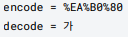
✅ 컴퓨터와 데이터
컴퓨터의 메모리는 반도체를 만들어져 있음 -> 수많은 전구들이 모여있음
이 전구들은 트랜지스터 라고 불리는 작은 전자 스위치임
각각의 트랜지스터 는 전기가 흐르거나 흐르지 않는 두가지 상태를 가짐 -> 0과 1이라는 이진수 표현
이 트랜지스터 들이 모여서 메모리를 구성 -> RAM 이 이런방식으로 만들어진 메모리의 한 종류임
컴퓨터가 정보를 처리하거나 처리할 때, 이 전구들을 켜고 끄는 방식으로 데이터를 저장 및 읽음
현대의 컴퓨터는 이 과정이 빠르게 일어나서 초당 수억번의 데이터 접근 처리가 가능하다
전구를 끈다 = 숫자 0로 표현
전구를 켠다 = 숫자 1로 표현
숫자 2나 3을 표현하려면 전구를 두개이상 사용하면 된다
전구를 한개 키고 한개는 끈다 = 1 0 = 이진수 계산하면 = 숫자 2로 표현
여기서 핵심은 컴퓨터는 사람과 같이 십진수를 이해해서 숫자를 메모리에 저장하거나 불러오는것이 아니라 단지 전구의 상태만 변경하거나 확인하는 것이다
즉 컴퓨터에 10진수 100을 저장하면 컴퓨터는 10진수 100을 2진수 1000100 으로 변경해서 저장함
✅ 비트 : 데이터를 나타내는 최소 단위
1bit : 2가지 표현 -> 0, 1 (0~1 표현)
2bit : 4가지 표현 -> 00, 01, 10, 11 (0~3 표현)
3bit : 8가지 표현 -> 000, 001, 010, 011, 100, 101, 110, 111 (0~7 표현)
1bit 를 추가할 때마다 표현할 수 있는 숫자는 2배씩 늘어난다
8bit = 1 byte 로 참고하자
만약 음수를 표현하고 싶으면 맨 앞자리 1bit를 음수, 양수를 표현하는데 사용한다
EX ) 8bit 예시
양수만 표현하는 경우
- 8bit를 모두 숫자표현에 사용한다 (0 ~ 255)
음수 표현이 필요한 경우
- 앞 1bit를 음수 양수를 구분하는데 사용하고, 나머지 7bit를 숫자 범위로 사용
- 0 ~ 127 (양수 표현시 첫 비트를 0으로 사용 -> 01111111)
- -128 ~ -1 (음수 표현시 첫 비트를 1로 사용 -> 11111111)
✅ 컴퓨터와 문자 인코딩
컴퓨터는 10진수를 2진수로 변경해서 메모리(전구)에 저장할 수 있지만
숫자가 아닌 문자는 2진수로 변경하는 방법이 없다
이를 해결하기 위해서 초기 컴퓨터 과학자들은 문자 집합을 만들고 각 문자에 숫자를 연결시켰다
EX ) 문자 'A'
-
문자 인코딩: 문자 집합을 통해 문자를 숫자로 변환하는 것
컴퓨터에 문자 'A' 저장 -> 컴퓨터는 문자 집합을 통해 'A'의 숫자 값 65를 찾음
-> 65를 이진수로 변환하여 메모리에 저장 -
문자 디코딩: 문자 집합을 통해 숫자를 문자로 변환하는 것
메모리에 저장된 65를 불러오기 -> 문자 집합을 통해 문자 'A'를 찾아서 화면에 출력
✅ ASCII 문자 집합 (아스키 문자 집합)
- 컴퓨터 회사마다 문자 집합이 다르면 문제가 발생할 수 있다
- 이러한 호환성을 해결하기 위해서
ASCII(미국 표준 코드) 라는 표준 문자 집합이 1960년도에 개발됨 - 총 7bit를 사용하여 총 128가지 문자를 표현할 수 있다
✅ ISO_8859_1 문자 집합
- 서유럽 문자를 표현해야 해서 1980년도에 만들어짐
- 기존
ASCII문자 집합에서 1bit를 추가하여 총 256가지를 표현함
✅ EUC-KR 문자 집합
- 한국에도 컴퓨터 사용 인구가 증가하면서 1980년도에 만들어짐
- 모든 한글을 담지 않고, 자주 사용하는 한글 2350개만 포함해서 만듬
- 2byte(16bit)를 사용하고 기존에
ASCII를 포함해서 총 65536가지 표현이 가능함 - 영어를 사용하면 1byte, 한글을 사용하면 2byte를 메모리에 저장
✅ MS949 문자 집합
- 마이크로소프트가
EUC-KR을 확장하여 1990년도에 만듬 - 한글의 초성, 중성, 종성을 모두 합치면 11172자임
- 기존
EUC-KR호환을 이루면서 한글 11172자를 모두 수용하도록 만듬
-> 기존EUC-KR은 "쀍", "삡" 등의 드물게 사용하는 음절은 표현하지 못함 - 윈도우 시스템에서 계속 사용됨
문제점 : 전세계적으로 컴퓨터 인구가 늘면서, 전 세계 문자를 다 표현할 수 있는 문자 집합이 필요해짐
-> 한글 문자표를 PC에 설치하지 않으면 외국인들은 한글로 작성된 문서를 열어볼 수 없음
✅ 유니코드
- 전 세계의 모든 문자와 기호를 하나의 표준으로 통합하여 만든 문자 집합
UTF-16UTF-8두 가지의 종류가 있으며 초반에는 16이 인기가 있었음
✅ UTF-16
- 16bit(2byte) 기반으로 자주 사용하는 기본 다국어들은 다 2byte로 표현
- 그외 고대문자, 중국어 확장 한자 등 자주 사용하지 않는 것들은 4byte로 표현
- 하지만
ASCII영문도 2byte를 사용해서ASCII와 호환이 되지 않는 단점이 있음 - 문서의 80%이상은 영문이다
UTF-16을 사용하면 영문의 경우 다른 문자 집합보다 2배의 메모리를 사용
✅ UTF-8
-
1byte ~ 4byte를 사용해서 문자를 인코딩
1byte :ASCII, 영문, 기본 라틴 문자
2byte : 그리스어, 히브리어 라틴 확장 문자
3byte : 한글, 한자, 일본어
4byte : 이모지, 고대문자 -
ASCII를 제외한 일부 언어에서는 더 많은 용량을 사용한다
->UTF-16에서는 대부분 2byte로 인코딩 되지만,UTF-8에서는 한글의 경우 3byte임
-> 즉EUC-KR과UTF-8에서 한글은 호환이 안됨
-> 하지만UTF-8은ASCII와 호환된다는 장점이 있음 -
UTF-8은 현대에서 자주 사용하는 표준 인코딩 기술임 (문서의 80% 이상은 영어이기 때문)
✅ 문자 집합 조회
- 현재 시스템에서 사용하는 기본 문자 집합을 반환하는 방법
- 문자 집합을 지정하지 않으면 현재 시스템에서 사용하는 기본 문자 집합을 인코딩에 사용
Charset defaultCharset = Charset.defaultCharset();
System.out.println(defaultCharset); // 운영체제마다 다르지만 대부분 UTF-8이 나옴ASCII 영문 인코딩은 UTF-16 을 제외하고는 모두 호환이 된다
-> ASCII는 영문을 1byte를 사용하는데 UTF-16 은 영문을 2byte로 사용하기 때문에
한글같은 경우 EUC-KR(M949) 와 UTF-8은 호환되지 않는다
-> EUC-KR(M949) 는 2byte를 사용하는데 UTF-8 은 한글을 3bye로 사용하기 때문에
✅ URL이 ASCII 를 사용하는 이유
HTTP 메시지에서 시작 라인(URL을 포함)과 HTTP 헤더의 이름은 항상 ASCII 를 사용해야 함
HTTP 메시지 바디는 UTF-8과 같은 다른 인코딩을 사용할 수 있다.
지금처럼 UTF-8이 표준화된 시대에 왜 URL은 ASCII만 사용할 수 있을까?
- 초기 인터넷의 기술적 제약과 전 세계적인 호환성을 유지하기 위한 선택했기 때문에
- 순수한 UTF-8로 URL을 표현하려면, 전 세계 모든 네트워크 장비, 서버, 클라이언트 소프트웨어가 이를 지원해야함
- HTTP 스펙은 매우 보수적이고, 호환성을 가장 우선시
그러면 URL에 쿼리스트링 방식으로 한글을 보내면 어떻게 될까?
http://localhost:12345/search?q=가나다
아마 출력은 %EA%B0%80%EB%82%98%EB%8B%A4 로 출력 될 것이다
이를 해결하려면 퍼센트(%) 인코딩 방식을 사용해야한다
- 클라이언트: 가 전송 희망
- 클라이언트 % 인코딩: %EA%B0%80
- "가"를 UTF-8로 인코딩
- EA , B0 , 80 3byte 획득
- 각 byte를 16진수 문자로 표현하고 각각의 앞에 % 를 붙임
- 클라이언트 서버 전송: q=%EA%B0%80
- 서버: %EA%B0%80 ASCII 문자를 전달 받음
%가 붙은 경우 디코딩해야 하는 문자로 인식- EA , B0 , 80 을 byte로 변환, 3byte를 획득
- EA , B0 , 80 (3byte)를 UTF-8로 디코딩 문자 "가" 획득
public static void main(String[] args) {
String encode = URLEncoder.encode("가", UTF_8);
System.out.println("encode = " + encode); // encode = %EA%B0%80
String decode = URLDecoder.decode(encode, UTF_8);
System.out.println("decode = " + decode); // decode = 가
}
