
안녕하세요 오늘은 현재 가장 많이 사용되는 MOM(Message Oriented Middleware) 인 Kafka 에 대해 알아보겠습니다.
🎮 카프카(Kafka) 란?
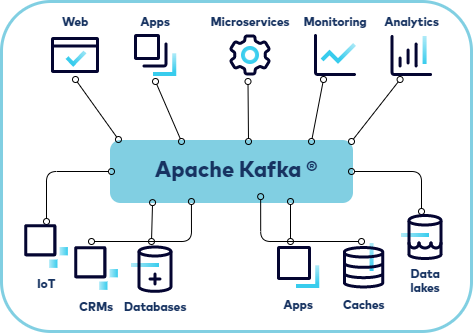
Apache 재단에서 관리하는 Kafka 는 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 application을 위한 오픈 소스 분산 이벤트 스트리밍 플렛폼 입니다.
Kafka 의 이벤트 스트리밍은 현재 많은 기업들이 사용하고 있으며 점차 사용빈도가 증가하고 있습니다.
이벤트 스트리밍 플렛폼이란?
Kafka 는 세 가지 주요 기능을 결합하여 end-to-end 이벤트 스트리밍을 구현할 수 있습니다.
- 이벤트 스트림을 지속적으로
발행(publish)그리고구독(subscribe)합니다. - 이벤트 스트림을 원하는 만큼 내구성 있고 안정적으로
저장(store)합니다.
이러한 특징과 더불어 Kafka 는 확장성이 뛰어나고 탄력적이며 내결함성이 있으며 안전한 방식으로 제공됩니다. Kafka 환경을 자가 관리하거나 다양한 공급 업체에서 제공하는 완전 관리형 서비스를 사용할 수 있습니다.
메세지 큐(Message Queue: MQ)
MOM(Message Oriented MiddleWare) 는 Asynchronous 메세지를 사용하는 각각의 응용프로그램 사이의 데이터 송수신을 의미하며 메세지(이벤트) 기반의 매개체라고 생각하면 됩니다.
그리고 MOM 을 구현한 시스템을 MQ(Message Queue) 라고 합니다.
현재 많이 사용되는 오픈소스 MQ 에는 RabbitMQ,Kafka,ActiveMQ 등이 있습니다❗️
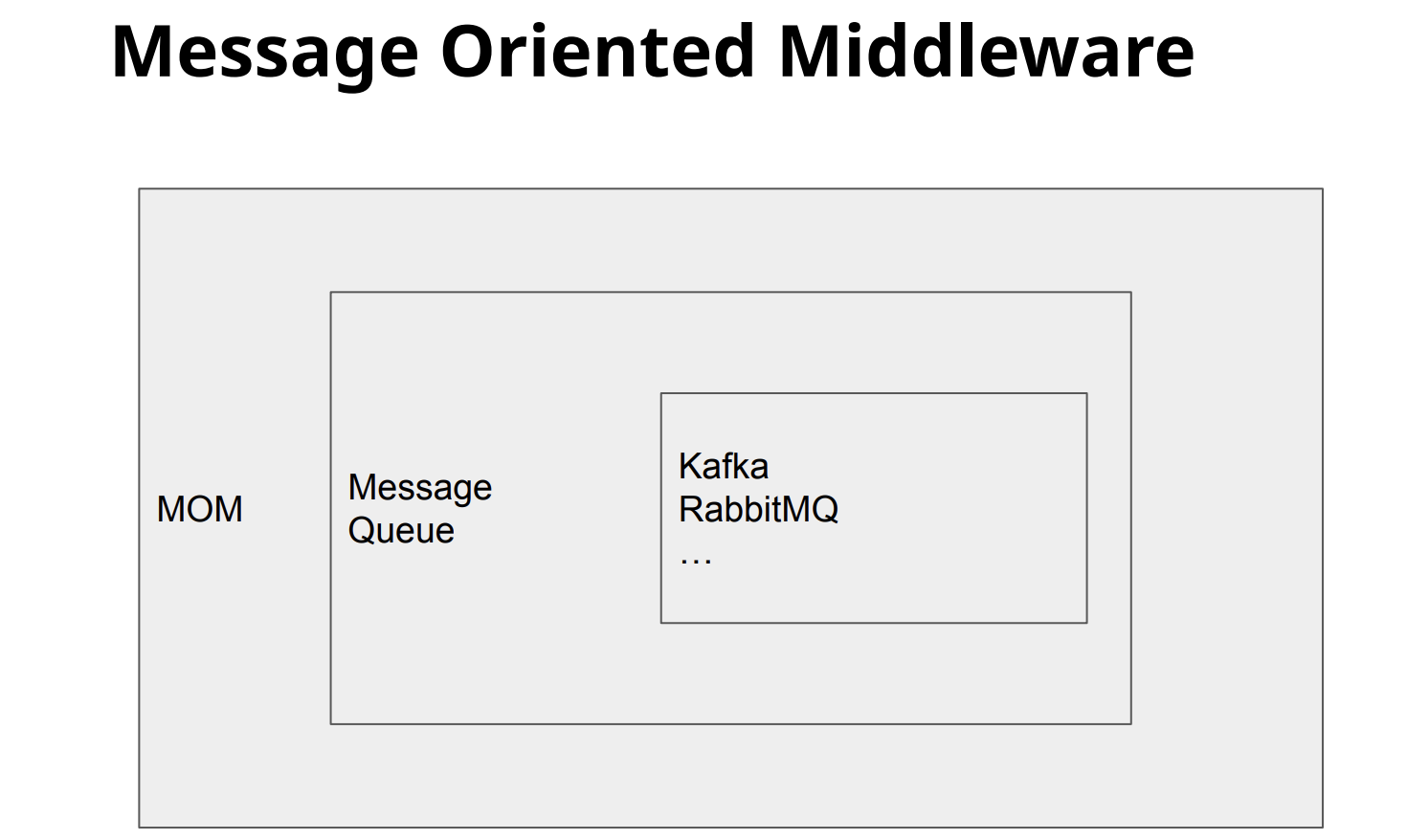
해당 이미지는 이번 포스팅에서 다룰 Kafka 에 대한 이미지입니다.
결국 Kafka 는 MOM 을 구현한 Message Queue의 한 종류라고 보면 됩니다 🔥
🎮 카프카 탄생 배경
Kafka 는 현재 Apache 재단에서 관리되고 있지만 Linked in 에서 만들어졌습니다.
Linked in 은 기존의 end-to-end 통신 방식 아키텍쳐에 대해 많은 문제점을 느꼈습니다 😱
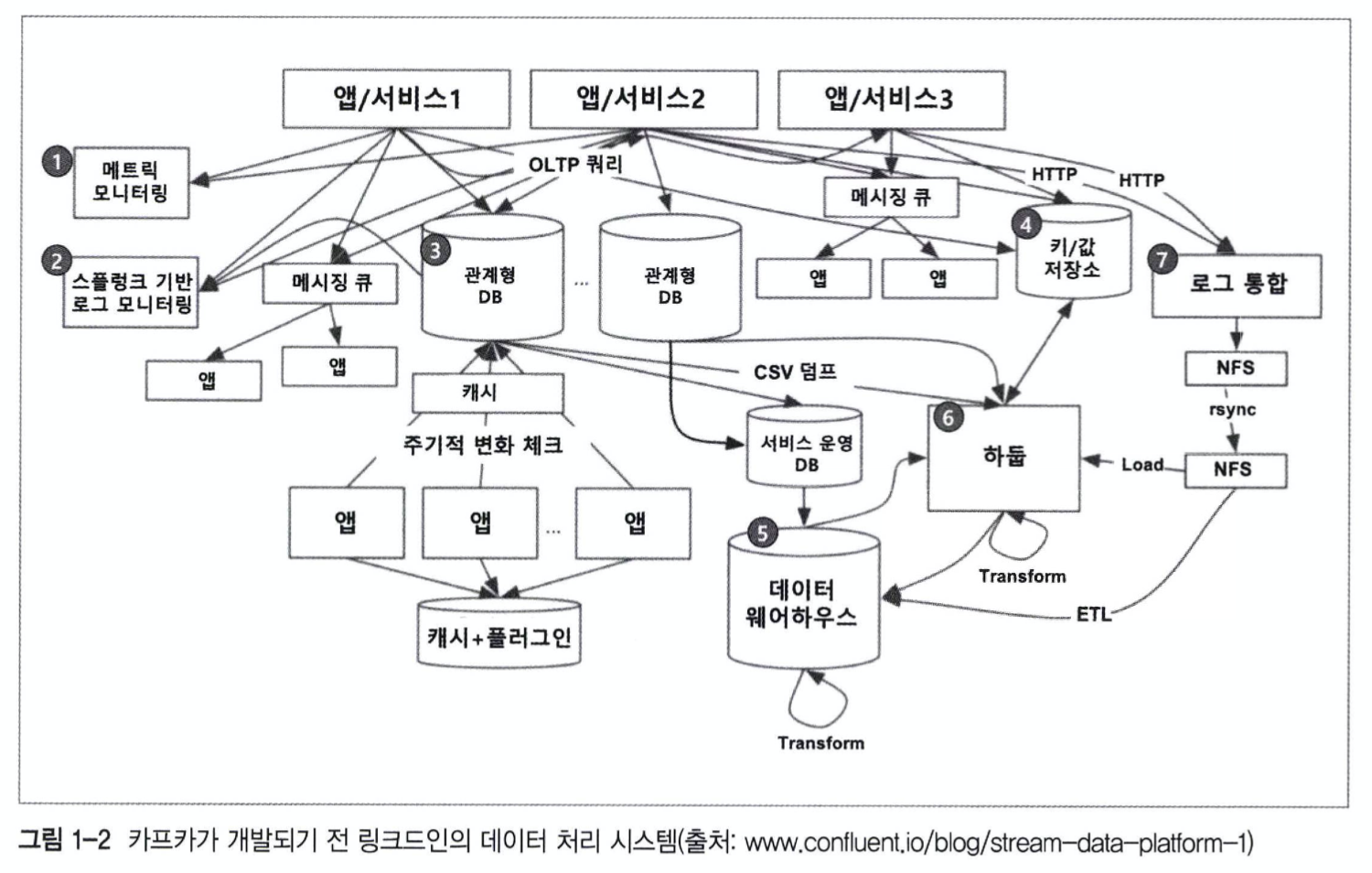
해당 이미지는 Kafka 시스템이 도입되기 이전의 Linked in 의 데이터 처리 시스템을 보여주는 이미지입니다.
어떤가요? 겉으로 보기에는 체계적으로 잘 연결된 시스템이라고 여길 수 있지만, 운영,관리 및 유지보수가 매우 어려워 보입니다 🤔
- Linked in 이 직면한 기존의 end-to-end 통신 방식의 문제점 ❗️
-
시스템 복잡도(Complexity)의 증가
-> 통합된 전송 영역이 없어 데이터 흐름을 파악하기 어렵고, 시스템 관리가 어려움
-> 특정 부분에서 장애 발생 시 조치 시간 증가 (연결 되어있는 애플리케이션들을 모두 확인해야 했기 때문)
-> HW 교체 혹은 SW 업그레이드 시 관리 포인트가 늘어나고, 작업시간의 증가(연결되어 있는 애플리케이션에 Side Effect 가 없는지 확인 필요) -
데이터 파이프라인 관리의 어려움
-> 각 애플리케이션과 데이터 시스템 간 별도의 파이프라인이 존재하고, 파이프라인마다 데이터 포맷과 처리 방식이 다름
-> 새로운 파이프라인 확장이 어려워지면서, 확장성 및 유연성이 떨어짐
-> 데이터 불일치 가능성이 존재했기 때문에 신뢰도 감소
이러한 문제점을 직면한 Linked in 개발팀은 Kafka 개발팀을 구성하여 목표를 설정합니다.
1. 기존 end-to-end 통신 방식에서 벗어나 통합/중앙화된 전송 영역을 설계하자.
2. 메세지를 생성하는Producer와Consumer을 분리하자.
3. 대용량 메세지 처리와 더불어 빠른 처리량을 이루자.
4. 확장(Scale-out) 이 용이하도록 설계하자.
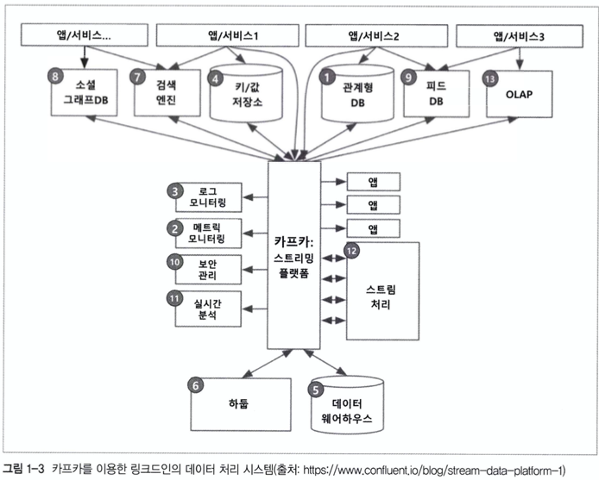
결국 카프카 개발팀은 초기에 설정한 목표를 이루고 Kafka 라는 데이터 플랫폼의 최강자를 만들어냅니다. 🧑🔧
해당 이미지는 Kafka 을 도입한 후에 데이터 처리 시스템을 보여줍니다.
마음이 벌써 편안해지네요 😊
🎮 주요 개념 및 정리
-
이벤트(Event)- Kafka 을 통해
Producer와Consumer가 데이터를 주고받는 단위, 메세지
- Kafka 을 통해
-
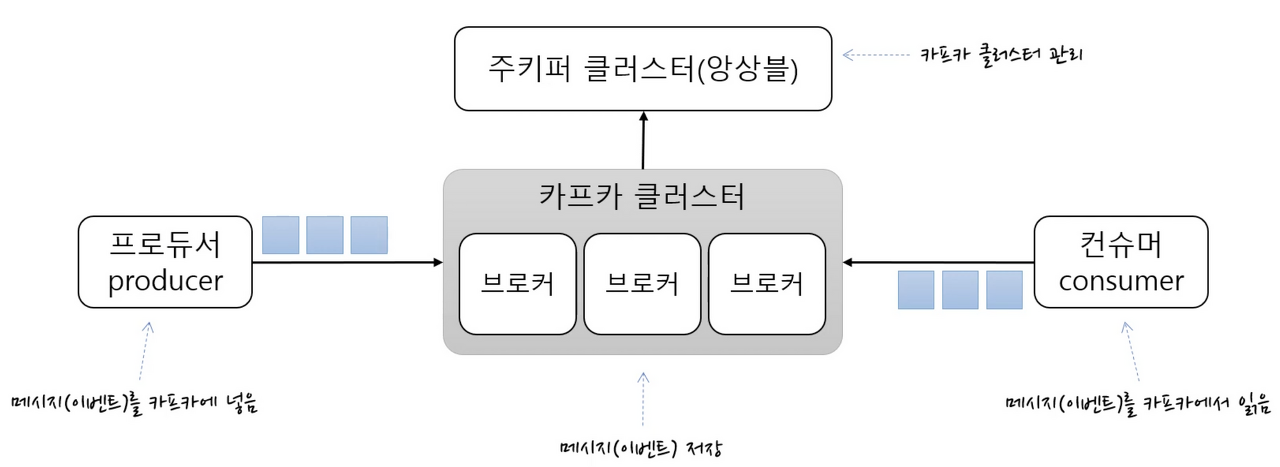
카프카 클러스터(Kafka Cluster)Kafka Broker들의 모임,Kafka는 확장성과 고가용성을 위하여 Broker 들이 클러스터로 구성
-> 여러개의 Kafka Broker 로 운영을 하면 동시에 더 많은 데이터를 처리할 수 있으며, 필요에 따라 Broker 을 추가할 수 있습니다.
-> 여러Kafka Broker로 구성된Kafka cluster에서는 하나의 Broker 가 실패하더라도 다른 Broker 동작을 계속할 수 있습니다.
-
브로커(Broker)- 각각의
Kafka서버, 동일 노드에 여러 브로커를 띄울 수 있음 - 실행된
Kafka서버를 말하며,Kafka그 자체임. - 내부에
Producer로 부터 받은 메시지(이벤트) 을 저장하고 관리하는 역할을 수행함
- 각각의
-
Zookeeper- Kafka 클러스터 정보 및 분산처리 관리 등 메타데이터 저장 Kafka 를 띄우기 위해서 반드시 실행되어야 함
- 분산 애플리케이션 관리를 위한 코디네이터
-
Producer- 메세지(이벤트)를 발행하여 생산하는 Kafka 클라이언트 애플리케이션
- 메세지 전송 시 Batch 처리가 가능(일정 량을 모아서 전송)
- 전송
Acks값을 설정하여 효율성을 높일 수 있음Acks= 0 :Partition리더가 받았는지 확인 하지 않음 -> 매우 빠르게 전송Acks= 1 :Partition리더가 받았는지 확인함 (Default)Acks= ALL :Partition리더 뿐만 아니라 팔로워까지 메세지를 받았는지 확인함 -> 상대적으로 느린 전송
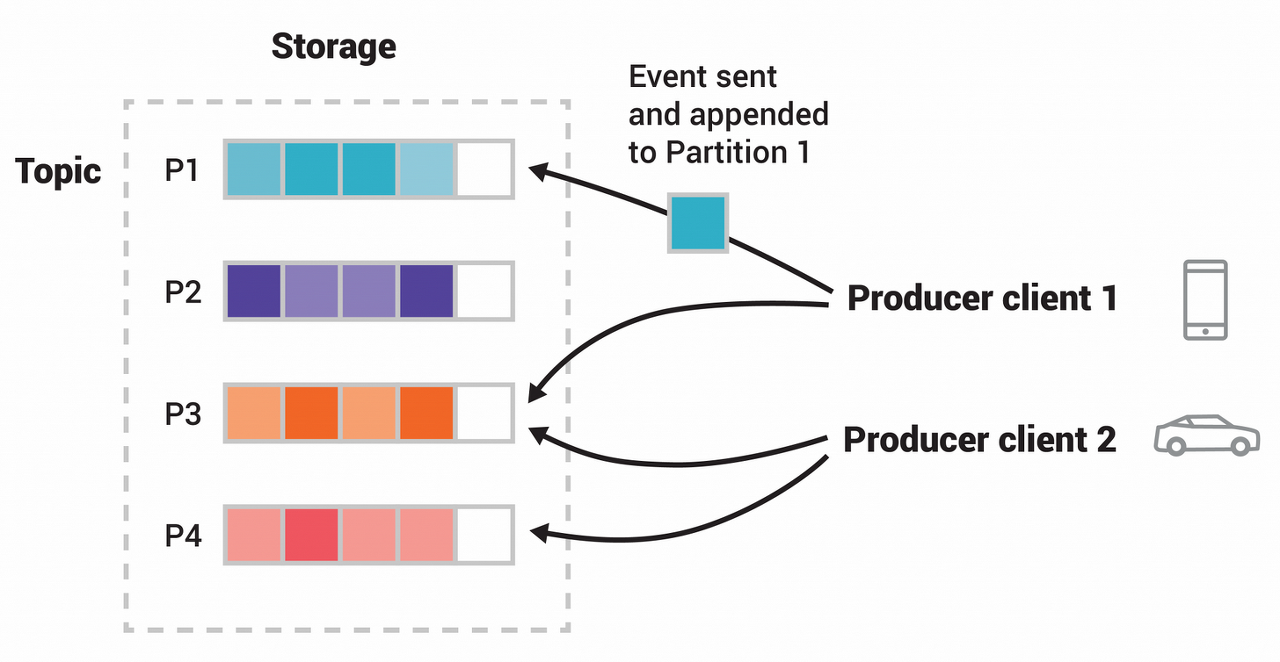
Producer 는 메세지 전송시 Topic 을 지정하며 같은 키를 갖는 이벤트는 같은 파티션에 저장되며 순서 유지를 합니다.
Consumer
- 메세지(이벤트)를 구독하여 소비하는 Kafka 클라이언트 애플리케이션
Kafka Cluster에서 메세지를 읽어서 소비한다.- 메세지(이벤트) 을 Batch 처리 가능하다.
- 한개의
Consumer는 여러 개의Topic처리가 가능하다.
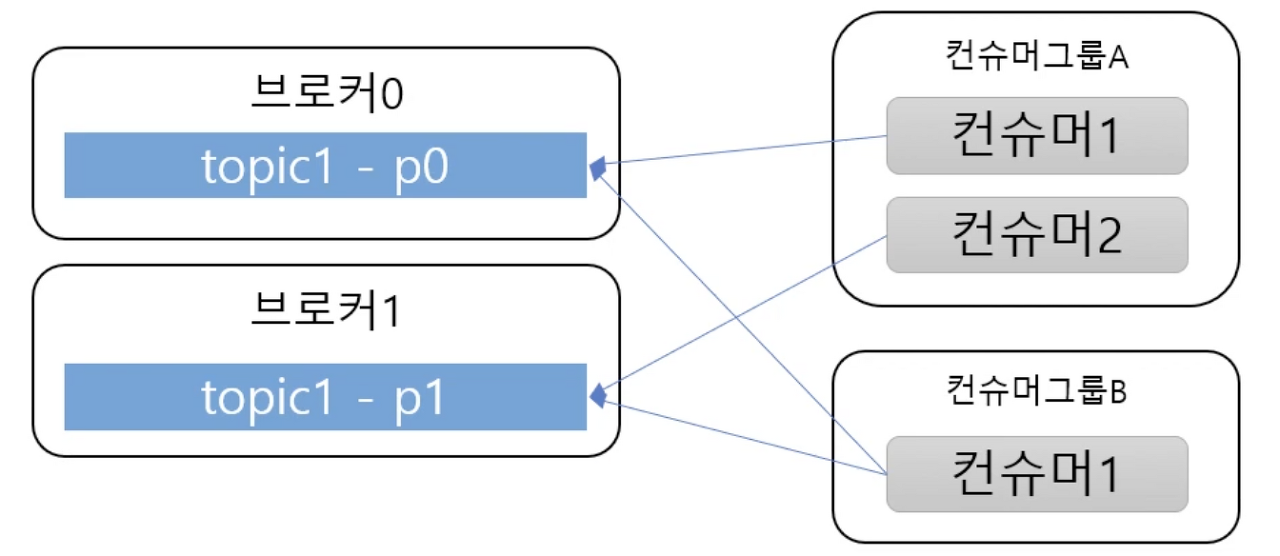
Consumer 는 Consumer Group 를 가집니다.
Consumer Group 이란 메세지를 소비하는 Consumer 들의 논리적 그룹입니다.
또한 Topic 의 Partition 은 Consumer Group과 1:N 매칭 관계로 동일 그룹내 한개의 Consumer 만 연결이 가능합니다.
이로써 Partition 의 메세지는 순서대로 처리되도록 보장됩니다.
하지만, Partition 이 한개 이상이라면, Topic 전체 관점에서 모든 메세지의 처리 순서는 보장되지 않습니다❗️
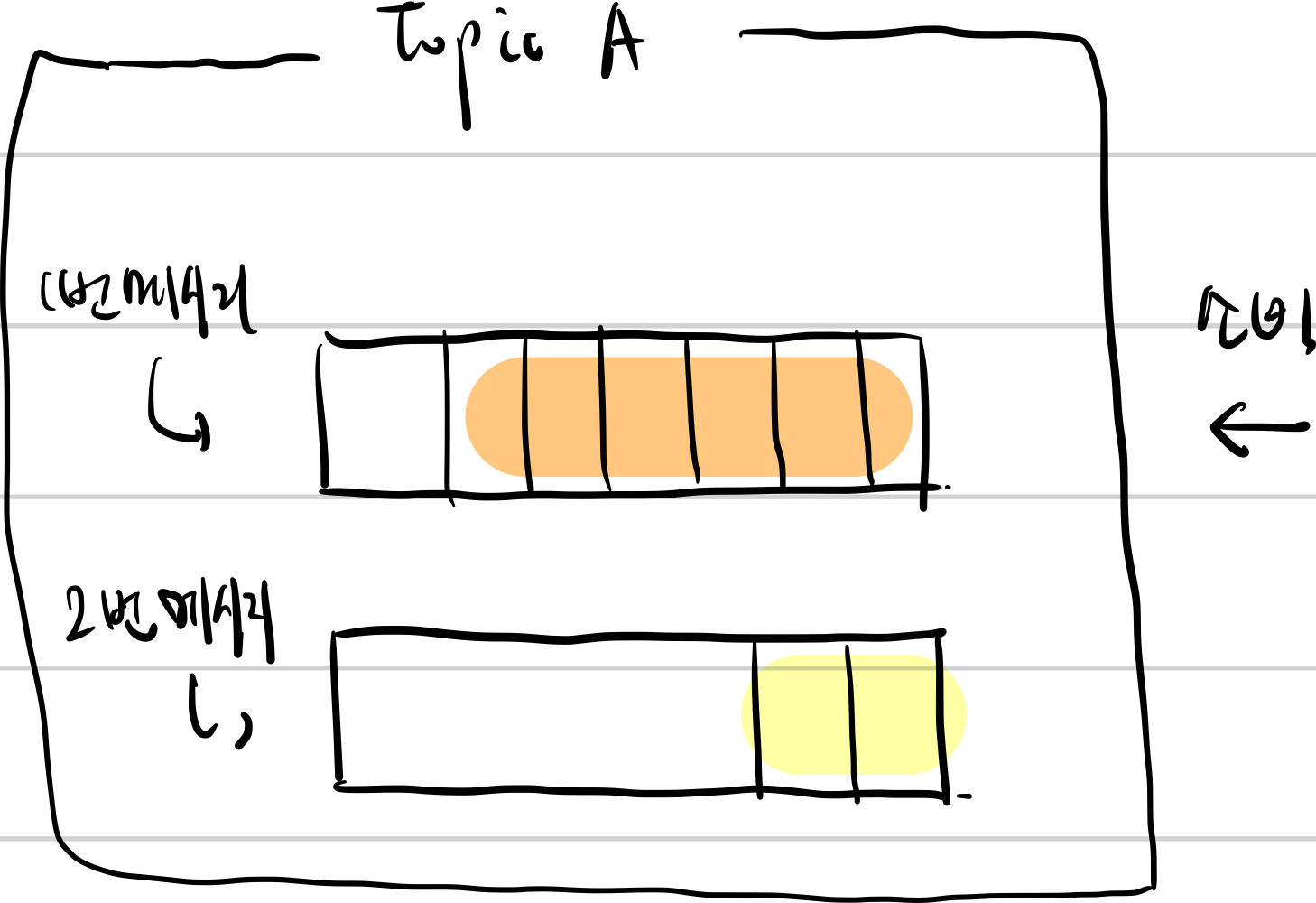
해당 이미지는 Partition 이 여러개라면 메세지 처리 순서가 보장이 되지 않는 이유를 설명할 수 있는 이미지입니다.
TopicA 는 2개의 Partition 으로 구성되어 있는데 1번 메세지가 들어오고 2번 메세지가 들어온다고 가정할 때, 1번 메세지가 들어가는 Partition 은 이미 다른 이벤트로 채워져 있기 때문에 비교적 여유로운 Partition 에 들어간 2번 메세지가 1번 메세지보다 먼저 처리될 수 있습니다.
이러한 이유 때문에, 이벤트의 처리 순서가 보장되지 않을 수 있습니다 👨💻
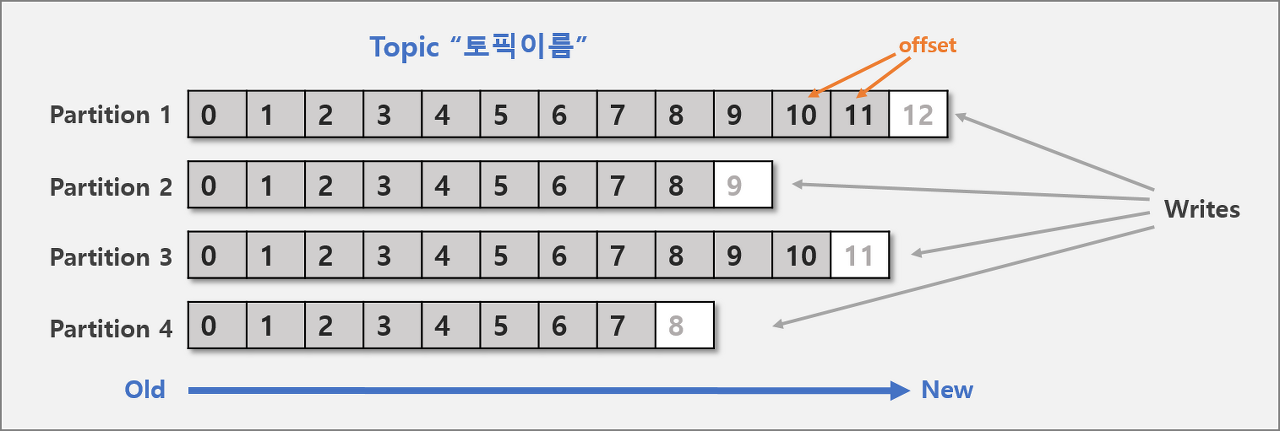
Topic- 메세지를 구분하는 단위, 파일시스템의 폴더와 유사
- 메세지를 전송하거나 소비할 때
Topic이름 필요함 Consumer는 자신이 담당하는 Topic 메세지를 처리함Topic은 한 개 이상의Partition으로 구성됨
-
Partition- 메세지를 저장하는 물리적인 파일,
Topic은 여러Broker에 분산되어 저장되며, 이렇게 분산된Topic을Partition이라고 함 - 각
Partition은 별도의 파일로Kafka Broker의 디스크에 저장됨 Partiton은Producer로 부터Kafka Broker로 들어오는 엄청난 양의 메세지(이벤트) 을 병렬로 처리할 수 있게 해줌
- 메세지를 저장하는 물리적인 파일,
-
Offset: Partition 내 각 메세지의 저장된 상대적 위치Producer가 넣은 메세지(이벤트)는 Partition 맨 뒤에 추가Consumer는Offset기준으로 마지막 커밋 시점부터 메세지를 순서대로 읽어서 처리- Partition 의 메세지 파일은 영속성을 유지하며 일정시간 뒤 삭제됨 -> 소비한 메세지를 다시 소비 가능
🎮 왜 카프카일까?
고성능
-
다중 Producer & 다중 Consumer 가 상호 간섭없이 메세지(이벤트)를 쓰고 읽어서 처리함(의존성 감소)
-
디스크 기반의 메세지(이벤트) 보존
- 영속성을 보장할 수 있음, 데이터 유실 위험이 적고 Consumer가 항상 안떠있어도 됨
-> 나중에 Consumer 가 필요로 할 때까지 메세지(이벤트)을 유지 - 장애 발생시 유실 복구 가능(재처리)
- Partition 파일은 OS 페이지 캐시를 통해 IO 를 메모리에서 처리하여 성능 유리
-> Consumer 가 메세지(이벤트) 을 필요로 할 때, OS 페이지 캐시를 사용하여 메모리에서 메세지(이벤트)을 가져와서 Consumer 에게 전달
- 영속성을 보장할 수 있음, 데이터 유실 위험이 적고 Consumer가 항상 안떠있어도 됨
-
Broker 하는일이 비교적 단순
- Broker 는 Consumer와 Partition간 mapping 관리만 하며 성능에 집중함
- Message Filter, Message 재전송과 같은 일은 Produer, Consumer에 위임
-
Batch 기능을 제공하여 동시 처리량 증가
- Producer : 일정 크기만큼 메세지를 모아서 전송
- Consumer : 최소 크기만큼 메세지를 모아서 읽어옴
-
확장성 : 수평확장이 쉽게 가능함 -> Broker,Consumer,Partition 추가
고가용성(High Availability)
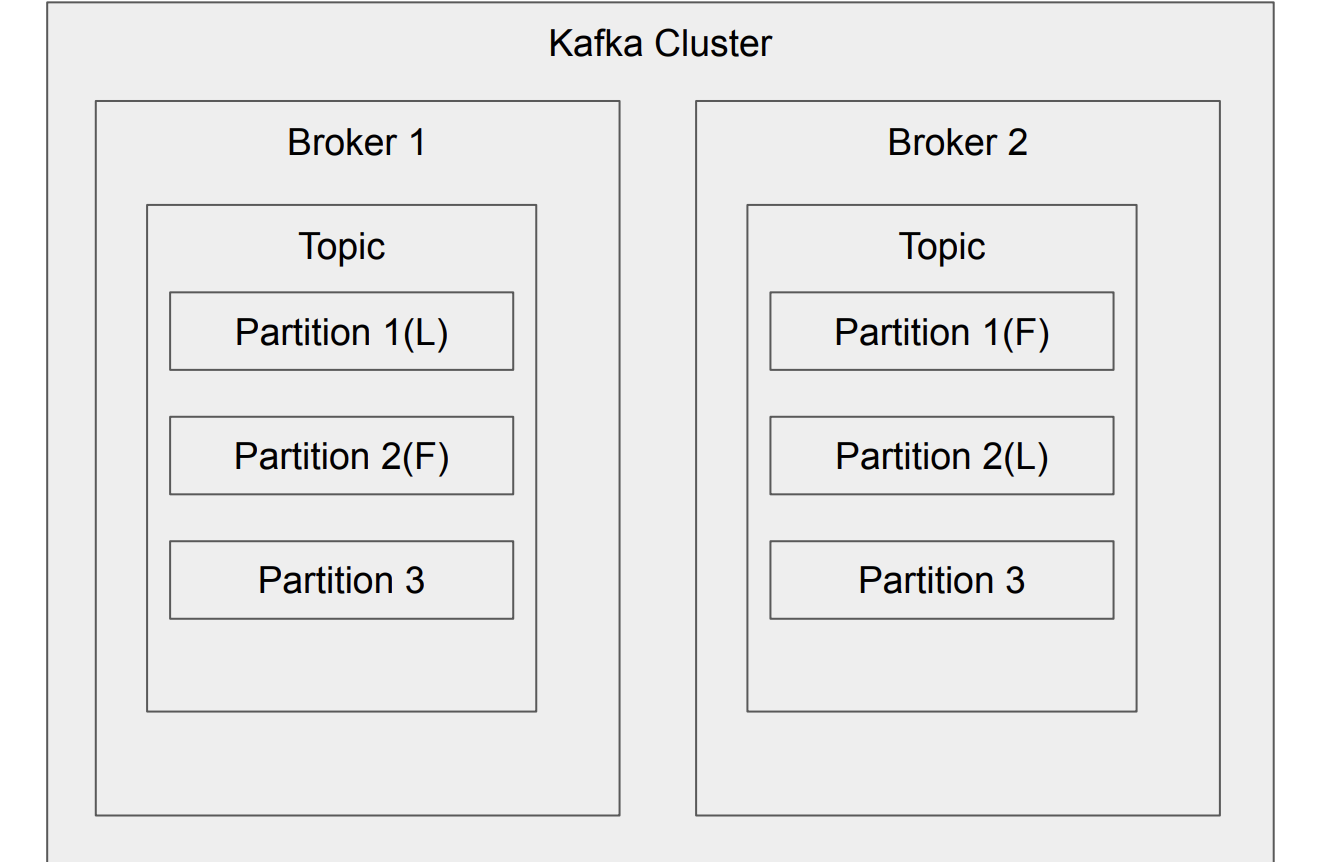
-
Kafka의 Topic 은 Partition단위로 쪼개어져 클러스터의 각 서버들에 분산되어 저장되고 고가용성을 위하여 복제설정을 할 수 있음 즉, Topic 을 구성하는 Partition단위로 각 Broker들에 분산되어 장애시 fail over을 수행
-
Replication은 Topic 내의 Partition의 복제본,replication-factor을 통해 replication 의 복제본 개수를 지정할 수 있음.
여기서replication-factor을 지정하면 그 만큼 Partition의 복제본이 각 Broker에 생김
여기서Leader와Follower로 구성되는데 복제된 Partition이Follower이고 복제 대상의 Partition이Leader임
리더(Leader) : Partition의 복제본 중에서 쓰기(Write) 작업을 담당하는 복제본
팔로워(Follower) : Partition의 복제본 중에서 리더로부터 메세지(이벤트) 을 복제하여 저장하는 복제본
-
이렇게 하나의 Partition 의 복제본을 구현함으로써, 리더 Partition 복제본의 문제 발생 시, 팔로워 Partition 복제본이 리더 역할을 수행 -> 고가용성(HA) 보장
-
따라서 특정
Topic을 구성하는 모든Partition들이 모두 동일한Kafka Broker에 의해 관리된다고 보장할 수 없음 (Partition 단위로 관리)
🎮 Kafka 에 대한 궁금중
1. 왜 하나의 Topic 을 여러개의 Partition 으로 나눌까?
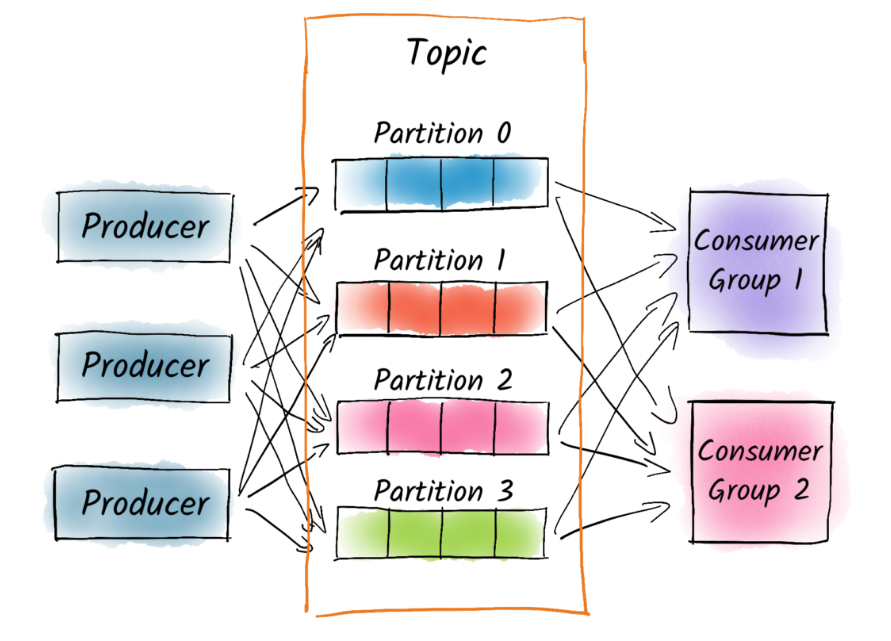
앞에서 살펴본 바와 같이 Topic 은 Producer 가 발행한 이벤트가 모이는 하나의 단위입니다.
즉, 특정 관심사를 대표하는 폴더라고 생각하면 좋을 것 같습니다.
그렇다면 왜 Topic 을 여러 Partition 으로 나눌까요?
👨💻 많은 양의 이벤트를 병렬로 처리하기 위해 분산처리합니다.
실제, Kafka 가 사용되는 Application 에서는 동시에 엄청나게 많은 양의 이벤트가 kafka Broker 에 Produce(Write) 되며 동시에 Consumer 에 의해 Consume(Read) 될 수 있습니다.
만약 Topic 안에 하나의 메세지 큐(Partition) 가 존재한다면 병목 현상이 발생할 수 있습니다.
따라서 효율적인 이벤트 분산 처리를 위해 Partition 을 여러개 두어 병렬 방식을 통해 분산 처리합니다.
단, 한번 늘린 Partition은 절대 줄일 수 없기 때문에 운영 중에, Partition 을 늘리는 건 충분히 검토 후에 실행되어야 합니다.
또한, Partition 을 늘렸을 때 메세지는 Round-Robin 방식으로 쓰여집니다. 따라서 하나의 Partition 내에서는 메세지 순서가 보장되지만, Partition 이 여러개인 경우 순서가 보장되지 않습니다❗️
결론 : 최소한의 Partition 으로 운영하고 사용량에 따라 필요시 늘리자
2. Consumer Group 이 왜 존재할까?
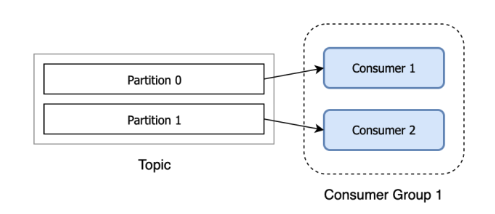
Consumer Group 은 하나의 Topic 에 대한 책임을 가집니다.
즉 어떤 Consumer 가 다운된다면, Partition Rebalancing 을 통해 다른 Consumer 가 해당 Partition의 Consume 을 맡아서 해야 합니다. 이를 위해 Consumer Group 이 존재합니다.
Partition 에서 어디까지 소비했는지에 대한 정보인 Offset 은 Consumer Group에서 공유하기 때문에 다운된 Consumer 을 대체하는 다른 Consumer 는 정상적으로 이어서 이벤트를 소비할 수 있습니다❗️
참고
[Apache Kafka] 카프카란 무엇인가?
메시지 큐(Message Queue)란?
카프카(Kafka)란?, 메세지 큐 들여다 보기
[카프카] 무엇이고, 왜 필요할까?
