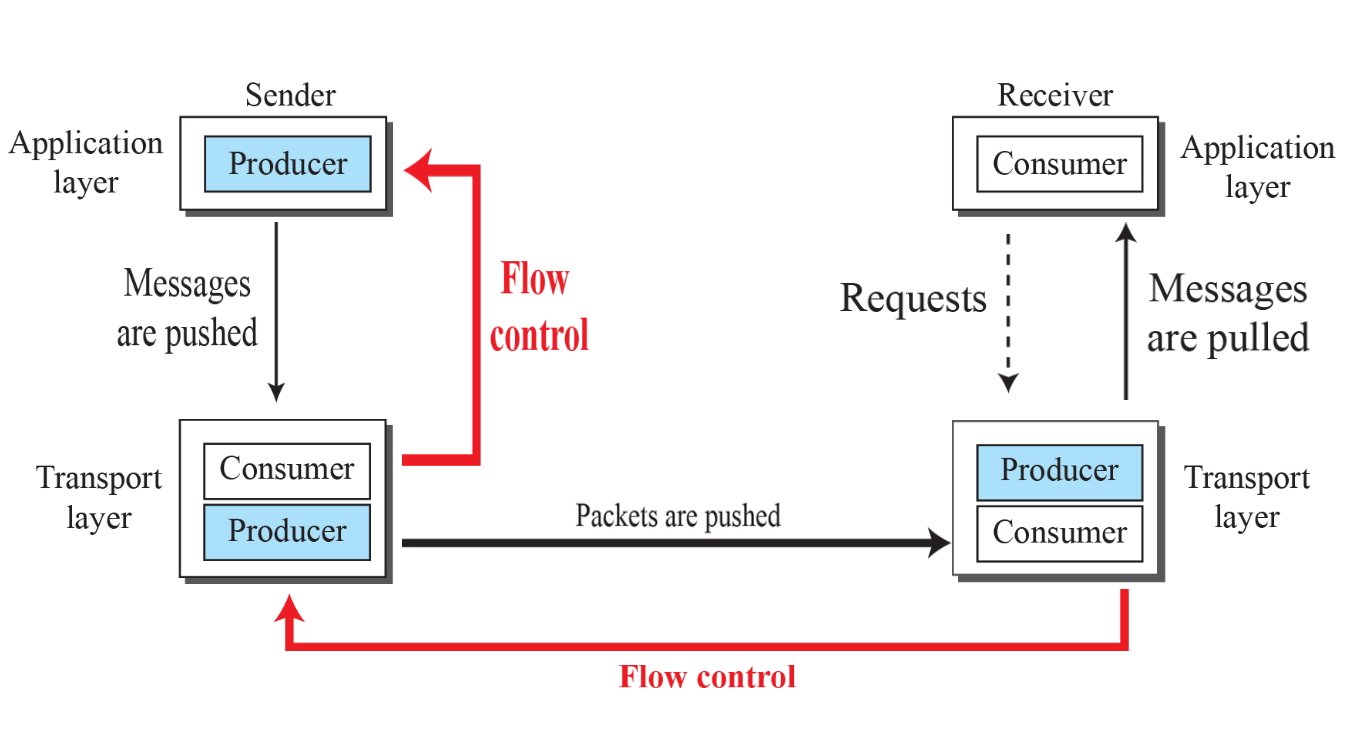
1. Sender의 응용 계층에서 데이터 생성됨.
2. Sender의 Transport layer에 push 방식으로 전송
3. Sender의 Transport layer에서 Receiver의 Transport layer로 push 방식으로 전송
4. Receiver의 Transport layer에서 응용계층으로 pullung 방식으로 전송
Error Control

- 에러 패킷을 탐지하거나 버린다.
- 에러 패킷에 대해 재전송을 요청한다.
- 중복 패킷을 제거한다.
- 순서가 바뀐 패킷을 맞춘다.
에러 검출은 Error detection code 또는 Correction code를 이용한다. 순서는 Sequence 번호를 이용한다.
- Positive ACK
- Negative ACK
Sliding Window
m=4인 경우, 총 15 비트 표현 가능.
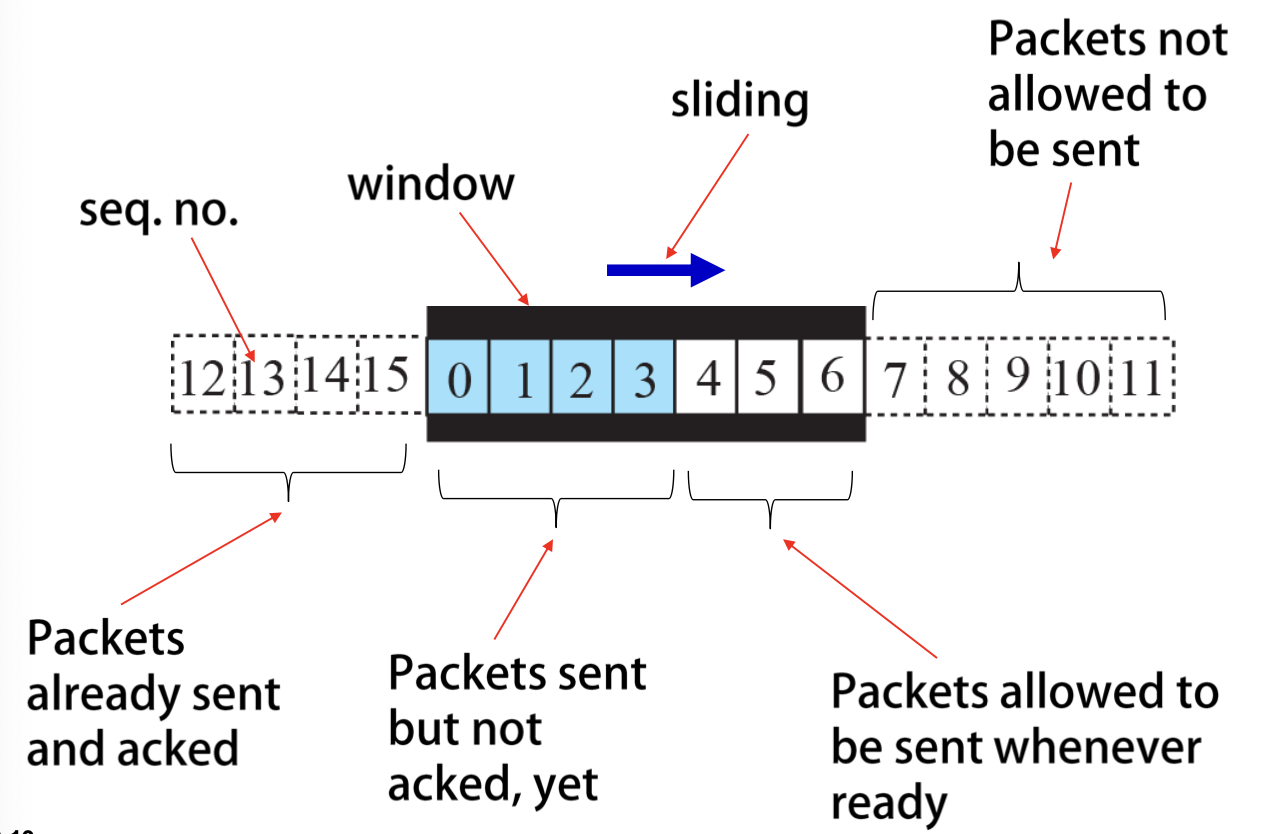
Box 왼쪽: 전송이 끝남
Box 오른쪽: 아직 전송하면 안되는 패킷
Box 안 파란색: 보내고 ACK를 기다리는 패킷 (OutStanding Packet)
BOX 안 흰색: 응용 계층에서 메시지가 내려오면 보낼 수 있는 패킷
과정
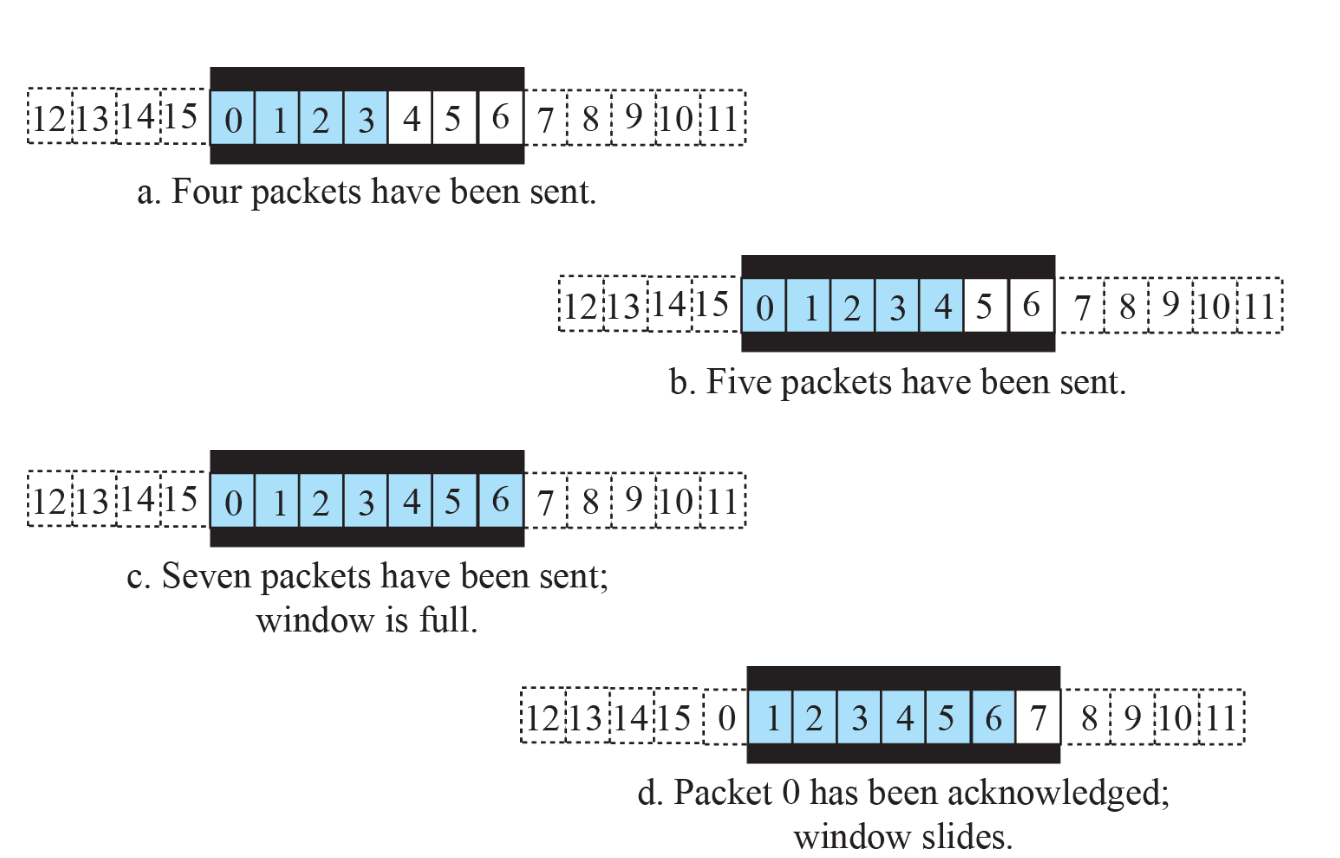
Congestion Control
라우터에 버퍼가 꽉 차서 버려질 수동 있다. 트래픽 로드가 네트워크의 capacity보다 클 때 발생한다.
Connection
Connectionless vs Connection-oriented
Connectionless: Datagram Switching, UDP
Connection-Oriented: Virtual-Circuit Switching, TCP
Connectionless
- 패킷이 독립적으로 전송된다.
- 순서가 보장되지 않는다.
- 데이터 청크가 사라질 수도 있다.
- No Flow, Error, Congestion Control
Connection-Oriented Service
- 연결을 위한 Setup phase 존재
- 해제를 위한 Release 존재
- 라우터들은 논리적 연결에 관여하지 않는다
- Flow, Error, Congestion Control
Transport Layer Protocols
- UDP: unreliable, connection-less
- TCP: reliable, connection-oriented
- SCTP: multimedia communications, UDP와 TCP를 적당히 합친 것.
Process-To-Process 통신을 위해 전송 계층의 통신을 위해 포트 번호를 부여한다.
Well Known Port Numbers
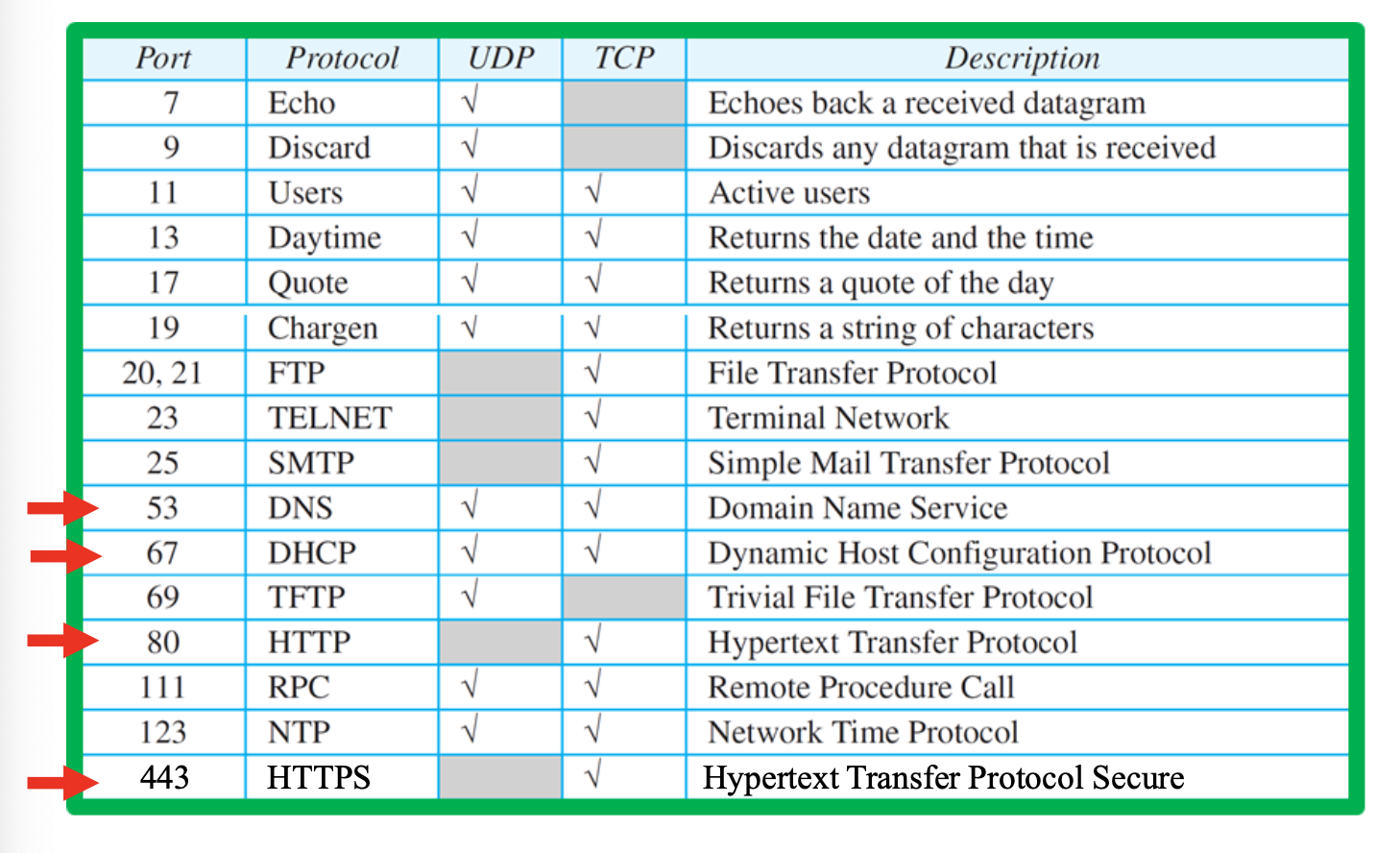
Protocol 데이터 이름들
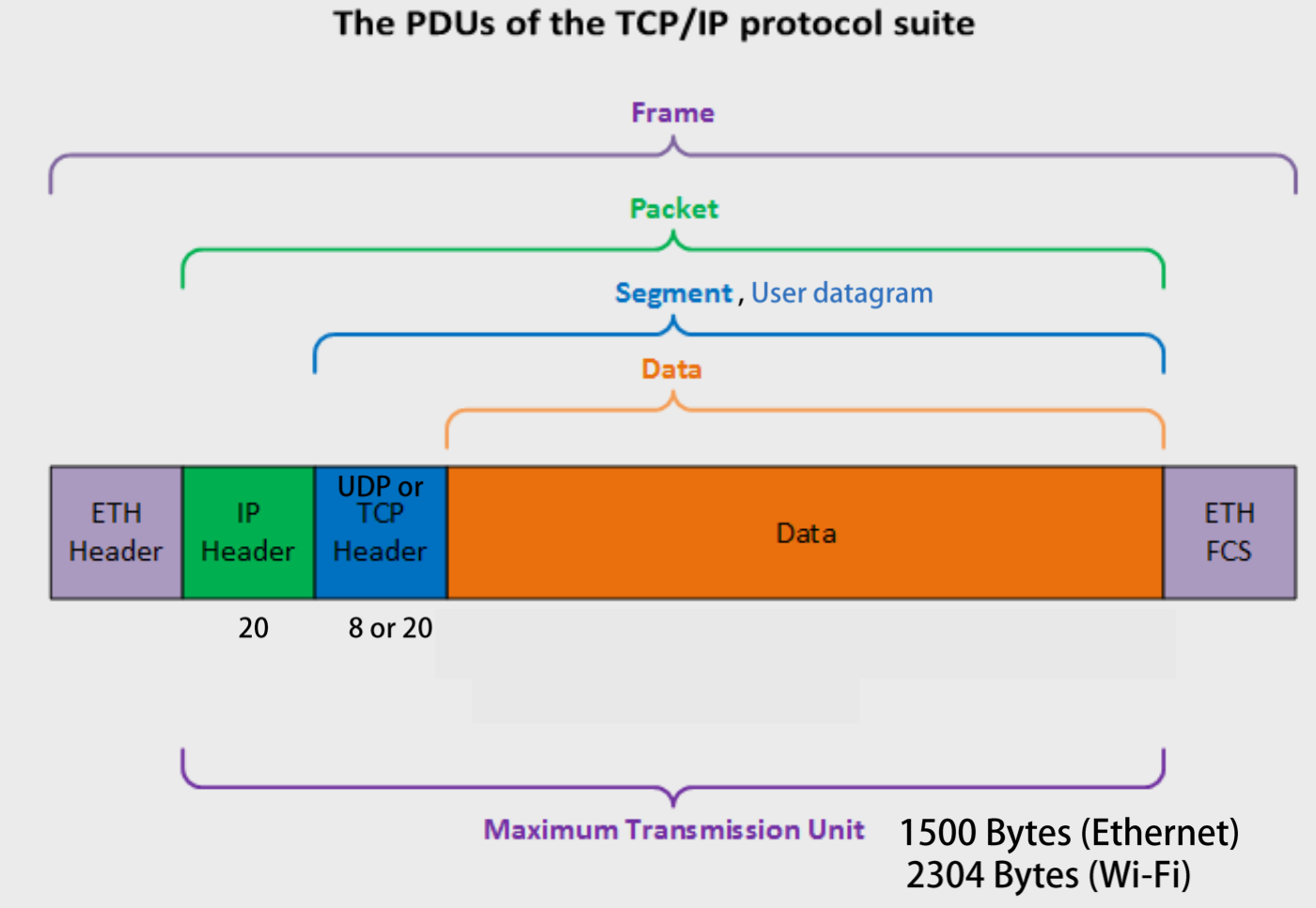
MTU(Maximum Transmission Unit): 하나의 패킷, 세그먼트가 가질 수 있는 최대 길이
