Today I Learned
오늘은 EDA에 사용하는 코드들을 정리해보았다.
EDA 코드 정리
- 구글 드라이브 접근 허용
from google.colab import drive
drive.mount('/content/drive', force_remount=True)- csv 파일 가져오기
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/data/data.csv')- seaborn 연습용 내장 데이터셋 : iris, tips, titanic
import seaborn as sns
df = sns.load_dataset('tips')
df.head()Pandas
-
df.head() : 상위 n개의 행 반환. default는 5
df.tail() : 하위 n개의 행을 반환. default는 5
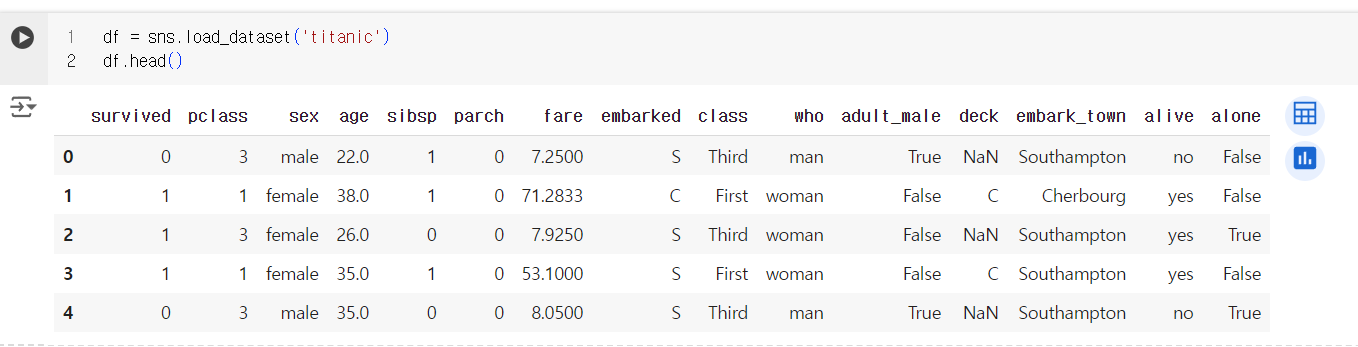
-
df.info() : DF의 기본 정보를 제공. 컬럼명, 데이터 타입, non-null의 개수 등
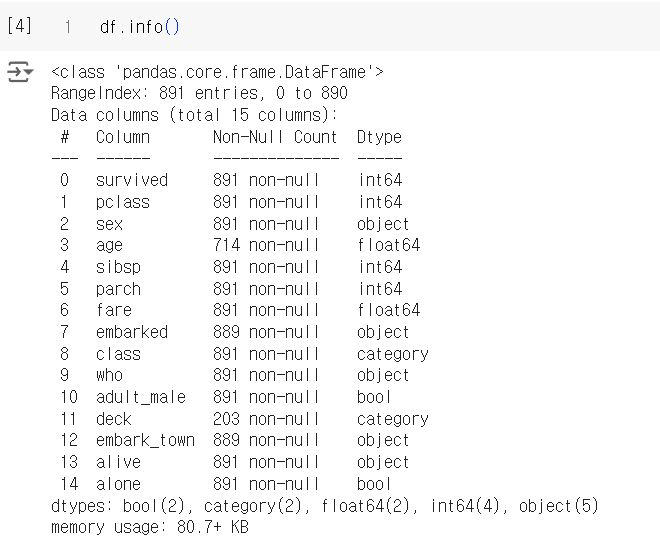
-
df.describe() : 수치형 열에 대한 통계 반환
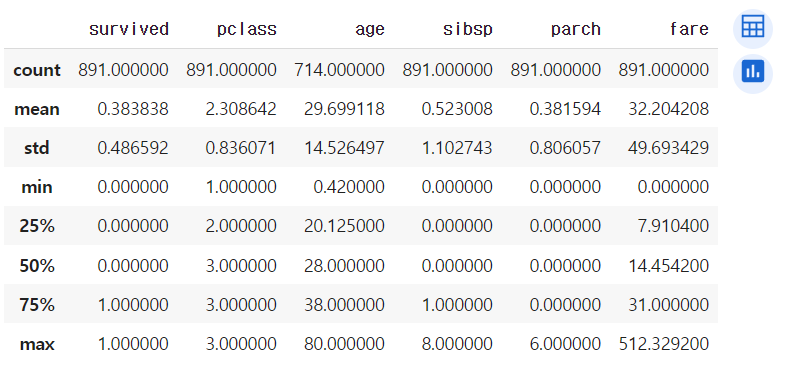
-
df.corr() : 수치형 열 간의 상관관계 계산. 수치형 열만 따로 빼야한다.
numeric_df = df.select_dtypes(include=[np.number])
numeric_df.corr()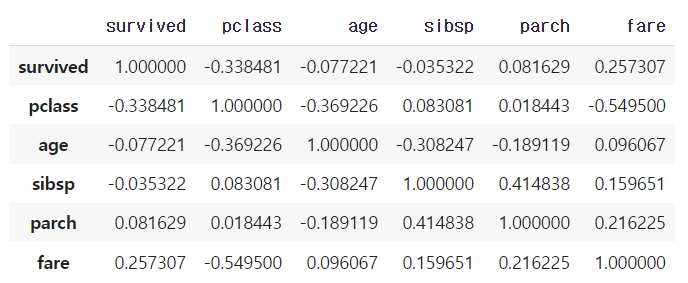
-
df.agg(['mean', 'std']) : mean, std, sum, min, max 등의 기본 통계 함수와 사용자 정의 함수같은 연산들을 사용하게 해준다. 주로 groupby()와 함께 사용되지만 단독으로 DF나 Series에 적용할 수 있다.
-
df.dtypes : 각 열의 데이터 타입
df.shape : 행, 열의 개수를 튜플 형태로 반환 ex. (891, 15)
df.columns: DF의 열 이름들을 반환
df.index: DF의 인덱스(행 이름)를 반환 RangeIndex(start=0, stop=891, step=1)
df.isnull().sum(): 각 열의 null 값 개수 반환 -
df['column_name'].value_counts() : DF 각 열에 대해 고유한 값들의 빈도를 반환.
df['column_name'].unique(): 특정 열의 고유한 값들을 반환
df['column_name'].nunique(): 특정 열의 고유한 값의 개수를 반환
Seaborn
- 열마다 boxplot 생성
numeric_columns = df.select_dtypes(include=['float64', 'int64']).columns
for col in numeric_columns:
plt.figure(figsize=(12, 5))
sns.boxplot(hue='survived', x=col, data=df)
plt.xlabel(col)
plt.ylabel('Value')
plt.title(f'Boxplot of {col} by survived')
plt.show()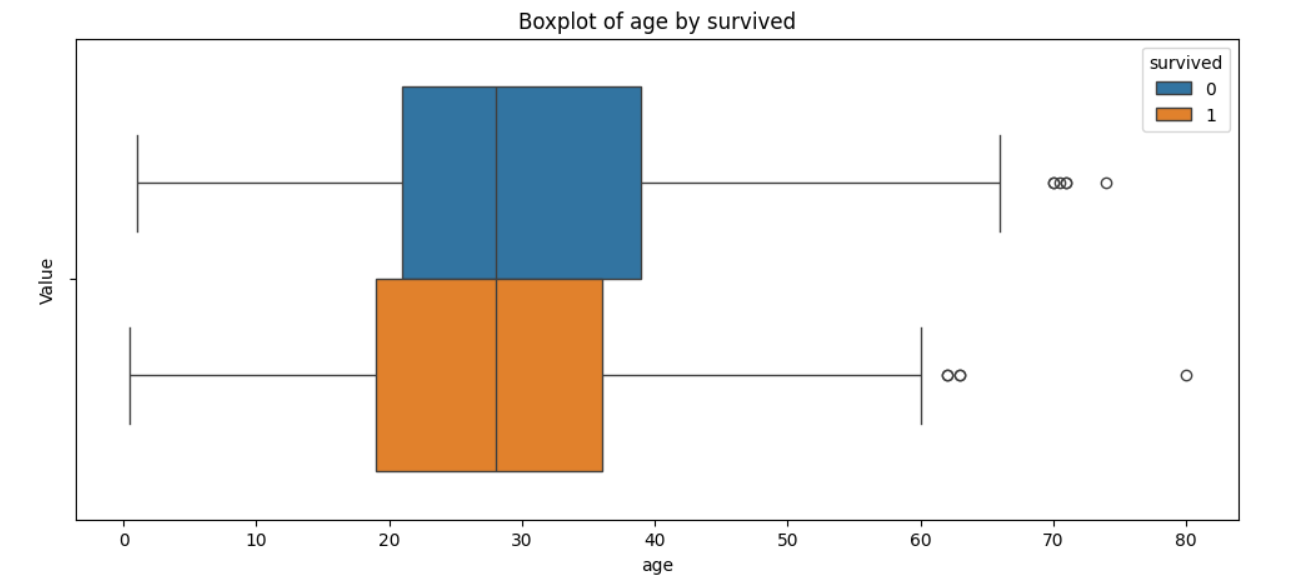
- 열마다 countplot(barplot) 생성
numeric_columns = df.select_dtypes(include=['float64', 'int64']).columns
for col in numeric_columns:
plt.figure(figsize=(30, 7))
sns.countplot(hue='survived', x=col, data=df)
plt.title(f'Countplot of {col} by survived')
plt.show()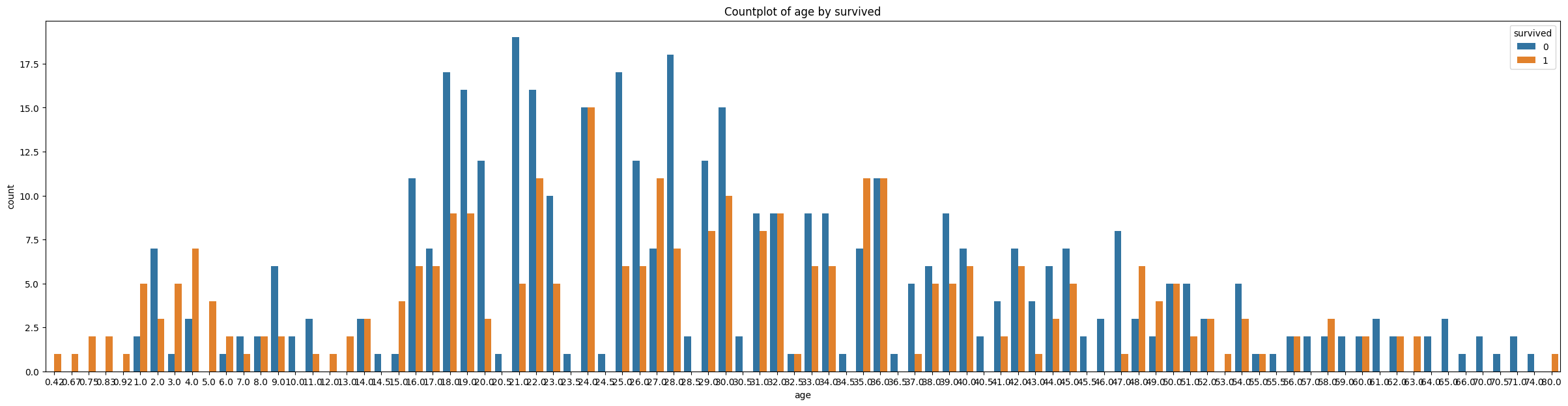
- 평균과 표준편차 시각화 : agg_stats를 전치(.T) 해줘야 한다.
agg_stats = df.select_dtypes(include='number').agg(['mean', 'std'])
agg_stats.T.plot(kind='bar', yerr=agg_stats.loc['std'], capsize=4)
plt.title('Mean and Standard Deviation of Titanic Dataset Numeric Columns')
plt.ylabel('Values')
plt.xticks(rotation=45)
plt.legend(title='Statistics')
plt.tight_layout()
plt.show()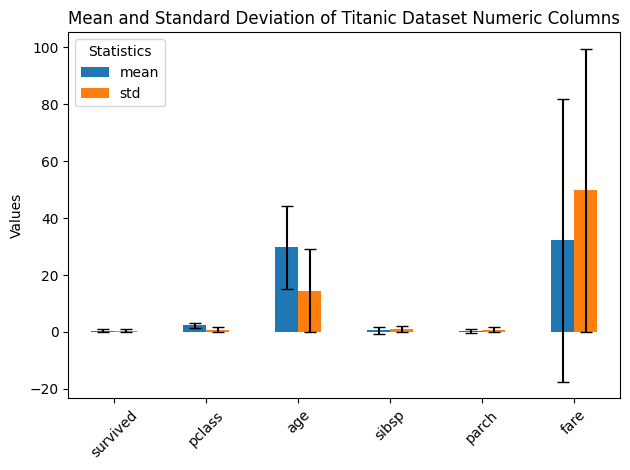
피어세션
- 오늘은 게임 데이터를 가지고 EDA를 한 내용들을 각자 공유했다.
정답은 없는 자료였지만 각자의 인사이트를 듣고 깨닳은 게 있었다.
멘토링
최신 추천 시스템 모델들
Deep Learning-based CF
-
NCF(neural CF) 2018
CF를 NN으로 구현.
inner product(선형 결합)만으로는 한계가 있는 Matrix Factorization을
NN을 통해 Non-linear성을 부여해 user와 item의 관계를 좀 더 복잡하게 표현
ALS와 마찬가지로 Implicit Feedback에 집중함 -
NGCF(neural graph CF)
NCF로도 부족한 user-item의 관계를 graph structure로 표현.
유저와 아이템의 관계를 graph로 여러번 얽힌 걸로 표현해 embedding을 계속 update -
LightGCN
NGCF가 임베딩 벡터를 업데이트하는 과정이 너무 과해서 simplify
현실 세계의 user-item 관계는 그렇게 안복잡하고 단순하다면서 간단한 모델을 주장
불필요한 로직을 제거해 neighborhood aggregation만 넣어 모델을 경량화
간소화한 모델이지만 성능이 더 좋음.
AutoEncoder + CF
AutoEncoder를 사용해 Latent vector 추출해 CF 로직 적용
Language Model to Rec
- 일반적으로 NLP,CV 논문이 나오고 1~2년 뒤에 추천시스템에 적용한 논문이 나온다.
- 그래서 추천 도메인만 아는것 보단 다른 도메인 논문도 보면 좋다.
- LLM을 Fine-tuning하는 방식 or 추천기술과 LLM을 병합하는 방식 두가지로 최근엔 많이 나온다.
후자의 경우 CF 모델에서 추출된 Latent factor 값을 LLM 프롬프트 입력으로 활용하는 논문도 있다.
회고
- 내일부터 프로젝트를 시작하는 데 커리큘럼 상 힘들긴 하겠지만, 프로젝트 주제가 재밌어 보여 기대가 된다.
