개요
개발자 면접 단골질문 중 하나라고 생각을 한다. 복습 겸 정리를 해보려고 한다.
Bubble Sort
말로 설명하기 복잡해, pseudo code로 표현하겠다.
시간 복잡도는 이다.
datas = [a_1, a_2, ..., a_n]
for i in range(n, 0, -1):
for j in range(0, i):
compare a_j and a_j+1. swap value to make proper ordering
Selection Sort
말로 설명하기 복잡해, pseudo code로 표현하겠다.
시간 복잡도는 이다.
datas = [a_1, a_2, ..., a_n]
results = []
for i in range(0, n):
find min value from datas
pop the min value from datas, and append to results
Insertion Sort
말로 설명하기 복잡해, pseudo code로 표현하겠다.
평균 시간 복잡도는 이지만, 최선의 경우 의 시간 복잡도를 가진다.
Insertion Sort는 이미 정렬된 상태에서, element을 insert/delete한 뒤 sorting하는 경우에 대해 최적으로 사용된다.
datas = [a_1, a_2, ..., a_n]
for i in range(1, n+1):
sort a_i among [a_1, a_2, ..., a_i] // just move a_i to proper orderingMerge Sort
Merge Sort는 array를 계속 2등분한다.(크기가 0 혹은 1이 될때까지)
그리고 나뉘어진 array들을 merge하면서, 정렬한다.
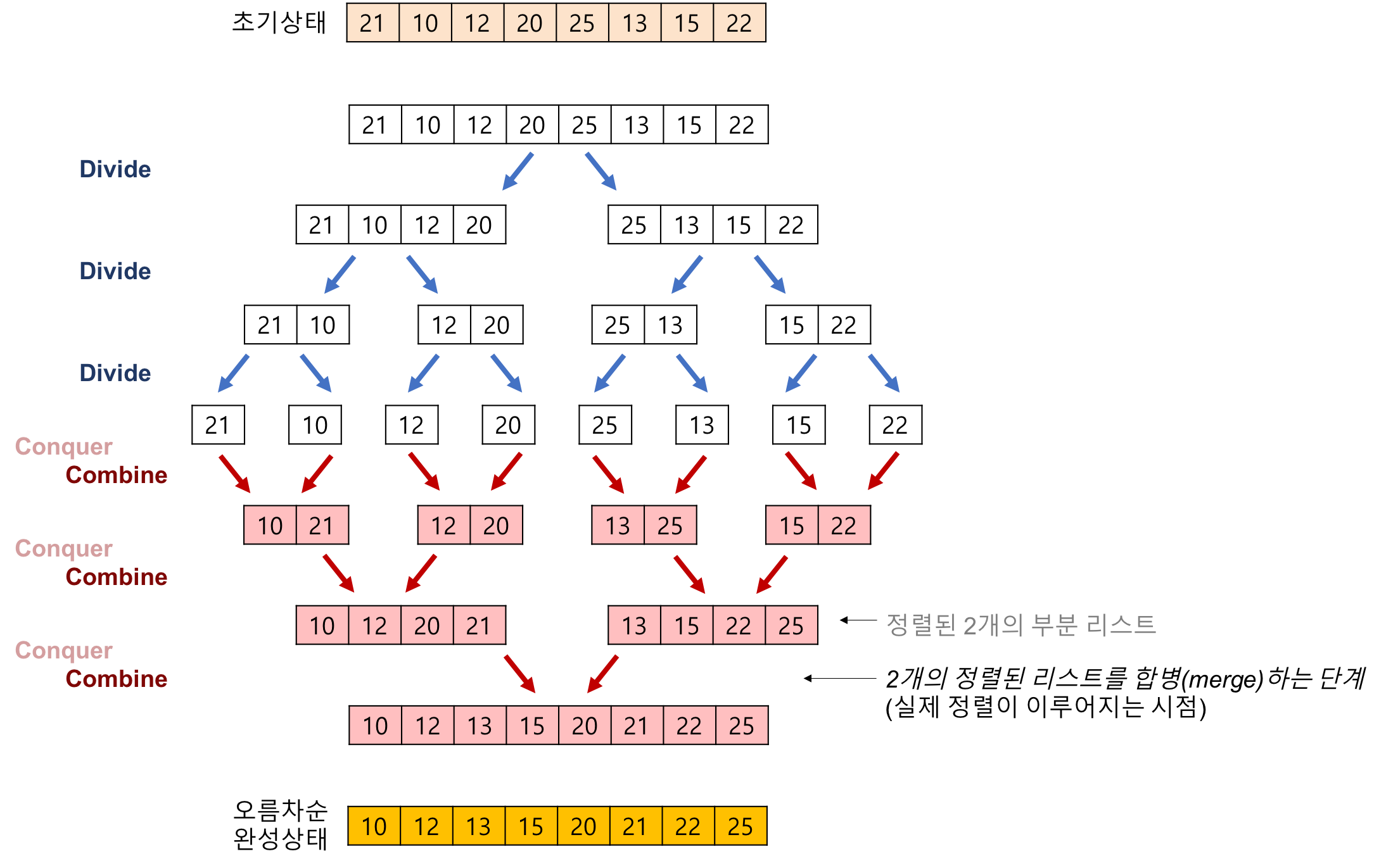
[출처: https://gmlwjd9405.github.io/2018/05/08/algorithm-merge-sort.html]
Merge Sort의 시간 복잡도를 생각할 때, Conquer 부분에서만 생각하면 된다.
각 단계마다 N번의 compare이 일어나야 되고, 단계가 만큼 존재하므로, 시간복잡도는 이다.
Heap Sort
Heap이란, 완전 이진 트리 중에서 우선순위 큐를 위한 조건이 추가된 데이터 구조이다. Max Heap이란, 완전 이진 트리 중에서 parent node의 값이 항상 child node 값보다 큰 경우이다.
우선순위 큐를 구현하는 방법에 대해 알면, Heap Sort을 이해할 수 있다.
주어진 데이터를 Heapify하기 위해서는 이 소요된다. 데이터들로 Max Heap을 구성하면, Pop하면 정렬된 데이터를 얻을 수 있다.
Quick Sort
Quick Sort는 Merge Sort와 마찬가지로, Divide and Conquer 방법을 사용한다.
데이터의 k번째 원소를 pivot으로 지정하고, pivot 값보다 작은 원소를 왼쪽, 큰 원소를 오른쪽에 배치한다.
pivot의 왼쪽과 오른쪽 데이터들에 대해 다시 각각의 pivot을 지정하고 반복하면 된다.
Quick Sort는 최악의 경우(역정렬 되어있고, 1번째 원소를 pivot으로 정하는 경우), 의 시간 복잡도가 발생한다.
하지만 평균적으로는 의 시간복잡도를 가진다.
