Today I Learned
오늘은 파이썬 자료 구조에 대해 공부했다.
Python 자료 구조
Stack
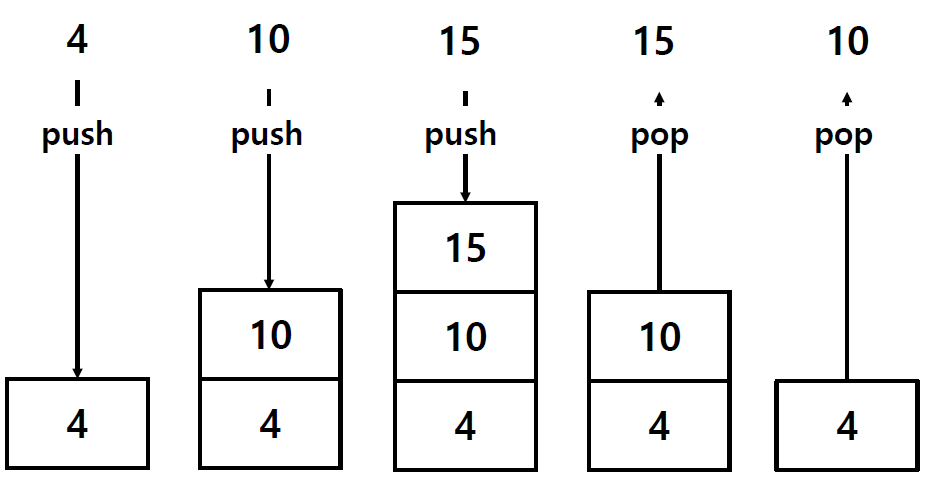
-
파이썬에서 스택은 리스트를 이용해 간단히 구현이 가능하다.
-
push는 append(), pop은
pop()함수를 사용하면 된다.
a = [1,2,3,4,5]
a.append(6)
a.append(7)
print(a.pop()) # 7
print(a.pop()) # 6Queue
-
파이썬에서 큐 역시 리스트를 이용해 간단히 구현이 가능하다.
-
put은 append()로, get은
pop(0)함수를 사용하면 된다.
b = [1,2,3,4,5]
b.append(6)
print(b.pop(0)) # 1
print(b.pop(0)) # 2Tuple
-
값의 변경이 불가능한 리스트
-
변경되지 않아야될 데이터, 즉 상수 데이터를 저장해둬야할 때 사용한다.
-
선언시
[ ]가 아니라( )를 사용해야 한다.
c = (1,2,3,4,5)
print(c*2)
print(len(c))
# c[0] = 3 수정시 에러 발생Set
-
값의 중복과 순서가 없는 집합
-
set 객체 선언을 통해 생성한다.
-
union, intersection, difference와 같은 집합 연산이 가능하다.
d = set([1,2,3])
d.add(4)
d.remove(1)
d.update([1,2,5])
print(d)
e = set([1,3,5,7,9])
print(d.union(e)) # 합집합 {1, 2, 3, 4, 5, 7, 9}
print(d.intersection(e)) # 교집합 {1, 3, 5}
print(d.difference(e)) # 차집합 {2, 4}Dictionary(Dict)
- key-value 쌍으로 이루어진 java로 치면 hashMap같은 자료구조.
country_code = {"america" : 1, "korea" : 82, "japan" : 81, "china" : 86}
print(country_code.items()) # dict_items([('america', 1), ('korea', 82), ('japan', 81), ('china', 86)])
print(country_code.keys()) # dict_keys(['america', 'korea', 'japan', 'china'])
print(country_code.values()) # dict_values([1, 82, 81, 86])
country_code["german"] = 49
print(country_code) # {'america': 1, 'korea': 82, 'japan': 81, 'china': 86, 'german': 49}Collections
- list, tuple, dict에 대한 python의 built-in 확장 자료구조
# 종류
from collections import deque
from collections import Counter
from collections import OrderedDict
from collections import defaultdict
from collections import namedtupleDeque
-
stack과 queue를 지원하는 모듈로 list에 비해 훨씬 빠르고 효율적인 자료 저장 방식을 지원한다.
-
rotate, reverse와 같은 linked list의 특성을 지원한다.
-
기존 list 형태의 함수를 모두 지원한다.
from collections import deque
deque_list=deque()
for i in range(5):
deque_list.append(i)
print(deque_list) # deque([0, 1, 2, 3, 4])
deque_list.appendleft(10)
print(deque_list) # deque([10, 0, 1, 2, 3, 4])Ordered Dict
-
Dict와 다르게 데이터를 입력한 순서대로 dict를 반환한다.
(하지만, python 3.6이후로 dict도 입력한 순서를 보장하여 출력하기때문에 이후 버전은 의미 x) -
dict의 값을 value나 key를 기준으로 sort할 때 사용가능하다.
Default Dict
-
dict type의 값에 기본값을 지정해 신규 값 생성시 사용하는 자료구조
-
기존 dict와 거의 유사하지만 존재하지 않는 키에 접근할 대 에러를 발생하지 않고 기본값을 반환한다.
-
아래의 예시에서 그냥 dict를 사용하면 존재하지 않는 키에 접근할 때 에러를 반환했을 것이다.
from collections import defaultdict
text = "apple banana cherry banana apple"
# defaultdict를 사용하여 문자 출현 빈도 세기
char_counts = defaultdict(int)
for char in text:
char_counts[char] += 1
print(char_counts)
# defaultdict(<class 'int'>, {'a': 8, 'p': 4, 'l': 2, 'e': 3, ' ': 4, 'b': 2, 'n': 4, 'c': 1, 'h': 1, 'r': 2, 'y': 1})Counter
-
Sequence type(문자열, 리스트 같은 해시 가능한 객체)의 요소들의 개수를 셀 수 있는 딕셔너리 서브 클래스
-
위의 Default Dict에서 사용한 word counter의 기능도 손쉽게 사용 가능하다.
-
set의 연산을 지원한다.
-
아래의 예에서 data에 있는 요소들의 개수를 세고 이를 딕셔너리 형태로 반환한다. 특정 값의 빈도를 쉽게 파악할 수 있다.
from collections import Counter
data = ["apple", "banana", "cherry", "banana", "apple"]
# Counter를 사용하여 데이터의 요소들의 개수 세기
data_counter = Counter(data)
print(data_counter) # Counter({'apple': 2, 'banana': 2, 'cherry': 1})Named Tuple
-
각 요소에 이름을 지정할 수 있는 튜플의 일종
-
튜플의 불변성을 가지면서도 각 요소에 명시적인 이름을 부여해 인덱스로만 접근하는 것 보다 가독성을 높인다.
from collections import namedtuple
# 네임드 튜플 정의
Point = namedtuple('Point', ['x', 'y'])
# 네임드 튜플 인스턴스 생성
p = Point(3, 4)
# 이름으로 요소에 접근
print(p.x) # 3
print(p.y) # 4