
부하분산
클러스터
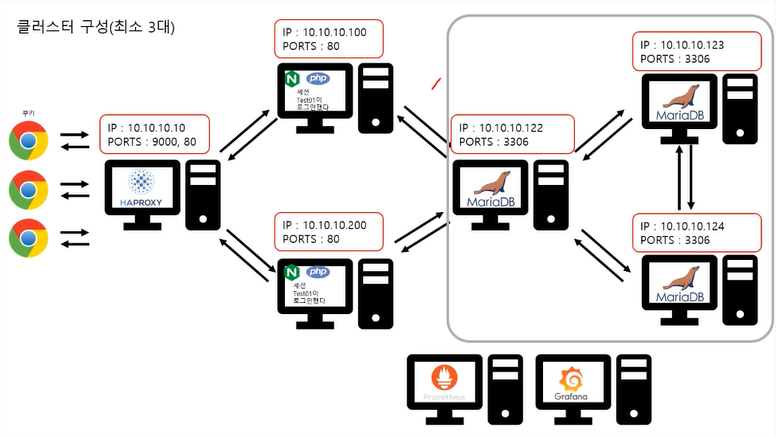
셋이서 저장하는거맞지? 확인하고 동시에 저장한다. 동기식 방식이라고도 부른다.
master slave는 비동기식
마스터슬레이브 에서 master를 쓰기전용 슬레이브를 읽기전용으로 둔다.
보통 마스터에서만 쓰기를 할거고 슬레이브에 천천히 저장이 되어도 상관이없다.
클러스터는 db서버가 100대라고 했을때 100대의 컴퓨터가 다 확인이 되어야 저장이 된다. 100대가 다 확인을 하고 저장을 하기 때문에 안정성은 높을 수 있으나 쓰기 성능이 좋지 않아진다.(마스터슬레이브에 비해서)
노드를 다 연결시키는 것이기 때문에 관리하기가 어렵다.
클러스터의 동작원리
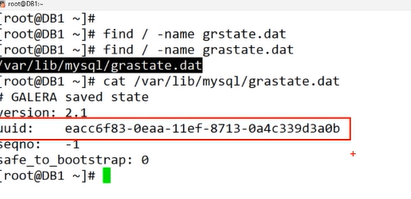
uuid 는 서버이름
seqno 데이터를 다 확인하고 저장할때 트랜잭션이라는 개념이 있는데 그 트랜잭션의 번호 어디까지 저장을 했다는 값
safe to bootstrap 클러스터로 묶인 서버3대중 1대가 장애가 생겼다고 했을때, 장애가 있는 서버만 번호가 다를 것이다.
결국 클러스터도 마스터슬레이브처럼 쓰기전용 읽기전용으로 나누게된다.
꿀팁
처음부터 다 만들어보고, 가고싶은 회사를 처음부터 다 만들어봐라!
면접질문 받은것
swap memory - elastic search에서 swap memory에서 끄고 쓸 수 있다. 쿠버네티스가 가상컴퓨터를 만들어주는데 vmware는 hdd에 저장하는데 도커는 메모리에서 그냥 동작을 하는아이. swap memory도 컴퓨터 기초에 나오는데 hdd는 용량이 많고 느리고 memory는 용량이 작아서 hdd에서 잠시 저장시키고 1,3번을 실행시키다가 2번을 실행시켜야하면 hdd에서 가져와서 실행시킨다. 이때 잠시 저장시키는 메모리가 swap memory이다.
왜 최소 3개로 구성하는지 - 실제 렉 장비로 구성하는데 렉장비가 뻗을 수 있으므로 옆에 2대를 놔둔다.
그럼 한대 죽으면 어떻게 되냐 - 한대가 죽으면 마스터가 누군지를 찾는다. 클러스터가 구성이 되면 투표권이 있어서 지들끼리 투표로 마스터를 정한다.
3대가 다 죽으면? - 서버는 보통 운영망 개발망이 있고 DR(재난복구active-active, active-standby)이 있다면 DR에서 가져와서 빠르게 복구를 해야할 것같다. 그러다 서버가 다 죽으면 답이 없다. 답이없는 이유는 서버에 저장하려고 했던게 다 날라간다는 의미이다.
이런식으로 계속 파고파고 물어본다. 포트폴리오는 회사에 주는 질문지라고 생각하면된다.
SQL 추가문법
view - 개발자편의, 가상테이블, 다담아놓고 하나로 보여주기. 재사용가능. 자신만의 index를 가질 수 없다.
create view as 뷰이름 as 쿼리
index - 성능
stored processor - 성능
mariadb 1대, 프로메테우스, 그라파나,
성능 비교 - 성능측정,
mariadb 1대 설치
DB생성
테이블생성
mariadb 1대 설치 - 0513DB (192.168.152.
30)
hostname : sqlDB
yum install -y mariadb-server
setenforce 0
systemctl stop firewalld
systemctl restart mariadb
로 mariadb설치를 해준다. database, user만들어서 권한 주기
테이블
1:N관계
member 1
이름 데이터type idx 숫자, 자동증가, 기본키 문자 nickname 문자 createdAt(데이터저장시간) datetime post N
이름 데이터type idx 숫자, 자동증가, 기본키 writerdIdx(누가 작성했는지) 숫자, 외래키(member_id) contents 문자 createdAt(데이터저장시간) datetime
view
개발자의 쿼리편의성을 위해서 사용하지만, 딱히 편한지 잘 모름. 기능이 추가되어서 쿼리가 변경이 되어야한다면, 원래 view 의 쿼리를 확인하고 다시 작성해주어야함.
특정조건에서만 삽입삭제가 가능하다.
member 기본키랑 post 기본키가 같으면 에러가 난다.
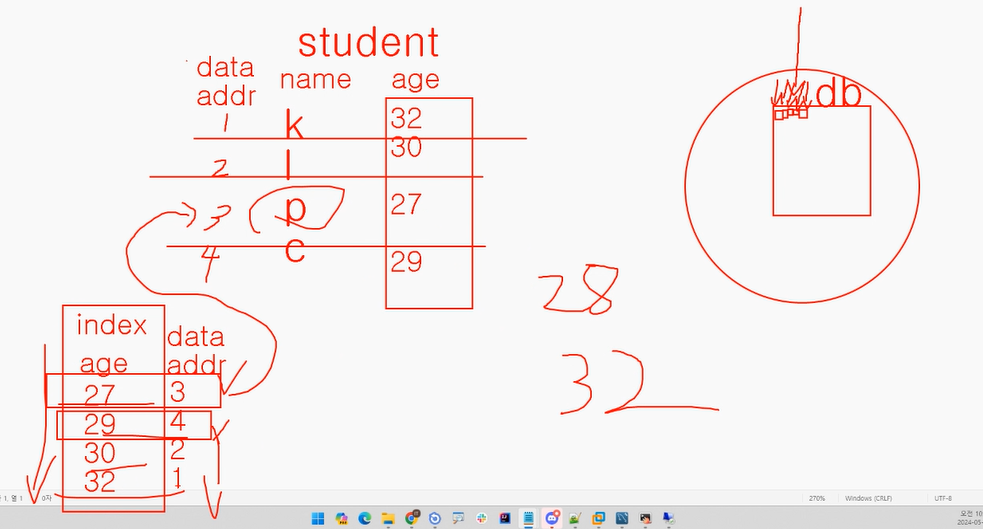
Index
index는 목차. 데이터를 빨리 찾기 위함. database는 모든 데이터를 찾게 되어있다. 조회할때는 상관없지만, 데이터를 삽입하고 수정할때는 성능이 안좋아짐.
세팅하기
member 회원 5명넣기
INSERT
1번 kim
2번 lee
3번 park
4번 choi
5번 sim
post 300백만건!?넣기
mockaroo
비대칭으로 넣기
200백만 4번
25만 1번
25만 2번
25만 3번
25만 5번
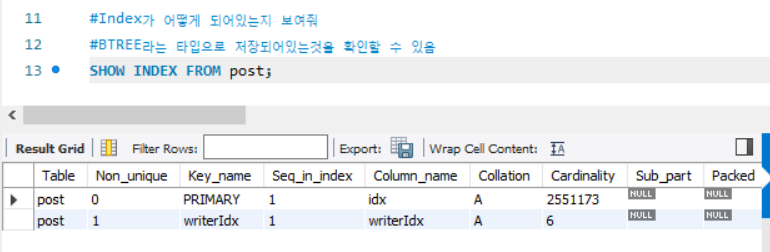
SHOW INDEX FROM post
BTree 타입으로 저장이 되어있어서 빠른것
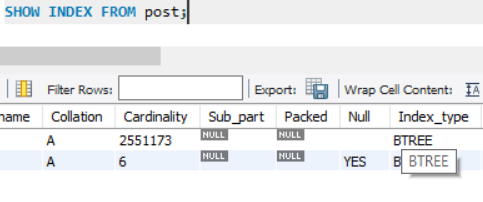
Btree
BTree
데이터를 정렬도 되면서 탐색횟수도 줄일 수 있는 자료구조
참고자료 : BTree Visualization
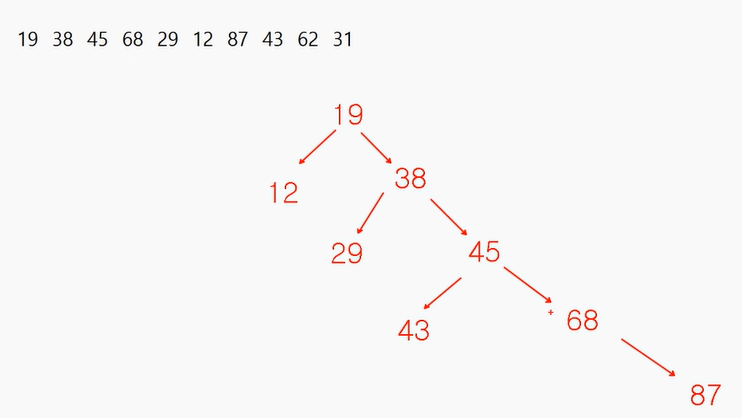
Binary Search Tree구조 - 19보다 크면 오른쪽 작으면 왼쪽
구조에 맞춰서 데이터를 저장하면 데이터를 찾아가는 횟수가 줄어들기 때문에 자료구조에 맞춰 데이터를 저장하는 것.
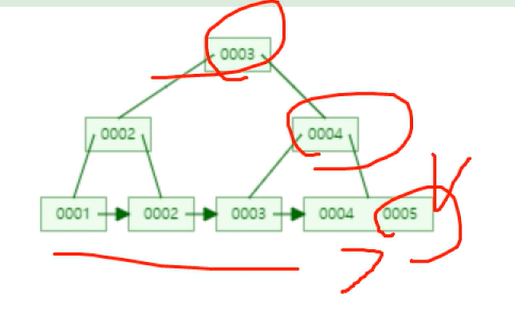
post의 index
idx라는 index
data_addr
데이터가 저장되어있는 형식

이런식으로 저장이 되어있다.

EXPLAIN SELECT writerIdx, count(idx), createdAt as count, createdAt
FROM post USE INDEX(post__index_createdAt) #특정index를 실행을 해라
WHERE writerIdx = 3 AND createdAt BETWEEN '2024-05-06' AND '2024-05-13'
GROUP BY writerIdx, createdAt;USE INDEX 를 넣어주고 wrierIdx,createdAt 이 두가지가 같이있을때 성능이 더 좋아진다.
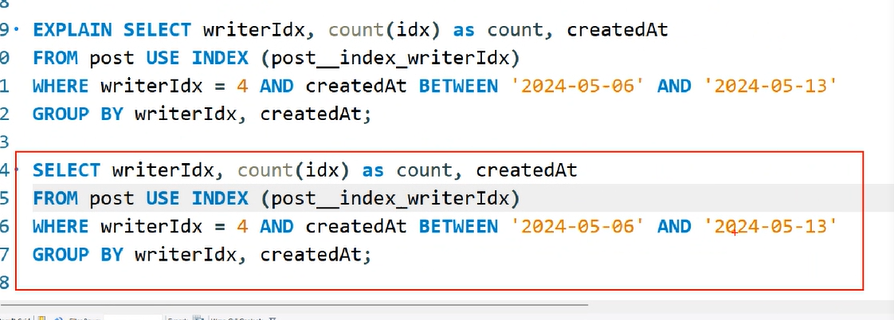
결론 :
Index는 쿼리 조회성능일때만 성능이 좋아진다. 삽입성능은 더 안좋아진다.
Stored Processor
저장되어있는 절차
쿼리 실행시 컴파일의 과정을 거치게 된다.
자주 사용하는 쿼리를 묶어서 컴파일 해놓은 것.
문법
SELECT * FROM member;
############# SP(stored procedure) 설정하기
DELIMITER $$
CREATE PROCEDURE SP_SELECT_member()
BEGIN
SELECT * FROM member;
END $$
DELIMITER ;
##################생성한 sp( stored procedure )사용하기
CALL SP_SELECT_member();
SELECT * FROM member WHERE idx=1;
#숫자를 하나입력받는 SELECT * FROM member WHERE idx = userIdx;의 SP생성
DELIMITER $$
CREATE PROCEDURE SP_SELECT_member2(IN userIdx INT) #userIdx가 어떤값인지 속성을 정해놔야함 여러개도 가능 IN userIdx, writerIdx INT
BEGIN
SELECT * FROM member WHERE idx = userIdx;
END $$
DELIMITER ;
CALL SP_SELECT_member2(2);
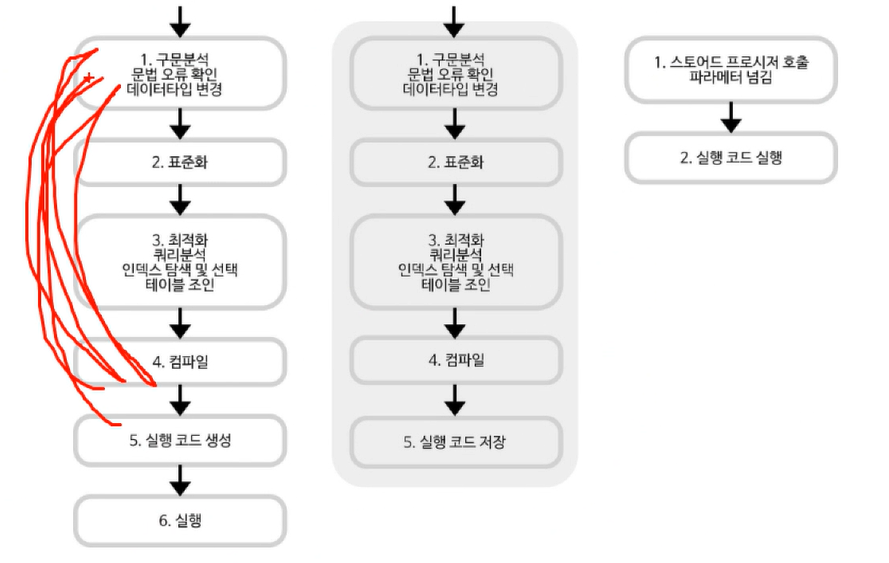
Compile vs Interpreter
Compile : 인간이 알아볼 코드를 컴퓨터가 알아볼 수 있는 코드로 변경해서 변경된코드 실행. 실행할때 꼭 Compiler로 Compile 후 실행 / 코드를 실행파일로 바꾸는것 (윈도우는 txt -> exe로 바꾸고 linux에서는 linux에 맞게 바꾸어주어야한다.) OS마다 컴파일러필요.
Interpreter : 인간이 알아볼 코드를 그대로 실행, 실행할 때 꼭 interpreter가 있어야함
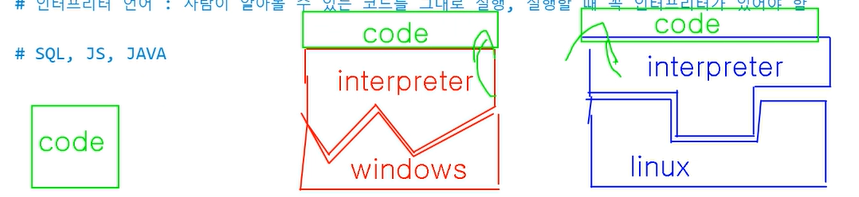
OS에 반드시 interpreter가 설치되어있어야한다. (window에서 java code를 실행시키려면 jdk라는 interpreter를 설치해놓아야 된다. linux에도 interpreter를 설치해놓고 그 위에 code를 실행시키면 compile해서 코드를 실행시켜줌)
SQL(compile)
JS(Interpreter)
JAVA(Interpreter, Compile)
Stored processor는 빨간부분을 저장해놓고 실행시킴.
#SELECT 쿼리생성 -> 성능측정
SELECT writerIdx, count(idx), createdAt as count
FROM post USE INDEX(post__index_writerIdx_createdAt)
WHERE writerIdx < 4 AND createdAt BETWEEN '2024-05-06' AND '2024-05-13'
GROUP BY writerIdx, createdAt;
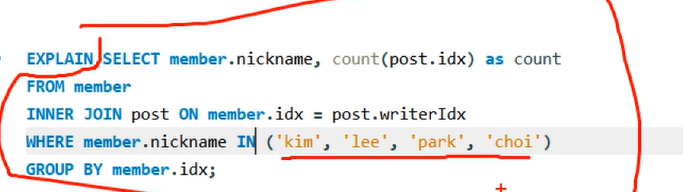
#회원의 이름이 kim,lee,park 3명의 사용자가 작성한 이름별 게시글의 수를 조회
SELECT member.nickname, count(post.idx) as count
FROM member
INNER JOIN post ON member.idx = post.writerIdx
WHERE member.idx <= 4
아니면
WHERE member.nickname = 'kim' OR member.nickname = 'lee' OR member.nickname = 'park' OR member.nickname = 'choi'
아니면
WHERE member.nickname IN ('kim', 'lee', 'park', 'choi')
GROUP BY member.
idx
아니면
GROUP BY member.nickname참조하는 rows의 수가 가장 적은게 성능이 좋은것
type에서 ALL은 가장 성능이 좋지 않은것
이 아이가 가장 성능이 좋은것

SELECT member.nickname, count(post.idx) as count
FROM member
INNER JOIN post ON member.idx = post.writerIdx
WHERE member.nickname IN ('kim', 'lee', 'park', 'choi')
GROUP BY member.idxidx는 기본index가 있으므로 member.nickname으로 GROUP BY하는 건 좋지 않다.
elastic search
그냥 조회를 하면 하나를 통으로 저장하지만 elastic search는 다 나눠서 키워드로 조회가 가능하도록 저장된다.

외래키지우고 인덱스 drop하기
실습을 위한 테이블 준비
CREATE TABLE member
(
idx INT AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(20),
nickname VARCHAR(20),
createdAt DATETIME
);
CREATE TABLE post
(
idx INT AUTO_INCREMENT PRIMARY KEY,
writerIdx INT,
contents VARCHAR(100),
createdAt DATETIME,
FOREIGN KEY (writerIdx) REFERENCES member(idx)
);View
복잡한 쿼리
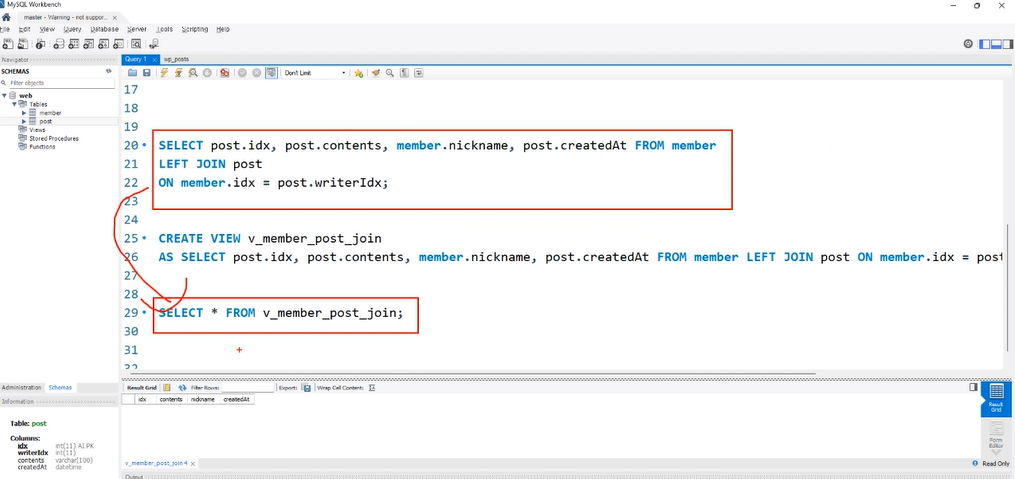
SELECT post.idx, post.contents, member.nickname, post.createdAt FROM member
LEFT JOIN post
ON member.idx = post.writerIdx;뷰 생성
CREATE VIEW v_member_post_join
AS
SELECT post.idx, post.contents, member.nickname, post.createdAt
FROM member LEFT JOIN post ON member.idx = post.writerIdx;뷰를 통해 간단해진 쿼리
SELECT * FROM v_member_post_join;실습을 위한 데이터 준비
회원 추가
INSERT INTO `web`.`member`
(`email`,`nickname`,`createdAt`)
VALUES
('kim@test.com', 'kim', '2024-05-13 11:09:00'),
('lee@test.com', 'lee', '2024-05-13 11:09:00'),
('park@test.com', 'park', '2024-05-13 11:09:00'),
('choi@test.com', 'choi', '2024-05-13 11:09:00'),
('sim@test.com', 'sim', '2024-05-13 11:09:00');회원 확인
SELECT * FROM `web`.`member`;SQL 파일로 post 테이블에 데이터 삽입
워크벤치 -> Server 메뉴 -> Data Import -> Import from Self-Contained File 체크 -> 자료실에서 받은 sql 파일 선택 -> Start Import 클릭
post 테이블에서 사용자별 작성 게시글의 수 확인
SELECT writerIdx, count(idx)
FROM post
GROUP BY writerIdx;4번 사용자가 작성한 글 전체 조회
SELECT *
FROM web.post
WHERE writerIdx = 2 LIMIT 10;post 테이블의 데이터

EXPLAIN : 쿼리의 실행 계획 조회
- const : WHERE 조건에서 상수와 일치하는 행을 찾을 때 사용
-> const가 가장빠르다. 정확한 조건에 딱맞는거만 찾을때- ref : 키에 의해 레코드를 읽는데 사용
- range : 인덱스에서 범위를 스캔하여 해당하는 행을 찾는데 사용
- all : 전체 테이블을 스캔하여 모든 행을 검색하는데 사용
-> all이 가장느리다. 테이블 모든행을 다 뒤져보는것.
EXPLAIN SELECT * FROM post WHERE idx=1;
EXPLAIN SELECT * FROM post WHERE writerIdx<=2; post 테이블에 생성된 인덱스 확인
SHOW INDEX FROM post;인덱스 생성 전 비교할 쿼리 실행 계획, row 수 확인
EXPLAIN SELECT writerIdx, count(idx) as count, createdAt
FROM post
WHERE writerIdx = 4 AND createdAt BETWEEN '2024-05-06' AND '2024-05-13'
GROUP BY writerIdx, createdAt;인덱스 생성 전 쿼리 실행해서 실행 시간 확인
SELECT writerIdx, count(idx) as count, createdAt
FROM post
WHERE writerIdx = 4 AND createdAt BETWEEN '2024-05-06' AND '2024-05-13'
GROUP BY writerIdx, createdAt;다양한 인덱스 생성
CREATE INDEX post__index_writerIdx_createdAt
ON post (writerIdx, createdAt);
CREATE INDEX post__index_writerIdx
ON post (writerIdx);
CREATE INDEX post__index_createdAt
ON post (createdAt);인덱스 생성 후 비교할 쿼리 실행 계획, row 수 확인
EXPLAIN SELECT writerIdx, count(idx) as count, createdAt
FROM post
USE INDEX (post__index_writerIdx_createdAt)
WHERE writerIdx = 4 AND createdAt BETWEEN '2024-05-06' AND '2024-05-13'
GROUP BY writerIdx, createdAt;인덱스 생성 후 쿼리 실행해서 실행 시간 확인
SELECT writerIdx, count(idx) as count, createdAt
FROM post
USE INDEX (post__index_writerIdx_createdAt)
WHERE writerIdx = 4 AND createdAt BETWEEN '2024-05-06' AND '2024-05-13'
GROUP BY writerIdx, createdAt;스토어드 프로시저
컴파일 언어 VS 인터프리터 언어
컴파일 언어 : 사람이 알아볼 수 있는 코드를 컴퓨터가 알아볼 수 있는 코드로 변경하고 변경된 코드를 실행
실행할 때 꼭 컴파일러로 컴파일 후 실행
인터프리터 언어 : 사람이 알아볼 수 있는 코드를 그대로 실행, 실행할 때 꼭 인터프리터가 있어야 함
ex) SQL, JS, JAVA
스토어드 프로시저 문법
DELIMITER $$ # ; = DELIMITER / $$부분은 변경가능 끝낸다는 의미
CREATE PROCEDURE SP이름 (IN 또는 Out 속성)#어떤값을 넣을수도, 나가게할수도있는 속성 / 없어도 되는 속성
BEGIN
쿼리 #COMPILE시키고싶은 쿼리를 적는다.
END $$
DELIMITER; #;로 원래대로 돌려놓기
# SELECT * FROM member; 에 대한 SP 생성
DELIMITER $$
CREATE PROCEDURE SP_SELECT_member ()
BEGIN
SELECT * FROM member;
END $$
DELIMITER ;
# 생성한 SP를 사용
CALL SP_SELECT_member();
# 숫자를 하나 입력 받는 SELECT * FROM member WHERE idx = userIdx; 에 대한 SP 생성
DELIMITER $$
CREATE PROCEDURE SP_SELECT_member2 (IN userIdx INT)
BEGIN
SELECT * FROM member WHERE idx = userIdx;
END $$
DELIMITER ;
CALL SP_SELECT_member2(2);SELECT 쿼리 생성 -> 성능 개선
문제 : 회원의 이름이 K, L, P 3명의 사용자가 작성한 게시글의 수와 사용자 이름을 조회
SHOW INDEX FROM post;
EXPLAIN SELECT member.nickname, count(post.idx) as count
FROM member USE INDEX(PRIMARY)
INNER JOIN post ON member.idx = post.writerIdx
WHERE member.nickname = 'kim' OR member.nickname = 'lee' OR member.nickname = 'park' OR member.nickname = 'choi'
GROUP BY post.writerIdx;
EXPLAIN SELECT member.nickname, count(post.idx) as count
FROM member USE INDEX(PRIMARY)
INNER JOIN post ON member.idx = post.writerIdx
WHERE member.nickname IN ('kim', 'lee', 'park', 'choi')
GROUP BY member.nickname;
SELECT member.nickname, count(post.idx) as count
FROM member
INNER JOIN post ON member.idx = post.writerIdx
WHERE member.nickname IN ('kim', 'lee', 'park', 'choi')
GROUP BY member.nickname;
CREATE INDEX member__index_nickname ON member(nickname);
SELECT member.nickname, count(post.idx) as count
FROM member USE INDEX(member__index_nickname)
INNER JOIN post USE INDEX(post__index_createAt) ON member.idx = post.writerIdx
WHERE member.nickname IN ('kim', 'lee', 'park', 'choi')
GROUP BY member.nickname;