Today I Learned
오늘은 2주간 배울 모델 최적화와 경량화를 개괄로 공부했다.
앞으로 아래의 내용들을 점차 심화로 배울 예정이다.
모델 최적화 & 경량화
AI 모델들이 점점 더 크고 복잡해지면서 실제 서비스에 적용하기 위해선 모델의 경량화와 최적화가 중요해졌다.
모델 경량화
AI 모델의 성능은 최대한 유지하면서, 모델 크기와 계산 비용을 최대한 감소시키는 기술
모델 경량화가 필요한 이유
-
실시간 처리의 latency 단축을 위해선 빠른 예측을 위해 모델 경량화가 필수
ex) 자율주행, 헬스케어, 핀테크 -
on-device(폰, IoT 등) 기기는 연산 자원이 한정되어있으므로 경량화가 필수
-
다양한 환경에서 거대한 모델을 운영하기에는 현실적인 제약이 많이 따름
주요 경량화 기법
-
아래의 3가지 기법이 대표적. 상황에 따라 단독 or 복수의 방법을 통해 모델을 경량화한다.
이 외에도 최근에는 강화학습이나 특정 규칙 기반으로 경량화 자동 연구도 진행 중이다. -
경량화에는 항상 모델 성능과 크기의 Trade-off 관계를 고려해야한다.
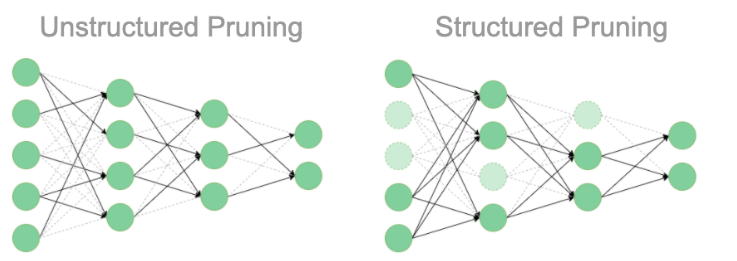
1. Pruning (가지치기)
중요도가 낮은 파라미터(뉴런, 연결)를 제거해 네트워크를 축소하는 기법
 이미지 출처 : ODSC
이미지 출처 : ODSC
-
Structured Pruning (구조적 가지치기)
뉴런, 채널, 레이어 전체를 제거하는 방식. (노드를 삭제)
Dense computation에 최적화된 환경에 적합 -
Unstructured Pruning (비구조적 가지치기)
개별 파라미터 단위로 제거하는 방식 (노드는 두고 연결만 삭제)
연결된 가중치를 개별적으로 검증해 독립적으로 제거
Sparse computation에 최적화된 환경에 적합
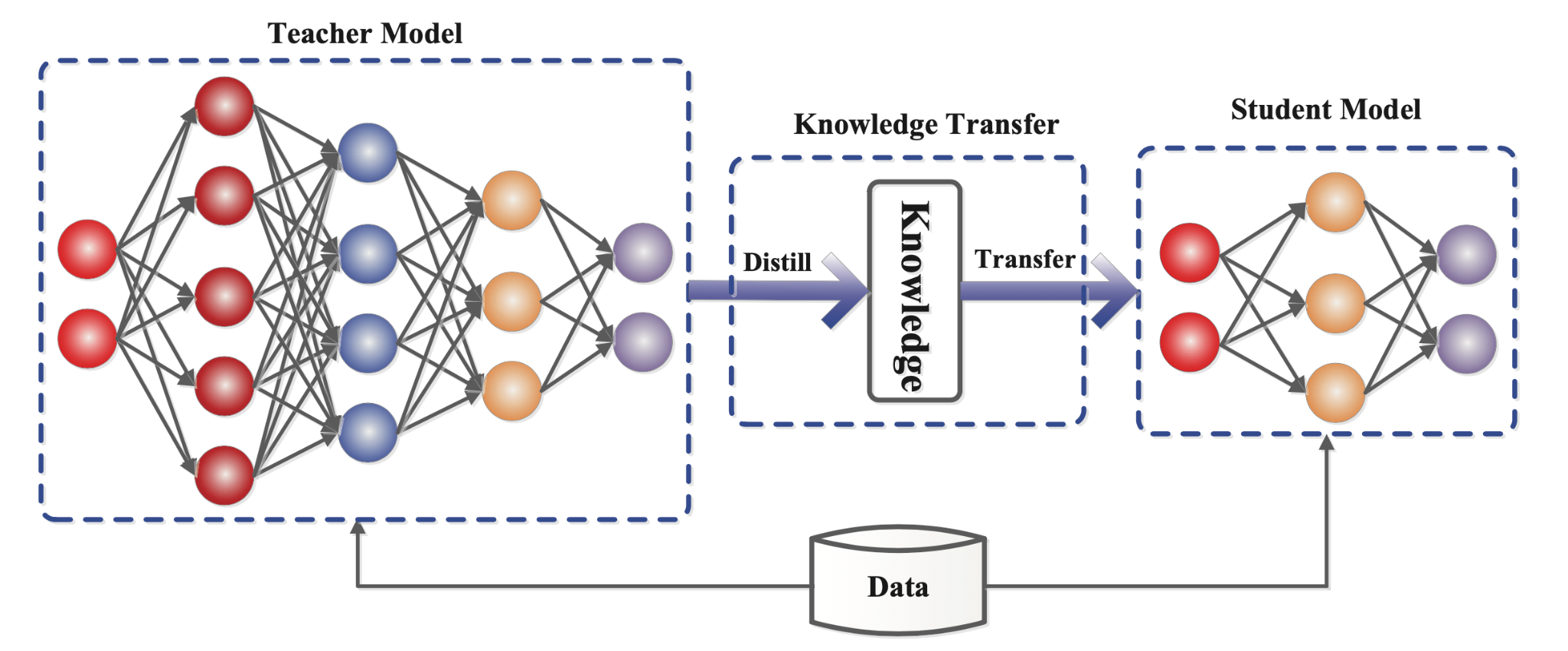
2. Knowledge Distillation (지식 증류)
큰 모델(Teacher)의 지식을 작은 모델(Student)에게 전달하는 방식
 이미지 출처 : Knowledge Distillation: A Survey (2020)
이미지 출처 : Knowledge Distillation: A Survey (2020)
-
성능 저하를 최소화하면서 모델을 압축하는 방법
-
White-box KD : LLaMA같은 오픈소스 공개 모델을 Teacher로 활용
-
Black-box KD : ChatGPT 같은 비공개 모델을 Teacher로 활용
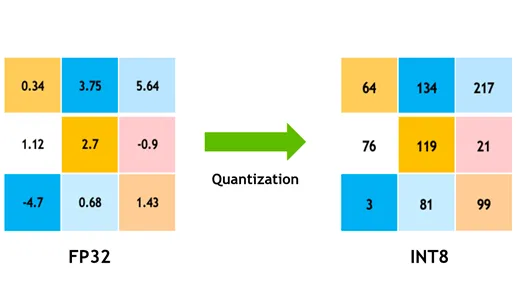
3. Quantization (양자화)
모델의 파라미터를 더 작은 데이터타입으로 변환하는 기법.
 이미지 출처 : medium
이미지 출처 : medium
-
float32 → float16, float32 → int8 같이 파라미터의 데이터 타입을 더 작은 비트 정밀도를 가진 타입으로 바꾸는 기법.
-
이를 통해 약간의 정확도 손실로 모델 크기를 줄이고 추론 속도를 높일 수 있다.
PEFT
- Fine-tuning
사전 훈련된 AI 모델을 특정 작업이나 도메인에 맞게 최적화하는 과정
모델의 모든 파라미터를 업데이트하므로 비용이 크다.
PEFT
Parameter-Efficient Fine-Tuning
모델의 전체 파라미터를 업데이트하지 않고 일부 선택된 파라미터만 조정함으로써 학습의 효율성을 극대화하는 방법
-
Adapter Layers
기존 네트워크의 파라미터는 고정한 채로, 기존 레이어 사이에 작은 추가 레이어를 삽입하여 그것만 학습. 기존 모델의 약 3.6% 개수의 파라미터만 어뎁터로 추가해도 풀파인튜닝과 비슷한 성능 -
LoRA
Low-Rank Adaptation. 저차원 행렬을 사용하여 특정 층의 파라미터를 조정하는 방식
어뎁터와 비슷하지만 병렬적으로 처리해 연산의 효율성을 갖는다. -
Prefix Tuning
모델의 입력단에 학습 가능한 파라미터를 추가하는 방식
모델 최적화
단일 GPU로는 학습하기 불가능할 정도로 점점 모델의 size가 커지고 있다.
Distributed Training (분산 학습)
모델을 여러 GPU로 분산해서 큰 모델을 학습하는 방법
- Data Parallelism (데이터 병렬화)
동일한 모델을 여러 GPU에 복제하여 각각 다른 데이터로 학습해 각 GPU에서 계산된 그래디언트를 취합하여 모델 파라미터 업데이트하는 방법.
한 GPU로 여러번 작업할 걸 여러 GPU로 한번에 가능(물론 취합 과정에서 overhead 발생)
BERT 같은 상대적으로 작은 모델 학습시 사용.
학습 속도가 높아진다.
- Model Parallelism (모델 병렬화)
큰 모델을 여러 GPU에 나누어 처리하는 방식
하나의 GPU로 감당하기 힘든 대규모 모델 학습에 적합
모델의 레이어를 분할하거나 학습 피처를 분할하는 방식으로 구현한다.
메모리 효율성이 높아진다.
