Today I Learned
프로젝트 D-1. git 정리하고 프로젝트 마무리 단계 돌입
EDA 결과
-
모든 피쳐 기본적인 상관관계 파악 후 추려내기
raw 파일에서 모든 feature들의 target과의 상관관계를 파악하고, 도메인 지식과 엮어 중요한 기본 feature들을 골라냄
-
target을 수치로 바꿔 회귀모델로 결과 낼 수 있는지 보고 xgboost를 간단하게 적용해 기본 피처의 Feature Importance 확인
4진 분류인 target을 등락% 수치형 데이터로 바꾸고 이를 회귀모델로 사용해 결과를 낼 수 있는지 살펴보니 가능성이 보임.
그리고 xgboost를 적용해 기본 피처들의 Feature Importance를 확인해봄
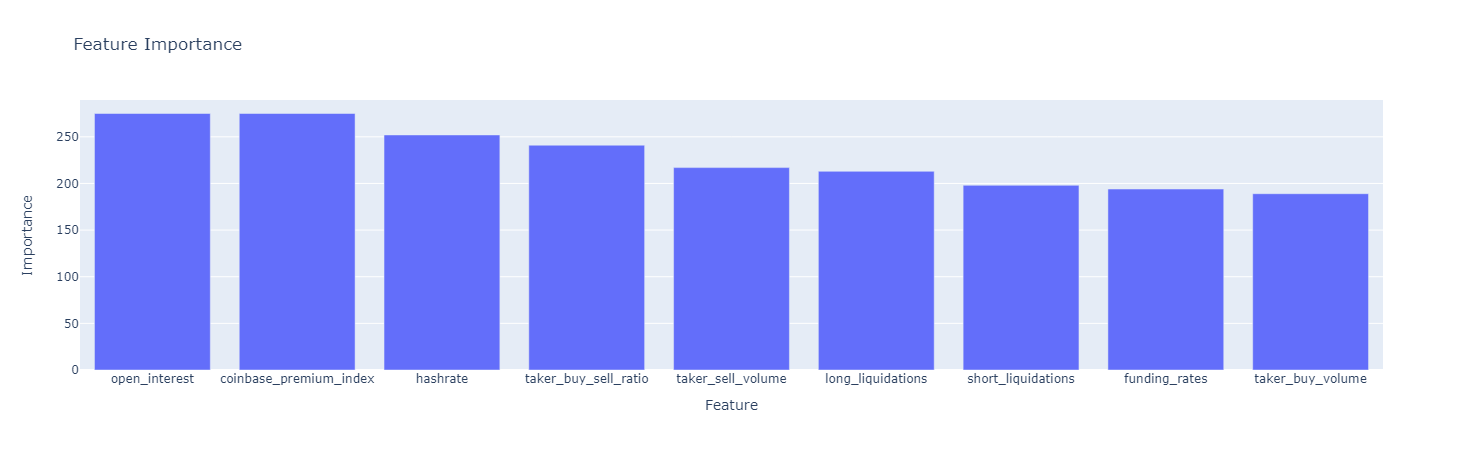
-
위의 결과를 토대로 feature enginnering을 통해 새 feature 생성 및 선택
분포가 적절하지 않은 데이터는 로그변환 후 표준화를 진행하고, buy+sell=total volume을 만들어 MA(이동평균) 지표를 생성.
liquidaion은 차이와 합 지표를 생성. 주기성 파악을 위해 요일을 0~6으로 할당해 feature 생성 -
데이터 증강 시도해보고 time series CV 적용
target 1,2번에 해당하는 데이터보다 0,3번 데이터가 적어 이를 보정하기 위해 RandomOverSampler로 데이터 증강을 시도.
그리고 현재의 random seed 기반 Validaion은 적합하지 않다고 생각해 time series CV 적용 시도
하지만 데이터 증강이 오히려 test accuracy를 하락시켜 이 부분은 추후 논의 필요 -
간단한 회귀모델과 분류모델로 엔지니어링 된 피쳐 적용해서 Feature Importance 확인과 test 점수 확인
모델 test 결과
- fe_GradientBoostingRegressor_1은 model = GradientBoostingRegressor(n_estimators=500, learning_rate=0.01, max_depth=7,subsample=0.9, max_features=None, random_state=42)에 결측치 .mean()으로 대체
-> test 결과 0.3913 - fe_GradientBoostingRegressor_2는 동일한 조건에서 결측치 .interpolate(method='linear', limit_direction='forward', axis=0)로 대체
-> test 결과 0.3828 - fe_RandomForestRegressor_1은 model = RandomForestRegressor(n_estimators=300,max_depth=10,min_samples_split=2,min_samples_leaf=1,random_state=42,n_jobs=-1)
-> test 결과 0.3793 - fe_HistGradientBoostingClassifier_1은 model = HistGradientBoostingClassifier(learning_rate=0.05,max_iter=200,l2_regularization=0.01, early_stopping=True,random_state=42). BorderlineSMOTE(random_state=42, sampling_strategy={0: 1000, 1: 3544, 2: 3671, 3: 2000}). X_test.fillna(X_test.mean())
-> test 결과 0.3807
- 하지만 위의 feature importance라는 지표 자체가 훈련된 모델에 기여한 피처의 중요도를 나타내는 것으로 보이지만, 훈련 정확도가 0.45 정도에서 피처 선택의 타당성을 보장하는지에 대한 확인이 필요하다.
피어세션
- 같이 모여서 feature를 선택하고 새로 만드는 작업을 했다.
회고
- 이번 프로젝트는 반성해야될게 많다. 너무 따로 eda를 진행해서 방향이 제각기 달랐고, 진행도 느렸으며, 가설부터 제대로 세우거나 도메인 공부가 부족했다고 느꼈다. 다음 프로젝트부터는 시작부터 계획 잘 짜서 이를 보완해야겠다.
