2021/08/27
주간 정리
P-Stage level-1 Image Classification
p-stage에서는 competition에 참여하여 주어진 문제를 해결하면서 내용 학습 및 실습을 진행함
주간 학습
학습내용
- 주어진 데이터셋을 사용할 수 있는 custom dataset 정의
- 데이터셋에 적용할 수 있는 전처리 종류 학습 및 적용
torch에서 제공하는transforms을 사용해 여러가지 전처리 적용
albumentation라이브러리 사용 - Custom Model 설계 및 pre-trained Model 적용 방법
pre-trained Model을 사용하는 여러가지 기법(feature extractor, fine-tuning) 학습
- Model Training 및 평가데이터 Inference
- Ensemble 기법
Competition
문제정의
- 코로나 바이러스 확산을 막고자 마스크 착용 여부를 판별하는 모델을 적용한 시스템을 공공기간에 정의
- 이미지 데이터: 18,900장 (정상 착용: 13500, 미착용: 2700, 비정상 착용: 2700)
- 데이터 속성: 나이, 성별, 인종, 이미지 경로
- 목표시스템: 총 18가지 classes (나이(3) * 성별(2) * 마스크착용상태(3)) 분류
DEA
- 특정 클래스의 데이터가 다른 클래스보다 많이 적은 경우가 있음(클래스 불균형 문제)
- 이미지 데이터 라벨링이 잘못된 경우가 있음
- 60대 이상으로 라벨링된 데이터를 확인해보니 정확히 60세인 데이터밖에 없음 (confusion 발생)
문제해결 방안
클래스 불균형 문제로 발생할 수 있는 현상을 확인하고자 각 도메인 별 모델(나이, 성별, 마스크상태를 예측하는 각각의 모델)을 만들어 confusion matrix 생성
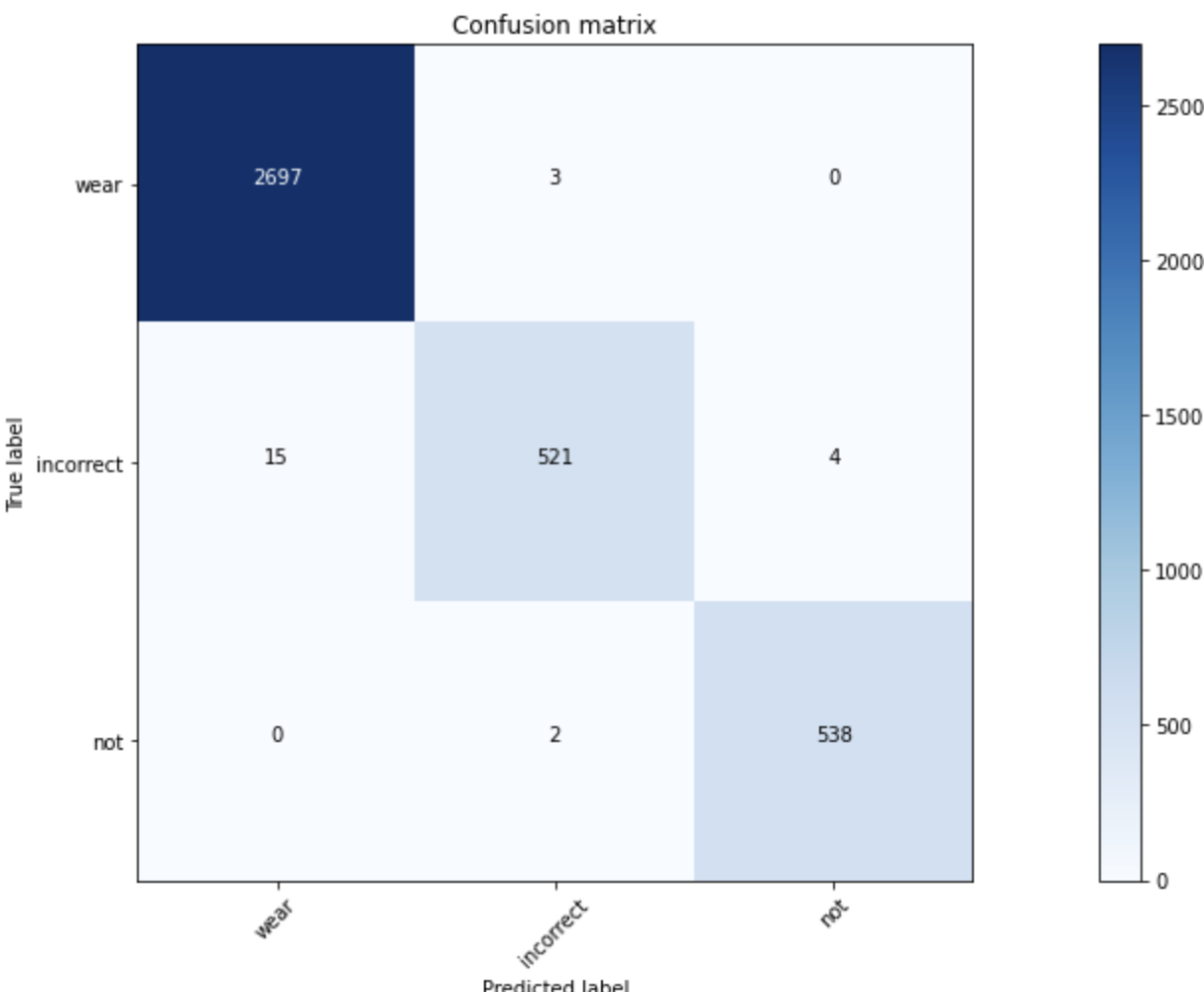
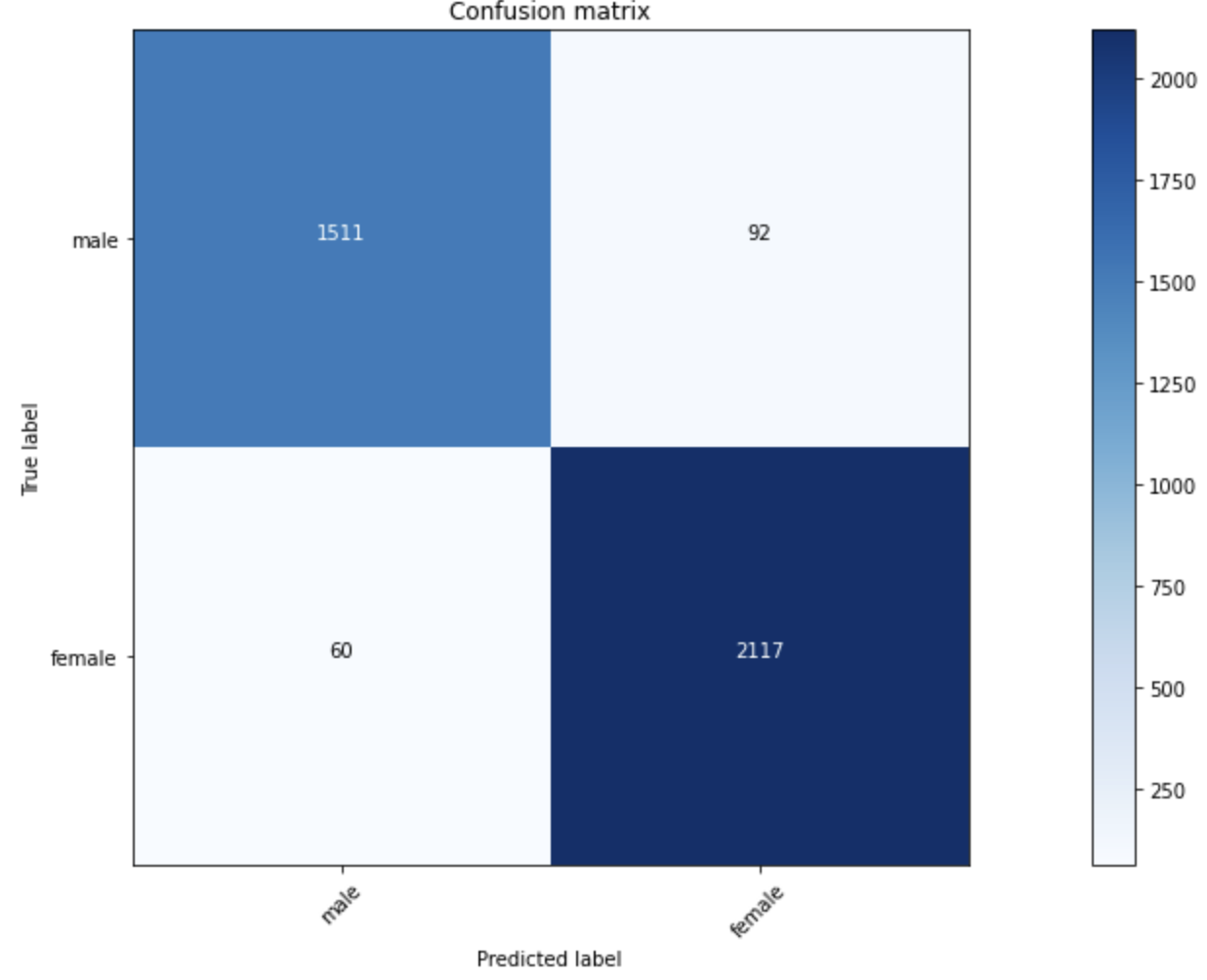
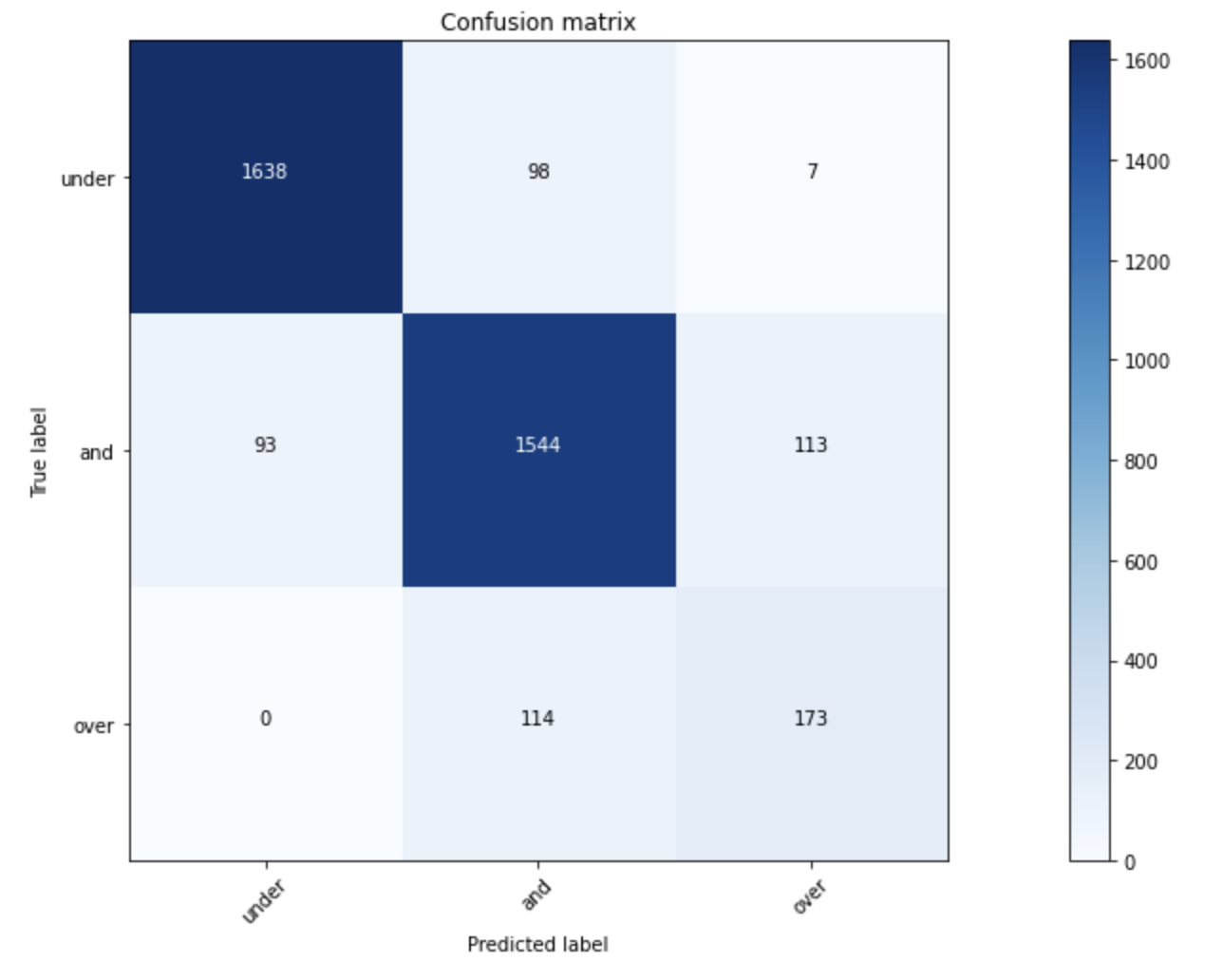
마스크 상태, 성별은 불균형 문제가 있음에도 성능이 좋았으나 나이를 예측하는 모델은 이상적인 matrix가 아니었음(f1 score가 낮음)
불균형 문제 해결법으로 접근해서 Label Smoothing 기법과 Focal Loss 사용 => Focal Loss를 적용했을때 성능 향상이 있었음
데이터가 부족한 특정 클래스 이미지를 복제하여 transform을 적용(부족한 데이터 증가) => train acc는 높아졌지만 test acc는 아니었음 (overfitting)
To Do
Over sampling,Under sampling을 적용해 불균형 문제를 해결 시도SMOTE는 Over sampling 기법 중 하나로 부족한 데이터의 분포를 sampling 하여 복제하는 기법 (이미지 데이터에 적합하지 않을 수 있음)- bias를 제거할 수 있는 augmentation 적용
- 외부 데이터셋을 찾아보고 task에 적절하다고 판단되면 학습데이터로 사용
회고
무조건 좋은 성능을 내기 위해 pre-trained model을 무분별하게 여러개 사용하였으나 결과는 좋지 못했다. => 어떤 문제가 발생했는지, 왜 성능이 안나오는지 생각할 필요가 있다.
근거있는 실험을 위해서 DEA가 정말 중요하다는 것을 느꼈다.
정확한 성능 평가를 위해서 환경 구성을 잘 해야한다는것을 배웠다. (ex. random seed)
팀원들과 함께 회의를 통해서 서로 좋았던 방법을 공유하면서 많은것을 배울 수 있었다.
피어세션
1주차는 개인 단위로 competition에 참여하는 시간이었다. 피어세션에서 서로 배운 내용을 공유했을때 굉장히 많은 공부가 되었다. 2주차부터는 팀 단위로 참여하는데 주말동안 준비가 필요할 것 같다. 본격적으로 협업을 하는 단계라서 기대가 많이 된다.
학습회고
이번주 가장 기억에 남는 시간은 멘토링 시간이었다. 얼마나 내가 무식하게 실험하고 있었는지 알 수 있었고 다양한 접근법을 배울 수 있었다. 멘토링 시간 이후로는 단 한번도 제출 하지 않았다. 모델링 과정에서 발생할 수 있는 다양한 문제를 배웠고 모델을 여러번 만든다고 해결할 수 있는 문제가 아니라는 것을 깨달았다. 매일 밤을 새서 이번 주 TIL을 쓸 시간도 없었다. 결과물은 없지만 많이 배울 수 있었고 반성도 할 수 있었다.
