Today I Learned
오늘 공부한 내용은 이항분류 binary classification!
강의 복습
이진 분류 (binary classification)
주어진 데이터를 두 개의 범주 or 클래스로 분류하는 작업
ex) 스팸메일 분류, 암 유무 판단 등
-
특징변수(Feature Variable)
= 설명변수, 독립변수. 모델이 입력으로 사용하는 데이터의 속성
여러 특징변수를 조합해 목표 변수를 예측한다. -
목표변수(Target Variable)
= 종속변수, 반응변수. 모델이 예측하려는 출력 값.
이진 분류 문제에서 목표변수는 일반적으로 0,1 / T,F 같은 두 클래스를 말한다. -
이진 분류 모델은 훈련 데이터를 이용해 특징변수와 목표변수 사이 관계를 학습해 최종적으로는 훈련하지 않은 데이터의 특징변수로 목표변수를 예측한다.
-
데이터는 DataFrame으로 불러와서 원하는 특징변수와 목표변수만 추출해서, 목표변수를 이산형 레이블로 매핑하고, 훈련-테스트 데이터를 분할해 표준화 시킨다.
해당 데이터를 model에서 사용하게 tensor로 변환해 준 뒤 Dataset과 DataLoader 클래스를 생성하고, nn.Model을 상속한 이진분류 모델을 만들어 훈련을 시킨다. -
텐서로 변환하는 과정에서 목표변수의 훈련,테스트 데이터는 2차원으로 unsqueeze해주는데, 특징변수는 [데이터수, 특징수]로 이미 2차원이므로, 배치 처리 과정에서 호환성을 고려한 것이다.
-
DataSet & DataLoader 클래스
from torch.utils.data import Dataset, DataLoader
두 클래스로 전처리와 배치처리를 할 수 잇다.
로지스틱 회귀
이진분류 문제를 해결하기 위해 사용되는 머신러닝 모델.
특정 입력 데이터가 두 클래스중 하나에 속할 확률을 예측한다.
- 데이터를 잘 구분하는 최적의 선형 결정 경계(z= wx + b)를 찾아 이를 기준으로 이진 분류를 한다.
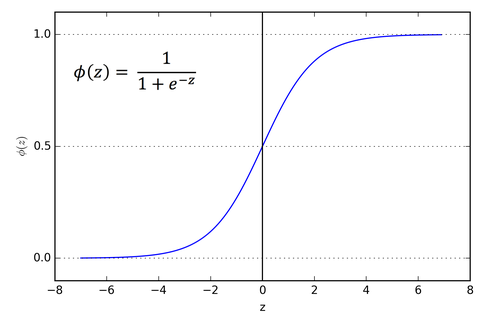
이미지 출처 : TheYoonicon
- 계산된 z값을 sigmoid 함수
y = Sigmoid(z) = 1/(1+exp(-z))에 넣어 결과를 0~1 사이의 클래스에 속할 확률로 변환한다. 0.5를 기준으로 1과 0으로 나눈다.
이진 교차 엔트로피(BCE)
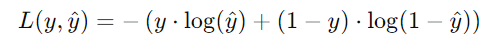
이진 분류 모델에서 사용되는 손실함수
cf. 선형회귀에서는 MSE(평균제곱오차)
-
최대 가능도 추정(MLE)
관측된 데이터를 기반으로 가장 잘 설명하는모수를 찾기 위해 가능도 함수를 최대화하는 것
(미분 계수가 0이 되는 지점이 최대가 된다)
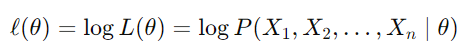
계산상의 이점을 위해 로그 가능도 함수를 사용하고 이를 최대화하는 파라미터(θ)를 찾는다.
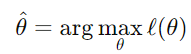
-
loss_funcion = nn.BCELoss()
이진 교차 엔트로피를 사용한 이진분류 모델의 손실함수 코드
코드 정리
- (Pandas) df
.isin(values)
주어진 values(리스트, 배열, series)의 값들과 일치하는 항목을 찾아 필터링 할 때 사용한다.
import pandas as pd
# DataFrame df에서 city열의 뉴욕, 시카고 항목만 필터링한 데이터
filtered_df = df[df['City'].isin(['New York', 'Chicago'])]- 목표 변수 이산형 레이블로 변환
뉴욕과 시카고 문자열 목표 변수를 1과 0의 숫자형으로 변환한다.
.loc으로 모든행의 city열을 선택한뒤, map으로 변경한다.
filtered_df.loc[:, 'City'] = filtered_df['City'].map({'New York': 0, 'Chicago': 1})- 데이터 분할 코드
일반적으로 훈련 6~8 : 테스트 1~2 : 검증 1~2 비율로 데이터를 나눈다.
from sklearn.model_selection import train_test_split
# 테스트를 20%로 설정한 코드. 난수는 관습적으로 42를 한다(별이유x)
f_train, f_test, t_train, t_test = train_test_split(f, t, test_size=0.2, random_state=42)- 데이터 전처리 과정
fit_transform은 데이터의 학습과 변환을 한번에 수행한다. 그래서 학습된 평균과 표준편차를 이용해 데이터를 변환한다. 하지만 테스트 데이터는 학습이 필요없으므로 transform으로 이미 학습된 스케일러를 이용해 데이터 변환만 한다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
f_train = scaler.fit_transform(f_train)
f_test = scaler.transform(f_test)과제
- 아래 두 코드의 차이는 cat은 마지막 차원에 3 텐서를 쌓는 것이고,
stack은 마지막에 새로운 차원을 만들어 3텐서를 쌓는 것이다.
green_img_t = torch.cat((zero_t, green_only, zero_t), dim=-1)
green_img_t = torch.stack((zero_t, green_only, zero_t), dim=-1)- Cross Entropy 손실함수는 모델의 예측확률이 0.5에 가까울 때 불확실성이 최대가 되어 모델의 예측 확률이 실제 레이블과 일치하지 않아 가장 큰 값을 가지게 된다.
0.5에 가깝다는 것은 분류가 맞는지 아닌지 애매한 상태이기 때문이다.
원래 CE는 손실함수이기 때문에 최소화 해야하며, 해당 문제는 반대 상황, 즉 최악의 경우를 말하는 것이다.
피어세션
- 선형회귀에서
y = w1x1 + w2x2 + ... wnxn + b
꼴로 절편(bias, intercept)은 하나, 가중치 (weight, 회귀계수, coef)는 여러 값.
intercept: [22.483147], other coef: [[-0.9662663 0.694296 0.25551897 0.7085805 -1.9914881 3.1231995
-0.17710298 -3.038284 2.205488 -1.7015713 -1.9768412 1.1222284
-3.6321542 ]]- optimizer를 바꾸면 결과가 달라질 수 있다.
adam, adagrad, sgd 등..
회고
- 마스터 클래스 들어보니 수학에 대한 공부를 절실히 느꼈다.
일단 바로 책 사서 기초 수학부터 주말이랑 남는 시간에 틈틈히 공부해보자!
