
도서 자바의신을 참고하였습니다.
1. String 클래스
public final class String
extends Object
implements Serializable, Comparable<String>, CharSequenceString 클래스는 위와 같이 Serializable, Comparable<String>, CharSequence를 구현하고 있습니다.
Serializable: 구현해야하는 메소드가 없습니다. 그냥 선언하면 해당 객체를 파일로 저장하거나 다른 서버에 전송 가능한 상태가 됩니다.Comparable<String>: compareTo()라는 메소드 하나만 있는데, 객체 비교에 쓰이고 int값을 리턴합니다.CharSequence: 해당 클래스가 문자열을 다루기 위한 클래스라는 것을 명시적으로 나타냅니다.
String 클래스는 생성자가 굉장히 많은데, 그 중 가장 잘 쓰이는 것은 아래 2가지가 있습니다.
String(byte[] bytes): 현재 사용중인 플랫폼의 캐릭터 셋을 사용하여 제공된 byte배열을 디코딩한 String 객체를 생성합니다.String(byte[] bytes, String charsetName): 지정한 이름을 갖는 캐릭터 셋을 사용하여 지정한 byte배열을 디코딩한 String 객체를 생성합니다.
2. String -> byte
String에서 byte로 변환하는 방법은 getBytes() 메소드를 사용하는 것입니다.
byte[] getBytes(): 기본 캐릭터 셋의 바이트 배열을 생성합니다.byte[] getBytes(Charset charset): 지정한 캐릭터 셋 객체 타입으로 바이트 배열을 생성합니다.byte[] getBytes(String charsetName): 지정한 이름의 캐릭터 셋으로 바이트 배열을 생성합니다.
여기서 매개변수가 있는 getBytes() 메소드는 다른 시스템에서 전달받은 문자열을 byte 배열로 변환할 때 사용합니다. 이때, UnsupportedEncodingException 발생할 가능성이 있으므로 예외를 잡거나 던져주어야 합니다.
3. Charset
java.nio.charset.Charset 클래스 API에 정해진 표준 Charset은 다음과 같습니다.
- US-ASCII : 7bit ASCII
- ISO-8859-1 : ISO 라틴 알파벳
- UTF-8 : 8bit UCS(Unicode Character Set) 변환 포맷
- UTF-16BE : 16bit UCS 변환 포맷. big-endian byte 순서
- UTF-16LE : 16bit UCS 변환 포맷. little-endian byte 순서
- UTF-16 : 16bit UCS 변환 포맷. byte-order mark byte 순서
추가적으로 EUC-KR과 MS949라는 캐릭터 셋이 있는데, EUC-KR은 8bit 문자 인코딩으로, EUC의 일종이며 대표적인 한글 완성형 인코딩입니다. MS949는 Microsoft에서 만든 한글 확장 완성형 인코딩입니다.
byte배열로 생성할 때 사용한 캐릭터 셋을 문자열로 다시 전환할 때도 동일하게 사용해야 합니다.
byte[] arr = str.getBytes("UTF-16");
String str2 = new String(arr, "UTF-16");4. String Methods
1) length()
public int length()는 문자열의 길이를 리턴합니다. 이 때, 공백도 길이에 포함됩니다.
String strEn = "hello";
String strKr = "안녕하세요";
String blank = " ";
System.out.println("strEn.length() = " + strEn.length()); //5
System.out.println("strKr.length() = " + strKr.length()); //5
System.out.println("blank.length() = " + blank.length()); //12) isEmpty()
public boolean isEmpty()는 문자열이 비어있는지 확인하는 메소드입니다. 만약 문자열이 비어있을 경우 true를 리턴합니다. 공백도 문자열에 포함되므로 false를 리턴합니다.
String strEn = "hello";
String blank = " ";
String empty = "";
System.out.println("strEn.isEmpty() = " + strEn.isEmpty()); //false
System.out.println("blank.isEmpty() = " + blank.isEmpty()); //false
System.out.println("empty.isEmpty() = " + empty.isEmpty()); //true만약 공백도 true로 리턴하게끔 하려면 Java11부터 추가된 isBlank()을 사용하면 됩니다.
String blank = " ";
System.out.println("blank.isBlank() = " + blank.isBlank()); //true3) equals()
boolean equals(Object anObject)boolean equalsIgnoreCase(String anotherStr)
-> 위 두 메소드는 동일한 값인지 비교할 때 사용됩니다. 여기서 IgnoreCase가 붙은 메소드들은 대소문자 구분을 하지 않습니다.
String str1 = "Hi";
String str2 = "Hi";
String str3 = new String("Hi");
String str4 = new String("hi");
System.out.println(str1 == str2); //true
System.out.println("str1.equals(str2) = " + str1.equals(str2)); //true
System.out.println(str1 == str3); //false
System.out.println("str1.equals(str3) = " + str1.equals(str3)); //true
System.out.println("str1.equalsIgnoreCase(str4) = " + str1.equalsIgnoreCase(str4)); //true자바에서는 객체들을 재사용하기 위해 Constant Pool(상수 풀)이 있고, String의 경우 동일한 값을 갖는 객체가 있으면 이미 만든 객체를 재사용합니다. 따라서 str1==str2가 true로 나올 수 있었으나, 이는 지양하는 것이 좋습니다. 재사용하지 않으려면 str3과 같이 new 연산자를 사용해 String 객체를 새로 생성을 해주어야 합니다. str1==str3이 false가 나올 수 있던 이유입니다.
int compareTo(String anotherStr)int compareToIgnoreCase(String str)
-> compareTo() 메소드는 보통 정렬할 때 많이 사용됩니다. 매개변수가 알파벳순으로 앞에 있으면 양수, 뒤에 있으면 음수를 리턴합니다.
String textA = "a";
String textB = "b";
String textC = "c";
System.out.println("textB.compareTo(textA) = " + textB.compareTo(textA)); //1
System.out.println("textB.compareTo(textC) = " + textB.compareTo(textC)); //-1
System.out.println("textA.compareTo(textC) = " + textA.compareTo(textC)); //-2- boolean contentEquals(CharSequence cs)
- boolean contentEquals(StringBuffer sb)
-> 매개변수로 넘어오는 CharSequence를 구현한 클래스의 객체가 String 객체와 동일한지 비교합니다.
String str = "hi";
StringBuffer sb = new StringBuffer("hi");
StringBuilder builder = new StringBuilder("hi");
System.out.println("str.equals(sb) = " + str.equals(sb)); //false
System.out.println("str.contentEquals(sb) = " + str.contentEquals(sb)); //true
System.out.println("str.contentEquals(builder) = " + str.contentEquals(builder)); //true4) 특정 조건에 문자열이 있는지 확인하는 메소드
boolean startsWith(String prefix): 가장 많이 사용하는 메소드로 prefix로 시작하는지 확인.boolean startsWith(String prefix, int toffset): 위 메소드와 동일하나 어디서부터 찾을지 지정 가능.boolean endsWith(String suffix): suffix로 끝나는지 확인.boolean contains(CharSequence s): 매개변수로 들어온 s값이 문자열에 존재하는지 확인. 중간에 있는 값 확인할 때 사용.boolean matches(String regex): 정규표현식에 맞는 문자열인지 확인.
boolean regionMatches(boolean ignoreCase, int toffset, String other, int ooffset, int len)boolean regionMatches(int toffset, String other, int ooffset, int len)
-> 문자열 중에서 특정 영역이 매개변수로 넘어온 문자열과 동일한지 확인.
- ignoreCase : true일 경우 대소문자 구분 없이 값 비교
- toffset : 비교 대상 문자열의 확인 시작 위치 지정
- other : 존재하는지를 확인할 문자열
- ooffset : other 객체의 확인 시작 위치 지정
- len : 비교할 char의 개수 지정
5) indexOf()
int indexOf(int ch): char는 정수형으로 자동으로 형변환해줍니다.int indexOf(int ch, int fromIndex)int indexOf(String str)int indexOf(String str, int fromIndex)
-> 앞에서부터 문자열이나 char를 찾는 메소드입니다. 0부터 시작하며, 찾고자 하는 값이 없으면 -1을 리턴합니다.
int lastIndexOf(int ch)int lastIndexOf(int ch, int fromIndex)int lastIndexOf(String str)int lastIndexOf(String str, int fromIndex)
-> 뒤에서부터 찾는 메소드입니다.
6) char단위 값 추출하는 메소드
char charAt(int index): 특정 위치의 char값을 리턴함.void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin): dst라는 char배열 내에 srcBegin에서 srcEnd 사이에 있는 char를 저장하는데 이때, dst배열의 시작 위치는 dstBegin입니다.int codePointAt(int index): 특정 위치의 유니코드 값 리턴. 리턴 타입은 int지만 char로 형 변환도 가능.int codePointBefore(int index): 특정 위치 앞에 있는 char의 유니코드 값 리턴. 리턴 타입은 int지만 char로 형변환도 가능.int codePointCount(int beginIndex, int endIndex): 지정한 범위에 있는 유니코드 개수 리턴.int offsetByCodePoints(int index, int codePointOffset): 지정된 index부터 offset이 설정된 인덱스를 리턴. 문자열 인코딩과 관련된 문제를 해결하기 위해서 사용됨.
7) Char -> String, String -> Char
(1) Char -> String
static String copyValueOf(char[] data): char배열에 있는 값을 문자열로 변환함.static String copyValueOf(char[] data, int offset, int count): char배열에 있는 값을 문자열로 변환함. 단, offset 위치부터 count까지의 개수만큼만 문자열로 변환함.
char[] values = new char[]{'H', 'e', 'l', 'l', 'o'};
String str = String.copyValueOf(values);
System.out.println("str = " + str); //Hello
str = String.copyValueOf(values, 1, 2);
System.out.println("str = " + str); //el(2) String -> Char
char[] toCharArray(): 문자열을 char 배열로 변환함.
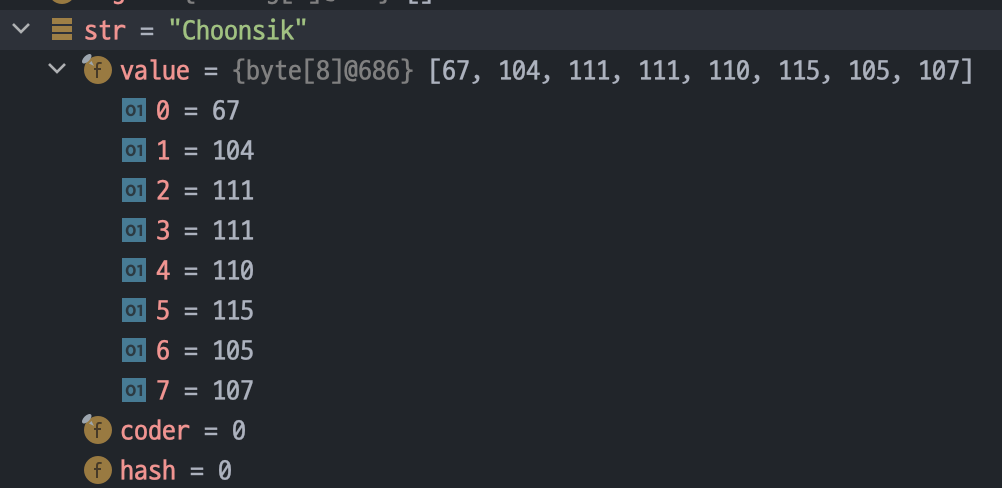
어떤 String 객체를 만들더라도, 그 객체 내부에는 char 배열을 포함합니다.
8) substring()
String substring(int beginIndex): beginIndex부터 끝까지 대상 문자열을 잘라 String으로 리턴함.String substring(int beginIndex, int endIndex): beginIndex부터 endIndex까지 대상 문자열을 잘라 String으로 리턴함.CharSequence subSequence(int beginIndex, int endIndex): beginIndex부터 endIndex까지 대상 문자열을 잘라 CharSequence로 리턴함.
9) split()
String[] split(String regex): regex(정규표현식)에 맞추어 문자열을 잘라 String 배열로 리턴함.String[] split(String regex, int limit): 위 메소드와 동일하나 limit보다 커서는 안됨.
자바에서 문자열을 나누는 방법에는 split()메소드와 StringTokenizer를 활용한 방법 2가지가 있습니다.
| split() | StringTokenizer | |
|---|---|---|
| 정규 표현식 | ⭕️ | ❌ |
| 특정 String | ❌ | ⭕️ |
| 특정 알파벳이나 기호 하나 | ⭕️ | ⭕️ |
10) replace()
String replace(char oldChar, char newChar): 해당 문자열에 있는 oldChar의 값을 newChar로 대치함.String replace(CharSequence target, CharSequence replacement): 해당 문자열에 있는 target과 같은 값을 replacement로 대치함.String replaceAll(String regex, String replacement): regex(정규표현식)에 포함되는 모든 내용을 replacement로 대치함.String replaceFirst(String regex, String replacement): regex(정규표현식)에 포함되는 첫번째 내용을 replacement로 대치함.
하지만 위 메소드를 사용한다고 해서 기존 문자열의 값은 바뀌지 않습니다. 또한 대소문자를 구분합니다.
String str = "Choonsik";
System.out.println("str.replace('o', 'z') = " + str.replace('o', 'z')); //Chzznsik
System.out.println("str.replace('c', 'a') = " + str.replace('c', 'a')); //Choonsik
System.out.println("str = " + str); //Choonsik11) format()
static String format(String format, Object...args): format에 있는 문자열의 내용 중 변환해야 하는 부분을 args의 내용으로 변경함.static String format(Locale l, String format, Object...args): 위 메소드와 동일하며, Locale 타입 l에 선언된 지역에 맞추어 출력함. 만약 Locale을 지정하지 않으면 자바 프로그램이 수행되는 OS의 지역 정보 제공함.
String str = "제 이름은 %s 입니다. 나이는 %d살 입니다.";
String realStr = String.format(str, "춘식이", 3);
System.out.println("realStr = " + realStr); //제 이름은 춘식이 입니다. 나이는 3살 입니다.대치해야할 문자열이 n개일 때, format뒤에 n+m개가 오는 것은 상관없지만 n개보다 적은 변수를 명시하면 MissingFormatArgumentException이 발생합니다.
String realStr = String.format(str, "춘식이");
Exception in thread "main" java.util.MissingFormatArgumentException: Format specifier '%d'12) 대소문자 바꾸는 메소드
String toLowerCase()String toLowerCase(Locale locale)
-> 모든 문자열을 소문자로 변경하는데, 지정한 지역 정보에 맞추어 변경할 수도 있습니다.
String toUpperCase()String toUpperCase(Locale locale)
-> 모든 문자열을 대문자로 변경하는데, 지정한 지역 정보에 맞추어 변경할 수도 있습니다.
13) 기본자료형 -> 문자열
static String valueOf(boolean b)static String valueOf(char c)static String valueOf(char[] data)static String valueOf(char[] data, int offset, int count)static String valueOf(double d)static String valueOf(float f)static String valueOf(int i)static String valueOf(long l)static String valueOf(Object obj): toString()을 구현한 객체나 정상적인 객체를 매개변수로 넘기면 toString()의 결과를 리턴합니다. 만약 null이 넘어오면 "null"이라는 문자열을 리턴해줍니다.
String str = null;
System.out.println(str); //null14) intern()
intern() 메소드는 절대로 사용해서는 안되는 메소드입니다. 자바로 구현되지 않고 C로 구현되어 있는 native 메소드 중 하나입니다.
5. StringBuffer, StringBuilder
String은 immutable 객체입니다. String 문자열을 더하면 새로운 String 객체가 생서되고, 기존 객체는 GC의 대상이 됩니다. 따라서 이 점을 보완하기 위해 StringBuffer와 StringBuilder가 탄생하게 됩니다. 둘 다 모두 CharSequence 인터페이스의 구현 클래스입니다.매개변수로 받는 작업할 때 String이나 StringBuilder보다는 CharSequence 타입으로 받는 것이 좋습니다.
- StringBuffer : Thread Safe. 인스턴스 변수가 선언되고 여러 thread에서 이 변수를 동시에 접근할 때 사용
- StringBuilder : 빠름. JDK5부터 String에서 더하기 연산을 사용할 경우 컴파일할 때 자동으로 해당 연산은 StringBuilder로 변환함. 하나의 메소드 내에서 문자열을 생성하여 더할 떄 사용.
StringBuffer와 StringBuilder는 문자열을 더하더라도 새로운 객체를 새로 생성하지 않습니다. 또한 더할 때는 append()라는 메소드를 사용하는데, 매개변수로 모든 기본 자료형과 참조 자료형이 포함됩니다.
지속적으로 수정해나갈 예정입니다.
2023-07-23 v1.0

잘 읽었습니다. 좋은 정보 감사드립니다.