
AzureVM 사용
AzureVM을 사용하는 것부터 난관이었다. Azure를 사용해본적도 없었다. 당연히 이걸로 뭐 어떻게 하라는 건지 감도 안잡혔다. 그나마 linux를 사용하는 것에 익숙해서 다행이었다.
Informer
장기 시계열 세미나에서 informer에 대한 자료가 있었어서 informer를 한동안 팠었다.
https://github.com/zhouhaoyi/Informer2020
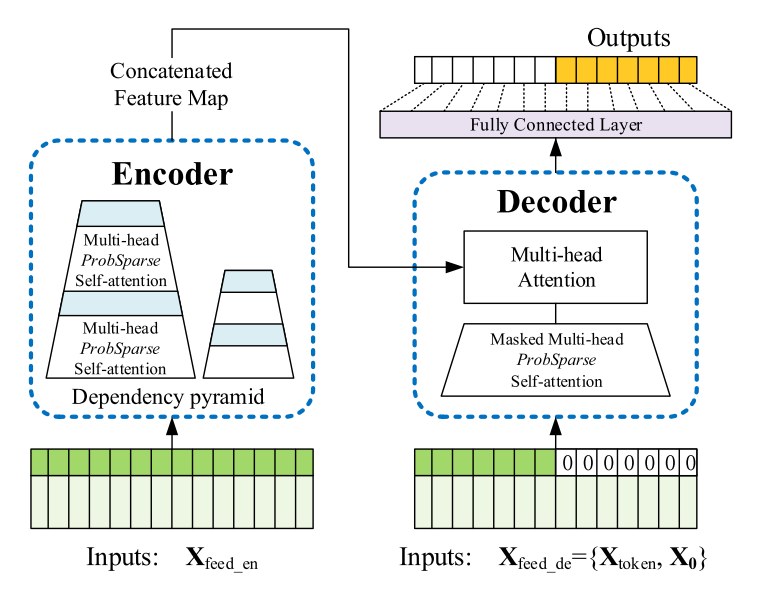
우리 과제의 경우 multivariate 예측을 했어야했고, 월 단위로 쪼게져 있었다.
따라서 baseline코드를 보고 우리 데이터에 맞게 변환이 필요했다.
def InformerRes(start_year, start_month, add_year, add_month, start_plot, iter, pitcher_list, data_train, targetName, res_df):
for _ in tqdm(range(iter), leave=True, desc='iter'):
min_max_scaler = MinMaxScaler()
for column in pitcher_list:
data_train[column] = min_max_scaler.fit_transform(data_train[column].to_numpy().reshape(-1,1)).reshape(-1)
dataset = Dataset_Pred(dataframe=data_train ,scale=True, size = (seq_len, label_len,pred_len))
data_loader = DataLoader(dataset,batch_size=batch_size,shuffle=shuffle_flag,num_workers=num_workers,drop_last=drop_last)
scaler = dataset.scaler
for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(data_loader):
pred, true = _process_one_batch(batch_x, batch_y, batch_x_mark, batch_y_mark)
preds = np.array(pred.detach().cpu().numpy())
predDf = pd.DataFrame(preds[-1], columns = pitcher_list)
...
scale_df = scaler.inverse_transform(predDf)
...
real = data_train["value"].to_numpy()
real = min_max_scaler.inverse_transform(real.reshape(-1,1)).reshape(-1)
result = min_max_scaler.inverse_transform(scale_df['value'].to_numpy().reshape(-1,1)).reshape(-1)
plt.figure(figsize=(20,5))
plt.plot(range(0,start_plot),real[:], label="real")
plt.plot(range(start_plot, start_plot + pred_len ), result, label="predict")
plt.legend()
plt.show()
start_plot = start_plot + pred_len
data_train = data_train.append(merged_df)
data_train = data_train.reset_index(drop=True)
for column in pitcher_list:
data_train[column] = min_max_scaler.inverse_transform(data_train[column].to_numpy().reshape(-1,1)).reshape(-1)
data_train
data_train.rename(columns={'value':targetName},inplace=True)
res_df = pd.concat([res_df, data_train[targetName]], axis=1)
return res_df--> 하지만 informer를 이용하여 타겟값을 예측을 했을 때, 좋은 성적을 내지 못했었다.
따라서 이를 이용하여 예측에 필요한 특정 피쳐를 예측을 하고 다른 모델을 이용하여 최종 예측을 해보기로 했다.
회기 섞기
간단히 informer에 회기를 섞어보기로 했다. 근데 이게 효과가 있었다.
따라서 boosting계열의 회기를 사용해보기로 했다.
Feature 조합 찾기
feature 조합을 어떻게 찾아야할지 고민이었다. 단순 계산으로도 조합을 짜도 몇 십만개의 조합이 나왔기 때문에 이를 손으로 모두 하기엔 무리가 있었다. 게다가 시간도 아껴야하기에 사람이 할 수 없는 시간에도 돌 수 있도록 하는 것이 중요했다.
따라서 이를 찾아내는 알고리즘을 만들기로 했다.
for length in range(6, 3, -1):
features = [...]
combine_list = list(combinations(features, length))
for combine in tqdm(combine_list, leave=True):
...
curr_dtw = cost
if curr_cost < best_cost:
best_cost = curr_cost
best_feature = combine_list
print('*********************************')
print('----------Best_cost 갱신----------')
print('*********************************')
print('Best Cost:', best_cost)
print('Best Feature',best_feature)
else:
print('*********************************')
print('----------Best_cost 미달----------')
print('*********************************')
print('Curr Cost:', curr_cost)
print('Best Cost:', best_cost)
print('Curr Feature:', combine_list)
print('Best Feature',best_feature)
일단 간단하게 이런식으로 만들어줘서 해결해줬다. 저걸 돌려놓고 다른 것들을 하기로 했다.
Prophet
시계열을 돌릴 때 가장 많이 사용된다는 이야기를 들었다.
https://news.ycombinator.com/item?id=33447976
확실히 뭔가 잘나오는 것 같았으나 추세를 약간 죽일 필요가 있어서 이 모델과 다른 모델을 섞어야했다. 추세를 죽여줄 수 있는 모델을 찾아 나섰다.
Sktime
이걸 깔아둔게 진짜 다행이었다. 내부에 여러가지 모델이 있었고 이들을 가지고 실험을 해볼 수 있었다.
https://www.sktime.org/en/stable/api_reference.html
결국 AutoETS와 ExponentialSmoothing을 사용하기로 했다.
마치며
사실 이 대회를 하면서 아쉬운 점이 많았다. 해보고 싶은 것들은 많았으나 폐쇄망 특성상 라이브러리를 설치할 수 있는 기간이 지나버리면 시도해볼 수가 없다. 처음하는 장기 시계열 데이터 예측이었기에 대회 기간중에 공부할 수 밖에 없었는데 공부하다가 사용하기 좋은 모델이나 라이브러리를 많이 발견했다. 아마 다음에도 이런 대회가 열리면 미리 공부를 해서 필요한 것들을 설치해두는 것이 좋아보인다.

결국 대상을 받았다. 물론 팀원분들께서 잘해주셔서 더 좋은 결과가 있었지 않나 싶다.
