Today I Learned
오늘 배운 내용은 또다른 경량화 기법인 지식증류!
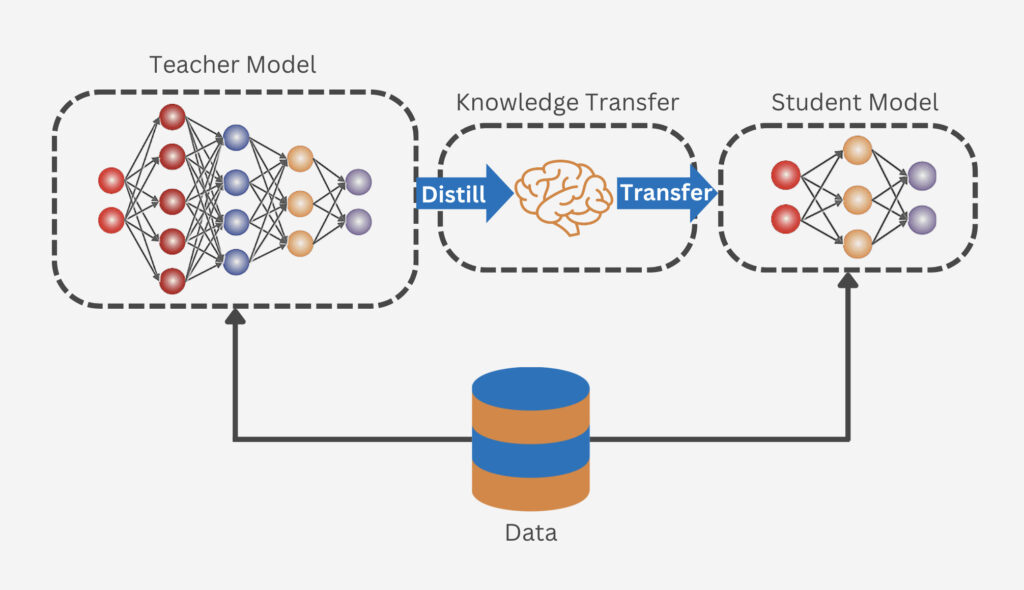
Knowledge Distillation (지식 증류)
큰 모델(Teacher)의 지식을 작은 모델(Student)로 전달하여 작은 모델의 성능을 향상시키는 딥러닝 기법
 이미지 출처 : innodata
이미지 출처 : innodata
-
Teacher Model
이미 학습된 큰 규모의 복잡한 네트워크 -
Student Model
상대적으로 작은 규모의 네트워크로, Teacher model의 지식을 전달받음
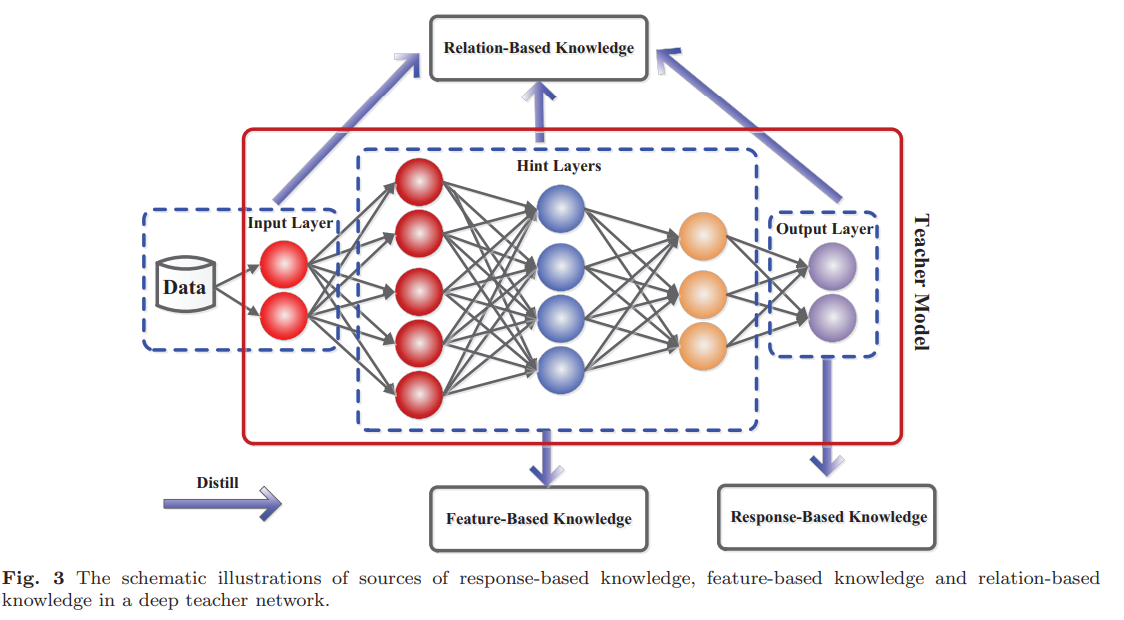
분류
 이미지 출처 : Knowledge Distillation: A Survey (2021)
이미지 출처 : Knowledge Distillation: A Survey (2021)
-
Feature-based : Teacher 중간 레이어의 feature나 representation을 사용
-
Response-based
Logit-based : Teacher의 logit을 사용
Output-based : Teacher의 output을 사용
-
Transparency : 모델의 내부 구조나 파라미터 열람 가능 여부
white-box : Teacher의 내부 구조와 파라미터 등을 알 수 있는 경우 (LLaMA)
gray-box : Teacher의 output, 최종 logit 값이나 제한된 정보만 알 수 있는 경우
black-box : Teacher의 output만 알 수 있는 경우 (ChatGPT, Claude, ..) -
black-box는 output-based만 사용 가능
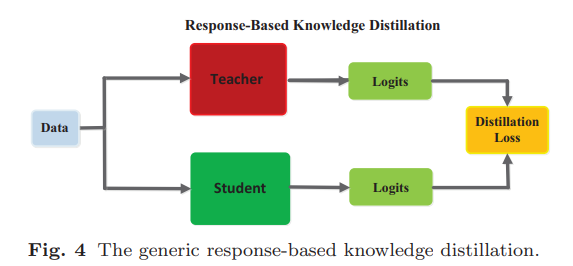
Logit-based KD
가장 기본적인 KD로 Teacher 모델의 출력 logit을 Student 모델이 학습하는 방식
 이미지 출처 : Knowledge Distillation: A Survey (2021)
이미지 출처 : Knowledge Distillation: A Survey (2021)
-
logit
신경망에서 최종 활성화 함수(softmax)를 적용하기 전의 출력값
분류 작업에서 각 클래스에 속할 정규화되지 않은 확률 분포값 -
각각 클래스 분류 학습을 진행한 뒤, Student의 클래스 예측과 Teacher의 클래스 예측이 유사해지도록 Student는 추가 학습을 진행한다. KL-Divergence Loss를 줄이는 방식으로 학습을 하는데 이 과정에서 지식이 전달된다.
-
Teacher는 실제 레이블에 대한 Cross Entropy Loss로 사전학습을 진행(Hard Label)
그 후 클래스 확률값(softmax 결과값)을 지식으로 전달한다. -
Student는 Cross Entropy Loss에 더해서 Teacher의 확률값으로 모사하는 KL-Divergence Loss를 추가로 학습한다.
-
Temperature
softmax 적용 전, logit을 나눠주는 동일한 값. 값이 크면 확률분포가 부드럽게(균등하게)되고, 작으면 날카롭게된다. 일반적으로 부드럽게 만드는 적절한 값을 넣으면 KD에 크게 도움이 된다.
Feature-based KD
Teacher 모델의 중간 레이어(hidden layer)에서 추출되는 특징(feature)을 Student 모델이 학습하는 방식
 이미지 출처 : Compressing Medical Deep Neural Network Models for Edge Devices using Knowledge Distillation
이미지 출처 : Compressing Medical Deep Neural Network Models for Edge Devices using Knowledge Distillation
-
중간 레이어에는 초기 레이어가 잡는 저수준 특징과 후반 레이어가 잡는 고수준 특징의 중간 지점인 객체의 일반적인 특징을 포착하기 때문에 지식이 더 의미가 있다.
-
Logit-based KD가 KD Loss라면, Feature-based KD는 중간에 MSE Loss 과정이 있다.
-
Teacher와 Student의 중간 레이어 feature를 비슷하게 만들어야 하는데, 문제는 두 feature의 차원이 다를 것이다.
-
두 차원을 맞춰주기 위해 regressor layer R을 사용하고, MSE Loss를 이용해서 두 feature간 차이를 최소화한다.
Imitation Learning (모방 학습)
다른 agent의 행동을 모방해서 자신의 정책을 학습하는 방법
-
black-box를 teacher로 삼을경우 output 말고는 다른 정보를 얻을 수 없기 때문에 Imitation Learning 방법을 사용해야한다. 주로 NLP 쪽에서 사용.
-
Knowledge Distillation에서만 쓰는 개념은 아니고 data augmentation에서도 쓴다.
-
다른 KD 기법과 다르게 지식 자체가 설명 가능해서 인간이 이해할 수 있다.
다만 심층 학습이 어렵고 데이터의 품질 편차가 심하다. -
모방 데이터 수집 -> 전처리 -> student 학습 의 과정을 거친다.
-
모방 데이터는 공개된 데이터를 쓰거나 Teacher 모델에게 직접 입력해 자동생성한다.
지식 추출에는 prompt engineering을 활용한다.
