Prefetch
Leap은 페이지가 캐싱되어 있지 않을 때, swapin_readahead 함수를 수행하는 부분에서 과반수 투표 알고리즘을 이용한 패턴 탐지와 prefetcher를 통한 스왑으로 기존 커널의 prefetching의 오버헤드를 감소시켰다.
Flow
Functions
-
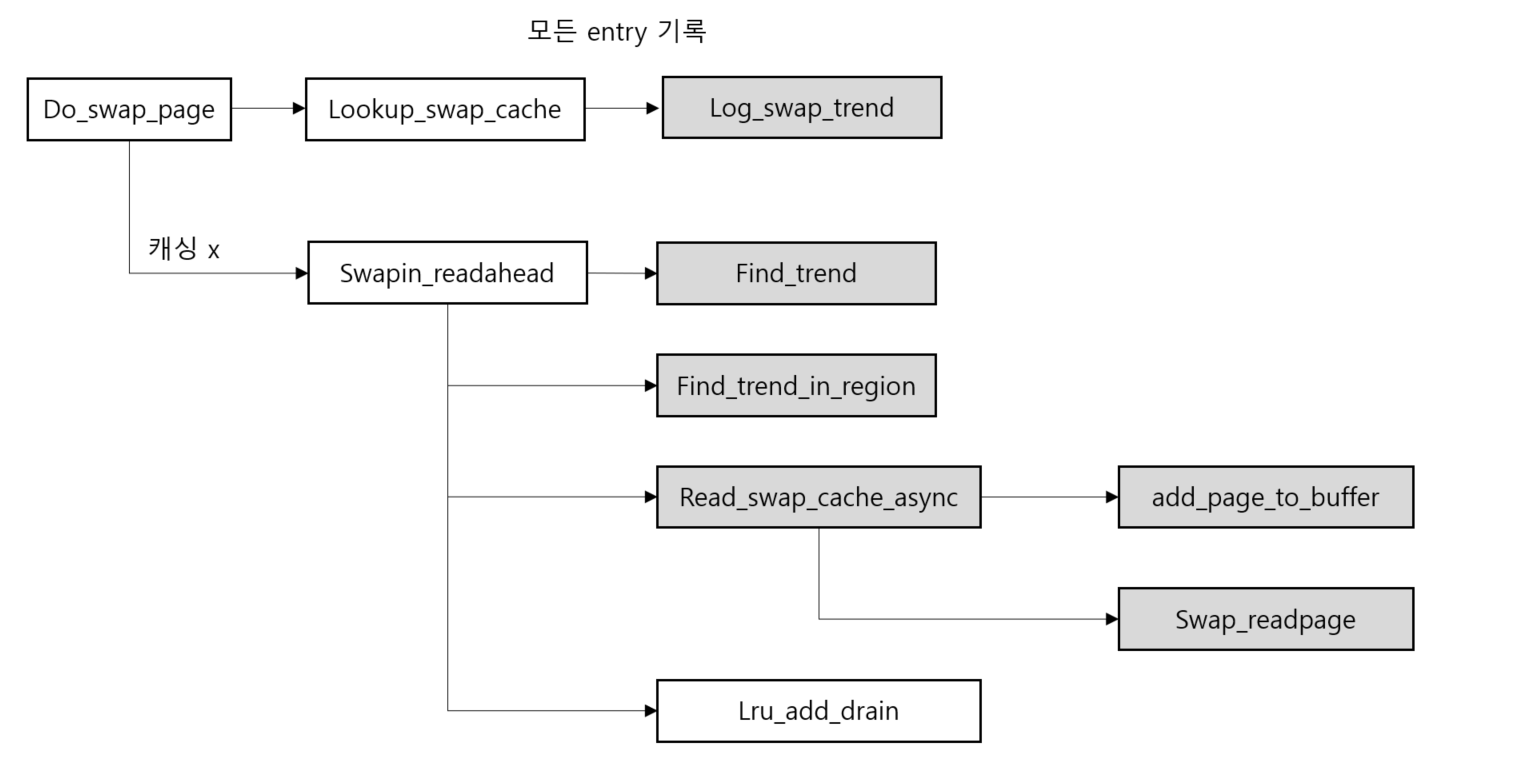
swapin_readahead:readahead연산을 수행한다. 결과적으로 read 연산은 요구되는 페이지 뿐만 아니라 인접한 슬롯의 몇 페이지 또한 가져온다. 프로세스는 종종 메모리에 순차적으로 접근하기 때문에, 적은 노력으로 속도를 상당히 높인다. 만약 순차적인 접근이 있을 경우, 페이지는 이미 메모리에 있다. -
read_swap_cache_async: 현재 필요한 페이지에 대해 한 번 더 호출된다. 작업은 비동기적으로 이루어지며, 커널은 추가 작업을 수행하기 전에 데이터가 read 됐는지 확인한다.read_swap_cache_async함수는 read 요청을 블록 계층으로 보내기 전에 페이지를 lock 한다. 그리고 블록 계층이 데이터 전송을 마치면 페이지 lock을 해제한다. -
log_swap_trend:trend_history에 접근하는 모든 페이지에 대해 기록 -
find_trend&find_trend_in_region: 과반수 투표 알고리즘을 이용한 패턴 탐지 -
read_swap_cache_async: 기존의 커널과 다르게 페이지를 캐시와 버퍼에 기록 -
swap_readpage: remote IO와 연결되는 함수로, 이 함수를 통해 rdma를 수행하게 된다.
Data Structures
trend_historyin swap_state.c
page fault 시 메모리에 접근하는 페이지를 모두 기록하는 자료구조이다. 이를 바탕으로 prefetch 알고리즘을 수행할 때, trend_history를 순회하면서 trend를 찾고 prefetch를 수행한다.

struct swap_entry {
long delta; // offset
unsigned long entry; // address
};
struct swap_trend {
atomic_t head;
atomic_t size; // window 크기
atomic_t max_size; // ACCESSHISTORY size (미리 정해둔 고정 크기)
struct swap_entry *history; // entry address
};
static struct swap_trend trend_history;
void init_swap_trend(int size) {
trend_history.history = (struct swap_entry *) kzalloc(size * sizeof(struct swap_entry), GFP_KERNEL);
atomic_set(&trend_history.head, 0);
atomic_set(&trend_history.size, 0);
atomic_set(&trend_history.max_size , size);
init_stat();
}prefetch_bufferin swap_state.c
prefetch한 페이지를 저장하는 버퍼이다.

unsigned long buffer_size = 8000;
unsigned long is_prefetch_buffer_active = 0;
void activate_prefetch_buffer(unsigned long val){
is_prefetch_buffer_active = val;
}
struct pref_buffer {
atomic_t head;
atomic_t tail;
atomic_t size;
swp_entry_t *offset_list;
struct page **page_data;
spinlock_t buffer_lock;
};
static struct pref_buffer prefetch_buffer;Code
do_swap_pagein memory.c- 기능: 페이지 폴트 시, 처리하는 함수
static int do_swap_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
unsigned int flags, pte_t orig_pte)
{
spinlock_t *ptl;
struct page *page, *swapcache;
struct mem_cgroup *memcg;
swp_entry_t entry;
pte_t pte;
int locked;
int exclusive = 0;
int ret = 0;
if (!pte_unmap_same(mm, pmd, page_table, orig_pte)) // mm, pmd, pt에 대하여 pte 검사
goto out;
entry = pte_to_swp_entry(orig_pte); // pte entry를 swp_entry로 변환
if (unlikely(non_swap_entry(entry))) { // 변환 검사
if (is_migration_entry(entry)) { // migration 검사
migration_entry_wait(mm, pmd, address); // migration 대기
} else if (is_hwpoison_entry(entry)) {
ret = VM_FAULT_HWPOISON;
} else {
print_bad_pte(vma, address, orig_pte, NULL);
ret = VM_FAULT_SIGBUS;
}
goto out;
}
/*
... 중략
*/
// Leap 변경 부분
if ( get_custom_prefetch() != 0 )
try_to_free_swap(page);
else if (vm_swap_full || (vma->vm_flags & VM_LOCKED) || PageMlocked(page))
try_to_free_swap(page);
// Leap
/*
생략
*/get_custom_prefetchin swap_state.c- 기능: prefetch 사용 유무
unsigned long is_custom_prefetch = 0;
atomic_t my_swapin_readahead_hits = ATOMIC_INIT(0);
atomic_t swapin_readahead_entry = ATOMIC_INIT(0);
atomic_t trend_found = ATOMIC_INIT(0);
void set_custom_prefetch(unsigned long val) {
is_custom_prefetch = val;
}
unsigned long get_custom_prefetch() {
return is_custom_prefetch;
}lookup_swap_cachein swap_state.c- 기능: 스왑할 entry가 캐시에 있는 지 검사
- 파라미터: entry
- 리턴: 캐시 된 페이지 or NULL
struct page * lookup_swap_cache(swp_entry_t entry)
{
struct page *page;
page = find_get_page(swap_address_space(entry), entry.val); // 캐시 검사
// Leap
if( get_custom_prefetch() != 0 ) { // prefetch 할 경우
log_swap_trend(swp_offset(entry)); // trend에 기록
}
// Leap
if (page) { // 캐싱 됨
INC_CACHE_INFO(find_success);
if (TestClearPageReadahead(page)) {
atomic_inc(&swapin_readahead_hits);
// Leap
if( get_custom_prefetch() != 0 ) {
atomic_inc(&my_swapin_readahead_hits); // readahead hit 증가
}
// Leap
}
}
INC_CACHE_INFO(find_total);
return page;
}log_swap_trendin swap_state.c- 기능: trend_history에 entry 기록
- 파라미터: entry
void log_swap_trend(unsigned long entry) {
long offset_delta; // entry - 이전 entry = 오프셋 저장
int prev_index; // 이전 페이지 인덱스
struct swap_entry se; // 전달 받은 엔트리의 오프셋과 주소 저장
if(atomic_read(&trend_history.size)) { // 윈도우가 0이 아니면
prev_index = get_prev_index(atomic_read(&trend_history.head)); // 페이지 인덱스
offset_delta = entry - trend_history.history[prev_index].entry; // 페이지 오프셋
se.delta = offset_delta; // 페이지 오프셋
se.entry = entry;
}
else { // 윈도우가 0이면
se.delta = 0;
se.entry = entry;
}
trend_history.history[atomic_read(&trend_history.head)] = se; // history에 entry 기록
inc_head();
inc_size();
}swapin_readaheadin swap_state.c- 기능: 폴트 페이지 스왑 및 prefetch
- 파라미터: swap entry of this memory, memory allocation flag, user vma address, 타겟 주소
- 출력: 스왑한 페이지
struct page *swapin_readahead(swp_entry_t entry, gfp_t gfp_mask,
struct vm_area_struct *vma, unsigned long addr)
{
struct page *page;
unsigned long entry_offset = swp_offset(entry);
unsigned long offset = entry_offset;
unsigned long start_offset, end_offset;
unsigned long mask;
struct blk_plug plug;
mask = swapin_nr_pages(offset) - 1;
// Leap
atomic_inc(&swapin_readahead_entry); // readahead 연산 횟수 + 1
if( get_custom_prefetch() != 0 ) {
int has_trend = 0, depth, major_count;
long major_delta;
has_trend = find_trend(&depth, &major_delta, &major_count); // 과반수 투표
if(has_trend) { // 패턴을 찾았을 경우
int count = 0;
atomic_inc(&trend_found); // 패턴 찾은 횟수 + 1
start_offset = offset;
// blk_start_plug(&plug);
for (offset = start_offset; count <= mask; offset+= major_delta, count++) {
/* Ok, do the async read-ahead now */
page = read_swap_cache_async(swp_entry(swp_type(entry), offset),
gfp_mask, vma, addr);
if (!page)
continue;
if (offset != entry_offset)
SetPageReadahead(page);
page_cache_release(page);
}
// blk_finish_plug(&plug);
lru_add_drain();
goto skip;
}
else
goto usual;
}
// Leap
usual:
// existing linux swapin_readahead code
}find_trendin swap_state.c- 기능: 패턴 탐지를 위한 윈도우 크기 조절
- 파라미터: 윈도우 크기, 과반수, 과반수 출현 횟수
- 출력: 패턴 찾은 유무
int find_trend (int *depth, long *major_delta, int *major_count) {
int has_trend = 0, size = (int) atomic_read(&trend_history.max_size)/4, max_size;
max_size = size * 4; // 패턴 찾은 유무, 윈도우 크기, AccessHistory 크기,
while(has_trend == 0 && size <= max_size) { // 윈도우 크기 내에서 패턴 찾을 때까지
has_trend = find_trend_in_region(size, major_delta, major_count);
size *= 2;
}
*depth = size;
return has_trend;
}find_trend_in_regionin swap_state.c- 기능: 과반수 투표 알고리즘
- 파라미터: 윈도우 크기, 과반수, 과반수 출현 횟수
- 리턴: 패턴 찾은 유무
int find_trend_in_region(int size, long *major_delta, int *major_count) {
int maj_index = get_prev_index(atomic_read(&trend_history.head)), count, i, j;
long candidate;
// 처음부터 윈도우 크기 내에서 검사
for (i = get_prev_index(maj_index), j = 1, count = 1; j < size; i = get_prev_index(i), j++) {
if (trend_history.history[maj_index].delta == trend_history.history[i].delta)
count++;
else
count--;
if (count == 0) {
maj_index = i;
count = 1;
}
}
candidate = trend_history.history[maj_index].delta; // 과반수
// 과반수 출현 횟수 세기
for (i = get_prev_index(atomic_read(&trend_history.head)), j = 0, count = 0; j < size; i = get_prev_index(i), j++) {
if(trend_history.history[i].delta == candidate)
count++;
}
*major_delta = candidate;
*major_count = count;
return count > (size/2); // [w / 2] + 1 이상일 경우에만 찾음
}read_swap_cache_asyncin swap_state.c- 기능: 스왑한 페이지를 캐시에 저장
- 파라미터: entry, gfp_mask(할당 가능 플래그), vma, 타겟 주소
- 출력: 캐시에 저장된 페이지
struct page *read_swap_cache_async(swp_entry_t entry, gfp_t gfp_mask,
struct vm_area_struct *vma, unsigned long addr)
{
bool page_was_allocated; // 결과 저장
// vma 타겟 주소에 페이지 스왑, 원격 메모리 페이지 or 페이지 리턴
struct page *retpage = __read_swap_cache_async(entry, gfp_mask,
vma, addr, &page_was_allocated);
if (page_was_allocated){ // 페이지 할당 됨
if(get_prefetch_buffer_status() != 0){
add_page_to_buffer(entry, retpage);
}
swap_readpage(retpage);
}
return retpage;
}__read_swap_cache_asyncin swap_state.c- 기능:
- 파라미터: entry, gfp_mask(할당 가능 플래그), vma, 타겟 주소, 페이지 할당 유무
- 리턴: 페이지
struct page *__read_swap_cache_async(swp_entry_t entry, gfp_t gfp_mask,
struct vm_area_struct *vma, unsigned long addr,
bool *new_page_allocated)
{
struct page *found_page, *new_page = NULL;
struct address_space *swapper_space = swap_address_space(entry); // address 포인터 반환
int err;
*new_page_allocated = false;
do {
found_page = find_get_page(swapper_space, entry.val); // 엔트리에 페이지 존재 검사
if (found_page) // 있으면 종료
break;
// 스왑할 새 페이지 할당
if (!new_page) {
new_page = alloc_page_vma(gfp_mask, vma, addr); // vma에 타겟 주소 할당하여 리턴
if (!new_page)
break; /* Out of memory */
}
err = radix_tree_maybe_preload(gfp_mask & GFP_KERNEL); // radix 트리 노드 할당
if (err)
break;
err = swapcache_prepare(entry); // entry 할당 해제 검사
if (err == -EEXIST) {
radix_tree_preload_end();
cond_resched();
continue;
}
if (err) { /* swp entry is obsolete ? */
radix_tree_preload_end();
break;
}
__set_page_locked(new_page);
SetPageSwapBacked(new_page);
err = __add_to_swap_cache(new_page, entry); // radix tree에 페이지 삽입
if (likely(!err)) {
radix_tree_preload_end();
lru_cache_add_anon(new_page);
*new_page_allocated = true;
return new_page;
}
radix_tree_preload_end();
ClearPageSwapBacked(new_page);
__clear_page_locked(new_page);
swapcache_free(entry);
} while (err != -ENOMEM);
if (new_page)
page_cache_release(new_page);
return found_page;
}__add_to_swap_cachein swap_state.c
int __add_to_swap_cache(struct page *page, swp_entry_t entry)
{
int error;
struct address_space *address_space;
VM_BUG_ON_PAGE(!PageLocked(page), page);
VM_BUG_ON_PAGE(PageSwapCache(page), page);
VM_BUG_ON_PAGE(!PageSwapBacked(page), page);
page_cache_get(page);
SetPageSwapCache(page);
set_page_private(page, entry.val);
address_space = swap_address_space(entry);
spin_lock_irq(&address_space->tree_lock); // 락
error = radix_tree_insert(&address_space->page_tree, // 트리 삽입
entry.val, page);
if (likely(!error)) {
address_space->nrpages++;
__inc_zone_page_state(page, NR_FILE_PAGES);
INC_CACHE_INFO(add_total);
}
spin_unlock_irq(&address_space->tree_lock); // 언락
if (unlikely(error)) {
VM_BUG_ON(error == -EEXIST);
set_page_private(page, 0UL);
ClearPageSwapCache(page);
page_cache_release(page);
}
return error;
}add_page_to_bufferin swap_state.c
void add_page_to_buffer(swp_entry_t entry, struct page* page){
int tail, head, error=0;
swp_entry_t head_entry;
struct page* head_page;
spin_lock_irq(&prefetch_buffer.buffer_lock);
inc_buffer_tail();
tail = get_buffer_tail();
while(is_buffer_full() && error == 0){
head = get_buffer_head();
head_entry = prefetch_buffer.offset_list[head];
head_page = prefetch_buffer.page_data[head];
if(!non_swap_entry(head_entry) && head_page){
if (PageSwapCache(head_page) && !page_mapped(head_page) && trylock_page(head_page)) {
test_clear_page_writeback(head_page);
delete_from_swap_cache(head_page);
SetPageDirty(head_page);
unlock_page(head_page);
error = 1;
}
else if(page_mapcount(head_page) == 1 && trylock_page(head_page)){
try_to_free_swap(head_page);
unlock_page(head_page);
error = 1;
}
else{
inc_buffer_tail();
tail = get_buffer_tail();
}
}
else {
error = 1;
}
inc_buffer_head();
}
prefetch_buffer.offset_list[tail] = entry;
prefetch_buffer.page_data[tail] = page;
inc_buffer_size();
spin_unlock_irq(&prefetch_buffer.buffer_lock);
}Remote IO
페이지의 입출력 시, 블록 계층으로 수행되는 연산을 원격 인터페이스로 입출력 연산이 이뤄질 수 있도록 페이징 이벤트를 redirect 했다. 앞서 prefetch의 flow에 이어서, 페이지를 스왑해 올 때 remote machine으로 연결되도록 한다.
swap 연산을 remote machine으로 수행하려면, kernel function인 set_process_id를 통해 remote machine의 접근이 가능하도록 하여야 한다.
Flow
swap_readpage&swap_writepagein Page_io.c

Functions
get_process_is: remote machine의 존재 유무 검사sys_is_request: page를 remote machine에 read/write 연산 요청하기 위해 세션 연결을 확인하고 control box와 chunk가 매핑이 된 지 확인한다. rdma device가 제대로 연결이 됐다면IS_transfer_chunk함수를 통해 page 요청을 보낸다.IS_transfer_chunk: 비선점 방식으로 전송할 수 있도록 한다.IS_rdma_write:ibv_post_sent함수를 통해chunk와cb를ctx에 실어서 보낸다.
Data Structures
IS_sessionin leap.h
struct IS_session {
unsigned long int *read_request_count; //how many requests on each CPU
unsigned long int *write_request_count; //how many requests on each CPU
int mapped_cb_num; //How many cbs are remote mapped
struct kernel_cb **cb_list;
struct IS_portal *portal_list;
int cb_num; //num of possible servers
enum cb_state *cb_state_list; //all cbs state: not used, connected, failure
struct IS_connection **IS_conns;
char portal[MAX_PORTAL_NAME];
struct list_head list;
struct list_head devs_list; /* list of struct IS_file */
spinlock_t devs_lock;
struct config_group session_cg;
struct completion conns_wait;
atomic_t conns_count;
atomic_t destroy_conns_count;
unsigned long long capacity;
unsigned long long mapped_capacity;
int capacity_g;
atomic_t *cb_index_map; //unmapped==-1, this chunk is mapped to which cb
int *chunk_map_cb_chunk; //sess->chunk map to cb-chunk
int *unmapped_chunk_list;
int free_chunk_index; //active header of unmapped_chunk_list
atomic_t rdma_on; //DEV_RDMA_ON/OFF
struct task_struct *rdma_trigger_thread; //based on swap rate
unsigned long write_ops[STACKBD_SIZE_G];
unsigned long read_ops[STACKBD_SIZE_G];
unsigned long last_ops[STACKBD_SIZE_G];
unsigned long trigger_threshold;
spinlock_t write_ops_lock[STACKBD_SIZE_G];
spinlock_t read_ops_lock[STACKBD_SIZE_G];
int w_weight;
int cur_weight;
atomic_t trigger_enable;
};kernel_cbin leap.h
struct kernel_cb {
int cb_index; //index in IS_sess->cb_list
struct IS_session *IS_sess;
int server; /* 0 iff client */
struct ib_cq *cq;
struct ib_pd *pd;
struct ib_qp *qp;
enum mem_type mem;
struct ib_mr *dma_mr;
// memory region
struct ib_recv_wr rq_wr; /* recv work request record */
struct ib_sge recv_sgl; /* recv single SGE */
struct IS_rdma_info recv_buf;/* malloc'd buffer */
u64 recv_dma_addr;
DECLARE_PCI_UNMAP_ADDR(recv_mapping)
struct ib_mr *recv_mr;
struct ib_send_wr sq_wr; /* send work requrest record */
struct ib_sge send_sgl;
struct IS_rdma_info send_buf;/* single send buf */
u64 send_dma_addr;
DECLARE_PCI_UNMAP_ADDR(send_mapping)
struct ib_mr *send_mr;
#if LINUX_VERSION_CODE >= KERNEL_VERSION(4, 4, 0)
struct ib_rdma_wr rdma_sq_wr; /* rdma work request record */
#else
struct ib_send_wr rdma_sq_wr; /* rdma work request record */
#endif
struct ib_sge rdma_sgl; /* rdma single SGE */
char *rdma_buf; /* used as rdma sink */
u64 rdma_dma_addr;
DECLARE_PCI_UNMAP_ADDR(rdma_mapping)
struct ib_mr *rdma_mr;
// peer's addr info pay attention
uint64_t remote_len; /* remote guys LEN */
struct remote_chunk_g_list remote_chunk;
char *start_buf; /* rdma read src */
u64 start_dma_addr;
DECLARE_PCI_UNMAP_ADDR(start_mapping)
struct ib_mr *start_mr;
enum test_state state; /* used for cond/signalling */
wait_queue_head_t sem; // semaphore for wait/wakeup
// from arg
uint16_t port; /* dst port in NBO */
u8 addr[16]; /* dst addr in NBO */
char *addr_str; /* dst addr string */
uint8_t addr_type; /* ADDR_FAMILY - IPv4/V6 */
int verbose; /* verbose logging */
int size; /* ping data size */
int txdepth; /* SQ depth */
int local_dma_lkey; /* use 0 for lkey */
/* CM stuff connection management*/
struct rdma_cm_id *cm_id; /* connection on client side,*/
struct rdma_cm_id *child_cm_id; /* connection on client side,*/
/* listener on server side. */
struct list_head list;
};remote_chunk_gin leap.h
struct remote_chunk_g {
uint32_t remote_rkey; /* remote guys RKEY */
uint64_t remote_addr; /* remote guys TO */
int *bitmap_g; //1GB bitmap
};Code
process_idin page_io.c
unsigned long process_id = 0;
void set_process_id(unsigned long __pid){
process_id = __pid;
}
unsigned long get_process_id(){
return process_id;
}sys_is_session_createin leap.c
asmlinkage int sys_is_session_create(const char *portal)
{
int i, j, ret;
char name[20];
g_IS_session = (struct IS_session *) kzalloc(sizeof(struct IS_session), GFP_KERNEL);
printk(KERN_ALERT "In IS_session_create() with portal: %s\n", portal);
submit_queues = num_online_cpus();
mutex_init(&g_lock);
INIT_LIST_HEAD(&g_IS_sessions);
memcpy(g_IS_session->portal, portal, strlen(portal));
pr_err("%s\n", g_IS_session->portal);
portal_parser(g_IS_session);
g_IS_session->capacity_g = STACKBD_SIZE_G;
g_IS_session->capacity = (unsigned long long)STACKBD_SIZE_G * ONE_GB;
g_IS_session->mapped_cb_num = 0;
g_IS_session->mapped_capacity = 0;
g_IS_session->cb_list = (struct kernel_cb **)kzalloc(sizeof(struct kernel_cb *) * g_IS_session->cb_num, GFP_KERNEL);
g_IS_session->cb_state_list = (enum cb_state *)kzalloc(sizeof(enum cb_state) * g_IS_session->cb_num, GFP_KERNEL);
for (i=0; i<g_IS_session->cb_num; i++) {
g_IS_session->cb_state_list[i] = CB_IDLE;
g_IS_session->cb_list[i] = kzalloc(sizeof(struct kernel_cb), GFP_KERNEL);
g_IS_session->cb_list[i]->port = htons(g_IS_session->portal_list[i].port);
g_IS_session->cb_list[i]->addr_str = (char *) kzalloc(strlen(g_IS_session->portal_list[i].addr_str), GFP_KERNEL);
memcpy(g_IS_session->cb_list[i]->addr_str, g_IS_session->portal_list[i].addr_str, strlen(g_IS_session->portal_list[i].addr_str));
in4_pton(g_IS_session->portal_list[i].addr, -1, g_IS_session->cb_list[i]->addr, -1, NULL);
g_IS_session->cb_list[i]->cb_index = i;
}
g_IS_session->cb_index_map = kzalloc(sizeof(atomic_t) * g_IS_session->capacity_g, GFP_KERNEL);
g_IS_session->chunk_map_cb_chunk = (int*)kzalloc(sizeof(int) * g_IS_session->capacity_g, GFP_KERNEL);
g_IS_session->unmapped_chunk_list = (int*)kzalloc(sizeof(int) * g_IS_session->capacity_g, GFP_KERNEL);
g_IS_session->free_chunk_index = g_IS_session->capacity_g - 1;
for (i = 0; i < g_IS_session->capacity_g; i++){
atomic_set(g_IS_session->cb_index_map + i, NO_CB_MAPPED);
g_IS_session->unmapped_chunk_list[i] = g_IS_session->capacity_g-1-i;
g_IS_session->chunk_map_cb_chunk[i] = -1;
}
for (i=0; i < STACKBD_SIZE_G; i++){
spin_lock_init(&g_IS_session->write_ops_lock[i]);
spin_lock_init(&g_IS_session->read_ops_lock[i]);
g_IS_session->write_ops[i] = 1;
g_IS_session->read_ops[i] = 1;
g_IS_session->last_ops[i] = 1;
}
g_IS_session->trigger_threshold = RDMA_TRIGGER_THRESHOLD;
g_IS_session->w_weight = RDMA_W_WEIGHT;
g_IS_session->cur_weight = RDMA_CUR_WEIGHT;
atomic_set(&g_IS_session->trigger_enable, TRIGGER_ON);
g_IS_session->read_request_count = (unsigned long*)kzalloc(sizeof(unsigned long) * submit_queues, GFP_KERNEL);
g_IS_session->write_request_count = (unsigned long*)kzalloc(sizeof(unsigned long) * submit_queues, GFP_KERNEL);
//IS-connection
g_IS_session->IS_conns = (struct IS_connection **)kzalloc(submit_queues * sizeof(*g_IS_session->IS_conns), GFP_KERNEL);
if (!g_IS_session->IS_conns) {
pr_err("failed to allocate IS connections array\n");
ret = -ENOMEM;
goto err_destroy_portal;
}
for (i = 0; i < submit_queues; i++) {
g_IS_session->read_request_count[i] = 0;
g_IS_session->write_request_count[i] = 0;
ret = IS_create_conn(g_IS_session, i, &g_IS_session->IS_conns[i]);
if (ret)
goto err_destroy_conns;
}
atomic_set(&g_IS_session->rdma_on, DEV_RDMA_OFF);
strcpy(name, "rdma_trigger_thread");
g_IS_session->rdma_trigger_thread = kthread_create(rdma_trigger, g_IS_session, name);
wake_up_process(g_IS_session->rdma_trigger_thread);
return 0;
err_destroy_conns:
for (j = 0; j < i; j++) {
IS_destroy_conn(g_IS_session->IS_conns[j]);
g_IS_session->IS_conns[j] = NULL;
}
kfree(g_IS_session->IS_conns);
err_destroy_portal:
return ret;
}swap_readpagein Page_io.c
int swap_readpage(struct page *page)
{
struct bio *bio;
int ret = 0;
struct swap_info_struct *sis = page_swap_info(page);
VM_BUG_ON_PAGE(!PageLocked(page), page);
VM_BUG_ON_PAGE(PageUptodate(page), page);
/* 기존 swap event
if (frontswap_load(page) == 0) {
SetPageUptodate(page);
unlock_page(page);
goto out;
}
*/
// Leap
if (get_process_id() > 0) { // 프로세스가 존재하면
ret = sys_is_request(page, 0); // remote machine에 page read request
if(ret != 0) // 에러 발생 시
goto failed_rdma; // 기존 스왑 방식 사용
count_vm_event(PSWPIN);
return ret;
}
// Leap
failed_rdma: // RDMA 실패 시
if (sis->flags & SWP_FILE) {
struct file *swap_file = sis->swap_file;
struct address_space *mapping = swap_file->f_mapping;
ret = mapping->a_ops->readpage(swap_file, page);
if (!ret)
count_vm_event(PSWPIN);
return ret;
}
ret = bdev_read_page(sis->bdev, swap_page_sector(page), page);
if (!ret) {
count_vm_event(PSWPIN);
return 0;
}
ret = 0;
bio = get_swap_bio(GFP_KERNEL, page, end_swap_bio_read);
if (bio == NULL) {
unlock_page(page);
ret = -ENOMEM;
goto out;
}
count_vm_event(PSWPIN);
submit_bio(READ, bio);
out:
return ret;
}swap_writepagein Page_io.c
int swap_writepage(struct page *page, struct writeback_control *wbc)
{
int ret = 0;
if (try_to_free_swap(page)) {
printk("swap_writepage: tried to free swap but failed\n");
unlock_page(page);
goto out;
}
/* 기존 swap event
if (frontswap_store(page) == 0) {
set_page_writeback(page);
unlock_page(page);
end_page_writeback(page);
goto out;
}
*/
// Leap
if(get_process_id() > 0){
set_page_writeback(page);
unlock_page(page);
count_vm_event(PSWPOUT);
ret = sys_is_request(page, 1); // remote machine에 page write 요청
if (ret != 0) // 실패
ret = __swap_writepage(page, wbc, end_swap_bio_write); // 기존 swap
}
// Leap
else
ret = __swap_writepage(page, wbc, end_swap_bio_write); // 기존 swap
out:
return ret;
}sys_is_requestin leap.c- 기능: remote machine으로 page를 read/write 요청
- 파라미터: page, read/write flag
- 리턴: 0 외엔 err
asmlinkage int sys_is_request(struct page *page, int is_write)
{
int write = is_write; // 읽기 연산 or 쓰기 연산
// ilog2(IS_PAGE_SIZE), 페이지 시작점
unsigned long start = page_private(page) << IS_PAGE_SHIFT;
unsigned long len = IS_PAGE_SIZE; // 4096 = 4KB 페이지 크기
int err = -1;
int gb_index;
unsigned long chunk_offset;
struct kernel_cb *cb; // control box
int cb_index;
int chunk_index;
struct remote_chunk_g *chunk;
int bitmap_i;
gb_index = start >> ONE_GB_SHIFT; // 30
// operation count
if (write) {
spin_lock_irq(&g_IS_session->write_ops_lock[gb_index]);
g_IS_session->write_ops[gb_index] += 1;
spin_unlock_irq(&g_IS_session->write_ops_lock[gb_index]);
} else {
spin_lock_irq(&g_IS_session->read_ops_lock[gb_index]);
g_IS_session->read_ops[gb_index] += 1;
spin_unlock_irq(&g_IS_session->read_ops_lock[gb_index]);
}
cb_index = atomic_read(g_IS_session->cb_index_map + gb_index);
if (cb_index == NO_CB_MAPPED){
//go to disk
printk("cb_index not mapped\n");
return err;
}
//find cb and chunk
chunk_offset = start & ONE_GB_MASK;
cb = g_IS_session->cb_list[cb_index];
chunk_index = g_IS_session->chunk_map_cb_chunk[gb_index];
if (chunk_index == -1){
printk("chunk_index not mapped\n");
return err;
}
chunk = cb->remote_chunk.chunk_list[chunk_index];
if (write){
// if rdma_dev_off, go to disk
if (atomic_read(&g_IS_session->rdma_on) == DEV_RDMA_ON){
err = IS_transfer_chunk(cb, cb_index, chunk_index, chunk, chunk_offset, len, write, page);
}
else {
printk("during write DEV_RDMA_OFF\n");
}
}else{ //read is always single page
if (atomic_read(&g_IS_session->rdma_on) == DEV_RDMA_ON){
bitmap_i = (int)(chunk_offset / IS_PAGE_SIZE);
if (IS_bitmap_test(chunk->bitmap_g, bitmap_i)){ //remote recorded
err = IS_transfer_chunk(cb, cb_index, chunk_index, chunk, chunk_offset, len, write, page);
}else {
printk("remote did not recorded this chunk\n");
return err;
}
}else{
printk("during read DEV_RDMA_OFF\n");
return err;
}
}
if (unlikely(err != 0))
pr_err("transfer failed for swap entry %lu, err: %d at %s\n", page_private(page), err, (write == 1 ? "write":"read"));
return err;
}IS_transfer_chunkin leap.c
int IS_transfer_chunk(struct kernel_cb *cb, int cb_index, int chunk_index, struct remote_chunk_g *chunk, unsigned long offset, unsigned long len, int write, struct page *page)
{
int cpu, retval = 0;
// printk("%s: try to grab cpu\n",__func__);
cpu = get_cpu();
if (write){
retval = IS_rdma_write(cb, cb_index, chunk_index, chunk, offset, len, page);
if (unlikely(retval)) {
pr_err("failed to map sg\n");
goto err;
}
}else{
retval = IS_rdma_read(cb, cb_index, chunk_index, chunk, offset, len, page);
if (unlikely(retval)) {
pr_err("failed to map sg\n");
goto err;
}
}
// printk("%s: releasing cpu %d\n",__func__, cpu);
put_cpu();
return 0;
err:
return retval;
}IS_rdma_writein leap.c
int IS_rdma_write(struct kernel_cb *cb, int cb_index, int chunk_index, struct remote_chunk_g *chunk, unsigned long offset, unsigned long len, struct page *page)
{
int ret;
struct ib_send_wr *bad_wr;
struct rdma_ctx *ctx;
int ctx_loop = 0;
// get ctx_buf based on request address
int conn_id = (uint64_t)(page_address(page)) & QUEUE_NUM_MASK;
struct IS_connection *IS_conn = g_IS_session->IS_conns[conn_id];
// if(!IS_conn->ctx_pools[cb_index]){
// printk("%s: ctx_pools undefined, cb_index:%d\n",__func__, cb_index);
// }
ctx = IS_get_ctx(IS_conn->ctx_pools[cb_index]);
while (!ctx){
if ( (++ctx_loop) == submit_queues){
int s_time = 1;
ctx_loop = 0;
msleep(s_time);
}
conn_id = (conn_id + 1) % submit_queues;
IS_conn = IS_conn->IS_sess->IS_conns[conn_id];
ctx = IS_get_ctx(IS_conn->ctx_pools[cb_index]);
}
ctx->page = page;
ctx->cb = cb;
ctx->offset = offset;
ctx->len = len;
ctx->chunk_ptr = chunk;
ctx->chunk_index = chunk_index;
atomic_set(&ctx->in_flight, CTX_W_IN_FLIGHT);
if (atomic_read(&IS_conn->IS_sess->rdma_on) != DEV_RDMA_ON){
pr_info("%s, rdma_off, give up the write request\n", __func__);
atomic_set(&ctx->in_flight, CTX_IDLE);
IS_insert_ctx(ctx);
return 0;
}
mem_gather(ctx->rdma_buf, page);
if LINUX_VERSION_CODE >= KERNEL_VERSION(4, 4, 0)
ctx->rdma_sq_wr.wr.sg_list->length = len;
ctx->rdma_sq_wr.rkey = chunk->remote_rkey;
ctx->rdma_sq_wr.remote_addr = chunk->remote_addr + offset;
ctx->rdma_sq_wr.wr.opcode = IB_WR_RDMA_WRITE;
#else
ctx->rdma_sq_wr.sg_list->length = len;
ctx->rdma_sq_wr.wr.rdma.rkey = chunk->remote_rkey;
ctx->rdma_sq_wr.wr.rdma.remote_addr = chunk->remote_addr + offset;
ctx->rdma_sq_wr.opcode = IB_WR_RDMA_WRITE;
#endif
ret = ib_post_send(cb->qp, (struct ib_send_wr *) &ctx->rdma_sq_wr, &bad_wr);
if (ret) {
printk(KERN_ALERT "client post write %d, wr=%p\n", ret, &ctx->rdma_sq_wr);
return ret;
}
// printk("rdma_write returning 0\n");
return 0;
}IS_get_ctxin leap.c
static struct rdma_ctx *IS_get_ctx(struct ctx_pool_list *tmp_pool)
{
struct free_ctx_pool *free_ctxs = tmp_pool->free_ctxs;
struct rdma_ctx *res;
unsigned long flags;
spin_lock_irqsave(&free_ctxs->ctx_lock, flags);
if (free_ctxs->tail == -1){
spin_unlock_irqrestore(&free_ctxs->ctx_lock, flags);
return NULL;
}
res = free_ctxs->ctx_list[free_ctxs->tail];
free_ctxs->tail = free_ctxs->tail - 1;
spin_unlock_irqrestore(&free_ctxs->ctx_lock, flags);
return res;
}Eager Eviction
Lead에서 Eviction은 적극적으로 이루어진다. 적극적인 eviction을 통해 prefetch 공간을 마련하기 위해서이다. Leap에서는 그래서 page를 스왑해 올 때마다 캐시 공간을 비우려 한다.
Code
do_swap_pagein swap_state.c
/* Leap added this code
*/
if( get_custom_prefetch() != 0 )
try_to_free_swap(page);
else if (vm_swap_full() || (vma->vm_flags & VM_LOCKED) || PageMlocked(page))
try_to_free_swap(page);
/* Leap
*/try_to_free_swapin swapfile.c
int try_to_free_swap(struct page *page)
{
VM_BUG_ON_PAGE(!PageLocked(page), page);
if (!PageSwapCache(page))
return 0;
if (PageWriteback(page))
return 0;
if (page_swapcount(page))
return 0;
if (pm_suspended_storage())
return 0;
delete_from_swap_cache(page);
SetPageDirty(page);
return 1;
}