✅ 완전탐색 알고리즘
- 정답이 될 가능성이 있는 모든 경우의 수를 확인하여 정답을 찾는 알고리즘
💡 시간복잡도를 잘 보면서 반복문을 구현해야함
✅ 배열과 리스트 (Array, ArrayList)
공통점은 둘다 데이터를 순차적으로 저장하는 구조
배열 : 순차적, 선언 할때 배열크기를 정하며 크기가 변하지 않음
리스트 : 순차적, 크기가 동적으로 변함
리스트의 주요 메소드 get set add remove
💡 헷갈린만한 포인트 : remove
remove(숫자) → 인덱스 삭제
remove(Integer.valueOf()) → 값 삭제
예를들어 remove(2) => 2번째 인덱스에 있는 부분 삭제
remove(Integer.valueOf(10)) => 리스트안에서 10이 있는 부분 삭제✅ Linked List
노드가 포인터(참조)를 통해 연결되어, 논리적인 순서를 형성하는 자료구조- 데이터를 자주 추가/삭제 할때 용이함
class Node {
int value;
Node next;
Node prev; // 이전 노드의 참조도 추가하면 이중 연결리스트
public Node(int value){
this.value = value;
}
}각각의 노드 객체는 실제 저장할 데이터와, 다음 노드 와 이전 노드 객체를
가리키는 참조(주소값)을 가지고 있다.
즉 양방향 탐색이 가능하며
자바에서는 java.util.LinkedList 클래스가 이 방식을 사용한다.
연결리스트의 주요 메소드 add addFirst addLast getFirst removeLast contains ...
- 동작원리
// 객체생성시 first와 last 변수가 생성, 각 노드를 가리킴 (처음에는 각각 null 가리킴)
LinkedList<String> list = new LinkedList<>();
list.add("B"); // B노드 추가시 first 와 last 변수는 각각 B를 가리킴
list.add("C"); // C노드 추가시 B와 C를 서로 연결시켜주고 last 변수는 C를 가리킴
list.get(1); // 조회시 cur 변수가 만들어져서 first부터 쭉 찾아서 조회 (시간복잡도 O(n))
// getFirst(), getLast() 는 O(1) 으로 처리 가능
// 첫번째 항목 삭제시 first 변수가 가리키던 B앞에 있는 C을 가리키게 바꿈
// C가 가리키고 있는 B를 NULL로 바꿔줌 -> B 노드는 이제 아무도 참조 X -> 가비지컬렉션이 메모리 자동으로 삭제
// 정리 : 삭제할때는 각 노드의 연결관계만 바꿔주면 되서 O(1)이지만, 삭제할 항목을 찾는 시간은 O(n)임
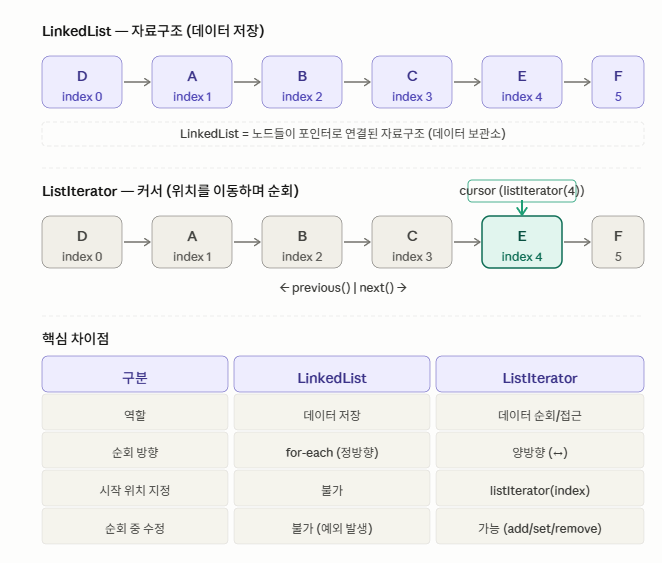
list.removeFirst(); ListIterator : 리스트 위에서 움직이는 커서(포인터)
리스트는 그대로 두고, 위치만 이동하면서 읽거나 수정할 때 사용
주로 특정 위치부터 순회할 때 많이 사용한다.
ListIterator 주요메소드 hastNext hasPrevious next previous
// 1. 특정 위치부터 정방향 순회
// D,A,B,C,E,F
ListIterator<String> cursor = list.listIterator(2); // index 2부터
while (cursor.hasNext()) {
System.out.println(cursor.next()); // B, C, E, F 출력
}
✅ Queue
- 가장 먼저 입력된 데이터가 먼저 출력되는
선입선출 FIFO구조
Queue 로 ArrayList, LinkedList, ArrayDeque 모두 구현 가능하지만
자바에서는 주로 ArrayDeque 를 사용 (배열 + 양방향 큐 = 원형큐)
ArrayDeque 는 head 와 tail 을 이용한 원형구조
그 이유는 3 개 모두 데이터를 추가할 때는 시간복잡도가 O(1) 이 걸리지만
데이터를 추출할 때는 ArrayList 는 O(n) 이 걸림 -> 삭제하면 다른 노드들도 다 옮겨야하기 때문에
하지만 ArrayDeque 는 head 만 1칸 옮기면 되기때문에 O(1) 이라서 더 효율적임
물론 LinkedList 도 first 만 옮기면 되기때문에 O(1) 이지만, 노드를 생성하는 과정자체가 비효율적이다
Queue<Integer> queue = new ArrayDeque<>(); // head 와 tail 맨앞을 가리키는 배열이 만들어짐
queue.offer(10);
int nextItem = queue.peek();
while(!queue.isEmpty()){
int item = queue.poll();
} 주요 메소드
offer -> 추가 메소드 = Enqueue
poll -> 추출 메소드 (꺼내면서 삭제까지함) = Dequeue
peek -> 다음 값이 무엇인지 확인만 할 때 사용 (꺼내기 x)
💡 큐가 가득차기 전까지는 head 와 tail 이 공간을 계속 재활용함 (원형구조)
✅ Stack
- 가장 나중에 넣은 데이터가 가장 먼저 출력되는
후입선출 LIFO구조
Deque<Integer> stack = new ArrayDeque<>();
stack.push(10);
stack.push(20);
int top = stack.peek();
while(!stack.isEmpty()){
int item = stack.pop(); // 20 부터 꺼내짐
}주요 메소드
push : 맨위에 넣기
pop : 맨위에서 꺼내기
peek : 맨 위 값이 무엇인지 확인만 할 때 사용 (꺼내기 x)
✅ 해시테이블
- Key 와 Value 를 한 쌍으로 저장하는 자료구조
최대한 고르게 분포하도록 만드는게 잘 만들어진 해시테이블이다
💡 만약 이미 저장되어 있는 곳에 충돌이 되면 어떻게?
첫번째 방법으로는 충돌되었을 때 그 다음 비어있는곳 에 넣음 (반복)
= 개방 주소법 (open addressing) : 특정버킷에서 충돌발생시, 비어있는 버킷을 찾아 항목에 저장
두번째 방법으로는 Separate Chaining(분리 체인법) = 저장되어 있는 곳 옆에 링크로 연결
만약 충돌이 많이 일어나서 링크로 많이 연결되어 있는 경우
너무 많은 데이터가 있다고 판단하여 더 큰 배열을 선언해서 다시 HashFunction 으로 재배치를 함
또는 충돌이 많이 일어나서 링크로 많이 연결되면 트리 형태로도 배치해줌
자바에서는 HashMap 을 사용하여 해시테이블을 사용
put get 모두 O(1) 시간으로 바로 인덱스 위치에 값을 저장하거나 조회할 수 있다
containsKey(key) : 키 존재 여부 확인 메소드 (boolean 형 반환)
containsValue(value) : 값 존재 여부 확인 메소드 (boolean 형 반환)
배열,리스트,연결리스트 모두 어떠한 값을 찾을 때 모두 다 뒤져봐야하지만 -> O(n)
HashMap 은 HashFunction 을 사용하여 어디에 저장되어있는지 바로 알려줘서 빠르게 찾음 -> O(1)
즉 키를 해시함수에 넣으면 번호로 나오고, 그 번호를 배열 인덱스처럼 사용하여 빠르게 접근할 수 있다
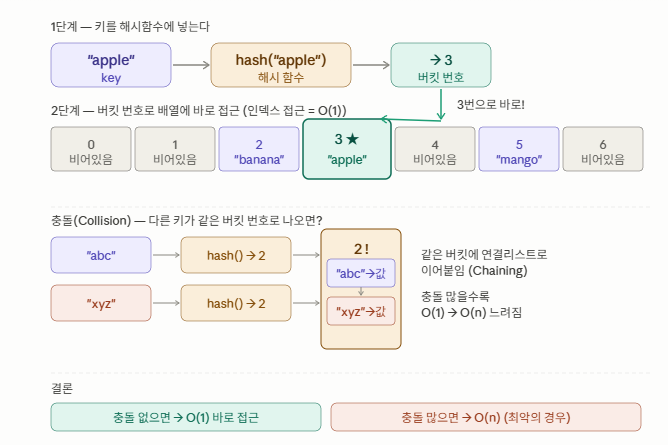
위 사진처럼 만약 버킷번호 3번에 데이터가 충돌하면 분리 체인법 으로 연결리스트로 이어붙이고
너무 많아지면 배열크기를 2배로 늘려서 충돌확률을 낮추거나, 같은 버킷에 8개 이상 쌓이면
트리형식으로 바꿔서 O(n) -> O(log n) 으로 처리한다.
✅ HashSet
- 중복된 요소를
허용하지 않는집합을 구현한 자료구조 - 내부적으로는 HashMap을 활용하여 해시 원리로 데이터를 관리함
HashMap 과 다르게 키 값만 존재
HashMap 과 다르게 containsKey containsValue 메소드가 없고 contains 메소드만 존재한다.
HashMap 과 동일한 원리로 찾기 때문에, O(1) 시간복잡도가 걸림
주요메소드
contains add remove size ...
