무신사 기술 블로그를 개인적으로 공부 겸 정리했습니다.
-
무신사의 경우 상품 검색 시 추천순이라는 정렬 방식을 사용 중
-
기존 모델이 정말 고객이 원하는 상품을 잘 추천해주고 있는지에 대한 의문
ex. "후드 집업"으로 검색을 했을 때, 랭킹 스코어가 낮은 후드 집업보다 스코어가 높은 후드티가 상위 랭크에 위치하는 경우가 발생
새로운 "무신사 추천순" 모델 제안
-
고객 피드백 결과, 특정 브랜드를 검색하는 고객에게는 해당 브랜드를, 특정 카테고리(ex. 슬리퍼)를 찾는 고객에게는 해당 카테고리를 보여준다.
-
적합도(Relevance) - 검색어와 상품 색인 필드의 단어간 확률적 연관 관계 - 개념 도입
(필드별 중요도 * 필드별 유사도)

-
필드별 중요도
- 특정 색인 필드를 얼마나 중시하는가 (ex. "태그" < "카테고리"에서 검색어 매칭시 해당 상품 부스팅)
-
필드별 유사도
- 검색어와 특정 색인 필드 단어 간 벡터 유사도 사용
- 유사도 계산 모델로는 TF-IDF, BM25
-
모델 개선안 (기존에 인기도 요소만 존재했던 모델에 적합도 요소 추가)
인기도(Popularity) : 상품의 구매, 후기, 클레임 등으로 판단한 점수
적합도(Relevance) : 검색어와 상품 정보 간 확률적 연관 관계
- A/B 테스트를 통해 효과 검증, metric은 mAP(mean Average Precision) 사용
모델 프로토타입 개발
- 핵심 : 각 요소의 가중치를 어떻게 설정할 것인가
- 적합도 적용 대상 필드 : 브랜드, 카테고리 (고객 피드백이 많았던 부분)
- 브랜드 적합도가 가장 높은 상품 그룹이 이외의 상품 그룹보다 상위에 노출되야 함
- 브랜드가 동일한 상품의 경우, 카테고리 적합도가 높은 순으로 노출되야 함
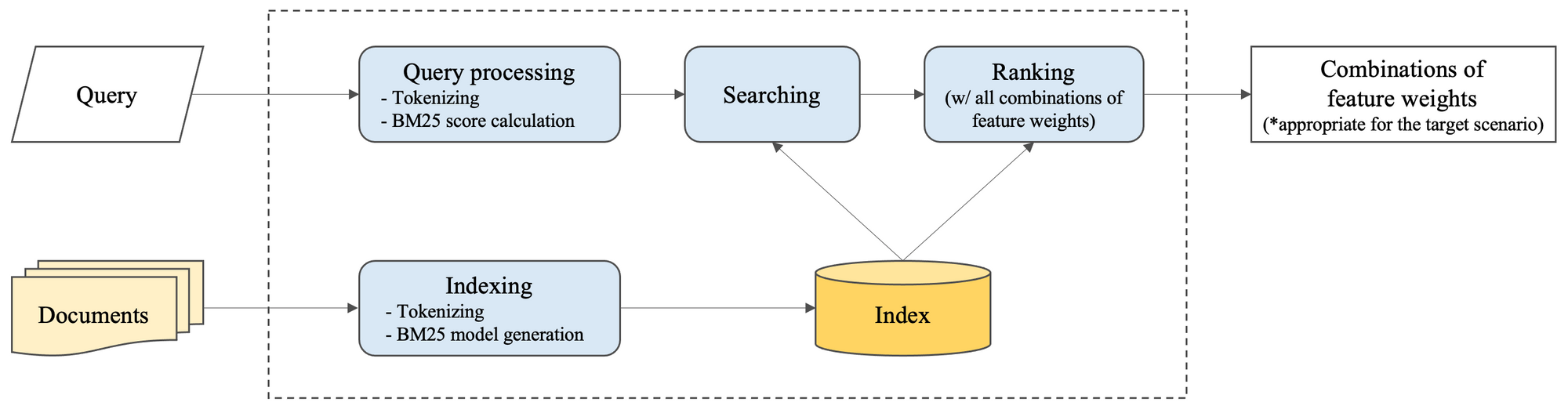
모델 프로토타이
- Tokenizer (형태소 분석) : Nori(Lucene의 한글 형태소 분석기)의 파이썬 버전 Pynori 사용
(Pynori의 경우 동의어 및 사용자 사전을 커스텀하게 적용 가능 → 기존 사전 적용) - BM25 : 검색어-색인 필드 단어간 유사도 알고리즘 모델 (elasticsearch 제공)
- 최근 1년 기준 무신사 인기 검색어 Top 1,000개와 모델링 요소별 가중치 조합 10,000개를 적용해 목표 시나리오를 만족시키는 가중치 조합 도출 → 초기 가중치 값 세팅
무신사 추천순 시스템 아키텍처 개선
- 기존 추천 시스템 : 하루 전날 기준의 상품 데이터를 이용하는 랭킹 모델의 점수 사용
일별로 생성되는 랭킹 점수를 Elasticsearch에 저장, 기본적인 필드 정렬을 사용
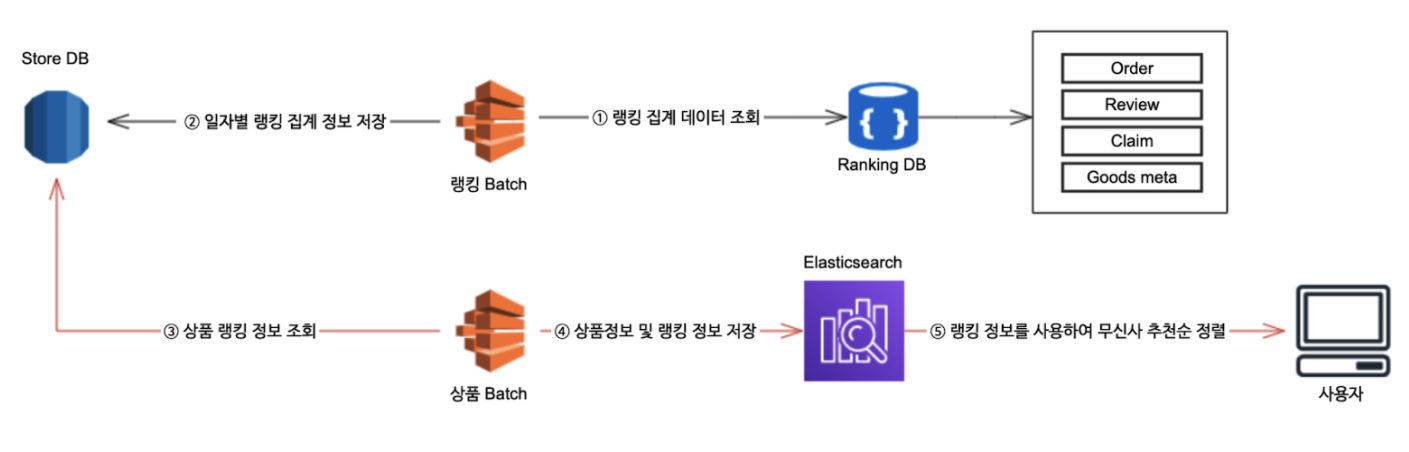
기존 추천 시스템 아키텍처
- 랭킹 점수 뿐만 아니라, 브랜드나 카테고리 필드에서 적합도 점수 산출을 위한 데이터도 함께 상품 인덱스에 저장

개선된 추천 시스템 아키텍처
시스템 구현을 위한 세부 절차들
-
프로토 타입에서 구현한 목표를 실제 서비스에 적용
→ Elasticsearch의 Function score query를 사용해 스코어링 모델 구현 -
적합도 점수와 인기도 점수 조합시 사용한 데이터
- 상품 랭킹에서 사용하는 상품별 랭킹 점수
- 한글/영문 브랜드 키워드
- 대/중/소 카테고리 키워드
- 부가 정보의 점수
-
Function score query에서 사용할 수식
-
Function score query 작동 조건
-
Field 점수 사용 여부
-
해당 함수 쿼리에 검색어의 Term이 있으면 1, 없으면 0
-
1번과 2번의 점수에 가중 할 점수 : 가중치로 우선 순위 지정
-
3번의 값들을 합산할 것인지 곱셈할 것인지 등에 관한 결정
⇒ 가중치를 통해 의도한대로 상품 정렬
-
데이터 전처리
- 상품 랭킹 데이터
- 랭킹 점수는 다른 모델링 요소보다 스케일이 크기 때문에 데이터 스케일링 진행
- 음수인 랭킹 점수를 모두 0으로 치환
→ 반품 실적만 있는 상품을 인기도가 없는 (인기도 점수가 0) 상품으로 간주
- 적합도 적용 대상 필드 데이터 전처리
- 적합도가 높은 상품들을 디테일하게 분류하기 위함
- 브랜드 : 한글명과 영문명 데이터를 각각 사용할 수 있도록 두 데이터를 구분해서 검색엔진에 저장
- 카테고리 : 대/중/소 카테고리를 사용하기 떄문에 서로 다른 Depth의 카테고리 필드에서 적합도 점수가 불필요하게 중복으로 부여될 수 있어 이를 방지하기 위해 데이터 전처리 수행
- 상위 카테고리명이 하위 카테고리 명에 부분 일치하는 경우, 일치된 부분 제거
ex. "팬츠 > 데님 팬츠" → "팬츠 > 데님"으로 전처리해 "팬츠"로 검색 시 대카테고리 필드에서만 스코어링 되도록 함) - 상위 카테고리명이 하위 카테고리명에 완전 일치하는 경우 전처리 하지 않음
ex. "선글라스/안경테 > 선글라스" 는 전처리 하지 않음
- 상위 카테고리명이 하위 카테고리 명에 부분 일치하는 경우, 일치된 부분 제거
- 브랜드와 카테고리 필드에 불용어 사전을 구축 및 적용 → 적합도 점수 부여받지 않을 단어 처리. 상품 검색이 아닌 정렬에만 영향을 끼칠 수 있도록 스코어 계산 분석기에 적용
- 브랜드 필드 전용 불용어 사전
카테고리, 동음이의어 브랜드 단어들로 구성 (ex. 아이웨어, 디자인 등) - 카테고리 필드 전용 불용어 사전
유의미하지 않은 카테고리 용어('기타')로 구성 - 브랜드/카테고리 필드 공통 불용어 사전
성별, 컬러 용어들로 구성
- 브랜드 필드 전용 불용어 사전
검색엔진 쿼리 작성
-
무신사 검색 엔진은 여러 가지 색인 필드 항목(브랜드, 카테고리, 상품명, 태그 등)을 Multi match query를 통해 하나의 필드처럼 만들어서 검색
- "type" : "cross_fields", "operation" : "AND" (elasticsearch parameters)
- 검색어가 대상 필드 중 존재하면 해당 상품이 검색 결과로 제공
-
Function score query
-
검색된 상품은 기존과 동일하나 정렬 순서만 변경하고자 함
-
query : 기존 검색 조건을 포함한 Multi match query 사용
-
functions : 스코어링하고 싶은 요소를 추가해 상품 정렬을 변경 (개선된 부분)
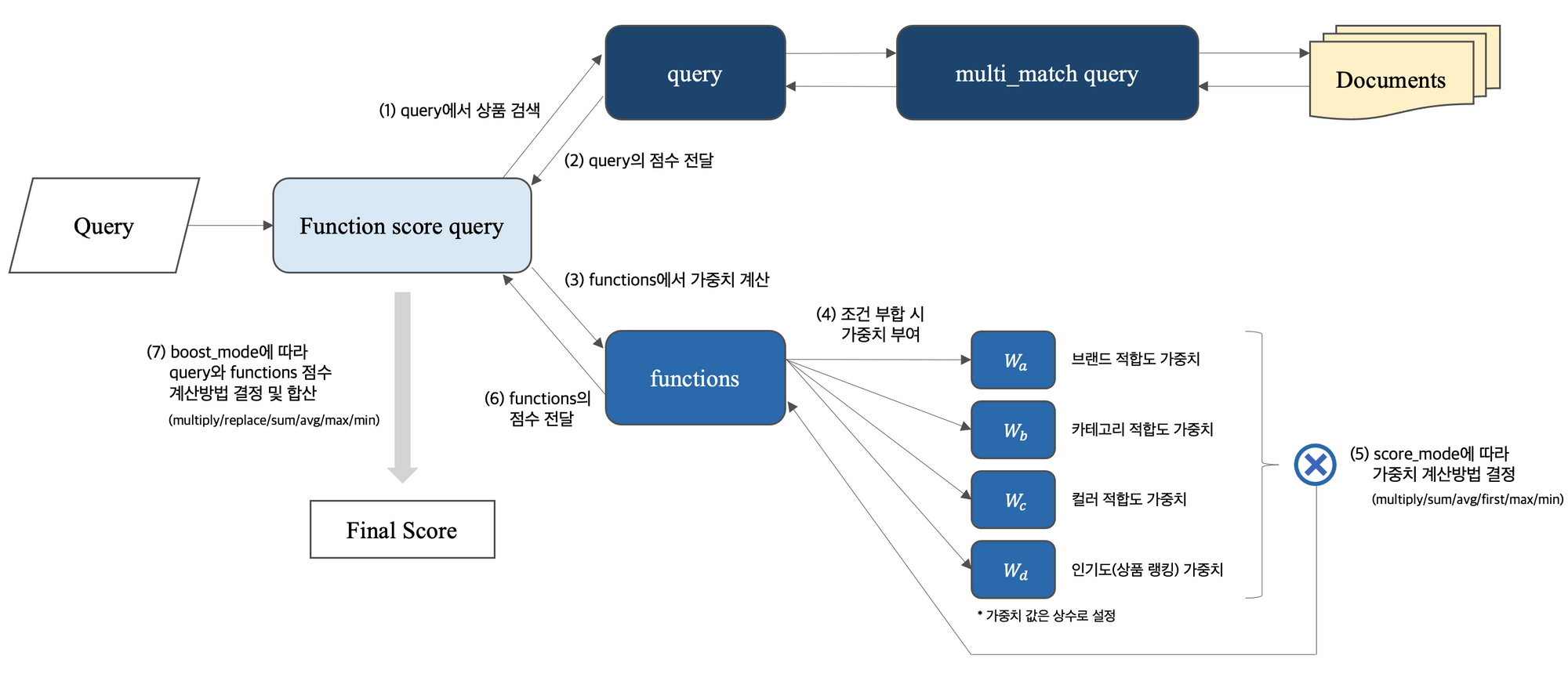
Function score query의 스코어링 Flow
- 검색어 query (사용자)
- 검색엔진이 Function score query의 query 부분에서 검색어가 매칭되는 문서(상품) 조회
BM25 알고리즘을 통해 선별된 상품들을 검색 결과로 제공 - functions 부분에서 미리 정의된 필드별 가중치 값과 "score_mode"에 설정된 계산 방법에 따라 각 필드의 적합도 점수를 하나의 적합도 점수로 합산
- query 부분과 functions 부분에서 각각 계산된 점수를 "boost_mode" 계산 방법에 따라 합쳐서 최종 점수 산출
-
Reference
