Today I Learned
오늘은 SQL 서브쿼리에 대해 공부했다. 면접 준비를 열심히 준비하다 보니 진도가 많이 나가진 않았지만 꾸준히 달리려고 한다.
서브 쿼리
SELECT문 처럼 DBMS에 대한 명령을 쿼리라 한다.
메인 쿼리 아래의 부 쿼리를 서브 쿼리라 한다.
- WHERE구에 쓸 경우 기본 구조
SELECT 컬럼명 FROM 테이블명
WHERE 컬럼명 연산자 (SELECT ~); // 괄호 안이 서브쿼리.-
서브 쿼리는 마지막에 세미 콜론을 붙이지 않는다.
-
서브 쿼리가 먼저 실행되고 그 뒤에 메인 쿼리가 실행된다.
-
매 레코드 마다 메인 쿼리 안에서 서브쿼리가 실행되는 것이 아니라, 서브쿼리가 먼저 한번만 실행 된 후 메인 쿼리안의 결과를 대체해 놓고 그 뒤에 메인쿼리가 실행되는 구조다.
-
실행한 서브 쿼리의 결과는 메인 쿼리의 조건으로 설정되는 경우가 많아 주로 WHERE구에 쓰인다. 하지만 WHERE구 이외의 SELECT구 등에도 쓸 수 있다.
-
서브 쿼리 사용은 여러 SELECT문을 하나의 SELECT문 안에 적을 수 있어 편리하지만 기본적으로 처리가 느릴 수 있으며(경우에 따라 빨라질 수도 있다) 굳이 서브 쿼리를 쓰지 않고 여러 SELECT문을 사용할 수 있으니 장단점을 따져가며 사용하면 된다.
서브쿼리 예시
- WHERE구에서 사용
아래의 productorder 테이블에서 평균 이상 가격의 주문id와 가격을 가져오려한다.

- 우선 가격의 평균을 가져온다.
SELECT AVG(price) FROM productorder;
# AVG(price)는 700- 그렇게 나온 결과를 기준으로 쿼리를 만든다.
SELECT order_id, price
FROM productorder
WHERE price >= 700;
# AVG(price)가 700이다.-
바로 WHERE price >= AVG(price); 를 쓰면 안되나?
집약함수는 WHERE구에 쓸 수 없다.
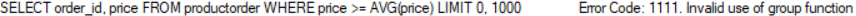
-
그렇다면 위의 두 쿼리를 한번에 적는 방법은?
두 쿼리를 메인쿼리 안에 서브쿼리 구조로 작성!
SELECT order_id, price
FROM productorder
WHERE price >= (
SELECT AVG(price)
FROM productorder
);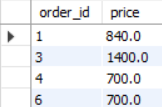
- SELECT AVG(price) FROM productorder의 서브쿼리가 먼저 실행되어 700이라는 결과로 대체해 두고 메인쿼리가 실행되는 구조이다.
- SELECT구에서 서브쿼리 사용
productorder 테이블에서 price 순으로 3건의 order_id와 price, productorder 테이블 전체 레코드 수를 가져와라
SELECT order_id, price,
(
SELECT COUNT(*)
FROM productorder
) AS order_count
FROM productorder
ORDER BY price
LIMIT 3;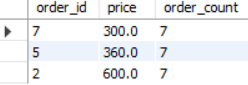
- SELECT구에서는 집약함수를 다른 컬럼과 함께 적을 수 없지만 위의 방식처럼 서브쿼리의 형식으로 사용이 가능하다.
- HAVING구에서 서브쿼리 사용
productorder 테이블을 customer_id로 그룹화하고, 그룹의 평균이 전체 레코드의 평균보다 작은 그룹의 customer_id와 평균 price를 가져와라.
SELECT customer_id, AVG(price)
FROM productorder
GROUP BY customer_id
HAVING AVG(price) < # 여기서 AVG는 그룹안에서의 평균
(
SELECT AVG(price) # 여기서 AVG는 전체 레코드의 평균
FROM productorder
);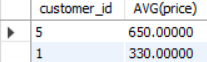
- 전체 레코드의 평균은 700이므로 700보다 평균 가격이 작은 그룹만 가져와진다.
- 메인쿼리와 서브쿼리의 테이블이 다른 경우
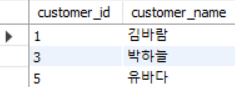
membertype 테이블에서 membertype이 '할인 회원'인 회원을 customer 테이블에서 가져와라
SELECT customer_id, customer_name
FROM customer
WHERE membertype_id =
(
SELECT membertype_id
FROM membertype
WHERE membertype = '할인 회원'
);
-
membertype 테이블에서 membertype 컬럼이 '할인 회원'인 membertype_id를 서브쿼리로 먼저 받아둔다. 그 값을 메인쿼리의 WHERE구에서 받아 실행시켜 일치하는 컬럼을 가져온다.
-
메인쿼리와 서브쿼리는 테이블이 다르지만 정상적으로 작동한다.
