230602 Today I Learned
기술면접 스터디 4회차. 어제 밤에 들었던 멘토링 강의에 대한 내용과 추가적으로 노드의 질문에서 정리하고 싶었던 걸 더 적어봤다.
1. List, Set, Map, HashMap의 차이에 대해서 설명해주세요.
List, Set, Map은 자바 컬렉션 프레임워크의 자료구조 인터페이스입니다.
List는 경우 입력 순서를 가진 데이터의 집합으로 데이터의 중복이 허용됩니다. ArrayList, LinkedList, Queue, Stack, Deque로 구현이 가능합니다.
Set은 수학에서 집합의 개념을 가져온 것으로, 입력 순서가 보장되지 않고 데이터의 중복이 없습니다. HashSet, LinkedHashSet, TreeSet으로 구현이 가능합니다.
Map은 key-value 쌍으로 이루어진 entry로 데이터를 저장하는데 key는 중복이 불가능하고 value는 중복이 가능합니다. HashMap, LinkedHashMap, TreeMap으로 구현이 가능합니다.
HashMap은 Map 인터페이스를 구현한 클래스 중 하나로, 해시 테이블을 사용해서 데이터의 삽입, 삭제, 탐색에 빠른 속도를 가지는 장점이 있습니다.
자료구조 상세
-
ArrayList : 배열기반. 인덱스 사용가능. 인덱스로 접근시 O(1).
-
LinkedList : 노드와 포인터로 구성. 삽입과 삭제에 효율적. 크기 확장시 arraylist는 배열을 재구성하지만 linkedlist는 노드만 더 달면 됨. 다만 순차적으로 접근해야하므로 탐색이 느리다.
-
HashSet : 해시테이블 기반. 중복불가. 삽입순서 x. 해시 충돌이 없으면 일반적으로 삽입/삭제/검색에 O(1)
-
LinkedHashSet : HashSet의 특성을 유지하면서 삽입 순서를 유지.
-
TreeSet : 이진탐색트리(레드블랙트리) 기반. 중복불가. 삽입순서가 아니라 오름차순처럼 정해진 기준에 따라 정렬. 삽입/삭제/검색에 O(log n)
-
LinkedHashMap : HashMap 특성 유지하면서 삽입 순서를 유지.
-
TreeMap: 이진탐색트리(레드블랙트리) 기반. 중복불가. 삽입순서가 아니라 오름차순처럼 정해진 기준에 따라 정렬. 삽입/삭제/검색에 O(log n).
2. 스프링 컨테이너(Spring Container)에 대해 설명해주세요.
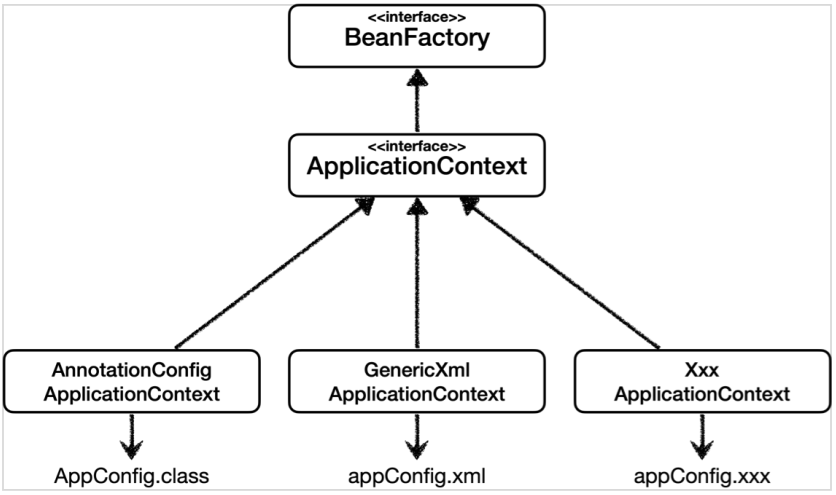
스프링 컨테이너는 스프링 프레임워크에서 Bean 객체의 lifecycle과 의존성 관리를 담당해 개발을 위한 런타임 환경을 제공합니다. 객체의 생성, 초기화, 소멸, 의존성 주입을 스프링 컨테이너가 관리하기 때문에 개발자는 비즈니스 로직에만 집중할 수 있는 장점이 있습니다.
두가지 유형으로 구분되는데, IoC와 DI의 기본 기능을 가진 BeanFactory와, 이를 상속받아 BeanFactory의 모든 기능을 포함하면서 AOP, 트랜잭션 관리 같은 추가 기능을 더 확장해서 주로 쓰이는 ApplicationContext가 있습니다.
- 컨테이너 : 애플리케이션에서 객체의 Lifecycle(생명주기)를 관리. 객체의 생성, 초기화, 소멸을 관리하고 의존성 주입을 담당. 애플리케이션을 실행하기 위해 필요한 리소스를 제공하고 관리
번외. 데이터베이스와 ORM에 대해 설명해보세요.
데이터베이스는 체계화된 데이터의 집합으로 효율적인 데이터 저장과 관리를 위해 사용됩니다. 구조화된 방식으로 데이터를 저장하고 검색, 수정, 삭제, 삽입 등의 작업을 수행할 수 있습니다.
ORM은 객체지향 프로그래밍과 관계형 데이터베이스 간에 데이터를 변환하고 매핑하는 기술입니다. 개발자는 객체 지향적인 방식으로 데이터를 다루고, ORM 프레임워크가 해당 객체를 데이터베이스 테이블에 매핑하여 저장, 검색, 수정, 삭제 등의 작업을 처리합니다. ORM을 사용하면 개발자는 SQL 쿼리를 직접 작성하는 번거로움을 줄이고, 객체 지향적인 코드 작성에 집중할 수 있습니다.
자바에는 ORM을 위한 표준 인터페이스인 JPA가 있고, 그 JPA의 구현체인 Hibernate가 있습니다.
-
RDBMS : 관계형 데이터베이스 시스템. 데이터를 테이블 형태로 구성하고 테이블간의 관계를 정의해 데이터를 저장하고 관리.
정형화된 데이터 구조에 적합. -
NoSQL : 비 관계형 데이터베이스 시스템. 비정형 데이터나 유연한 데이터 구조에 적합.
멘토링 시간 필기 (AOP)
신입이 알아야 할 스프링의 핵심은 ioc/di/bean과 aop/filter/interceptor가 있다.
aop/filter/interceptor를 쓰는 이유?
횡단의 관심사를 공통화 해서 사용하는 것.
중복코드를 처리해서 유지보수가 쉽게만든다.
aop/filter/interceptor를 각각 언제 써야하나?
- filter
request가 정상적인지 확인한다.
큰틀에서 세션값이 있냐 로그인 정보가 있냐 정도의 큰 규모의 인증/인가
request가 들어온지 안들어온지 여부판단 정도의 log를 찍는다.
비즈니스로직과는 무관하게 request/response 메세지를 다뤄야할 때 압축, 인코딩 같은 걸 한다.- (dispatcherselvlet) : 여기서 컨트롤러를 할당?
- interceptor
로그인정보가 있으면 jwt토큰 파싱이나
이 컨트롤러를 사용할수있는 요청인가? 분리하는 정도의 좀 더 세밀인증/인가
api호출에 대한 로깅- aop
필터 인터셉터는 url패턴이지만 aop는 다양하게 적용가능
세세하게 포인트컷으로 적용위치를 정할 수 있다.
