
Database 부하분산
부하분산
Stored Processor : 일련의 쿼리를 마치 하나의 함수처럼 실행하기 위한 쿼리의 집합. sql문 필요없이 여러 sql문이 실행되는것.
-> sql성능관련해서 할때 배울것
DB 서버에 장애가 나는건 여러 이유로 날 수 있다. 전체서비스에 장애가 있다는 의미.
배민 우아콘
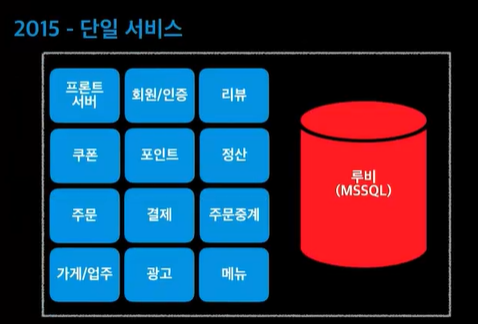
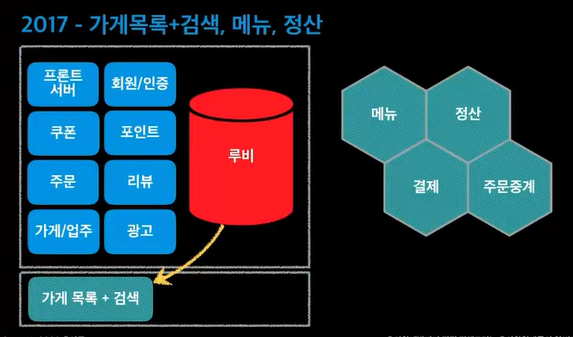
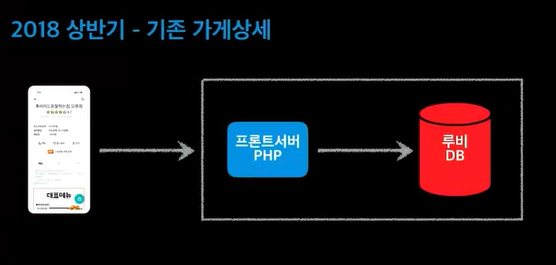
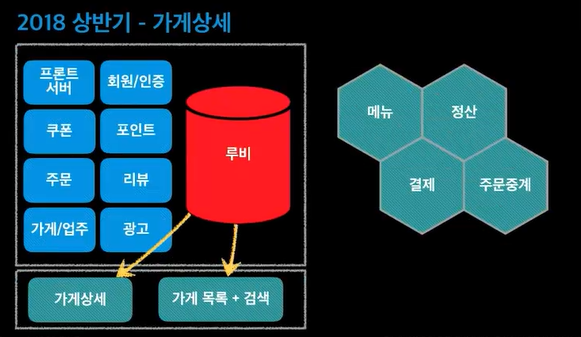
데이터베이스를 하나로 다 사용하고 있었음. 루비DB가 죽으면 다 죽는것!@

부하분산을 잘한 회사의 예는 넷플렉스이다.
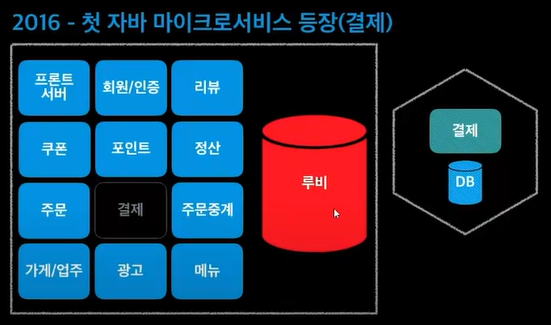
마이크로서비스로 만들면 서버가 하나있고 DB랑 연결이 되는데 자기만의 DB를 가지고 연결한다. 데이터베이스까지 다 분리된것! 육각형으로 그린 이유? 육각형아키텍쳐라고 한다.
부하를 분산시켜놓으면 결제시스템이 죽어도 다른것들을 사용이 가능하다.
부하를 분산시키는 이유
1. 트래픽을 많이 감당하기 위해서
2. 다른서비스는 살아있어서 계속 서비스유지가 가능하다.
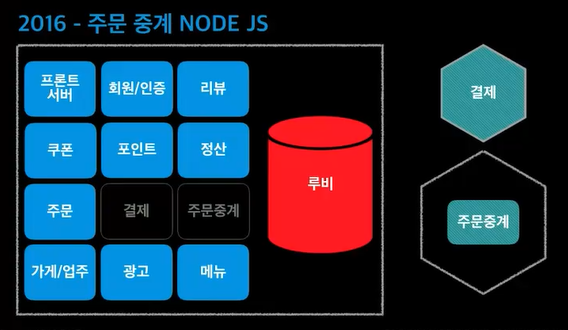
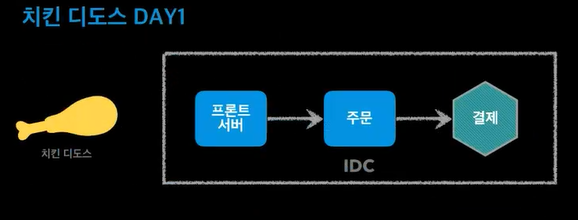
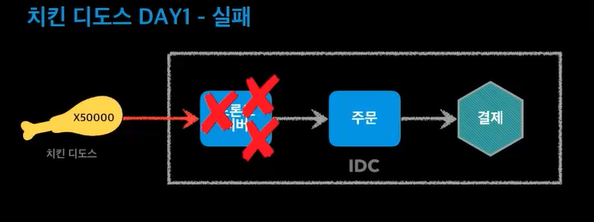
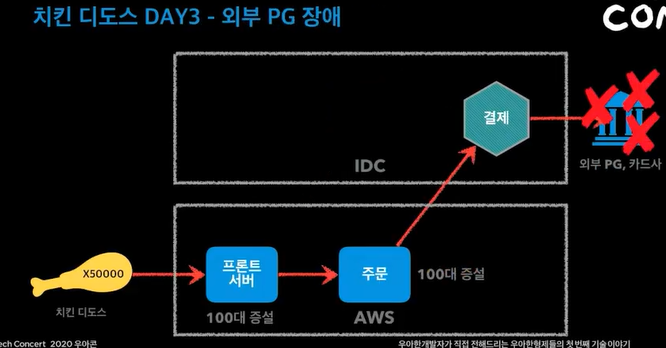
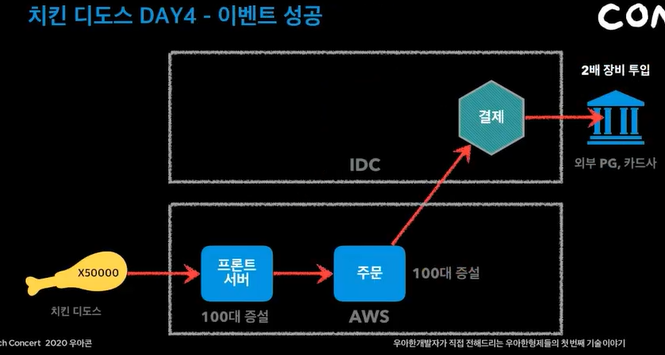
주문량이 너무 많아서 프론트서버가 꺼짐
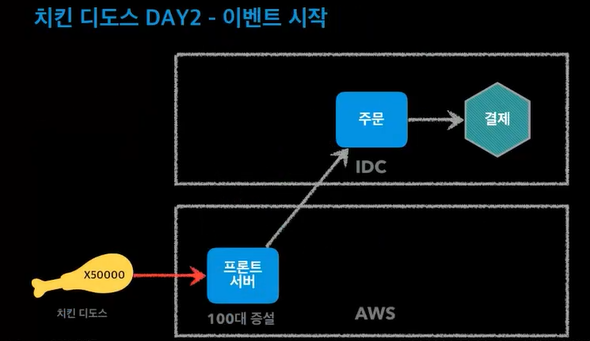
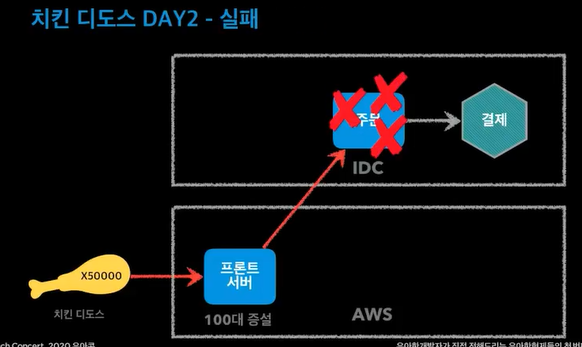
aws클라우드와 IDC 두대로 서버를 분산함
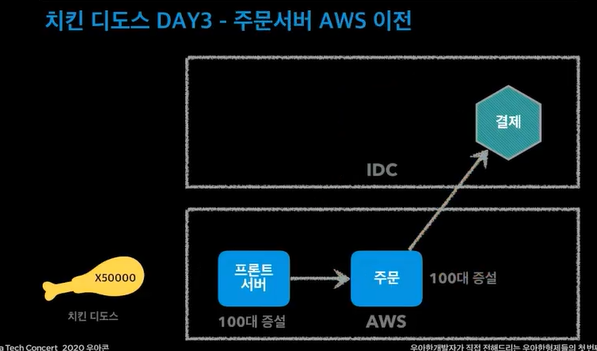

하나의가게가 하나의 광고만 할 수 있었는데, 여러광고를 할 수 있게 하자 였지만 주요장애를 먼저 수정하자가 먼저가 되었음.
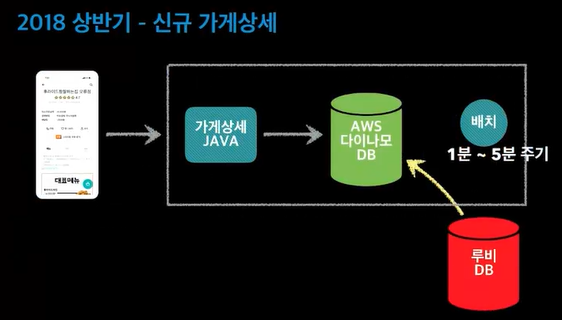
AWS다이나모DB - nosql / mongoDB같은것. 배치처리 - 웹서버를 구성하면 관리자가 끄기전까지는 24/7 켜저있는데 5분주기로 켜져서 자기할일을 하고 꺼지고를 반복한다.
루비DB의 트래픽을 줄였지만 싱크가 느림.

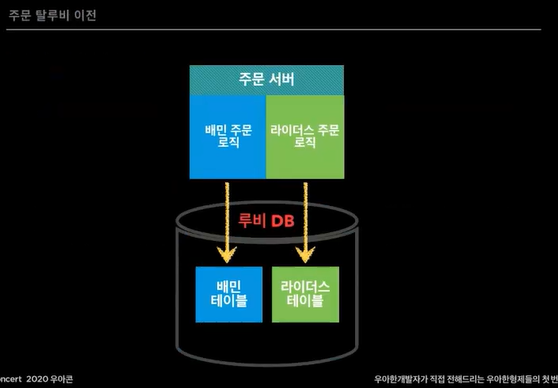
주문이 가장 복잡함.
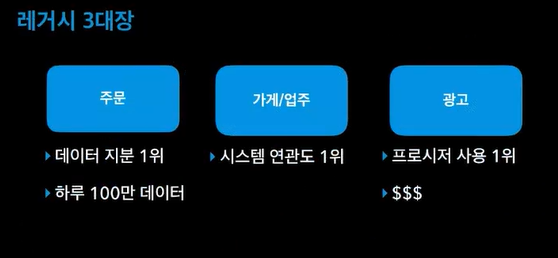
주문 - 데이터지분1위 / 수억개의 데이터
가게/업주 - 시스템연관도1위
광고 - 스토어드 프로시저사용1위
조직이 다르다보니 라이더스주문을 별도로 만들어버림. 합치기도 분리하기도 애매해버림 그러다 통합하기로 결정
부하분산이란?
장애가 발생하더라도 서비스를 유지할 수 있도록 서비스를 만들어야함.
ex) 이중화, 클러스터링
고가용성(HighAvailability) : 서비스를 잘 적응시키는것
서비스를 얼마나 잘 유지했는지 / 복구를 얼마나 빨리할 수 있느냐
- HAProxy
- 재난복구,미러사이트
- Active - Active : 서버가 둘다 실행되고 있다. 복구를 하는데 시간이 걸리지 않음.
- Keepalived
- 핫사이트
- Active-Standby : 서버 하나는 돌아가고 하나는 준비된 상태. Active서버에 문제가 생기면 Standby가 켜지는 것. 다운타임이 조금 발생할 수 있다.
부하분산 실습
1. 웹서버 이중화
준비물)
- 가상머신 3대
: 각 가상머신에 다르게 IP설정 및 vi /etc/hostname 에 들어가서 바꾸고싶은 이름 적고 변경해주기
IP설정 및 이름 변경해주는법
- IP설정
vi 편집기로 들어가서 ip주소 설정을 해준다.
- vi /etc/hostname 로 들어가서
안에 내용물을 다 지운후
원하는 이름을 적어준후 :wq로 저장
Restart guest로 재부팅ㄱ아래그림은 vi /etc/hostname 화면
1. haproxy설정하기
1) haproxy설치
: yum install haproxy2) haproxy 설치설정
vi /etc/haproxy/haproxy.cfg 를 실행 :set number 입력 -> 코드 옆에 숫자가 보이도록
63번째 줄 아래 내용을 다 지우고 아래내용을 추가listen stats bind :9000 -> 9000번 포트로 설정 stats enable stats realm Haproxy\ Statistics stats uri /haproxy_stats -> haproxy_stats 로 uri설정
3) haproxy 실행 및 확인
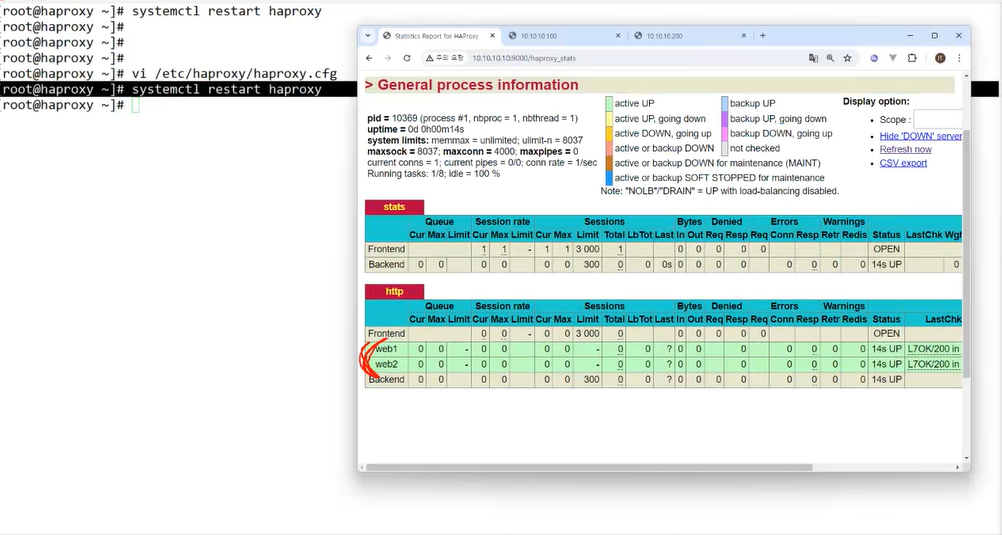
systemctl restart haproxy설치 후에는 돌아가는지 확인 / 방화벽은 항상끄기
윈도우에 웹 브라우저로 [haproxy IP 주소]:9000/haproxy_stats 접속 확인
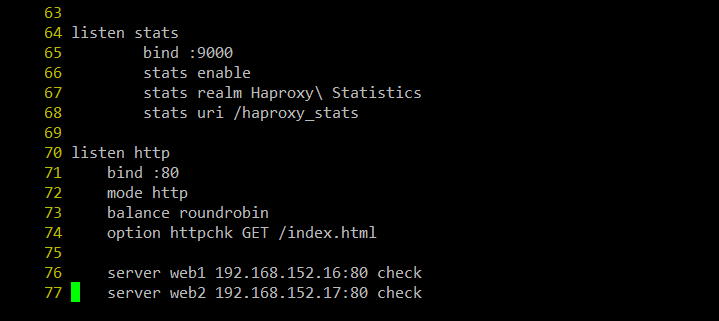
roundrobin - haproxy에 들어가면 들어간 순서대로 할당해주는 알고리즘
httpchk - haproxy가 서버가 죽었는지 체크하는 것
하단의 server머시깽이는 ip랑 포트연결만 잘하면 됌
!! 파일변경을 하면 재시작을 무조건 해야 적용이 된다. 명심!!!
haproxy는 요청을 받아서 보내주는 역할만 해주기 때문에 사양이 높을 필요가 없다. 부하를 분산해주는 역할만 할뿐
2) web1,web2설정하기
- 방화벽끄고
systemctl stop firewalld setenforce 0
- nginx설치
yum install -y nginx
- 웹페이지 수정
vi /usr/share/nginx/html/index.html 안에 있는 내용 전부 삭제 web1 또는 web2 라고 작성
- 웹서버실행
systemctl restart nginx 윈도우에 웹 브라우저로 [각 서버 주소]:80 접속 확인
3) haproxy 설정 추가
1) haproxy 설정
vi /etc/haproxy/haproxy.cfg맨 마지막 줄 밑에 내용 추가
listen http bind :80 mode http balance roundrobin option httpchk GET /index.html server web1 10.10.10.100:80 check server web2 10.10.10.200:80 check2) haproxy 재시작 및 확인
systemctl restart haproxy윈도우에 웹 브라우저로 [haproxy IP 주소]:9000/haproxy_stats 접속 확인
부하분산 테스트
윈도우에 웹 브라우저로 [haproxy IP 주소]:80 접속 확인
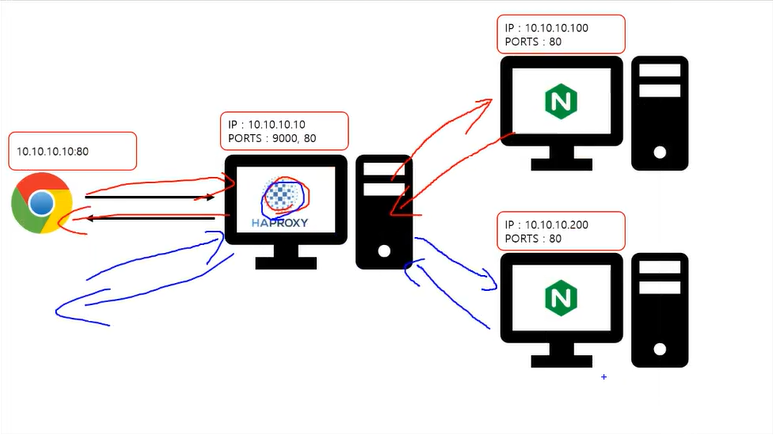
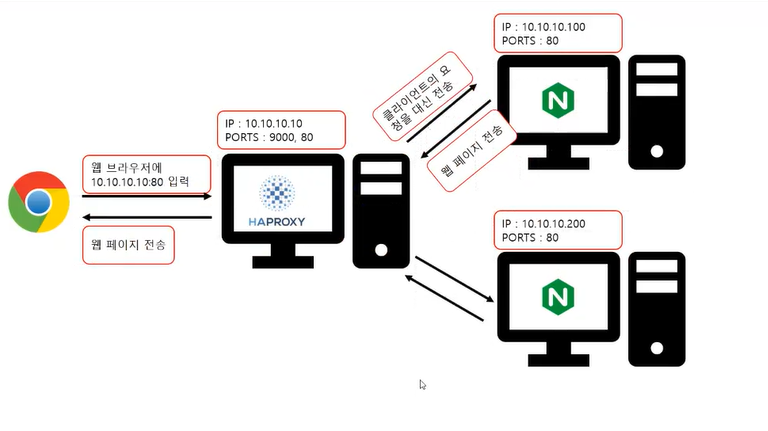
웹브라우저에 10.10.10.10:80을 입력하면 haproxy가 받아서 대신 nginx컴퓨터에 전송하면 웹페이지를 haproxy에게 보내주고 haproxy가 웹페이지를 웹브라우저에 보내준다.
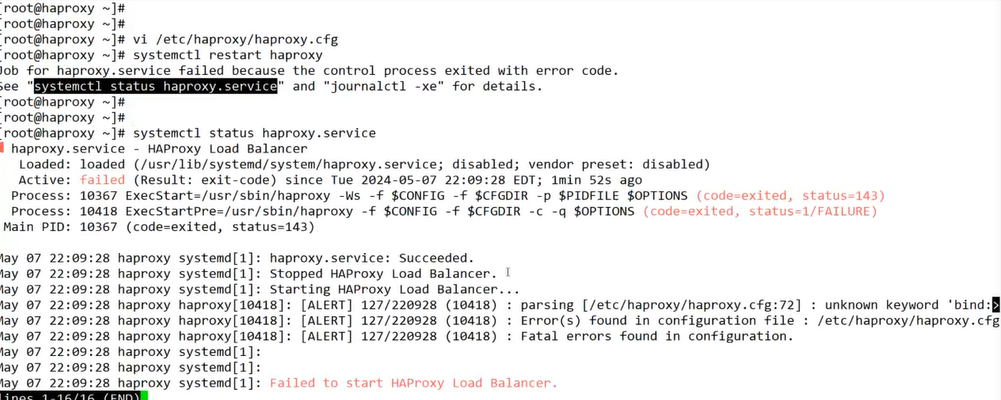
Error가 났을때
cat /var/log/messages는 리눅스에 일어난 모든 로그를 저장해두는 곳이므로 한눈에 찾기는 쉽지않으나 에러까지 다 적혀있음!
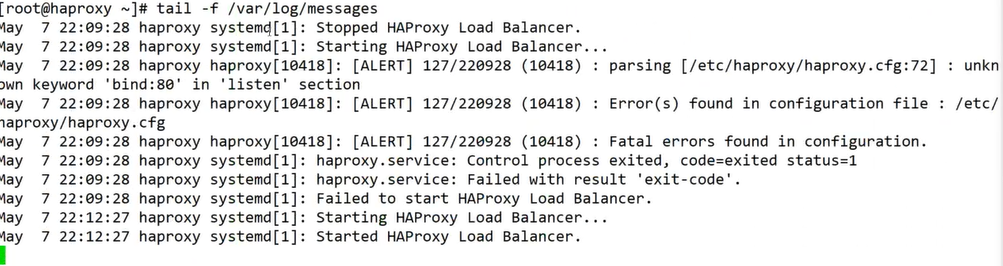
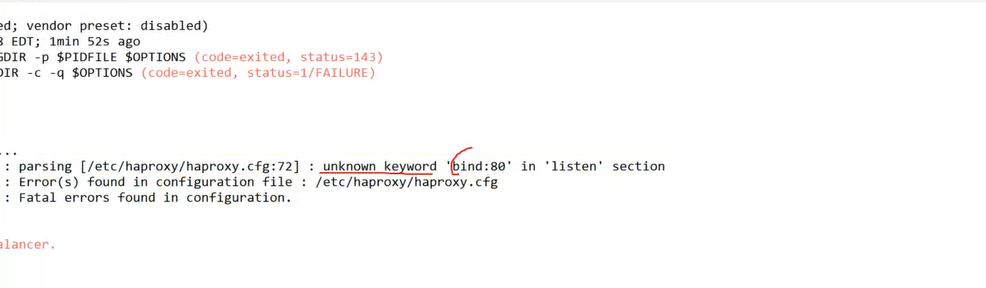
!!에러가 났을때 확인해보기!!
bind에 띄어쓰기를 안해서 에러가 난 상황
/var/log/messages 앞에 tail -f에서 tail은 내용의 마지막부분을 보여주는 명령어. tail에 -f를 붙여주면 계속 마지막 부분을 실시간으로 바라본다.
해당 창에서 엔터로 빈 공간을 만들어주고 새로운 창에 systemctl restart haproxy를 해보면 해당 코드에 실행되는 부분을 보여줌. 수정하고 restart다시해주면 된다.


scp명령어 :
10.10.10.200에 해당 코드내용을 가져와서 남의 컴에 복사붙여넣기 하고싶다. 하면 scp를 사용
Login
Login을 만들때 어떻게 만들까?
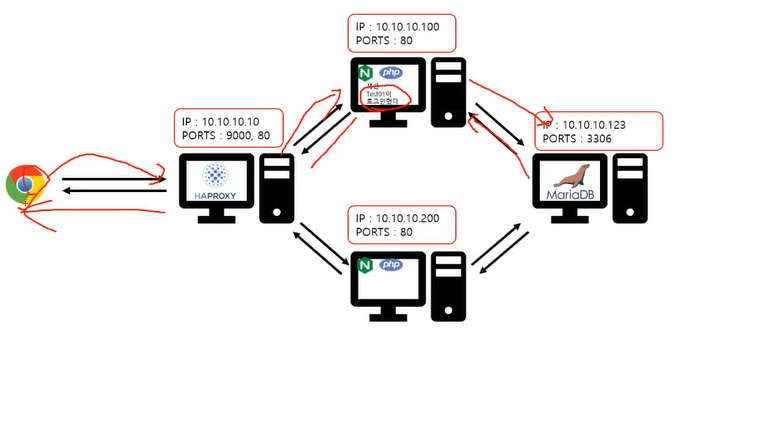
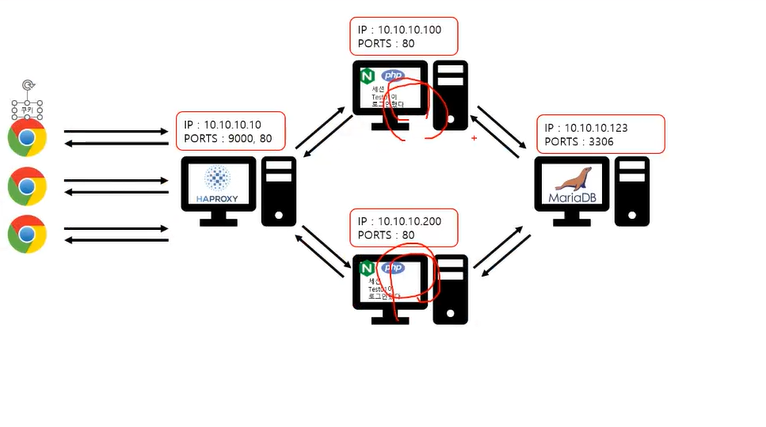
세션 - 메모리에 저장해놓는것 -> db저장보다 속도가 빠름
1. 세션 클러스터링 : 서버를 추가할때마다 세션을 각자 공유하도록 묶어놓기(톰캣서버)
장점 : 세션을 메모리에서 확인하기 때문에 상대적으로 빠르다.
단점 : 서버를 여러대 추가했을때 추가적인 작업을 해줘야한다. 서버의 수만큼 메모리를 복사해줘야하기 때문에 그만큼 메모리가 낭비된다.
Sticky Session(톰캣서버) - 한쪽으로만
장점 : 세션을 메모리에서 확인하기 때문에 상대적으로 빠르다.
단점 : 부하분산이 제대로 안될수도있다.DB에 저장 - db에서만 저장
장점 : 서버가 여러대늘려도 따로 추가할게 없다.
단점 : 사용자가 요청할때마다 db에 조회해줘야함. db에 과부하. HDD를 조회하는 것이기 때문에 상대적으로 느리다캐시서버(Redis)에 저장 - 메모리에 저장
장점 : redis설정만 해놓으면 웹서버가 여러대 늘려도 따로 추가할거 없음
단점 : redis서버관리를 따로 해주어야함.토큰방식(클라이언트에 저장) - JWT토큰 서버저장x, 클라이언트한테만
장점 : 서버에 저장할게 하나도 없다. 서버에 부담이 줄어든다
단점 : 보안에 취약하다.
쿠키는 웹브라우저에 저장된다.
세션 로그인방식 : 세션 + 쿠키(각각의 사용자를 구분하기 위해 사용)
로큰 로그인 방식 : 쿠키
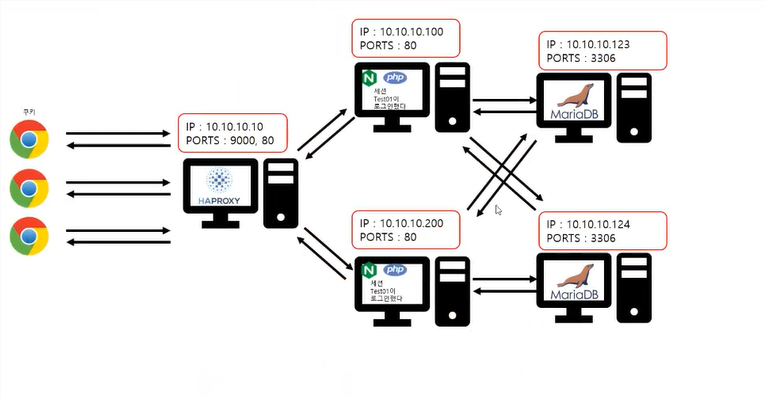

위그림처럼 화살표는 만들기 나름. 클라와 백서버는 서로 나눈다.
Login동작 방식 확인
1) Session Hijacking 확인
웹크라우저 실행해서 웹접속(haproxy) 후 로그인
웹브라우저 쿠키에 로그인 정보가 저장됨
웹브라우저 시크릿탭실행해서 웹접속(haproxy)후 로그인
웹브라우저 쿠키에 원래 웹브라우저의 로그인 정보를 그대로 복붙 후 새로고침
2) DB에 로그인 정보 저장
웹브라우저 실행해서 웹 접속(haproxy) 후 로그인
DB에서 wp_usermeta 테이블 SELECT로 조회해서 확인
DELETE FROM wp_usermeta; 로 로그인 정보 삭제 후 웹 브라우저에서 새로고침으로 확인
DB이중화
Master, Slave설정
DB에 맞는 설정과 DB에 맞는 코드도 따로 있다 (사담)
내부적인 환경설정은 다 비슷하다.
1. Master(기존에 있는 서버)
1) 기존 서버 사용
2) master 설정
vi /etc/my.cnf.d/mariadb-server.cnf
[mariadb]
log-bin
server_id=1
log-basename=master1
binlog-format=mixed [mariadb]: 이거는 추가하는거 아님 이 아래에 입력하기
log-bin : master에서 변경된 내용을 slave 가 받아갈건데 컴퓨터가 알 수 있는 2진수로 저장하겠다(binary-log).
server_id=1 : 서버아이디가 1번이다 라는 의미 / 각 서버마다 다른 아이디로 적어줘야함
log-basename=master1 : log의 이름을 적어준것
binlog-format=mixed : 로그파일을 저장해줄텐데 저장의 형태를 섞어서 쓰겠다.
입력 후
systemctl restart mariadb -> 무언가 변경이 있으면 꼭!!! restart!!!@
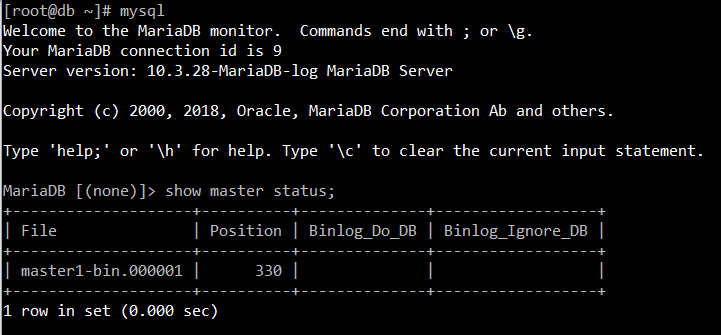
3) master 확인
mysql
show master status;
4) 사용자 추가 및 권한 설정
CREATE USER 'slave_user'@'%' IDENTIFIED BY 'qwer1234';
-> slave_user에 user를 생성할 건데 qwer1234로 비번을 걸거임
GRANT REPLICATION SLAVE ON *.* TO 'slave_user'@'%';
-> 모든 db에 있는 모든 테이블에 slave_user에게 복사할 권리는 부여할거임
5) DB 백업
-> mysql이 아니라 Linux 명령어임!
mysqldump -u root [DB 이름] > web.sql
scp web.sql [SLAVE 서버의 IP]:/root/web.sql 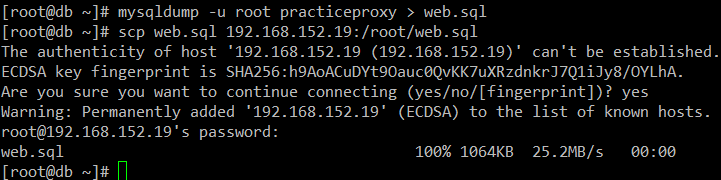
master서버가 slave에 접근할 수 있도록 해주어야한다.
ip주소
포트번호 3306
db이름 slave가 접속할때 쓰는 것을 하나 만들어줄것 / 공유하고싶은 db이름
id
pw
2. Slave(새로만든 db2서버) -> slave에서 master를 확인해서 체크하는 구조
1) DB 서버 프로그램 설치
yum install -y mariadb-server2) DB 서버 프로그램 실행
systemctl start mariadb3) 방화벽 끄기
setenforce 0
systemctl stop firewalld4) DB 생성
mysql
CREATE DATABASE [DB 이름];
exit 5) DB 복구
-> Linux 명령어임!!!!!!!!!!!!!
mysql -u root [DB 이름] < web.sql
-> web.sql안에 있는 sql을 slave[DB이름] 에 넣어준다.6) DB 서버 설정
vi /etc/my.cnf.d/mariadb-server.cnf
[mariadb] <- 이거는 추가하는거 아님
server_id=2 -> id겹치지 않게 잘 설정할것
systemctl restart mariadb7) Master 지정
mysql
-> 그다음에 저장되는건 master에서도 저장되는걸 slave에서도 저장되도록 설정하는 것
CHANGE MASTER TO
MASTER_HOST='[Master 서버 IP]',
MASTER_USER='slave_user',:
MASTER_PASSWORD='qwer1234',
MASTER_PORT=3306,
MASTER_LOG_FILE='[마스터에서 show master status 했을 때 File 이름]',
MASTER_LOG_POS=[마스터에서 show master status 했을 때 position 번호],
MASTER_CONNECT_RETRY=10;
START SLAVE;8) Slave 확인
SHOW SLAVE STATUS\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
mysql -u slave_user -p -u
기존데이터를 백업해서 새로만든 db에도 똑같이 만들어줘야함. 기존 db에 락을 걸고 백업을 하고 다시 락을 풀는 방식으로 백업을 해준다.<내일실습>
읽기전용쓰기전용
DB에서 CRUD할때 SELECT를 가장 많이쓰는데
slave에 더 많이 분산을 어떻게 하는지
active standby하는데 복구하는 시간을 줄이려면 어떻게 해야하나.
