
Numpy, Pandas 복습
배열, 데이터프레임의 속성과 메소드
새롭게 알게된 것, 자주 헷갈리는 것 위주로 정리
배열 관련
axis
- 가장 바깥 리스트에서 안쪽을 향해 0부터 숫자를 매김
- 2차원
spl = [[1, 2, 3],
[4, 5, 6]]
spl_arr = np.array(spl)
spl_arr.shape # (2, 3) - 3차원
list1 = [[[1, 2, 3],
[4, 5, 6]],
[[7, 8, 9],
[10, 11, 12]]]
arr1 = np.array(list1)
arr1.shape # (2, 2, 3)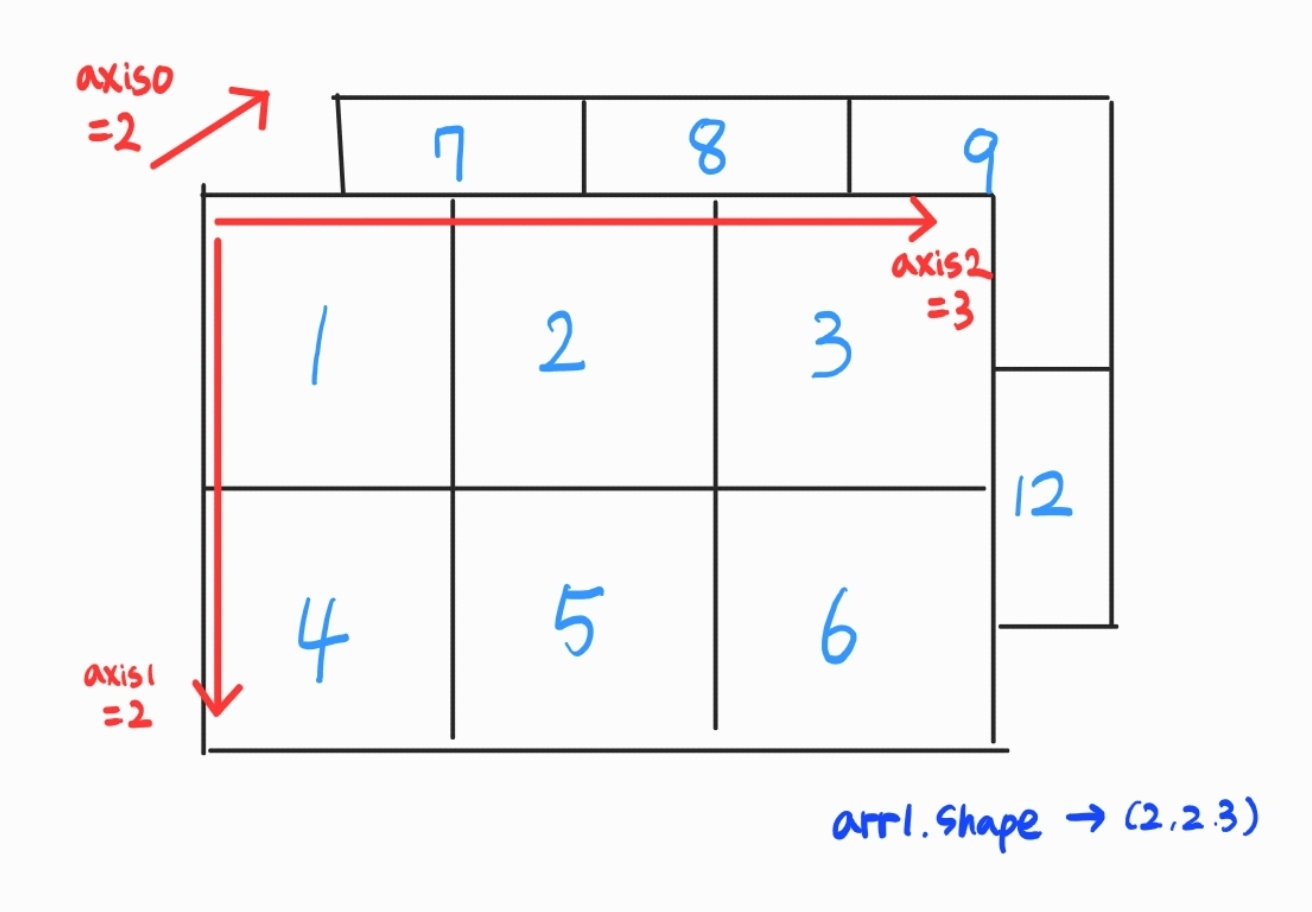
- 두께, 행, 열 등으로 정의하면 차원이 높아질수록 헷갈리니 주의할 것
rank
- 축의 갯수
shape
- 배열의 크기(축의 길이)
3차원 배열
- 3차원 배열 = 2차원 배열의 중첩
dtype
- 배열은 한 가지 자료형만 가질 수 있다.
- 여러 개의 자료형이 있을 경우, 좀 더 넓은 의미를 갖는 자료형으로 변한다.
- ex. 숫자와 문자가 있을 경우 문자로, 정수와 실수가 있을 경우 실수로 바뀐다.
reshape()
- reshape할 때, -1을 넣어주면 다른 숫자를 통해 자동으로 계산해서 변환한다.
2차원 배열의 행과 열 조회
spl = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# `배열[[행 관련 정보], [열 관련 정보]]`
print(spl[[0, 1], : ] # 열 관련 정보가 생략됨. : 놓어두면 전체 조회.
# [[1 2 3] 첫번째, 두번째 행만 출력된다.
[4 5 6]]
# 행 관련 정보를 생략하고 싶을 때는 꼭 : 를 넣어줘야하고, 열 관련 정보를 생략할 땐 :도 생략할 수 있다.
# print(a[,]) # SyntaxError: invalid syntax
# print(a[:]) 혹은 print(a[:,]) # 전체 출력됨. 뒤가 생략된 것
# print(a[]) # SyntaxError: invalid syntax데이터프레임 관련 속성과 메소드
- 일반적으로 데이터프레임을 변경하는 메소드들은 변경 결과를 반환만 하고, 실제로는 반영되지 않는다.
- 반영하려면
inplace=True옵션을 주거나, 반환된 결과를 별도의 변수로 받아줘야한다. - 데이터프레임을 변경할 땐 신중하게 할 것!(data 백업 중요)
인덱스 관련
df.set_index(): 일반 열을 인덱스로 설정df.index.name=None: 인덱스 이름 삭제
df.reset_index(): 행 번호에 기반한 정수값으로 인덱스 초기화drop=True: 기존 인덱스열을 버림df.rename(columns = {'index' : '바꾸고싶은 이름'}, inplace=True)
정보 확인 관련
-
df.dtypes: column들의 자료형 확인- 문자열 데이터는
object임(string아니다!)- 객체라는 의미 X
- 문자열 데이터는
-
df.info(): 각 column의 자료형, 갯수, null 여부 등 확인 -
df.describe(): 기술통계 확인 (갯수, 평균, 표준편차, 최대최소, 사분위값 등)df[col1].describe(),df[[col1, col2]].describe()
정렬 관련
df.sort_values(by=['col1','col2'], ascending=True): 정렬ascending = True: default, 오름차순ascending = False: 내림차순
통계 관련
-
df['col1'].value_counts(): 범주형 열 'col1'의 고윳값 갯수 확인normalize=True: 비율로 결과 제공dropna=True: NaN 제외하고 계산
-
df['col1'].mode(): 최빈값 확인 -
df.sum()==df.sum(axis=0): 각 열의 모든 행을 더함 -
df.sum(axis=1): 각 행의 모든 열을 더함인자로 들어가는 axis가 연산의 대상이 된다.
series
- 데이터프레임에서 하나의 열만 떼어낸 것
- 인덱스와 value로 구성됨
type(df['col1']) # series
type(df[ ['col1'] ]) # dataframe
# 리스트로 컬럼을 묶었다는건, 여러 개의 컬럼을 가질 수 있다(=dataframe)는 가능성을 의미한다고 생각하기Bit, Byte, ASCII 코드
-
Bit: Binary Digit- 컴퓨터에서 사용하는 가장 작은 단위의 데이터 (0, 1)
- ex. 4bit는 0~15(2⁴) 까지의 수를 표현할 수 있음
-
Byte: 정보 교환의 기본 단위- 1byte = 8bit = 알파벳 문자 1개
- Kilobyte, Megabyte, Gigabyte...
-
따라서 8의 약수나 배수를 사용하는 4bit나 16진수를 활용하면 컴퓨터가 10진수보다 1byte의 범위를 구분하기 쉬워진다.
-
ASCII 코드: 미국정보교환표준부호- 7bit의 128개의 제어문자와 숫자, 알파벳, 특수부호에 10진수를 대응하여 이를 8bit로 변환한다. (1bit는 통신에러 컨트롤용)
-
유니코드: 아스키코드로 표현할 수 없는 언어의 문자를 표현하기 위해 만들어짐.- 아스키코드에 해당하지 않는 문자가 다양한 byte를 사용하여 추가되어있다.
- ex. UTF-8
