
CloudWatch
사실 단어만 봐도 무슨 서비스인지 유추가 가능한 서비스이다. AWS의 모니터링 서비스이다.
사실 현대에 IT 시스템 이나 인프라를 구축하고 관리하기에는 정말 어려운 일이다. 이러한 거대한 서비스나 인프라를 관리할려면 모니터링 서비스를 꼭사용해야 어떤 곳에 문제가 발생했는지 쉽게 파악이 가능하다.
클라우드 AWS 에서 모니터링을 아키텍처를 생성할 떄 고려 해야 할 부분은 다음과같다.
- 리소스 사용량 및 애플리케이션 성능에 대한 정보 수집
- 비용 절감
- 보안 모니터링으로 사용자가 환경의 일부에 액세스하는지 여부 및 시기를 알 수 있음
CloudWatch는 실시간에 가까운 시스템 이벤트를 제공한다. 실시간에 가까운 정보를 제공함에 따라 변경점에 대해 신속하게 대응하고 조치를 취할 수 있다.
CloudWatch는 한곳 에서 모든 AWS 리소스, 애플리케이션, 서비스에 걸쳐 이 데이터를 수집 및 액세스하고 관계를 파악할 수 있다. 또한 CloudWatch는 온프레미스 서버에서도 데이터를 수집할 수 있다.
CloudWatch 의 기능
- 메트릭 수집 및 분석
- AWS에 있는 리소스와 애플리케이션에서 메트릭 값을 수집후 분석(시각화) 함
- 로그 관리
- 다양한 소스에서 로그를 수집, 저장, 분석할 수 있음
- 쿼리를 통해 특정 로그를 필터링 가능
- 알람 및 이벤트
- 메트릭, 로그 등 이벤트 기반으로 알람을 설정하여 리소스를 조정가능
- 이벤트 기반이기 때문에
Lambda,SNS,eventbridge, ..와 같이 사용 가능
- 대시보드 및 시각화
- 사용자 정의 대시보드를 통해 메트릭 과 로그를 시각화하여 현재 시스템을 한눈에 파악 가능
- 컨테이너 인사이트
- 컨테이너화 된 애플리케이션의 성능을 모니터링 하고 문제를 진단할 수 있음
ECS,EKS,Fargate를 통하여 사용가능
- 보안 및 규정 준수 모니터링
- 보안 이벤트와 규정 준수 관련 메트릭을 모니터링하여 보안 위협을 식별할 수 있음
CloudWatch 지표
다음과 같은 지표는 EC2 CPU 사용률에 대한 데이터이다. AWS의 모든 서비스에서는 기본적으로 리소스 관련 지표를 제공한다. CloudWatch 에서는 지표에 대한 데이터를 일련의 데이터 요소로 저장한다. 각 데이터 요소에는 연결된 타임스탬프가 있다.
EC2 인스턴스와 같은 일부 리소스에 대한 세부 모니터링 활성화 및 자체 애플리케이션 지표를 게시할 수도 있다. CloudWatch는 검색, 그래프 및 경보를 위해 계정에 모든 지표를 로드할 수 있다. 또한 이런 지표 데이터는 14개월 동안 보관되므로 최신 데이터 와 옜날 데이터를 모두 볼 수 있다.
지표는 다음과 같은 구성 요소로 이루어져있다.
- 네임스페이스
- 네임스페이스는 지표를 논리적으로 그룹화한다. 네임스페이스의 지표는 서로 격리 되어있다. 따라서 지표가 다른 네임스페이스와 같이 섞여서 통계가 나올 수 없다
AWS/Service와 같은 형식으로 구분된다.
- Dimensions (차원)
- 차원은 지표를 고유하게 식별할 수 있는 키/값 페어를 말한다.
- 각 지표에는 차원을 10개까지 할당할 수 있다.
- 데이터 포인트
- 지표를 구성하는 시계열 데이터로 시간과 값으로 구성된다.
- 단위
- 데이터 포인트를 해석하기 위한 측정 단위로 메트릭의 의미를 명확히 하는 데 도움이 됨.
CPU -> %,Network -> Bytes
- 해상도
- 해상도는 지표의 데이터 포인트 수집 주기를 나타낸다.
CloudWatch Logs
모니터링에서 각종 성능 지표를 시각화하여 확인도 있지만 로그도 정말 중요한 요소이다. 이러한 로그를 직접 접속하여 확인하는 방법도 있지만 비효율적이다. (굉장히 많은 서버는 오래걸린다..)
따라서 이러한 로그를 중앙집중형식으로 수집하고 분석할 필요가 있다. AWS 에서는 CloudWatch 에서 가능하다.
다른 로그 서비스도 있다. CloudTrail, VPC 흐름 로그, 사용자 지정 로그 등..
로그는 다음과 같은 요소로 이루어짐
- 로그 그룹
- 로그 스트림의 컨테이너
- 로그 스트림
- 동일 소스의 로그 이벤트 시퀀스
- 메트릭 필터
- 로그 패턴을 메트릭으로 변환
- Log Insights
- 쿼리 언어로 로그 분석 지원
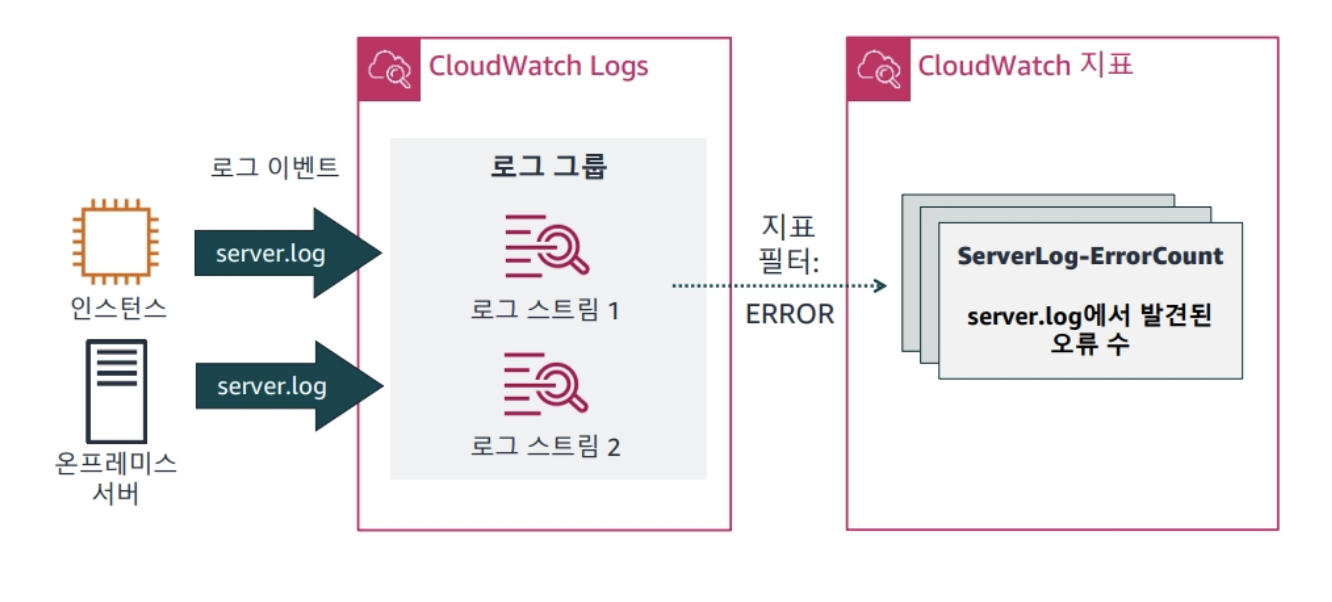
다음과 같은 예시로server.log데이터를 기록하는 웹서버가 있다고 가정한다. 두 서버는 모두 로그파일의 이벤트를 로그 스트림에 기재한다.
여러 로그 스트림을 단일 로그 그룹에 수집이 가능하다. 로그 그룹을 생성한 후에 지표필터를 사용하여 로드 이벤트에서 일치하는 단어, 구문 또는 값을 검색하여 특정 로그를 찾을 수 있다.
- 쿼리 언어로 로그 분석 지원
CloudWatch 경보
CloudWatch를 통해서 알람을 가게 만들 수 있는데 2가지 경보를 생성할 수 있다.
지표 경보 와 복합 경보이다.
지표 경보는 수학 표현식의 결과를 감시합니다라고 되어있다. 즉 특정 리소스의 대한 임계값을 지정해놓고 임계값을 초과할 경우 알람을 보내게된다.
복합 경보는 사용자가 생성한 다른 경보의 경보 상태를 고려하는 규칙 표현식이 포함됩니다라고 되어있다. 임계값에 대해 여러개를 가질 수 있다. 예를 들어 한개의 EC2가 존재한다면 해당 EC2의 CPU 와 메모리 사용량이 80% 로 임계값을 설정해둔다면 CPU, 메모리 둘다 임계점을 초과하게 된다면 알람이 가게 되는 형식이다.
기타등등..
그 외에 기능으로도 정말 많은 기능을 가지고있다. Cross-Account Observability, ServiceLens, Auto Scaling과 연동 등등
