이번 포스팅은 팀 프로젝트를 리팩토링하다 발견한 무엇인가 잘못된 객체 조회를 이야기하려고 합니다.
객체 조회란 단순하게 레포지토리에서 조회하여 데이터베이스에서 유저 객체를 가지고 오는 것을 의미합니다.
문제라고 생각하는 지점
먼저, 문제를 말씀드리면, 유저 객체가 필요한 API에서 유저를 조회할 때, SecurityContextHolder에서 Principal(email) 정보를 가지고와서 유저의 이메일로 레포지토리에서 유저 객체를 가지고 오는 것이었습니다.(JWT 방식)
즉, SecurityContextHolder -> principal(email) 조회 -> findbyEamil(email) -> 객체 가지고 옴이런 식의 로직을 짠 배경
보통은 api는 /users/{id} 이렇게 url을 작성을 합니다.
그런데 어차피 SpringContextHolder에 회원 정보를 저장하는데 굳이 path varivble에 id를 받아야되나??
라는 생각을 하게 됩니다. 그리고 이러한 생각을 실현시키게 됩니다.
코드는 이러합니다.
class UserService {
//....
public User getLoginUser() {
String principal = (String) SecurityContextHolder
.getContext()
.getAuthentication()
.getPrincipal(); //jwt에서 Principal로 email을 저장했습니다.
Optional<User> userOptional = userRepository.findByEmail(principal);
return userOptional.orElseThrow(() -> new BusinessLogicException(ExceptionCode.USER_NOT_FOUND));
}
}이 메서드를 UserService인 서비스 계층에 만들고 User 객체가 필요한 모든 서비스 계층에 DI를 해서 사용합니다.
이런 식의 로직은 어떤 문제가 있을까?
1. 의존 문제
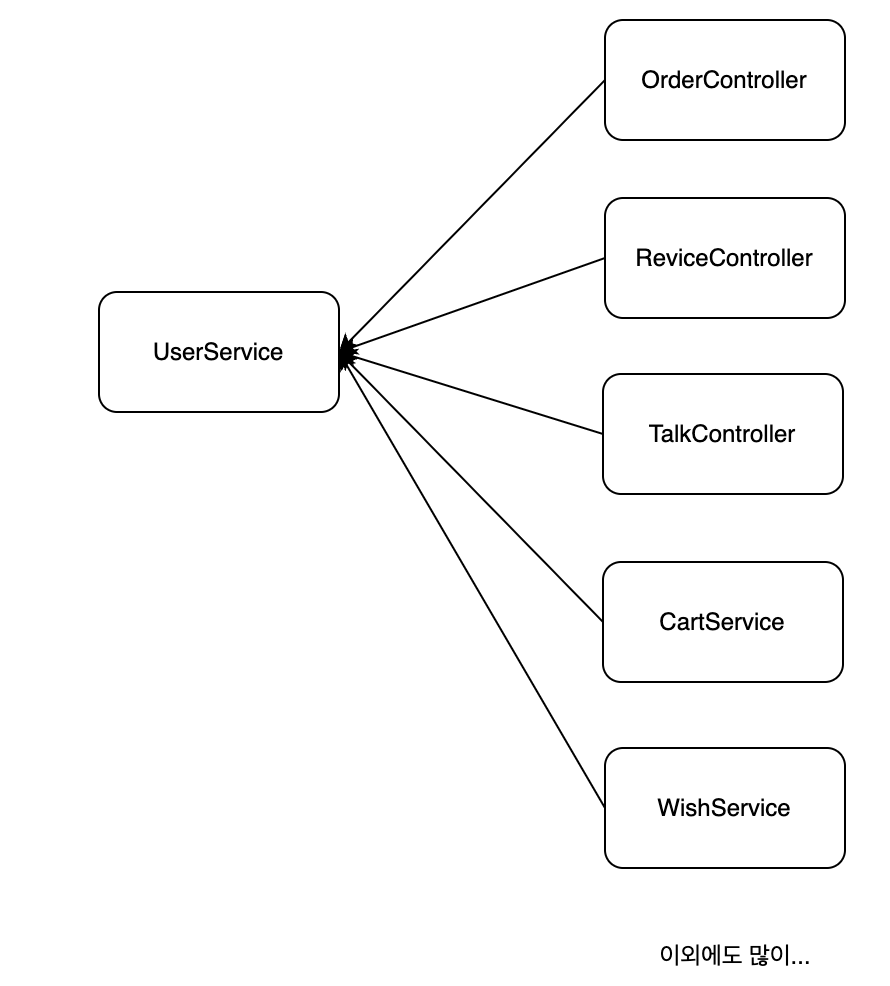
우선, 이런 로직의 문제는 User 객체가 필요한 web 계층과 service 계층은 User 객체를 가지고 오기 위해 UserService에 의존적이게 됩니다.
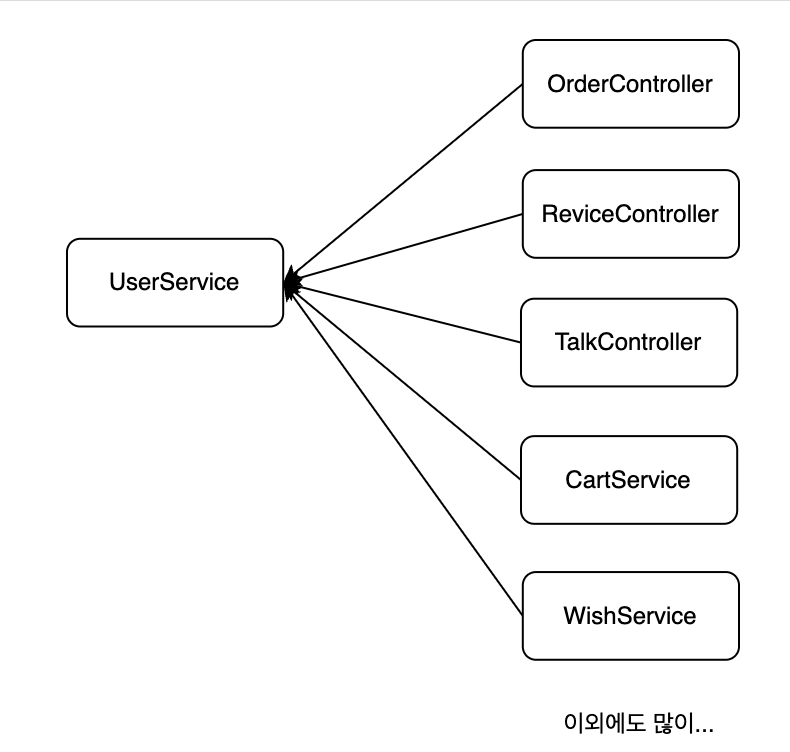
딱 봐도, 문제가 있어보이는 의존 관계입니다.
혹시라도 UserService에 문제가 생긴다면 사실상 애플리케이션 자체가 장애가 나버리는 치명적인 상황이 올 것이라고 생각합니다.
물론, web 계층인 컨트롤러 계층은 서비스에 의존적입니다. 그리고 서비스 계층도 서비스 계층에 의존할 수 있다고 생각합니다.
그런데, 단지 User 객체를 가지고 오기 위해 UserService에 거의 모든 계층이 의존하는 것은 아닌것 같습니다...
이러한 사실을 프로젝트 당시에는 인지하지 못했습니다.
2. email로 유저를 찾는다??
Optional<User> userOptional = userRepository.findByEmail(principal);만약 userService.getLoginUser();를 모든 계층에서 사용해도 된다고 가정을 해도, 위 처럼 이메일로 user 객체를 찾는 것은 비효율적이라고 생각합니다.
왜냐하면, 저희 서비스에 가입한 회원이 굉장히 많다고 가정을 해봅시다.
만약 'email'로 유저를 찾는다면, 유저를 조회하는 시간이 오래걸릴 것입니다.
만약 email을 검색 시간을 빠르게 하려면 인덱싱을 사용해합니다.
이러면, 회원 가입을 할 때마다, 인덱싱처리를 해주어야 하고, 메모리 또한 더욱 차지하게 됩니다.
그런데, id(primary key)로 유저 객체를 찾는다면, 인덱싱 처리를 하지 않아도 됩니다.
왜냐하면, primary key를 사용하면 인덱싱 처리가 그냥 되기 때문이죠!
한 번 실험을 해 보았습니다.
- 약 100개의 더미 데이터를 넣고, "test@gmail.com"이라는 이메일을 가진 테스트 유저를 조회하는데 email과 id 중 어느 방식이 더 빠른지 테스트했습니다.

- 결과


id 조회가 더 빨리 조회가 되는 것을 알 수 있습니다. 100개만 들어 갔음에도 불구하구요!
회고
- 프로젝트를 하던 중 이러한 문제점을 발견하지 못했다는 것이 공부가 많이 부족했다는 생각이 들었습니다.
- 아쉬운 점은 이러한 문제점을 발견했음에도 불구하고, 너무 많은 로직이 위 처럼 짜여져있어 수정하기가 매우 번거롭다는 점입니다.
- 그래도 앞으로는 이러한 로직을 구현하지 말아야 겠다는 큰 깨달음을 얻었습니다.
- api 디자인 가이드를 참고하여 수정을 시도할 예정입니다.
참고: 세션 방식을 쓰면, SecurityContextHolder에 user 객체를 저장할 수 있어 위와 비슷하게 static을 써서 바로 가지고 올 수는 있습니다. (잘못된 방식일 수 있음)
