Today I Learned
오늘은 SQL 4장 집약함수와 그룹화에 대해 공부했다.
DISTINCT
중복된 결과를 통합해서 하나로 가져온다.
가져옴과 동시에 통합하는 것이 아닌, SELECT 한 결과를 통합해서 가져온다.
SELECT DISTINCT 컬럼명 ~
- 사용 예
아래의 데이터에서
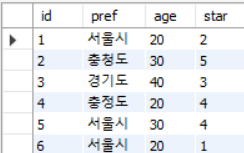
SELECT pref FROM inquiry;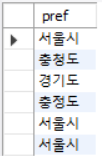
그냥 SELECT로 데이터를 가져오면 중복된 결과도 같이 가져온다.
하지만 DISTINCT를 사용하면
SELECT DISTINCT pref FROM inquiry;
위와 같이 중복된 데이터를 한번만 가져온다.
함수
어떤 값을 넣으면 특정한 처리를 시행해 그 결과를 내는 것.
예약어와는 다르다. 인수를 넣어 반환값을 결과로 낸다.
-
함수명(인수)로 작성한다. -
MySQL에서는 함수 명이 회색으로 인식된다. 예약어는 하늘색.
-
DBMS에 따라 사용할 수 있는 함수와 없는 함수가 갈릴 수 있다.
COUNT(*)
인수에 컬럼을 지정하면 NULL이 아닌 레코드 수를 반환한다.
- 예시
7번은 id를 제외한 다른 값은 NULL 이다.
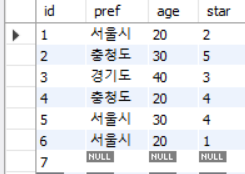
SELECT COUNT(*) FROM inquiry;을 하면 결과는 7이 나온다.
하지만
SELECT COUNT(pref) FROM inquiry;을 하면 결과는 6이 나온다. 7번째 레코드의 NULL은 count되지 않기 때문이다.
집약함수(집계함수)
대상이 되는 데이터의 값을 집약해 단 1개의 결과를 반환한다.
위의 COUNT()처럼 결과물이 여러 레코드가 아니라 하나로 나온다.
-
집약함수는
SELECT, HAVING, ORDER BY구에만 적을 수 있다.
FROM, WHERE, GROUP BY 구에는 적을 수 없다. -
SELECT 구에서 집약함수와 같이 적을 수 있는 건 상수, 집약함수, DISTINCT, 연산자 등이다.
여러개의 레코드가 나오는 일반 함수나 컬럼은 적을 수 없다. -
집계하려는 컬럼안에 NULL이 있을 경우 COUNT(*)외에는 전부 NULL을 무시한다.
즉, 평균낼때 NULL은 0 취급하지 않고 아예 없는 셈 친다. -
집약함수 종류
| 함수명 | 인수 | 반환값 |
|---|---|---|
| COUNT | * 또는 컬럼명 | 레코드 또는 컬럼의 수 |
| SUM | 컬럼명 | 컬럼의 합계값 |
| MAX | 컬럼명 | 컬럼의 최댓값 |
| MIN | 컬럼명 | 컬럼의 최솟값 |
| AVG | 컬럼명 | 컬럼의 평균값 |
문자열에서 MIN, MAX의 기준은 사전순이다.(MIN | ABC...Z | MAX)
날짜에서 MIN, MAX의 기준은 시간순이다. (MIN | '1900-01-01' .... '2023-10-31' | MAX)
- 예시
SELECT
SUM(star), MAX(star), MIN(star), AVG(star)
FROM inquiry;
각 함수당 하나의 결과물이 나오고 1개의 행에 모두 나열된다.
- 조건(WHERE문) 결합
SELECT
AVG(star) AS 포인트 평균
FROM inquiry
WHERE age = 30;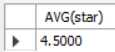
그룹화(GROUP BY)
테이블을 특정 기준으로 그룹화해서 연산할 수 있다.
SELECT 컬럼명 // 상수, 집약함수, 집약키의 컬럼명만 올 수 있다.
FROM 테이블명
GROUP BY 컬럼명; // 집약키-
GROUP BY 컬럼명을 이용해 해당 컬럼의 데이터를 기준으로 그룹화할 수 있다.
해당 컬럼명은집약 키라고 부른다. -
GROUP BY는 FROM 구 뒤에 적는다.
-
그룹화를 통해 집약함수를 각 그룹마다 독립적으로 시행할 수 있다.
-
집약 키가되는 컬럼에 NULL이 있다면 NULL끼리도 하나의 그룹으로 형성된다.
-
그룹화를 시행했을 때,
상수, 집약함수, 집약키의 컬럼명만 SELECT 구에 지정할 수있다. -
예시
SELECT pref, AVG(star)
FROM inquiry
GROUP BY pref;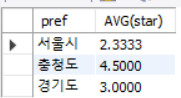
pref의 데이터는 경기도, 서울시, 충청도의 3가지다.
pref의 데이터를 기준으로 그룹화를 해서 해당 그룹의 AVG값을 각각 구해 그룹 당 하나의 결과물을 도출해낸다.
- 복수 집약키
여러 컬럼의 조합으로 그룹화를 할 수 있다. 집약키를 복수로 설정해 ,로 구분하면 된다.
SELECT pref, age, COUNT(*)
FROM inquiry
GROUP BY pref, age;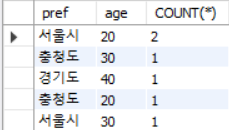
- WHERE문의 결합
WHERE 구를 추가해 조건을 지정하고 그룹화를 시행할 수 있다.
WHERE 구에서 먼저 조건에 맞는 레코드를 추출한 뒤 GROUP BY로 그룹화를 시행한다.
SELECT pref, AVG(star)
FROM inquiry
WHERE star >= 3
GROUP BY pref;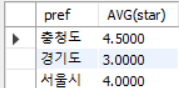
HAVING
특정 그룹에 대한 결과만 가져오고 싶을 때, 그룹에 대한 조건을 지정한다.
-
WHERE구는 GROUP BY보다 먼저 시행되어 전체 레코드에 대한 조건을 지정하는 반면,
HAVING은 그룹에 대한 조건을 직접 지정한다. -
HAVING 구에도
상수, 집약함수, 집약키의 컬럼명만 조건으로 가져올 수 있다. -
작성 양식
GROUP BY 구 뒤에 작성한다.
SELECT 컬럼명 // 무엇을 가져와라.
FROM 테이블명 // 어디(테이블)에서
WHERE 조건 // 전체 레코드에서 조건에 만족하는 것들만
GROUP BY 집약키 // 그룹별로 나눠
HAVING 조건; // 특정 조건의 그룹만- 예시
pref 컬럼의 레코드가 2개 이상인 그룹만 레코드 수를 가져온다.
SELECT pref, COUNT(*)
FROM inquiry
GROUP BY pref
HAVING COUNT(*)>= 2;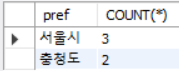
- 예시 2(WHERE구와 함께 사용)
age가 30이상인 레코드를 pref 컬럼을 기준으로 그룹화하고, star의 평균값이 4 이상인 그룹만 inquiry 테이블에서 가져와라
SELECT pref, AVG(star)
FROM inquiry
WHERE age>= 30
GROUP BY pref
HAVING AVG(star) >= 4;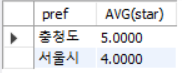
SQL문의 순서
-
작성순서
SELECT > DISTINCT > FROM > WHERE > GROUP BY > HAVING > ORDER BY > LIMIT > OFFSET -
실행 순서
- FROM : 테이블을 지정해서 전체 레코드를 추출
- WHERE : 조건에 따라 레코드를 축소
- GROUP BY : 그룹화
- HAVING : 조건에 만족하는 그룹으로만 축소
- SELECT : 가져올 데이터를 선택
- DISTINCT : 중복 데이터 통합
- ORDER BY : 주어진 기준으로 데이터 정렬
- OFFSET : 결과물의 일부만 가져올 때 시작위치
- LIMIT : 결과물의 일부만 가져올 때 가져올 레코드 수
WHERE? HAVING?
둘 다 조건을 지정해 가져오는 데이터를 축소시키는 기능을 한다.
그래서 경우에 따라 둘 중 어느것을 써도 결과가 같아지는 조건도 존재한다.
그럴 경우 WHERE문을 사용해 레코드 수를 먼저 줄여버리는 것이 처리시간 단축에 더 좋다.
물론 최종적으로 가져오려는 데이터에 따라 논리에 맞게 둘 중 골라서 사용하는 것이 가장 좋다.
