- MySQL에서는
EXPLAIN이라는 명령으로 쿼리 실행 계획을 확인할 수 있다.
개요
- 옵티마이저는 쿼리의 실행 계획을 수립한다.
- 실행 계획을 이해하면 실행 계획의 불합리한 부분을 찾아내고 최적화된 방법으로 실행 계획을 수립하도록 유도할 수 있다.
MySQL 쿼리 실행 과정
1. SQL 문장을 잘게 쪼개서 MySQL 서버가 이해할 수 있는 수준으로 분리(파스 트리)한다.
- 이를 SQL 파싱이라고 하며 MySQL 서버의 SQL 파서라는 모듈로 처리한다.
- SQL 문장이 문법적으로 잘못됐다면 이 단계에서 걸러진다.
- 이 단계에서 SQL 파스 트리가 만들어진다.
- SQL 문장이 아닌 SQL 파스 트리를 이용해 쿼리를 실행한다
2. SQL의 파싱 정보(파스 트리)를 확인하면서 어떤 테이블부터 읽고 어떤 인덱스를 이용해 테이블을 읽을지 결정한다.
- 불필요한 조건 제거 및 복잡한 연산 단순화
- 여러 테이블의 조인이 있는 경우 어떤 순서로 테이블을 읽을지 결정
- 각 테이블에 사용된 조건과 인덱스 통계 정보를 이용해 사용할 인덱스를 결정
- 가져온 레코드들을 임시 테이블에 넣고 다시 한번 가공해야 하는지 결정
- 이 단계가 완료되면 실행 계획이 만들어진다
3. 결정된 테이블의 읽기 순서나 선택된 인덱스를 이용해 스토리지 엔진으로부터 데이터를 가져온다.
- 실행 계획대로 스토리지 엔진에 레코드를 읽어오도록 요청
- MySQL 엔진에서는 스토리지 엔진으로부터 받은 레코드를 조인하거나 정렬하는 작업을 수행
옵티마이저의 종류
규칙 기반 최적화
- 대상 테이블의 레코드 건수나 선택도 등을 고려하지 않고 옵티마이저에 내장된 우선순위에 따라 실행 계획을 수립하는 방식을 의미한다. 통계 정보를 사용하지 않고 실행 계획이 수립되기 때문에 같은 쿼리에 대해서는 거의 항상 같은 실행 방법을 만들어 낸다. 옛날에는 CPU가 느려 비용 계산 과정이 부담스럽다는 이유라 사용되었지만 요즘은 CPU도 빠르고 사용자의 데이터 분포도가 매우 다양하기 때문에 거의 사용하지 않는다.
비용 기반 최적화
- 쿼리를 처리하기 위한 여러 가지 가능한 방법을 만들고 각 단위 작업의 비용 정보와 대상 테이블의 예측된 통계 정보를 이용해 실행 계획별 비용을 산출한다. 이렇게 산출된 실행 방법별로 비용이 최소로 소요되는 처리 방식을 선택해 최종적으로 쿼리를 실행한다.
기본 데이터 처리
풀 테이블 스캔과 풀 인덱스 스캔
MySQL 옵티마이저가 풀 테이블 스캔을 선택하는 경우
- 테이블의 레코드 건수가 너무 작아서 인덱스를 통해 읽는 것보다 풀 테이블 스캔을 하는 편이 더 빠른 경우 (일반적으로 테이블이 페이지 1개로 구성된 경우)
- WHERE 절이나 ON 절에 인덱스를 이용할 수 있는 적절한 조건이 없는 경우
- 인덱스 레인지 스캔을 사용할 수 있는 쿼리라고 하더라도 옵티마이저가 판단한 조건 일치 레코드 건수가 너무 많은 경우(인덱스의 B-Tree를 샘플링해서 조사한 통계 정보 기준)
일반적으로 테이블은 매우 크기 때문에 풀 테이블 스캔을 수행할 때 한 번에 여러 블록이나 페이지를 읽습니다. 테이블의 연속된 데이터 페이지가 읽힐 때, 백그라운드 스레드에 의해 리드 어헤드 작업이 자동으로 시작됩니다. 리드 어헤드는 특정 영역의 데이터가 곧 필요하게 될 것이라 예상하여, 요청이 도착하기 전에 디스크에서 미리 읽어 InnoDB의 버퍼 풀에 저장하는 것을 말합니다.
따라서 풀 테이블 스캔이 실행되면, 처음 몇 개의 데이터 페이지는 포그라운드 스레드가 페이지 읽기를 담당하지만, 특정 시점부터 읽기 작업을 백그라운드 스레드로 전환합니다. 이 시점부터 백그라운드 스레드는 한 번에 4개 또는 8개씩 페이지를 읽으며, 이런 작업을 늘려가며 최대 64개의 데이터 페이지를 읽어 버퍼 풀에 저장합니다. 그 결과, 포그라운드 스레드는 미리 버퍼 풀에 저장된 데이터를 사용할 수 있어 쿼리 처리가 매우 빠르게 완료됩니다.
리드 어헤드는 풀 테이블 스캔에서만 사용되는 것이 아니라 풀 인덱스 스캔에서도 동일하게 사용된다.
mysql > SELECT COUNT(*) FROM employees;이 쿼리는 아무 조건 없이 SELECT쿼리를 실행해 테이블의 레코드 건수를 조회하고 있으므로 풀 테이블 스캔을 할 것 같지만 단순히 레코드의 건수만 필요로 하는 쿼리이기 때문에 풀 인덱스 스캔하게 될 가능성이 높다.
mysql > SELECT * FROM employees;이 쿼리는 풀 테이블 스캔이 된다.
병렬 처리
- MySQL 8.0 버전부터 서버에서도 쿼리의 병렬 처리가 가능해졌다.
- 병렬 처리용 스레드 개수가 늘어날수록 쿼리 처리에 걸리는 시간이 줄어든다.
- 하지만 서버에 장착된 CPU의 코어 개수를 넘어서는 경우에는 오히려 성능이 떨어질 수도 있다.
ORDER BY 처리(Using filesort)
ORDER BY 처리 방법

모든 정렬을 인덱스를 이용해서 할 수 있는 것은 아니다.
모든 정렬을 인덱스를 이용하도록 튜닝하기 힘든 이유
- 정렬 기준이 너무 많아서 요건별로 모두 인덱스를 생성하는 것이 불가능한 경우
- GROUP BY의 결과 또는 DISTINCT 같은 처리의 결과를 정렬해야 하는 경우
- UNION의 결과와 같이 임시 테이블의 결과를 다시 정렬해야 하는 경우
- 랜덤하게 결과 레코드를 가져와야 하는 경우
소트 버퍼
- MySQL은 정렬을 수행하기 위해 별도의 메모리 공간을 할당받아서 사용하는데 이 메모리 공간을 소트 버퍼라고 한다.
- 소트 버퍼는 정렬이 필요한 경우에만 할당된다.
- 버퍼의 크기는 정렬해야 할 레코드의 크기에 따라 가변적으로 증가한다.
- 소트 버퍼를 위한 메모리 공간은 쿼리의 실행이 완료되면 즉시 시스템으로 반납한다.
소트 버퍼의 문제점
레코드 정렬이 필요할 때, 정렬해야 할 레코드 수가 할당된 소트 버퍼보다 크다면, MySQL은 레코드를 여러 조각으로 나누어 처리합니다. 메모리의 소트 버퍼에서 정렬을 수행한 다음, 그 결과를 임시로 디스크에 저장합니다. 이어서 다음 레코드를 가져와 정렬하고, 이를 반복하며 디스크에 임시 저장합니다. 각 버퍼 크기만큼 정렬된 레코드를 다시 병합하면서 정렬을 수행해야 합니다. 이 과정에서 디스크를 사용하여 임시 저장하면서 I/O 작업이 많이 발생하므로 성능이 좋지 않습니다.
소트 버퍼에 큰 메모리 공간을 할당하면 빠르게 정렬할 수 있을 것 같지만, 실제로는 리눅스 계열 운영체제에서 큰 메모리 공간 할당 때문에 성능이 더 떨어질 수 있습니다. 메모리에 남는 공간이 생기거나 스왑 메모리를 사용하게 되어 디스크 I/O가 발생할 수 있습니다.
소트 버퍼는 세션 메모리 영역이며, 여러 클라이언트 간에 공유되지 않습니다. 커넥션이 많을수록 정렬 작업이 많아지면, 소트 버퍼로 소비되는 메모리 공간도 커집니다. 이러한 상황에서 OOM-Killer가 여유 메모리를 확보하기 위해 프로세스를 강제로 종료할 수 있습니다. OOM-Killer는 메모리 사용량이 높은 프로세스를 강제 종료하는데, 일반적으로 메모리를 많이 사용하는 데이터베이스가 강제 종료 대상의 최우선입니다.
정렬 알고리즘
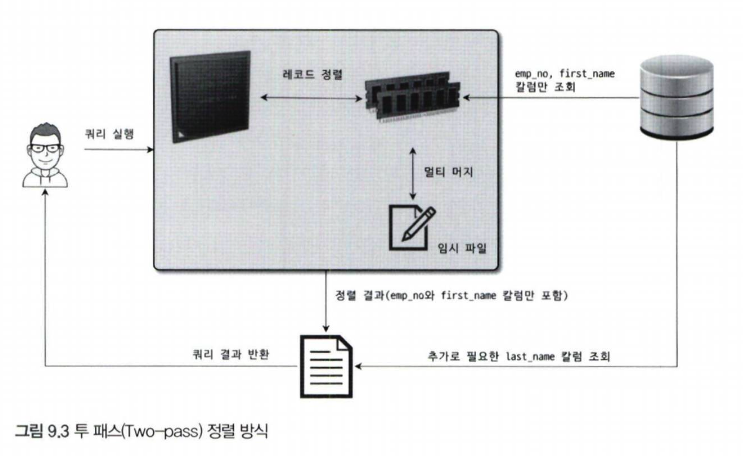
레코드를 정렬할 때 레코드 전체를 소트 버퍼에 담을지 또는 정렬 기준 컬럼만 소트 버퍼에 담을지에 따라 "싱글 패스"와 "투 패스" 2가지 정렬 모드로 나눌 수 있다.
MySQL 정렬 방식
투 패쓰
- <sort_key, rowid> : 정렬 키와 레코드의 로우 아이디만 가져와서 정렬하는 방식
싱글 패쓰
- <sort_key, additional_fiedls> : 정렬 키와 레코드 전체를 가져와서 정렬하는 방식으로 레코드의 컬럼들은 "고정 사이즈"로 메모리 저장
- <sort_key, packed_additional_fields> : 정렬 키와 레코드 전체를 가져와서 정렬하는 방식으로 레코드의 컬럼들은 "가변 사이즈"로 메모리 저장
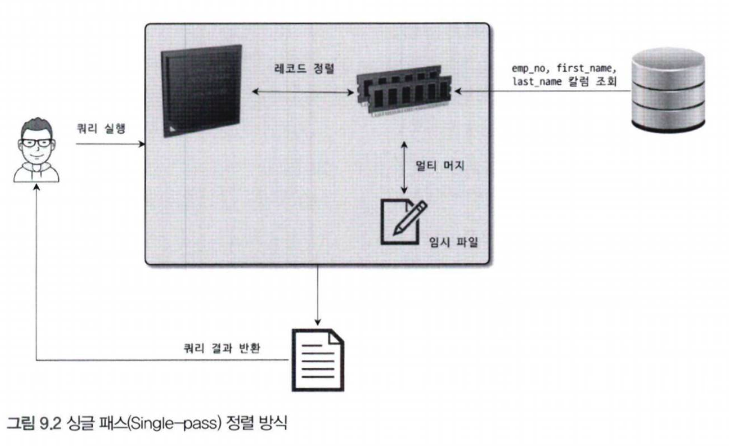
투 패쓰 방식에서는 정렬이 완료된 후, 결과 순서에 따라 정렬키 이외의 값들을 테이블에서 한 번 더 읽어와야 합니다. 따라서 테이블을 두 번 읽어야 해서 비효율적입니다. 반면, 싱글 패쓰 방식은 테이블을 한 번만 읽으면 됩니다. 싱글 패쓰는 정렬키 외에 필요한 레코드 전체를 읽어오기 때문에 메모리 사용량이 큽니다.
정렬 처리 방법
쿼리에 ORDER BY가 사용되면 다음 3가지 방법 중 하나로 정렬이 처리된다.
| 정렬 처리 방법 | 설명 |
|---|---|
| 인덱스를 사용한 정렬 | 별도 표기 없음 |
| 조인에서 드라이빙 테이블만 정렬 | "Using filesort" 메시지가 표시됨 |
| 조인에서 조인 결과를 임시 테이블로 저장 후 정렬 | "Using temporary; Using filesort" 메시지가 표시됨 |
옵티마이저는 먼저 정렬 처리를 위해 인덱스를 이용할 수 있을지 검토한다.
- 인덱스를 이용할 수 있다면 별도의 Filesort 과정 없이 인덱스를 순서대로 읽어서 결과를 반환한다.
- 인덱스를 사용할 수 없다면 WHERE 조건에 일치하는 레코드를 검색해 정렬 버퍼에 저장하면서 정렬을 처리한다.
이때 MySQL 옵티마이저는 정렬 대상 레코드를 최소화하기 위해 다음 2가지 방법 중 하나를 선택한다.
- 조인의 드라이빙 테이블만 정렬한 다음 조인을 수행
- 조인이 끝나고 일치하는 레코드를 모두 가져온 후 정렬을 수행
인덱스를 이용한 정렬
인덱스를 이용한 정렬을 위해서는 반드시 ORDER BY에 명시된 컬럼이 제일 먼저 읽는 테이블에 속하고 ORDER BY의 순서대로 생성된 인덱스가 있어야 한다. 또한 WHERE 절에 첫 번째로 읽는 테이블의 컬럼에 대한 조건이 있다면 그 조건과 ORDER BY는 같은 인덱스를 사용할 수 있어야 한다. 그리고 B-Tree 계열의 인덱스가 아닌 해시 인덱스나 전문 검색 인덱스 등에서는 인덱스를 이용한 정렬을 사용할 수 없다. 여러 테이블이 조인되는 경우에는 네스티드-루프 방식의 조인에서만 이 방식을 사용할 수 있다.
인덱스를 이용해 정렬이 처리되는 경우에는 실제 인덱스의 값이 정렬돼 있기 때문에 인덱스 순서대로 읽기만 하면 된다. 실제로 MySQL 엔진에서 별도의 정렬을 위한 추가 작업을 수행하지 않는다.
인덱스를 사용한 정렬이 가능한 이유는 B-Tree 인덱스가 키 값으로 정렬돼 있기 때문이다. 또한 조인이 네스티드-루프 방식으로 실행되기 때문에 조인 때문에 드라이빙 테이블의 인덱스 읽기 순서가 흐트러지지 않는다. 하지만 조인이 사용된 쿼리의 실행 계획에 조인 버퍼가 사용되면 순서가 흐트러질 수 있기 때문에 주의해야 한다.
ORDER BY 절을 넣지 않아도 자동으로 정렬되므로 ORDER BY 절 자체를 쿼리에서 완전히 제거해서 쿼리를 작성하는 것은 좋지 않은 선택이다. MySQL 서버는 인덱스로 처리할 수 있는 경우 부가적으로 불필요한 정렬 작업을 수행하지 않는다. 또한 어떤 이유로 실행 계획이 조금 변경된다면 ORDER BY가 명시되지 않은 쿼리는 결과를 기대했던 순서대로 가져오지 못해서 버그로 연결될 수도 있다.
조인의 드라이빙 테이블만 정렬
일반적으로 조인이 수행되면 결과 레코드의 건수가 몇 배로 불어나고 레코드 하나하나의 크기도 늘어난다. 그래서 조인을 실행하기 전에 첫 번째 테이블의 레코드를 먼저 정렬한 다음 조인을 실행하는 것이 정렬의 차선책이 될 것이다. 이 방법으로 정렬이 처리되려면 조인에서 첫 번째로 읽히는 테이블(드라이빙 테이블)의 칼럼만으로 ORDER BY 절을 작성해야 한다. 옵티마이저는 드라이빙 테이블만 검색해서 정렬을 먼저 수행하고 그 결과와 salaries 테이블을 조인한다.
임시 테이블을 이용한 정렬
쿼리가 여러 테이블을 조인하지 않고 하나의 테이블로부터 SELECT해서 정렬하는 경우라면 임시 테이블이 필요하지 않다. 하지만 2개 이상의 테이블을 조인해서 그 결과를 정렬해야 한다면 임시 테이블이 필요할 수도 있다. 앞에서 살펴본 조인의 드라이빙 테이블만 정렬은 임시 테이블을 사용하지 않지만 그 외 패턴의 쿼리에서는 항상 조인의 결과를 임시 테이블에 저장하고 그 결과를 다시 정렬하는 과정을 거친다. ORDER BY 절의 정렬 기준 컬럼이 드라이빙 테이블이 아니라 드리븐 테이블에 있는 컬럼인 경우 조인이 된 데이터를 가지고 정렬할 수밖에 없다.
정렬 처리 방법의 성능 비교
1. 스트리밍 처리 방식
서버 쪽에서 처리할 데이터가 얼마인지에 관계없이 조건에 일치하는 레코드가 검색될때마다 바로바로 클라이언트로 전송해주는 방식을 의미한다. 이 방식으로 쿼리를 처리할 경우 클라이언트는 쿼리를 요청하고 곧바로 원했던 첫 번째 레코드를 전달받는다.
쿼리가 스트리밍 방식으로 처리될 수 있다면 클라이언트는 MySQL 서버가 일치하는 레코드를 찾는 즉시 전달받기 때문에 동시에 데이터의 가공 작업을 시작할 수 있다. 웹 서비스 같은 OLTP 환경에서는 쿼리의 요청에서부터 첫 번째 레코드를 전달받게 되기까지의 응답 시간이 중요하다. 스트리밍 방식으로 처리되는 쿼리는 쿼리가 얼마나 많은 레코드를 조회하느냐에 상관없이 빠른 응답 시간을 보장해준다.
또한 스트리밍 방식으로 처리되는 쿼리에서는 LIMIT 처럼 결과 건수를 제한하는 조건들은 쿼리의 전체 실행 시간을 상당히 줄여줄 수 있다.
2. 버퍼링 방식
ORDER BY나 GROUP BY 같은 처리는 쿼리의 결과가 스트리밍되는 것을 불가능하게 한다. 우선 WHERE 조건에 일치하는 모든 레코드를 가져온 후 정렬하거나 그루핑해서 차례대로 보내야 하기 때문이다. 어느 테이블이 먼저 드라이빙되어 조인되는지도 중요하지만 어떤 정렬 방식으로 처리되는지는 더 큰 성능 차이를 만든다. 가능하다면 인덱스를 사용한 정렬로 유도하고 그렇지 못하다면 최소한 드라이빙 테이블만 정렬해도 되는 수준으로 유도하는 것도 좋은 튜닝 방법이라고 할 수 있다.
정렬 처리 방법 중 인덱스를 사용한 정렬 방식만 스트리밍 형태의 처리이며 나머지는 모두 버퍼링된 후에 정렬된다.
GROUP BY 처리
GROUP BY 절이 있는 쿼리에서는 HAVING 절을 사용할 수 있는데 HAVING 절은 GROUP BY 결과에 대해 필터링 역할을 수행한다. GROUP BY에 사용된 조건은 인덱스를 사용해서 처리될 수 없으므로 HAVING 절을 튜닝하려고 인덱스를 생성하거나 다른 방법을 고민할 필요는 없다.
GROUP BY 작업도 인덱스를 사용하는 경우와 그렇지 못한 경우로 나눠 볼 수 있다. 인덱스를 이용할 때는 인덱스를 차례대로 읽는 인덱스 스캔 방법과 인덱스를 건너뛰면서 읽는 루스 인덱스 스캔이라는 방법으로 나뉜다. 그리고 인덱스를 사용하지 못하는 쿼리에서 GROUP BY 작업은 임시 테이블을 사용한다.
인덱스 스캔을 이용하는 GROUP BY (타이트 인덱스 스캔)
조인의 드라이빙 테이블에 속한 칼럼만 이용해 그루핑할 때 GROUP BY 칼럼으로 이미 인덱스가 있다면 그 인덱스를 차례대로 읽으면서 그루핑 작업을 수행하고 그 결과로 조인을 처리한다. GROUP BY가 인덱스를 사용해서 처리된다 하더라도 그룹 함수 등의 그룹값을 처리해야 해서 임시 테이블이 필요할 때도 있다. GROUP BY가 인덱스를 통해 처리되는 쿼리는 이미 정렬된 인덱스를 읽는 것이므로 쿼리 실행 시점에 추가적인 정렬 작업이나 내부 임시 테이블은 필요하지 않다. 이러한 그루핑 방식을 사용하는 쿼리의 실행 계획에서는 Extra 컬럼에 별도로 GROUP BY 관련 코멘트나 임시 테이블 사용 또는 정렬 관련 코멘트가 표시되지 않는다.
루스 인덱스 스캔을 이용하는 GROUP BY
루스 인덱스 스캔 방식은 인덱스의 레코드를 건너뛰면서 필요한 부분만 읽어서 가져오는 것을 의미하는데 옵티마이저가 루스 인덱스 스캔을 사용할 때는 실행 계획 Extra 컬럼에 "Using index for group-by" 코멘트가 표시된다.
mysql > SELECT emp_no
FROM salaries
WHERE from_date='1985-03-01'
GROUP BY emp_no;MySQL의 처리 순서
1. (emp_no, from_date) 인덱스를 차례대로 스캔하면서 emp_no의 첫 번째 유일한 값 "10001"을 찾아낸다.
2. (emp_no, from_date) 인덱스에서 emp_no가 "10001"인 것 중에서 from_date 값이 "1985-03-01"인 레코드만 가져온다.
3. (emp_no, from_date) 인덱스에서 emp_no의 그 다음 유니크한 값을 가져온다.
4. 3번 단계에서 결과가 더 없으면 처리를 종료하고 결과가 있다면 2번 과정으로 돌아가서 반복을 수행한다.
임시 테이블을 사용하는 GROUP BY
GROUP BY의 기준 컬럼이 드라이빙 테이블에 있든 드리븐 테이블에 있든 관계없이 인덱스를 전혀 사용하지 못할 때는 임시 테이블을 사용해서 처리된다.
DISTINCT 처리
특정 컬럼의 유니크한 값만 조회하려면 SELECT 쿼리에 DISTINCT를 사용한다. DISTINCT는 MIN(), MAX() 또는 COUNT() 같은 집합 함수가 없는 경우 2가지로 구분된다. 집합 함수와 같이 DISTINCT가 사용되는 쿼리의 실행 계획에서 DISTINCT 처리가 인덱스를 사용하지 못할 때는 항상 임시 테이블이 필요하다. 하지만 실행 계획의 Extra 컬럼에서는 Using temporary 메시지가 출력되지 않는다.
SELECT DISTINCT
단순히 SELECT되는 레코드 중에서 유니크한 레코드만 가져오고자 하면 SELECT DISTINCT 형태의 쿼리 문장을 사용한다. 이 경우에는 GROUP BY와 동일한 방식으로 처리된다. 특히 MySQL 8.0 버전부터 GROUP BY를 수행하는 쿼리에 ORDER BY 절이 없으면 정렬을 사용하지 않기 때문에 다음 두 쿼리는 내부적으로 같은 작업을 수행한다.
mysql > SELECT DISTINCT emp_no FROM salaries;
mysql > SELECT emp_no FROM salaries GROUP BY emp_no;DISTINCT는 SELECT하는 레코드를 유니크하게 SELECT하는 것이지 특정 컬럼만 유니크하게 조회하는 것이 아니다.
SELECT 절에 사용된 DISTINCT 키워드는 조회되는 모든 컬럼에 영향을 미친다. 절대로 SELECT하는 여러 컬럼 중 일부 컬럼만 유니크하게 조회하는 것은 아니다.
집합 함수와 함께 사용된 DISTINCT
COUNT() 또는 MIN(), MAX() 같은 집합 함수 내에서 DISTINCT 키워드가 사용될 수 있는데 이 경우에는 일반적으로 SELECT DISTINCT와 다른 형태로 해석된다. 집합 함수 내에서 사용된 DISTINCT는 그 집합 함수의 인자로 전달된 컬럼 값이 유니크한 것들을 가져온다.
내부 임시 테이블 활용
MySQL 엔진이 스토리지 엔진으로부터 받아온 레코드를 정렬하거나 그루핑할 때는 내부적인 임시 테이블을 사용한다. 내부적이라는 단어가 포함된 이유는 여기서 이야기하는 임시 테이블은 "CREATE TEMPORARY TABLE" 명령으로 만든 임시 테이블과는 다르기 때문이다.
일반적으로 MySQL 엔진이 사용하는 임시 테이블을 처음에는 메모리에 생성됐다가 테이블의 크기가 커지면 디스크로 옮겨진다. MySQL 엔진이 내부적인 가공을 위해 생성하는 임시 테이블은 다른 세션이나 다른 쿼리에서는 볼 수 없으며 사용하는 것도 불가능하다.
메모리 임시 테이블과 디스크 임시 테이블
MySQL 8.0 버전부터는 메모리는 TempTable이라는 스토리지 엔진을 사용하고 디스크에 저장되는 임시 테이블은 InnoDB 스토리지 엔진을 사용한다.
임시 테이블이 필요한 쿼리
유니크 인덱스를 가지는 내부 임시 테이블이 만들어지는 쿼리
- ORDER BY와 GROUP BY에 명시된 컬럼이 다른 쿼리
- ORDER BY나 GROUP BY에 명시된 컬럼이 조인의 순서상 첫 번째 테이블이 아닌 쿼리
- DISTINCT와 ORDER BY가 동시에 쿼리에 존재하는 경우
- DISTINCT가 인덱스로 처리되지 못하는 쿼리
- UNION이나 UNION DISTINCT가 사용된 쿼리(select_type 컬럼이 UNION RESULT인 경우)
유니크 인덱스가 없는 내부 임시 테이블이 만들어지는 쿼리
- 쿼리의 실행 계획에서 select_type이 DERIVED인 쿼리
일반적으로 유니크 인덱스가 있는 내부 임시 테이블은 그렇지 않은 쿼리보다 처리 성능이 상당히 느리다.
임시 테이블이 디스크에 생성되는 경우
내부 임시 테이블은 기본적으로는 메모리상에 만들어지지만 다음과 같은 조건을 만족하면 메모리 임시 테이블을 사용할 수 없게 된다. 이 경우에는 디스크 기반의 임시 테이블을 사용한다.
- UNION 이나 UNION ALL 에서 SELECT 되는 컬럼 중에서 길이가 512바이트 이상인 크기의 컬럼이 있는 경우
- GROUP BY나 DISTINCT 컬럼에서 512바이트 이상인 크기의 컬럼이 있는 경우
고급 최적화
MySQL 서버의 옵티마이저가 실행 계획을 수립할 때 통계 정보와 옵티마이저 옵션을 결합해서 최적의 실행 계획을 수립하게 된다. 옵티마이저 옵션은 크게 조인 관련된 옵티마이저 옵션과 옵티마이저 스위치로 구분할 수 있다.
조인 최적화 알고리즘
MySQL에는 조인 쿼리의 실행 계획 최적화를 위한 알고리즘 2개가 있다. MySQL의 조인 최적화는 나름 많이 개선됐다고 이야기한다. 하지만 사실 테이블의 개수가 많아지면 최적화된 실행 계획을 찾는 것이 상당히 어려워지고 실행 계획을 수립하는 데만 몇 분이 걸릴 수도 있다. 테이블의 개수가 특정 한계를 넘어서면 그때부터는 실행 계획 수립에 소요되는 시간만 몇 시간이나 며칠로 늘어날 수도 있다. 여기서는 왜 그런 현상이 생기고 어떻게 그런 현상을 피할 수 있는지 알아보자.
Exhaustive 검색 알고리즘
MySQL 5.0과 그 이전 버전에서 사용되던 조인 최적화 기법으로 FROM 절에 명시된 모든 테이블의 조합에 대해 실행 계획의 비용을 계산해서 최적의 조합 1개를 찾는 방법이다. 테이블이 20개라면 이 방법으로 처리했을 때 가능한 조인 조합은 모두 20! 개가 된다.
Greedy 검색 알고리즘
Exhaustive 검색 알고리즘의 시간 소모적인 문제점을 해결하기 위해 MySQL 5.0부터 도입된 조인 최적화 기법이다. Greedy는 Exhaustive 검색 알고리즘보다는 조금 복잡한 형태로 최적의 조인 순서를 결정한다.
-
전체 N개의 테이블 중에서 optimizer_search_depth 시스템 설정 변수에 정의된 개수의 테이블로 가능한 조인 조합을 생성
-
생성된 조인 조합 중에서 최소 비용의 실행 계획 하나를 선정
-
선정된 실행 계획의 첫 번째 테이블을 "부분 실행 계획"의 첫 번째 테이블로 선정
-
전체 N-1개의 테이블 중에서 optimizer_search_depth 시스템 설정 변수에 정의된 개수의 테이블로 가능한 조인 조합을 생성
-
생성된 조인 조합들을 하나씩 3번에서 생성된 부분 실행 계획에 대입해 실행 비용을 계산
-
비용 계산 결과 최적의 실행 계획에서 두 번쨰 테이블을 3번에서 생성된 "부분 실행 계획"의 두 번째 테이블로 선정
-
남은 테이블이 모두 없어질 때까지 4~6번까지의 과정을 반복 실행하면서 "부분 실행 계획"에 테이블의 조인 순서를 기로
-
최종적으로 "부분 실행 계획"이 테이블의 조인 순서로 결정됨
쿼리 힌트
MySQL의 버전이 업그레이드되고 통계 정보나 옵티마이저의 최적화 방법들이 더 다양해지면서 쿼리의 실행 계획 최적화가 많이 성숙하고 있다. 하지만 여전히 MySQL 서버는 우리가 서비스하는 비즈니스를 100% 이해하지는 못하기 때문에 부족한 실행 계획을 수립할 때가 있다. 이런 경우에는 옵티마이저에게 쿼리의 실행 계획을 어떻게 수립해야 할지 알려줄 수 있는 방법이 필요한데 이런 목적으로 힌트가 제공되며 MySQL에서도 다양한 옵티마이저 힌트를 제공한다.
MySQL 서버에서 사용 가능한 쿼리 힌트는 다음과 같이 2가지로 구분할 수 있다.
- 인덱스 힌트
- 옵티마이저 힌트
인덱스 힌트는 예전 버전의 MySQL 서버에서 사용되어 오던 "USE INDEX" 같은 힌트를 의미하며 옵티마이저 힌트는 MySQL 5.6 버전부터 새롭게 추가되기 시작한 힌트를 지칭한다.
인덱스 힌트
"STRAIGHT_JOIN"과 "USE INDEX" 등을 포함한 인덱스 힌트들은 모두 MySQL 서버에 옵티마이저 힌트가 도입되기 전에 사용되던 기능들이다. 이들은 모두 SQL의 문법에 맞게 사용해야 하기 때문에 사용하게 되면 ANSI-SQL 표준 문법을 준수하지 못하게 되는 단점이 있다. MySQL 5.6 버전부터 추가되기 시작한 옵티마이저 힌트들은 모두 MySQL 서버를 제외한 다른 RDBMS에서는 주석으로 해석하기 때문에 ANSI-SQL 표준을 준수한다고는 볼 수 있다. 그래서 가능하다면 인덱스 힌트보다는 옵티마이저 힌트를 사용할 것을 추천한다. 또한 인덱스 힌트는 SELECT 명령과 UPDATE 명령에서만 사용할 수 있다.
STRAIGHT_JOIN
STRAIGHT_JOIN은 옵티마이저 힌트인 동시에 조인 키워드이기도 하다.
STRAIGHT_JOIN은 SELECT, UPDATE, DELETE 쿼리에서 여러 개의 테이블이 조인되는 경우 조인 순서를 고정하는 역할을 한다.
다음 쿼리는 3개의 테이블을 조인하지만 어느 테이블이 드라이빙 테이블이 되고 어느 테이블이 드리븐 테이블이 될지 알 수 없다.
mysql > SELECT *
FROM employees e, dept_no de, departments d
WHERE e.emp_no=de.emp_no AND d.dept_no=de.dept_no;일반적으로 조인을 하기 위한 컬럼들의 인덱스 여부로 조인의 순서가 결정되며 조인 컬럼의 인덱스에 아무런 문제가 없는 경우에는 레코드가 적은 테이블을 드라이빙으로 선택한다.
USE INDEX / FORCE INDEX / IGNORE INDEX
조인의 순서를 변경하는 것으로 다음으로 자주 사용되는 것이 인덱스 힌트인데 STRAIGHT_JOIN 힌트와는 달리 인덱스 힌트는 사용하려는 인덱스를 가지는 테이블 뒤에 힌트를 명시해야 한다. 대체로 MySQL 옵티마이저는 어떤 인덱스를 사용해야 할지를 무난하게 잘 선택하는 편이다. 하지만 3~4개 이상의 컬럼을 포함하는 비슷한 인덱스가 여러 개 존재하는 경우에는 가끔 옵티마이저가 실수를 하는데 이런 경우에는 강제로 특정 인덱스를 사용하도록 힌트를 추가한다.
SQL_CALC_FOUND_ROWS
옵티마이저 힌트
옵티마이저 힌트는 영향 범위에 따라 다음 4개 그룹으로 나뉜다.
- 인덱스 : 특정 인덱스의 이름을 사용할 수 있는 옵티마이저 힌트
- 테이블 : 특정 테이블의 이름을 사용할 수 있는 옵티마이저 힌트
- 쿼리 블록 : 특정 쿼리 블록에 사용할 수 있는 옵티마이저 힌트로서 특정 쿼리 블록의 이름을 명시하는 것이 아니라 힌트가 명시된 쿼리 블록에 대해서만 영향을 미치는 옵티마이저 힌트
- 글로벌(쿼리 전체) : 전체 쿼리에 대해서 영향을 미치는 힌트
이 구분으로 인해 힌트의 사용 위치가 달라지는 것은 아니다. 그리고 힌트에 인덱스 이름이 명시 될 수 있는 경우를 인덱스 수준의 힌트로 구분하고 테이블 이름까지만 명시될 수 있는 경우를 테이블 수준의 힌트로 구분한다. 또한 특정 힌트는 테이블과 인덱스의 이름을 모두 명시할 수도 있지만 인덱스의 이름을 명시하지 않고 테이블 이름만 명시할 수도 있는데 이런 경우는 인덱스 테이블 수준의 힌트가 된다.

많은 것을 배웠습니다, 감사합니다.