Today I Learned
오늘은 강의 진도를 빨리 나가는걸 목표로 삼았다. 일단 이론을 다 듣고 내일부터 실습과 과제를 병행해서 이번주는 빠르게 나가보려고 한다. 화이팅!!
강의 복습
피처 엔지니어링
머신러닝 모델의 성능을 개선하기 위해 데이터를 변형하고 새로운 피처(특성)를 만드는 과정.
-
피처간 결합을 통해 새로운 피처를 만드는
특성 추출(extraction)과 중요한 피처를 선택하는 과정인특성 선택(selection)두 가지가 있다. -
데이터 전처리, 특성 선택, 특성 변환, 특성 생성, 인코딩, 특성 추출 같은 단계가 있다.
-
데이터 전처리 단계에서 결측치와 이상치를 처리해야 한다.
결측치
=Null, NA. 데이터에서 비어있거나 누락된 값.
-
처리방법으로는 행or열을
삭제, 대표값(평균,최빈,중간값)으로대체, 알고리즘을 활용해예측하는 방법이 있다. -
pip install missingno: 결측치 시각화 라이브러리 -
결측치가 과반수면 결측치 유무만 사용하거나 아예 열을 제외하는 것이 좋다.
보통 결측치가 유의미하게 많다는 기준은 5%정도 -
결측치 대체할 때 너무 복잡하거나 단순하면 bias(편향)이 생길 수 있으니 주의해야한다.
대표값을 사용하면 이상치에 민감해질 수 있고, 예측모델을 사용하면 과적합이 될 수 있다.
이상치
=Outlier. 다른 데이터포인트들과 현저히 차이나는 값.
- 입력, 측정과정에서 오류로 인해 발생할 수도 있고, 자연적이거나 특별한 사건에 의해 발생할 수도 있다.
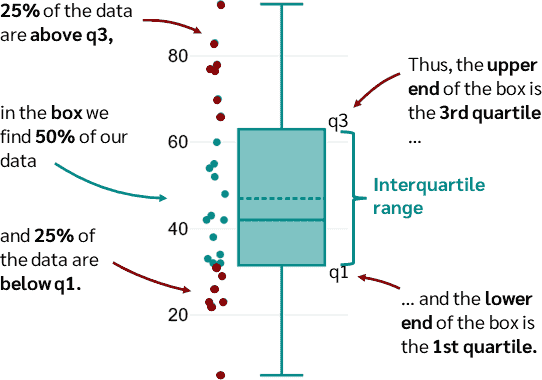 box plot 이미지 출처 : datatab
box plot 이미지 출처 : datatab
-
box plot, 산점도, 히스토그램 등의 시각적방법으로 탐지할수도 있다.
-
IQR : Q1과 Q3의 차이.
일반적으로Q1 - 1.5 * IQR보다 작거나Q3 + 1.5 * IQR보다 크면 이상치로 간주한다. -
Z-score : 평균으로부터 얼마나 떨어져있는지 표준편차 단위로 측정하는 방법.
일반적으로 +-2~3을 넘어선 데이터를 이상치로 간주한다. -
DBSCAN
밀도 기반 클러스터링 기법. K-mean과 유사. 클러스터에 멀어진 포인트가 이상치
클러스터링
유사한 특성을 가진 데이터를 그룹으로 묶는 기법
-
데이터셋에서 패턴을 찾아내 구조를 이해하는 데 도움을 줄 수 있고, 이상치 판별에도 도움이 되고, 클러스터링 자체로 특성 추출과 차원 축소가 가능하다.
-
K-mean, 계층적 클러스터링, DBSCAN, GMM 등의 방법이 있다.
-
대부분은 유클리드 거리를 사용하기 때문에 스케일링 관련 전처리가 중요하다. 제대로 하지 않으면 편향된 결과를 가져올 수 있다.
차원 축소
고차원 데이터에서 중요한 특징을 유지하면서 데이터릐 차원을 줄이는 기법
-
모델 성능향상, 과적합 방지, 시각화 가능의 장점이 있지만, 정보 손실이 있을 수 있다.
-
특징 추출
원래의 특징을 조합하거나 변형해서 새로운 저차원 특징을 만드는 방법
원래 정보는 유지하면서 차원을 축소한다. -
특징 선택
특징 중에서 중요한 것만 선택하고 덜중요한 특징은 제거.
시계열 데이터
시간의 흐름에 따라 순차적으로 기록된 데이터.
-
변화와 패턴, 변동성 예측에 대한 통찰을 얻는 것이 목표.
-
시계열 데이터의 특징
추세(trend) : 장기적인 변동
계절성(seasonality) : 특정 요일이나 계절(고정된 빈도)에 따라 변동
주기(cycle) : 고정된 빈도는 아니지만 형태적으로 유사하게 반복되는 패턴
노이즈(noise) : 오류 같은 원인으로 생기는 왜곡 -
성분분석
변동폭 일정하면 가법, 변동폭이 시간에 따라 커지면 승법 사용
가법모델(additive model) : 추세 + 계절성 + 주기 + 노이즈
승법모델(multiplicative model) : 추세 * 계절성 * 주기 + 노이즈 -
정상성 - 시간에 따라 통계적 특성 변화 x / 비정상성 - 시간에 따라 통계적 특성 변화
시계열 데이터는 시간에 따라 통계적 특성이 변한다. 시간이 지나면 물가, 사용자 수 같은게 변하기 때문에 시간에 따라 결과에 영향이 간다. -
따라서 모델에 활용하기 위해 비정상성을 제거하는데, 차분, 로그연산 같은 방법을 쓴다.
시계열 데이터 전처리
- 평활(smoothing)
데이터의 불필요한 변동을 제거하는 방법.
노이즈를 줄여 추세와 계절성 파악을 쉽게 해준다.
가중이동평균(WMA), 지수이동평균(EMA) 같은 방법을 사용한다.
이동평균은 구간(window)을 정하고 시간을 이동해가며 평균을 구하는 방법이다.
이미지 데이터
-
이미지가 어떤 도메인(의료, 교통, 만화 등)에서 왔는지, 어떤 task(분류, 생성 등)를 수행해야 하는지, 그에맞는 quality가 갖춰져 있는지가 중요하다.
-
저장방식
RGB : 빨초파의 합으로 색을 표현
HSV : 색상, 채도, 명도로 구분
CMY(K) : RGB의 보색. 인쇄에 용이
YCbCr : 밝기 / 파랑에대한 색차 / 빨강에 대한 색차로 구분. 디지털 영상에 용이 -
포맷
JPEG : 손실압축. YCbCr 색상공간 사용. 양자화로 손실 압축
PNG : 무손실 압축. 투명도 포함
WEBP : 구글 이미지 포맷. 위의 방식들 포함 가능
SVG : 벡터 이미지. 크기에 무관하게 저장. 로고에 사용
이미지 데이터 전처리
-
퀄리티 향상, 양 증대, 쉬운 검증(시각화로 인지 개선)을 위해 전처리를 진행한다.
-
색상, 사이즈 조정, 노이즈 삽입, 특성 추출, affine 변환(회전, 왜곡, 이동 등)의 방법이 있다.
-
OpenCV, PIL, scikit-image, albumentataions, torchvision, scipy 등의 라이브러리가 있다.
텍스트 데이터
-
언어를 다루기 때문에 구조, 순서에 따라 의미가 변경되거나 오타같은 오차도 많고 신조어 등 여러 변수가 너무 많아 텍스트 데이터는 까다롭다.
-
짧은 단어나 표현에 대한 전처리는 패턴, 토큰화, 소문자 변환, 철자 교정, 불용어 제거가 있고, 문단 단위의 전처리는 문장 토큰화, 띄어쓰기 교정, 문장구조 분석, 문맥의미 분석 등이 있다.
-
정규식 : 문자열의 특정한 패턴을 표현하는 방법
-
wordcloud : 텍스트 데이터에서 단어나 구의 빈도수를 시각적으로 표현한 그래픽.
피어세션
-
오늘은 진도에대한 질문이 없어 코딩테스트 얘기를 했다.
-
최근에 구현 문제와 CS 문제가 많아지는 추세. 공부 방향에 대해 얘기했다.
-
코테 문제를 보자마자 제약사항부터 봐서 시간복잡도와 메모리를 체크한 뒤 어떤 알고리즘, 어떤 자료구조를 써야 제한안에 문제를 풀 수 있을 지 부터 생각하고 문제를 풀어볼 것!
회고
- 일단 오늘은 진도부터 다 나가고 실습과 과제는 내일로 미뤄뒀다. 이번주차 데이터 시각화 파트는 정리 자체가 힘들어서 그냥 개념정도 이해하고 라이브러리 사용법은 따로 정리하지 않고 그때그때 찾아보는 방향으로 진행하는 게 좋을 것 같다.
