
- 이전의 버전 2 api는 흔히 말하는 N + 1 문제가 발생한다. N + 1 문제란 1번의 조회가 이루어졌을때 연관된 엔티티에서 N번의 쿼리가 덧붙혀지는 것을 의미하는데, 여기서는 연관된 엔티티의 갯수 X order(주문) 수 만큼 쿼리가 실행되게 된다. 따라서 아래와 같은 버전 3을 만들어 보았다.
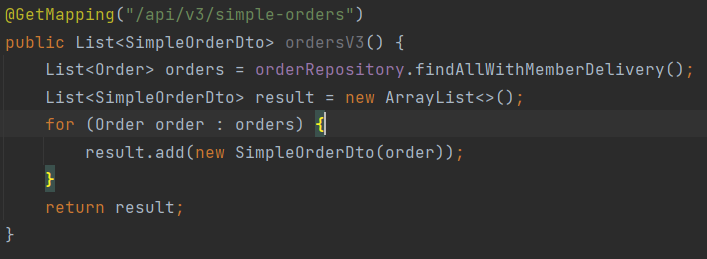
- 결과는 버전 2와 같다. 그러나 참조한 함수가 다르다.
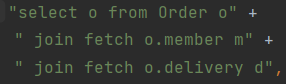
-
위와같이 join fetch를 이용해 select 하였다. 쿼리를 보았는데, 연관 엔티티가 2개이고 주문 수가 5개일때 1 + 2 X 5, 즉 11번의 쿼리가 나가지만 fetch join을 사용했을 때는, 물론 양이 많지만, 1번의 쿼리만 나가는 것을 알 수 있다.
-
또한 join fetch는 지연로딩을 무시하고 '실제 값을' '즉시' 가져온다.
-
지금까지의 버전들은 jpa에서 엔티티로 조회를 해서 dto를 변환을 하였다. 따라서 jpa에서 dto로 바로 끄집어 내보자.
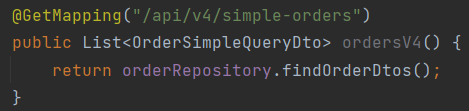
- 굉장히 간단하다. findOrderDtos는 쿼리문을 아래와 같이 짠다.

-
버전 3이 join fetch로 모든 엔티티를 조회하고 거기서 dto로 원하는 변수를 찾는 것이었다면, 버전 4는 직접 jpa에서 엔티티를 조회하는것이 아닌 쿼리문을 직접 작성하여 dto를 통해 바로 원하는 변수를 가져오는 것이 차이점이다.
-
또한 dto에서 조회하게되면 엔티티와 달리 setName 등으로 변경이 불가능하다. 그리고 직접 추가적인 쿼리문을 짜기 때문에 코드가 좀 더 지저분해질 수 있다.
-
버전 3과 4는 누가 더 우열에 있다고 말하기 어렵다. 버전 3은 엔티티를 직접 건드리지 않고 fetch를 통해 작업하였으므로 확장성, 즉 재사용성이 높아 협업에 있어 굉장히 유용할 것이고, 버전 4는 내가 하고있는 작업에 딱 맞는 쿼리를 직접 짜서 만든것이기 때문에 성능이 높을 것이다.
-
그러나 버전 3과 4의 쿼리문을 직접 보면 select문의 갯수 차이가 유일한 차인데, 쿼리문에서 성능차이가 가장 심하게 나는 곳은 조회가 아닌 join부분이 가장 많이 차지한다. 따라서, 물론 성능 테스트를 해 봐야겠지만 대부분의 경우엔 성능상 둘이 그렇게 차이가 크지 않다. (데이터양이 크거나 고객이 조회만하고 변경이 잘 없는 데이터일 경우 버전 4를 선택하는게 더 좋을수도 있다.)
-
결론적으로 버전3은 확장성이 높으나 성능이 버전 4보다는 살짝 낮고, 버전 4는 버전3보다 성능은 살짝 높으나 확정성은 낮다고 할 수 있다.
실무에서는 왠만하면 버전 3을 쓰자.
