코딩뉴비의 OCR 문제 해결기 - 2
Google Vision
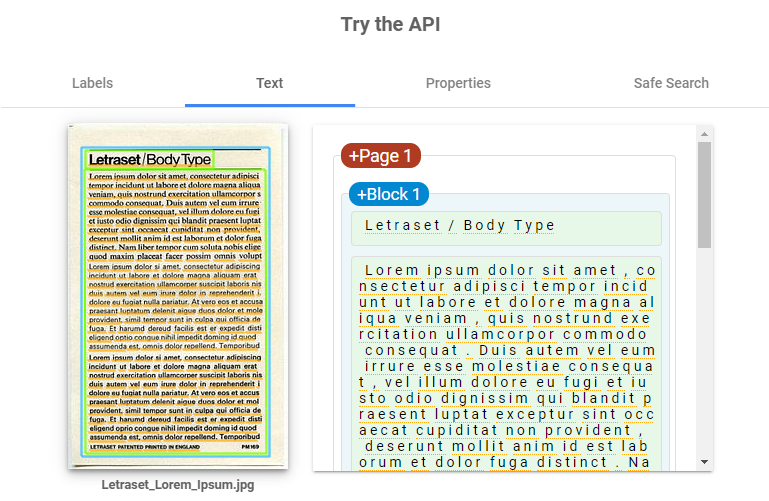
구글 비전 API를 이용한 OCR에서는 다음과 같이 유사한 문장을 연결해 하나의 문단으로 구성해준다.
이를 '블록'이라고 하며, 이걸 통해 문제를 해결할 수 있겠다는 희망을 봤다
블록이 완벽하게 문장에 맞게 지정되지는 않지만, 그래도 기존 문서의 레이아웃에 맞게 블럭을 구성해주고, 가져와서 사용할 수 있었다.
- BlockParser
fun getTextBlocks(response: AnnotateImageResponse): List<String> {
return response.fullTextAnnotation.pagesList
.flatMap { page -> page.blocksList }
.map { block -> getTextInBlock(block) }
.toList()
}Response에 있는 Block들을 순회하여 String List로 바꿔주는 간단한 함수이다.
요걸 개행문자등을 넣어 flatten 시킨 뒤 번역해서 클라이언트에게 반환하면 해결되는 줄 알았..으나
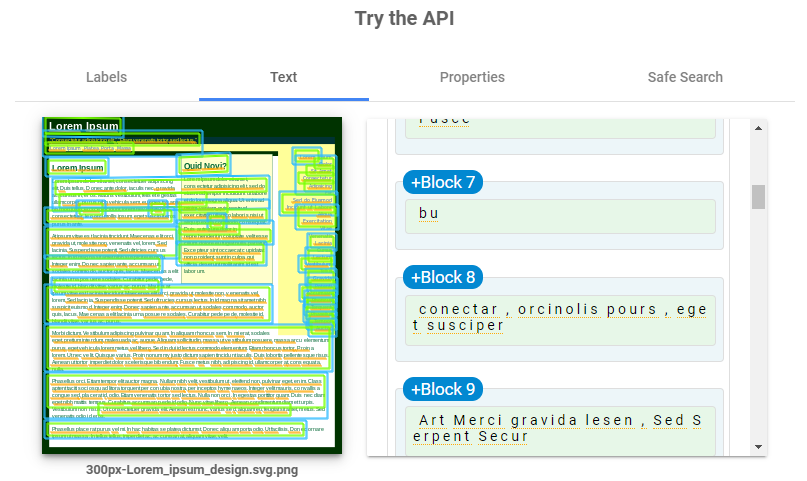
1편에서 발목을 잡았던 단락 + 표에서 블럭이 제대로 안잡히는 문제 때문에 변경 요청이 들어왔다.
위 이미지를 보면 분명 문단에 맞게 블럭이 잘 잡힌것처럼 보이나, 중간에 블럭사이에 또 다른 블럭이 하나 둘 잡혀있는 모습을 볼 수 있고, 이를 텍스트화 시키면 중첩된 블럭때문에 가독성이 상당히 떨어졌다.
이를 최대한 전처리 과정을 거쳐 없앴으나 (의미 없는 데이터일경우 제거), 이번엔 표에서 문제가 발생했다.
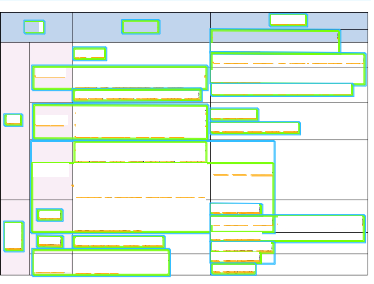
일단 내용은 지운 상황인데, 위 표를 보면 각 셀마다 블럭(초록색)이 잘 잡혀있는 경우도 있지만, 셀 경계를 침범해서 다른 셀과 합쳐져 있는 경우가 있다.
이 때문에 파싱된 데이터가 정상적인 블럭의 데이터인지 판단할 수 없어 매우 곤란했고, 이를 클라이언트에게 그대로 반환해도 가독성이 매우 좋지 않은 상태로 반환되었다.
따라서.. 일단 표는 둘째치더라도 문서의 문단을 잘 파싱할 수 있는 방법에 대해 고민해봤다.
어떻하지
일단 지금까지 생각해본 방법은 '응답의 가공'이였다. API를 통해 읽은 문서의 문자들의 좌표를 어떻게든 잘 이용하고, 그걸 잘 끼워맞춰서 문단을 구성하자~ 라는 방식이다.
하지만, 그 방식에는 항상 예외가 존재했고 이 예외로 인해 진행이 어려웠다.
LLM
그래서 더 생각해본 결과, ChatGPT를 이용해 재구성 하는 방법을 제안했던게 생각났다.
어쨌든 문장을 끼워맞출려면 LLM을 거치는게 사실상 제일 좋은 방법이라 관련 Bert 모델과 LLM을 찾아봤으나..
이것도 좋은 방법이 아니였다.
일반 줄글의 경우는 문장이 명확하고, 주제도 정해져있어 문장 유사도 비교를 이용해 하나의 문단을 구성할 수 있지만 (KoBert등 형태소 분석기 이용..) 위 사안에는 맞지 않았다.
도표의 경우 각 cell이 header일수도 있고, 1. 2. 3과 같은 순서를 표시한 단순 셀일 가능성도 있기 때문에 의미를 담지 않아 이걸 통해 문단을 구성하기란 쉽지 않았다.
AI
그래서 다음 방법은 직접 학습하는 방법밖에 없나.. 라고 생각했다. 하지만 딥러닝쪽으로는 깊게 알고 있지 않아 상당히 난감했고, 어떤 모델을 기반으로 제작을 해야하는지, LLM을 이용할거면 위 도표, 단락과 같은 문제는 어떻게 해결할지 잘 몰랐다.
관련해서 더 찾아보던중 영수증, 주민등록증, 운전면허증과 같이 일정한 규격이 있으면 그걸 파싱해서 json으로 반환해주는 기능이 clova에 있었으나, 이번 프로젝트에서는 문서의 규격이 일정하지 않았다.
하아...
그래서 더 찾아보던중 문서 AI라는것을 찾았다.
말 그대로 문서를 분석해서 문단, 표 등등을 추출해 줄 수 있는 서비스였다.
하지만 지금 하는 프로젝트는 문서이긴 하지만, Input이 사진에 의존하는 OCR 서비스였고, 해당 서비스를 사용하지 못할것 같았다.
아무리 문서라도 이미지로 되어 있으면 문서로 바꾸는 과정이 사실상 어려우니까.
그런데 OCR에 AI를 적용해 위 문서AI처럼 체계적으로 분석해주는 API가 있었다
Document Intelligence
말 그대로 문서 지능이다. 문서를 분석하는 AI를 이용하여 각 문단의 위치와, 표, 각종 정보를 분석하고 반환해주는 서비스였다.
이를 Azure에서 제공하였는데 위 문제점을 모두 해결해주었다.
Azure의 컴퓨터 비전을 이용해서 이미지의 내용을 모두 읽고, 이를 AI를 이용해 분석하며 데이터를 추출하는 방식으로 이루어졌다.
AI를 거쳐 데이터를 추출하는 방식이라 기존 OCR보다 조금 더 오랜 시간이 소요됐지만, 위 문제점인 도표간 문단 겹침, 단락 문제를 해결하여 깔끔한 결과를 반환해주었다.

AI 그는 신이야!!!
내용은 마스킹했습니당
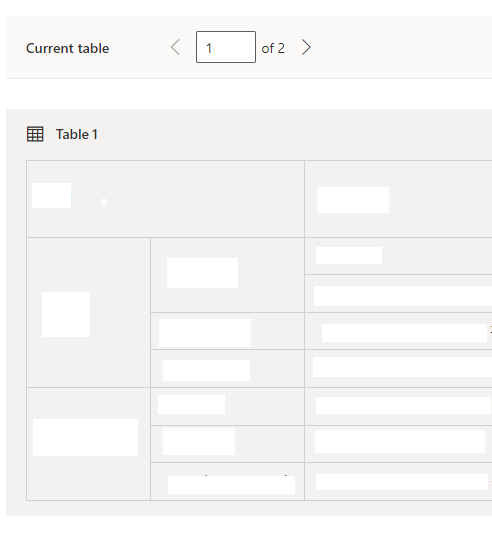
그리고 Table탭에서는 위와 같이 읽혀진 테이블을 재구성해서 반환해주기 때문에 이걸 잘 이용하면 표 또한 깔끔하게 반환할 수 있었다.
(각 cell마다 row, colspan값이 있어 병합된 셀도 인식가능)
Return
이렇게 Azure를 이용해서 잘 가져온 문단을 String으로 잘 반환해서 해결되었다.
라고 끝났으면 좋았다.
표를 문자열로 반환하니 가독성이 좋지 않은점이 지적되었다.
예를 들어
| 과목 | 성적 |
|---|---|
| 국어 | 100 |
| 수학 | 95 |
위와 같은 표를 파싱해서 반환한다고 하자. 문자열이니 각 cell은 하나의 문장으로 반환될것이다.
{"과목", "성적", "국어", "100", "수학", "95"}
이를 flatten 하면 "과목\n성적\n국어\n100\n수학\n95"로 나타낼 수 있다.
이걸 딱 봤을때 아~ 이건 성적표구나~ 라고 한눈에 들어올까?
또 하나의 난관을 마주했다.
회의 당시 이건 표현할 방법이 없어 추후에 Azure의 표 분석기(위 도표 사진)을 이용해서 최대한 클라이언트에서 표를 나타낼 수 있도록 지원한다고 했으나 가독성이 떨어진다고 계속 말씀을 하시면서 파파고의 이미지 번역을 비교대상으로 지속적으로 이야기 하셨다.
근데 해당 기능을 알아보지 않은건 아니였다. 위 Azure외에도 AI를 이용해서 문단을 분석해주는 서비스는 2개가 더 있었다.
-
Upstage Layout Analysis (미출시)
OCR로 읽혀진 데이터를 html로 표현 -
Papago Image Translation
업로드한 이미지를 OCR 한뒤 문단을 구성하고 이를 이미지 번역해서 반환.
Upstage의 기능의 경우 html로 표현하기 때문에 원본을 재구성할 수 있어 사용하고자 했으나, 아직 출시되지 않아 제한되었고, 파파고 이미지 번역은 구글링을 하다가 겨우 찾았으나, 무료 한도도 없었고, 중요한 '표 분석'기능이 제공되지 않았다.
Azure의 경우 표를 인식해서 반환까지 해주지만, Papago Image Translation은 표를 반환하지 않고, 결과값으로 받을 수 있는 이미지도 Papago의 번역기능을 거쳐 생성된 이미지이므로 기존에 고려했던 구글 번역기를 사용할 수 없었다.
물론 이미지 생성없이 단순 문장인식과 번역기능만 사용할 수 있지만, 단가도 쌔고 azure랑 큰 차이점을 느낄 수 없었다.
그래서 일단 회의를 마무리 짓고 다시 생각해봤을때 '표'가 중요한게 아니라 '이미지'를 통해 한눈에 볼 수 있다는게 중요해서 그런게 아닐까 하고 생각해 봤다.
3편에서 계속..