
📖 들어가며
세계에서 가장 널리 사용되는 NoSQL DBMS, MongoDB.
많은 사람들이 MongoDB를 사랑하는 이유 중 하나는 바로 Schemaless라는 강력한 매력에 있을 것이다.
하지만, 그 특징을 잘 사용하기란 참 어려운 일이다.
RDBMS에 익숙한 사용자들은 때때로 MongoDB에도 RDB처럼 엄격한 스키마를 적용하거나, 혹은 반대로 Schemaless한 특성을 지나치게 자유롭게 사용한 나머지 성능 저하를 일으키기도 한다.
'Schemaless'와 'Modeling', 얼핏보면 두 단어는 서로 반대되는 것처럼 느껴질 수도 있다.
하지만 실제로는, 스키마에 제약이 없을 수록, 최적의 성능과 사용성을 보장하기 위해서는 더욱 공들여서 적절한 활용 방법을 찾아야 한다.
그리고 그 첫걸음은 Document DB의 모델링 패턴을 이해하고 설계하는 것에서 시작한다.
MongoDB 공식 블로그의 Building with Patterns 포스트에서는 MongoDB에 적합한 12가지의 스키마 설계 패턴을 소개한다.
이번 시리즈에서는 Building with Patterns 포스트를 한국어로 정리하며, 데이터를 MongoDB답게 모델링하는 방법을 알아볼 것이다.
📝 Patterns
Approximation Pattern
✔️ What 이벤트가 발생할 때마다 DB에 write하지 않고, N회에 한번 write하는 등 데이터의 추산치를 저장해두는 방법
✔️ When 비용이 큰 연산작업이 자주 수행되고, 연산 결과의 정확성이 크게 중요하지 않을 때
✔️ Pros
- DB write 작업 수 감소
- 정확하지는 않으나, 통계적으로는 유효한 값이 유지됨
✔️ Cons
- 정확하지 않은 데이터
- 어플리케이션에서 구현 필요
Attribute Pattern
✔️ What 비슷한 필드 집합을 key-value 쌍의 배열 필드로 관리하는 방법
✔️ When 도큐먼트 내에 비슷한 필드가 매우 많고, 이 필드들을 정렬하거나 쿼리해야할 때
✔️ Pros
- 인덱스 개수 감소
- 쿼리 단순화
- 쿼리 성능 개선
Bucket Pattern
✔️ What 데이터를 특정 시간 단위로 Bucketing하여 하나의 도큐먼트로 관리하는 방법
✔️ When 시계열(Time Series), 사물 인터넷(IoT)과 같은 스트리밍 데이터
✔️ Pros
- 컬렉션의 도큐먼트 개수 감소
- 인덱스 성능 향상
- 사전 집계를 통한 데이터 액세스 단순화
* 역주) MongoDB 6.0부터 Time Series 컬렉션을 지원하게 되면서, Bucket Pattern을 적용하던 요구사항의 대부분을 대체하게 되었다.
Computed Pattern
✔️ What 매번 집계를 수행하지 않고, 집계 결과를 미리 데이터로 저장해두고 읽어가는 방법
✔️ When Write 작업보다 Read 작업이 훨씬 자주 수행되고, 반복적인 계산이 필요할 때
✔️ Pros
- 잦은 연산으로 인한 CPU 작업 부하 감소
- 쿼리 단순화
- 쿼리 속도 향상
✔️ Cons
- Computed 패턴이 필요한 경우를 알아채기 어려움
- 반대로, Computed 패턴을 무분별하게 사용하여 복잡성이 늘어날 수 있음
Document Versioning Pattern
✔️ What 최신 버전의 데이터만 저장하는 컬렉션과, 모든 버전의 데이터를 저장하는 컬렉션을 각각 관리하는 방법
✔️ When 정책 등의 이유로 과거 버전의 데이터를 함께 관리해야할 때
✔️ Pros
- 단순한 구현
- 최신 버전의 데이터를 조회하는 쿼리의 성능 향상
✔️ Cons
- Write 횟수 두 배 증가
- 쿼리할 때 두 개의 컬렉션 중 적절한 컬렉션을 선택해야 함
Extended Reference Pattern
✔️ What 다른 컬렉션에서 자주 조회하는 정보를 메인 컬렉션에 함께 저장해두는 방법
✔️ When Join($lookup)이 자주 필요할 때
✔️ Pros
- 쿼리 성능 향상
- Join(
$lookup) 횟수 감소
✔️ Cons
- 데이터 중복
Outlier Pattern
✔️ What 예외적인 데이터에 대해, 플래그 필드를 추가해두고 특수하게 처리하도록 하는 방법
✔️ When 가끔 일반적이지 않은 예외 데이터가 발생하며, 이러한 예외 데이터를 기존과 다른 방식으로 처리해야할 때
✔️ Pros
- 소수의 예외 케이스를 고려하지 않고, 일반적인 요구사항에 최적화하여 로직을 구현할 수 있음
✔️ Cons
- 일회성 쿼리를 수행하기 까다로움 (예외 데이터는 따로 처리해야하므로)
- 어플리케이션에서 구현 필요
Pre-allocation Pattern
✔️ What 데이터 구조를 미리 만들어두고, 데이터를 나중에 채워넣는 형태
✔️ When 도큐먼트 구조가 정형화 되어있고, 도큐먼트 사이즈를 줄이는 것보다 단순한 구현이 중요할 때
✔️ Pros
- 설계 단순화
✔️ Cons
- 도큐먼트 사이즈 증가
- 성능 감소
* 역주) MMAPv1 스토리지 엔진에서 메모리 최적화를 위한 전략으로, WiredTiger 스토리지 엔진을 사용하는 최근 버전에는 거의 적용되지 않음
Polymorphic Pattern
✔️ What 컬렉션을 분리하지 않고 하나의 컬렉션에 다양한 데이터를 함께 보관하는 방법
✔️ When 다양한 유형의 데이터가 구조는 유사하고 일부 필드만 다를 때
✔️ Pros
- 구현 단순화
- 하나의 컬렉션에서 쿼리 수행 가능
✔️ Cons
- 스키마 복잡성
- 스키마 검증이 까다로움
Schema Versioning Pattern
✔️ What 도큐먼트에 schema version 필드를 추가하여 스키마의 버전을 관리하는 방법
✔️ When 데이터의 스키마가 자주 변경되거나, 스키마 변경으로 인한 서비스 다운타임이 허용되지 않을 때
✔️ Pros
- 서비스 다운타임이 필요하지 않음
- 스키마 마이그레이션 제어
- 미래의 기술 부채 감소
✔️ Cons
- 스키마 마이그레이션 기간에는 동일한 값에 대해 두 개의 인덱스가 필요할 수 있음
Subset Pattern
✔️ What 도큐먼트에서 자주 사용하는 필드와 그렇지 않은 필드를 구분하여 두 개의 컬렉션에 따로 보관하는 방법
✔️ When 크기가 큰 도큐먼트로 인해 성능 저하가 발생하고, 이 중 자주 사용하는 필드가 적을 때
✔️ Pros
- working set 크기 감소 -> 메모리 최적화
- 쿼리 성능 향상
✔️ Cons
- 데이터를 Subset으로 관리하는 비용
- 2개의 컬렉션을 각각 조회하는 경우가 생김
Tree Pattern
✔️ What Root 노드까지의 경로를 배열 필드로 저장하는 방법
✔️ When 데이터가 계층적 구조를 가지고, 계층 구조가 자주 변경되지 않으며, 쿼리가 잦을 때
✔️ Pros
$graphLookup반복을 최소화하여 쿼리 성능 향상
✔️ Cons
- 경로 데이터를 관리해주어야 함
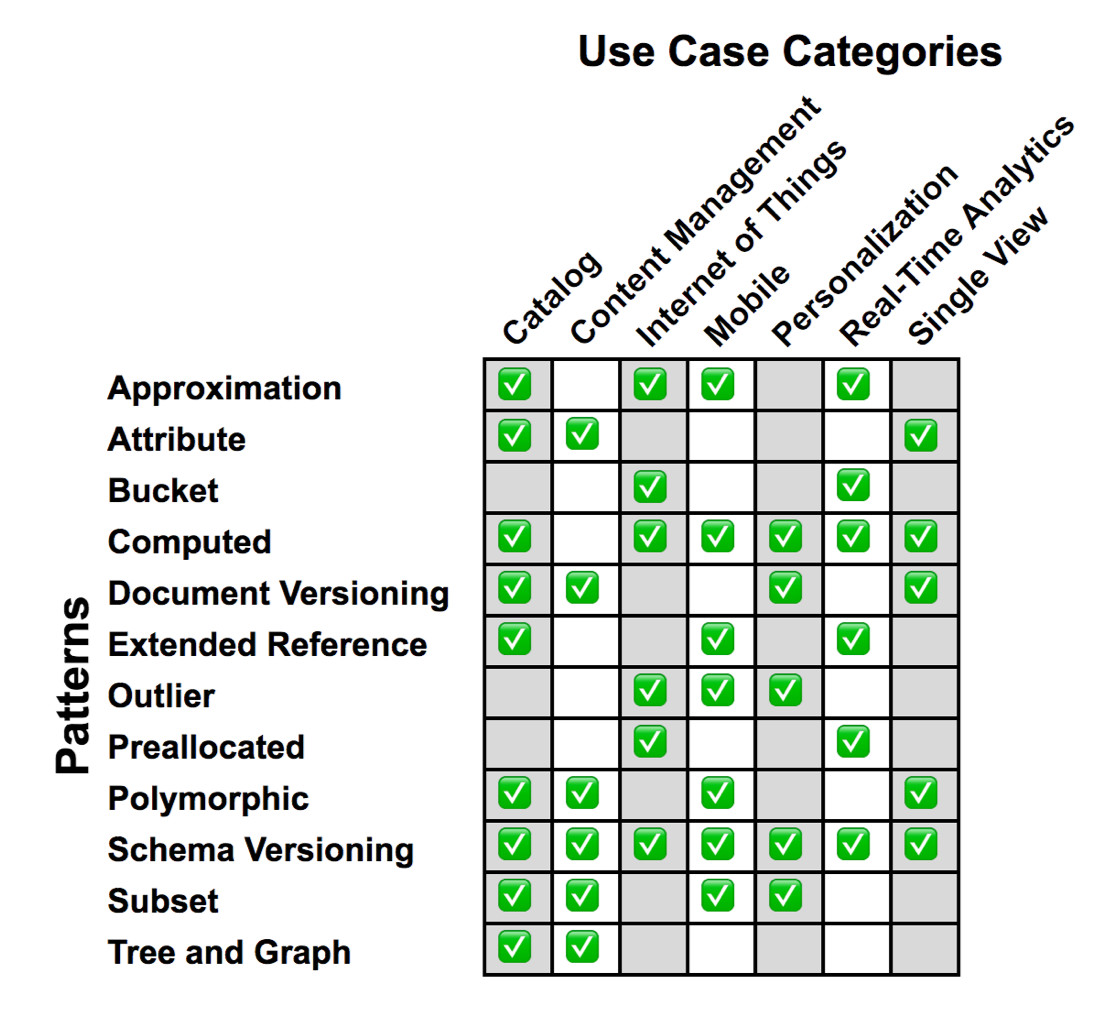
👩💻 사용 사례
해당 차트는 MongoDB가 고객사와 협업하며 체득한 어플리케이션 유형에 따른 스키마 가이드라인이다.
그러나 이것이 항상 적용되는 불변의 법칙은 아니기 때문에, 참고 목적으로만 보자.
데이터 모델링 방법은 데이터 접근 유형에 따라 크게 달라진다.
📔 마치며
이 시리즈를 통해 MongoDB 도큐먼트 모델이 데이터를 모델링하는 방식에 있어 큰 유연성을 제공한다는 것을 확인했을 것이다.
이러한 유연성은 매우 강력하지만, 어플리케이션의 데이터 액세스 패턴에 최적화된 형태로 사용해야 비로소 진가가 드러난다.
MongoDB에서 스키마 설계는 어플리케이션에 큰 영향을 미치며, 잘못된 스키마 설계로 인해 수 많은 성능 이슈를 초래할 수 있음을 기억해야 한다.
또한, 상황에 따라 스키마 설계 패턴들을 적절하게 섞어서 사용할 때 도큐먼트 모델의 힘이 더 강력해진다는 점을 알아두자.
예를 들어, Schema Versioning Pattern은 여러 다른 패턴들과 함께 사용할 수 있을 것이다.
지금까지 도큐먼트 모델의 유연성을 최대한 활용하기 위한 도구, 12가지의 스키마 설계 패턴을 알아보았다.
📄출처
