씹어먹는 C++
16장 C++ 쓰레드 766p-825p
컴퓨터 구조
메모리 memory
CPU <-> RAM(메모리)
물리적 거리로 인해 데이터를 읽어 오는데 시간이 걸림
캐시 Cache
cpu 칩 안에 있는 작은 메모리
RAM과는 다르게 연산을 하는 부분과 붙어있어 읽기와 쓰기 속도가 빠름
CPU가 특정한 주소에 있는 데이터에 접근 시, 일단 캐시에 있는지 확인, 있다면 해당 값을 읽고, 없다면 메모리 까지 갔다 오는 방식으로 진행
-
Cache hit
캐시에 있는 데이터를 다시 요청해서 시간을 절약 -
Cache miss
캐시에 요청한 데이터가 없어서 메모리 까지 갔다 오는 것 -
CPU에서 캐시 작동 방식
메모리를 읽으면 일단 캐시에 저장
만일 캐시가 다 찼다면 특정한 방식에 따라 처리- LRU(Least Recently Used)
캐시를 날려버리고 그 자리에 새로운 캐시를 기록하는 방식
최근에 접근한 데이터를 자주 반복해서 접근한다면 매우 유리
- LRU(Least Recently Used)
CPU 파이프라이닝(pipelining)
- 파이프라이닝(pipelining)
작업이 끝나기 전에, 다음 작업을 시작하는 방식으로 동시에 여러 개의 작업을 동시에 실행하는 것
CPU 에서 명령어를 실행할 때 여러 단계를 거침
명령어를 읽어야 하고 (fetch),
읽은 명령어가 무엇 인지 해석해야 하고 (decode),
해석된 명령어를 실행하고(execute),
마지막으로 결과를 써야함 (write).
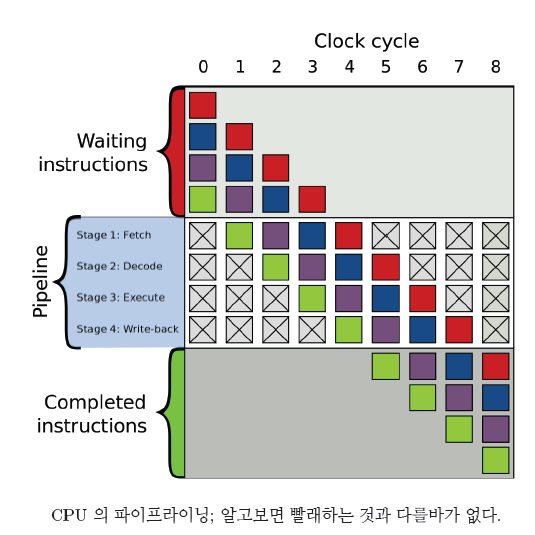
컴파일러는 최대한 CPU 의 파이프라인을 효율적으로 활용할 수 있도록 명령어 재배치
수정 순서(modification order)
C++ 의 모든 객체들이 정의 가능
원자적 연산을 할 경우에 모든 쓰레드에서 같은 객체에 대해서 동일한 수정 순서 관찰 가능
순서 동일 -> 수정 순서가 바뀌지 않는 것을 보장
따라서
명령어 재배치를 한다해도
모든 쓰레드에서 변수의 수정 순서에 동의만 한다면
문제될 것이 없음
원자성(atomicity)
원자처럼 쪼갤 수 없다
모든 연산들이 원자적일때
C++ 에서 모든 쓰레드들이 수정 순서에 동의해야만 함
원자적 연산
CPU 가 명령어 1 개로 처리하는 명령
중간에 다른 쓰레드가 끼어들 여지가 전혀 없는 연산
원자적 연산들은 올바른 연산을 위해 굳이 뮤텍스가 필요하지 않음
-> 연산 속도가 더 빠르다
c++에서 몇몇 타입들에 원자적인 연산을 쉽게 할 수 있도록 여러가지 도구들을 지원
atomic
std::atomic<int> counter(0);
atomic 의 템플릿 인자로 원자적으로 만들고 싶은 타입을 전달
atomic 객체에서 제공하는 함수들을 통해서, 여러가지 원자
적인 연산들을 손쉽게 수행
example code
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
void worker(std::atomic<int>& counter) {
for (int i = 0; i < 10000; i++) {
counter++;
}
}
int main() {
std::atomic<int> counter(0);
std::vector<std::thread> workers;
for (int i = 0; i < 4; i++) {
workers.push_back(std::thread(worker, ref(counter)));
}
for (int i = 0; i < 4; i++) {
workers[i].join();
}
std::cout << "Counter 최종 값 : " << counter << std::endl;
Counter 최종 값 : 40000
CPU는 원래 한 명령어에서 메모리에 읽기 혹은 쓰기 둘 중 하나 밖에 못함
그러나
Assembly Language
lock add DWORD PTR [rdi], 1
lock add 명령어를 통해
rdi 에 위치한 메모리를 읽고 - 1 더하고 - 다시 rdi 에 위치한 메모리에 쓰기를 모두 함.
-
해당 명령어를 컴파일러가 사용 가능 이유
어느 CPU 에서 실행할 지(x8) 컴파일러가 알고 있기 때문에 이런 CPU 특이적인 명령어를 제공 가능함.
CPU에 따라 해당 명령이 없는 경우도 있음 -
is_lock_free() 함수
lock free 에서의 lock 이 없다 의미
뮤텍스와 같은 객체들의 lock, unlock 없이도 해당 연산을
올바르게 수행할 수 있다는 뜻std::atomic<int> x; std::cout << "is lock free ? : " << boolalpha << x.is_lock_free() << std::endl;Is lock free ? : true
memory_order
막기 위해서 메모리 재배치 순서를 강제를 위해 C++에서 제공
atomic 객체들의 경우 원자적 연산 시에 메모리에 접근할 때 어떠한 방식으로 접근하는지 지정 가능
memory_order_relexed
메모리에서 읽거나 쓸 경우, 주위의 다른 메모리 접근들과 순서가 바뀌어도 무방
메모리 연산들사이에서 어떠한 제약조건도 없음
서로 다른 변수의 relaxed 메모리
단일 쓰레드 관점에서 결과가 동일하다면 연산은 CPU 마음대로 재배치 가능
-> CPU에서 매우 빠른 속도로 실행 가능
relaxed 메모리 연산을 사용하면 예상치 못한 결과가 나올 수 있으니 주의 필요.
#include <atomic>
#include <cstdio>
#include <thread>
#include <vector>
using std::memory_order_relaxed;
void t1(std::atomic<int>* a, std::atomic<int>* b) {
b->store(1, memory_order_relaxed); // b = 1 (쓰기)
int x = a->load(memory_order_relaxed); // x = a (읽기)
printf("x : %d \n", x);
}
void t2(std::atomic<int>* a, std::atomic<int>* b) {
a->store(1, memory_order_relaxed); // a = 1 (쓰기)
int y = b->load(memory_order_relaxed); // y = b (읽기)
printf("y : %d \n", y);
}
int main() {
std::vector<std::thread> threads;
std::atomic<int> a(0);
std::atomic<int> b(0);
threads.push_back(std::thread(t1, &a, &b));
threads.push_back(std::thread(t2, &a, &b));
for (int i = 0; i < 2; i++) {
threads[i].join();
}
}x : 1
y : 0
or
x : 0
y : 1
or
x : 1
y : 1
- store & load
atomic 객체들에 대해서 원자적으로 쓰기와 읽기를 지원해주는 함수
memory_order_acquire 과 memory_order_release
두 개의 다른 쓰레드들이 같은 변수의 release 와 acquire 를 통해서 동기화 (synchronize)를 수행
memory_order_release
해당 명령 이전의 모든 메모리 명령들이 해당 명령 이후로 재배치 되는 것을 금지
memory_order_acquire
release 와는 반대로
해당 명령 뒤에 오는 모든 메모리 명령들이 해당 명령 위로 재배치 되는 것을 금지
example code
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
using std::memory_order_relaxed;
std::atomic<bool> is_ready;
std::atomic<int> data[3];
void producer() {
//store시에는 relaxed라서 재배치 가능하나
data[0].store(1, memory_order_relaxed);
data[1].store(2, memory_order_relaxed);
data[2].store(3, memory_order_relaxed);
// 아래 release 명령어를 넘어서 재배치는 안된다.
is_ready.store(true, std::memory_order_release);
}
void consumer() {
// data 가 준비될 때 까지 기다린다.
while (!is_ready.load(std::memory_order_acquire)) {
}
std::cout << "data[0] : " << data[0].load(memory_order_relaxed) << std::endl;
std::cout << "data[1] : " << data[1].load(memory_order_relaxed) << std::endl;
std::cout << "data[2] : " << data[2].load(memory_order_relaxed) << std::endl;
}
int main() {
std::vector<std::thread> threads;
threads.push_back(std::thread(producer));
threads.push_back(std::thread(consumer));
for (int i = 0; i < 2; i++) {
threads[i].join();
}
}data[0] : 1
data[1] : 2
data[2] : 3
memory_order_acq_rel
acquire 와 release 를 모두 수행
읽기와 쓰기를 모두 수행하는 명령들,
예를 들어서 fetch_add 와 같은 함수에서 사용
memory_order_seq_cst
메모리 명령의 순차적 일관성(sequential consistency) 을 보장
순차적 일관성을 보장하기 위해서는 CPU 의 동기화 비용이 매우 큼
따라서 해당 명령은 정말 꼭 필요 할 때만 사용
- 순차적 일관성
메모리 명령 재배치도 없고, 모든 쓰레드에서 모든 시점에 동일한 값을 관찰 가능 함
atomic 의 메모리 memory_order 지정 연산 정리
| 연산 | 허용된 memory order |
|---|---|
| 쓰기 (store) | memoryorder_relaxed, memory-orderrelease, memory_order_seq-cst |
| 읽기 (load) | memoryorder_relaxed, memory-orderconsume, memory_order-acquire, memory_order_seq_cst |
| 읽고 - 수정하고 - 쓰기 (read - modify - write) | memoryorder_relaxed, memory-orderconsume, memory_order-acquire, memoryorder_release, memory_order_acq_rel, memory-order_seq_cst |
동기 (synchronous) 와 비동기(asynchronous) 실행
C++ 에서 제공하는 promise, future, packaged_task, async 를 잘 활용하면
귀찮게 mutex 나 condition_variable 을 사용하지 않고도
매우 편리하게 비동기적 작업을 수행
동기적 (synchronous)실행
한 번에 하나씩 순차적으로 실행 되는 작업되도록 실행
동기적인 작업들은 한 작업이 끝날 때 까지 다음 작업으로 이동하지 않기 때문
비동기적(asynchronous) 실행
프로그램의 실행이, 한 갈래가 아니라 여러 갈래로 갈라져서 동시에 진행
어떠한 데이터를 다른 쓰레드를 통해 처리해서 받아내도록 실행
C++ 의 경우 위와 같이 명시적으로 쓰레드를 생성해서 적절히 수행하여 사용할 수 있도록 함
std::promise 와 std::future
어떤 쓰레드 T 를 사용해서,
비동기적으로 값을 받아내겠다
미래에 (future)쓰레드 T 가 원하는 데이터를 돌려 주겠다 라는 약속 (promise)
생산자-소비자 패턴에서
promise 는 생산자 (producer) 의 역할을 수행하고,
future 는 소비자 (consumer) 의 역할을 수행
해당 패턴은 조건 변수로도 구현이 가능하나 더 복잡하다.
또한 조건 변수와는 다르게 예외 전달도 가능.
-
promise 객체
연산을 수행 후에 돌려줄 객체의 타입을 템플릿 인자로 받음
연산이 끝난 다음에 promise 객체는 자신이 가지고 있는 future 객체에 값을 넣어줌. -
future 객체
promise 가 future 에 값을 전달하기 전까지 wait으로 대기
get 함수를 바로 호출하더라도 알아서 promise 가 future 에 객체를 전달할 때 까지 기다린 다음에 리턴
future 에서 get 을 호출하면, 설정된 객체가 이동
따라서 절대로 get 을 두 번 호출하면 안됩니다.
example code
#include <future>
#include <iostream>
#include <string>
#include <thread>
using std::string;
void worker(std::promise<string>* p) {
// 약속을 이행하는 모습. 해당 결과는 future 에 들어간다.
p->set_value("some data");
}
int main() {
std::promise<string> p;
// 미래에 string 데이터를 돌려 주겠다는 약속.
std::future<string> data = p.get_future();
std::thread t(worker, &p);
// 미래에 약속된 데이터를 받을 때 까지 기다린다.
data.wait();
// wait 이 리턴했다는 뜻이 future 에 데이터가 준비되었다는 의미.
// 참고로 wait 없이 그냥 get 해도 wait 한 것과 같다.
std::cout << "받은 데이터 : " << data.get() << std::endl;
t.join();
}받은 데이터 : some data
wait_for
정해진 시간 동안만 기다리고 그냥 진행 가능
promise 가 설정될 때 까지 기다리는 대신에 wait_for 에 전달된 시간 만큼 기다렸다가 바로 리턴
리턴하는 값은 현재 future 의 상태를 나타내는 future_status 객체 3가지
- future_status
1. future_status::ready
2. future_status::timeout
wait_for 에 지정한 시간이 지났지만 값이 설정되지 않아서 리턴
3. future_status::deferred
결과값을 계산하는 함수가 채 실행되지 않았다는 의미
shared_future
여러 개의 다른 쓰레드에서 future를 get 할 필요성이 있을때 사용
condition_variable를 사용하서 구현 가능하나 future가 편리
shared_future 의 경우
future 와는 다르게 복사가 가능
복사본들이 모두 같은 객체를 공유
따라서 레퍼런스나 포인터로 전달할 필요가 없음
example code
#include <chrono>
#include <future>
#include <iostream>
#include <thread>
using std::thread;
void runner(std::shared_future<void> start) {
start.get();
std::cout << "출발!" << std::endl;
}
int main() {
std::promise<void> p;
std::shared_future<void> start = p.get_future();
thread t1(runner, start);
thread t2(runner, start);
thread t3(runner, start);
thread t4(runner, start);
// 참고로 cerr 는 std::cout 과는 다르게 버퍼를 사용하지 않기 때문에 터미널에
// 바로 출력된다.
std::cerr << "준비...";
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cerr << "땅!" << std::endl;
p.set_value();
t1.join();
t2.join();
t3.join();
t4.join();
}준비...땅!
출발!
출발!
출발!
출발!
packaged_task
C++에서 지원
비동기적 함수(정확히는 Callable - 즉 람다 함수, Functor 포함) 의 리턴값에 간단히 적용
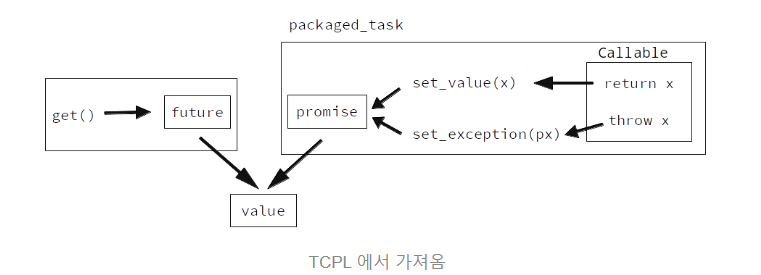
packaged_task 에 전달된 함수가 리턴할 때,
그 리턴값을 promise 에 set_value 하고,
만약에 예외를 던졌다면 promise 에 set_exception
해당 future 는 packaged_task 가 리턴하는 future 에서 접근 가능
packaged_task
비동기적으로 수행할 함수 자체를 생성자의 인자로 받음
템플릿 인자로 해당 함수의 타입을 명시 필요
packaged_task 는 전달된 함수를 실행해서,
그 함수의 리턴값을 promise 에 설정
쓰레드에 굳이 promise 를 전달하지 않아도 알아서
packaged_task 가 함수의 리턴값을 처리해줘서 매우 편리
example code
#include <future>
#include <iostream>
#include <thread>
int some_task(int x) { return 10 + x; }
int main() {
// int(int) : int 를 리턴하고 인자로 int 를 받는 함수. (std::function 참조)
std::packaged_task<int(int)> task(some_task);
//해당 promise 에 대응되는 future 는 위와 같이 get_future 함수로 받음
std::future<int> start = task.get_future();
std::thread t(std::move(task), 5);
std::cout << "결과값 : " << start.get() << std::endl;
t.join();
}결과값 : 15
std::async
비동기적으로 실행을 하기 위해서는,
쓰레드를 명시적으로 생성해서 실행하는 promise 나 packaged_task과 다르게
std::async는
어떤 함수를 전달한다면, 아예 쓰레드를 알아서 만들어서
해당 함수를 비동기적으로 실행하고, 그 결과값을 future 에 전달
-
첫번째 인자
std::launch::async :
바로 쓰레드를 생성해서 인자로 전달된 함수를 실행std::launch::deferred :
future 의 get 함수가 호출되었을 때 실행 (새로운 쓰레드를 생성하지 않음)
해당 함수를 굳이 바로 당장 비동기적으로 실행할 필요가 없다면 deferred 옵션 선택
실행하는 함수의 결과값을 포함하는 future 를 리턴
example code
#include <future>
#include <iostream>
#include <thread>
#include <vector>
// std::accumulate 와 동일
int sum(const std::vector<int>& v, int start, int end) {
int total = 0;
for (int i = start; i < end; ++i) {
total += v[i];
}
return total;
}
int parallel_sum(const std::vector<int>& v) {
// lower_half_future 는 1 ~ 500 까지 비동기적으로 더함
// 참고로 람다 함수를 사용하면 좀 더 깔끔하게 표현할 수 도 있다.
// --> std::async([&v]() { return sum(v, 0, v.size() / 2); });
std::future<int> lower_half_future =
std::async(std::launch::async, sum, cref(v), 0, v.size() / 2);
// upper_half 는 501 부터 1000 까지 더함
int upper_half = sum(v, v.size() / 2, v.size());
return lower_half_future.get() + upper_half;
}
int main() {
std::vector<int> v;
v.reserve(1000);
for (int i = 0; i < 1000; ++i) {
v.push_back(i + 1);
}
std::cout << "1 부터 1000 까지의 합 : " << parallel_sum(v) << std::endl;
}1 부터 1000 까지의 합 : 500500
