
엑셀은 직장인들이 데이터를 다룰 때 자주 사용하는 프로그램입니다. 엑셀은 직관적인 UI와 사용의 편리성의 인해 오랫동안 사랑받아온 프로그램이지만 다양한 데이터 처리와 여러 파일을 다룰 때는 한계가 있습니다. 이때 파이썬의 대표적인 라이브러인 판다스(pandas)를 이용하면 쉽고 빠른 처리를 할 수 있습니다. 즉, 여러 개의 엑셀 파일을 불러와서 하나로 통합한다거나 불러온 데이터를 한꺼번에 처리할 때 판다스를 이용하면 편리합니다. 여기서는 판다스로 엑셀 파일을 다루는 기본적인 내용을 살펴보겠습니다. 여러 개발 환경이 있지만 여기서는 주피터 노트북(Jupyter Notebook)을 이용한다고 가정하겠습니다.
여기서는 판다스로 엑셀 파일을 읽고 쓰기는 방법과 여러 엑셀 파일 하나로 통합하는 방법에 대해 살펴보겠습니다.
판다스 DataFrame 데이터
DataFrame 데이터 구조
판다스를 이용하기 위해서는 우선 아래와 같이 판다스를 임포트해야 합니다.
import pandas as pd # 판다스 임포트그 후에는 판다스를 이용할 때 pd를 이용합니다.
다음 그림은 판다스 DataFrame 데이터의 구조를 보여줍니다.
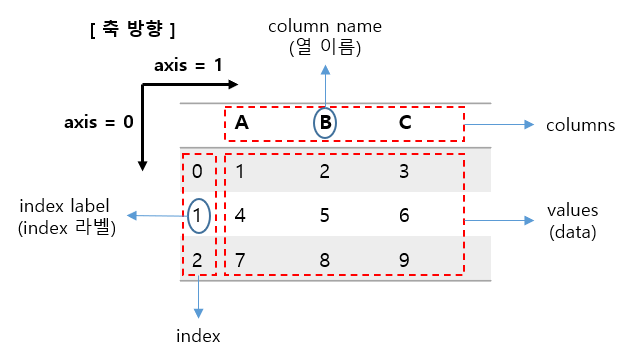
DataFrame 데이터 생성
다양한 방법으로 판다스 DataFrmae 데이터를 생성할 수 있지만 여기서는 리스트 데이터를 이용해 DataFrame 데이터를 생성하는 방법을 알아보겠습니다.
import pandas as pd # 판다스 임포트
data = [[1,2,3], [4,5,6], [7,8,9]] # 리스트 데이터
df = pd.DataFrame(data) # DataFrame 데이터
df주피터 노트북 코드 셀에 위와 같이 입력하고 수행하면 DataFrame 데이터가 표 형식으로 출력되는 것을 볼 수 있습니다.
판다스로 엑셀 파일 읽고 쓰기
엑셀 파일 읽기
엑셀의 워크시트에 있는 내용을 판다스의 DataFrame 형식으로 읽어오는 기본적인 방법은 다음과 같습니다.
import pandas as pd
df = pd.read_excel(excel_file)여기서 excel_file은 엑셀 파일의 경로로 폴더명과 파일명을 포함합니다.
위와 같이 수행한 후에 주피터 노트북 코드 셀에 아래와 같이 df를 수행하면 엑셀 워크시트의 내용을 DataFrame 형식으로 가져온 결과를 볼 수 있습니다.
df만약 출력되는 데이터가 너무 많다면 아래와 같이 df.head()나 df.tail()을 이용하면 됩니다.
df.head() # 처음 5개의 데이터를 보여 줌
df.tail() # 마지막 5개의 데이터를 보여줌엑셀 파일 쓰기
판다스 DataFrmame 데이터를 엑셀 파일의 워크시트로 출력하려면 다음과 같은 방법을 이용합니다.
df.to_excel(excel_file, index=False)위와 같이 수행하면 DataFrame 데이터 df의 내용을 지정한 경로의 엑셀 파일(excel_file)에 씁니다. 이때 index 옵션에 False를 지정하면 DataFrame 데이터에서 index를 제외하고 나머지를 표 형식으로 엑셀 워크시트에 씁니다.
DataFrame 데이터 처리
판다스의 DataFrame은 집계 및 연산을 위한 다양한 메서드를 제공합니다. 그 중 일부만 살펴보면 다음과 같습니다.
데이터 연산
판다스의 DataFrame 데이터 df1과 df2가 있을 때 다음과 같은 사칙 연산을 할 수 있습나다.
df1 + df2 # 데이터끼리 더히기
df1 - df2 # 데이터끼리 빼기
df1 * df2 # 데이터끼리 곱하기
df1 / df2 # 데이터끼리 나누기데이터 집계 및 통계
DataFrame은 데이터에서 행 데이터의 개수를 구하는 메서드는 다음과 같습니다.
df.count()DataFrame은 데이터에서 index 방향으로 평균을 구하는 메서드는 다음과 같습니다.
df.mean()DataFrame은 데이터에서 index 방향으로 표준 편차를 구하는 메서드는 다음과 같습니다.
df.std()판다스는 다음과 같이 데이터의 개수, 평균, 표준 편차, 최솟값, 최댓값 등 기본 통계량을 한꺼번에 구할 수 있는 메서드도 제공합니다.
df.describe()데이터 통합
DataFrame 데이터 통합을 위한 메서드로는 concat(), append(), join(), merge()등이 있습니다. 그 중에 세로 방향으로 연결하는 append()의 사용법을 살펴보겠습니다.
두 개의 DataFrame 데이터 df1, df2가 있을 때 이 둘을 세로 방향으로 통합하려면 다음과 같이 수행합니다.
df1.append(df2, ignore_index=True)위를 수행하면 두 개의 DataFrame 데이터 df1, df2를 하나로 통합한 DataFrame 데이터를 반환합니다. 여기서 ignore_index=True을 이용하면 연결할 데이터의 index를 무시하고 새로운 index를 생성합니다.
여러 엑셀 파일을 하나로 통합하기
다음 그림과 같이 여러 개의 엑셀 파일을 하나로 통합하는 일은 빈번하게 일어납니다.

일반적으로 엑셀을 이용해서 이러한 작업을 수행하겠지만 파이썬을 이용해서도 이러한 작업을 수행할 수 있습니다.
아래는 동영상 링크는 엑셀과 파이썬을 이용해서 여러 엑셀 파일을 하나로 통합하는 방법을 예를 들어 설명합니다.
엑셀 자동화 with 파이썬: 여러 개의 엑셀 파일을 하나로 통합하기
통합을 위한 코드
여러 엑셀 파일을 하나로 통합하는 코드는 다음과 같습니다.
import pandas as pd
from pathlib import Path
input_folder = 'C:/myPyExcel/data/ch07/sales_data/input' # 원본 데이터 폴더
raw_data_dir = Path(input_folder)
excel_files = raw_data_dir.glob('상반기_제품_판매량_*') # 폴더 내 데이터 파일 이름
total_df = pd.DataFrame() # 빈 DataFrame 생성
for excel_file in excel_files:
# 각 엑셀 파일의 데이터 가져오기
df = pd.read_excel(excel_file)
# 세로 방향으로 연결하기. 순차적으로 index 증가
total_df = total_df.append(df, ignore_index= True)
# 생성할 통합 엑셀 파일 경로 지정
folder = 'C:/myPyExcel/data/ch07/sales_data/'
merged_excel_file = folder + '상반기_제품_판매량_통합.xlsx'
# DataFrame 데이터(total_df)를 생성한 엑셀 객체에 쓰기(옵션 지정)
total_df.to_excel(merged_excel_file, # 엑셀 파일 이름
sheet_name='상반기_제품_판매량_통합', # 시트 이름 지정
index=False) # DataFrame 데이터 index는 출력 안함
print("생성 파일:", merged_excel_file) # 생성한 엑셀 파일 경로엑셀과 파이썬을 이용했을 때 수행 시간 비교
다음의 표는 엑셀과 파이썬을 이용해 여러 파일을 통합하는 작업을 수행했을 때 수행 시간을 비교한 것입니다. 수행하는 사람과 컴퓨터의 성능에 따라서 수행 시간은 차이가 나겠지만, 통합해야 할 파일의 개수가 증가할수록 엑셀로 통합하는 것보다 파이썬을 이용하는 것이 비교할 수 없을 만큼 빠릅니다.
| 엑셀 파일 개수 | 엑셀로 통합 | 파이썬으로 통합 |
|---|---|---|
| 3개 | 38.67초 | 0.13초 |
| 10개 | 1분 52초 | 0.37초 |
| 100개 | 17분 39초 | 1.43초 |
| 300개 | 52분 43초 | 3.98초 |
(엑셀로 통합하 때는 엑셀 파일을 여는 시간 포함)
정리
지금까지 판다스의 기본 내용과 엑셀 파일을 읽고 쓰는 방법에 대해 살펴봤습니다. 또한 여러 엑셀 파일을 하나로 통합하는 예도 살펴봤습니다.
파이썬으로 엑셀 데이터 처리를 자동화하는 방법에 대해 좀 더 자세히 알고 싶다면 아래의 책을 참고하세요.
-
일 잘하는 직장인을 위한 엑셀 자동화 with 파이썬
(출판사: 위키북스, 책 홈페이지)
