Today I Learned
오늘은 면접 준비를 하다가 지인 개발자분께 들은 빅데이터 관련 지식을 정리해보고자 한다.
빅데이터 기본 구성
-
수집서버
스프링이나 파이썬 같은 기본 서버. -
메세지큐 - 버퍼 역할 카프카
카프카 같은 메세지 큐로 속도를 조절한다.
버퍼 역할을 메세지큐가 해준다.
수집서버로 들어오는 속도와 DB에 저장되는 속도에 차이가 있을 수 있기때문에 둔다.
- 배치처리 or 스트림 처리
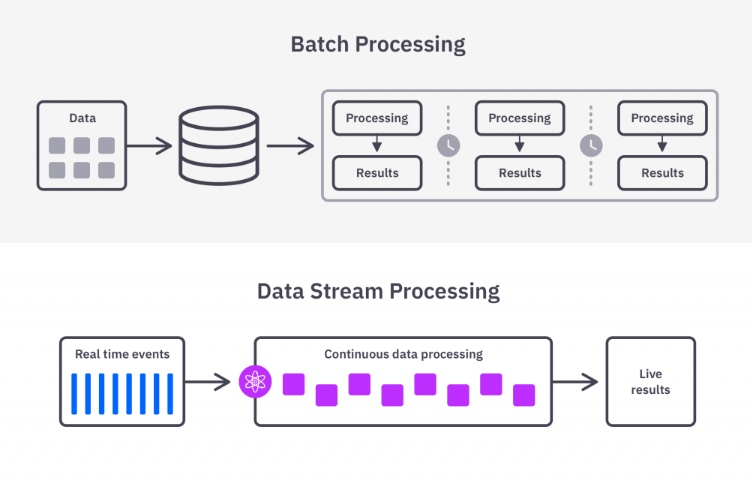
배치 : 대량의 데이터를 일괄로 처리
스트림 : 실시간으로 처리
- 하둡(hadoop) 분산데이터베이스
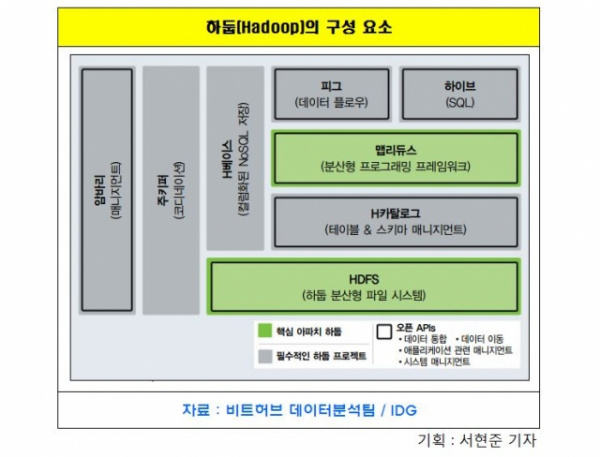
sql기반 rdb로 넣으면 속도가 못따라가고 용량도 못따라간다.
rdb는 조회를 염두에 두고 저장하는건데 빅데이터를 감당하지 못한다.
그래서 하둡은 nosql로 레코드 단위로 저장하지않고 파일 단위로 떨궈서 저장한다.
중요한건 분산 데이터베이스 시스템인데
데이터가 얼마나 저장될 지 모르는데 스케일업으로는 감당이 안된다.
스케일 아웃으로 계속 스토리지를 추가해서 용량을 늘리는 방법이 더 효율적이기때문에 분산 시스템을 쓴다.

Full-Stack Dev / MLOps