
🖥️ Background
- Instructions should be in physical memory to be executed
➔ In order to execute a program, should we load entire program in memory? → 필요한 부분만 - Some parts are rarely used
- Error handling codes
- Arrays/lists larger than necessary
- Rarely used routines
- Alternative
- Executing program which is only partially in memory
- If we can run a program by loading in parts ...
- A program is not constrained by the amount of physical memory
- More program can run at the same time
- Less I/O is need to load or swap programs
Virtual Memory
- Virtual memory: a separation of logical memory from physical memory
→ paging + swapping(Disk)- Contents not currently reside in main memory can be addressed
➔ H/W and OS will load the required memory from auxiliary storage automatically - User programs can reference more memory than actually exists
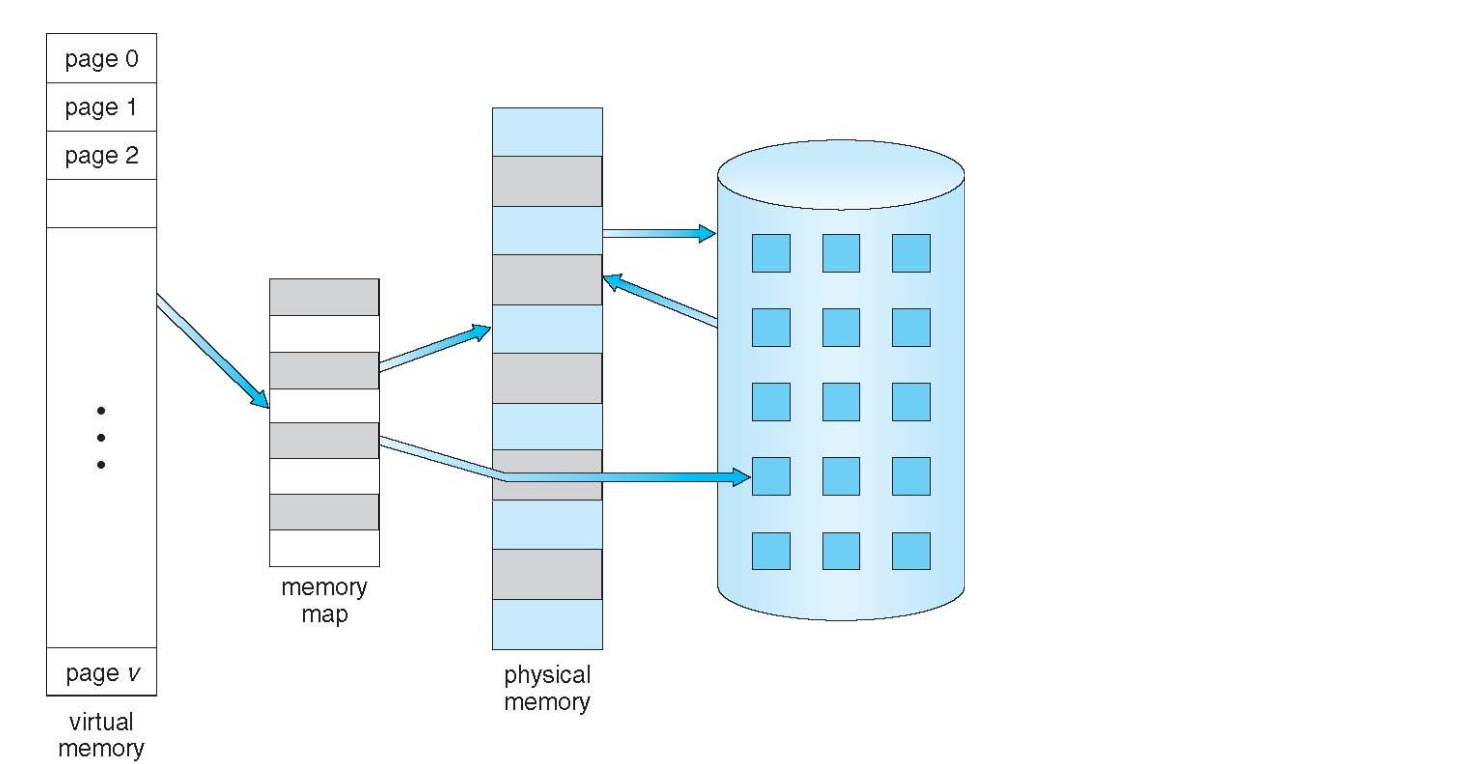
- Only part of the program(일부만 load → 단위 : page) needs to be in memory for execution
- Logical address space can be much larger than physical address space → Swapping (Disk)
- Allows address spaces to be shared by several processes → paging sharing
- Allows for more efficient process creation (e.g. COW)
- More programs running concurrently
→ program size가 줄어서 더 많은 program 가능 - Less I/O needed to load or swap processes
→ I/O overhead ⬇️, 전체 swapping이 아닌 page(4K ~ 4M)
- Contents not currently reside in main memory can be addressed
Virtual Address Space
- Virtual address space: logical view of how process is stored in memory
- Usually start at address 0, contiguous addresses until end of space.
- Meanwhile, physical memory organized in page frames
- MMU must map logical to physical
- Programmers don’t have to concern about memory management
- Virtual address space can be sparse
Implementation Techniques
- Demand paging
- Paging + swapping
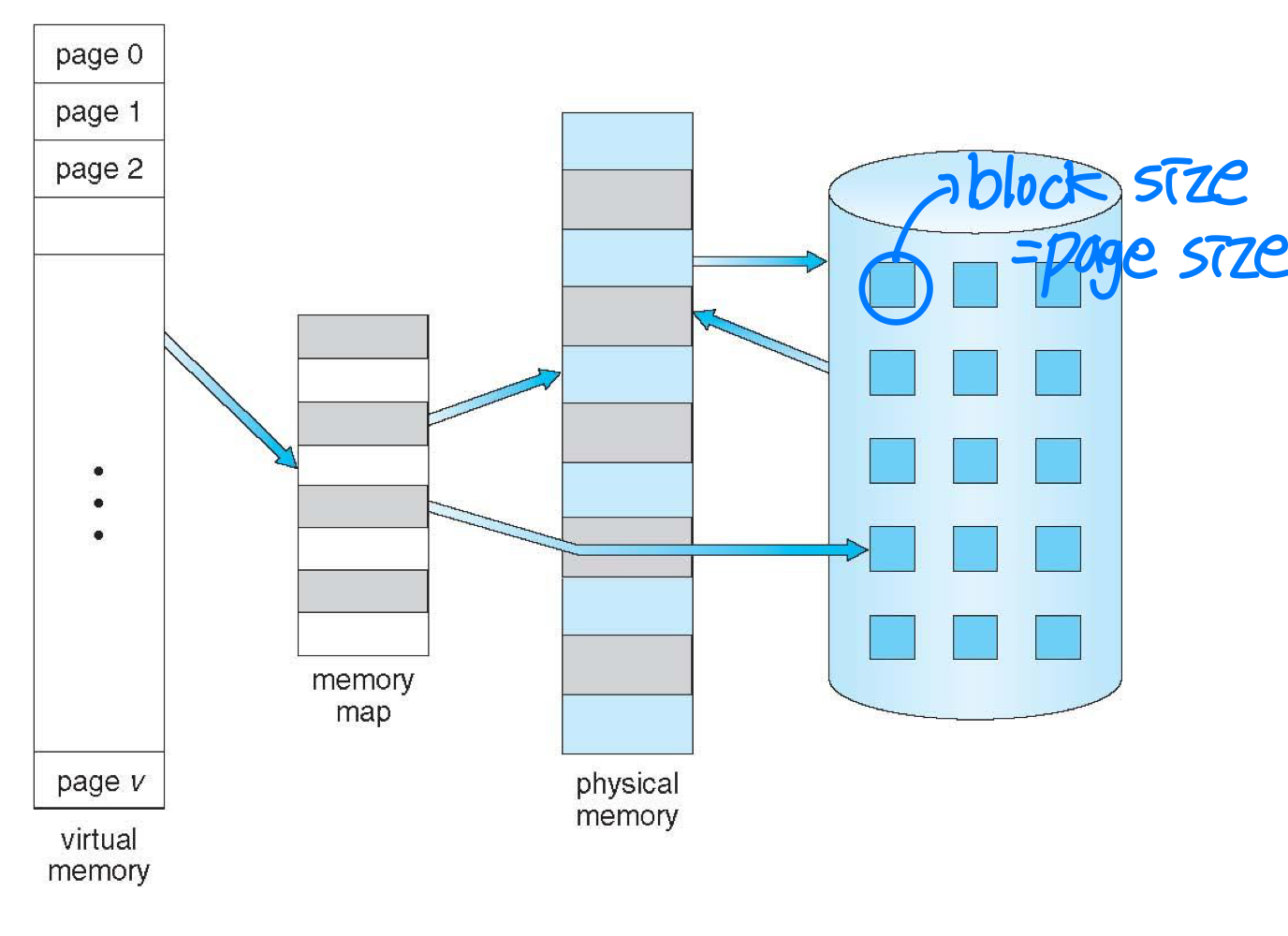
- Paging + swapping
🖥️ Demand paging
- Similar to paging system with swapping
- Lazy swapper(꼭 옮겨야 하는것만 swapping) (or pager)
- Pages are only loaded when they are demanded during execution
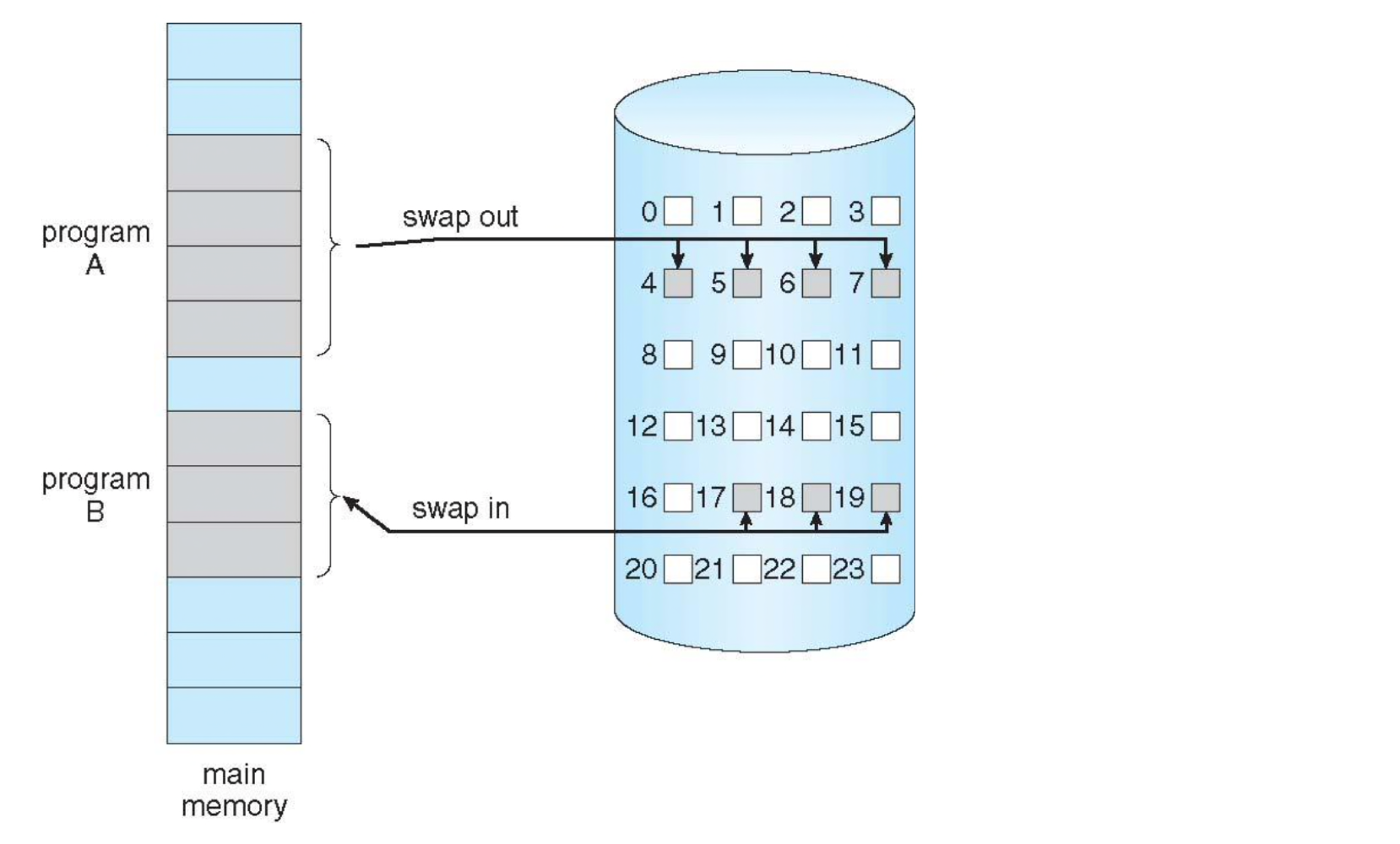
- Pages are only loaded when they are demanded during execution
- Pages are loaded only when they are demanded during program execution
- Requires H/W support to distinguish the page on memory or on disk
- Requires H/W support to distinguish the page on memory or on disk
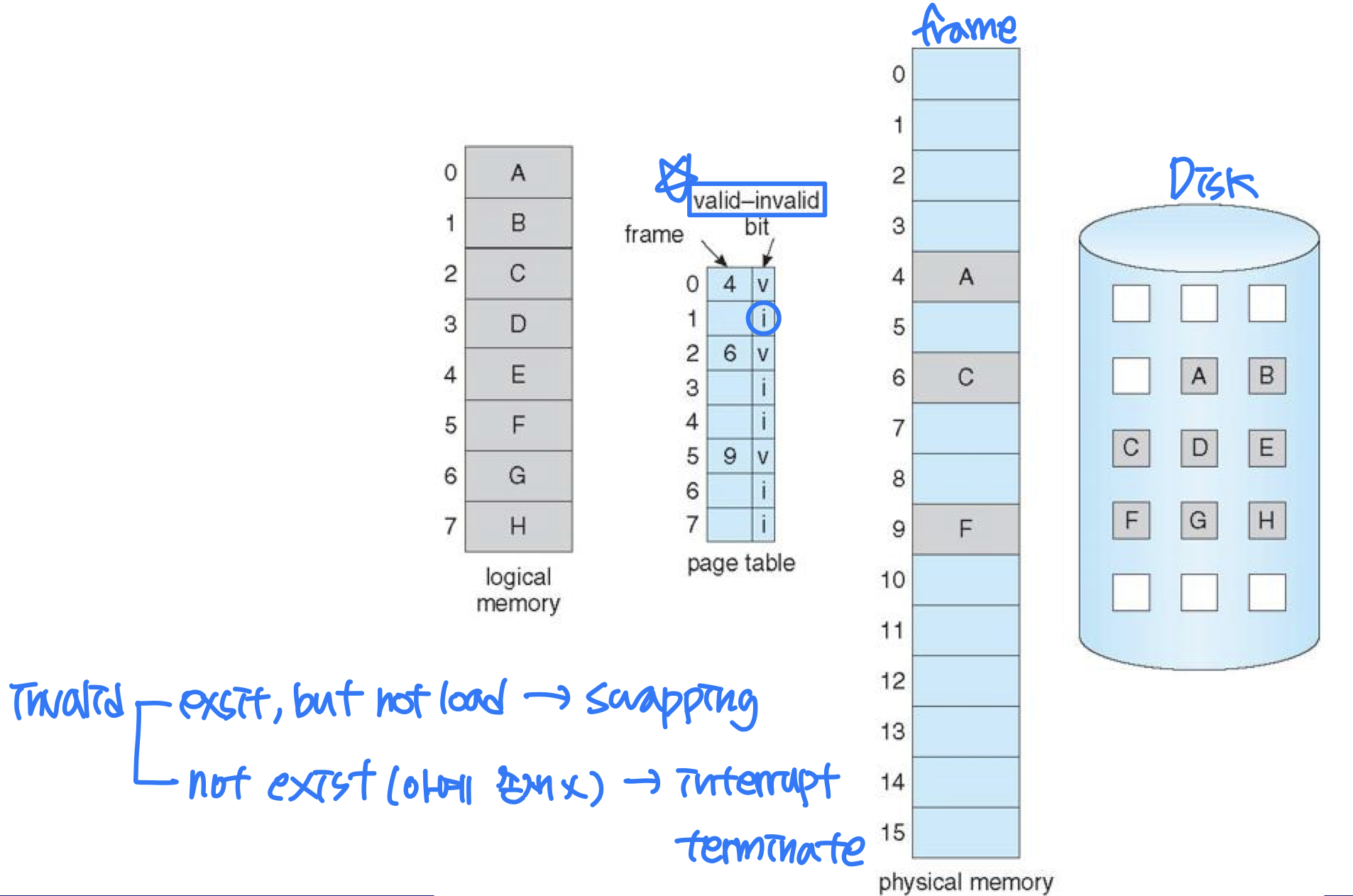
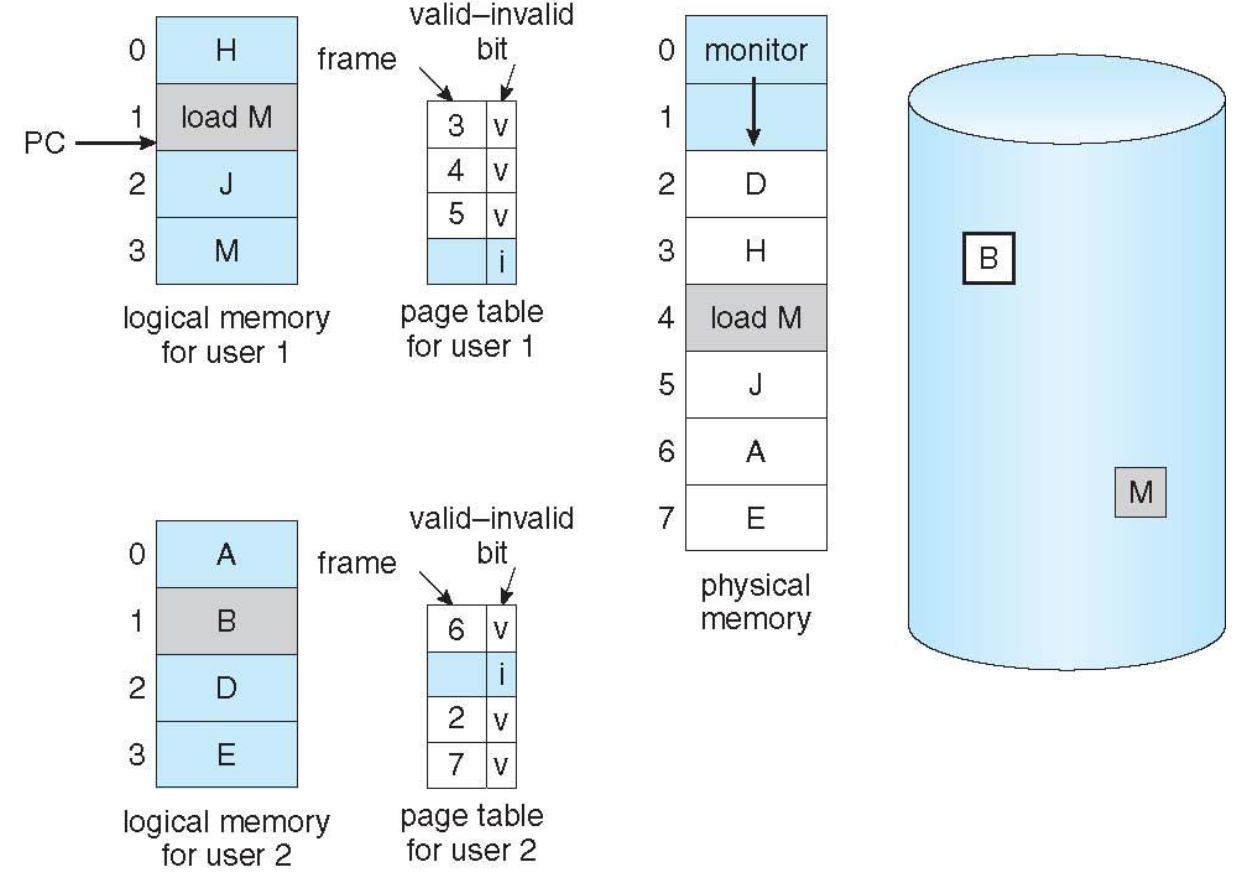
Page Table with Valid/Invalid Bit
- Valid/invalid bit of each page
- Valid: the page is valid and exists in physical memory
- Invalid: the page is not valid (not in the valid logical address space of the process (not exist) or (exist, but) not loaded in physical memory
- If program tries to access ..
- Valid page: execution proceeds normally
- Invalid page: cause ⭐️ page-fault trap to OS → interrupt (H/W support)
Basic Concepts
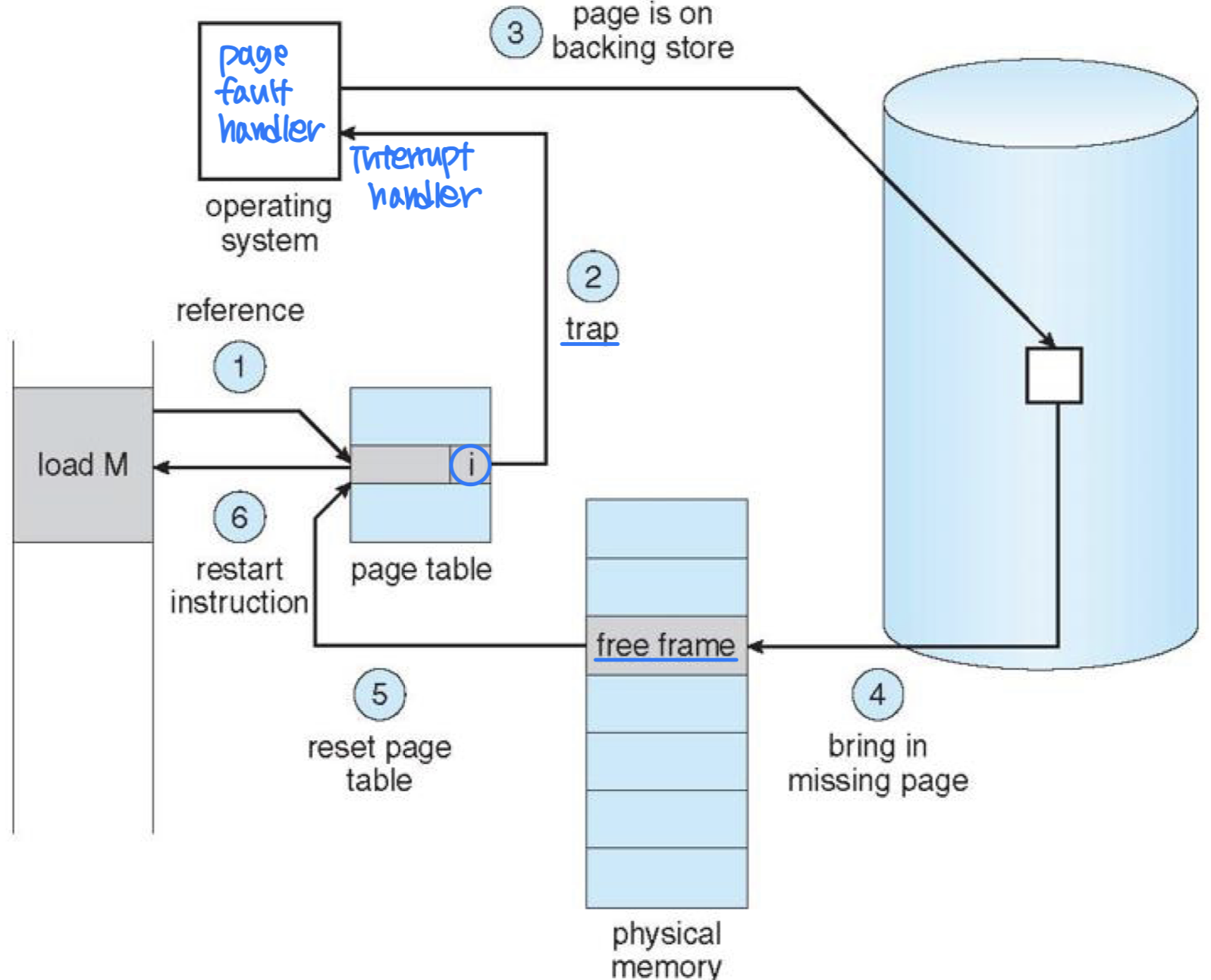
- Handling page-fault
- Check an internal table to determine whether the reference was valid or not
- If the reference was invalid(not exist), terminates the process
- If valid, page it in (not loaded)
- Find a free frame
- Read desired page into the free frame (load)
- Modify internal(page) table
- Restart the instruction that caused the page-fault trap
- In pure demand paging, a page is not brought into memory until it is required
- Performance degradation
- Theoretically(이론적으로), some program can cause multiple page faults per instructions
- But actually, this behavior is exceedingly unlikely
- locality of references
- H/W supports for demand paging
- Page table (support for valid-invalid bit, ...) → page fault handler
- Secondary memory (swap space) → Disk
- Instruction restart
Performance of Demand Paging
- Effective access time
= (1 - p)*ma + p * < page fault time >- ma : memory access time (10~200 nano sec.)
- p : probability of page fault
- Page fault time
- Service page-fault interrupt → 1~100 sec
- Read in the page → about 8 msecs
- Restart the process → 1~100 sec
- Example
- Memory access time: 200 nano sec
- Page-fault service time: 8 milliseconds
- Then...
- Effective access time (in nano sec.)
= (1-p) 200 + 8,000,000 p
200 + 7,999,800 * p- Proportional to page fault rate
Ex) p == 1/1000, effective access time = 8.2 sec (40 times) → 200 nano sec * 40
- Proportional to page fault rate
- Page fault rate should be kept low (작게 유지)
- Effective access time (in nano sec.)
Execution of Program in File System
- Ways to execute a program in file system
- Option1: copy entire file into swap space(overhead) at starting time
- Usually swap space is faster than file system
- ✅ Option2: initially, demand pages from files system and all subsequent paging can be done from swap space
- Only needed pages are read from file system
- Option1: copy entire file into swap space(overhead) at starting time
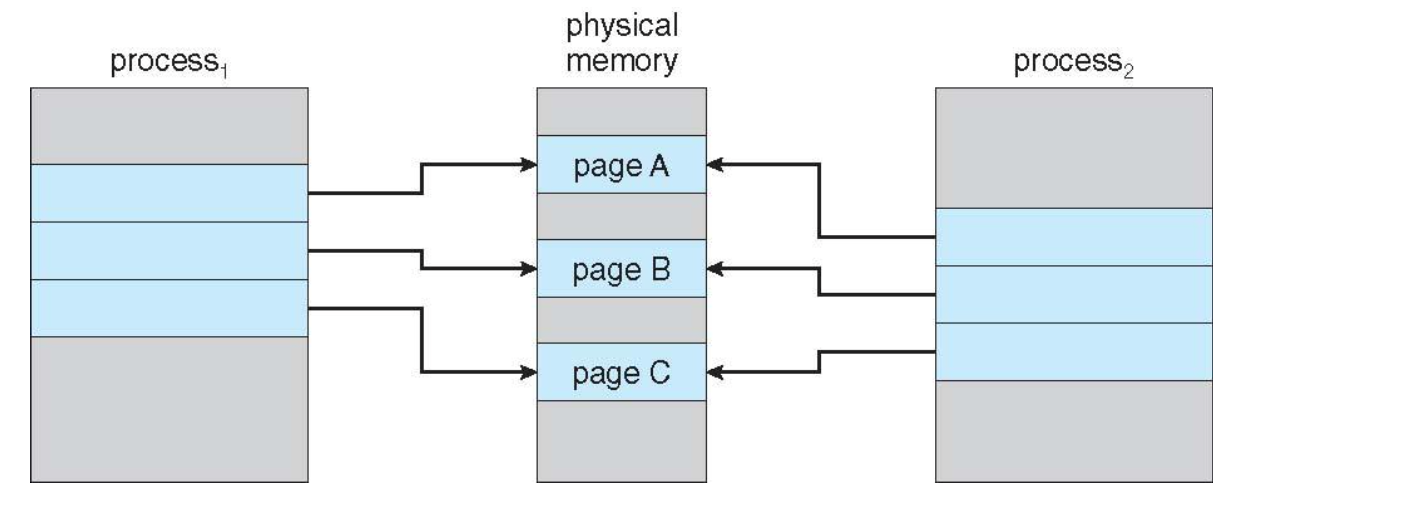
🖥️ Copy-on-Write (COW)
- fork() copies process
- Duplicates pages belong to the parent
- Copy-on-write (COW)
- When the process is created, pages are not actually duplicated but just shared
- Process creation time is reduced
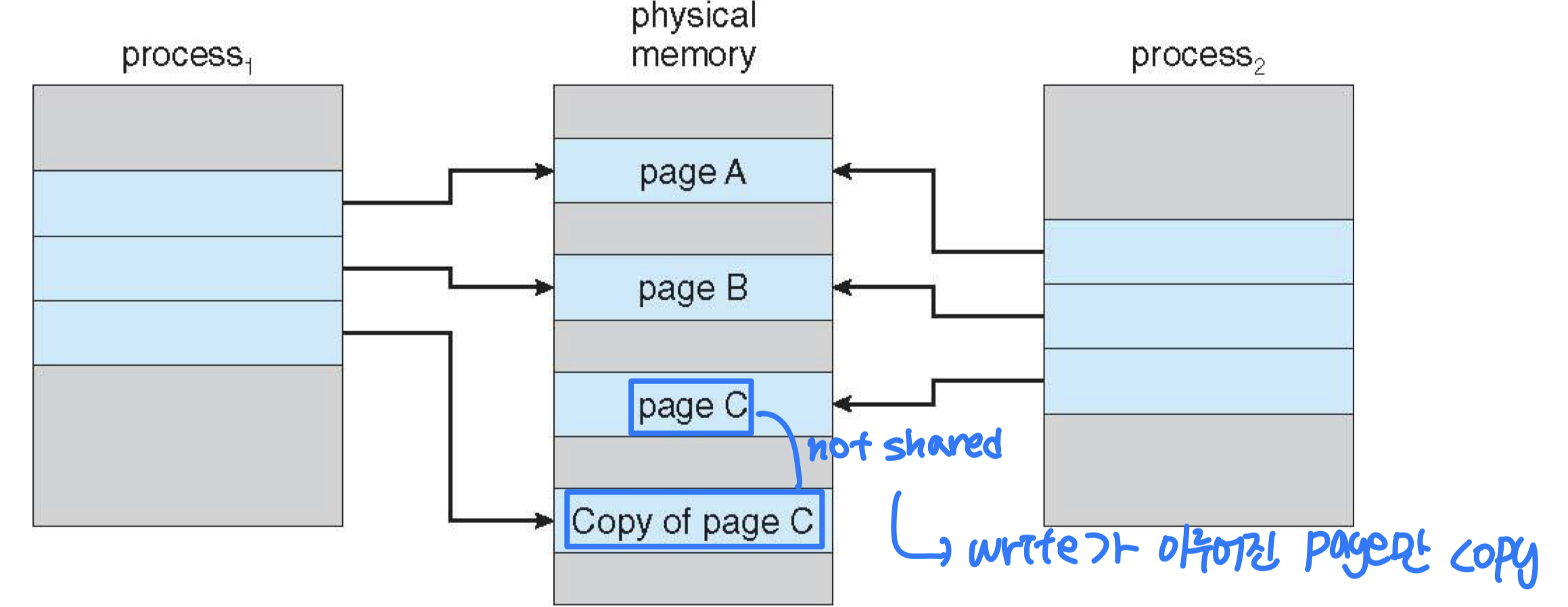
- When either process writes to a shared page, a copy of the page is created
cf. vfork() – logically(논리적으로 sharing) shares memory with parent (obsolete) → using X
- When the process is created, pages are not actually duplicated but just shared
- Many OS’s provides a list of free frames for COW or stack/heap that can be expanded
➔ Zero-fill-on-demand (ZFOD) → free frame으로 선언된 frame 내용도 최대한 끝까지 유지해서 Disk access를 줄이는 테크닉 ( zero-fill = remove )- Zero-out pages before being assigned to a process
- Before P1 modifies page C!
- After P1 modifies page C
- Two major problems in demand paging
- Page-replacement algorithm
- Frame-allocation algorithms
- Even slight improvement can yield large gain in performance.
- Effective access time = (1-p) * ma + p * < page fault time >
🖥️ Page replacement
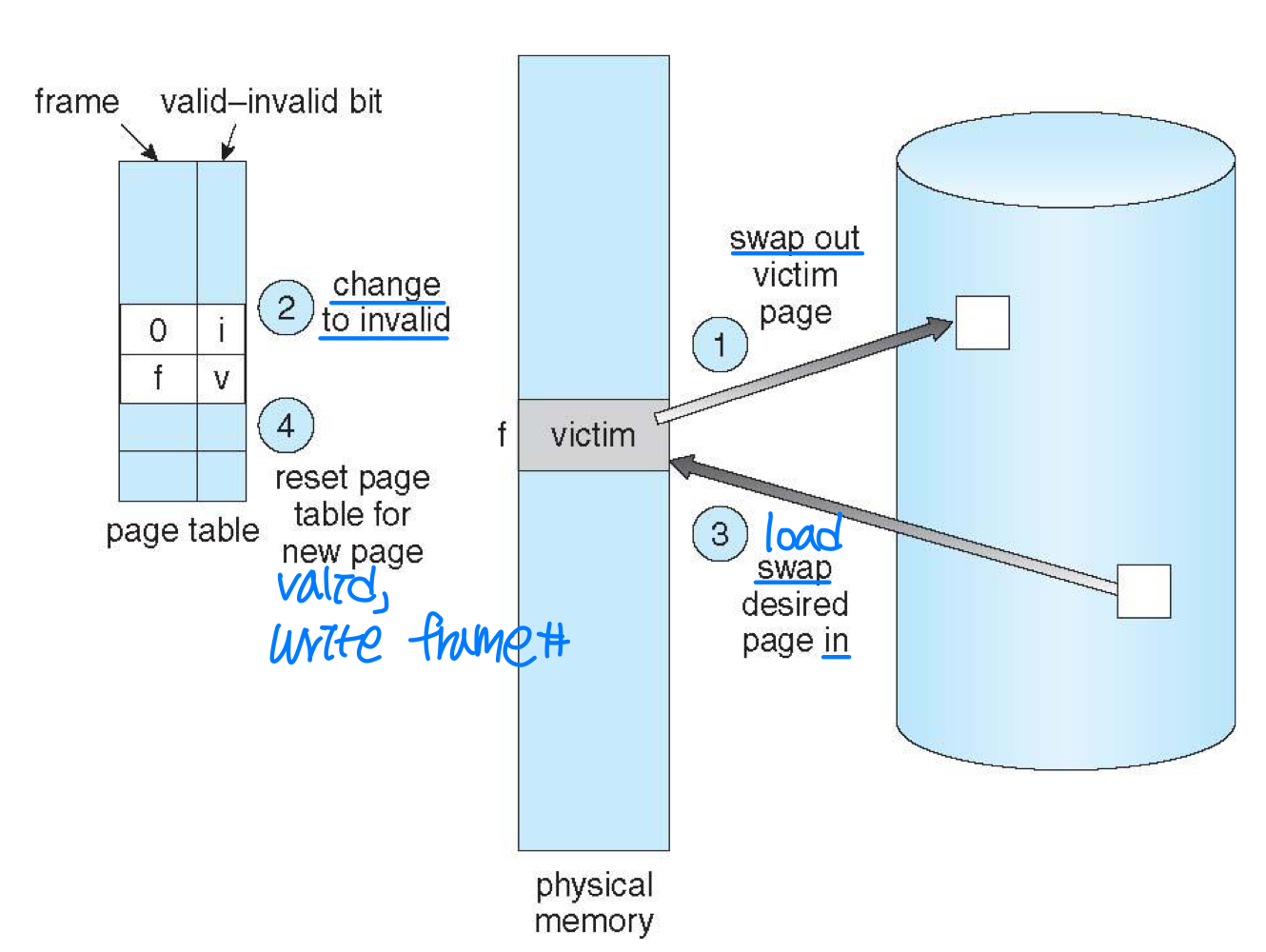
- Page replacement
- If no frame is free at a page fault, we find a frame not being used currently, and swap out
- Writing overhead can be reduced by modify-bit (or dirty-bit) for each frame → 0이면 swap할 필요 X
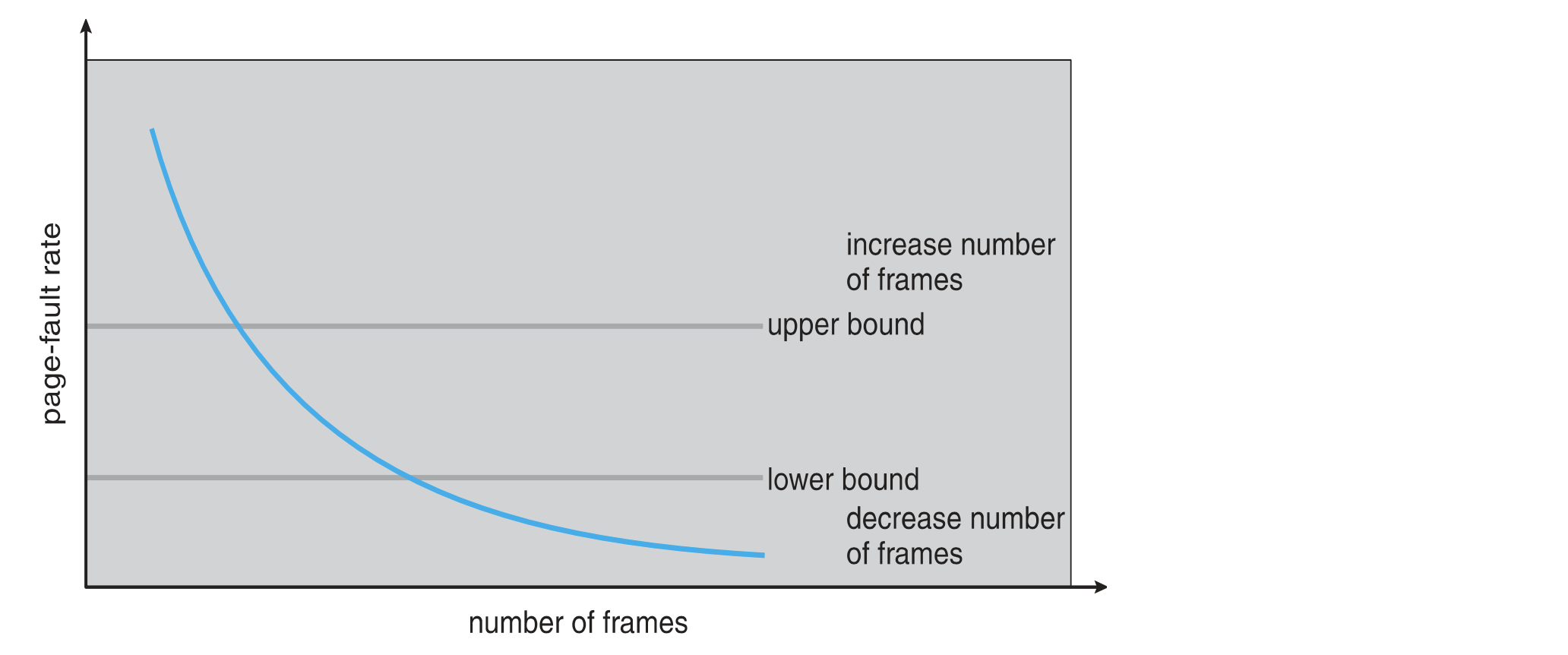
Page Faults vs. Number of Frames
- In general, the more frames, the fewer page faults
→ 반비례, but linear 하진 않음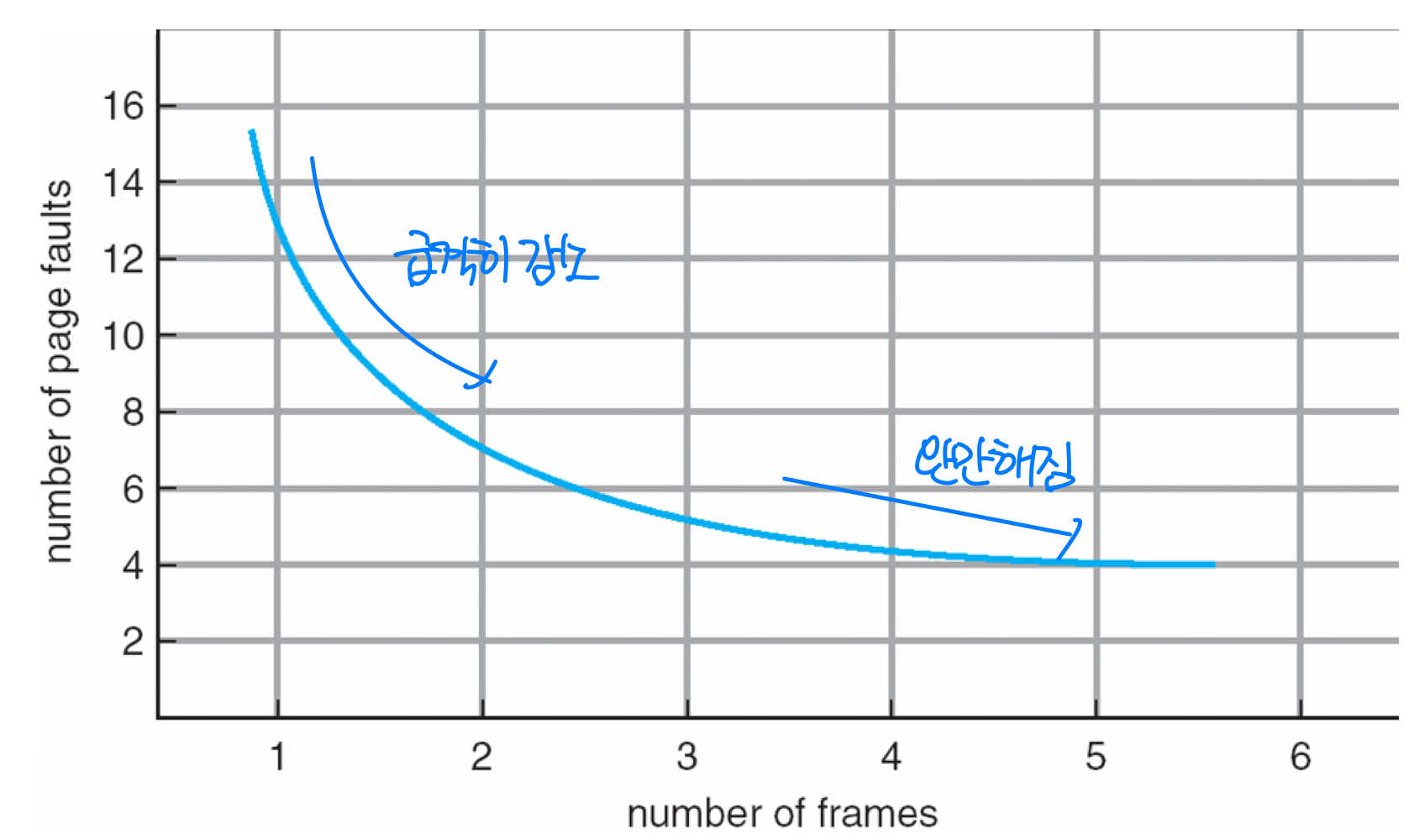
Page Replacement Algorithms
→ Page fault handling할 때 발생
FIFO page replacement
- First-in, first-out: when a page should be replaced, the oldest page is chosen
- Easy, but not always good
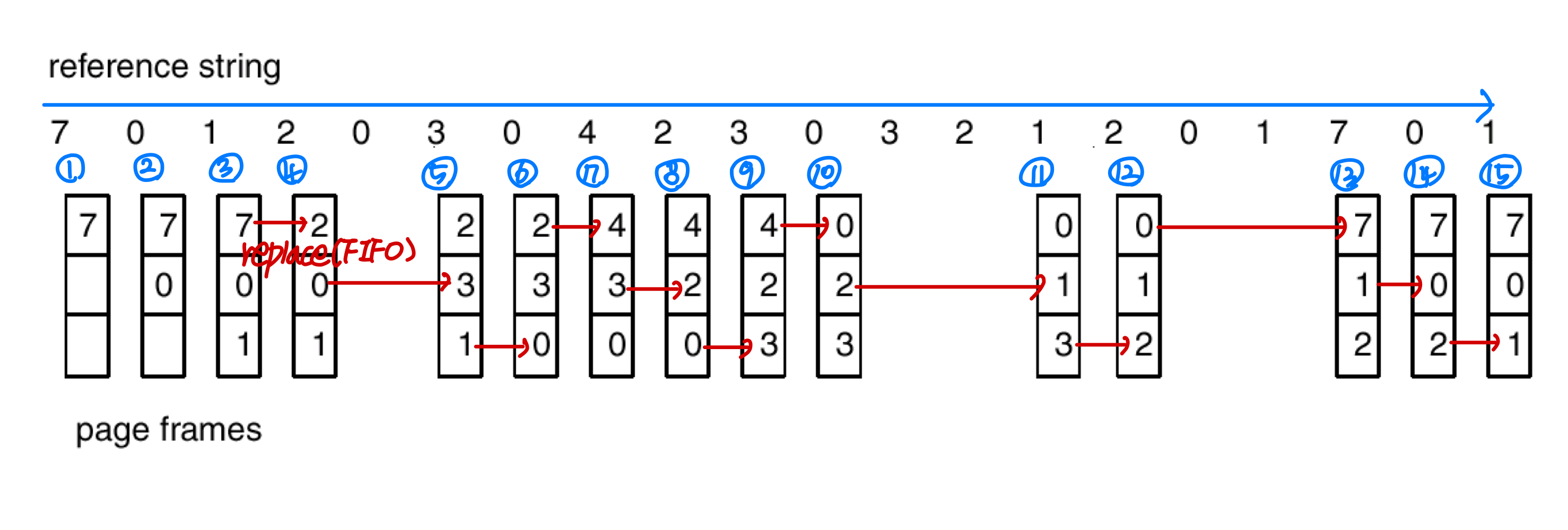
- # of page faults: 15
- Easy, but not always good
- Problem: Belady’s anomaly
- Belady’s anomaly: # of faults for 4 frames is greater than # of faults for 3 frames
(Reference string: 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5)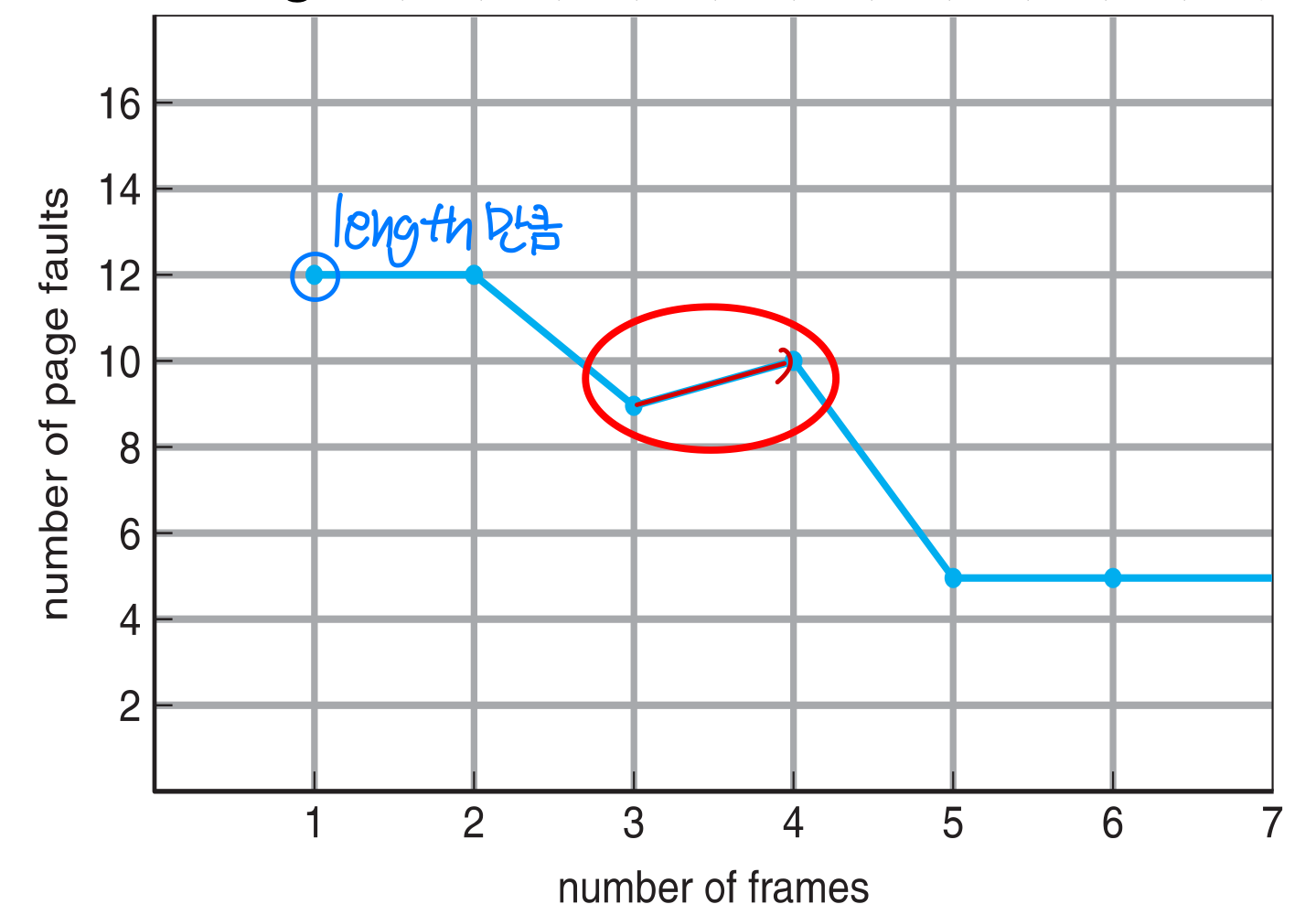 Page-fault rate may increase as the number of frames increase
Page-fault rate may increase as the number of frames increase
Optimal Page Replacement
- Replace the page that will not be used for the longest period of time
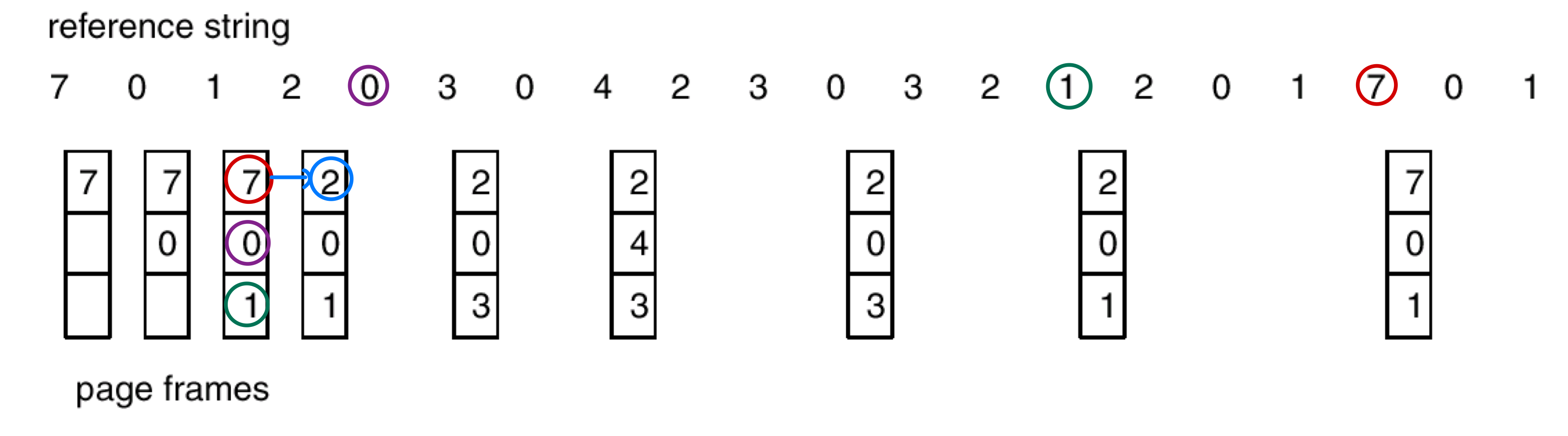
- # of page faults: 9
- Problem: It requires future knowledge
LRU Page Replacement
- LRU (Least Recently Used): replace page that has not been used for longest period of time
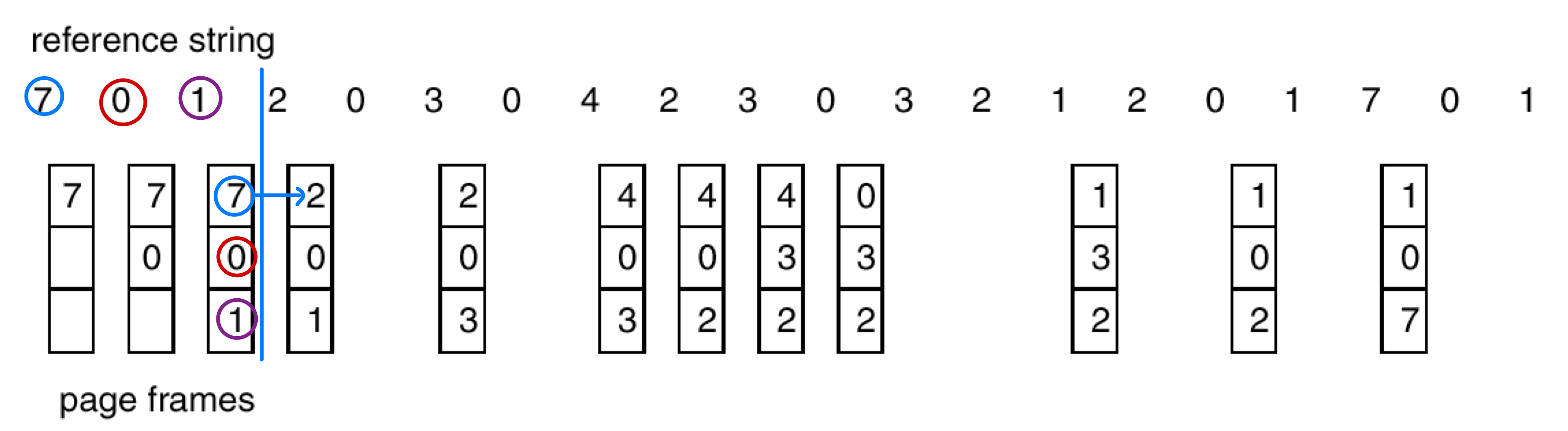
- # of page faults: 12
- LRU is considered to be good and used frequently
Implementation of LRU
- Using counter (logical clock)
- Associate with each page-table entry a time-of-used field → memory access가 너무 자주돼서 overhead가 너무 큼
- Whenever a page is referenced, clock register is copied to its time-of-used field
- Using stack of page numbers
- If a page is referenced, remove it and put on the top of the stack
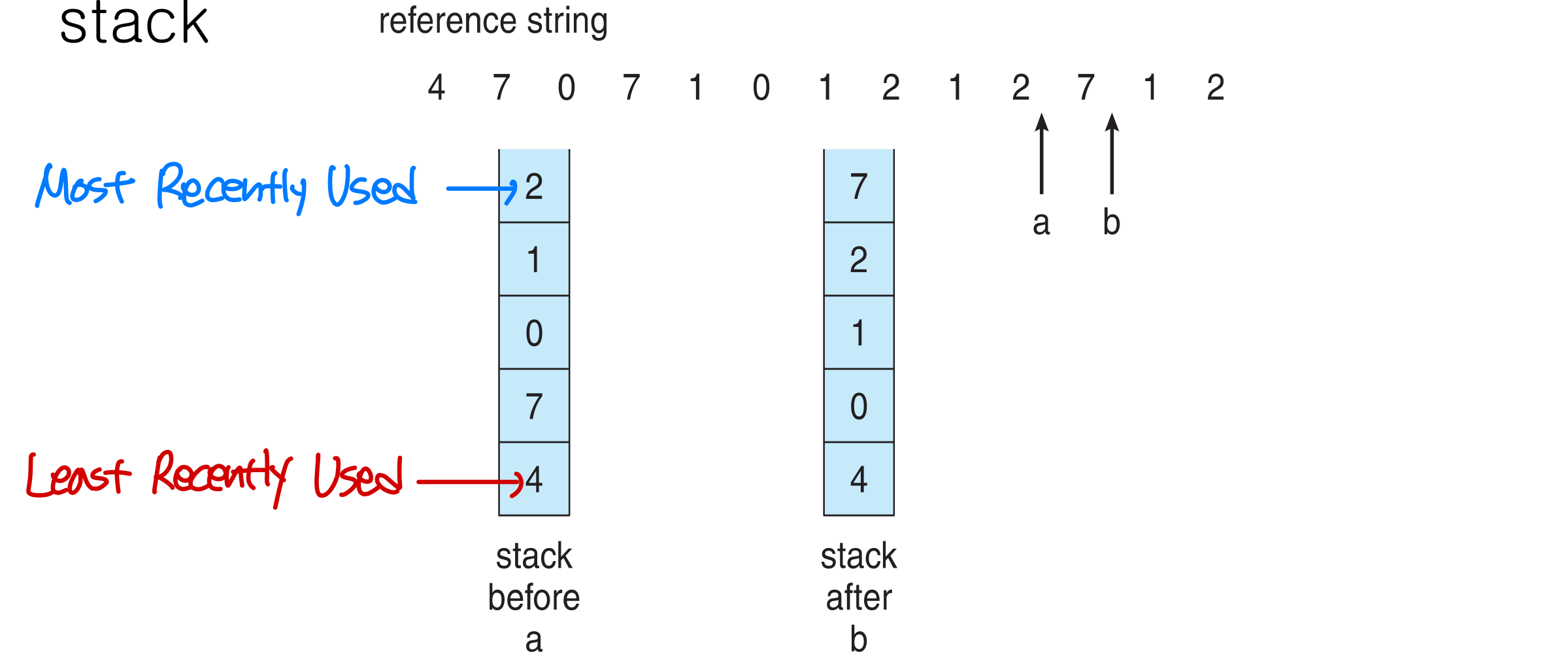 → 대안, but 여전히 slow
→ 대안, but 여전히 slow
- If a page is referenced, remove it and put on the top of the stack
LRU-Approximation Page Replacement → 정확한 LRU 아님
- Motivation
- LRU algorithm is good, but few system provide sufficient supports for LRU
- However, many systems support reference bit(supported by H/W, 사용시 1로 바꿔줌) for each page
- We can determine which pages have been referenced, but not their order.
- LRU-approximation algorithms
- Additional-reference-bit algorithm
- Gain additional ordering information by recording the reference bits at regular intervals.
Ex) keep 8-bit byte for each page and records current state of reference bits of each page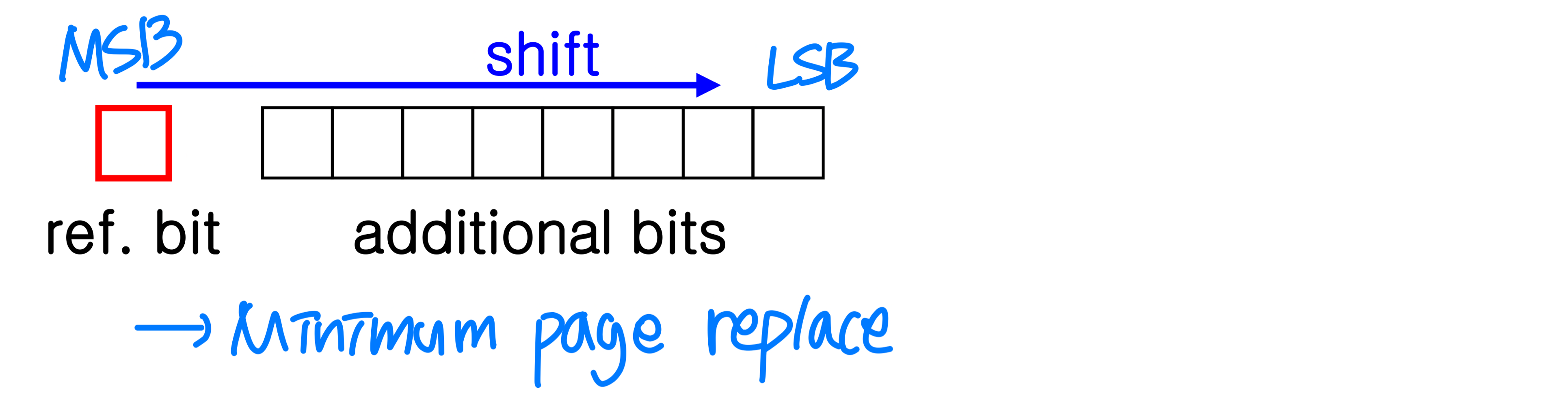
- Gain additional ordering information by recording the reference bits at regular intervals.
- Second-chance algorithm
- Basically, FIFO algorithm
- If reference bit of the chosen page is 1, give a second chance
- The reference bit is cleared → set to 0
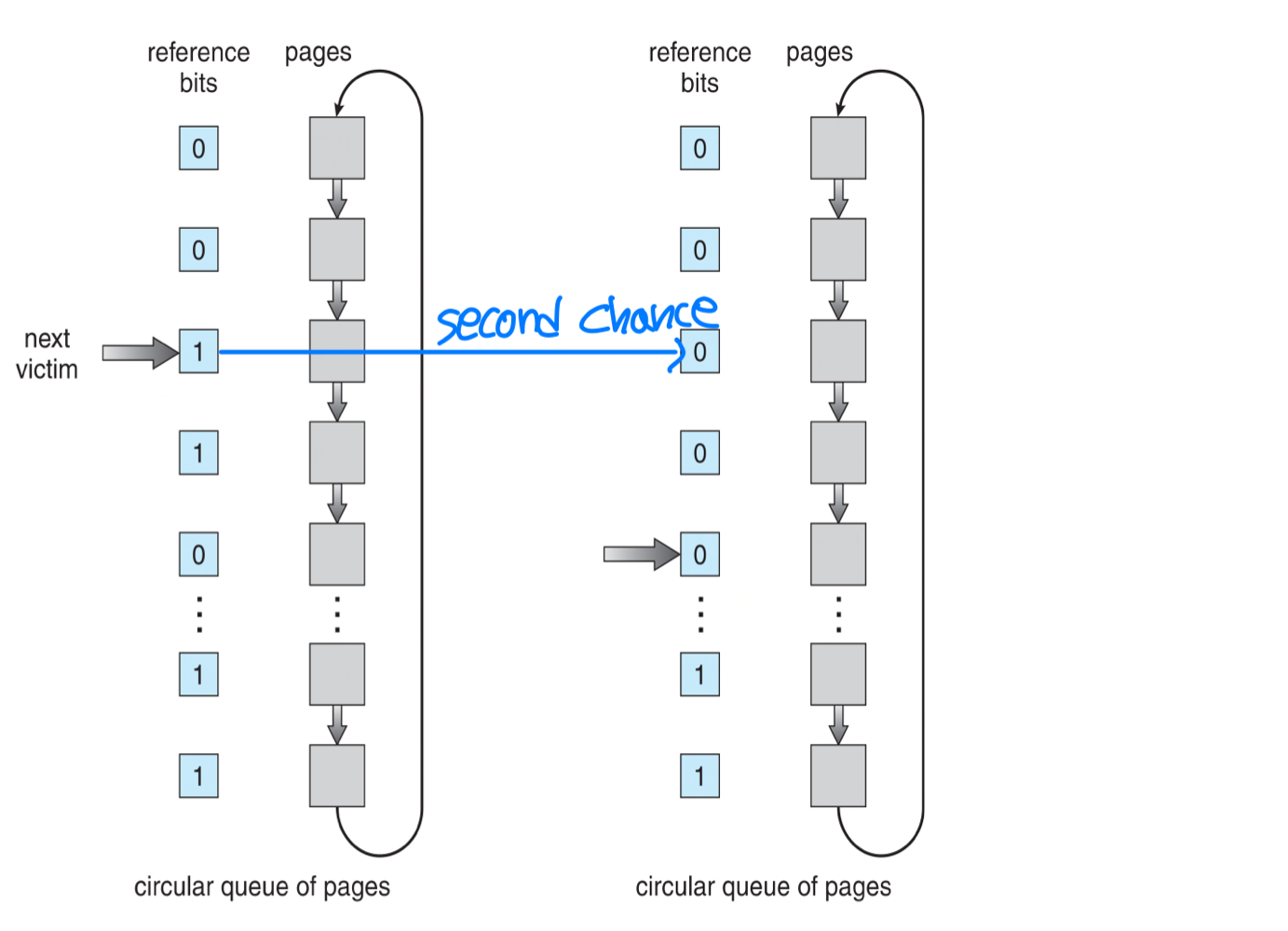
- The reference bit is cleared → set to 0
- Additional-reference-bit algorithm
Page-Buffering Algorithms
- Pool of free frames
- Some system maintain a list of free frames
→ page replacement algo.으로 미리 결정해둠, swap out을 미리 해둔다 (삭제준비) → swap in만 하면됨 - When a page fault occurs, a victim frame is chosen from the pool.
- Frame number of each free page can be kept for next use.
- Some system maintain a list of free frames
- Keep a list of free frames and remember which page was in each frame.
- The old page can be reused.
- OS typically applies ZFOD(zero-fill on demand) technique.
- List of modified pages
- Whenever the page device is idle, a modified page is written to disk
🖥️ Allocation of Frames
- How do we allocate the fixed amount of free memory among various processes?
- How many frames does each process get?
- Minimum number of frames for each process
- # of frames for each process decreases
→ page-fault rate is increases
→ performance degradation - Minimum # of frames should be large enough to hold all different pages that any single instruction can reference
- # of frames for each process decreases
Equal allocation
- Split m frames among n processes
→ m / n frames for each process
Proportional allocation → process 크기에 비례해서
- Allocate available memory to each process according to its size
a = s / S * m(process #)- a: # of frames allocated to process p
- s: size of process p
- S = s → process total size
- Variation: frame allocation based on ...
- Priority of process → 중요도 반영 X
- Combination of size and priority
Global vs. Local Allocation
- Global replacement: a process can select a replacement frame from the set of all frames, including frames allocated to other processes
→ All process frame 전체 중에서 replace- A process cannot control its own page-fault rate
- 장점 : 효율적, 단점 : process간 경계 X, performance 영향
- Local replacement: # of frames for a process does not change
- Less used pages of memory can’t be used by other process
→ Global replacement is more common method
🖥️ Thrashing
→ memory가 부족할 때
- If a process does not have enough frames to support pages in active use, it quickly faults again and again.
- A process is thrashing if it is spending more time paging(swapping) than executing
→ paging time (= Using Disk) > executing time (= Using CPU) - If trashing sets in, CPU utilization drops sharply
- Degree of multiprogramming should be decreased
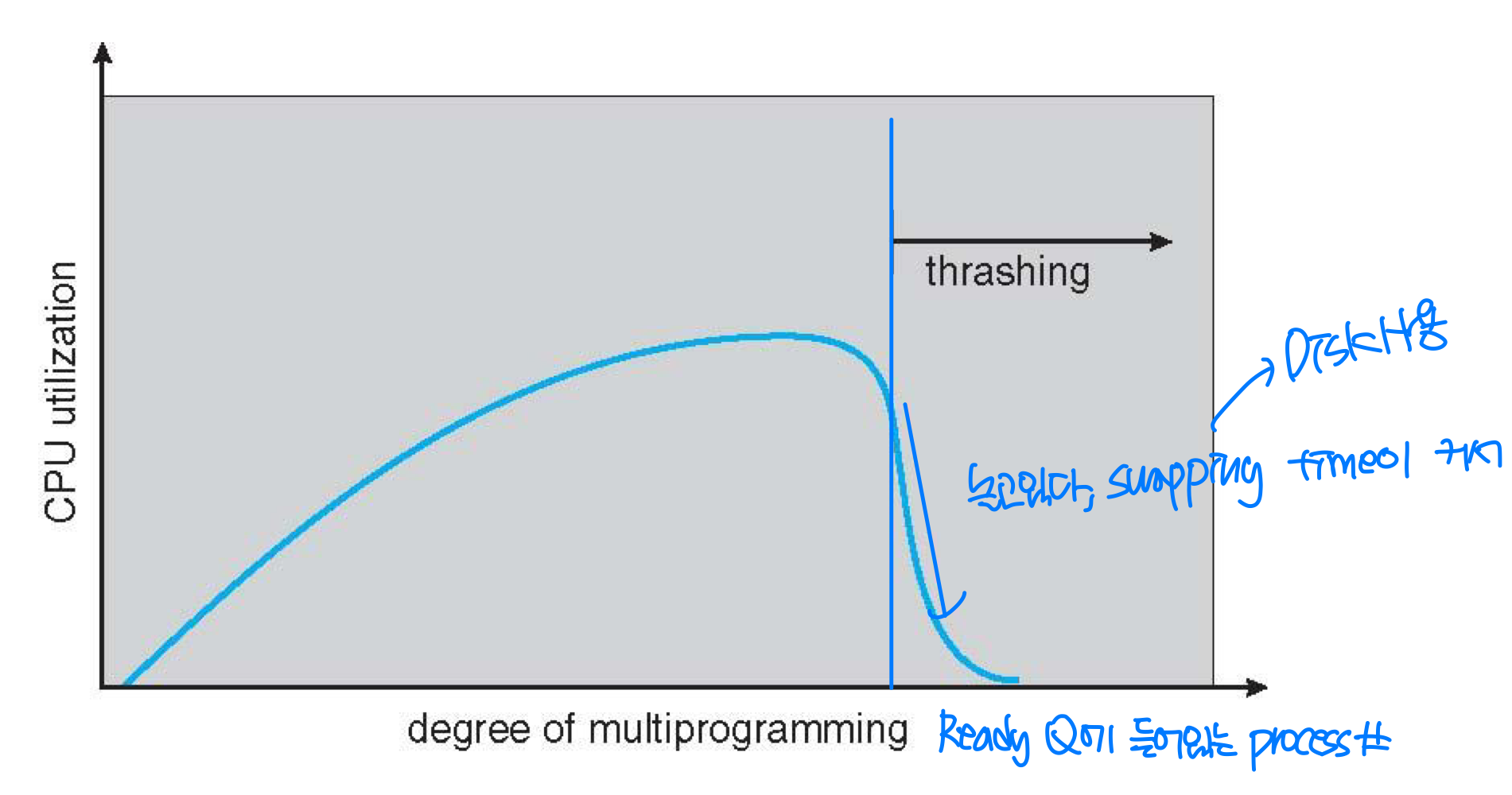
- Degree of multiprogramming should be decreased
- To prevent thrashing, a process must be provided with as many frames as it needs
→ How to know how many frames it needs? - Locality model
- Locality: set of pages actively used together
- A program is generally composed of several localities

Working-Set Model
- Working set: set of pages in the most recent page references
- Parameter : working-set window
Ex_ 10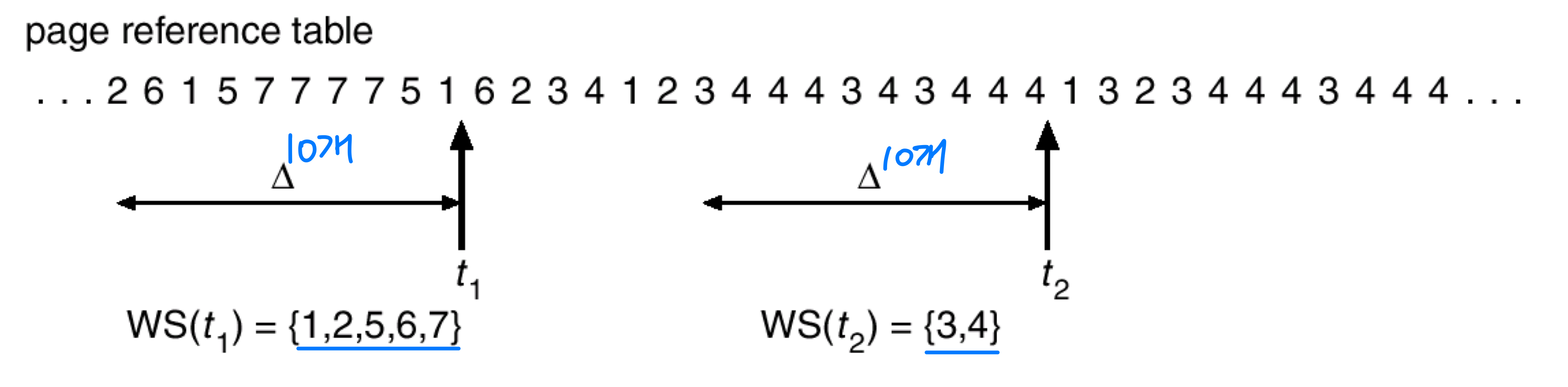
- WSS: working set size of process p
- Process p needs WSS frames → p < WSS : page fault 급격히 증가 = performance drop
- Parameter : working-set window
- If total demand is greater than # of available frames, thrashing will occur.
Working Sets and Page Fault Rates
- Direct relationship between working set of a process and its page-fault rate
- Working set changes over time
- Peaks and valleys over time
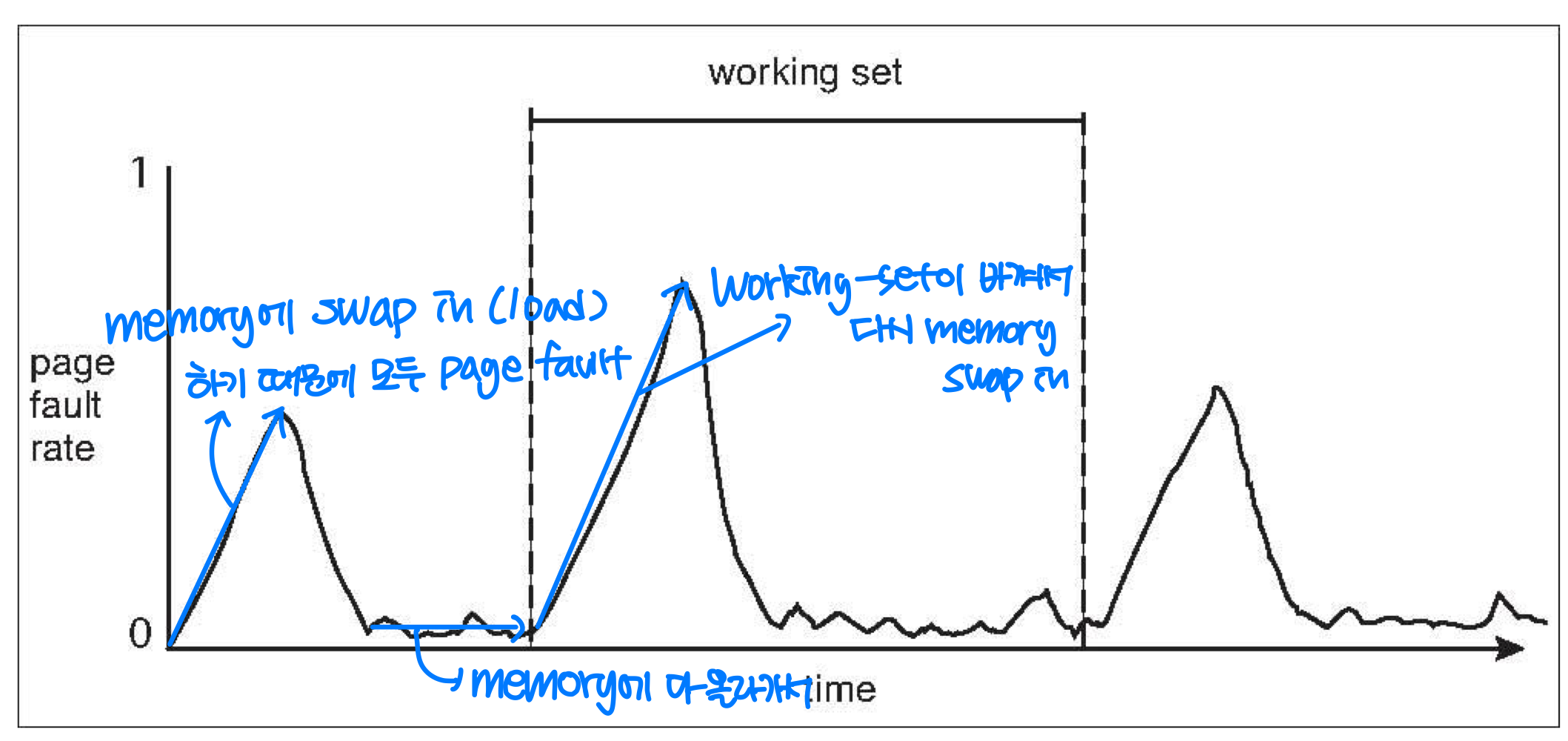
Page-Fault Frequency
- Alternative method to control trashing: control degree of multiprogramming by page-fault frequency (PFF)
- If PFF of a process is too high, allocate more frame
- If PFF of a process is too low, remove a frame from it
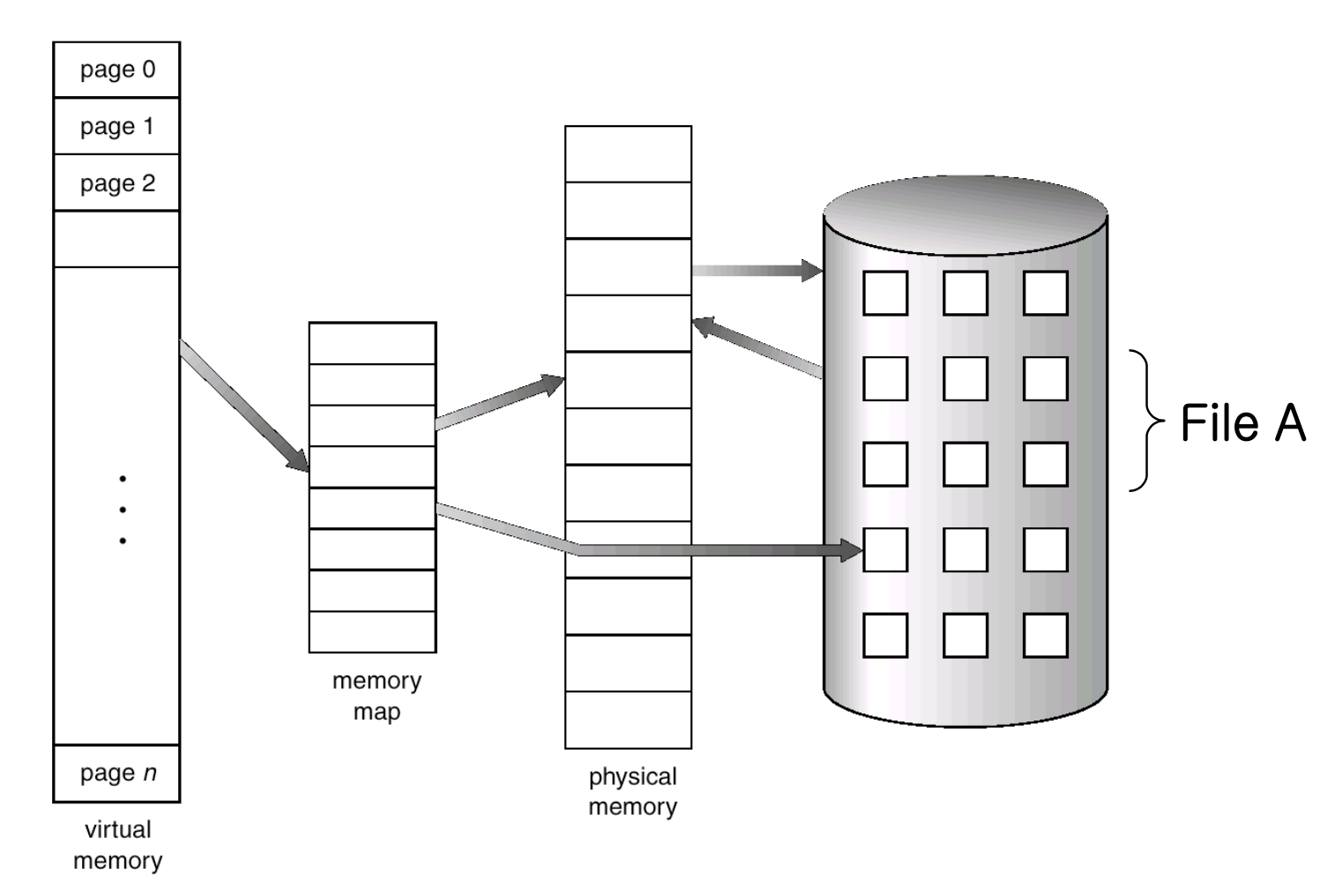
🖥️ Memory-mapped files
- Memory-mapped file: a part of virtual address space is logically associated with a file
- Map a disk block to a page in memory
- Initial access proceeds through demand paging results in page fault
- A page-sized portion of the file is read from the file system into a physical page
- Subsequent access is through memory access routine
- When the file is closed, memory-mapped data are written back to disk
- Advantages
- Reduces overhead of read() and write()
- File sharing
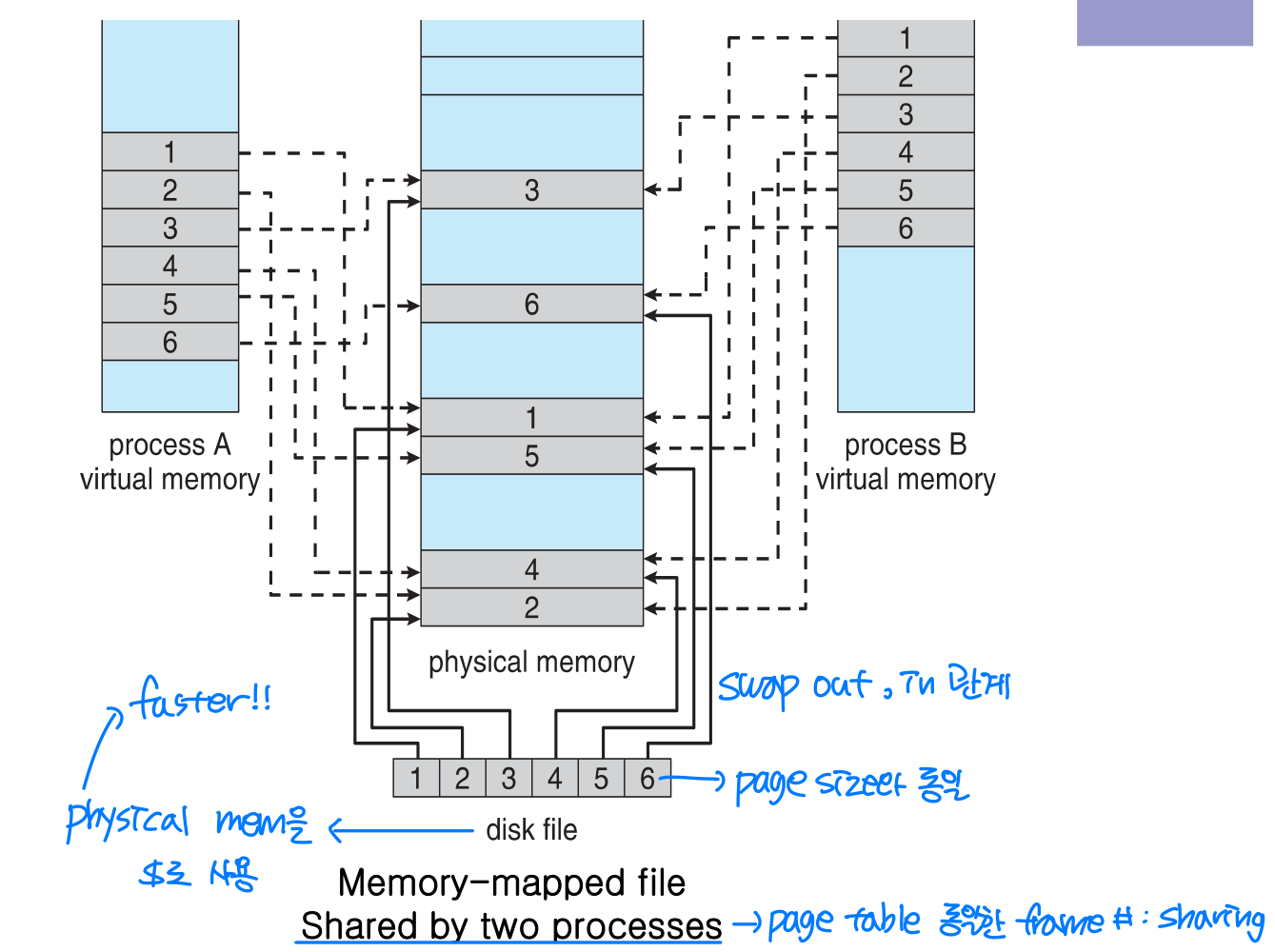
→ ⭐️ Faster
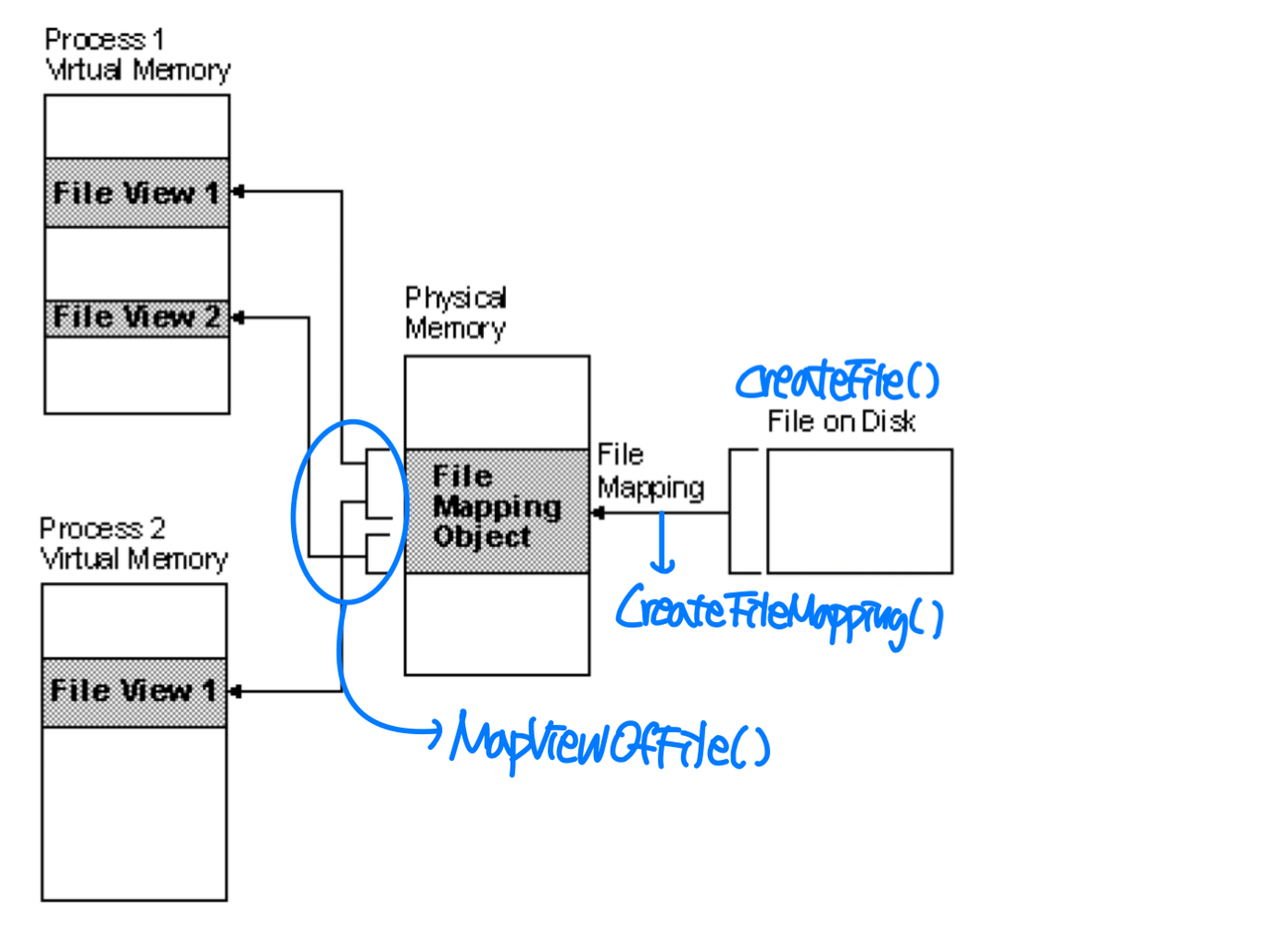
Shared Memory in Win32 API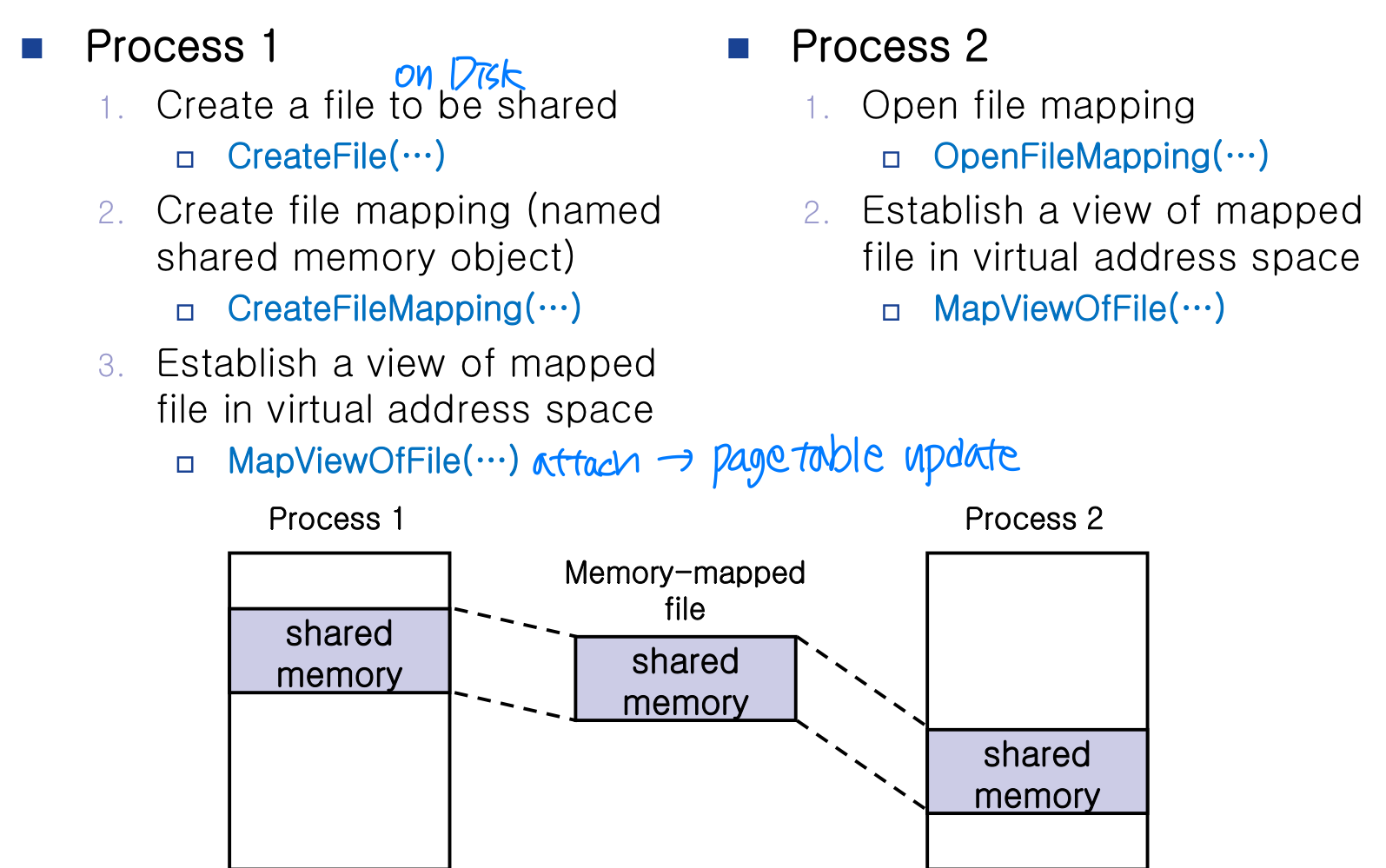
- File mapping is the association of a file's contents with a portion of the virtual address space of a process.
- The system creates a file mapping object to maintain this association.
- A file view is the portion of virtual address space that a process uses to access the file's contents.
- It also allows the process to work efficiently with a large data file.
- Multiple processes can also use memory-mapped files to share data
Memory-Mapped I/O
- I/O devices are accessed through ...
- Device registers in I/O controller to hold command and data
- Usually, special instructions transfer data between device registers and memory
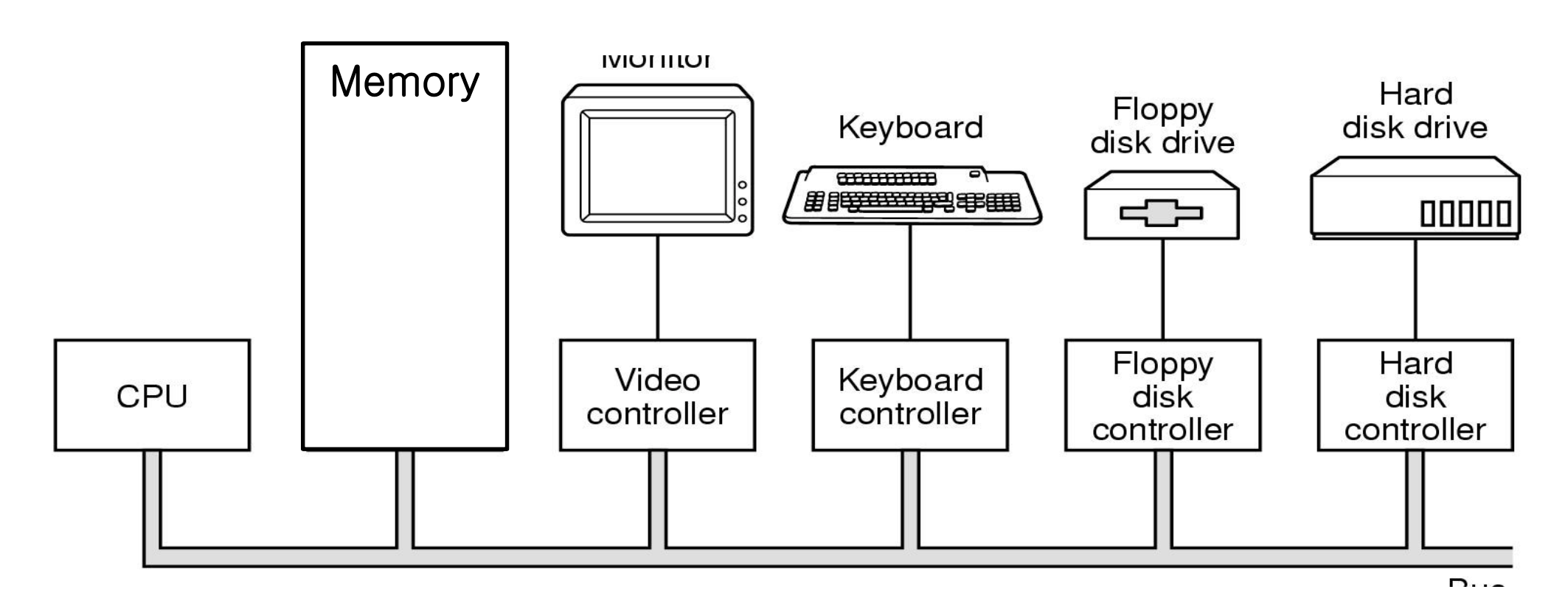
- Memory-mapped I/O: ranges of memory addresses are set aside and mapped to the device registers
- In IBM PC, each location on screen is mapped to a memory location
- Serial/parallel ports - data transfer through reading/writing device registers (ports)
- Programmed I/O (PIO)
Ex) Sending a long string of bytes through memory-mapped I/O- CPU sets a byte to a register and set a bit in the control register to signal that the data is available.
- Device receives the data and clears the bit in the control register to signal CPU that it is ready for the next byte.
cf. Interrupt driven I/O
🖥️ Allocating Kernel Memory
→ Externel fragmentation 문제를 해결할 paging을 사용하지 못함
1) Buddy System
- Buddy system: allocates memory from a fixed-size segment consisting of physically contiguous pages
- Power-of-2 allocator
Ex) initially 256 KB(memory) is available, 21 KB(kernel) was requested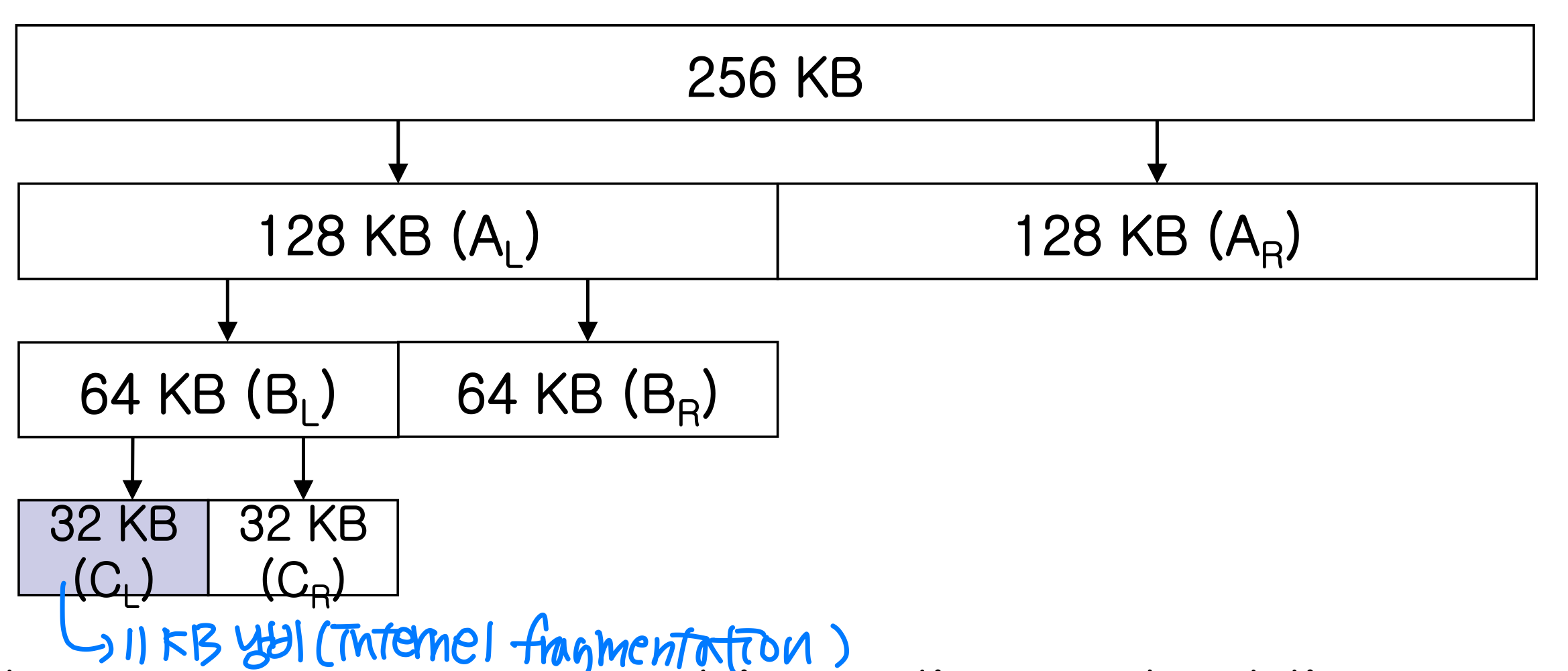
- Advantage: easy to combine adjacent buddies
- Disadvantage: internal fragmentation
- Power-of-2 allocator
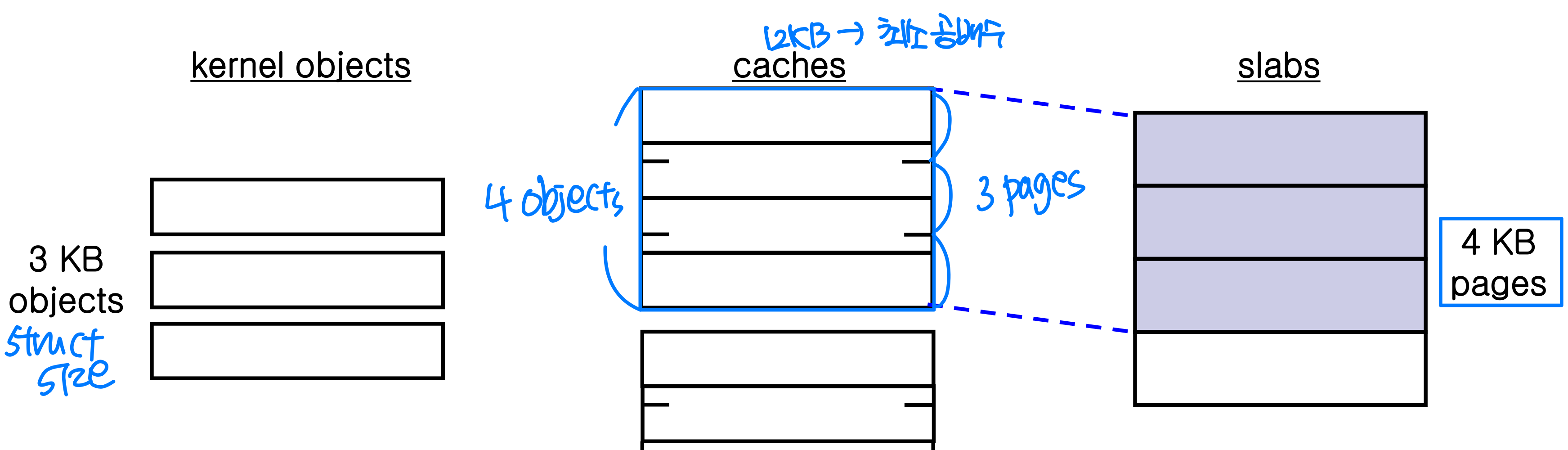
2) Slab Allocation
→ kernel은 일정한 크기의 struct size를 할당과 해제를 반복함
- Motivation: mismatch between allocation size and requested size
- Page-size granularity vs. byte-size granularity
- Applied since Solaris 2.4 and Linux 2.2
- Cache for each unique kernel data structure
- A slab is made up of one or more physically contiguous pages
- A cache consists of one or more slabs
🖥️ Other considerations
Prepaging
- A problem of pure demand paging (page fault가 나면 그 page만 읽어온다): a large number of page faults
- Prepaging: bring all pages that will be needed at one time to reduce page faults
Ex) working-set model- Important issue: cost of prepaging vs. cost of servicing corresponding page faults
Page size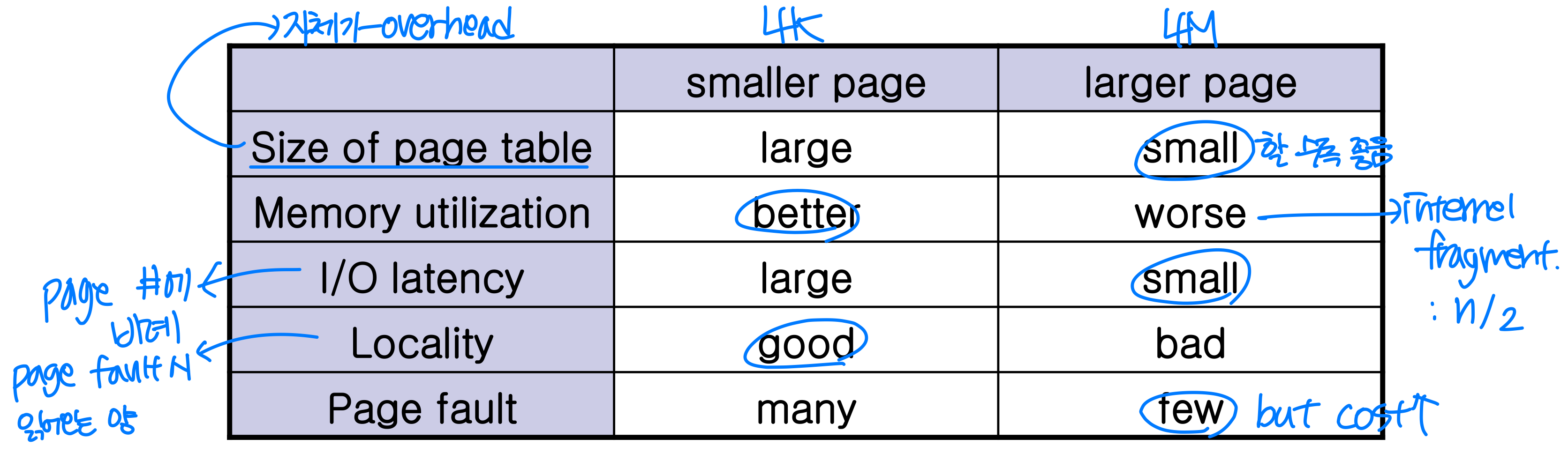
- Historical trend: page size is getting larger
TLB reach
- To improve TLB hit ratio, size of TLB should be increased.
→ but associate memory is expensive, power hungry - TLB reach: amount of memory accessible from TLB
- TLB reach = < # of entries in TLB > * < page size >
→ 크면 클수록 hit ratio ⬆️
- TLB reach = < # of entries in TLB > * < page size >
- TLB reach can increase by increasing page size
- However, with large page, fragmentation also increases.
➔ S/W managed TLB (OS support several different page sizes)
Ex) UltraSparc, MIPS, Alpha
Cf) PowerPC, Pentium: H/W managed TLB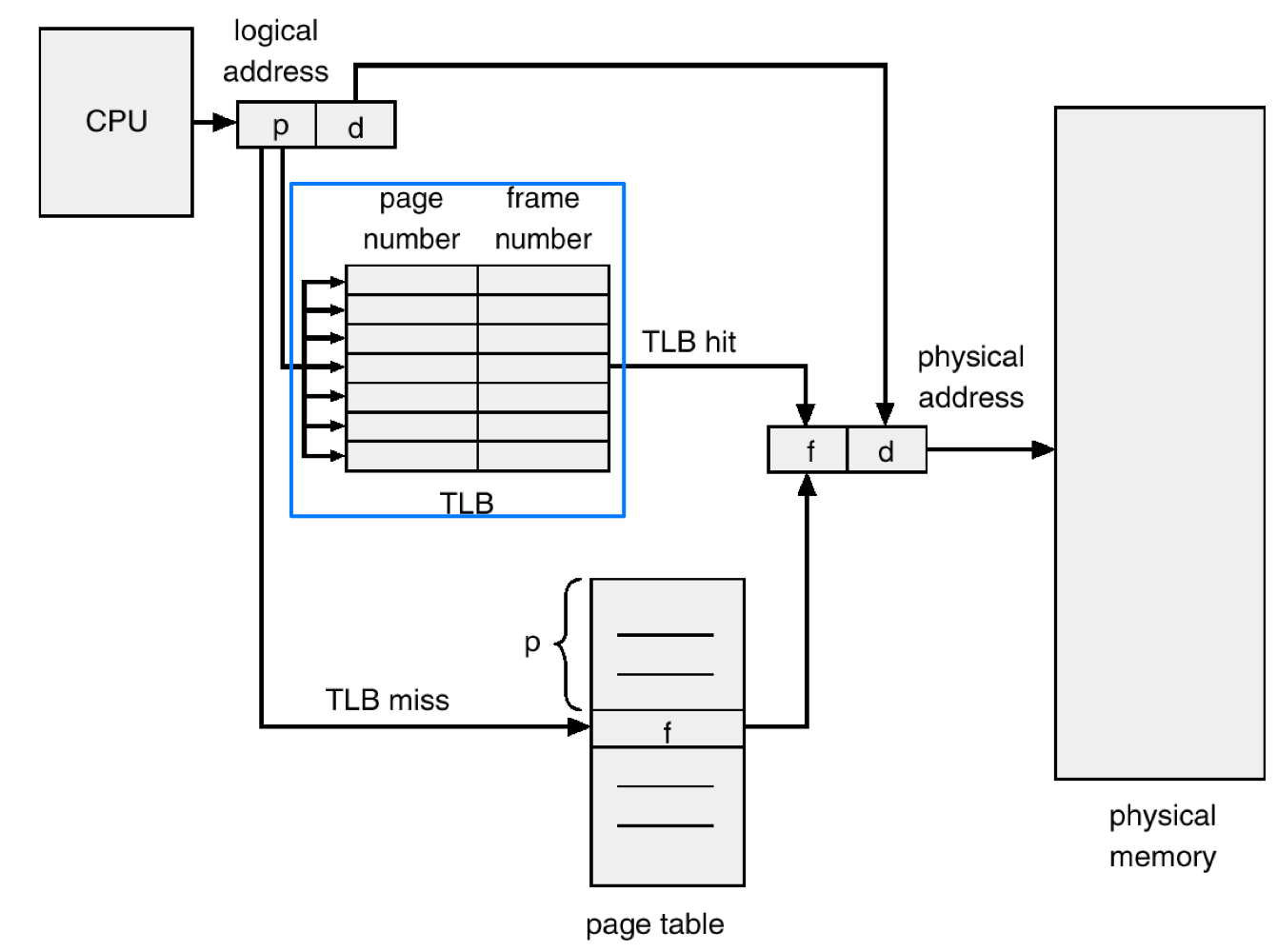
- However, with large page, fragmentation also increases.
Program structure
- User don’t’ have to know about nature of memory. But, if user knows underlying demand paging, performance can be improved
- Ex) If page size is 128 words(integer size), B is better than A
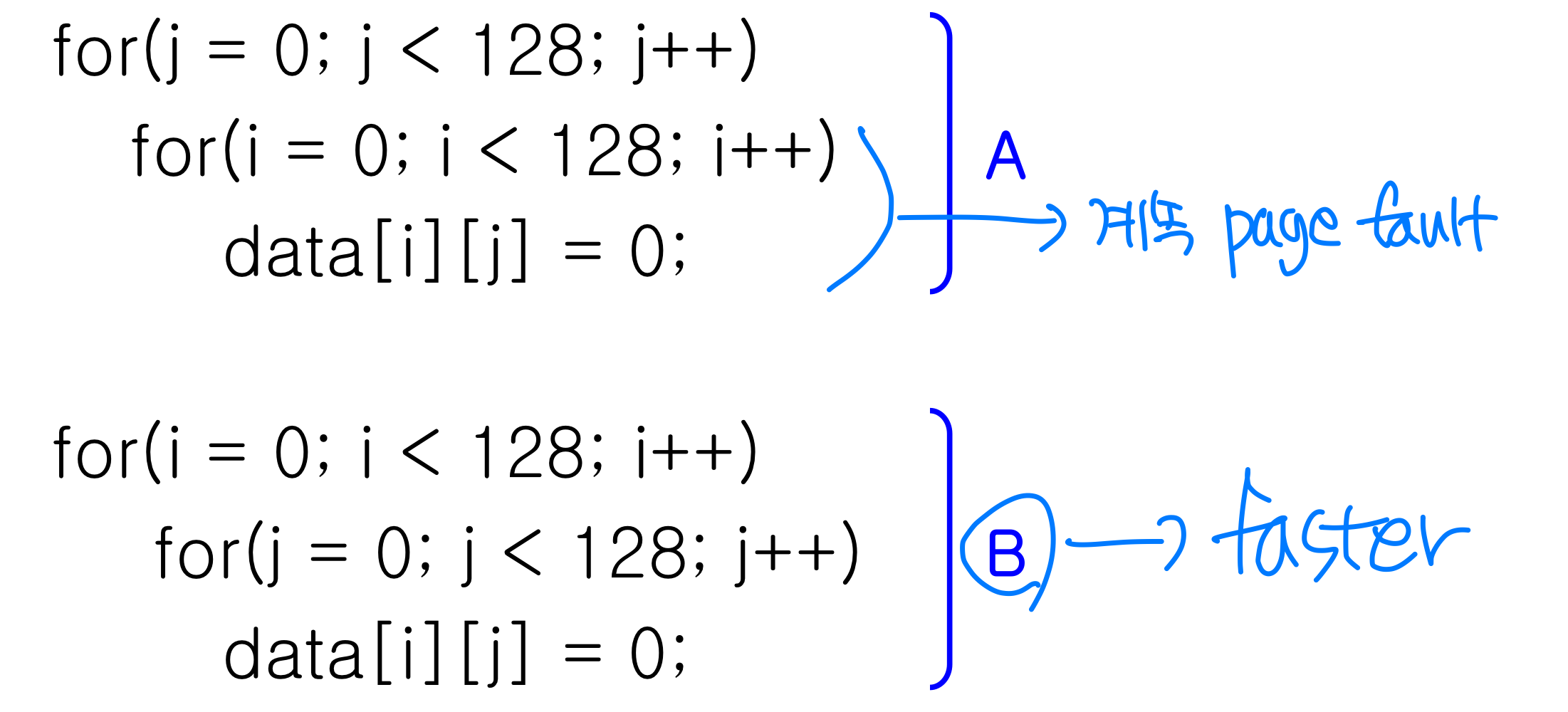
- Ex) If page size is 128 words(integer size), B is better than A
I/O interlock
- Memory space related to I/O transfer should not be replaced
- Remedies
- I/O transfer is performed only through system memory
- Locking pages in memory → swapping에서 제외시킴
HGU 전산전자공학부 김인중 교수님의 23-1 운영체제 수업을 듣고 작성한 포스트이며, 첨부한 모든 사진은 교수님 수업 PPT의 사진 원본에 필기를 한 수정본입니다.

HGU - 개인 공부 기록용 블로그