Computer Vision 주요 논문 읽기 도전을 하고 있습니다. 첫번째 논문은 Deep Residual Learning for Image Recognition (CVPR 2016) 입니다.
핵심 아이디어인 잔여 학습에 대해 이해하고 구현을 통해 실제 ResNet을 어떻게 사용하는지 알아보려고 합니다. 소개할 논문의 내용은 개인적인 이해와 해석으로 완벽한 내용은 아닐 수 있습니다.
Problem statement
"Deeper neural networks are more difficult to train."
더 깊은 convolutional neural networks는 이미지 분류 분야에서 해결책을 제시해주었습니다. 네트워크가 깊어질수록 더 풍부한 feature를 표현하였고, 최근 여러 논문을 통해 깊은 네트워크가 성능이 더 좋은것을 증명해주고 있습니다. 그렇다면 더 좋은 네트워크는 더 많은 layer를 쌓으면 되지 않을까 생각할 수 있습니다. 하지만 20개의 layer, 56개의 layer 각각 모델을 실험한 결과 오히려 56개의 layer를 쌓은 모델이 training error가 더 높았습니다. 이는 학습하는데 어려움이 있다는 것입니다.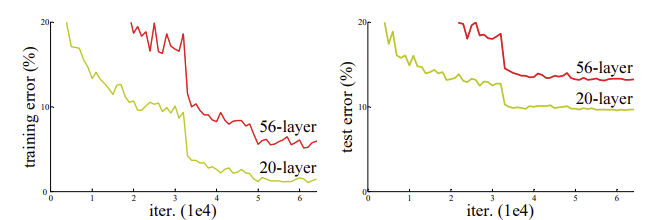
오래전부터 layer만 깊어지는 것은 다른 문제를 야기한다고 알려져 왔습니다. 대표적으로 gradient vanishing 문제, overfiting 문제입니다. 사실 overfiting은 test error가 높아지는 것을 의미하는 것이기 때문에 그래프에서 정확한 원인은 아니지만 overfiting 문제는 전통적으로 layer가 깊어짐에 따라 발생하는 것으로 알려져 있습니다. gradient vanishing 문제는 layer가 깊어지면 반복적으로 sigmoid 같은 activation 함수가 반복적으로 적용되어 발생할 수 있는 문제입니다.
결론적으로 training error에 대한 degradation 문제는 학습이 잘 되는 것이 아닌, 최적화가 잘 이루어지지 않는 문제입니다.
Key idea
ResNet의 핵심 아이디어는 residual block을 이용해 네트워크의 최적화 난이도를 낮추는것 입니다.

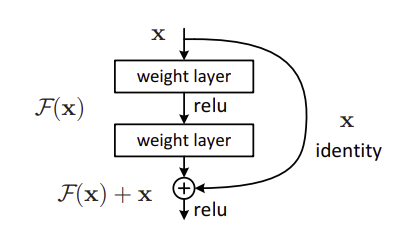
degradation problem을 해결하기 위해 제시한 deep residual learning framework 에서는 원래 의도했던 mapping이 아닌 residual mapping에 적합하도록 명시하여 학습 난이도를 낮출수 있다고 소개하고 있습니다.
일반적으로 데이터(x)가 input으로 들어왔을 때 두개의 weight layer를 거쳐 나오는 것이 H(x)라 할때 단순히 이전 layer를 거쳐 나온 결과인 x를 더해주어 H(x) + x가 되도록 하는 것입니다. H(x)를 F(x)라 하면 F(x)는 잔여 정보, x는 앞서 학습된 정보가 됩니다. 추가 정보 F(x)만 학습되도록 한다는 의미입니다.
이전 정보 x를 더해주는 것으로 추가적인 parameter 필요 없고 구현하기도 쉽다는 장점이 있습니다.
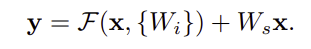
또한, 논문에서 표현하는 F(x)는 위 수식과 같이 layer가 여러개 존재할 수 있다고 말합니다. 하지만 1개의 layer만 존재 했을때는 일반적인 linear 모델과 같아지기 때문에 이점은 없습니다.
Implementation

비교를 위한 Plain Network는 (i)VGG처럼 3x3 filter를 사용하고 output feature map size를 같도록 하기 위해 같은 개수의 filter를 사용합니다. (2) 그리고 feature map의 size가 절반으로 줄어들면 filter의 개수를 2배로 늘려 layer마다 time complexity를 보존합니다.
별도의 pooling layer를 사용하지 않고 stride 값을 2로 해서 downsampling을 하고 layer 마지막 부분에서 average pooling을 사용합니다.
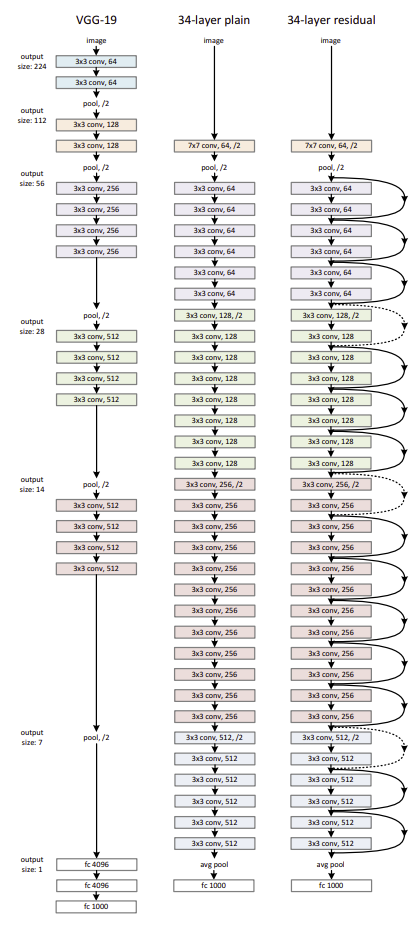
Residual Network는 그림 처럼 실선으로된 shortcut connection을 삽입해 residual block을 구현하였고 같은 색상의 layer들이 하나의 block으로 동작합니다 block이 바뀔때 각 block의 첫번째 layer는 점선으로 shortcut connection이 표현되어 있는데 이는 입력단과 출력단의 dimension이 달라 맞춰주는것을 표현한것 입니다. 같은 색상인 block 내부에서는 입력과 출력의 output feature가 같은 것을 확인할 수 있습니다. 마지막 layer는 똑같이 average pooling을 사용합니다.
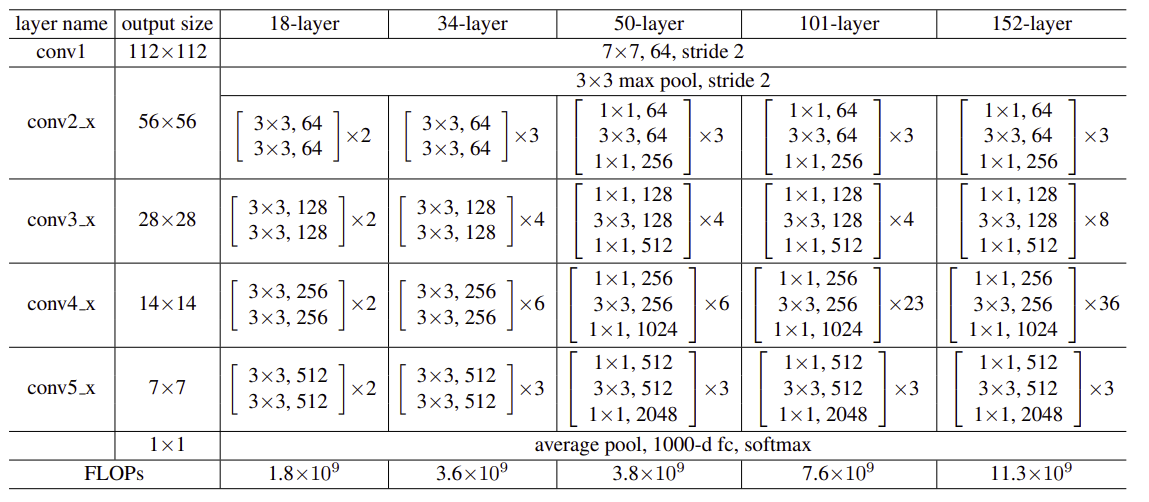
구현할 ResNet-18을 예로 들면 각 block은 2개의 layer로 구성되어 있고 block이 2번씩 반복되는 형태입니다. block 내부 layer의 입력과 출력은 같고 block이 2번 반복되면 output size가 증가합니다.
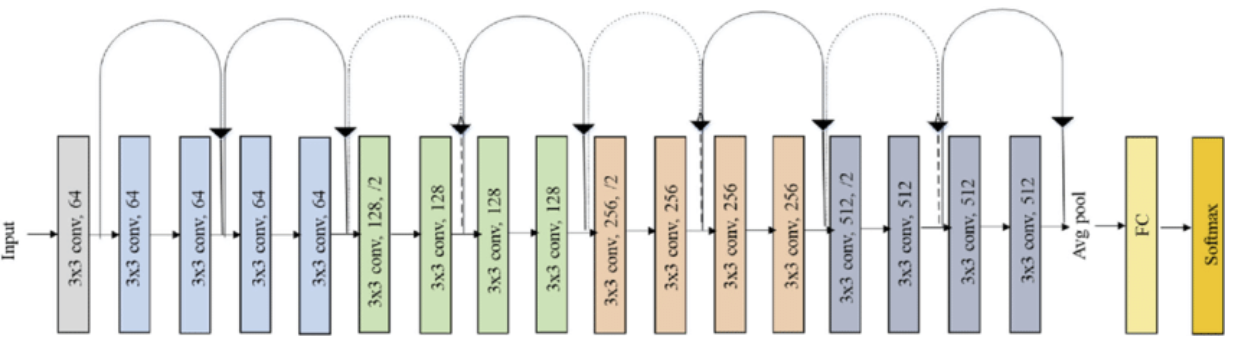
구현할 실제 ResNet-18은 위와 같은 구조로 되어 있습니다. 입력과 출력이 같은 layer 2개가 1개의 block으로 구성되어 있고 2번씩 반복되고 있습니다. 최종 output의 크기는 512입니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
%matplotlib inline
%config InlineBackend.figure_format='retina'
print("PyTorch version:[%s]"%(torch.__version__))
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print("device:[%s]" %(device))학습에 필요한 모듈을 import 합니다.
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
])
test_transform = transforms.Compose([
transforms.ToTensor()
])
cifar_train = datasets.CIFAR10(root='../dataset/CIFAR_10', train=True, transform=train_transform, download=False)
cifar_test = datasets.CIFAR10(root='../dataset/CIFAR_10', train=False, transform=test_transform, download=False)
BATCH_SIZE = 256
train_iter = torch.utils.data.DataLoader(cifar_train, batch_size=BATCH_SIZE, shuffle=True, num_workers=1)
test_iter = torch.utils.data.DataLoader(cifar_test, batch_size=BATCH_SIZE, shuffle=True, num_workers=1)논문에서 제시한것 처럼 32x32 크기로 crop하고 RandomHorizontalFlip()함수를 사용해 augmentation를 적용하였습니다. 사용할 데이터셋은 CIFAR-10입니다. batch size는 256입니다.
class BlockClass(nn.Module):
"""
define 'block' used in ResNet-18 or -34
There is 3-size kernel(3x3 filter)
if stride is not '1', not identity mapping.
"""
def __init__(self, in_planes, planes, stride):
super(BlockClass, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes)
)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = F.relu(out)
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out2개의 layer가 구성할 block 입니다. ResNetClass에서 block을 구성할 때 사용하는 class입니다. conv1에서는 stride에 따라서 output의 크기가 변경될 수 있지만 그 다음 layer에서는 input과 output이 동일합니다. shorcut은 핵심 아이디어로 출력 결과에 이전 x를 더해줄 수 있도록 합니다. 만약 stride가 1이 아니라면 새로운 block의 시작점으로 입력값과 출력값의 dimension이 다른 것입니다. 크기를 절반으로 줄여 dimension을 맞춰줍니다.
forward함수에서 입력값x로 두번의 convolution, batch normalization을 통과하고 나온 결과에 shortcut(x)를 더해주고 최종적으로 relu 함수를 적용합니다.
class ResNetClass(nn.Module):
def __init__(self, block, num_blocks, block_outs, ydim=10):
super(ResNetClass, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self.make_layer(block, block_outs[0], num_blocks[0], stride=1)
self.layer2 = self.make_layer(block, block_outs[1], num_blocks[1], stride=2)
self.layer3 = self.make_layer(block, block_outs[2], num_blocks[2], stride=2)
self.layer4 = self.make_layer(block, block_outs[3], num_blocks[3], stride=2)
self.linear = nn.Linear(512, ydim)
def make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks -1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def ResNet18():
return ResNetClass(BlockClass, [2, 2, 2, 2], [64, 128, 256, 512])
def ResNet34():
return ResNetClass(BlockClass, [3, 4, 6, 3], [64, 128, 256, 512])
conv1은 3개의 채널을 가진 이미지 데이터를 3x3 filter로 스캔하여 64개의 feature map을 생성합니다. bn1은 Batch Normalization을 적용합니다 layer1 ~ layer4는 ResNet-18 과 같은 구조를 구성하는 layer들 입니다. layer를 생성할때 make_layer함수를 사용하였으며 block_outs은 각 2개의 block들의 출력 dimension을 의미하고 num_blocks는 block의 개수 입니다. ResNet-18은 block이 2, 2, 2, 2 개로 이루어져 있고 ResNet-34는 3, 4, 6, 3 개로 이루어져 있습니다. 함수ResNet18(), ResNet34()로 필요한 ResNet Model을 생성할 수 있습니다. 최종적으로 layer1 ~ layer4는 각각 2개의 block씩 4개의 layer로 구성되 총 16개의 layer로 구성될 수 있습니다.
make_layer함수는 block들을 구성해주는 함수이고 처음 크기가 변경되는 layer만 stride를 2로 만들어 크기를 줄여줍니다.
res18 = ResNet18()
res18 = res18.to(device)
loss = nn.CrossEntropyLoss()
optm = optim.SGD(res18.parameters(), lr=1e-3, momentum=0.9, weight_decay=0.0002)논문에서 사용한 loss function과 optimizer를 정의합니다. SGD의 momentum과 weight_decay도 정의합니다.
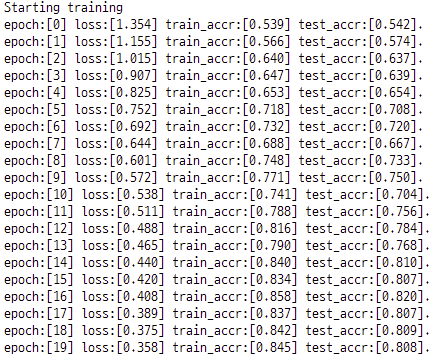
학습 결과입니다. epoch는 총 20으로 설정하였고 학습이 진행됨에 따라 loss가 줄어들고 train, test accuracy가 증가하는것을 확인할 수 있었습니다.
Reference
https://arxiv.org/abs/1512.03385 (Deep Residual Learning for Image Recognition, CVPR 2016)
https://www.youtube.com/watch?v=671BsKl8d0E,
https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice/blob/master/code_practices/ResNet18_CIFAR10_Basic_Training.ipynb
(나동빈 - ResNet: Deep residual Learning for Image Recongnintion)
https://www.researchgate.net/figure/Original-ResNet-18-Architecture_fig1_336642248 (ResNet-18 Architecture)
