✅ 트랜잭션 : 논리적으로 절대 쪼개질 수 없는 하나의 이상의 데이터베이스 작업 묶음
트랜잭션으로 묶인 작업들은 모두 다 성공해야만 그 결과를 실제 데이터베이스에 영구적으로 반영함
만약 작업그룹 내에서 단 하나의 작업이라도 실패하면, 전에 성공했던 작업들을 되돌려야함
트랜잭션은 원자성 일관성 격리성 지속성 을 다 보장해야함
-
원자성: 트랜잭션 내에서 실행한 작업들은 마치 하나의 작업인 것처럼 모두 성공하거나 실패해0야함 -
일관성: 모든 트랜잭션은 일관성 있는 데이터베이스 상태로 유지해야함
EX) 트랜잭션 시작 전 A(5만원) B(2만원) 계좌의 총액은 7만원이다. 여기서 성공적인 트랜잭션 후
A(4만원) B(3만원) 7만원 -> 즉 트랜잭션이 시스템의 전체 돈의 총량을 바꾸지 않는일관성을 유지
EX) 잔액이 >= 0 이라는 제약 조건이 있을 때, 잔고를 음수로 만드는 트랜잭션은 실패한다
-> 즉 잔고는 0원 이상이어야 한다는일관성을 유지 -
격리성: 동시에 실행되는 트랜잭션들이 서로에게 영향을 미치지 않도록 격리해야함
->격리성은 동시성과 관련된 성능 이슈로 인해 트랜잭션 격리 수준을 선택해야 한다.동시성 문제 유형 :
더티 리드반복 불가능 읽기유령읽기등이 있다더티 리드: 한 트랜잭션이 아직 COMMIT 하지 않은, 수정중인 데이터를 다른 트랜잭션이 읽는것
EX) 트랜잭션 A가 특정 상품의 가격을 100 -> 120원으로 바꾸고 아직 COMMIT을 하지 않은 상태에서
트랜잭션 B가 이 상품의 가격을 조회하면 120원으로 보인다. 하지만 트랜잭션 A 작업이 ROLLBACK 을 하면, 가격은 다시 100원이 되고 트랜잭션 B는 존재하지 않는더러운데이터를 읽은 것반복 불가능 읽기: A 트랜잭션 내에서 동일한 SELECT 쿼리를 두번 실행했는데, 그 사이 B 트랜잭션이 값을 수정하고 COMMIT 하는 바람에 두 SELECT 쿼리의 결과가 다르게 나오는 현상
EX) 트랜잭션 A가 특정상품의 가격을 조회하였더니 100원이 나오고 다른 작업을 실행한다. 그 사이에 트랜잭션 B가 값을 150원으로 바꾸고 COMMIT 하였다. 그 후 끝나지 않는 트랜잭션 A에서 다시 그 상품의 가격을 조회하였더니 150원으로 바뀌어있다. 결국 트랜잭션 A에서 같은 데이터의 반복 조회가 불가능해진 것이다.유령 읽기: 한 트랜잭션 내에서 특정범위 데이터를 두번 읽었는데, 첫 번째 조회에서 없던 행이 두번째 조회에서는 나타나는 현상 -> 다른 트랜잭션이 새로운 행을 INSERT하고 COMMIT해서 발생
EX) 트랜잭션 A가 '전자기기' 카테고리의 상품 수를 세었더니 5개였는데, 그 사이 다른 트랜잭션 B가 새로운 '전자기기' 상품을 등록 -> 트랜잭션 A가 다시 '전자기기' 카테고리의 상품 수를 세었더니 6개가 되었음 -> 없었던 유령상품이 나타남
트랜잭션 격리 수준
READ UNCOMMITED (커밋되지 않은 것 읽기) => 더티리드, 반복불가능읽기, 유령읽기 다 발생
READ COMMITTED (커밋된 읽기) => 반복불가능읽기, 유령읽기 발생
REPEATABLE READ (반복 가능한 읽기) => 유령읽기 발생
SERIALIZABLE (직렬화 가능) => 세개 다 해결이 가능
ORACLE 의 기본 격리 수준은 READ COMMITTED 고 MYSQL의 기본 격리수준으 REPEATABLE READ 로
특별한 이유가 없다면 기본 격리수준을 사용하면 된다. 하지만 트래픽이 많고, 반복불가능 읽기, 유령읽기 상황이 많이 발생된다면 READ COMMITTED 를 사용하는것이 좋다
SERIALIZABLE 은 동시성이 많이 떨어지기 때문에 성능에 병목이 생길 가능성이 매우 높아서 사용하지 않는것이 좋음
실질적으로 한 트랜잭션에서 같은 쿼리를 두번 하는 작업은 거의없기 때문에 더티 리드 만 해결하는것도 좋은 방법이다
지속성: 트랜잭션을 성공적으로 끝내면 결과가 항상 기록되어야함 (내용을 복구하기 위해서)
즉 COMMIT 된 트랜잭션 결과는, 시스템 장애가 발생하더라도 영구적으로 보존된다
✅ 데이터베이스의 연결구조와 DB 세션
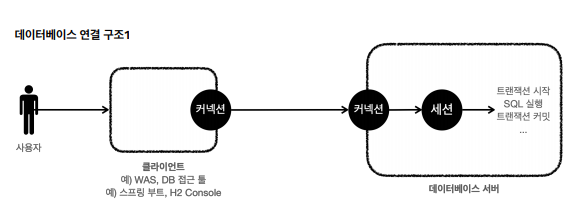
- 사용자는 웹 애플리케이션 서버 (WAS)와 같은 클라이언트를 사용해서 데이터베이스 서버에 접근
- 클라이언트는 데이터베이스 서버에 연결을 요청하고
커넥션을 맺음 - 데이터베이스 서버는 내부에
세션을 만듬 세션은 트랜잭션을 시작하고,COMMIT또는ROLLBACK을 함- 사용자가
커넥션을 닫거나 DBA 세션을 강제로 종료하면 세션은 종료됨
수동 커밋vs자동 커밋
트랜잭션을 사용하려면자동 커밋과수동 커밋을 이해해야 한다
자동 커밋으로 설정하면 쿼리 실행 직후에 따로COMMIT이나ROLLBACK명령어를 호출하지 않아도 되지만, 원하는 트랜잭션 기능을 제대로 사용할 수 없다.
수동 커밋으로 설정하면 쿼리 직후에 꼭COMMIT이나ROLLBACK을 호출해야한다.
수동 커밋모드로 전환하는 것을 트랜잭션을 시작한다라고 표현할 수 있다.
수동 커밋 으로 했을 경우 세션 1에서 쿼리 작업을 진행 후 COMMIT 명령어를 호출하지 않으면
세션 1에서는 쿼리 작업의 결과를 볼 수 있지만, 세션 2에서는 아직 반영이 되지 않았기 때문에 확인할 수 없다.
자동커밋 설정 : set autocommit true;
수동커밋 설정 : set autocommit false;
데이터베이스는 기본적으로 자동커밋(오토커밋) 설정이 되어 있어서
CRUD를 해도 일일이 COMMIT, ROLLBACK 처리를 안해줘도 됨
✅ DB 락
DB 락 : 세션 1과 세션 2가 동시에 같은 데이터를 수정하면 원자성 의 문제점이 발생한다. 이러한 문제점을 막기 위해서 세션이 트랜잭션을 시작하고 데이터를 수정할 때 COMMIT 이나 ROLLBACK 을 하지 않았으면, 다른 세션에서 해당 데이터를 수정할 수 없도록 막는 것을 DB 락 이라고 한다.
세션1에서 COMMIT 이나 ROLLBACK 을 수행하면, 세션 2에서는 락 을 얻으면서 쿼리 진행이 가능하다
락 타임아웃 : 다른 세션에서 락을 얻을 때 까지 기다리는데, 그 락을 타임아웃으로 설정해서
시간이 넘어도 락을 얻지 못하면 락 타임아웃 오류가 발생
✅ 트랜잭션 매니저
트랜잭션은 비즈니스 로직이 있는 서비스 계층 에서 시작해야 한다.
DB 트랜잭션을 사용하려면 트랜잭션을 사용하는 동안 같은 커넥션 을 유지해야 한다.
트랜잭션 매니저 : 데이터베이스 시스템에서 트랜잭션을 관리하는 중요한 구성 요소
-> Oracle, MySQL, PostgreSQL 등에서 트랜잭션 매니저가 내장되어 있음
-> 트랜잭션 매니저 는 크게 트랜잭션 추상화 와 리소스 동기화 의 역할을 담당한다
트랜잭션 추상화: 데이터 접근 기술에 따라서 (JPA, JDBC 등등) 트랜잭션 구현체를 만들어두었기 때문에 가져다 사용하기만 하면 된다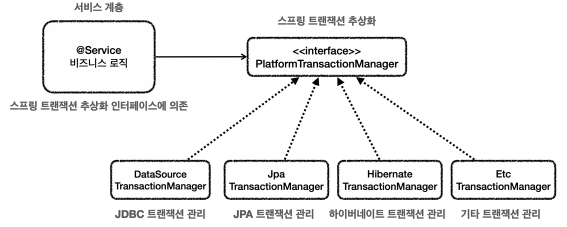
리소스 동기화:커넥션을 파라미터로 전달 할 필요 없이트랜잭션 동기화 매니저를 통해서 커넥션을 보관해서 커넥션이 필요할 때 갖다 씀 (커넥션유지가 쉬워짐)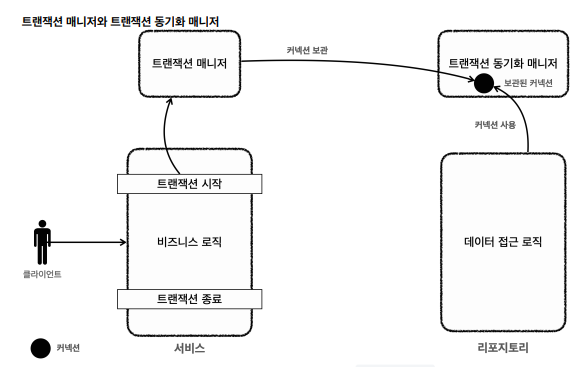
✅ 트랜잭션 템플릿
서비스에서 트랜잭션을 시작하면 try catch finally 포함한 commit rollback 코드가 반복됨
달라지는 부분은 서비스 비즈니스 로직만 달라짐
이런 반복되는 부분을 템플릿 콜백 패턴 을 활용하면 해결 가능함
-> 스프링에서 제공하는 TransactionTemplate 클래스
-> 언체크 예외가 발생하면 rollback 처리, 체크 예외의 경우 commit 처리
트랜잭션 템플릿 덕분에 반복되는 코드는 제거 할 수 있다
하지만 서비스 로직 뿐 아니라 트랜잭션을 처리하는 기술 로직도 포함되어 있다.
//ex)
txTemplate.executeWithoutResult((status) -> { // 트랜잭션 처리 기술
try {
bizLogic(fromId, toId, money); //비즈니스 로직
}
catch (SQLException e) {
throw new IllegalStateException(e);
}
});이러한 문제점을 해결하기 위해 트랜잭션 AOP 를 사용한다
✅ 트랜잭션 AOP
트랙재션 처리가 필요한 곳에 @Transactional 어노테이션을 붙여주면 됨
이러한 방법을 선언적 트랜잭션 관리 라고 불린다.
위에서 설명한 트랜잭션 매니저 또는 트랜잭션 템플릿 등을 사용해서 트랜잭션 관련 코드를 직접 작성하는 것을 프로그래밍 방식의 트랜잭션 관리 라고 한다.
대부분 실무에서는 선언적 트랜잭션 관리 를 많이 사용
스프링 트랜잭션 AOP 는 이 어노테이션을 인식해서 트랜잭션 프록시 를 적용시켜줌
프록시 : 다른 객체에 대한 대리자 역할을 하는 디자인 패턴
프록시를 사용하면 트랜잭션을 처리하는 객체와 비즈니스 로직을 처리하는 서비스 객체를 분리 가능하다
즉 서비스 계층에서는 순수한 비즈니스 로직만 남길 수 있음
✅ 스프링 부트의 자동 리소스 등록
스프링 부트가 등장하면서
DataSource 랑 트랜잭션 매니저를 직접 빈으로 등록할 필요 없이 자동 등록이 가능해짐
기존에는 다음과 같이 스프링 빈 으로 직접 등록했었음
@Bean
DataSource dataSource() {
return new DriverManagerDataSource(URL, USERNAME, PASSWORD);
}
@Bean
PlatformTransactionManager transactionManager() {
return new DataSourceTransactionManager(dataSource());
}하지만 요즘 스프링부트에서는 application.properties 에 있는 속성을 이용해서 DataSource 생성
spring.datasource.url=jdbc:h2:tcp://localhost/~/test
spring.datasource.username=sa
spring.datasource.password