[TIL] 2025/03/19 Pandas 활용하기
부트캠프에서 Python 라이브러리인 Pandas를 활용한 개인 과제를 내줬는데요!
오늘 문제를 다 풀어서 사용한 함수들을 다시 정리해 보겠습니다~
📌사용환경

구글에서 제공하는 editor인 코랩은 사용했습니다.
📌기본 라이브러리 import
import pandas as pd
import numpy as np
from datetime import datetime, timedeltapandas : 데이터 분석 및 조작을 위한 라이브러리
pd로 줄여서 라이브러리를 보다 편하게 사용 가능합니다!
df = pd.DataFrame(data) # data를 DataFrame으로 변환이런식으로 말이죠 !
numpy : 수치 연산을 위한 라이브러리
수학 연산을 수행하거나 배열을 생성하고 조작하는 데 사용 가능합니다!
datetime : 날짜 및 시간 관련 작업을 수행하는 표준 라이브러리
날짜 및 시간 정보 가져오기 (datetime.now())
날짜 계산 (timedelta 사용)
📌데이터 불러오기
df = pd.read_csv("/content/flight_data_homework.csv")pd.read_csv() 함수
: CSV(Comma-Separated Values) 파일을 읽어와 DataFrame 형태로 저장합니다
경로는 구글 드라이브에 csv파일을 가져와 사용했지만 파일이 로컬에 있다면 "C:/Users/.../flight_data_homework.csv"처럼 사용 가능 합니다
📌데이터프레임의 행(row)과 열(column) 개수 확인
df.shape #(10683, 11)df.shape는 (행 개수, 열 개수)를 튜플(tuple)로 반환합니다
여기서는, df.shape의 결과가 (10683, 11)이기 때문에 10683개의 행(row) 11개의 열(column) 을 가진 데이터라는 것을 알 수 있습니다
📌데이터프레임의 처음 5개 행 확인
df.head()df.head() 함수는 데이터의 처음 5개 행을 출력합니다
기본적으로 5개 행을 출력하지만, df.head(10)처럼 숫자를 넣으면 원하는 개수만큼 출력할 수 있습니다
+) df.tail() → 마지막 5개 행을 확인 가능
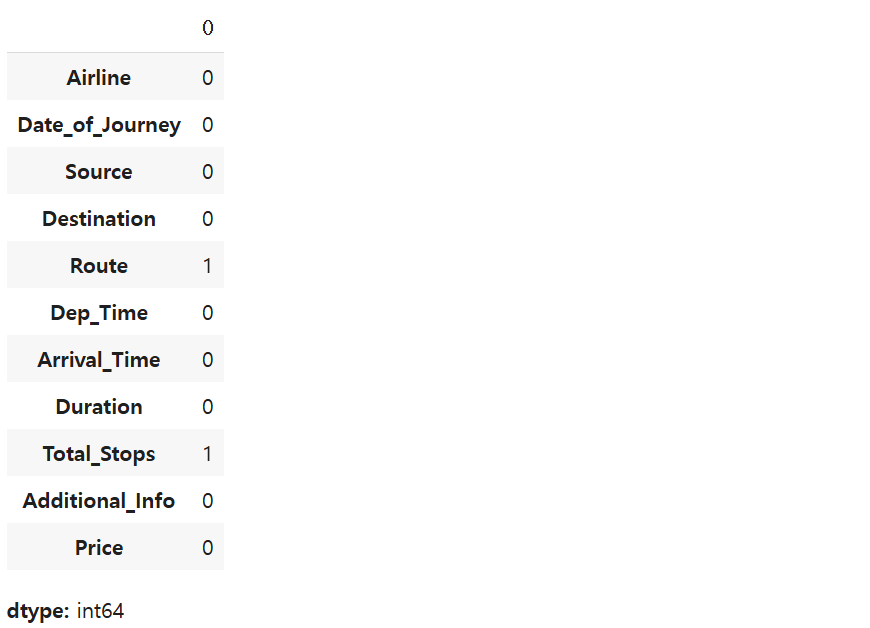
📌각 컬럼별 결측치 개수 확인
df.isnull().sum()df.isnull()
: 데이터프레임(df)에서 결측치(NaN)가 있는지 여부를 확인하는 함수
결측치면 True, 아니면 False 반환
.sum()
-> True(1) 값들을 합산하여 각 컬럼별 결측치 개수를 구함
📌결측치가 있는 행 제거
df = df.dropna(axis=0)df.dropna()
: 결측치(NaN)가 있는 행(row) 또는 열(column)을 제거하는 함수
axis=0 → 행(row) 단위로 삭제
axis=1 → 열(column) 삭제
이 함수를 실행해서 결측치를 제거하고 다시 결측치의 개수를 확인해 봤더니
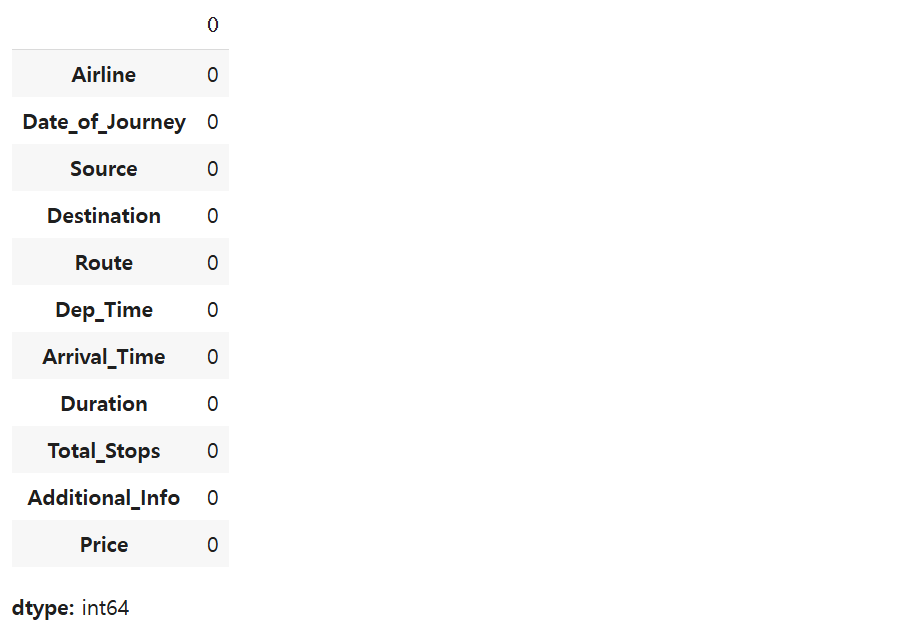
잘 제거됐다. 괜히 신기싱기...
📌Destination 기준으로 Price 평균 & 중앙값 구하기
df.groupby('Destination')['Price'].agg(['mean', 'median']).round(1)📌 설명
df.groupby('Destination') → Destination(목적지)별로 데이터를 그룹화
['Price'].agg(['mean', 'median']) → 그룹별 Price의 평균(mean)과 중앙값(median)을 계산
.round(1) → 소수점 첫째 자리까지 반올림
+) 추가 학습**
groupby()는 데이터를 특정 컬럼 기준으로 그룹화한 후, 각 그룹에 대해 연산(집계) 을 수행하는 기능
주요 집계 함수
| 함수 | 설명 |
|---|---|
| .mean() | 평균값 |
| .median() | 중앙값 |
| .sum() | 합계 |
| .count() | 개수(행 개수) |
| .max() | 최댓값 |
| .min() | 최솟값 |
| .std() | 표준편차 |
| .var() | 분산 |
| .first() | 첫 번째 값 |
| .last() | 마지막 값 |
df.groupby('Destination')['Price'].sum()이런 식으로 사용 가능!
여러 개의 집계 함수를 사용하고 싶으면!
df.groupby('Airline')['Price'].agg(['mean', 'median', 'sum', 'count'])두 개 이상의 컬럼을 기준으로 그룹화!
df.groupby(['A', 'B'])['C'].mean()특정 조건을 만족하는 그룹만 필터링!
df.groupby('A').filter(lambda x: x['B'].mean() > 100)📌Airline, Total_Stops 기준 Route 컬럼 중복 제거 & 인덱스 재정렬
df2 = df.groupby(['Airline','Total_Stops'])['Route'].unique().reset_index()df.groupby(['Airline','Total_Stops'])
-> Airline(항공사)와 Total_Stops(경유 횟수) 기준으로 그룹화
['Route'].unique()
-> Route(경로) 컬럼에서 중복을 제거하고 고유한 값만 리스트로 저장
.reset_index()
-> 그룹화로 변경된 인덱스를 초기화하여 새로운 데이터프레임(df2)로 저장
📌피벗테이블을 활용한 데이터 요약 pivot_table()
pd.pivot_table(df, index=['Source', 'Destination'], values='Airline', aggfunc='count').sort_values(by='Airline', ascending=False)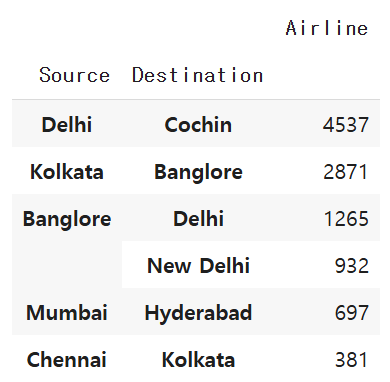
pd.pivot_table(df, index=['Source', 'Destination'], values='Airline', aggfunc='count')
-> 출발지(Source)와 도착지(Destination)를 기준으로 그룹화
aggfunc='count'를 사용하여 Airline 컬럼의 값 개수를 셈
.sort_values(by='Airline', ascending=False)
-> Airline 개수를 기준으로 내림차순 정렬하여 가장 많은 항공편이 있는 출발지-도착지 구간을 먼저 확인.
+) 추가 학습
pdf1 = pd.pivot_table(df, # 피벗할 데이터프레임
index = 'class', # 행 위치에 들어갈 열
columns = 'sex', # 열 위치에 들어갈 열
values = 'age', # 데이터로 사용할 열
aggfunc = 'mean') # 데이터 집계함수
pdf1pdf3 = pd.pivot_table(df,
index = ['class','sex'],
columns = 'survived',
values = ['age','fare'],
aggfunc = ['mean','max'])
pdf3dataframe : 피벗테이블을 적용할 데이터프레임
index : 그룹화할 기준이 되는 컬럼
columns : 컬럼 방향으로 정렬할 변수 (선택 사항)
values : 요약할 대상이 되는 컬럼
aggfunc : 적용할 집계 함수
📌특정 조건에 맞는 데이터 필터링
df[(df['Airline'] == 'Air India') & (df['Price'] >= 7000)]데이터 필터링 할 때 당황하지 말고 써보자!
📌수요일(Wednesday)의 평균 항공권 가격 계산하기
import pandas as pd
from datetime import datetime, timedelta
df['Date_of_Journey'] = pd.to_datetime(df['Date_of_Journey'], dayfirst=True)
df['Day_Name'] = df['Date_of_Journey'].dt.day_name()
wed = df.loc[df['Day_Name'] == 'Wednesday']
pd.pivot_table(wed, index = 'Day_Name', values = 'Price', aggfunc='mean')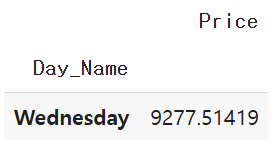
✅df['Date_of_Journey'] = pd.to_datetime(df['Date_of_Journey'], dayfirst=True)
pd.to_datetime()을 사용하여 Date_of_Journey 컬럼을 날짜 형식으로 변환
dayfirst=True : 날짜가 DD-MM-YYYY 형식일 경우, 이를 올바르게 변환
✅df['Day_Name'] = df['Date_of_Journey'].dt.day_name()
dt.day_name()을 사용하여 Date_of_Journey의 요일을 문자열로 추출
새로운 컬럼 Day_Name에 요일 저장
✅wed = df.loc[df['Day_Name'] == 'Wednesday']
df.loc[]을 사용하여 'Wednesday'인 행만 필터링
결과를 wed 데이터프레임에 저장
✅pd.pivot_table(wed, index = 'Day_Name', values = 'Price', aggfunc='mean')
wed 데이터프레임에서 Price 컬럼의 평균을 계산
Day_Name을 인덱스로 설정하여 그룹화
📌출발 시간을 기준으로 밤, 아침, 낮, 오후를 분류하고, 각 시간대별 항공사 개수 count
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
df['Dep_Time'] = pd.to_datetime(df['Dep_Time'], format='%H:%M')
df['Hour'] = df['Dep_Time'].dt.hour
df['Time_Zone'] = df['Hour'].apply(lambda x:
'밤' if 0 <= x < 5 else
'아침' if 5 <= x < 12 else
'낮' if 12 <= x < 18 else
'오후'
)
pd.pivot_table(df, values='Airline', index='Time_Zone', aggfunc='count')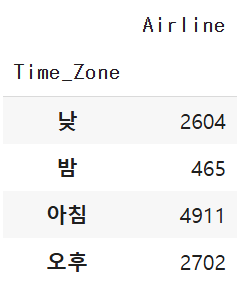
✅df['Dep_Time'] = pd.to_datetime(df['Dep_Time'], format='%H:%M')
Dep_Time 컬럼을 datetime 형식으로 변환
format='%H:%M' → Dep_Time이 "시간:분" (예: 14:30) 형식이므로 이를 명확하게 지정합니다
✅df['Hour'] = df['Dep_Time'].dt.hour
dt.hour 속성을 사용해 출발 시간(Dep_Time)의 "시간(Hour)" 값만 추출
Hour 값을 기준으로 Time_Zone 컬럼을 생성하는데 Lambda 함수 + if-else 문을 사용해 시간대를 분류합니다.
그리고 pivot table 생성!! 이건 위에서 했으니까 pass


파이티잉🤩