Today I Learned
RecSys 성능 평가지표에 대해 복습했다.
RecSys 성능 평가지표
-
비즈니스 측면에서는 매출이나 PV(page view, 방문자수), CTR(Click-Through Rate, 클릭 확률)이 더 늘어났는 지 체크.
-
품질관점에서는 연관성(유저와 아이템 관련성), 다양성, 새로움(novelty, 추천되는 아이템이 중복되지않고 갱신), 참신함(serendipity, 유저의 기대에 없던 뜻밖의 추천)이 있다.
Ranking 사용 지표
-
기본 설명
Precision = (True Positives) / (True Positives + False Positives)
Recall = (True Positives) / (True Positives + False Negatives)
precision은 FP를 줄여야하니 오진을 줄여야하고,
recall은 FN을 줄여야하니 target을 못맞추고 넘어가는걸 줄여야한다. -
Precision@K= 유저가 관심있는 아이템 수 / K
상위 K개 추천 결과 중 관련 있는 아이템의 비율. 추천의 정확성 측정. -
Recall@K= 추천된 유저 관련 아이템 수 / 유저가 관심있는 전체 관련 아이템 수
유저가 관심있는 전체 관련 아이템 중 상위 K개 추천에 포함된 비율
관련 아이템 포함 정도 측정. 망라성을 평가한다. K값이 커질수록 커진다. -
AP@K
Precision@1~Precision@K까지의 평균값. 관련 아이템을 더 높은 순위에 추천할 수록 점수 상승
유저 한명당 하나씩 나옴. -
MAP@K
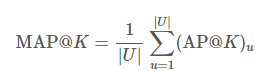
위의 AP@K를 전체 유저 m명의 평균을 낸 값.
nDCG@K
이상적인 순위와 실제 순위 비교. 상위 순서에 더 큰 가중치 부여. 0~1 사이의 정규화된 값.
MAP와 다르게 연관성을 이진값이 아니라 수치로도 사용할 수 있다.
DCG(순위에따라 관련도 합을 discount)를 IDCG(이상적인 상황에서 DCG)로 나눈 값.
in torch
- torch 기반의 추천시스템 평가지표 라이브러리인 recsys_metrics 사용
import torch
from recsys_metrics import precision, recall, map, ndcg
# 예측값과 실제값 준비
preds = torch.tensor([[.5, .3, .1], [.3, .4, .5]])
target = torch.tensor([[0, 0, 1], [0, 1, 1]])
# k값 설정하여 각 지표 계산
k = 2
p_at_k = precision(preds, target, k=k)
r_at_k = recall(preds, target, k=k)
map_at_k = map(preds, target, k=k)
ndcg_at_k = ndcg(preds, target, k=k)[1]in tensorflow
import tensorflow as tf
import tensorflow_ranking as tfr
# 메트릭 초기화
map_metric = tfr.keras.metrics.MeanAveragePrecisionMetric(topn=10)
ndcg_metric = tfr.keras.metrics.NDCGMetric(topn=10)
precision = tf.keras.metrics.Precision(top_k=10)
recall = tf.keras.metrics.Recall(top_k=10)
# 예시 데이터
y_true = tf.constant([[0., 1., 1.]])
y_pred = tf.constant([[3., 1., 2.]])
# 메트릭 계산
map_score = map_metric(y_true, y_pred)
ndcg_score = ndcg_metric(y_true, y_pred)
p_score = precision(y_true, y_pred)
r_score = recall(y_true, y_pred)
# 모델 컴파일시 메트릭 사용
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=[
tfr.keras.metrics.MeanAveragePrecisionMetric(topn=10),
tfr.keras.metrics.NDCGMetric(topn=10),
tf.keras.metrics.Precision(top_k=10),
tf.keras.metrics.Recall(top_k=10)
]
)

Full-Stack Dev / MLOps