백엔드 개발자로써 개발을 하다보면 많은 데이터를 DB 작업을 통해 다루게 됩니다.
DB 작업은 컴퓨터 내부에서 일어나는 모든 작업 중 상대적으로 오래걸리는 작업에 속합니다.
따라서 지속적인 DB 접근 및 연산은 부담이 되는 작업이며 수 맣은 DB 작업 호출이 있는 경우, 사용자가 불편을 느낄 정도로 오래걸리기도 합니다. 이때 우리는 좋은 해결 방안으로 캐싱(Caching) 을 고려해 볼 수 있습니다.
일단 캐싱에 대해서 알아봅시다.
사실 컴퓨터 공학자 및 개발을 하고 있는 누구라면 캐싱이라는 단어를 자주 접해봤을 것 입니다.
저는 대학교 3학년 시절 컴퓨터 구조 과목을 수강하면서 처음 듣게 되었는데요🤔 그 당시에 굉장히 어려운 개념으로 다가왔습니다. // 캐시 링크
저희가 사용하는 대표적인 프레임워크 스프링 부트에서는 캐싱 기법을 어떻게 쓸까요?
다행히도 그리고 너무 고맙게도 스프링부트에서는 기본 캐시 기능을 제공합니다.
간단히 설명하자면 스프링부트 어플리케이션 실행시, 해당 애플리케이션과 함께 자그마한 개시 공간을 같이 생성한다고 생각하면 됩니다. 여기서 자그마한 이라는 단어에 집중해야 합니다.
즉 많은 메모리를 제공하는 것이 아닌, 각 상황에서 유용하게 사용하기 위해 약간의 메모리만 할당한다는 것 입니다. 그렇다면 무턱대고 모든 관련된 데이터를 빠르게 사용하기 위해 다 캐시에 넣는 건 불가능 하겠죠?! 또한 캐시는 일반적인 휘발성(volatile) 특징을 가지는 메모리(RAM) 과 동일하게 해당 애플리케이션이 종료되면 자동적으로 캐시의 모든 데이터가 삭제 됩니다.
💡 정리
1. 스프링부트는 캐시 기능을 제공한다.
2. 많은 공간이 아닌 조그마한 메모리 공간을 할당한다.
3. 휘발성의 특징을 가진다.(분산 캐싱을 사용하면 애플리케이션이 종료되도 캐시에 남길 수 있음.)
자,그렇다면 지금 부터 어떻게(HOW) 스프링 부트의 캐싱 기능을 사용할 수 있는지 살펴봅시다!🔥
SpringBoot 기본 Cache 사용하기 위한 설정
Step 1. SpringBoot 종속성 추가하기
gradle
implementation 'org.springframework.boot:spring-boot-starter-cache'maven
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>Step 2. @EnableCaching 어노테이션 추가하기
step 1 에서 종속성을 성공적으로 추가 하였다면 해당 @EnableCaching 어노테이션 사용이 가능해집니다. 이는 SpringBoot 애플리케이션 부분에 붙여줘야 합니다. 성공적으로 추가하였다면
스프링부트에서의 캐싱 기능이 활성화 되었습니다.👏
package com.example.velog;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cache.annotation.EnableCaching;
@SpringBootApplication
@EnableCaching
public class VelogApplication {
public static void main(String[] args) {
SpringApplication.run(VelogApplication.class, args);
}
}Step 3. @Cachable 캐시 데이터 생성 및 활용
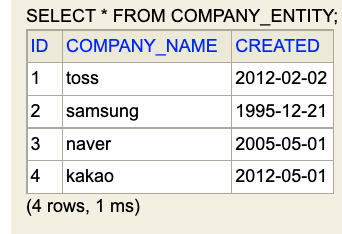
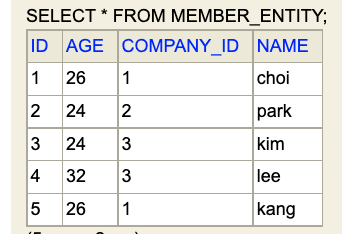
제가 작성한 두 개의 테이블을 H2 콘솔창에 찍어본 결과입니다.
하나는 Member 테이블이고 나머지 하나는 Company 테이블입니다. 각 테이블 성격에 맞는 적절한 칼럼 정보를 가지고 있군요.
여기서 문제 캐싱 기법을 무조건 사용하는 것이 좋을까요?
스프링 프레임워크는 스프링 부트와 함께 강력한 기능들을 제공합니다. 또한 하위 프레임 워크와 함께 개발자에게 편의를 제공하는 혁신적인 기능을 제공합니다.
하지만 임의의 기능이 무조건 현신적이라고 해서 아무 곳에나 사용을 남발하면 어떤 부분에서는 저희에게 스트레스를 주는 오류로 다가올 것입니다.
무슨 말 이냐? 사용하기 전에 해당 부분에 사용하는 것이 적절한지 확인해야 한다는 것입니다.
캐싱이 필요한 부분은 어디일까?
1. DB 조회가 활발한 부분
2. 업데이트가 자주 일어나지 않은 부분
// id에 해당하는 멤버 엔티티 가져오기
@Transactional(readOnly = true)
@Cacheable("member")
public MemberEntity get(Long id){
MemberEntity member = memberRepository.findById(id)
.orElseThrow(() -> new RuntimeException("해당하는 회원이 존재하지 않습니다."));
return member;
}앞에서 캐싱 기능 사용이 적절하다고 판단되었으면 해당 메소드 혹은 클래스 위에다가 @Cachable 어노테이션을 붙여줄 수 있습니다.
@Cacheable 어노테이션은 위와 같이 기본으로 텍스트 값을 넣어줘야하는데 그게 바로 캐시 데이터 저장 공간의 이름이 됩니다. 물론 value, key 파라미터로 명시를 해줄 수 있습니다. value는 캐시 데이터의 이름이 되고 key는 캐시 데이터의 키 값이 됩니다.
추후 캐시 데이터에서 key 를 기준으로 각 데이터를 구분하게 됩니다.👏
위와 같은 방법으로 해당 부분에 캐싱 기능을 사용하겠다고 설정을 하고 다시 조회하는 메소드를 호출 하면 가장 먼저 캐시 데이터를 조회하여 있으면 가져오고 없으면 그 때서야 비로서 DB 를 조회하게 됩니다. 이를 통해 상대적으로 멀리 있는 DB 로 가는 시간을 줄일 수 있게됩니다.
