Q2. 다음 중 오라클 백그라운드 프로세스에 대한 설명으로 가장 부적절한 것을 고르시오.
- System Monitor(SMON) : 장애가 발생한 시스템을 재기동할 때 인스턴스 복구를 수행하고, 임시 세그먼트와 익스텐트를 모니터링한다.
- Process Monitor(PMON) : 이상이 생긴 프로세스가 사용하던 리소스를 복구한다.
- Database Writers(DBWR) : 버퍼캐시에 있는 Dirty 버퍼를 데이터파일에 기록한다.
- Log Writer(LGWR) : 로그 버퍼에 로그를 기록한다.
- 오라클 백그라운드 프로세스
- System Monitor(SMON) : 장애가 발생한 시스템을 재기동할 때 인스턴스 복구를 수행하고, 임시 세그먼트와 익스텐드를 모니터링
- Process Monitor(PMON) : 이상이 생긴 프로세스가 사용하던 리소스를 복구
서버 프로세스가 작업 도중 비정상저긍로 종료 시, 해당 프로세스가 사용하던Transcaction Table Rollback,lock 및 자원 할당 해제- Database Writers(DBWR) : 버퍼캐시에서 변경된 블록 (
Dirty 블록)을 모아 주기적으로데이터파일에 일괄 기록- Log Writer(LGWR) : 로그 버퍼 엔트리를 Redo 로그 파일에 기록
Redo 로그 파일에 기록하기 전 로그 버퍼에 먼저 기록,로그 버퍼에 기록한 내용은 LGWR 프로세스가Redo 로그파일에 일괄(Batch) 기록- Archiver(ARCn) :
Archive Log Mode로 데이터베이스를 운영할 경우, 가득 찬 Redo 로그가 덮어 쓰여지기 전에 Archive 로그 디렉토리로 백업- Checkpoint(CKPT) : 버퍼캐시와 데이터파일 동기화 시점 관리. 장애 발생 시 체크포인트 이후의 로그 데이터만 디스크에 기록하여 인스턴스 복구 용도로 사용.
이전에 Checkpoint가 일어났던 마지막 시점 이후의 데이터베이스 변경 사항을 데이터파일에 기록하도록 트리거링, 기록이 완료되면 현재 어디까지 기록했는지Control File과Data File Header에 저장. Write Ahead Logging 방식 오라클은 데이터를 변경하기 전에 항상 로그부터 기록
(선)LGWR 프로세스가 Redo 로그 파일에 로그 기록 → Checkpoint 신호 전달 → (후)DBWR 프로세스가 Dirty 블록을 디스크에 기록- Recoverer(RECO) : 분산 트랜잭션 과정에서 장애 발생 시
Transaction 복구 작업수행
Q5. 다음 중 오라클이 Undo를 사용하는 목적과 가장 거리가 먼 것을 고르시오.
- Transaction Rollback
- Transaction Recovery
- Read Consistency
- Fast Commit
- Undo의 용도
Oracle은Insert,Update,Delete시 Undo 세그먼트에 기록을 남긴다. Undo 공간은 해당 트랜잭션이Commit순간, 다른 트랜잭션이 재활용할 수 있는 상태로 바뀐다.
- Transaction Rollback : 트랜잭션에 의한 변경사항을
Commit하지 않고Rollback하고자 할 때- Transaction Recovery :
Instance Crash발생 후 Redo를 이용해Roll forward단계가 완료되면 최종Commit되지 않은 변경사항까지 모두 복구된다. 즉, 시스템이 셧다운된 시점에 아직 커밋되지 않은 트랜잭션을 모두Rollback할 때- Read Consistency : 사용자들에게 가장 최근에 Commit된 데이터를 보여주는 것. Oracle 외 DBMS Oracle 외 DBMS는 Row Lock을 사용하여 Read Consistency 구현
Q6. 다음 중 Redo 로그에 대한 설명으로 가장 부적절한 것을 고르시오.
- Online Redo 로그는 최소 두 개 이상의 파일로 구성해야 하며, 로그 스위치 주기는 빠를수록 좋다.
- Online Redo 로그는 인스턴스가 비정상적으로 종료되었을 때 캐시를 복구하기 위해 사용된다.
- Archived(=Offline) Redo 로그는 물리적인 저장 매체에 문제가 생겼을 때 데이터베이스를 복구하기 위해 사용된다.
- 대부분 DBMS는 Redo 로그를 이용해 Fast Commit을 구현한다.
- Redo의 용도
- Database Recovery : 물리적 장애 발생 시
Online Redo 로그를 백업해 둔Archived Redo로 복구. 'Media Recovery'라고도 한다.- Cache Recovery : 휘발성 캐시에 저장된 변경사항이 디스크 상의 데이터 블록에 아직 기록되지 않은 상태에서 인스턴스가 비정상으로 종료되는 트랜잭션 유실에 대비. 'Instance Recovery'라고도 한다.
- Fast Commit : 아직 디스크에 기록하지 않았지만,
Redo 로그를 믿고 빠르게Commit을 완료
동시에 많은 트랜잭션이 몰려 로그 스위치가 너무 자주 발생하면, 백업(Archive)를 완료하지 못한 Online Redo 로그로 스위칭이 일어나면서 DB hang이 발생할 수 있다. 적절한 크기와 개수의 Redo 파일을 할당해야 한다.
Q7. 다음 중 Redo 매커니즘과 관련이 적은 것을 고르시오.
- Log Force at Commit
- Write Ahead Logging
- Snapshot Too Old
- Fast Commit
- Redo 매커니즘
- Log Force at Commit :
LGWR프로세스는 서버 프로세스가Commit신호를 보내면,Redo 로그 버퍼를Redo 로그 파일에 기록. 메모리상의 로그 버퍼는 언제든 유실될 가능성이 있기 때문에, 트랜잭션의 영속성을 보장하려면 최소한 Commit 시점에는 로그를메모리가 아닌데이터파일에 안전하게 기록해야 한다.- Write Ahead Logging : 데이터를 변경하기 전에 항상 로그부터 기록.
- Fast Commit : 사용자의 갱신내용이 휘발성인 메모리상의
버퍼캐시에만 기록한 채 아직 디스크에 영구 기록하지 않았지만,Redo 로그를 믿고 빠르게Commit을 완료한다는 의미. Commit 정보까지 로그파일에 기록했다면, Instance Crush가 발생하더라도Redo 로그를 이용해 복구 가능
- Snapshot Too Old
MVCC Model의Consistent mode에서 데이터를 읽는 도중 다른 트랜잭션에 의해 변경되었거나 변경 중인 블록을 만나면,Undo 정보를 이용하여 과거 시점으로 되돌린CR Copy블록을 만들어 읽는다. 필요한 Undo 블록이 다른 트랜잭션에 의해 재활용 된 상태면CR Copy를 생성할 수 없어 'Snapshot Too Old'error가 발생한다.
Q8. 오라클 SGA 구성요소가 아닌 것을 고르시오.
- 버퍼 캐시
- 딕셔너리 캐시
- 로그 버퍼
- Sort Area
Sort Area는 PGA에 할당
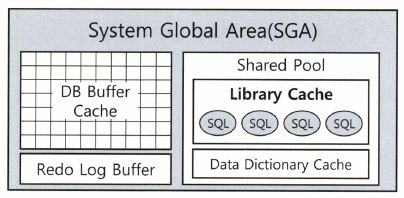
Q9. 다음 중 오라클이 사용하는 메모리 캐시에 대한 설명으로 가장 부적절한 것을 고르시오.
- DB 버퍼 캐시 : 테이블 블록, 인덱스 블록, Undo 블록
- 라이브러리 캐시 : DB 저장형 함수/프로시저, 트리거
- 딕셔너리 캐시 : SQL, 테이블 정보, 인덱스 정보, 데이터파일 정보, 시퀀스
- Result 캐시 : SQL 결과 집합
SQL은 라이브러리 캐시에 캐싱
Q11. 다음 중 SQL 언어의 특징과 거리가 먼 것을 고르시오.
- 구조적(Structured)
- 집합적(Set-based)
- 선언적(Declarative)
- 절차적(procedural)
PL/SQL, SQL server T-SQL와 같은 절차적(procedural) 프로그래밍 기능 구현이 가능한 확장 언어도 제공하지만, SQL은 기본적으로 구조적, 집합적, 선언적인 질의 언어다.
Q17. 다음 중 옵티마이저 힌트가 정상적으로 잘 작동하는 것을 고르시오.
SELECT /*+ INDEX(E, EMP_X01) INDEX(D, DEPT_X03) */ * FROM EMP E, DEPT D WHERE E.DEPTNO = D.DEPTNO AND E.SAL >= 3000SELECT /*+ INDEX(E), FULL(D) */ * FROM EMP E, DEPT D WHERE E.DEPTNO = D.DEPTNO AND E.SAL >= 3000SELECT /*+ FULL(SCOTT.EMP) */ EMPNO, ENAME FROM EMP WHERE SAL >= 3000SELECT /*+ FULL(EMP) */ EMPNO, ENAME FROM EMP WHERE SAL >= 3000
- 옵티마이저 힌트 사용
- 힌트 내에 인자를 나열할 땐
,(콤마)를 사용할 수 있지만, 힌트와 힌트 사이에는 사용할 수 없다.- 테이블을 지정할 때 스키마명까지 명시하면 안된다.
- FROM 절 테이블명 옆에 ALIAS를 지정했다면, 힌트에도 반드시 ALIAS를 사용해야 한다.
Q19. 다음 중 블록 단위로 I/O 하지 않는 오퍼레이션을 고르시오.
- 테이블 및 칼럼 정보를 딕셔너리 캐시에 적재할 때
- 파일에 저장된 데이터 블록을 DB 버퍼캐시로 적재할 때
- DB 버퍼캐시에서 데이터 블록을 읽고 쓸 때
- DB 버퍼캐시에서 변경된 데이터 블록을 파일에 쓸 때
I/O는 블록 단위.
즉, 하나의 레코드를 읽더라도 레코드가 속한 블록 전체를 읽는다.
Q21. 다음 중 메모리 버퍼캐시를 경유하지 않는 블록 I/O 오퍼레이션을 고르시오.
- 인덱스 루트 블록을 읽을 때
- 인덱스 루트 블록에서 얻은 주소 정보로 브랜치 블록을 읽을 때
- 인덱스 리프 블록에서 얻은 주소 정보로 테이블 블록을 읽을 때
- 병렬 프로세스로 테이블 블록을 Full Scan 할 때
대량 데이터는 버퍼캐시에서 블록을 찾기 어려워 재사용성이 낮고, 이를 디스크에서 버퍼캐시에 적재하고 읽어야 하는 부담이 존재한다.
Direct Path I/O 작동 경우
1. 병렬 쿼리로 Full Scan 수행
2. 병렬 DML 수행
3.Direct Path Insert수행
4. Temp 세그먼트 블록들을 읽고 쓸 때
5.direct옵션을 지정하고 export 수행
6.nocache옵션을 지정한 LOB 칼럼 읽을 때
Q22. 아래 SQL 트레이스 정보를 이용해서 버퍼캐시 히트율을 구하시오.
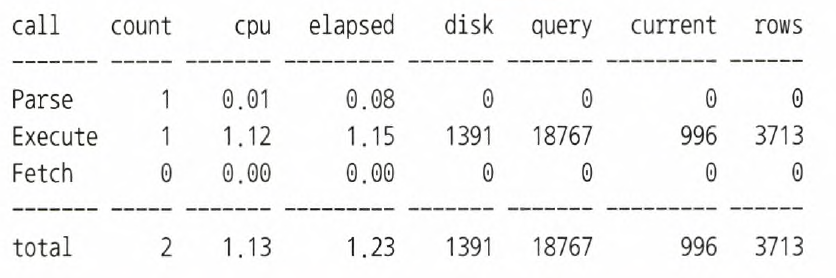
버퍼캐시 히트율 (Buffer Cache Hit Ratio, BCHR)
= (캐시에서 곧바로 찾은 블록 수 / 총 읽은 블록 수) x 100
= ((논리적I/O - 물리적I/O) / 논리적I/O) x 100
= (1 - 물리적I/O / 논리적I/O) x 100
- 논리적I/O = Query + Current
(수행 과정에서 읽은 총 블록 개수)- 물리적I/O = Disk
Q23. 아래 빈칸 (ㄱ)에 들어갈 용어를 고르시오.
DB 버퍼캐시는 일정한 크기를 갖는 메모리 공간이므로 모든 데이터를 캐싱해 둘 수는 없다. 그래서 DBMS는 사용 빈도가 높은 데이터 블록들이 버퍼캐시에 오래 남아있도록 하기 위해 (ㄱ) 알고리즘을 사용한다.
- Toss Immediate
데이터가 캐시되었다가 사용된 후 즉시 삭제- LRU (Least Recently Used)
가장 오랫동안 사용되지 않은 데이터를 가장 먼저 삭제- MRU (Most Recently Used)
가장 최근에 사용된 데이터를 가장 먼저 삭제
Q26. 다음 중 Multiblock I/O에 대한 설명으로 가장 부적절한 것을 고르시오.
- 한 번의 디스크 I/O Call로 여러 블록을 버퍼 캐시에 적재하는 기능이다.
- Multiblock I/O 단위는 db_file_multiblock_read_count 파라미터에 의해 결정된다.
- 익스텐트 경계를 넘지 못한다. 즉, 한 번의 디스크 I/O Call에서 두 개의 익스텐트를 읽지 않는다.
- Multiblock I/O를 모니터링해보면 db file sequential read 대기 이벤트가 나타난다.
Multiblock I/O는 캐시에서 찾지 못한 특정 블록을 읽으려고 I/O Call 할 때 디스크 상에 그 블록과 '인접한’ 블록들을 한꺼번에 읽어 캐시에 미리 적재하는 기능이다. Multiblock I/O 단위는db_file_multiblock_read_count파라미터에 의해 결정된다.
‘인접한 블록‘이란 같은익스텐트에 속한 블록을 의미하며,Multiblock I/O방식으로 읽더라도 익스텐트 경계를 넘지 못한다. 예를 들어, 한 익스텐트에 20개 블록이 담겨있고 Multiblock I/O 단위가 8이라고 할 때, 세 번째 I/O Call에서는 4개 블록만 얻게 된다. 이 때 8개를 마저 채우기 위해 다음 익스텐트까지 읽지 않는다.
Q27. 다음 중 데이터베이스 I/O 원리에 대한 설명으로 가장 부적절한 것을 고르시오.
- 한 쿼리가 같은 블록을 반복해서 엑세스하면 버퍼캐시 히트율(BCHR)은 높아진다.
- Multiblock I/O는 한 번의 I/O Call로 여러 데이터 블록을 읽어 메모리에 적재하는 방식이다.
- 테이블을 Full Scan할 때, 테이블이 작은 익스텐트로 구성돼 있을수록 더 많은 I/O Call이 발생한다.
- 인덱스를 통해 테이블을 엑세스할 때, 테이블이 큰 익스텐트로 구성돼 있으면 더 적은 I/O Call이 발생한다.
Multiblock I/O는 익스텐트 경계를 넘지 못한다. 한 번의 디스크 I/O Call에서 두 개의 익스텐트를 읽지 않는다. 따라서, 작은 익스텐트로 구성된 테이블을 Full Scan 하면 I/O Call이 더 많이 발생한다.
인덱스를 이용해서 테이블을 읽을 때는Single Block I/O방식을 사용하므로, 익스텐트 크기에 따라 I/O Call 횟수가 달라지지 않는다.
