
1. BufferedReader를 사용하는 이유
자바에서 입력을 받을 때 사용하는 대표적인 Class는 Scanner이다. 나도 그동안 백준을 풀면서 Scanner을 사용해왔다.
하지만 다양한 기능을 지원하여 상대적으로 무거운 Scanner보다 문자열에 최적화 된 BufferedReader을 사용하는 게 속도가 더 빠르다.
2. 간단 비교
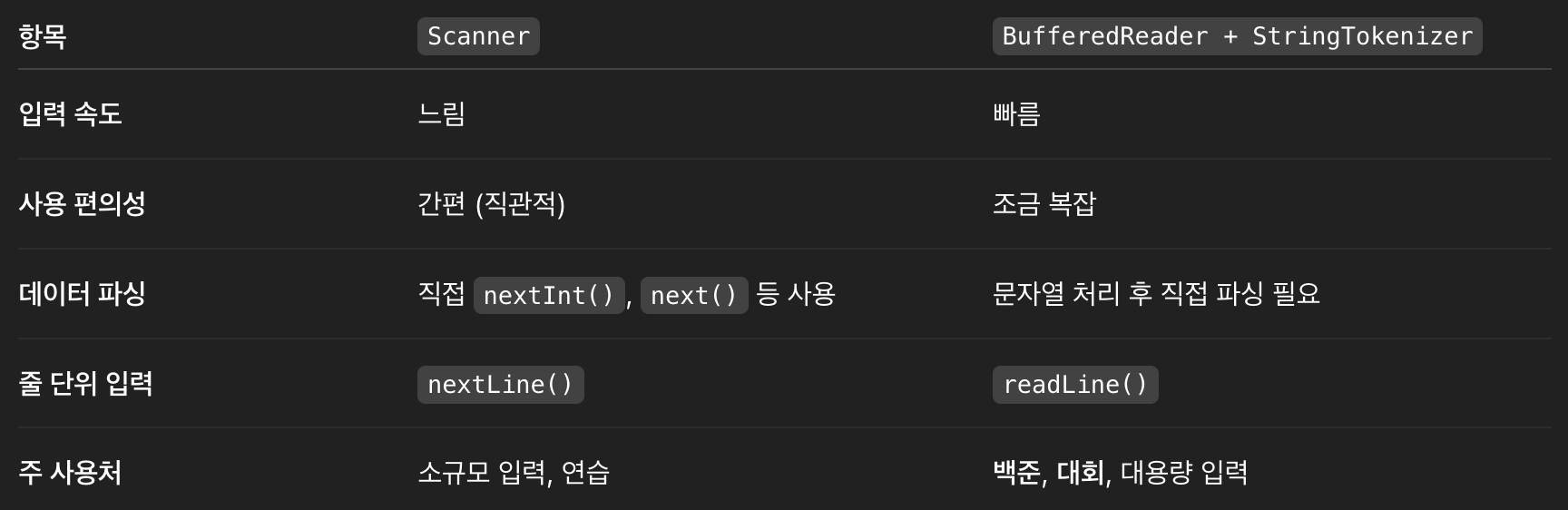
GPT가 정리한 비교 표이다.
입력량이 커질수록, Scanner의 속도는 매우 느려진다.
정리하자면, 코딩 테스트 문제를 위해서는 BufferedReader를, 그 외에 간단한 입력을 받기 위해서는 Scanner을 사용하는 게 적절한 것 같다.
3. 예시 코드
// Scanner 사용 코드
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt(); // 정수
long l = sc.nextLong(); // long
String s = sc.next(); // 공백 없는 문자열
sc.nextLine(); // 버퍼 비우기 ('\n' 제거)
String s2 = sc.nextLine(); // 한 줄 전체
}
}
// BufferedReader 사용 코드
// ‼️ 이 방식은 BufferedReader.readLine()으로 한 줄 전체를 문자열로 받고, 필요한 경우 직접 parseInt, parseLong으로 변환.
// ‼️ 이 방식은 버퍼를 비우지 않아도 됨 → 줄 단위로 입력을 항상 처리하기 때문.
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine()); // 정수
long l = Long.parseLong(br.readLine()); // long
String s = br.readLine(); // 공백 없는 문자열
String s2 = br.readLine(); // 한 줄 전체
}
}4. StringTokenizer 이란?
StringTokenizer는 Java에서 문자열을 특정 구분자 기준으로 "토큰" 단위로 분리하는 데 사용되는 클래스이다.
쉽게 말하면, 문자열을 자르고 하나씩 꺼낼 수 있게 도와주는 "문자열 분해 도구"라고 보면 된다.
(우리가 흔히 알고 있는 split() 메서드와 비슷하다고 생각하면 된다.)
5. split() VS StringTokenizer


YunseoChoe