
해당 글은 김영한 님의 ["자바 ORM 표준 JPA 프로그래밍"] 을 스터디 하면서 정리하는 글 입니다 !👨💻
📣 이번 글은 엔티티 매핑에 대한 글입니다.
JPA 에서 가장 핵심이 되는 내용임으로 꼭 완주해주세요!
JPA를 사용하는 데 가장 중요한 일은 엔티티와 테이블을 정확히 매핑하는 것입니다 💡
따라서 매핑 어노테이션을 꼭 숙지하고 있어야 합니다.
JPA 와 관련된 매핑 어노테이션에는 4가지가 있습니다.
| 종류 | 매핑 어노테이션 |
|---|---|
| 객체와 테이블 매핑 | @Entity, @Table |
| 기본 키 매핑 | @Id |
| 필드와 칼럼 매핑 | @Column |
| 연관관계 매핑 | @ManyToOne, @JoinColumn |
📚 @Entity & @Table
- @Entity : 테이블과 매핑할 클래스는 @Entity 어노테이션을 필수로 붙여야 합니다.
해당 어노테이션을 붙이면 JPA 가 엔티티 클래스를 관리하게 됩니다.- name : JPA 에서 사용할 엔티티 이름을 지정합니다.
설정하지 않으면 클래스 이름을 기본값으로 사용합니다. - 엔티티 객체를 생성할 때 기본 생성자를 사용하기 때문에 기본 생성자는 필수입니다.
- name : JPA 에서 사용할 엔티티 이름을 지정합니다.
- @Table : 엔티티 클래스와 매핑할 테이블을 지정하기 위해서는 @Table 어노테이션을 필수로
붙여야 합니다.- name : 매핑할 테이블 이름을 지정합니다.
설정하지 않으면 해당 테이블과 매핑되는 엔티티 클래스의 이름을 테이블의 이름으로 지정합니다. - uniqueConstraints : DDL 생성 시에 유니크 제약조건을 만듭니다.
- name : 매핑할 테이블 이름을 지정합니다.
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity(name = "member")
@Table(name = memberTable")
@Setter
@Getter
public class Member{
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
private String username;
private int age;
}해당 코드를 보겠습니다.
상단에 여러가지 어노테이션이 사용된게 보이시죠?
가장 먼저 @Entity 어노테이션이 있습니다. 따라서 Member 클래스는 JPA 가 관리하는 엔티티 클래스가 됩니다. name 속성을 이용해 엔티티 클래스의 이름을 member 라고 지정했지만, 사실
엔티티는 name 속성이 없어도 자동으로 member 라는 이름을 가질 것 입니다 💡
그 다음 @Table 어노테이션이 존재합니다.
name 속성을 이용해 테이블에 memberTable 이라는 이름을 지정해 준것이 보입니다.
따라서 데이터베이스를 확인해보면 해당 테이블의 이름은 memberTable이 될 것 입니다 ✨
📚 @Id
어떤 테이블이던지 데이터 무결성(Data Integrity)를 위해 기본키(Primary Key) 는 필수적입니다.
JPA 에서 엔티티 클래스를 테이블로 매핑시, 기본키 매핑은 어떤 방식으로 할까요?
여기서 저희가 떠올려야할 점은 데이터베이스 벤더 마다 기본키를 생성하는 방식이 서로 다르다는 것 입니다. 다행히 JPA 는 이러한 문제점을 해결하면서 기본키를 생성하는 '기본 키 생성 전략'을 가집니다.
기본 키 생성 전략에는 2가지가 있습니다. 🎁
- 직접 할당 : 기본 키를 애플리케이션에서 직접 할당
- 자동 생성 : 대리 키 사용 방식
- AUTO : 데이터베이스 방언에 따라 전략 자동 선택
- IDENTITY : 기본 키 생성을 데이터베이스에 위임한
- SEQUENCE : 데이터베이스 시퀀스를 사용해서 기본 키를 할당
- TABLE : 키 생성 테이블을 사용
기본 키를 직접 할당하는 방식은 기본 키로 사용하고자 하는 칼럼에 @Id 어노테이션만 붙이면 됩니다.
하지만 자동 생성 하는 방식은 @GeneratedValue 어노테이션을 통해 원하는 키 생성 전략을 선택 해야 합니다.
@Entity
public class User {
@ Id
private String userEmail; -> 기본 키 직접 할당
....
}@Entity
public class User {
@Id
@Column(name = "ID") -> 기본 키 자동 생성
@GeneratedValue(Strategy = GenerationType.IDENTITY
private Long id;
}앞에서 살펴본 2가지 기본 키 생성 전략 중 어떤 방법이 데이터 무결성을 유지하는 데이터베이스 작업을 보장할까요?
여기서 자연키와 대리키에 대한 개념 이해가 필요합니다.
해당 개념에 대한 이해를 위해 대리키 & 자연키 를 참고해주세요.
기본키의 설정 조건을 완벽하게 지킬 수 있는 키라면 개발자가 원하는 자연키를 기본키로 설정해도 되지만, 서비스가 제공되면서 예상치 못한 일들이 일어날 수 있습니다 😱
따라서 어떤 경우에서도 기본키의 조건을 만족하는 '대리키' 를 사용하는 것이 안전하고, 이를 위해 기본 키 자동 생성 방식을 사용하도록 합시다 🙆🏻
📚 @ Column
엔티티 클래스와 필드와 테이블의 칼럼을 매핑하기 위해서는 @Column 을 사용합니다.
@Table(name = "TB_USER")
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name="U_ID")
private long id;
@Column(name="ID")
private String userId;
@Column(name="NICK_NAME")
private String nickName;
@Builder
public User(long id, String nickName) {
this.id = id;
this.nickName = nickName;
}
} Use 엔티티 클래스는 2가지의 필드를 가집니다.
JPA 가 관리하는 해당 엔티티 클래스는 테이블로 매핑 시, 필드는 칼럼으로 매칭되게 됩니다.
이때, @Column 의 다양한 속성을 사용 할 수 있습니다.
| 속성 | 설명 | 기본값 |
|---|---|---|
| name | Mapping 할 Colum의 이름을 설정 | 필드 이름 |
| insertable | Entity 저장 시 해당 필드도 저장, false 로 읽기 전용 설정 가능 | true |
| updatable | Entity 수정 시 해당 필드도 수정, false 로 읽기 전용 설정 가능 | true |
| table | 하나의 Entity 설정에서 두 개 이상의 Table 매핑할 때 사용 | 매핑된 Table |
| nullabe | null 허용 여부 설정 | true |
| unique | Unique 제약 조건 설정 | |
| length | Column 속성 길이 설정 | 255 |
| columnDefinition | DB Column 정보를 직접 설정 | DB 방언으로, 적절한 Column Type 생성 |
| precision, scale | 아주 큰 숫자가 정밀한 실수를 다룰 때 사용 | precision = 19, scale = 2 |
이렇게 다양한 속성을 통해 엔티티 클래스의 필드를 칼럼으로 매핑할 수 있습니다 💪
📚 연관관계 매핑
엔티티 클래스는 대부분 다른 엔티티와 연관관계가 있습니다.
또한 데이터베이스 관점에서 보았을 때, 외래키를 이용한 '조인(Join)' 이라는 기능을 이용해 연관관계를 맺어줍니다.
즉, 연관관계 매핑이란 엔티티 객체 사이의 연관관계를 테이블 사이의 연관관계로 매핑하는 것을 의미합니다.
다시 정리하자면, 객체는 서로를 '참조(Reference)' 라는 방식으로 연관관계를 맺기 때문에
참조 방식과 외래키 방식을 매핑하는 방식을 공부하고자 합니다 ❗️
개인적인 생각이지만 엔티티 매핑 과정에서 연관관계 매핑이 가장 어렵습니다!
따라서 천천히 공부하시는 것을 추천 드립니다 💡
- 방향 : 단방향 / 양방향
- 다중성 : 일대일(1:1), 다대일(N:1), 일대다(1:N), 다대다(N:N)
- 연관관계의 주인 : 객체에서의 연관관계와 테이블에서의 연관관계의 방식에 차이가 존재하기에, 연관관계의 주인이 필요
이번 글에서는 연관관계에서 가장 많이 사용되는 다대일(N:1) 관계를 기준으로 설명합니다 ❗️
1. 다대일 단뱡향 연관관계 🖇️
- 회원 엔티티와 팀 엔티티가 있습니다.
- 회원은 하나의 팀에만 소속됩니다.
- 따라서 팀과 회원은 다대일 관계입니다.
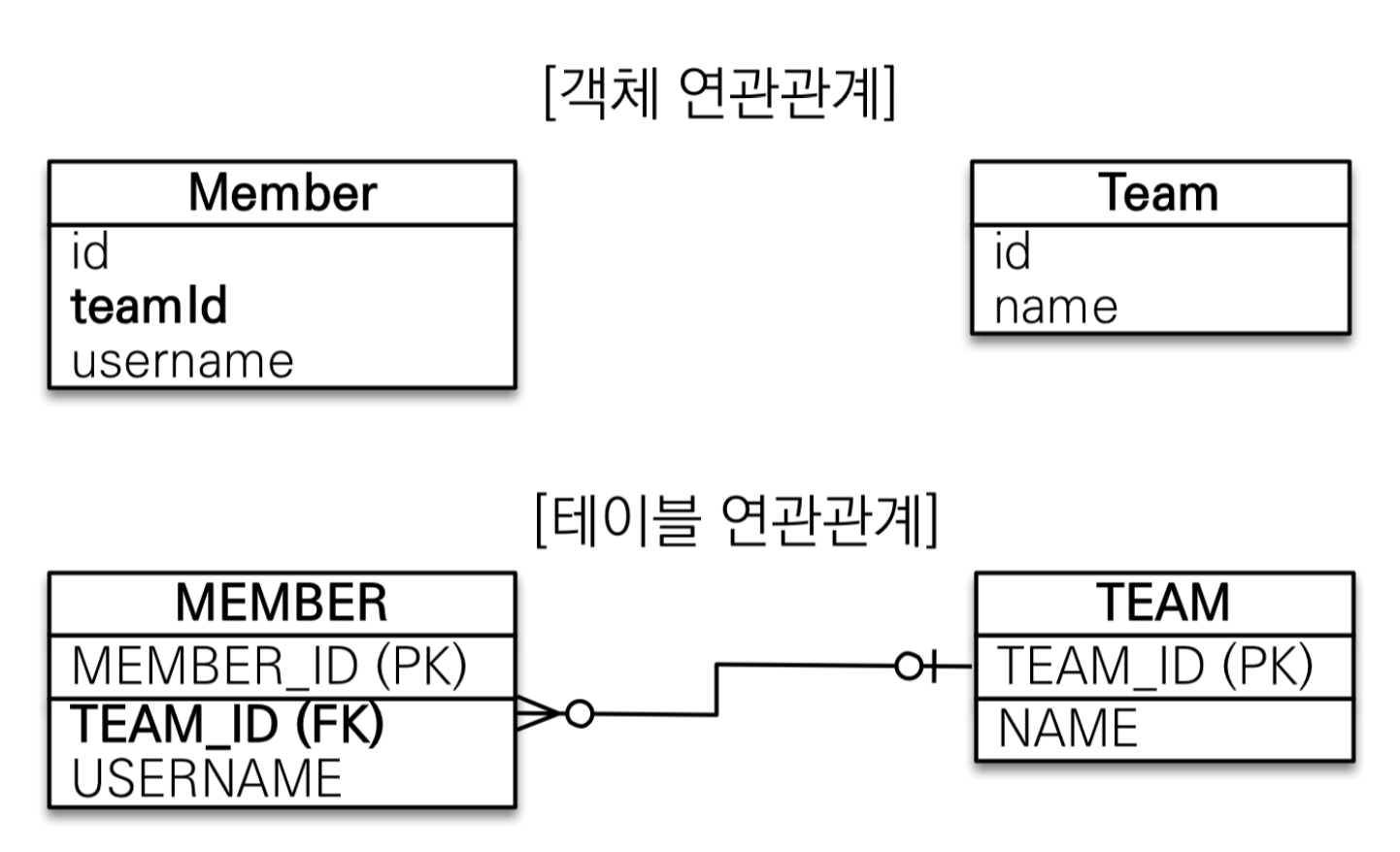
그림에 대해서 간단하게 설명하겠습니다.
-
엔티티 객체 연관관계 관점 👨💻
- 회원 객체는 Member.team 필드(멤버 변수)로 팀 객체와 연관관계를 맺습니다.
- 회원 엔티티와 팀 엔티티는 단방향 관계입니다.
- 회원은 자신이 속한 팀 정보를 알 수 있지만, 단방향이기에 팀은 자신에게 속한 회원들을 알 수 있는 방법이 없습니다.
-
테이블 연관관계 관점 👩🏼💻
- 회원 테이블은 TEAM_ID 외래 키로 팀 테이블과 연관관계를 맺습니다.
- 회원 테이블과 팀 테이블은 양방향 관계입니다.
따라서 해당 외래키를 통해서 팀과 회원을 조인할 수 있고 반대로 팀과 회원도 조인할 수 있습니다. (회원 Join 팀 or 팀 Join 회원)
🎁 객체 연관관계 VS 테이블 연관관계
연관관계 매핑이라는 것은 다시 한번 강조드리자면 엔티티 객체 입장에서 맺는 연관관계 방식을 테이블 입장에서 맺는 연관관계 방식으로 바꾸는 것을 의미합니다 ❗️
따라서 둘 사이에 존재하는 패러다임의 불일치를 해소해야 합니다.
객체와 테이블 연관관계의 가장 큰 차이점은 방향입니다.
참조 방식을 통한 객체 연관관계는 언제나 단방향 입니다. 따라서 만약 서로 참조하는 양방향을 만들고 싶다면 반대편 객체에도 상대방 객체 참조를 위한 필드를 추가해야 합니다.
반면, 외래키를 통한 테이블 연관관계는 언제나 양방향 입니다.
- 객체는 참조(주소) 로 연관관계를 맺는다 ( 항상 단방향)
- 테이블은 외래 키로 연관관계를 맺는다 (항상 양방향)
// 매핑한 회원 엔티티
@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
private String username;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
...
}
// 매핑한 팀 엔티티
@Entity
public class Team {
@Id @GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
private String name;
...
}
해당 코드는 다대일 단뱡향 연관관계에 있는 회원 엔티티와 팀 엔티티를 매핑한 것입니다.
- @ManyToOne
회원과 팀의 다대일 관계를 의미 합니다. 이렇게 다중성을 나타내는 어노테이션을 필수로 사용해야 합니다.
- @JoinColum
외래키를 매핑할 때 사용합니다.
즉, Team team 참조 변수를 외래 키인 TEAMID 로 매핑하는 것을 의미합니다.
name 속성을 통해 매핑할 외래키 이름을 지정 할 수 있습니다.
name 속성을 사용하지 않거나 @JoinColumn 을 생략시, 필드명 + _ + 참조하는 테이블의 칼럼명을 사용합니다.
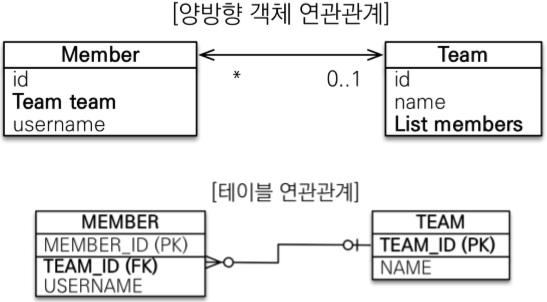
2. 다대일 양방향 연관관계 🖇️
양방향 연관관계에서도 단뱡향 연관관계와 같은 상황을 가정하겠습니다.
- 회원 엔티티와 팀 엔티티가 있습니다.
- 회원은 하나의 팀에만 소속됩니다.
- 따라서 팀과 회원은 다대일 관계입니다.
기존 단방향 연관관계에서는 회원 엔티티를 통해 팀 엔티티에 접근 할 수 있었지만
양방향 연관관계에서는 팀 엔티티 또한 자신에 속한 회원 엔티티 정보를 참조하고 있습니다.
단 팀 관점에서 해당 연관관계는 일대다 관계이기 때문에 팀 엔티티는 여러 회원 엔티티와 연관관계를 맺을 수 있습니다. 따라서 컬렉션의 형태로 참조합니다 ❗️
// 매핑한 회원 엔티티
@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
private String username;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
// 연관관계 설정
public void setTeam(Team team) {
this.team = team;
}
...
}
@Entity
public class Team {
@Id
@Column(name = "TEAM_ID")
private String id;
private String name;
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
}해당 코드를 설명해보겠습니다.
Member 엔티티는 단방향인 경우와 동일함으로, Team 엔티티 위주로 설명하겠습니다.
Team 엔티티는 Member 엔티티와 일대다 연관관계를 맺습니다.
따라서 @OneToMany 어노테이션을 통해 다중성을 나타냅니다. 여기서 눈에 띄는 부분은 해당 어노테이션 안에 존재하는 'mappedBy' 속성입니다.
mappedBy를 이해하기 위해서는 연관관계의 주인에 대한 이해가 필요합니다.
연관관계의 주인이란 을 참고 부탁드립니다 🧐
이렇게 양방향으로 연관관계를 맺으면 서로를 참조할 수 있게 됩니다 😎
3. 양방향 연관관계의 주의점 🖇️
양방향 연관관계를 설정하고 할 수 있는 실수에는 어떤 것이 있을까요?
바로 잘못된 위치에서 외래키 값을 변경하는 실수입니다 ⛔️
양방향에는 연관관계의 주인 엔티티와 연관관계의 주인이 아닌 엔티티가 존재하기 마련인데,
연관관계의 주인이 아닌 엔티티에서 값을 조작하면 외래키값이 정상적으로 처리되지 않음으로 개발자가 의도했던 로직과 다른 방향으로 결과가 나올 수 있습니다.
public void testSaveNonOwner() {
Member member1 = new Member("member1", "회원1");
em.persist(member1);
Member member2 = new Member("member2", "회원2");
em.persist(member2);
Team team1 = new Team("team1" ,"팀1");
team1.getMembers().add(member1);
team1.getMembers().add(member2);
// Team 엔티티는 연관관계의 주인이 아니다 -> only 읽기만 가능
// 그러나, 해당 코드에서는 저장하고 있음 -> 연관관계의 주인인 Member 에 반영 x
em.persist(team1);
}
JPA 가 아닌 순수 객체까지 고려 했을 때 양방향 연관관계시, 두 곳에서 전부 값을 저장하는 것이 안전합니다 ✅ 즉, Member 에 Team 을 지정 할 때, Team 에 Member 값도 지정하는 것이 로직 관점에서 보았을때, 훨씬 견고한 코드가 될 수 있습니다 ❗️
이처럼 양방향 연관관계는 반대방향으로 객체 그래프 탐색 기능이 추가된 것뿐 예상치 못한 버그가 발생할 가능성이 있습니다. 따라서 양방향 연관관계를 사용시, 견고한 로직 구현이 필요합니다 👍
참고
