자세한 내용은 논문을 참고하세요.
Retrieval-Augmented Generation for
Knowledge-Intensive NLP Tasks : https://arxiv.org/pdf/2005.11401
Background
1. Parametric Memory
- 일반적인 language model은 사전학습을 통해 많은 지식을 model parameter 안에 저장한다.
- 예를 들어 BART, T5와 같은 모델은 학습 과정에서 본 문장들을 기반으로 특정 사실 정보를 어느 정도 기억할 수 있다.
- 이처럼 model parameter 안에 저장된 지식을 논문에서는 parametric memory라고 표현한다.
- 하지만 parametric memory만 사용하는 방식에는 몇 가지 문제가 있다.
- 학습 이후에 새로운 지식을 반영하기 어렵다.
- 모델이 어떤 근거를 바탕으로 답변했는지 확인하기 어렵다.
- 잘 모르는 질문에 대해서도 그럴듯한 답변을 생성하는 hallucination 문제가 발생할 수 있다.
2. Non-Parametric Memory
- Non-parametric memory는 model parameter가 아닌 외부 지식 저장소를 의미한다.
- 본 논문에서는 Wikipedia document index를 non-parametric memory로 사용한다.
- 질문이 들어오면, 이 외부 문서 저장소에서 관련 문서를 검색하고, 검색된 문서를 generator가 함께 참고한다.
Introduction
본 논문의 핵심 문제의식은 다음과 같다.
기존 language model은 많은 지식을 parameter 안에 저장하지만,
지식을 정확하게 접근하거나 수정하거나 근거를 제시하는 데 한계가 있다.
- 기존 BART, T5와 같은 seq2seq model은 다양한 NLP task에서 좋은 성능을 보였지만, knowledge-intensive task에서는 여전히 한계가 존재한다.
Who is the president of Peru?
다음과 같은 질문에 대해 parametric model만 사용하면,
모델이 학습 당시 알고 있던 정보를 바탕으로 답변한다. 하지만 시간이 지나 대통령이 바뀌었다면, 모델 parameter 안의 지식은 outdated knowledge가 된다. 이 문제를 해결하려면 모델을 다시 학습해야 하는데, 이는 비용이 크고 비효율적이다.
- 따라서 저자들은 Parametric Memory + Non-Parametric Memory 구조를 제안한다.
- BART와 같은 generator는 그대로 사용하되,
외부 Wikipedia index에서 관련 문서를 검색하여 답변 생성에 활용한다.
Method
1. Overall Architecture
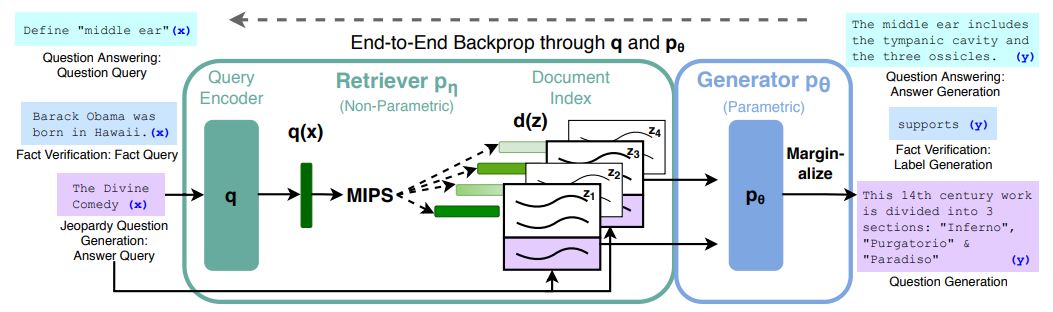
- RAG는 단순히 language model이 답변을 생성하는 것이 아니라, 먼저 외부 문서를 검색한 뒤 그 문서를 조건으로 답변을 생성하는 방식이다.
- Retriever는 입력 query와 관련 있는 문서를 찾는 역할을 한다.
- Generator는 입력 query와 검색된 문서를 함께 보고 최종 답변을 생성한다.
2. Retriever Component
- Retriever는 DPR(Dense Passage Retriever)을 사용한다.
- DPR은 Query encoder, Document encoder로 구성된 bi-encoder 구조로 이루어져 있다.
- 질문과 문서를 각각 BERT encoder에 넣어 vector representation을 만들고, 두 vector의 inner product를 계산하여 유사도를 구한다.
- 질문과 문서를 같은 embedding space에 올려놓고, 가장 가까운 문서를 top-k로 검색하는 방식이다.
- 검색 과정에서는 모든 문서를 직접 비교하면 비용이 너무 크기 때문에 MIPS(Maximum Inner Product Search)를 사용하여 빠르게 top-k document를 찾는다.
3. Generator Component
- Generator는 BART-large를 사용한다.
- 검색된 document와 input question을 concat하여 BART에 입력한다.
- RAG가 단순히 문서에서 정답 span을 복사하는 extractive 방식이 아니라 검색된 문서를 참고하지만, 최종 output은 generator가 생성한다.
4. RAG-Sequence
Question x → Top-k documents 검색 → 각 document를 기준으로 전체 sequence y 생성 → document별 확률을 marginalization
- RAG-Sequence는 하나의 문서가 전체 답변을 설명한다고 보는 방식이다.
- 하나의 output sequence 전체를 생성할 때 동일한 retrieved document를 사용한다고 가정한다.
- 여러 문서를 각각 참고하여 답변을 생성해보고, 각 문서가 선택될 확률과 그 문서를 조건으로 답변을 생성할 확률을 합산하여 최종 답변 확률을 계산한다.
5. RAG-Token
y1 생성 시 document 1 참고
y2 생성 시 document 2 참고
y3 생성 시 document 1 참고
...
- RAG-Token은 output token을 생성할 때마다 서로 다른 document를 참고할 수 있다.
- 즉, 하나의 답변을 생성하는 과정에서도 여러 문서의 정보를 섞어서 사용할 수 있다.
- RAG-Sequence가 “하나의 문서가 전체 답변을 책임지는 방식”이라면, RAG-Token은 “각 token마다 필요한 문서를 다르게 참고할 수 있는 방식”이다.

- Hemingway를 입력으로 Jeopardy question을 생성할 때, The Sun Also Rises를 생성하는 부분에서는 해당 작품이 포함된 문서의 posterior가 높고, A Farewell to Arms를 생성하는 부분에서는 다른 문서의 posterior가 높게 나타난다.
- 이를 통해 RAG-Token은 여러 문서에 흩어진 정보를 조합하는 데 유리하다고 볼 수 있다.
6. Training
- RAG는 retriever와 generator를 end-to-end로 학습한다.
- 하지만 학습 과정에서 정답 document에 대한 supervision을 직접 사용하지 않는다.
- question-answer pair만 사용하여 모델은 답변 y를 잘 생성하기 위해 어떤 document를 검색해야 하는지 latent variable로 학습한다.
- document encoder는 fine-tuning하지 않고 고정한다.

한양대학교 인공지능학과 대학원생 조권휘입니다.