List
리스트는 대괄호 안에 원하는 값들을 나열하는 식으로 생성할 수 있으며, 각각의 값들은 쉼표를
사용해서 구분한다. List에 저장되어 있는 값은 element라고 한다.
List는 여러 string 이외에도 숫자, boolean값 등 모든 type의 값을 저장 할 수 있으며
서로 다른 type의 값들을 저장하는것도 가능하다.
my_values = [1, "two", True]
List는 값들에 순서(ordering)가 존재하며 index라고 한다.
index는 0번부터 시작한다.
List에 저장되어 있는 값들 중 원하는 값을 index를 통해 읽을 수 있다.
index의 마지막은 list 길이의 -1값을 갖는다.
List 또한 List의 요소가 될 수 있으며 아래와 같은 모양을 하고 있다.
[["Bulls", 23], ["white fox", 45]]
python에서는 이와같은 List를 Multi-dimensional lists(다차원 리스트)라고 부른다.
List에 새로운 값을 추가하고 싶으면 append()메소드를 사용하면 된다.
append()메소드는 리스트의 가장 끝에 새로운 값을 추가한다.
List 안에있는 데이터를 제거하고 싶을 때는 pop()메소드를 이용한다.
List의 가장 마지막 데이터를 제거한다.
List Slicing
파이썬에서는 리스트의 일부분을 따로 copy 할수 있으며 ,이것을 slicing이라고 한다. 피자 한판에서 한 조각을 slice라고 하듯이 리스트의 부분들을 복사하는 기능이다.
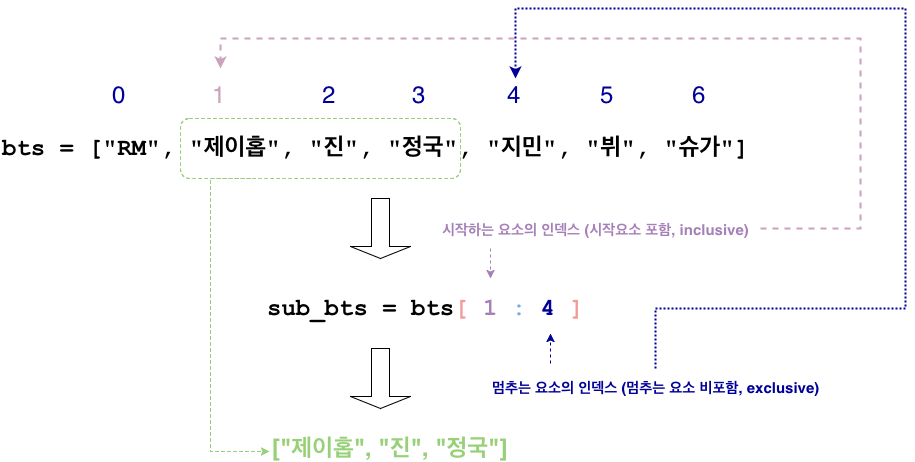
리스트의 일부분만 카피해서 부분적인 리스트를 만드는 문법은 다음과 같다.
list_name[start : stop]
- 먼저 list이름이 위치하고
- 그 다음 중괄호([)가 열리고
- 부분적인 리스트가 시작할 첫번째 요소(포함)의 index 번호가 나오고
- :으로 나눠주고
- 부분적인 리스트가 멈추는 요소(비포함)의 index번호가 나오고
- 중괄호(])를 닫아준다.
Slicing Steps
앞서 방금 list slicing 에는 start와 stop그리고 step이 있다.
step을 포함한 slicing 문법은 다음과 같다.
list_name[start : stop : step]Step은 그 값만큼 건너뛰어 가져오는 기능이다. Step의 뜻인 "걸음"처럼 한번에 몇 요소씩
건너뛸것인가를 정한다. step은 optional이기 때문에 선언해주지 않아도 된다.
만일 선언이 안되면 default로 1로 지정된다. 즉list[1:4] == list[1:4:1]
위와 같이 되는것이다.
Copying. Not Modifying
Slicing은 오리지널 list를 수정하는게 아니라, 새로운 list를 만들어 낸다는 것이다.
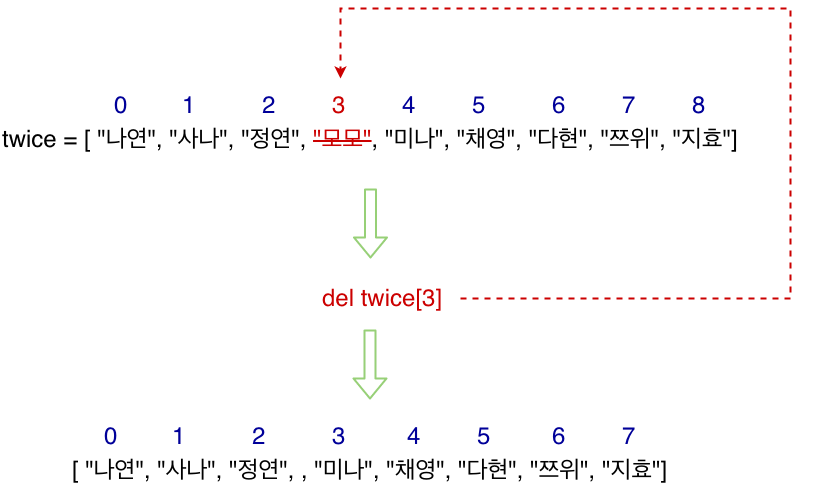
Deleting Elements From List
del 키워드와 list의 인덱스를 사용하여 원하는 요소를 리스트에서 삭제하는 것이다.
참고로 요소가 리스트에서 삭제되면 파이썬이 자동으로 리스트의 인덱스들을 다시 정렬해준다.
그럼으로 인덱스 번호가 중간에 비어있지 않도록 하게 해준다.
Remove
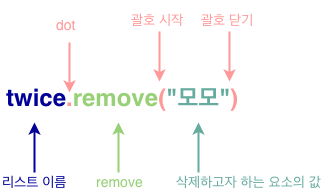
del 키워드를 사용해서 요소를 리스트에서 삭제하는 방법의 단점은 인덱스를 사용해야 한다는 것이다. del과 다르게 remove는 리스트의 method(메소드)이다.
Tuple
tuple은 일반적으로 2개에서 5개 사이의 요소들을 저장할 때 사용되며, 특정 데이터를
ad hoc(즉석적으로)하게 표현하고 싶을 때 사용된다.
tuple은 주로 list와 같이 쓰인다. List의 요소들로 tuple을 사용하는 것이다.
물론 list를 사용해서 동일한 데이터를 표현할 수 있다.
하지만 이 경우에는 list보다는 tuple이 더 효과적이다. list는 수정이 가능하고 여러 수의
요소들을 저장할 수 있도록 했기 때문에 tuple보다 차지하는 메모리 용량이 더 크다.
더 많은 기능과 flexibility를 제공하기 때문에 어쩔 수 없이 용량이 커지는것이다.
하지만 tuple은 제한적인 만큼 용량이 더 적다. 그래서 수정이 필요없고 간닪나 형태의 데이터를
표현할때 tuple을 사용하는게 효과적이다.
set
set은 list의 친척이다.
list와 마찬가지로 여러 다양한 타입의 요소(element)들을 저장할 수 있다.
하지만 list와 동일하다면 set가 있을 이유가 없다.
list와 다른점은 다음과 같다.
- List와 다르게 요소들이 순서대로 저장되어 있지 않다. 즉 ordering이 없다.
그러므로 for문에서 읽어들일때 요소들이 순서대로 나오는게 아니라 무작위 순서대로 나온다.- 순서가 없으므로 indexing도 없다. 몇번째 요소를 읽어들이거나 할 수 없다.
- 동일한 값을 가지고 있는 요소가 1개 이상 존재 할수 없다. 즉 중복된 값을 저장할 수 없다.
만일 새로 저장하려고 하는 요소와 동일한 값의 요소가 존재한다면 새로운 요소가 이 전 요소를 치환한다.
set 생성하는 법
set을 생성하는 법은 일반적으로 2가지가 있다. 중괄호{}를 사용하는 방법과 set()함수를 사용하는 방법이다.
set1 = {1, 2, 3} set2 = set([1, 2, 3])
보시다시피 set() 함수를 사용해서 set를 만들기 위해서는 list를 parameter로 전달해야한다.
그러므로 일반적으로 set()함수를 사용해서 set를 만드는 경우는 list를 set로 변환하고 싶을 때 사용한다. 앞서 말했듯이 set에서는 중복된 값은 저장이 안된다. 그러므로 동일한 값이 1이상
있다면 맨 나중에 저장되는 요소만 남아있게 된다.
set1 = {1,2,3,1} print(set1) # {1,2,3} set2 = set([1,2,3,1]) print(set2) # {1,2,3}Set에서 새로운 요소 추가하기
Set는 list와 달리 add()라는 함수를 사용해서 새로운 요소를 추가한다.
my_set = {1,2,3} my_set.add(4) print(my_set) # {1,2,3,4}
Set에서 요소 삭제하기
set에서 요소를 삭제할때는 remove 함수를 사용해서 삭제한다.
my_set = {1,2,3} my_set.remove(3) print(my_set) # {1,2,}
Look Up
set에 어떠한 값이 이미 포함되어 있는지를 알아보는 것을 look up이라고 한다.
set에서 look up을 하기 위해서는 in키워드를 사용한다.
my_set = {1,2,3} if 1 in my_set: print("1 is in the set") # 1 is in the set if 4 not in my_set: print("4 is not in the set") # 4 is not in the set
Dictionary
dictionary의 기본적인 문법은 다음과 같다.
my_dic = {"key1" : "value1", "key2" : "value2"}
중괄호 {}를 사용해 dictionary를 선언한다.
key와 value의 값으로 이루어져 있다. key값이 먼저 나오고 그리고 :이 위치하고 그 다음에
value값이 나온다.
각각의 key:value들은 ,(comma)로 구분한다.
Dictionary에서 요소(element)읽어들이기
Dictionary 에서 element를 읽어 들이는 방법은 list와 유사하다. List와 차이점은 요소의
index를 사용하는것이 아니라 key값을 사용한다는 점이다.
my_dic["key1"]key는 string 뿐만이 아니라 숫자도 가능하다.
key값은 중복될 수 없다. (중요)
만일 이미 존재하는 key값이 또 추가되면 기존의 key 값의 요소를 치환하게 된다.
dict1= {1: "one", 1: "two"} print(dict1) #{1:"two"}
위의 코드에서 dict1은 1이라는 동일한 key가 2번 있는것을 볼 수 있다. 이렇게 동일한
key가 있으면 나중에 추가된 key의 요소가 먼저 있떤 key의 요소를 지원한다.
Dictionary에서 새로운 요소(element) 추가하기
dictionary에서 새로운 요소를 추가하는 문법은 다음과 같다.
dictionary_name[new_key] = new_value
여기서 조심할건 값이 동일한 key가 이미 존재하면 새로 추가되는 요소가 그 전의 요소를 치환한다는 점이다.

Dictionary 에서 요소 수정하기
요소를 수정하는 방법은 list와 유사하다. 차이점은 index가 아니라 key값을 사용한다는 점이다.
my_dict = {"one": 1, 2:"two", 3:"three"} my_dict["four"] = 4 print(my_dict) # {"one": 1, 2: "two", 3:"three", "four : 4}
처음부터 비어있는 dictionary를 만든 다음에 하나씩 추가해 나가는 것도 가능하다.
